知识蒸馏(KD)详解三:基于BERT的知识蒸馏代码实战
知识蒸馏(KD)详解三:基于BERT的知识蒸馏代码实战
前言
数据集:数据集我们使用huggingface中的"banking77"
任务:拿BERT构建和训练一个意图识别模型
关于BERT模型和知识蒸馏理论知识在前两节已经详细介绍了,可以自己去查看
1. 教师模型训练
1.1 训练
教师模型采用BERT骨干网络 + 自定义分类头来训练,完整代码如下:
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
import evaluate
from datasets import load_dataset, DatasetDict # huggingface
from transformers import AutoTokenizer, AutoModel, TrainingArguments, Trainer, set_seed, DataCollatorWithPadding, AutoConfig # huggingface
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchinfo import summary # ======================== 配置 ==================================
DATASET = "banking77" # 可选: "banking77" | "clinc150" | "massive_en" | "massive_zh"
BACKBONE = "bert-base-uncased"
MAX_LEN = 256
SEED = 42
LR = 2e-5
EPOCHS = 10
BSZ_TRAIN = 32
BSZ_EVAL = 32 OUT_DIR= f"runs/{DATASET}_teacher_custom"
set_seed(SEED) # 1 ==================== 数据集加载 ====================
def load_intent_dataset(dataset_name): if dataset_name == "banking77": ds = load_dataset("banking77") text_col, label_col = "text", "label" num_labels = len(ds["train"].unique(label_col)) else: raise ValueError("Unknown dataset") if "validation" not in ds: if "test" in ds: ds = DatasetDict({"train": ds["train"], "validation": ds["test"]}) else: split = ds.train_test_split(test_size=0.1, SEED=SEED) ds = DatasetDict({"train": split["train"], "validation": split["test"]}) return ds, text_col, label_col, num_labels # 2.======================= 数据预处理 ====================
def tok_fn(batch, tok, max_len, TEXT): return tok(batch[TEXT], truncation=True, max_length=max_len) # 4. ======================= 构建Teacher ====================
class MeanPooler(torch.nn.Module): """ hidden: 通常是 last_hidden_state,形状 [B, S, H](批大小/序列长/隐藏维) mask: 通常是 attention_mask,形状 [B, S],有效 token 为 1,padding 为 0。 """ def forward(self, hidden, mask): mask = mask.unsqueeze(-1) # [b,s,1] summded = (hidden * mask).sum(dim=1) denom = mask.sum(dim=1).clamp(min=1e-6) return summded / denom class TeacherBackboneHead(torch.nn.Module): def __init__(self, backbone_name, num_labels, config=None): super().__init__() self.backbone = AutoModel.from_pretrained(backbone_name) h = self.backbone.config.hidden_size self.pool = MeanPooler() self.head = nn.Sequential( nn.Dropout(0.2), nn.Linear(h, h), nn.GELU(), nn.Dropout(0.2), nn.Linear(h, num_labels) ) self.config = config def forward(self, input_ids=None, attention_mask=None, token_type_ids=None, labels=None): assert input_ids is not None and attention_mask is not None and token_type_ids is not None, "input_ids, attention_mask, token_ids must be not None" out = self.backbone(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids, return_dict=True) hidden = out.last_hidden_state sent = self.pool(hidden, attention_mask) # (B, H) logits = self.head(sent) #(B,C) loss = F.cross_entropy(logits, labels) if labels is not None else None return {"loss":loss, "logits": logits} if __name__ == "__main__": cfg = AutoConfig.from_pretrained(BACKBONE) ds, TEXT, LABEL, N_LABELS = load_intent_dataset(DATASET) tok = AutoTokenizer.from_pretrained(BACKBONE, use_fast=True) # # ds: {'train': ['text', 'label'], 'validation': ['text', 'label']} # ds_enc: {'train': ['label', 'input_ids', 'token_type_ids', 'attention_mask'], 'validation': ['label', 'input_ids', 'token_type_ids', 'attention_mask']} ds_enc = ds.map(tok_fn, batched=True, remove_columns=[TEXT], fn_kwargs={"tok": tok, "max_len": MAX_LEN, "TEXT": TEXT}) """ ds_enc["train"][0] => { "input_ids": [101, 2026, 3899, ... , 102], "attention_mask": [1, 1, 1, ..., 1], "token_type_ids": [0, 0, 0, ..., 0], "labels": 17 } """ labels = ds["train"].features["label"].names id2label = {i: name for i, name in enumerate(labels)} cfg.id2label = id2label # 每一个mini batch padding 不在tok_fn中做padding,因为Trainer会自动padding collator = DataCollatorWithPadding(tok) # 3. ======================= 定义指标 ==================== acc = evaluate.load("accuracy") # 预测正确的率 # 所有类别求宏平均F1,反应整体类别预测的准确性 f1 = evaluate.load("f1") # F1 = 2 * (precision * recall) / (precision + recall), precision=TP / (TP + FP), recall=TP / (TP + FN) def compute_metrics(eval_pred): logits, labels = eval_pred preds = logits.argmax(-1) acc_result = acc.compute(predictions=preds, references=labels) f1_result = f1.compute(predictions=preds, references=labels, average="macro") return {"accuracy": acc_result["accuracy"], "f1": f1_result["f1"]} # 5. ======================= 训练Teacher ==================== teacher = TeacherBackboneHead(BACKBONE, N_LABELS, config=cfg) # 输出模型结构 examples = [ds_enc["train"][i] for i in range(2)] batch_ex = collator(examples) inputs_ex = {key: batch_ex[key] for key in ["input_ids", "attention_mask", "token_type_ids"]} class Wrapper(nn.Module): def __init__(self, core): super().__init__() self.core = core def forward(self, input_ids, attention_mask=None, token_type_ids=None): out = self.core(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids) return out["logits"] # [B, num_labels] wrapped = Wrapper(teacher) summary( wrapped, input_data=inputs_ex, depth=3, col_names=("input_size","output_size","num_params","trainable"), verbose=2 ) # args args = TrainingArguments( output_dir=OUT_DIR, learning_rate=LR, per_device_train_batch_size=BSZ_TRAIN, per_device_eval_batch_size=BSZ_EVAL, num_train_epochs=EPOCHS, evaluation_strategy="epoch", save_strategy="epoch", logging_steps=50, load_best_model_at_end=True, metric_for_best_model="f1", greater_is_better=True, seed=SEED, fp16=torch.cuda.is_available(), report_to="none" ) trainer = Trainer( model=teacher, args=args, train_dataset=ds_enc["train"], eval_dataset=ds_enc["validation"], tokenizer=tok, data_collator=collator, # 动态padding compute_metrics=compute_metrics ) trainer.train() metrics = trainer.evaluate() print(f"Final metrics: {metrics}") # 保存(包含自定义头) os.makedirs(f"{OUT_DIR}/best", exist_ok=True) trainer.save_model(f"{OUT_DIR}/best") tok.save_pretrained(f"{OUT_DIR}/best") # trainer 中会自动保存tokenizer, 这一步可以不要 cfg =cfg.save_pretrained(f"{OUT_DIR}/best") print(f"Saved teacher to {OUT_DIR}/best")
运行之后,首先我们可以看到模型结构:以下部分截图
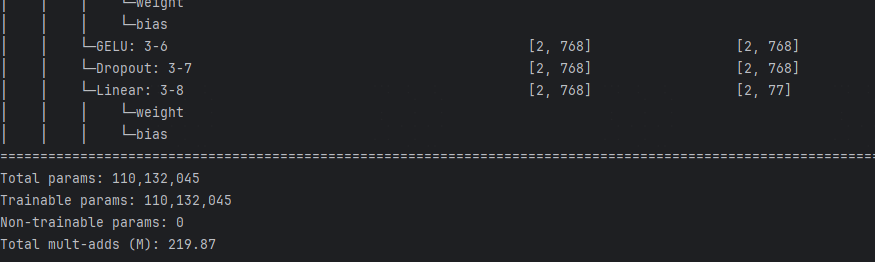
我们可以看到我们这个教师模型的参数大概1亿1千万
模型训练完成后,如下:

模型最后的精度在0.92,f1也在0.92
1.2 测试
我们找几条文本来测试一下效果:
测试代码:
from pyarrow.lib import Mapping
from transformers import AutoTokenizer, AutoConfig
import os, torch, numpy as np
from bert_kd import TeacherBackboneHead, MAX_LEN
from safetensors.torch import load_file @torch.no_grad()
def predict(texts, topk3, model, tok, cfg): batch = tok(texts, return_tensors="pt", padding=True, truncation=True, max_length=MAX_LEN) inputs = {k: v.to(device) for k, v in batch.items()} out = model(**inputs) probs = torch.softmax(out["logits"], dim=-1) topv,topi = torch.topk(probs, topk3, dim=-1) id2label = cfg.id2label for i, text in enumerate(texts): top_l = [id2label[id] for id in topi[i].tolist()] top_v = topv[i].tolist() print("\nText:", text) print("Top-3:", (top_l, top_v)) if __name__ == "__main__": TEACHER_DIR = r"runs/banking77_teacher_custom/best" cfg_t = AutoConfig.from_pretrained(TEACHER_DIR) tok_t = AutoTokenizer.from_pretrained(TEACHER_DIR) model_t = TeacherBackboneHead(TEACHER_DIR, num_labels=77, config=cfg_t) device = torch.device("cuda:0") state_dict_t = load_file(os.path.join(TEACHER_DIR, "model.safetensors")) model_t.load_state_dict(state_dict_t) model_t = model_t.to(device) model_t.eval() samples = [ "I lost my card yesterday. Can you block it?", # 丢卡 "Why was I charged twice for the same transaction?", # 重复扣款 "My contactless payment isn't working at the store.", # 闪付失效 "The transfer hasn't arrived to the recipient yet.", # 转账未到账 "How can I change my PIN code?", # 修改PIN "Is Apple Pay supported for my card?", # Apple Pay 支持 "The ATM swallowed my card. What should I do?", # ATM 吞卡 "Balance didn’t update after my bank transfer.", # 余额未更新 "I want to terminate my account.", # 注销账户 "What are the fees for international card payments?", # 汇率/手续费 "Can I get a spare physical card for my account?", # 备用卡 "Why do I need to verify my identity again?", # 身份验证 ] predict(samples, 3, model=model_t, tok=tok_t, cfg=cfg_t)
测试结果:
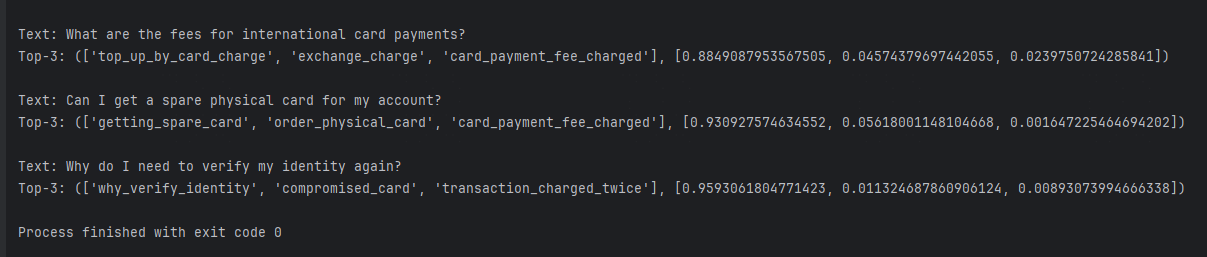
从测试结果来看,测试的意图识别结果都是正确的。
2. 学生模型训练
2.1 代码
以下代码不仅训练了一个带有KD的学生模型,还训练了一个不带KD的学生模型,对比蒸馏与非蒸馏的效果。
教师模型采用1中训练的模型。
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
import evaluate
from datasets import load_dataset, DatasetDict # huggingface
from transformers import AutoTokenizer, AutoModel, TrainingArguments, Trainer, set_seed, DataCollatorWithPadding, AutoConfig, AutoModelForSequenceClassification # huggingface
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchinfo import summary
from bert_kd import TeacherBackboneHead
from safetensors.torch import load_file
from dataclasses import dataclass
from typing import Optional, Union, Callable, Dict, Any, List, Tuple # ======================== 配置 ==================================
DATASET = "banking77"
TEACHER_DIR = f"runs/{DATASET}_teacher_custom" # 训练好的teacher模型路径
MAX_LEN = 256
SEED = 42
LR = 3e-4
EPOCHS = 20
BSZ_TRAIN = 32
BSZ_EVAL = 32 STUDENT_CKPT = "huawei-noah/TinyBERT_General_4L_312D" OUT_DIR= f"runs/{DATASET}_tinybert_kd"
set_seed(SEED) def load_intent_dataset(dataset_name): if dataset_name == "banking77": ds = load_dataset("banking77") text_col, label_col = "text", "label" num_labels = len(ds["train"].unique(label_col)) else: raise ValueError("Unknown dataset") if "validation" not in ds: if "test" in ds: ds = DatasetDict({"train": ds["train"], "validation": ds["test"]}) else: split = ds.train_test_split(test_size=0.1, SEED=SEED) ds = DatasetDict({"train": split["train"], "validation": split["test"]}) return ds, text_col, label_col, num_labels def tok_fn(batch, tok, max_len, TEXT): return tok(batch[TEXT], truncation=True, max_length=max_len) def dual_tok_fn(batch, tok_s, tok_t, max_len, TEXT): enc_s = tok_s(batch[TEXT], truncation=True, max_length=max_len) enc_t = tok_t(batch[TEXT], truncation=True, max_length=max_len) out = { "input_ids": enc_s["input_ids"], "attention_mask": enc_s["attention_mask"], "token_type_ids": enc_s["token_type_ids"], "t_input_ids": enc_t["input_ids"], "t_attention_mask": enc_t["attention_mask"], "t_token_type_ids": enc_t["token_type_ids"], } return out @dataclass
class KDConfig: T: float = 4.0 alpha: float = 0.7 mid_weight: float = 0.0 # 如需中间层蒸馏,设 >0 并看下方可选块 # 构建知识蒸馏训练trainer
class DistillerTrainer(Trainer): def __init__(self, *ar, teacher=None, kd=None, **kw): super().__init__(*ar, **kw) self.teacher = teacher self.kd = kd self.T = kd.T self.alpha = kd.alpha def compute_loss(self, model, inputs, return_outputs=False): labels = inputs["labels"] # students out out_s = model( input_ids=inputs["input_ids"], attention_mask=inputs["attention_mask"], token_type_ids=inputs["token_type_ids"], return_dict=True ) z_s = out_s.logits # teacher out with torch.no_grad(): out_t = self.teacher.backbone( input_ids=inputs["t_input_ids"], attention_mask=inputs["t_attention_mask"], token_type_ids=inputs["t_token_type_ids"], return_dict=True ) hidden = out_t.last_hidden_state sent = self.teacher.pool(hidden, inputs["t_attention_mask"]) # (B, H) z_t = self.teacher.head(sent) #(B,C) loss_kd = F.kl_div(F.log_softmax(z_s/self.T, dim=-1), F.softmax(z_t/self.T, dim=-1), reduction="batchmean") * (self.T ** 2) loss_ce = F.cross_entropy(z_s, labels) loss = self.alpha * loss_kd + (1 - self.alpha) * loss_ce return (loss, out_s) if return_outputs else loss class DualDataClllatorWithPadding: def __init__(self, tok_s, tok_t): super().__init__() self.collator_s = DataCollatorWithPadding(tok_s) self.collator_t = DataCollatorWithPadding(tok_t) self.keys_s = ["input_ids","attention_mask","token_type_ids", "label"] self.keys_t = ["t_input_ids","t_attention_mask","t_token_type_ids"] def __call__(self, features: List[Dict[str, Any]])-> Dict[str, Any]: # features: list of dict features_s = [{k:v for k,v in f.items() if k in self.keys_s} for f in features] features_t = [{k[2:]:v for k,v in f.items() if k in self.keys_t} for f in features] # 去掉t_前缀 batch_s = self.collator_s(features_s) batch_t = self.collator_t(features_t) # batch_s 中加入带t_的batch_t for k,v in batch_t.items(): batch_s[f"t_{k}"] = v return batch_s if __name__ == "__main__": # load teacher model TEACHER_DIR = r"runs/banking77_teacher_custom/best" cfg_t = AutoConfig.from_pretrained(TEACHER_DIR) tok_t = AutoTokenizer.from_pretrained(TEACHER_DIR, use_fast=True) model_t = TeacherBackboneHead(TEACHER_DIR, num_labels=77, config=cfg_t) device = torch.device("cuda:0") state_dict_t = load_file(os.path.join(TEACHER_DIR, "model.safetensors")) model_t.load_state_dict(state_dict_t) model_t = model_t.to(device) model_t.eval() # load dataset ds, TEXT, LABEL, N_LABELS = load_intent_dataset(DATASET) tok_s = AutoTokenizer.from_pretrained(STUDENT_CKPT, use_fast=True) ds_enc_s = ds.map(tok_fn, batched=True, remove_columns=[TEXT], fn_kwargs={"tok": tok_s, "max_len": MAX_LEN, "TEXT": TEXT}) collator_s = DataCollatorWithPadding(tok_s) collator_t = DataCollatorWithPadding(tok_t) ds_enc = ds.map(dual_tok_fn, batched=True, remove_columns=[TEXT], fn_kwargs={"tok_s": tok_s, "tok_t": tok_t, "max_len": MAX_LEN, "TEXT": TEXT}) collator = DualDataClllatorWithPadding(tok_s, tok_t) # 学生模型 student = AutoModelForSequenceClassification.from_pretrained(STUDENT_CKPT, num_labels=N_LABELS) # cfg cfg = AutoConfig.from_pretrained(STUDENT_CKPT, num_labels=N_LABELS) labels = ds["train"].features["label"].names id2label = {i: name for i, name in enumerate(labels)} cfg.id2label = id2label # acc f1 acc = evaluate.load("accuracy") # 预测正确的率 f1 = evaluate.load("f1") def compute_metrics(eval_pred): logits, labels = eval_pred preds = logits.argmax(-1) acc_result = acc.compute(predictions=preds, references=labels) f1_result = f1.compute(predictions=preds, references=labels, average="macro") return {"accuracy": acc_result["accuracy"], "f1": f1_result["f1"]} # 输出模型结构 examples = [ds_enc_s["train"][i] for i in range(2)] batch_ex = collator_s(examples) inputs_ex = {key: batch_ex[key] for key in ["input_ids", "attention_mask", "token_type_ids"]} class Wrapper(nn.Module): def __init__(self, core): super().__init__() self.core = core def forward(self, input_ids, attention_mask=None, token_type_ids=None): out = self.core(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids) return out["logits"] # [B, num_labels] wrapped = Wrapper(student) summary( wrapped, input_data=inputs_ex, depth=3, col_names=("input_size","output_size","num_params","trainable"), verbose=2 ) # kd KD = KDConfig() # args args_ = TrainingArguments( output_dir=OUT_DIR, learning_rate=LR, per_device_train_batch_size=BSZ_TRAIN, per_device_eval_batch_size=BSZ_EVAL, num_train_epochs=EPOCHS, evaluation_strategy="epoch", save_strategy="epoch", logging_steps=500, load_best_model_at_end=True, metric_for_best_model="f1", greater_is_better=True, seed=SEED, fp16=torch.cuda.is_available(), report_to="none", remove_unused_columns=False ) # trainer trainer = DistillerTrainer( model=student, args=args_, train_dataset=ds_enc["train"], eval_dataset=ds_enc["validation"], tokenizer=tok_s, data_collator=collator, # 动态padding compute_metrics=compute_metrics, teacher=model_t, kd=KD ) # train trainer.train() metrics = trainer.evaluate() print(f"Final metrics for student: {metrics}") # 保存(包含自定义头) os.makedirs(f"{OUT_DIR}/best", exist_ok=True) trainer.save_model(f"{OUT_DIR}/best") tok_s.save_pretrained(f"{OUT_DIR}/best") # trainer 中会自动保存tokenizer, 这一步可以不要 cfg.save_pretrained(f"{OUT_DIR}/best") print(f"Saved student to {OUT_DIR}/best") # 对比直接训练 student2 = AutoModelForSequenceClassification.from_pretrained(STUDENT_CKPT, num_labels=N_LABELS) trainer2 = Trainer( model=student2, args=args_, train_dataset=ds_enc_s["train"], eval_dataset=ds_enc_s["validation"], tokenizer=tok_s, data_collator=collator_s, # 动态padding compute_metrics=compute_metrics ) # train trainer2.train() metrics2 = trainer2.evaluate() print(f"Final metrics for student no kd: {metrics2}") # 保存(包含自定义头) os.makedirs(f"{OUT_DIR}_no_kd/best", exist_ok=True) trainer2.save_model(f"{OUT_DIR}_no_kd/best") tok_s.save_pretrained(f"{OUT_DIR}_no_kd/best") # trainer 中会自动保存tokenizer, 这一步可以不要 cfg.save_pretrained(f"{OUT_DIR}_no_kd/best") print(f"Saved student to {OUT_DIR}_no_kd/best")
2.2 结果
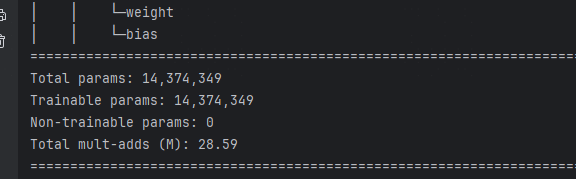
直接运行上面代码,首先可以看到student模型结构和参数。可发现其参数量比教师模型少了很多,大概只有教师模型的10%。
最后acc和f1的结果我们可以看到:
KD Student:

No KD Student:

结果:带KD的模型比不带KD的模型提升了4%左右。
结论
- 基于BERT 骨干网络的预训练模型,结合自定义的分类头,训练一个意图识别模型,需要很少的epoch就能完成,并且得到的效果还不错。说明BERT的预训练模型确实有着不错的语言特征提取能力。
- KD的效果确实能够在一个小模型上得到跟教师模型差不多的效果,并且由于不带KD直接训练的小模型。说明KD确实起了作用。
- 这里我们只用了基本的KD手断,比如中间层计算损失也没用,参数也没怎么去调整。
4. KD的参数很大程度了影响了结果,这个参数也是试了好几次得到相对比较好的效果,最好是加上隐藏层损失,那样会更好一点,这个留给看这篇文章的人自己去尝试。