rag-anything —— 一站式 RAG 系统
rag-anything —— 一站式 RAG 系统
rag-anything 简介
RAG-Anything 是基于轻量化的 LightRAG ,面向多模态文档(PDF、图片、表格、公式等)处理的RAG系统。该系统能够无缝处理和查询包含文本、图像、表格、公式等多模态内容的复杂文档,提供完整的RAG解决方案。
使用场景
对于以下任意场景,RAG-Anything 会是一个非常好的选择。
- 文档为带图表和公式的科研论文、报告、PPT等,需要多模态支持
- 需要端到端方案(端到端即用户只需输入原始文档,系统自动完成文档解析->查询响应全部流程,无需人工干预各个中间步骤。)
- 文档数量多,需要并行处理
RAG-Anything 亮点
1.多模态支持:能够处理包含 文本、图像、表格、公式 等 多模态 内容的复杂文档(详见系统架构-多模态分析引擎)。
2.端到端多模态流水线:提供从文档解析到多模态查询响应的完整处理链路,确保系统的 一体化运行 。
3.VLM增强查询:当文档包含图片时,能把图像与文本上下文一起送入 VLM 做更深入的联合分析。
系统架构
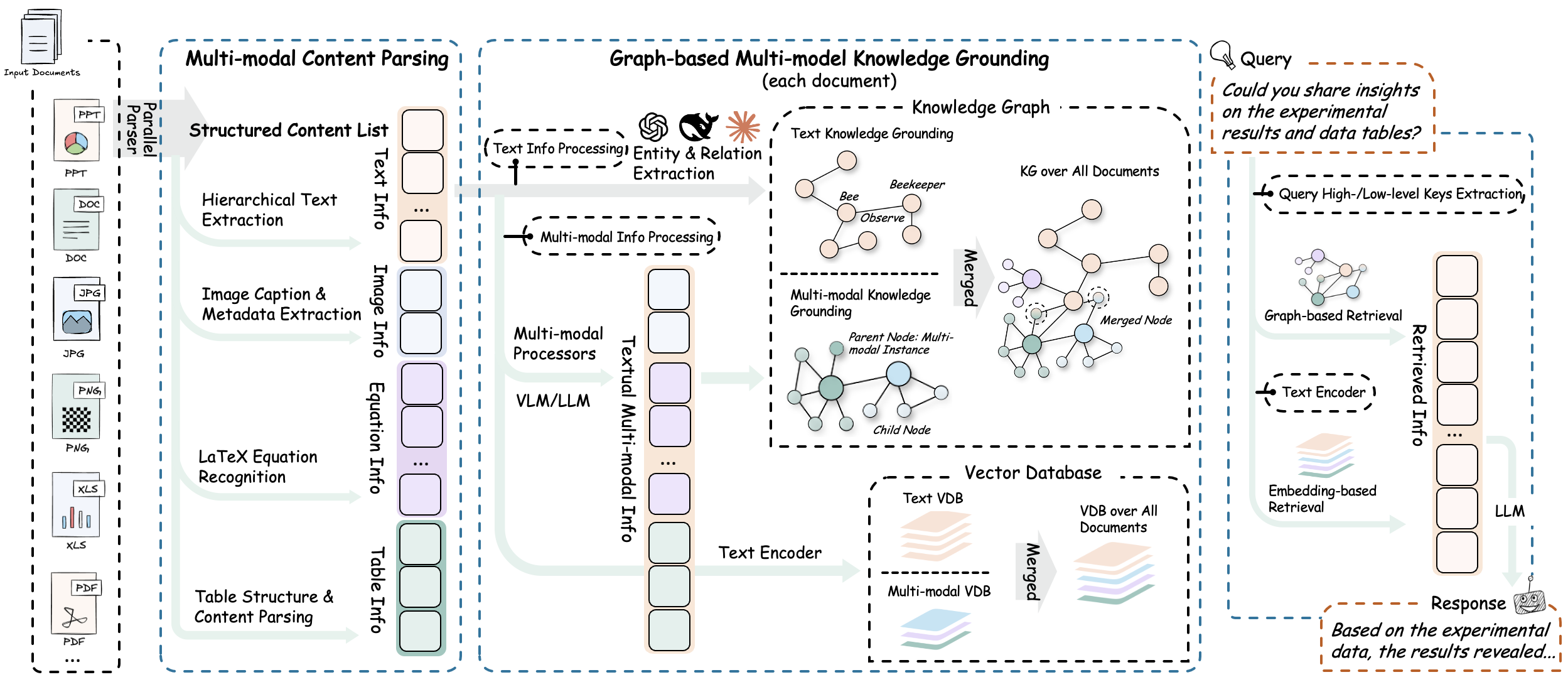
RAG-Anything 的系统架构分为以下几个阶段与功能:
- 📄文档解析阶段
通过高精度解析平台,系统实现多模态元素的完整识别与提取,核心功能包括:
1.1. 结构化提取引擎:集成MinerU和Docling,实现文档结构识别与多模态内容提取。
1.2. 自适应内容分解:智能分离文本、图像、表格和公式,保持语义关联。
1.3. 多格式兼容处理:支持 PDF、Office文档、图像等主流格式的统一解析输出。
- 🧠多模态内容理解与处理
通过自主分类路由机制和并发多流水线架构,实现内容的高效并行处理,核心功能包括:
2.1. 内容分类与路由:将不同内容类型发送至优化处理通道。
2.2. 并发多流水线:文本与多模态数据并行处理,保证效率与完整性。
2.3. 文档层次结构保持:在转换过程中保留原始文档层次和元素关联关系。
- 🧠多模态分析引擎
系统针对异构数据类型设计了模态感知处理单元,核心功能包括:
3.1. 视觉内容分析器:图像识别、语义标题生成、空间关系解析。
3.2. 结构化数据解释器:表格分析、趋势识别、多表语义依赖提取。
3.3. 数学表达式解析器:高精度公式解析,支持 LaTeX 集成。
3.4. 可扩展模态处理器:插件式架构支持新模态类型的动态集成。
- 🔍多模态知识图谱索引
将文档内容转化为结构化语义表示,建立跨模态关系,核心功能包括:
4.1. 多模态实体提取:将重要元素转为知识图谱节点。
4.2. 跨模态关系映射:文本与多模态组件建立语义连接。
4.3. 层次结构保持:维护原始文档组织结构。
4.4. 加权关系评分:通过语义和上下文权重优化检索。
- 🎯模态感知检索
通过向量搜索与图遍历算法实现内容检索与排序,核心功能包括:
5.1. 向量-图谱融合:结合语义嵌入与结构关系进行全面检索。
5.2. 模态感知排序:基于查询类型动态调整结果优先级。
5.3. 关系一致性维护:保证检索结果在语义和结构上的一致性。
更多技术讲解及项目实战:https://brmes.xet.tech/s/272wjp
rag-anything 安装和使用
安装 rag-anything及其扩展
# 从GitHub克隆项目
git clone https://github.com/HKUDS/RAG-Anything.git
# 进入项目目录
cd RAG-Anything
# 创建虚拟环境
python -m venv venv
# 激活虚拟环境
.\venv\Scripts\Activate.ps1
# 安装项目所需基础依赖
pip install -e .
# 安装项目所需扩展依赖
pip install -e '.[all]'
验证MinerU安装(安装rag-anything时会自动安装MinerU)
mineru --version #查看MinerU版本python -c "from raganything import RAGAnything; rag = RAGAnything(); print('✅ MinerU安装正常' if rag.check_parser_installation() else '❌ MinerU安装有问题')" #输出✅ MinerU安装正常代表安装成功
如需处理Office文档 (.doc, .docx, .ppt, .pptx, .xls, .xlsx) ,需要安装 LibreOffice
请从LibreOffice官网下载安装
rag-anything官方示例运行
下述api-key需要使用OpenAI的,可到openai官网获取apikey或参考使用教程-api及RAGAnything配置自行配置api及模型
# 端到端处理
python examples/raganything_example.py path/to/document.pdf --api-key YOUR_API_KEY --parser mineru# 直接模态处理
python examples/modalprocessors_example.py --api-key YOUR_API_KEY# Office文档解析测试(仅MinerU功能)
python examples/office_document_test.py --file path/to/document.docx# 图像格式解析测试(仅MinerU功能)
python examples/image_format_test.py --file path/to/image.bmp# 文本格式解析测试(仅MinerU功能)
python examples/text_format_test.py --file path/to/document.md# 检查LibreOffice安装
python examples/office_document_test.py --check-libreoffice --file dummy# 检查PIL/Pillow安装
python examples/image_format_test.py --check-pillow --file dummy# 检查ReportLab安装
python examples/text_format_test.py --check-reportlab --file dummy
更多技术讲解及项目实战:https://brmes.xet.tech/s/272wjp
使用教程(以硅基流动平台为例)
引入依赖
import asyncio
from raganything import RAGAnything, RAGAnythingConfig
from raganything.modalprocessors import ImageModalProcessor, TableModalProcessor,GenericModalProcessor
from lightrag import LightRAG
from lightrag.llm.openai import openai_complete_if_cache, openai_embed
from lightrag.utils import EmbeddingFunc
import os
api及RAGAnything配置
到硅基流动官网注册账号并获取api-key
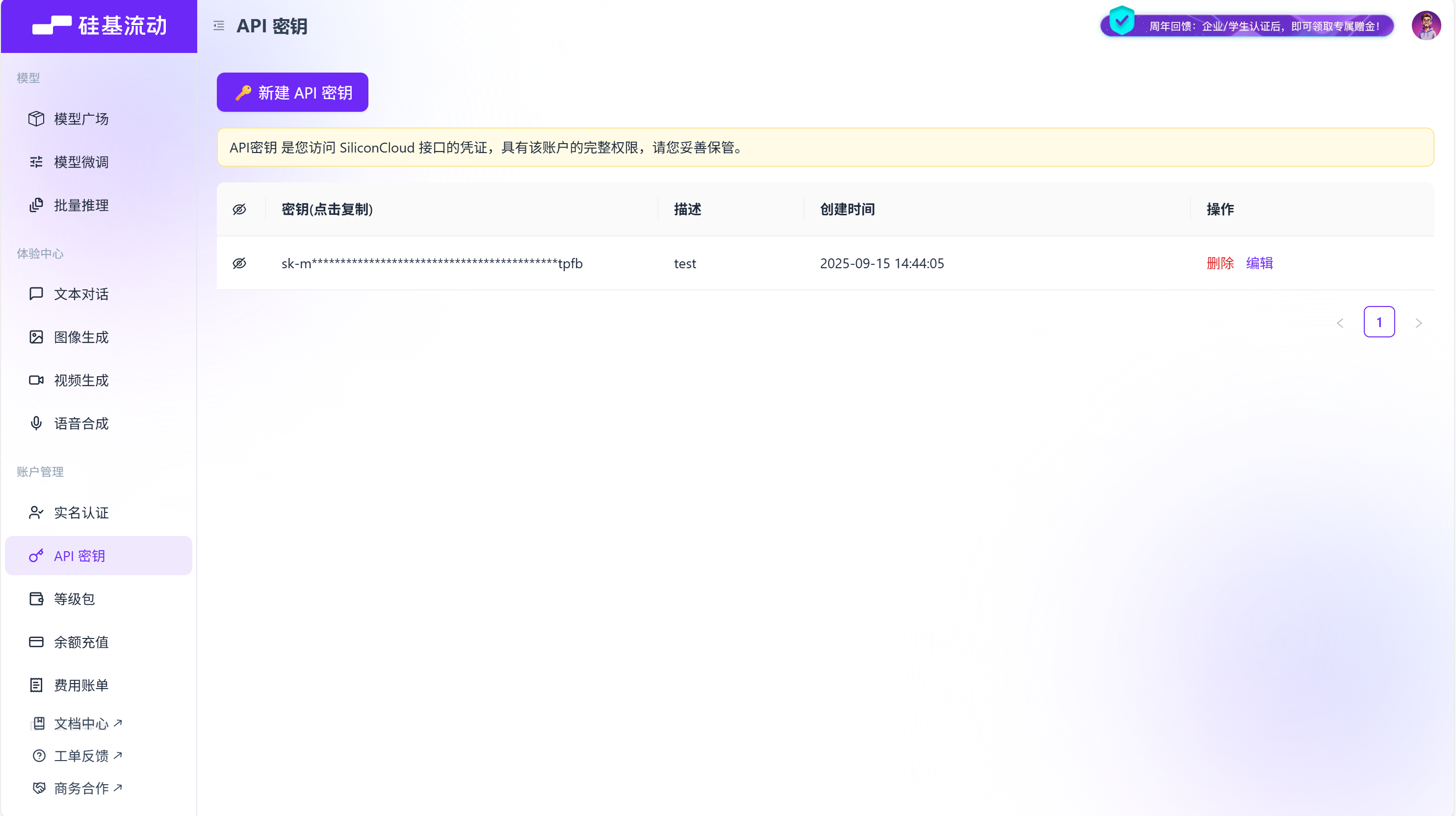
硅基流动的base-url是固定的 https://api.siliconflow.cn/v1
async def main():# 设置 API 配置api_key = "your api key" # 填写api key base_url = "https://api.siliconflow.cn/v1" #填写base url# 创建 RAGAnything 配置config = RAGAnythingConfig(working_dir="./rag_storage",parser="mineru", # 选择解析器:mineru 或 doclingparse_method="auto", # 解析方法:auto, ocr 或 txtenable_image_processing=True,enable_table_processing=True,enable_equation_processing=True,)
定义LLM模型函数
选择你想要的模型名称
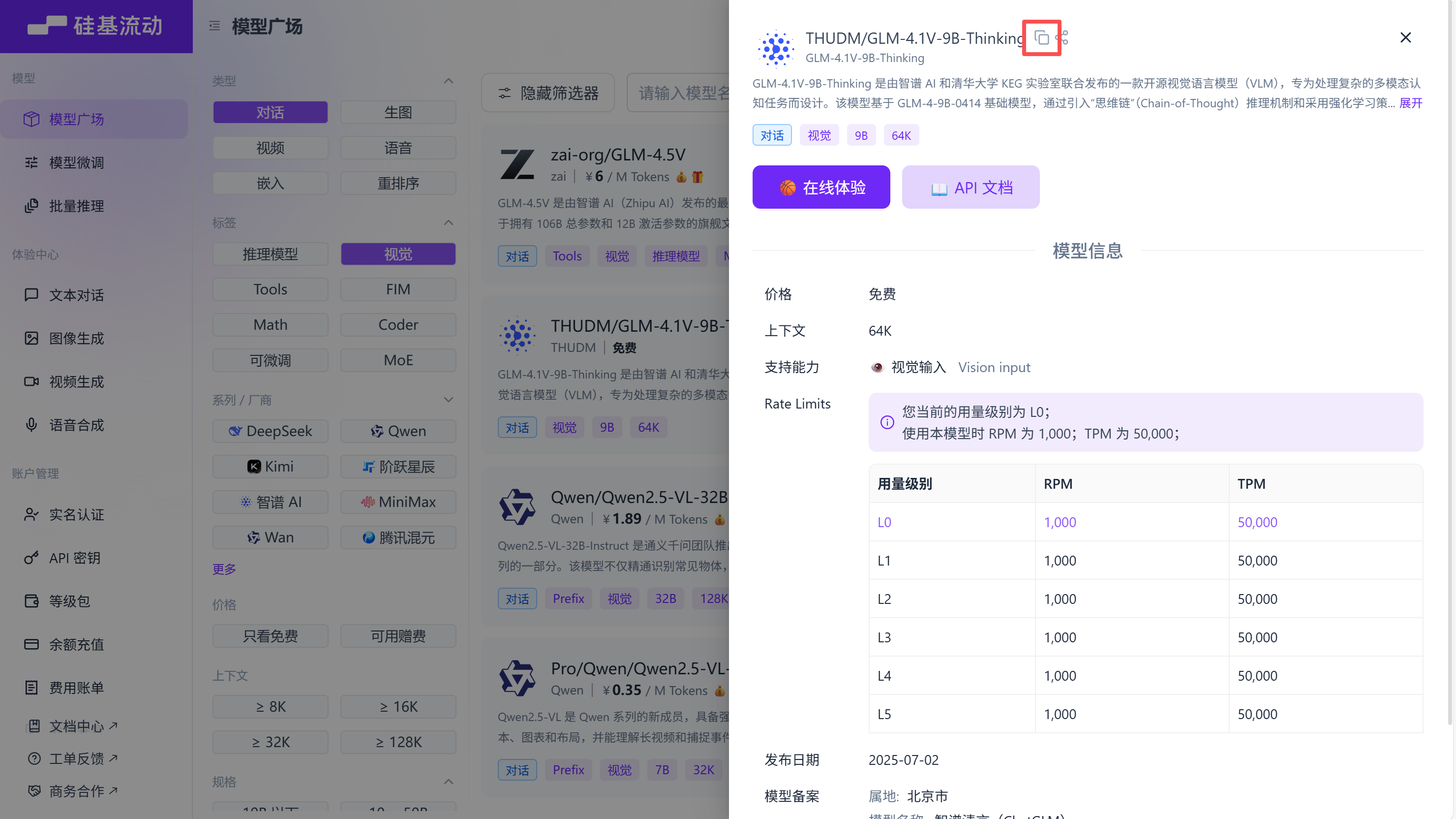
# 定义 LLM 模型函数def llm_model_func(prompt, system_prompt=None, history_messages=[], **kwargs):return openai_complete_if_cache("THUDM/GLM-4.1V-9B-Thinking", # 填写模型名称prompt,system_prompt=system_prompt,history_messages=history_messages,api_key=api_key,base_url=base_url,**kwargs,)
定义视觉模型函数
按照类型:对话, 标签:视觉筛选,选择你想要的视觉模型
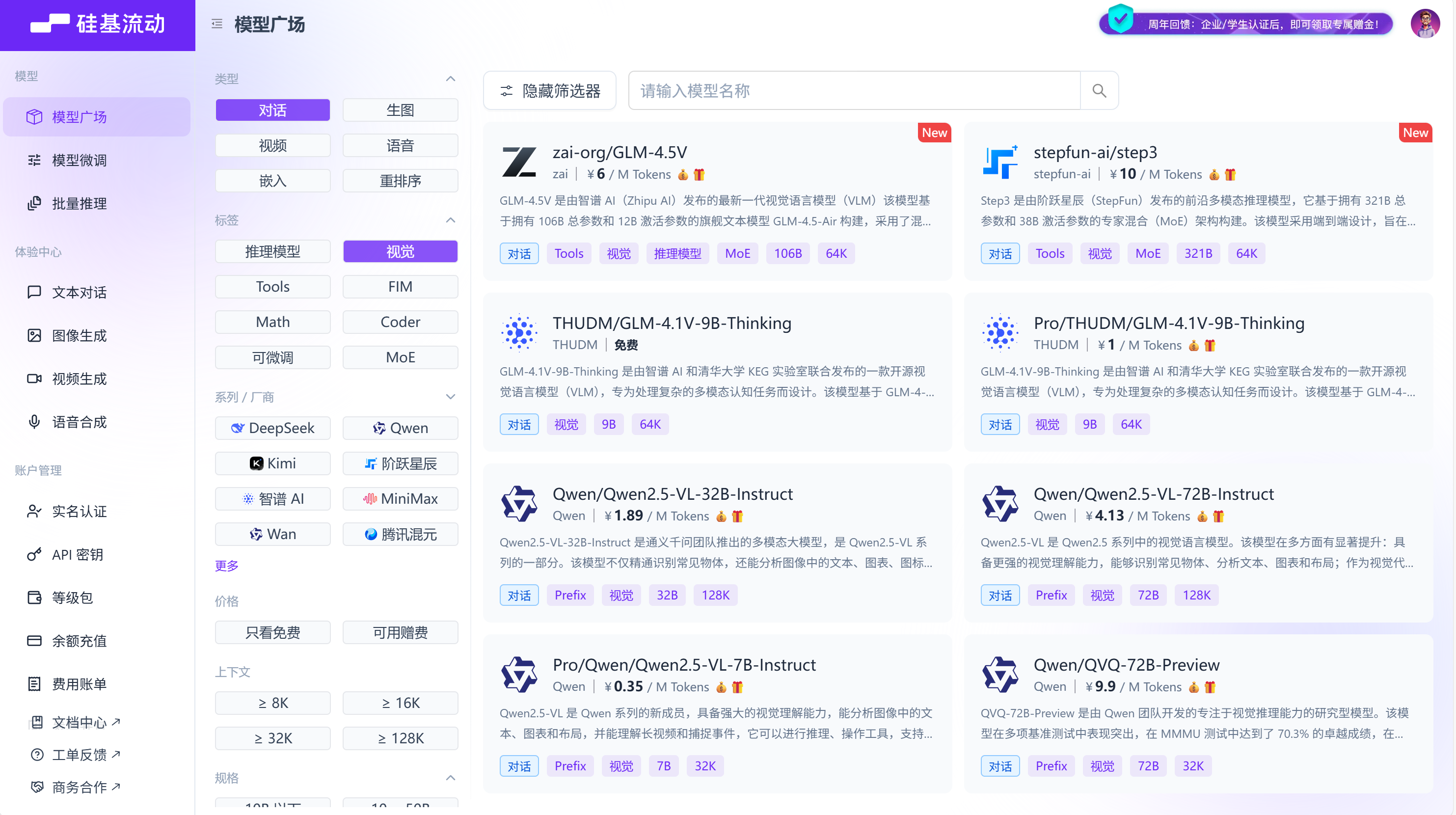
# 定义视觉模型函数用于图像处理def vision_model_func(prompt, system_prompt=None, history_messages=[], image_data=None, messages=None, **kwargs):# 如果提供了messages格式(用于多模态VLM增强查询),直接使用if messages:return openai_complete_if_cache("THUDM/GLM-4.1V-9B-Thinking", # 填写模型名称"",system_prompt=None,history_messages=[],messages=messages,api_key=api_key,base_url=base_url,**kwargs,)# 传统单图片格式elif image_data:return openai_complete_if_cache("THUDM/GLM-4.1V-9B-Thinking", # 填写模型名称"",system_prompt=None,history_messages=[],messages=[{"role": "system", "content": system_prompt}if system_promptelse None,{"role": "user","content": [{"type": "text", "text": prompt},{"type": "image_url","image_url": {"url": f"data:image/jpeg;base64,{image_data}"},},],}if image_dataelse {"role": "user", "content": prompt},],api_key=api_key,base_url=base_url,**kwargs,)# 纯文本格式else:return llm_model_func(prompt, system_prompt, history_messages, **kwargs)
定义嵌入模型函数
按照类型:嵌入筛选,选择你想要的模型,填写模型维度
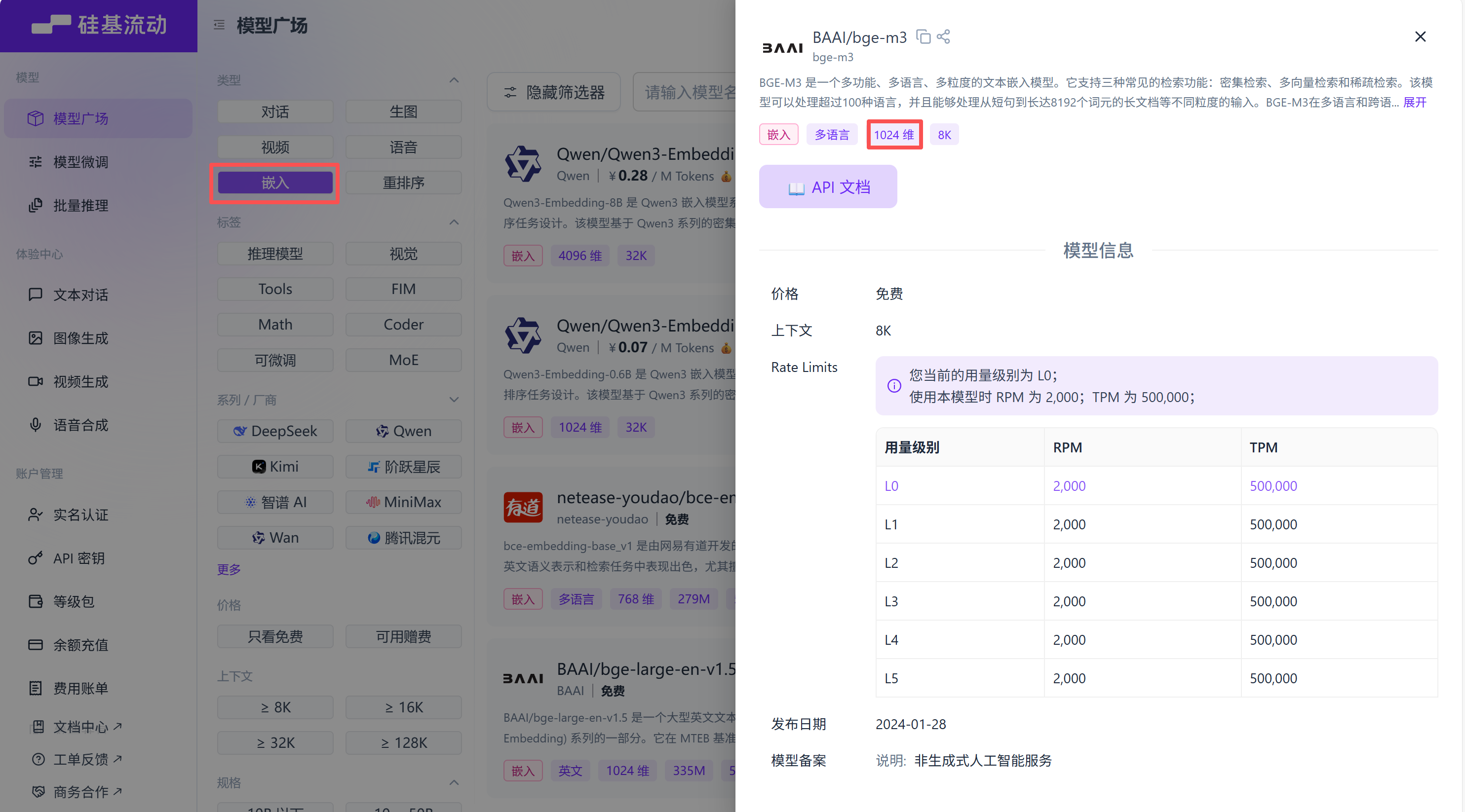
# 定义嵌入函数embedding_func = EmbeddingFunc(embedding_dim=1024, # 填写模型维度max_token_size=512, # 填写模型最大token长度func=lambda texts: openai_embed(texts,model="BAAI/bge-m3", # 填写embedding模型名称api_key=api_key,base_url=base_url,),)
初始化 RAGAnything
# 初始化 RAGAnythingrag = RAGAnything(config=config,llm_model_func=llm_model_func, # 上面定义的LLM模型函数vision_model_func=vision_model_func, # 上面定义的视觉模型函数embedding_func=embedding_func, # 上面定义的嵌入模型函数)
文档解析
处理文档
# 处理文档await rag.process_document_complete(file_path=r"path\to\your\file.pdf", # 填写要处理的文件路径output_dir="./output", # 输出目录parse_method="auto")
处理多个文档
# 处理多个文档
await rag.process_folder_complete(folder_path="./documents", # 在项目中创建documents文件夹,将要处理的文档放到下面output_dir="./output",file_extensions=[".pdf", ".docx", ".pptx"], # 填写要处理的文件类型recursive=True, # 是否递归处理子文件夹max_workers=4 # 要使用的线程数
)
从RAGAnything中查询
纯文本查询
# 1. 纯文本查询 - 基本知识库搜索text_result = await rag.aquery("文档的主要内容是什么?", # 填写查询内容mode="hybrid" # 选择你的查询模式 mode="hybrid" mode="local" mode="global" mode="naive")print("文本查询结果:", text_result)VLM增强查询
# 2. VLM增强查询(RAGAnything初始化时提供vision_model_func会自动启用)vlm_result = await rag.aquery("分析文档中的图表和数据", # 填写查询内容mode="hybrid"# vlm_enhanced=True # 也可强制手动选择是否启用)print("VLm查询结果:", vlm_result)
多模态查询
# 3. 多模态查询 - 包含具体多模态内容的查询# 3.1 包含表格数据的查询multimodal_result = await rag.aquery_with_multimodal("分析这个购物车挽回策略表格,并结合文档内容解释针对不同商品类型的挽回手段", # 查询内容multimodal_content=[{"type": "table", # 多模态内容类型"table_data": """商品类型,挽回手段,预期效果服装类,个性化推荐+限时折扣,提升转化率30%电子产品,价格对比+延保服务家居用品,搭配推荐+免费配送美妆护肤,试用装赠送+会员积分""", # 表格内容"table_caption": "购物车挽回策略对比表" # 表格标题}],mode="hybrid")print("多模态表格查询结果:", multimodal_result)# 3.2 包含公式内容的查询equation_result = await rag.aquery_with_multimodal("解释这个公式及其与文档内容的相关性",multimodal_content=[{"type": "equation", # 多模态内容类型"latex": "P(d|q) = \\frac{P(q|d) \\cdot P(d)}{P(q)}", # 公式内容"equation_content": "文档相关性概率" # 公式解释}],mode="hybrid")print("多模态公式查询结果:", equation_result)
更多技术讲解及项目实战:https://brmes.xet.tech/s/272wjp
加载已存在的LightRAG实例(如有,可选)
检查是否已有存储目录
# 定义 LightRAG 实例目录lightrag_working_dir = "./existing_lightrag_storage" # 检查是否存在之前的 LightRAG 实例,若存在则加载,否则创建新实例if os.path.exists(lightrag_working_dir) and os.listdir(lightrag_working_dir):print("✅ 发现已存在的 LightRAG 实例,正在加载...")else:print("❌ 未找到已存在的 LightRAG 实例,将创建新实例")
创建或加载 LightRAG 实例
# 使用您的配置创建/加载 LightRAG 实例lightrag_instance = LightRAG(working_dir=lightrag_working_dir,llm_model_func=lambda prompt, system_prompt=None, history_messages=[], **kwargs: openai_complete_if_cache("THUDM/GLM-4.1V-9B-Thinking",prompt,system_prompt=system_prompt,history_messages=history_messages,api_key=api_key,base_url=base_url,**kwargs,),embedding_func=EmbeddingFunc(embedding_dim=1024,max_token_size=512,func=lambda texts: openai_embed(texts,model="BAAI/bge-m3",api_key=api_key,base_url=base_url,),))
初始化存储
# 初始化存储(如果有现有数据,这将加载它们)await lightrag_instance.initialize_storages()await initialize_pipeline_status()
定义视觉模型函数
# 定义视觉模型函数用于图像处理def vision_model_func(prompt, system_prompt=None, history_messages=[], image_data=None, messages=None, **kwargs):# 如果提供了messages格式(用于多模态VLM增强查询),直接使用if messages:return openai_complete_if_cache("THUDM/GLM-4.1V-9B-Thinking","",system_prompt=None,history_messages=[],messages=messages,api_key=api_key,base_url=base_url,**kwargs,)# 传统单图片格式elif image_data:return openai_complete_if_cache("THUDM/GLM-4.1V-9B-Thinking","",system_prompt=None,history_messages=[],messages=[{"role": "system", "content": system_prompt}if system_promptelse None,{"role": "user","content": [{"type": "text", "text": prompt},{"type": "image_url","image_url": {"url": f"data:image/jpeg;base64,{image_data}"},},],}if image_dataelse {"role": "user", "content": prompt},],api_key=api_key,base_url=base_url,**kwargs,)# 纯文本格式else:return lightrag_instance.llm_model_func(prompt, system_prompt, history_messages, **kwargs)
用已有 LightRAG 实例初始化 RAGAnything
# 现在使用已存在的 LightRAG 实例初始化 RAGAnythingrag = RAGAnything(lightrag=lightrag_instance, # 传入已存在的 LightRAG 实例vision_model_func=vision_model_func,# 注意:working_dir、llm_model_func、embedding_func 等都从 lightrag_instance 继承)
查询同从RAGAnything中查询
添加新文档
# 向已存在的 LightRAG 实例添加新的多模态文档await rag.process_document_complete(file_path="path/to/new/multimodal_document.pdf",output_dir="./output")
直接插入内容列表(如有预解析的内容列表时,可选)
已经有预解析的内容列表(例如,来自外部解析器或之前的处理结果)时,可以直接插入到 RAGAnything 中而无需文档解析
准备内容列表
# 示例:来自外部源的预解析内容列表content_list = [{"type": "text", # 文本类型"text": "这是我们研究论文的引言部分。","page_idx": 0 # 内容在原始文档中出现的页码(从0开始的索引)},{"type": "image", # 图像类型"img_path": r"C:\absolute\path\to\figure1.jpg", # 重要:使用绝对路径"img_caption": ["图1:系统架构"], "img_footnote": ["来源:作者原创设计"],"page_idx": 1},{"type": "table", # 表格类型"table_body": "| 方法 | 准确率 | F1分数 |\n|------|--------|--------|\n| 我们的方法 | 95.2% | 0.94 |\n| 基准方法 | 87.3% | 0.85 |","table_caption": ["表1:性能对比"],"table_footnote": ["测试数据集结果"],"page_idx": 2},{"type": "equation", # 公式类型"latex": "P(d|q) = \\frac{P(q|d) \\cdot P(d)}{P(q)}", # 公式的LaTeX表示"text": "文档相关性概率公式","page_idx": 3}]
插入内容列表
# 插入内容列表await rag.insert_content_list(content_list=content_list, # 上面的内容列表file_path="research_paper.pdf", # 用于引用的参考文件名#split_by_character="\n\n", # 可选的文本分割#split_by_character_only=False, # 可选的文本分割模式doc_id=None, # 可选的自定义文档ID(如果未提供将自动生成)#display_stats=True # 显示内容统计信息)
ext": “文档相关性概率公式”,
“page_idx”: 3
}
]
#### 插入内容列表
```python# 插入内容列表await rag.insert_content_list(content_list=content_list, # 上面的内容列表file_path="research_paper.pdf", # 用于引用的参考文件名#split_by_character="\n\n", # 可选的文本分割#split_by_character_only=False, # 可选的文本分割模式doc_id=None, # 可选的自定义文档ID(如果未提供将自动生成)#display_stats=True # 显示内容统计信息)
更多技术讲解及项目实战:https://brmes.xet.tech/s/272wjp