Diffusion Model与视频超分(1):解读淘宝开源的视频增强模型Vivid-VR
前言:近年来,基于扩散的生成模型取得了显著进展,现已能够合成逼真的内容,这一进步确立了生成式视频修复作为一种有前景的新范式。Vivid-VR 首先使用 CogVLM2-Video 处理低质量(LQ)输入视频,生成文本描述,并通过 T5 编码器将其编码为文本标记。同时,3D VAE 编码器将输入视频转换为潜在表示,我们的控制特征投影器在此去除退化伪影。为了增强可控性,引入了一个双分支连接器,一个用于特征映射的 MLP 和一个用于动态控制特征检索的交叉注意力分支,实现自适应的输入对齐。
目录
贡献概述
背景介绍
基于扩散模型的视频超分模型的问题
解决方案
方法详解
方法概述
文本描述生成
控制特征预处理
ControlNet 流程
概念蒸馏
训练细节
双分支Controlnet消融实验

贡献概述
我们提出了基于dit的生成视频恢复方法Vivid-VR,该方法建立在先进的T2V基础模型之上,利用ControlNet来控制生成过程,确保内容的一致性。然而,由于多模态排列不完美的限制,这种可控管道的传统微调经常受到分布漂移的影响,导致纹理真实感和时间一致性受损。为了解决这一挑战,我们提出了一种概念蒸馏训练策略,该策略利用预训练的T2V模型合成具有嵌入文本概念的训练样本,从而提取其概念理解以保持纹理和时间质量。为了增强生成的可控性,我们用两个关键组件重新设计了控制架构:1)一个控制特征投影层,它可以过滤输入视频电位中的退化伪影,以最大限度地减少它们在生成管道中的传播,以及2)一个采用双分支设计的新型ControlNet连接器。该连接器将基于mlp的特征映射与动态控制特征检索的交叉注意机制协同结合,实现了内容保存和自适应控制信号调制。大量的实验表明,在合成和现实世界的基准测试以及AIGC视频中,与现有的方法相比,Vivid-VR表现良好,实现了令人印象深刻的纹理真实感、视觉生动性和时间一致性。
• 我们提出了一种新颖的概念蒸馏训练策略,利用预训练的 T2V 模型合成对齐的文本-视频配对数据,有效缓解了微调过程中的分布漂移问题,同时保持了纹理质量和时序一致性。
• 我们改进了 ControlNet 架构,引入了轻量级的控制特征投影器和双分支连接器,实现了退化伪影的去除和动态控制特征的检索。
• 所提出的 Vivid-VR 方法在合成数据、真实世界基准数据以及 AIGC 视频上均优于现有方法,表现出卓越的修复性能。
背景介绍
基于扩散模型的视频超分模型的问题
近年来,基于扩散的生成模型取得了显著进展,现已能够合成逼真的内容。这一进步确立了生成式视频修复作为一种有前景的新范式。虽然早期基于文本到图像(T2I)扩散模型的探索在图像修复任务中取得了令人印象深刻的结果,但其直接应用于视频序列时,由于运动建模不足,往往会出现严重的时序不一致问题。为解决这一局限性的早期尝试通常引入时序增强机制,包括在扩散去噪器和VAE解码器中添加可训练的时序层,或采用基于光流的运动补偿。然而,这些在模型微调过程中的后修改方法不足以实现强健的时序一致性。扩散Transformer(DiT)的出现推动了显著进步,使得文本到视频(T2V)模型现在能够生成高质量且时序稳定的视频内容。这促进了基于T2V的修复方法的发展。例如,SeedVR 将移窗注意力机制与DiT结合以提高计算效率,STAR提出了一种动态频率损失以增强保真度,两者均取得了不错的效果。
尽管已有显著进展,当前的修复方法在纹理真实感和时序一致性方面仍逊于原生的T2V模型。这一性能差距主要源于微调过程中不完美的多模态对齐所导致的分布漂移。这一问题在T2V模型的预训练阶段并不显著,因为其依赖大规模且多样化的训练数据集。但在将这些模型微调用于视频修复时,该挑战被显著放大,表现为生成的纹理不真实以及时序一致性下降。
解决方案
为应对这一挑战,我们提出一种概念蒸馏训练策略,利用预训练T2V模型生成的合成数据。该方法首先获取源视频及其通过视觉-语言模型(VLM)获得的对应文本描述。我们首先对源视频添加噪声,然后利用预训练的T2V模型在结合文本描述的情况下进行去噪。此过程生成的视频封装了T2V模型对文本概念的语义理解,确保在T2V模型的潜在空间中,生成视频与文本描述之间实现完美的模态对齐。在微调过程中,通过将这些合成数据与真实训练样本混合,我们的方法成功地将T2V模型的概念性知识迁移到视频修复模型中,从而缓解了分布漂移问题,同时保留了纹理的真实感和时序的一致性。
此外,我们使用 ControlNet 实现生成控制,并引入了两项关键创新。首先,我们设计了一种控制特征投影器(control feature projector),能够有效滤除退化伪影,最大限度地减少其在生成过程中的传播。FaithDiff 虽然实现了类似功能,但其通过联合微调 VAE 编码器来达成,训练成本较高;而我们的解决方案将该特征投影器实现为 VAE 编码器上的轻量级 CNN 扩展模块,显著降低了开销。其次,我们采用双分支架构重新设计了 ControlNet 的连接器(connector)。不同于现有连接器 在特征融合过程中未能充分考虑 DiT 特征的问题,我们结合了 MLP 分支与交叉注意力机制,实现了动态特征检索,从而在保留原生 T2V 模型生成质量与真实感的同时,增强了控制能力。得益于这些改进,所提出的方法(命名为 Vivid-VR)在纹理真实感和视觉生动性方面表现出色(见图1)。
方法详解
方法概述
Vivid-VR 首先使用 CogVLM2-Video 处理低质量(LQ)输入视频,生成文本描述,并通过 T5 编码器将其编码为文本标记。同时,3D VAE 编码器将输入视频转换为潜在表示,我们的控制特征投影器在此去除退化伪影。随后,视频的潜在表示被分块、加噪,并与文本标记及时间步嵌入一同作为输入送入 DiT 和 ControlNet。为了增强可控性,我们引入了一个双分支连接器:一个用于特征映射的 MLP 和一个用于动态控制特征检索的交叉注意力分支,实现自适应的输入对齐。经过 T 次去噪步骤后,3D VAE 解码器重建出高质量(HQ)输出视频。训练过程中,仅控制特征投影器、ControlNet 和连接器通过所提出的概念蒸馏策略进行训练,其余参数保持冻结。
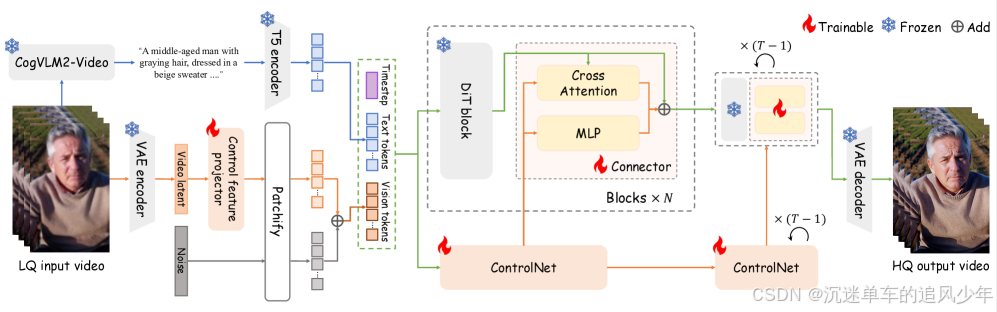
文本描述生成
基于T2V框架,所提出的方法需要低质量(LQ)输入视频及其对应的文本描述。我们采用 CogVLM2-Video [40] 生成文本,以与 CogVideoX1.5-5B 的训练配置保持一致,因为在该模型的训练中,此视觉语言模型(VLM)即被用作视频描述生成器(captioner)。对于给定的LQ输入视频,CogVLM2-Video 生成一个对齐的文本描述,随后通过 T5 [23] 文本编码器将其编码为文本标记(text tokens)。
控制特征预处理
在生成文本标记的同时,我们对LQ输入视频进行预处理,以生成供DiT和ControlNet使用的视觉标记(visual tokens)。该预处理流程首先通过VAE编码器对LQ视频进行编码,得到包含内容信息和退化伪影的潜在表示。由于这些退化伪影可能对生成质量产生负面影响,我们提出了一种轻量级的控制特征投影器(Control Feature Projector)来消除它们。该投影器由三个级联的时空残差块构成,能够有效滤除退化特征,输出更干净的潜在表示。随后,将视频的潜在表示进行分块(patchified)并注入噪声,形成用于后续处理的视觉标记。
ControlNet 流程
在给定文本标记、视觉标记和时间步嵌入(timestep embedding)的情况下,DiT 和 ControlNet 共同执行 T 次去噪步骤。DiT 包含 N 个 DiT 模块,而 ControlNet 包含 N/6 个模块,其参数初始化自 DiT 的前 N/6 个模块。在去噪过程中,ControlNet 的视觉标记通过 N 个提出的双分支连接器(Dual-branch Connectors)被融合到 DiT 中。
训练数据收集
有效训练基于 DiT 的视频修复模型需要大量高质量的文本-视频配对数据,而现有的公开数据集 在规模和多样性方面均难以满足需求。为此,我们构建了一个大规模视频库,包含 300 万个视频,这些视频的分辨率高于 1024 × 1024,帧率高于 24 fps,时长超过 2 秒。视频内容涵盖广泛场景,包括人物肖像、自然风光、动植物、城市景观等。为确保视频质量,我们进一步采用无参考视频质量评估指标 [36, 46] 对这些视频进行筛选,剔除低质量样本。对于剩余的高质量视频,我们使用 CogVLM2-Video [40] 生成对应的文本描述,以与 CogVideoX1.5-5B 的训练配置保持一致。最终构建的多模态训练数据集包含 50 万对高质量、高多样性的文本-视频配对数据。
概念蒸馏
由于视觉语言模型(VLM)描述生成器的局限性,所构建的文本-视频配对数据并非完美对齐(见图3 顶部行)。这可能导致微调过程中的分布漂移,从而降低生成视频的纹理质量和时序一致性。虽然开发更精确的 VLM 描述器可以解决此问题,但成本高昂。我们的目标是保持 T2V 基础模型的生成分布,这可以通过在 T2V 模型的潜在空间中实现视频与文本的对齐来达成。为此,我们利用 T2V 模型本身(即 CogVideoX1.5-5B)执行视频到视频的转换,该过程由文本描述进行引导。具体而言,给定一个文本-视频对,我们向源视频添加噪声,其标准差对应于 T/2 个时间步。然后,我们使用 CogVideoX1.5-5B 在文本描述的条件下对视频进行 T/2 步的去噪,生成一个融合了文本概念的合成视频。如图 3(第二行)所示,生成的视频在很大程度上保留了源视频的内容,但部分概念已调整,以更好地与文本描述中的语义对齐。我们从构建的多模态训练数据集中随机抽取文本-视频对,并通过上述过程生成 10 万个样本对。这些生成的样本随后与原始训练数据集混合,用于微调我们基于 DiT 的视频修复模型中的控制模块。
训练细节
整体训练数据集包含 50 万段真实视频和 10 万段生成视频,以及它们对应的文本描述。在训练过程中,我们将视频的短边调整为 1024 像素,然后进行中心裁剪,得到分辨率为 1024 × 1024 的视频帧。训练时的视频帧数在 17 到 37 帧之间随机选择。我们使用 AdamW 优化器 ,学习率为 0.0001,并采用余弦退火学习率调度策略。Vivid-VR 的训练在 32 块 NVIDIA H20-96G GPU 上进行,每块 GPU 的批量大小(batch size)为 1。总训练迭代次数为 30K,整个训练过程耗时约 6000 GPU 小时。
在推理阶段,我们设置去噪步数为 50,并使用 DPM 求解器。为与训练设置保持一致,推理时视频的分辨率固定为 1024 × 1024。对于更高分辨率的输入,我们采用聚合采样(aggregation sampling),并使用直接块拼接(direct block concatenation)而非高斯加权平均,以避免重叠区域产生伪影。
双分支Controlnet消融实验
对于 ControlNet 连接器,我们提出了一种双分支架构,结合了用于特征映射的 MLP 和用于动态特征检索的交叉注意力机制。人们可能会质疑这一设计是否真正有助于视频修复。为了回答这一问题,我们进行了三项消融研究:1)禁用交叉注意力分支,仅保留 MLP,这是一种简单的连接器设计;2)禁用 MLP 分支;3)采用 ZeroSFT 连接器 [42]。表 2 和图 6 展示了消融实验的对比结果。当禁用交叉注意力分支时,仅使用 MLP 的连接器表现不佳,生成的结果缺乏细节(见表 2(c) 和图 6(e))。当禁用 MLP 分支时,由于模型仅从控制输入中选择类似 DiT 的特征,视频修复模型无法收敛。结果,ControlNet 无法实现有效控制,输出结果与输入内容不符(见图 6(f))。这些实验验证了我们在 ControlNet 连接器中采用双分支设计的必要性。