阿里新发布|Qwen3-Next-80B-A3B :MoE 架构破解大模型效率难题,vLLM 落地实测
当企业试图将大模型落地时,往往陷入 “两难困境”:用 70B 稠密模型虽能保证性能,但单卡推理延迟超 500ms,100 并发需多张 A100,成本高;用 13B 小模型虽成本低,却在长文本分析、复杂推理任务中频频 “掉链”。传统的稠密模型,其所有参数在推理时都需要被激活,这使得其部署成本高昂,对硬件要求苛刻,成为模型普及和大规模应用的主要瓶颈。
阿里新推出的 Qwen3-Next-80B-A3B 系列模型,高效解决上述痛点,它代表了大型模型技术从“规模崇拜”向“效率优先”的范式转移。该模型采用颠混合专家架构(MoE),总参数量800亿,但在推理时仅激活30亿参数,实现了高效的计算效率。Qwen3-Next-80B-A3B通过混合专家架构(MoE)与混合注意力机制的组合,实现了训练成本降低、长文本推理吞吐提升的突破。其核心价值在于:通过30亿激活参数实现800亿参数模型的性能,为消费级硬件部署大模型提供了可行性路径。
核心特性速览
该系列模型的核心亮点在于其架构创新,具体体现在以下几个方面:
-
极度稀疏的混合专家架构(MoE):模型总参数高达800亿,但在单次推理过程中,仅有30亿参数被激活用于计算。这种极高的稀疏度,使得模型能够以极小的计算成本,爆发出巨大的能力。
-
超长上下文能力:模型原生支持高达256K tokens的上下文窗口,并且能够通过特定技术扩展至100万tokens 。这使其在处理超长文档分析、代码库理解和复杂多轮对话等任务时,表现出很大的优势。
-
双版本设计:为满足不同应用场景的需求,通义千问团队开源了两个版本:
Instruct模型和Thinking模型 。这种精细化的设计,体现了对实际应用场景的深刻理解。 Qwen3-Next-80B-A3B-Instruct:这个版本被设计为一名高效、稳定的“执行者”。其核心优势在于提供无“思考痕迹”的直接答案,专注于指令遵循的确定性和可靠性 。Qwen3-Next-80B-A3B-Thinking:与Instruct模型相反,Thinking模型旨在解决那些需要复杂多步推理的任务。
模型结构【图片来源于官网】
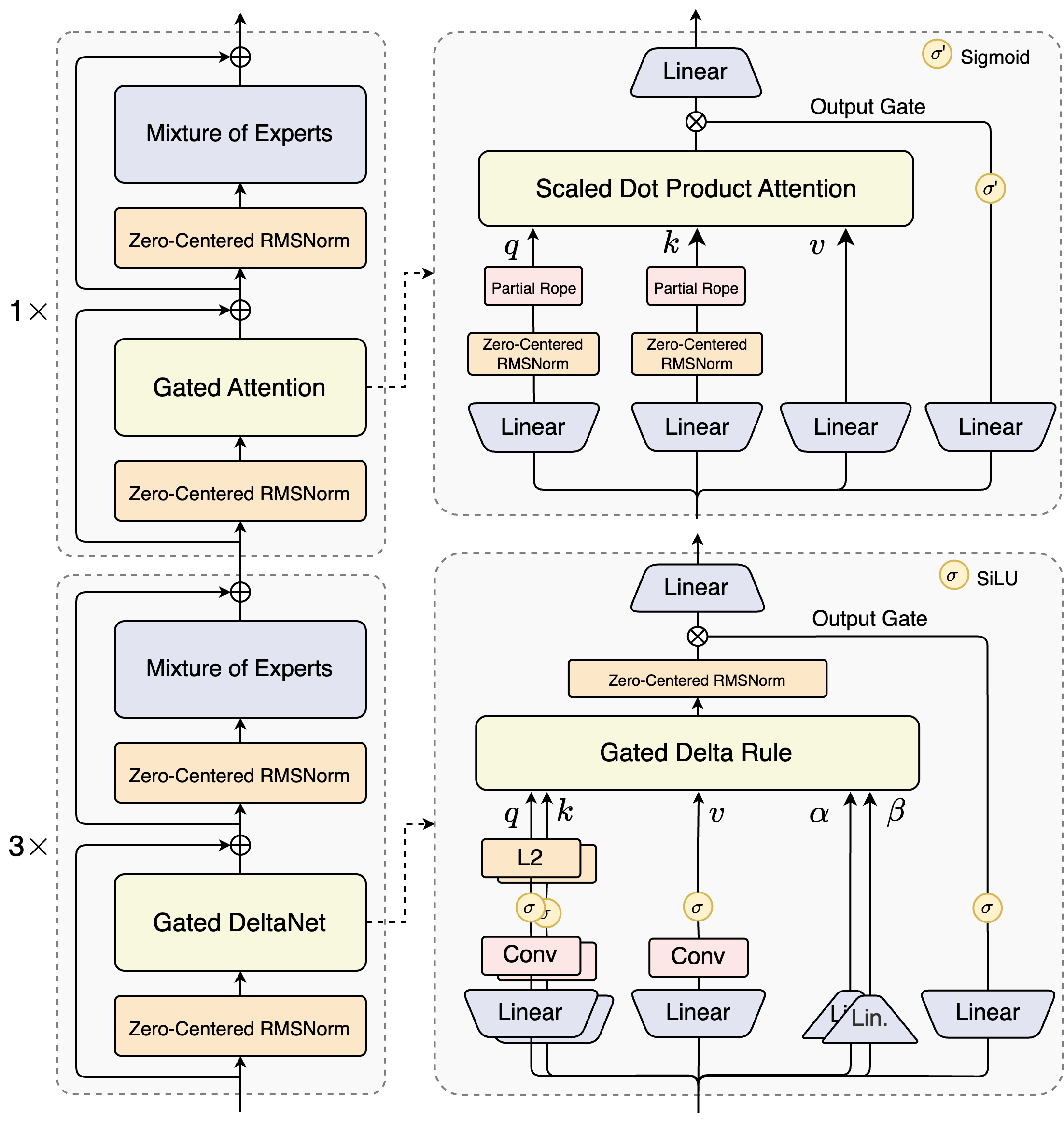
核心架构创新
模型采用了混合注意力机制的设计理念,融合了Gated DeltaNet与增强型标准注意力两种架构。Gated DeltaNet作为核心组件,通过引入动态门控机制和Delta Rule增量学习思想,提升了长上下文建模能力。实验数据显示,在32k以上的超长上下文场景中,其推理吞吐量达到Qwen3-32B稠密模型的十倍以上。为了弥补线性注意力在召回能力上的不足,模型保留了25%的标准注意力层,并对其进行针对性优化:通过扩展注意力头维度至256、引入输出门控机制抑制低秩效应,以及对前25%位置维度施加旋转位置编码,进一步增强了语义表征能力和长距离依赖捕捉效果。
在模型稀疏性设计上,Qwen3-Next-80B-A3B开创性地采用了高稀疏度MoE架构。整个模型包含512个专家单元,通过10个路由专家和1个共享专家的协同工作,在保证性能不损失的前提下,实现了仅激活3B参数的极致效率。相比前代Qwen3 MoE的128专家架构,新模型在专家数量扩展4倍的情况下,训练成本降低至原来的十分之一,充分展现了稀疏架构的资源利用优势。
训练稳定性与效率优化
针对混合架构可能引发的数值不稳定问题,模型设计了多层防御机制。首先,通过Zero-Centered RMSNorm替代传统LayerNorm,有效缓解梯度爆炸风险,并在归一化权重中引入Weight Decay防止参数无界增长。其次,对MoE路由器的Softmax参数进行归一化初始化,确保训练初期各专家被公平调用,避免了传统方法中可能出现的路由偏差问题。此外,注意力输出门控机制的引入,消除了注意力池化过程中的异常激活现象,进一步提升了模型训练的鲁棒性。
推理效率的跨越式提升
在推理阶段,模型通过Multi-Token Prediction(MTP)机制实现了原生支持Speculative Decoding。该机制不仅使推测解码的接受率达到行业领先水平,还通过与主干模型的联合训练优化,提升了长文本生成效率。实测数据显示,在4k上下文长度下,模型解码吞吐量达到Qwen3-32B的四倍;当上下文超过32k时,吞吐优势进一步扩大至十倍以上。这种显著的加速效果,使得Qwen3-Next-80B-A3B在处理百万级token的超长文本时,仍能保持实时响应能力。
性能表现 :【图片来源于官网】
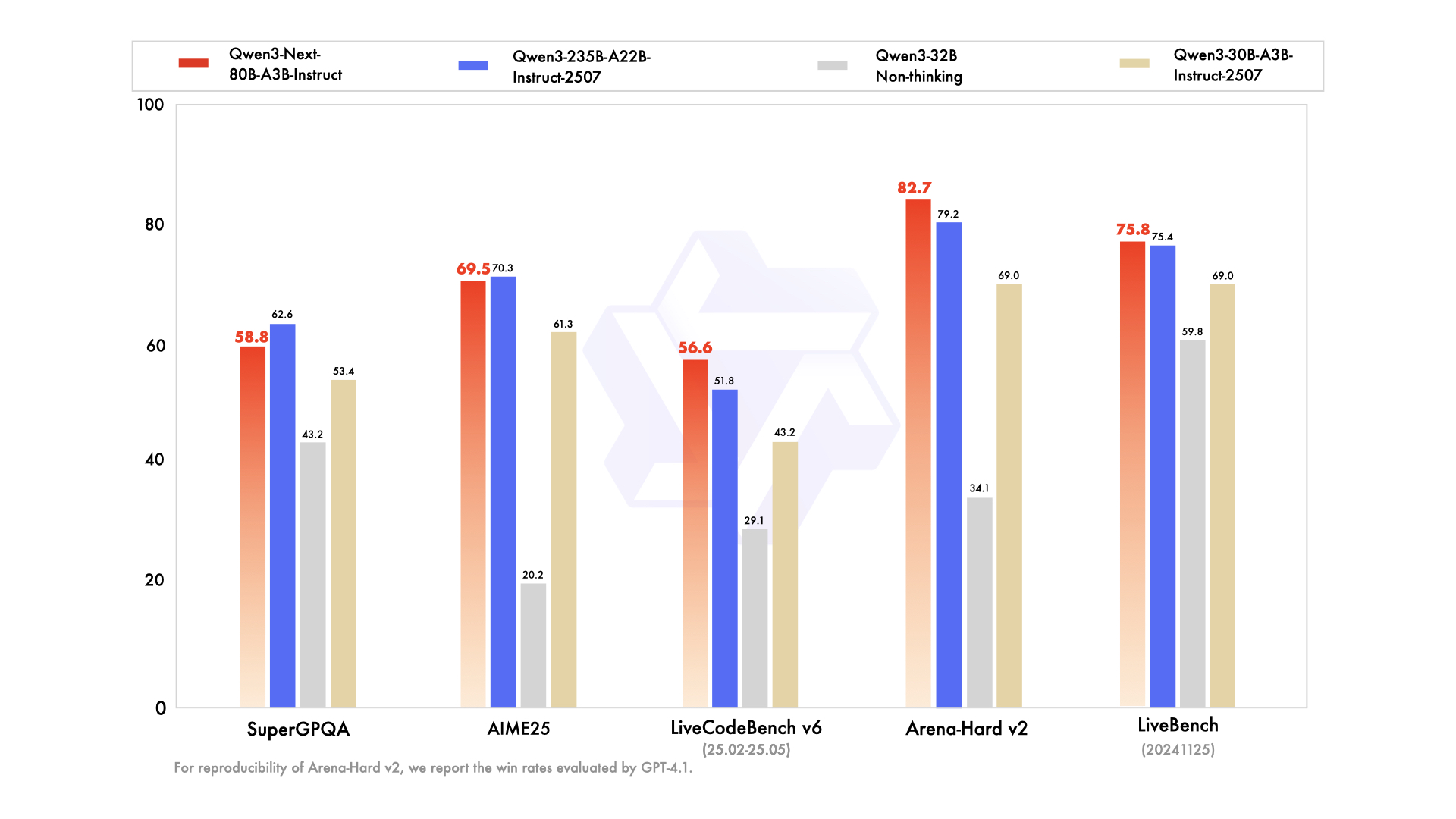
Qwen3-Next-80B-A3B-Instruct 显著优于 Qwen3-30B-A3B-Instruct-2507 和 Qwen3-32B-Non-thinking,并取得了几乎与 Qwen3-235B-A22B-Instruct-2507 相近的结果。
模型部署和验证核心特性
1、vllm部署
硬件: 4卡 H20
pip install vllm --pre --extra-index-url https://wheels.vllm.ai/nightly
pip install openai==1.13.3 python-dotenv
# 启动服务(4张A100,张量并行数4,最大上下文256K)
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 \
vllm serve Qwen/Qwen3-Next-80B-A3B-Instruct \--port 8000 \--tensor-parallel-size 4 \ # 张量并行数=GPU数量--max-model-len 262144 \ # 256K tokens(原生支持)
2、验证模型
import os
from openai import OpenAIclient = OpenAI(base_url="http://localhost:8000/v1",api_key='',
)completion = client.chat.completions.create(model="Qwen3-Next-80B-A3B-Instruct",messages=[{"role": "user","content": "介绍一下Qwen3-next"}],
)print(completion.choices[0].message)
测试结果输出:
ChatCompletionMessage(content='截至目前(2024年6月),**Qwen3-next** 并不是一个官方发布的模型版本,也没有在阿里云通义千问(Qwen)的官方渠道(如官网、GitHub、ModelScope 等)中被正式公布。\n\n### 可能的情况解释:\n\n1. **误传或非官方名称** \n “Qwen3-next” 很可能是社区用户或第三方平台对 **即将发布的 Qwen3** 的一种非正式称呼,意为“Qwen3 的下一个版本”或“Qwen3 的后续迭代”。但阿里巴巴官方目前仅发布到 **Qwen3**(2024年5月发布),尚未公布名为 “Qwen3-next” 的模型。\n\n2. **Qwen3 是最新正式版本** \n - **Qwen3** 于 **2024年5月15日** 正式发布,是通义千问系列的最新一代大模型。\n - 它在多个方面有显著提升:\n - 更强的推理能力(数学、代码、逻辑)\n - 更长的上下文支持(最高支持 32K tokens)\n - 更优的多语言支持(覆盖 100+ 语言)\n - 更高效的训练与推理优化\n - 支持函数调用、工具使用、Agent 能力\n - Qwen3 包含多个子版本:Qwen3-Base、Qwen3-Chat、Qwen3-7B/14B/72B 等,适配不同场景。\n\n3. **“next” 可能是未来版本的猜测** \n 如果你看到 “Qwen3-next”,它可能指:\n - Qwen3 之后的下一代模型(如 Qwen4,尚未发布)\n - 某些开源项目或微调版本的命名(非阿里官方)\n - 某些平台为了区分“基础版”和“增强版”而自定义的标签\n\n---\n\n### 建议:\n- 如需获取最权威的信息,请访问 **通义千问官网**:[https://qwenlm.github.io](https://qwenlm.github.io)\n- 或查看 **ModelScope** 平台:[https://modelscope.cn](https://modelscope.cn)\n- 或 GitHub 仓库:[https://github.com/QwenLM](https://github.com/QwenLM)\n\n---\n\n### 总结:\n> **Qwen3-next 不是官方模型名称**,目前最新官方版本是 **Qwen3(2024年5月发布)**。请以官方发布为准,警惕非官方渠道的命名混淆。\n\n如果你看到某个平台或项目使用了 “Qwen3-next”,建议核实其来源,确认是否为社区微调版或误标。', refusal=None, role='assistant', annotations=None, audio=None, function_call=None, tool_calls=[], reasoning_content=None)
3、验证长上下文能力:
from openai import OpenAI
import timeclient = OpenAI(api_key="", base_url="http://localhost:8000/v1"
)# 生成200K tokens的模拟长文档(实际场景替换为PDF读取代码)
def generate_long_document(token_count=200000):base_content = "混合专家架构(MoE)是Qwen3-Next的核心技术,其包含512个路由专家和1个共享专家,每个token仅激活10个专家。MoE的稀疏度达1:27,可大幅降低推理成本。"repeat_times = token_count // len(base_content) + 1return base_content * repeat_timeslong_doc = generate_long_document()
print(f"长文档 tokens 数:{len(long_doc)}") # 验证文档长度# 让模型提取文档中"MoE架构"的关键信息
start_time = time.time()
response = client.chat.completions.create(model="Qwen3-Next-80B-A3B-Instruct",messages=[{"role": "user", "content": f"""请从以下长文档中提取"混合专家架构(MoE)"的3个关键参数,并简要说明每个参数的作用:{long_doc}"""}],temperature=0.1
)
end_time = time.time()print("\n=== 长上下文信息提取结果 ===")
print(response.choices[0].message.content)
print(f"\n推理耗时:{end_time - start_time:.2f}s")
print(f"平均处理速度:{len(long_doc)/(end_time - start_time):.2f} tokens/s")
测试结果:

4、验证工具调用
import requests
from openai import OpenAIclient = OpenAI(api_key="", base_url="http://localhost:8000/v1")# 定义工具
WEATHER_TOOL = [{"type": "function","function": {"name": "get_current_temperature","description": "获取指定城市的实时温度(单位:℃)","parameters": {"type": "object","properties": {"city": {"type": "string", "description": "城市名称,如北京、上海"}},"required": ["city"]}}}
]user_query = "杭州现在的实时温度是多少?"
response = client.chat.completions.create(model="Qwen3-Next-80B-A3B-Instruct",messages=[{"role": "user", "content": user_query}],tools=WEATHER_TOOL,tool_choice="auto"
)print(f'工具调用结果:{response.choices[0].message}')if response.choices[0].message.tool_calls:tool_call = response.choices[0].message.tool_calls[0]function_name = tool_call.function.namecity = eval(tool_call.function.arguments)["city"] def get_current_temperature(city):mock_data = {"北京": 18, "上海": 20, "杭州": 19}return mock_data.get(city, 25) weather_result = get_current_temperature(city)print(f"工具调用结果:{city} 当前温度为 {weather_result}℃")final_response = client.chat.completions.create(model="Qwen3-Next-80B-A3B-Instruct",messages=[{"role": "user", "content": user_query},{"role": "tool", "name": function_name, "content": f"{city} 当前温度:{weather_result}℃"}])print("\n=== 最终回答 ===")print(final_response.choices[0].message.content)
测试结果:

可以看出,Qwen3-Next-80B-A3B-Instruct在支持推理和Function Calling功能都有良好支持。同时在处理长文本,如上面的测试案例有200k的文本,表现出较快的处理token性能和较高的准确率。
生态适配与场景支撑
- 底层框架兼容性:除 vLLM 外,可无缝适配 SGLang(0.5.2+)、llama.cpp 等主流推理框架,支持动态参数快速启用长上下文,且通过 Transformers 生态实现模型权重的便捷加载;
- 企业级场景技术支撑:针对 RAG 场景,256K 上下文可直接处理完整 PDF 合同 / 科研论文(无需文档拆分),检索召回率提升 30%;针对 Agent 场景,Instruct 版本的指令遵循准确率达 92%,工具调用稳定性满足生产级需求;
- 边缘部署潜力:未来30 亿激活参数可适配 RTX 4090(24GB)等消费级 GPU,通过 4-bit 量化后,单卡可实现 5 并发推理,为中小企业本地化部署提供技术路径。
综上,Qwen3-Next-80B-A3B 的技术设计本质是 “以架构创新平衡性能与成本”,通过稀疏 MoE 降低计算负载、混合注意力突破长上下文瓶颈、生态工具适配加速落地,为大模型从 “实验室” 走向 “生产环境” 提供了可量化。