深度学习中的池化、线性层与激活函数
在深度学习模型,尤其是卷积神经网络(CNN)的构建中,池化层、线性层和激活函数层扮演着至关重要的角色。它们相互配合,让模型能够高效地提取特征、进行计算和引入非线性,从而完成复杂的任务。
一、池化层:特征的 “筛选与浓缩”
池化层的主要作用是对特征图进行下采样,减少参数数量,降低计算复杂度,同时还能在一定程度上保持特征的平移不变性,增强模型的泛化能力。常见的池化层有最大值池化、平均池化,还有用于上采样的最大值反池化。
1. 最大值池化(Max Pooling)
- 功能:在指定的池化窗口内,选取最大值作为该窗口的输出。这样可以提取出窗口内最显著的特征,突出图像中的强响应区域,比如物体的边缘、纹理等关键特征。
- 示例代码(PyTorch):
import torch.nn as nn# 定义一个2×2的最大值池化层,步长为2
max_pool = nn.MaxPool2d(kernel_size=2, stride=2)
# 模拟输入,batch_size为1,通道数为3,特征图尺寸为32×32
input_data = torch.randn(1, 3, 32, 32)
output = max_pool(input_data)
print(output.shape) # 输出:torch.Size([1, 3, 16, 16])- 特点:对局部特征的变化比较敏感,能更好地保留图像中的尖锐特征。
2. 平均池化(Average Pooling)
- 功能:在池化窗口内计算所有元素的平均值作为输出。它更注重对窗口内特征的整体平均水平的提取,能平滑图像,减少噪声的影响。
- 示例代码(PyTorch):
# 定义一个2×2的平均池化层,步长为2
avg_pool = nn.AvgPool2d(kernel_size=2, stride=2)
input_data = torch.randn(1, 3, 32, 32)
output = avg_pool(input_data)
print(output.shape) # 输出:torch.Size([1, 3, 16, 16])- 特点:计算简单,对特征的整体表示更平滑,但可能会丢失一些细节信息。
3. 最大值反池化(Max Unpooling)
- 功能:最大值池化的逆操作,用于上采样,将小尺寸的特征图恢复到较大的尺寸。在一些需要还原特征图尺寸的任务(如语义分割的解码阶段)中非常有用。它需要结合最大值池化时记录的最大值位置信息来进行准确的上采样。
- 示例代码(PyTorch):
# 先进行最大值池化并记录最大值位置
max_pool = nn.MaxPool2d(kernel_size=2, stride=2, return_indices=True)
input_data = torch.randn(1, 3, 32, 32)
output_pool, indices = max_pool(input_data)# 定义最大值反池化层,将特征图上采样回32×32
max_unpool = nn.MaxUnpool2d(kernel_size=2, stride=2)
output_unpool = max_unpool(output_pool, indices)
print(output_unpool.shape) # 输出:torch.Size([1, 3, 32, 32])- 特点:能够利用池化时的位置信息,较为精准地还原特征图,但依赖于最大值池化的中间信息。
二、线性层:特征的 “线性映射”
线性层(也称为全连接层)的作用是对输入进行线性变换,将输入的特征映射到新的维度空间。其数学表达式为 y=Wx+b,其中 W 是权重矩阵,x 是输入,b 是偏置项。
功能与特点
- 线性层可以将前面提取到的特征进行整合,将高维的特征映射到低维(如分类任务的类别数)或者其他需要的维度。
- 但如果没有非线性激活函数的配合,多个线性层的堆叠仍然是线性变换,无法学习复杂的非线性关系,模型的表达能力会受到很大限制。
示例代码(PyTorch)
# 定义一个线性层,输入维度为100,输出维度为10(用于10分类任务)
linear = nn.Linear(in_features=100, out_features=10)
# 模拟输入,batch_size为32,特征维度为100
input_data = torch.randn(32, 100)
output = linear(input_data)
print(output.shape) # 输出:torch.Size([32, 10])三、激活函数层:模型的 “非线性催化剂”
激活函数为模型引入了非线性因素,使得模型能够学习复杂的非线性关系,从而处理各种复杂的任务。常见的激活函数有 Sigmoid、Tanh、ReLU 及其改进版本。
1. Sigmoid 函数
- 公式:
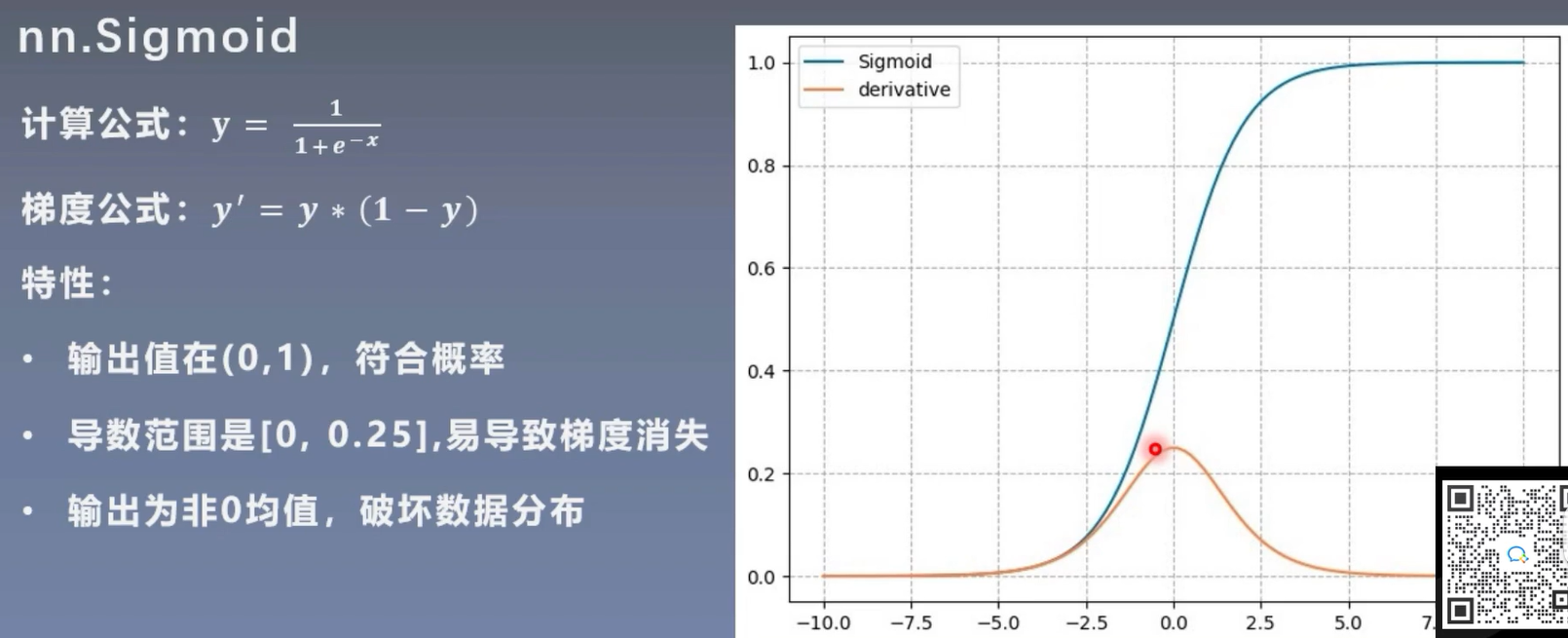
- 特点:将输入映射到\([0, 1]\)区间,适合用于二分类任务的输出层,也可用于隐藏层。但存在梯度消失问题,当输入值过大或过小时,梯度趋近于 0,不利于深层网络的训练。
- 示例代码(PyTorch):
sigmoid = nn.Sigmoid()
input_data = torch.randn(1, 10)
output = sigmoid(input_data)
print(output) # 输出值在0到1之间2. Tanh 函数
- 公式:
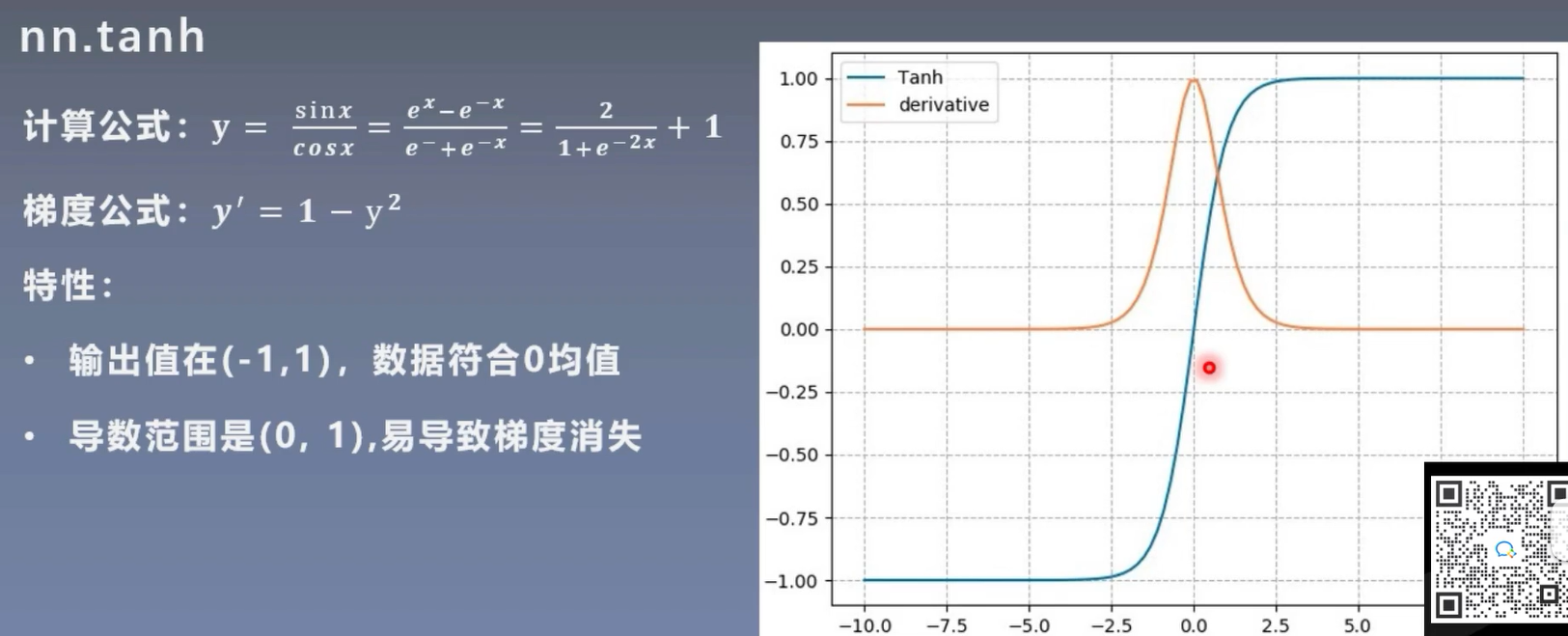
- 特点:将输入映射到\([-1, 1]\)区间,相比 Sigmoid,其输出以 0 为中心,在一定程度上缓解了梯度消失问题,但仍然存在梯度消失的情况,且计算复杂度较高。
- 示例代码(PyTorch):
tanh = nn.Tanh()
input_data = torch.randn(1, 10)
output = tanh(input_data)
print(output) # 输出值在-1到1之间3. ReLU 函数
- 公式:
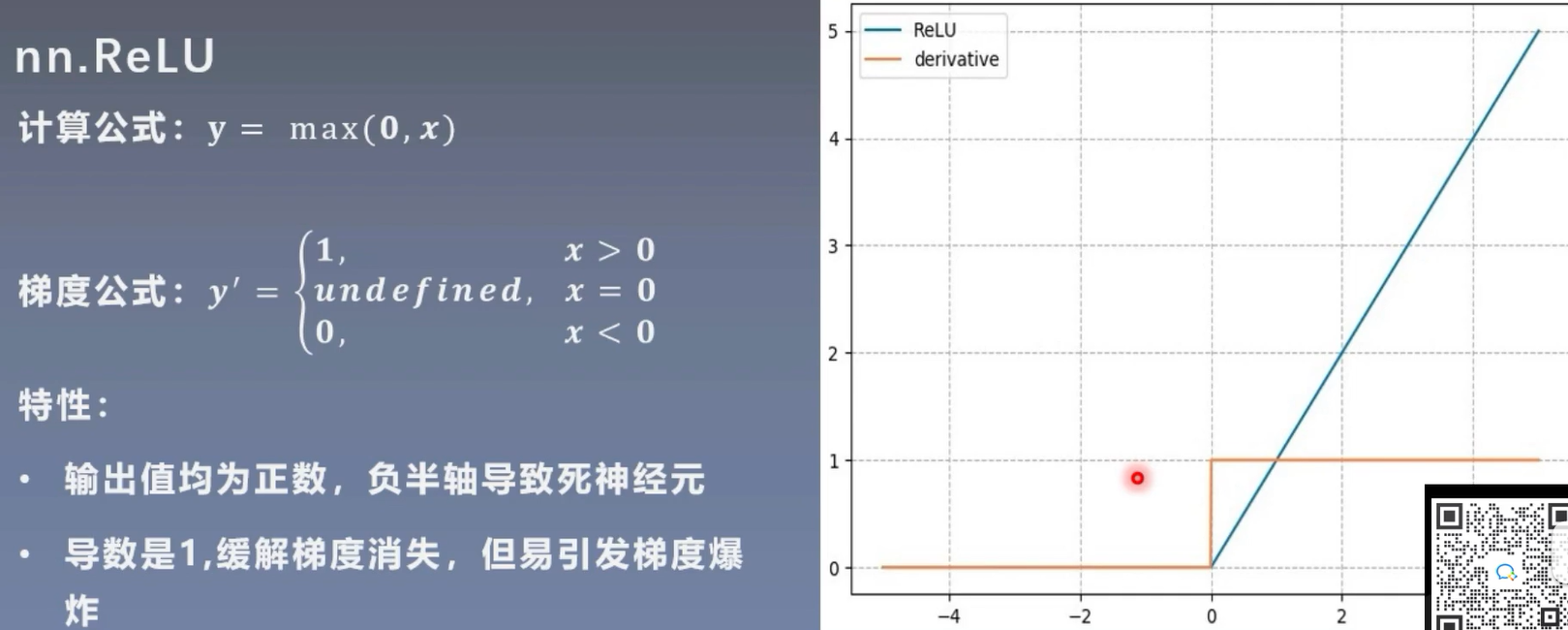
- 特点:当输入大于 0 时,输出为输入本身;当输入小于等于 0 时,输出为 0。它有效缓解了梯度消失问题,计算简单,收敛速度快,是目前使用最广泛的激活函数之一。但存在 “死亡 ReLU” 问题,即某些神经元可能永远不会被激活,导致参数无法更新。
- 示例代码(PyTorch):
relu = nn.ReLU()
input_data = torch.randn(1, 10)
output = relu(input_data)
print(output) # 负数部分被置为04. ReLU 改进版本(以 Leaky ReLU 为例)
- 公式:\(f(x) = \max(\alpha x, x)\)(其中\(\alpha\)是一个很小的正数,如 0.01)
- 特点:解决了 “死亡 ReLU” 问题,当输入小于 0 时,不再输出 0,而是输出一个很小的正值,使得所有神经元都有机会被激活,参数能够更新。
- 示例代码(PyTorch):
leaky_relu = nn.LeakyReLU(negative_slope=0.01)
input_data = torch.randn(1, 10)
output = leaky_relu(input_data)
print(output) # 负数部分输出为0.01×输入四、总结
池化层负责对特征进行筛选和浓缩,减少计算量并增强泛化能力;线性层承担特征的线性映射任务;而激活函数则为模型注入非线性,让模型能够学习复杂的关系。这三者相互配合,共同构建出强大的深度学习模型,在图像分类、目标检测、语义分割等众多领域发挥着重要作用。