PyTorch 中特征变换:卷积与转置卷积
在深度学习尤其是计算机视觉领域,卷积操作是提取特征的核心手段,而转置卷积则承担着上采样、恢复特征维度的关键作用。今天我们就结合 PyTorch 的nn.Conv2d和nn.ConvTranspose2d,深入解析这两种操作的原理、参数与应用。
一、基础卷积:nn.Conv2d—— 特征的 “提炼者”
1. 核心功能
nn.Conv2d的作用是对多个二维信号(如图像的多个通道)进行二维卷积,通过滑动卷积核对输入特征图进行局部加权求和,从而提取更抽象的特征(如边缘、纹理、物体部件等)。
二、卷积的各种类型(第二部分来自于此文章)
https://blog.csdn.net/weixin_44505185/article/details/126817075?fromshare=blogdetail&sharetype=blogdetail&sharerId=126817075&sharerefer=PC&sharesource=sweet_ran&sharefrom=from_link![]() https://blog.csdn.net/weixin_44505185/article/details/126817075?fromshare=blogdetail&sharetype=blogdetail&sharerId=126817075&sharerefer=PC&sharesource=sweet_ran&sharefrom=from_link
https://blog.csdn.net/weixin_44505185/article/details/126817075?fromshare=blogdetail&sharetype=blogdetail&sharerId=126817075&sharerefer=PC&sharesource=sweet_ran&sharefrom=from_link
1、标准卷积
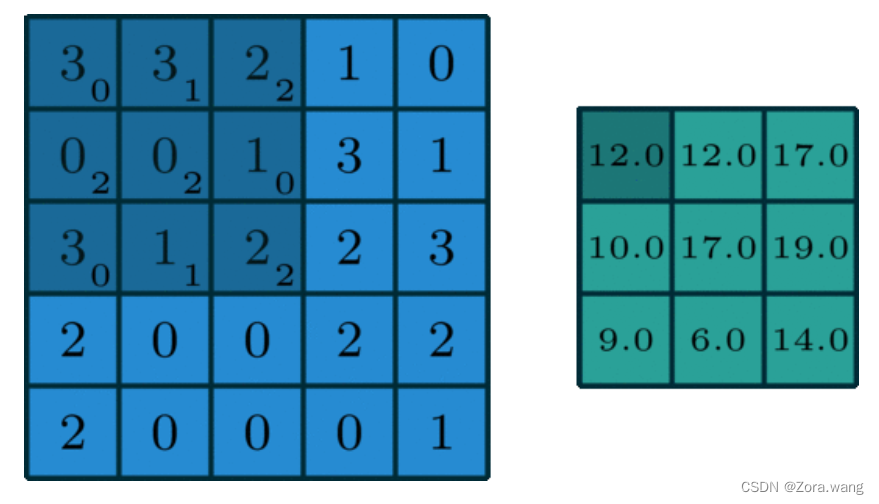
(1)二维卷积(单通道卷积版本)(2D Convolution: the single channel version)
只有一个通道的卷积。
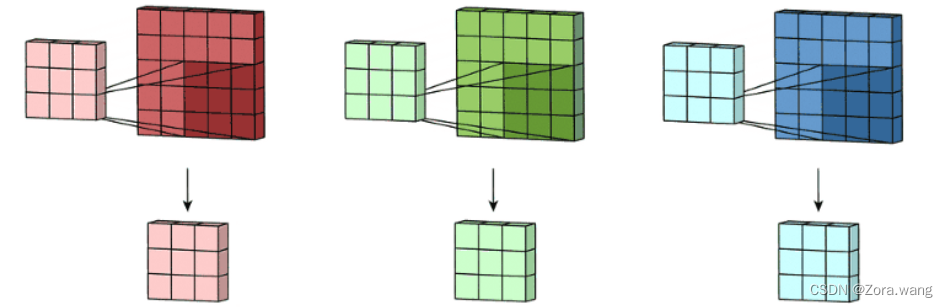
(2)二维卷积(多通道版本)(2D Convolution: the multi-channel version)
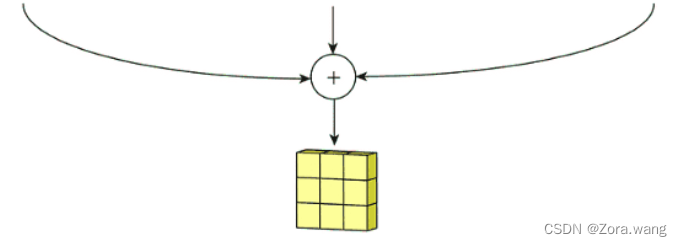
拥有多个通道的卷积,例如处理彩色图像时,分别对R, G, B这3个层处理的3通道卷积。实际我们上是对一个 3D 体积执行卷积。但通常而言,我们仍在深度学习中称之为 2D 卷积。这是在 3D 体积数据上的 2D 卷积。过滤器深度与输入层深度一样。这个 3D 过滤器仅沿两个方向移动(图像的高和宽),再将三个通道的卷积结果进行合并(一般采用元素相加),这种操作的输出是一张 2D 图像(仅有一个通道),如下图:
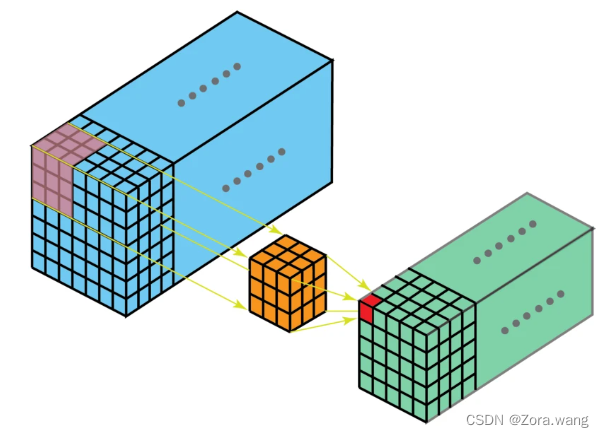
(3)三维卷积(3D Convolution)
这是 2D 卷积的泛化。3D 卷积的过滤器深度小于输入层深度(核大小<通道大小)。因此,3D 过滤器可以在所有三个方向(图像的高度、宽度、通道)上移动。在每个位置,逐元素的乘法和加法都会提供一个数值。因为过滤器是滑过一个 3D 空间,所以输出数值也按 3D 空间排布。也就是说输出是一个 3D 数据。如下图:
(4)1x1卷积(1 x 1 Convolution)
当卷积核尺寸为1x1时的卷积,也即卷积核变成只有一个数字。如下图:
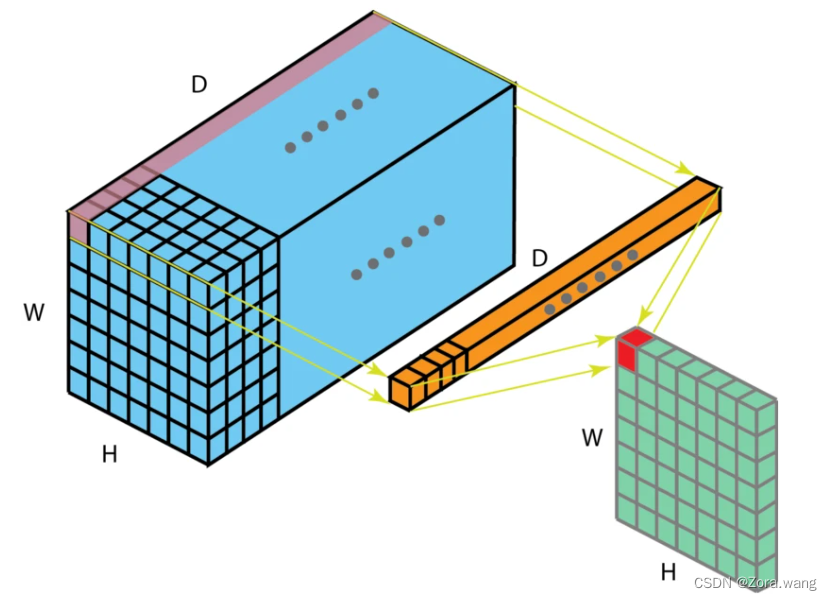
从上图可以看出,1x1卷积的作用在于能有效地减少维度(channel),降低计算的复杂度。1x1卷积在GoogLeNet网络结构中广泛使用。
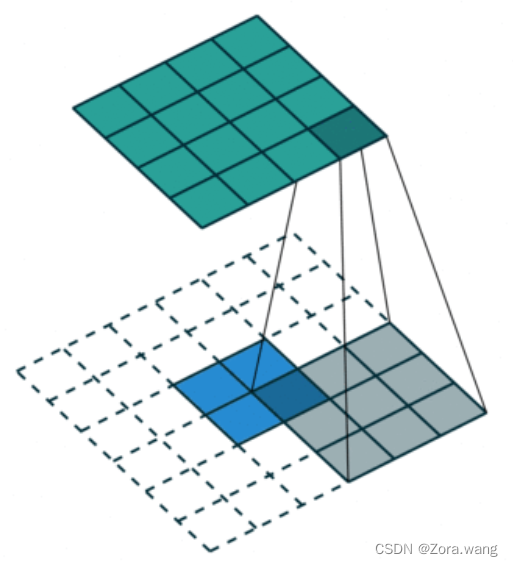
2、反卷积(转置卷积 / 去卷积)(Deconvolution / Transposed / Fractionally Strided Convolution)
卷积是对输入图像提取出特征(可能尺寸会变小),而所谓的“反卷积”便是进行相反的操作。但这里说是“反卷积”并不严谨,因为并不会完全还原到跟输入图像一样,一般是还原后的尺寸与输入图像一致,主要用于向上采样。实现上采样的传统方法是应用插值方案或人工创建规则。而神经网络等现代架构则倾向于让网络自己自动学习合适的变换,“反卷积”相当于是将卷积核转换为稀疏矩阵后进行转置计算,因此,也被称为“转置卷积”
如下图,在2x2的输入图像上应用步长为1、边界全0填充的3x3卷积核,进行转置卷积(反卷积)计算,向上采样后输出的图像大小为4x4
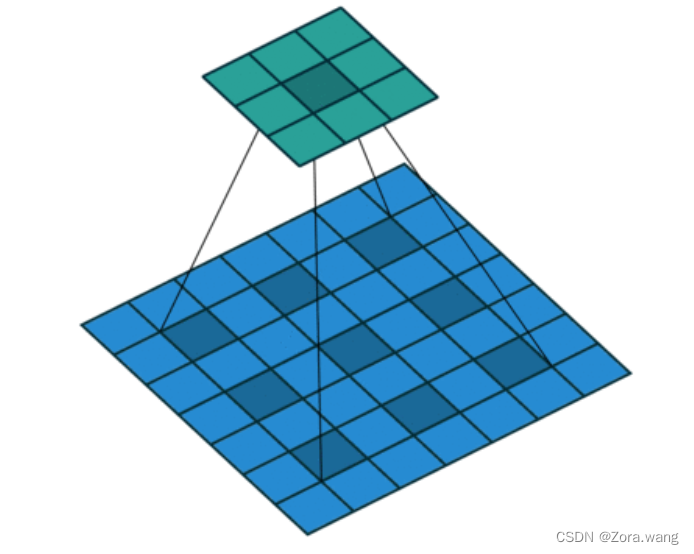
3、空洞卷积(膨胀卷积)(Dilated Convolution / Atrous Convolution)
为扩大感受野,在卷积核里面的元素之间插入空格来“膨胀”内核,形成“空洞卷积”(或称膨胀卷积),并用膨胀率参数L表示要扩大内核的范围,即在内核元素之间插入L-1个空格。当L=1时,则内核元素之间没有插入空格,变为标准卷积。
如下图为膨胀率L=2的空洞卷积:
2. 关键参数解析
in_channels:输入特征图的通道数。例如,RGB 图像的in_channels=3,灰度图则为1。out_channels:输出特征图的通道数,等价于卷积核的个数。每个卷积核学习一种特定的特征模式,out_channels越多,模型能提取的特征种类越丰富。kernel_size:卷积核的尺寸(如3表示3×3的方形卷积核,也可传入元组(3, 5)表示矩形卷积核)。stride:卷积核滑动的步长。步长越大,输出特征图尺寸缩小得越快。padding:在输入特征图边缘填充的像素数。用于控制输出特征图的尺寸,避免因卷积导致尺寸过度缩小(如padding=1可让3×3卷积核在32×32输入上输出32×32的特征图)。dilation:空洞卷积的膨胀率。若dilation>1,卷积核元素间会插入空洞,从而扩大感受野(例如dilation=2时,3×3卷积核的实际感受野相当于5×5,但参数数量不变)。groups:分组卷积的组数。用于控制输入输出通道的连接方式(如groups=in_channels时为深度可分离卷积,大幅减少参数量)。bias:是否添加偏置项。偏置为每个输出通道提供一个可学习的偏移量,使模型更灵活。
3. 代码示例
import torch
import torch.nn as nn# 定义一个卷积层:输入3通道,输出16通道,3×3卷积核,步长1,填充1
conv = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=1, padding=1)
x = torch.randn(1, 3, 32, 32) # 模拟输入:batch_size=1,3通道,32×32
output = conv(x)
print(output.shape) # 输出: torch.Size([1, 16, 32, 32])三、转置卷积:nn.ConvTranspose2d—— 特征的 “放大器”
1. 核心功能
nn.ConvTranspose2d实现转置卷积(也叫反卷积),主要用于上采样—— 将小尺寸的特征图放大到更大的尺寸,常见于图像生成(如 GAN)、语义分割(如 U-Net)等需要恢复空间分辨率的任务。
2. 关键参数解析
转置卷积的参数与普通卷积高度对应,但作用逻辑有所不同:
in_channels/out_channels:输入 / 输出通道数,含义与nn.Conv2d一致。kernel_size/stride/padding:这些参数决定了上采样的 “放大倍数”。例如,当stride=2时,输出特征图的尺寸通常是输入的 2 倍(需结合padding等参数计算)。output_padding:转置卷积特有的参数,用于微调输出尺寸。当普通卷积的stride>1时,转置卷积可能因整除问题导致输出尺寸偏差,output_padding可手动补充像素修正。dilation/groups/bias:含义与nn.Conv2d一致,用于空洞卷积、分组卷积和偏置控制。
3. 代码示例
# 定义一个转置卷积层:输入16通道,输出3通道,3×3卷积核,步长2,填充1
conv_trans = nn.ConvTranspose2d(in_channels=16, out_channels=3, kernel_size=3, stride=2, padding=1)
x = torch.randn(1, 16, 16, 16) # 模拟输入:batch_size=1,16通道,16×16
output = conv_trans(x)
print(output.shape) # 输出: torch.Size([1, 3, 32, 32]) (实现2倍上采样)四、卷积与转置卷积的核心差异
| 维度 | 普通卷积(nn.Conv2d) | 转置卷积(nn.ConvTranspose2d) |
|---|---|---|
| 功能 | 下采样 / 特征提取 | 上采样 / 特征恢复 |
| 尺寸变化 | 输入尺寸 ≥ 输出尺寸(stride≥1) | 输入尺寸 ≤ 输出尺寸(stride≥1) |
| 典型场景 | 分类网络的特征提取(如 ResNet) | 生成网络的上采样(如 DCGAN)、分割网络的解码(如 U-Net) |
| 参数逻辑 | 参数决定 “如何压缩特征” | 参数决定 “如何放大特征” |
五、实际应用:U-Net 中的 “卷积 - 转置卷积” 协作
以语义分割经典模型 U-Net 为例,其结构完美体现了两者的协作:
- 编码阶段(下采样):通过
nn.Conv2d+nn.MaxPool2d不断缩小特征图尺寸,同时增加通道数,提取更抽象的特征。 - 解码阶段(上采样):通过
nn.ConvTranspose2d逐步放大特征图尺寸,同时与编码阶段的特征图拼接(Skip Connection),恢复细节信息,最终输出与输入尺寸一致的分割结果。
class UNetBlock(nn.Module):def __init__(self, in_channels, out_channels):super().__init__()self.conv = nn.Sequential(nn.Conv2d(in_channels, out_channels, 3, padding=1),nn.ReLU(),nn.Conv2d(out_channels, out_channels, 3, padding=1),nn.ReLU(),)self.up = nn.ConvTranspose2d(out_channels, out_channels // 2, 2, stride=2) # 转置卷积上采样def forward(self, x, skip):x = self.conv(x)x = self.up(x)x = torch.cat([x, skip], dim=1) # 拼接编码阶段的特征return x六、总结
nn.Conv2d是深度学习中 “提炼” 特征的核心工具,通过下采样和卷积核提取抽象模式;而nn.ConvTranspose2d则是 “还原” 特征的关键手段,通过上采样恢复空间细节。两者相辅相成,共同支撑起从图像分类到生成、分割等复杂视觉任务的实现。理解它们的参数与逻辑,是掌握深度学习视觉模型的重要基础。