微博舆情大数据实战项目 Python爬虫+SnowNLP情感+Vue可视化 全栈开发 大数据项目 机器学习✅
博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅点击查看作者主页,了解更多项目!
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、最全计算机专业毕业设计选题大全(建议收藏)✅
1、项目介绍
技术栈:Python语言、Flask框架、Vue前端框架、Echarts可视化、requests爬虫、SnowNLP情感分析、HanLP符号处理、numpy、pandas数据分析、MySQL数据库、SQLAlchemy ORM
研究背景:微博日活过亿,话题扩散呈“秒级”传播,传统人工舆情监测滞后明显。利用requests实时抓取话题与评论,SnowNLP完成中文情感极性判断,HanLP清洗符号噪声,结合Flask+Vue+Echarts构建前后端分离架构,可在分钟级完成“数据采集-情感计算-可视化-预警”闭环,为高校、政府、企业提供轻量化舆情洞察工具。
研究意义:系统全程本地部署,保障数据隐私;模块化设计支持插拔式替换算法或数据源,适合作为“数据科学”“NLP”课程实践与毕业设计模板,推动大数据情感计算在教学与产业中的双向落地。
2、项目界面
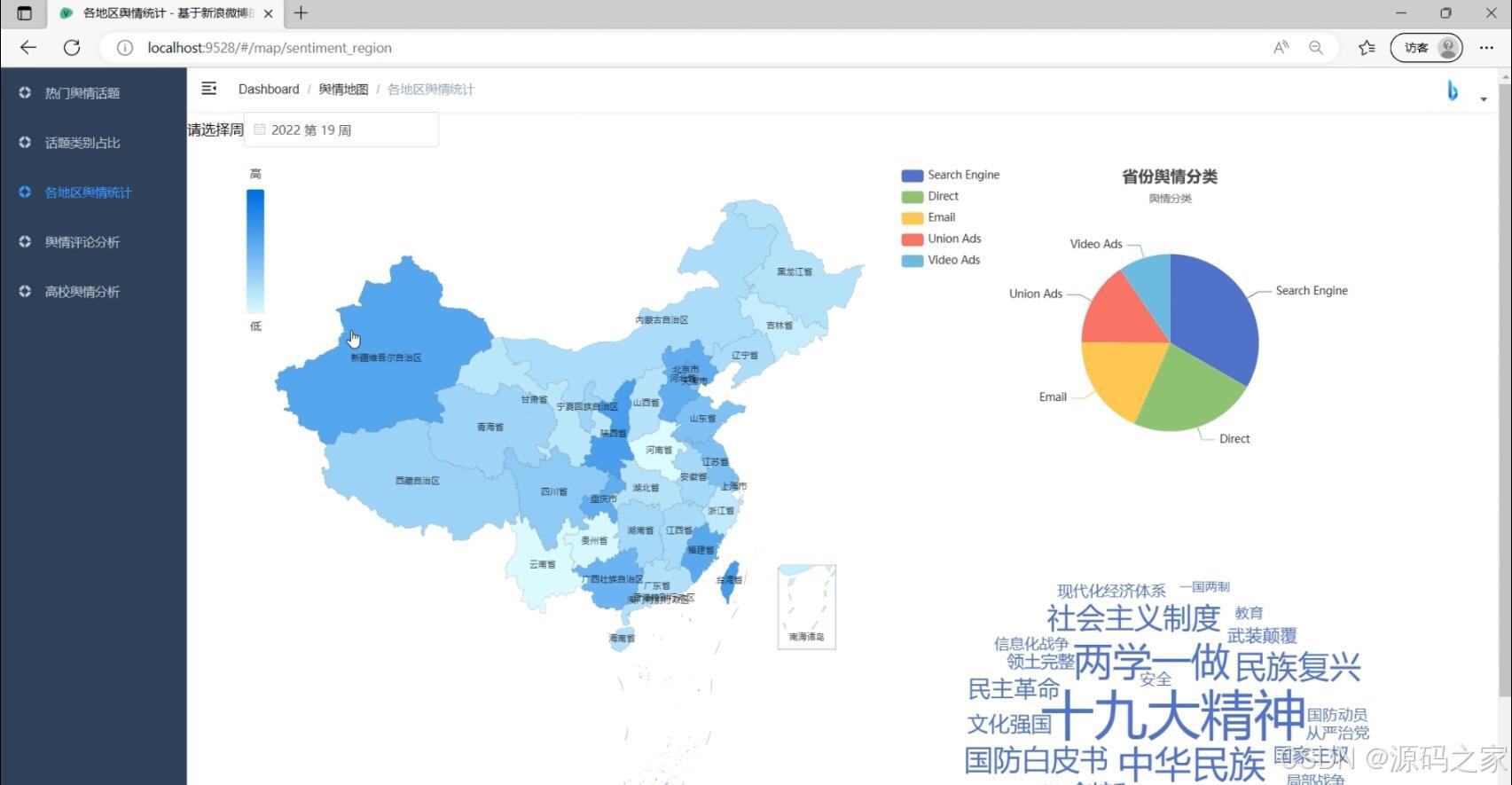
(1)各地区舆情统计分析
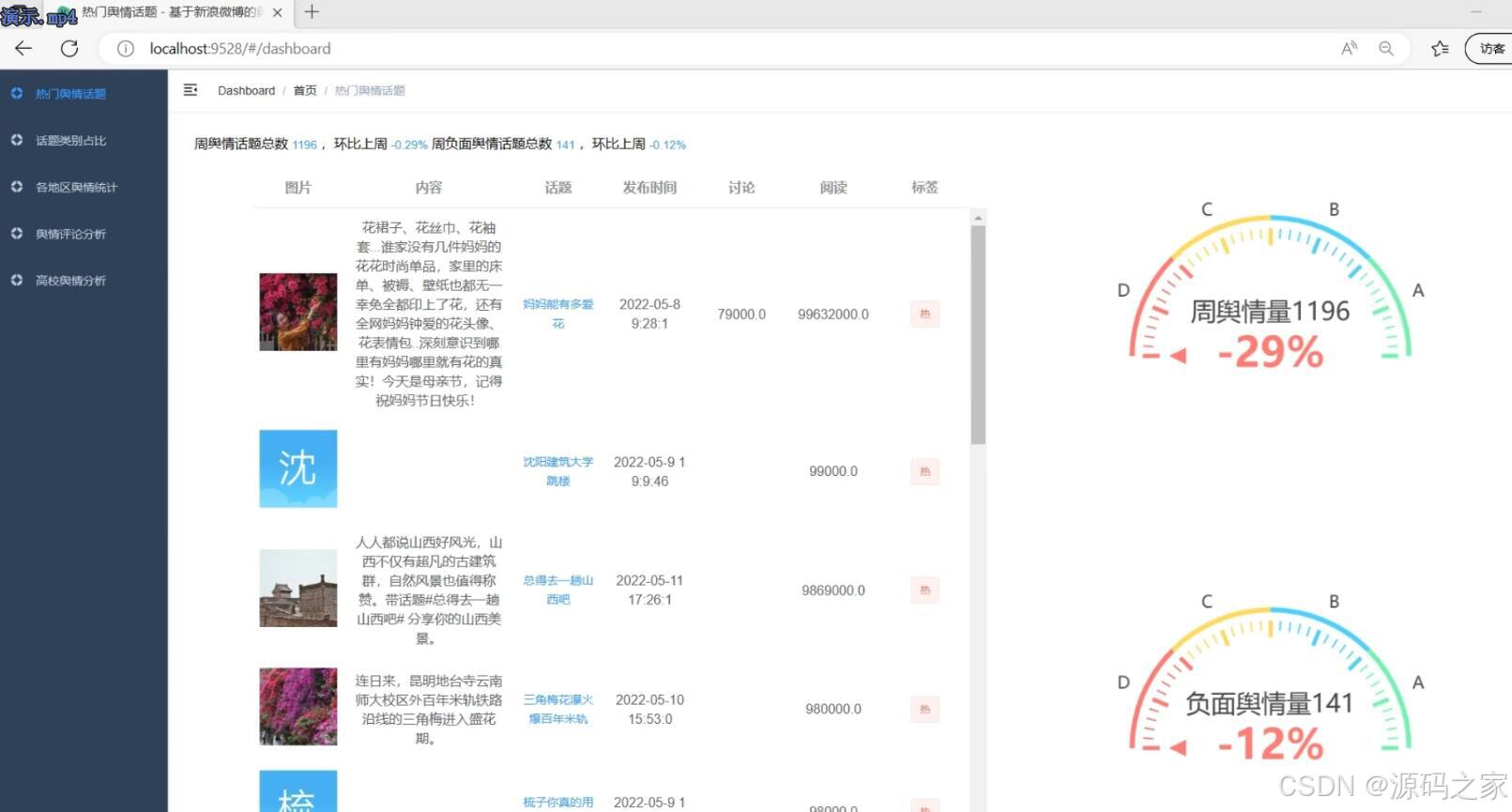
(2)热门舆情话题分析
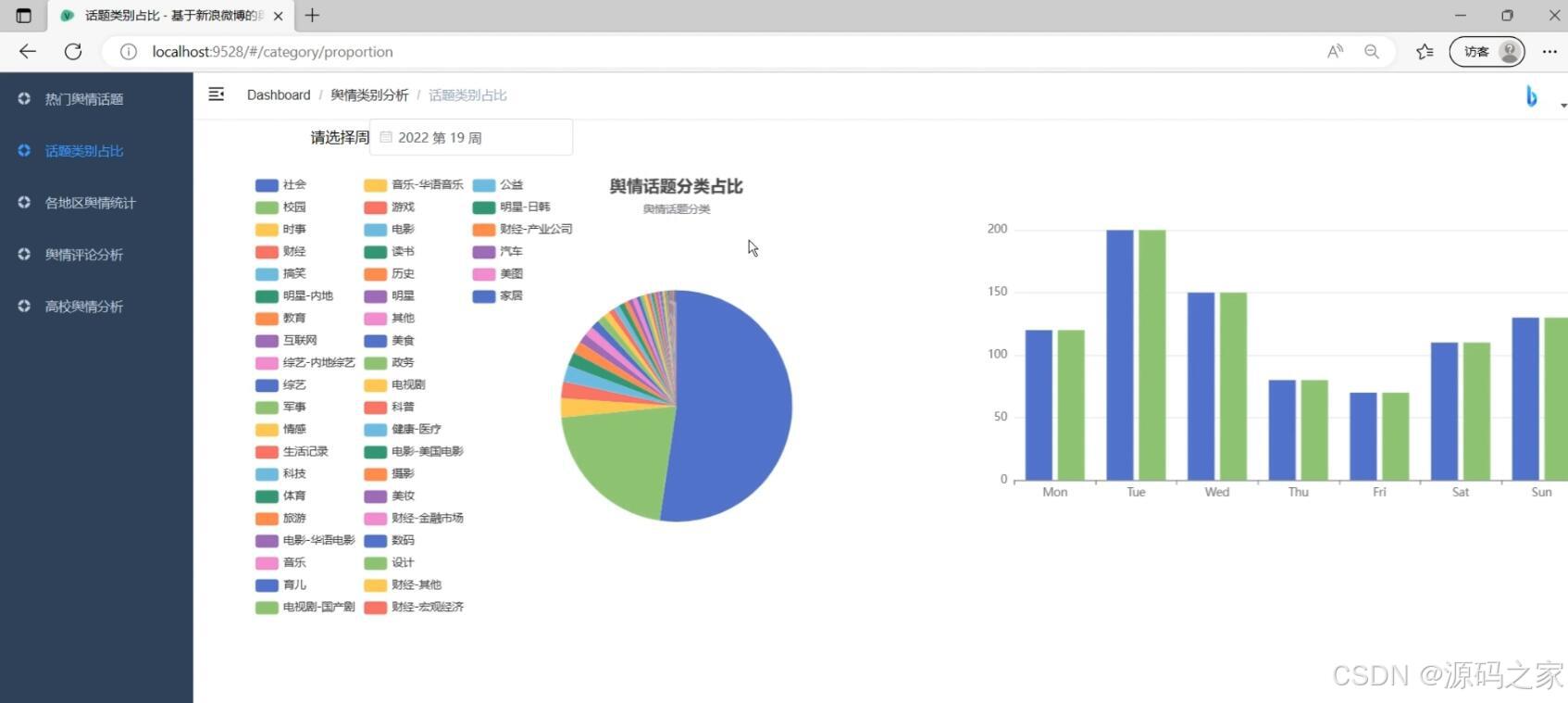
(3)话题分类占比分析
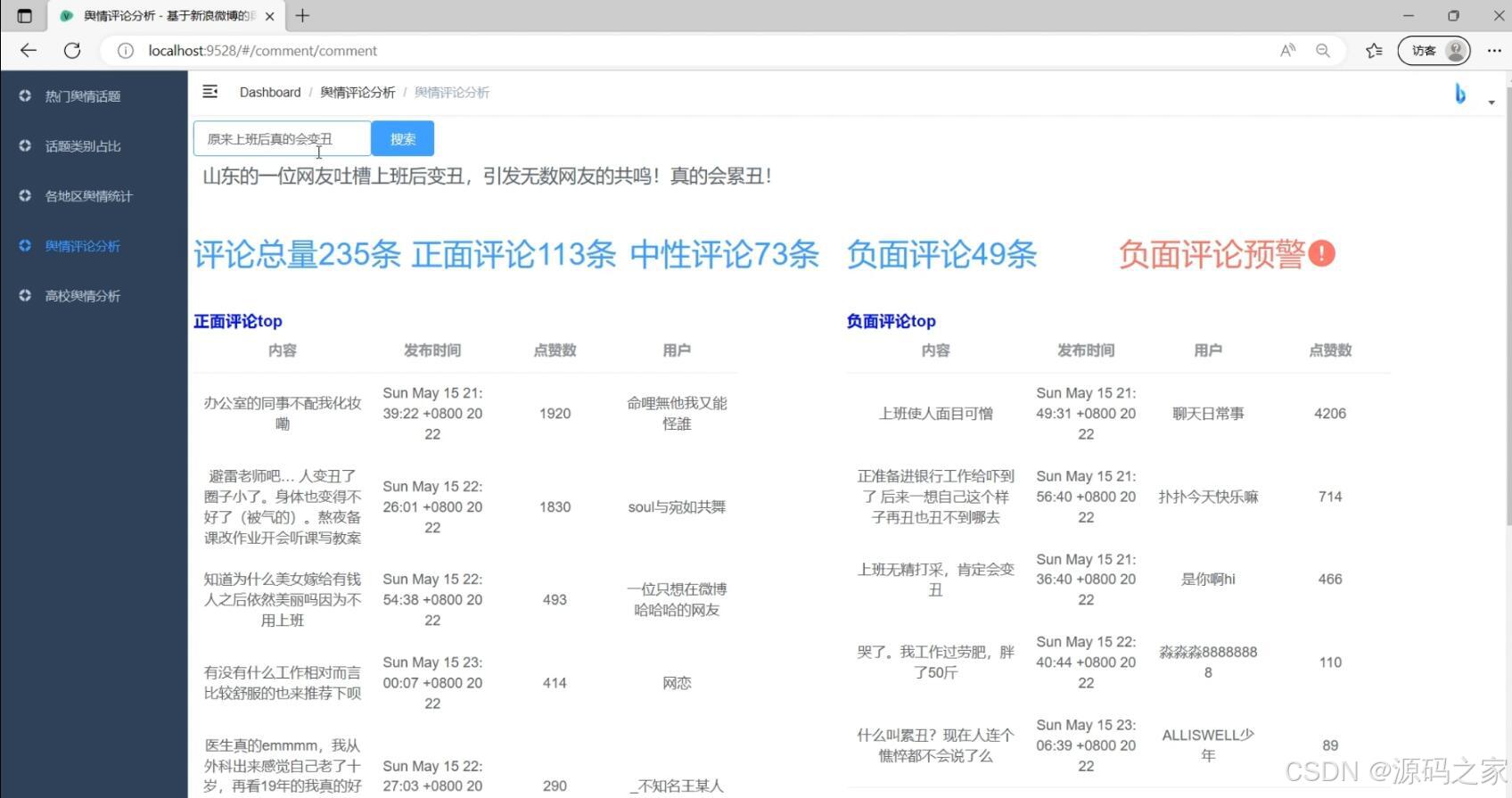
(4)舆情评论分析
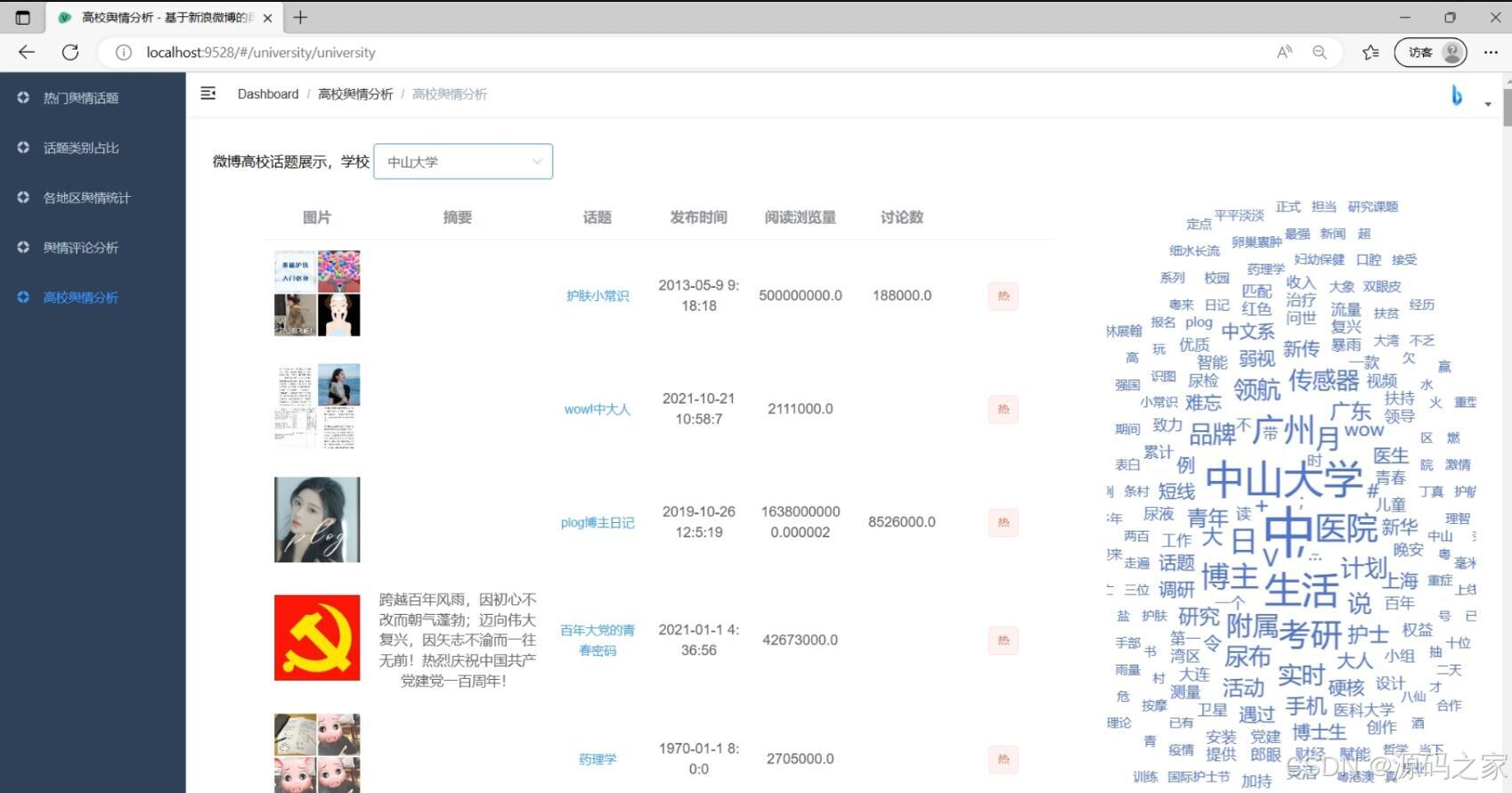
(5)高校舆情分析
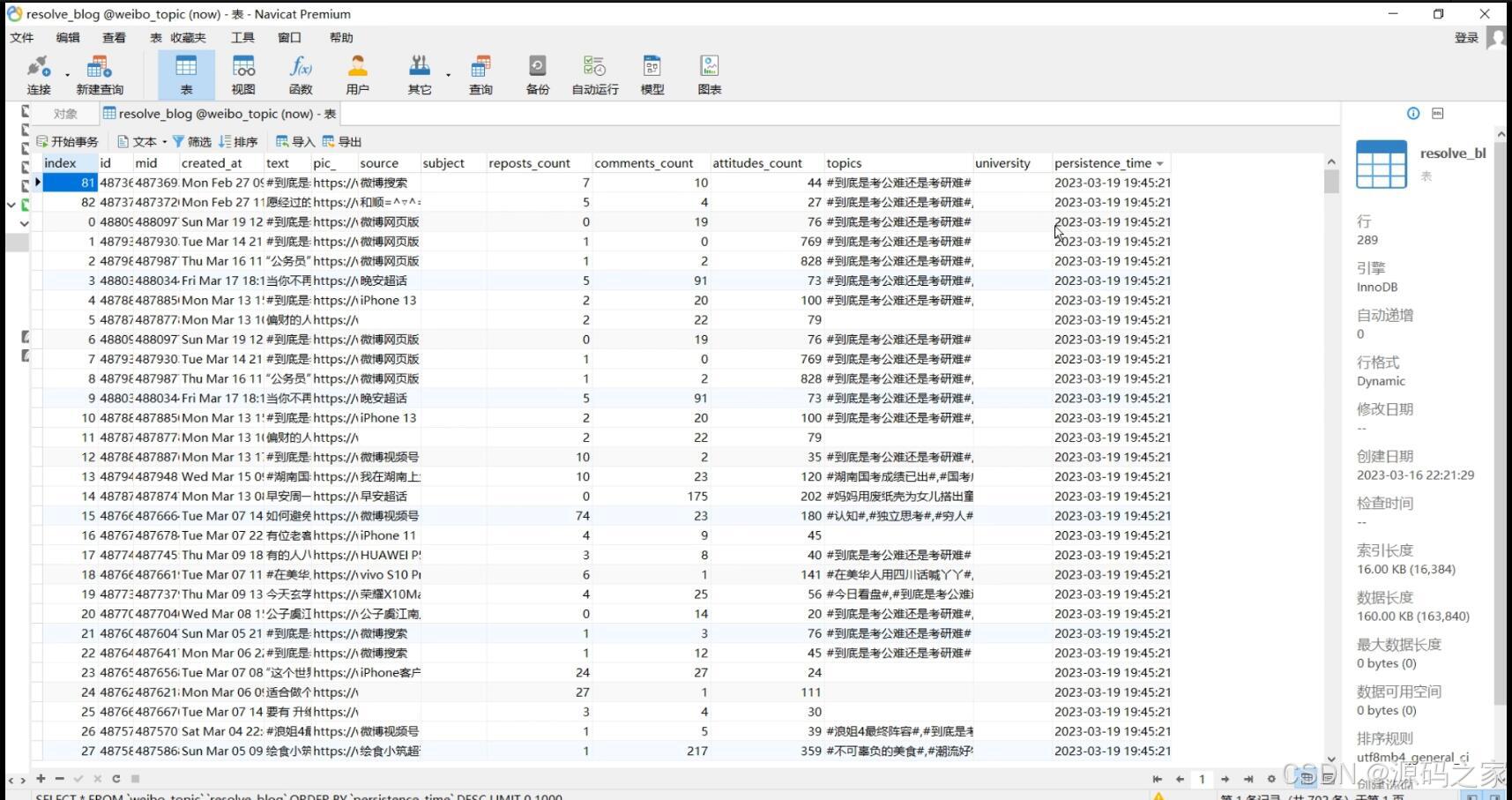
(6)数据库数据
3、项目说明(约900字)
摘要:在社交网络迅猛发展的今天,微博已成为舆情事件酝酿、扩散和演变的核心舞台。为帮助管理者及时洞察公众情绪、优化服务体验并提升突发事件应对能力,本文设计并实现了一套基于微博平台的舆情分析系统。系统以“数据爬取-情感分析-可视化管理”为主线,采用Flask+SQLAlchemy+Vue架构,通过requests爬虫实时抓取微博热搜、话题帖与评论,利用HanLP清洗符号与停用词,SnowNLP进行情感极性判断,最终用Echarts将热度、情感分布、地区占比、高校话题等多维结果呈现给用户,并支持CSV导出与历史回溯。
总体架构分为三层:
- 数据采集层——官方API+requests爬虫双路获取,话题榜、评论、指数信息定时入库;
- 数据处理层——HanLP分词与符号过滤、SnowNLP情感得分、numpy/pandas统计聚合,并生成热度时序数据供ARIMA预测(扩展接口已预留);
- 数据展示层——Vue+Echarts渲染交互式图表,包括词云、地图热力、话题分类饼图、评论情感折线、高校舆情雷达等,用户可拖拽缩放、点击下钻。
功能模块高度解耦:
- 微博数据采集:热搜榜前50、单条话题全部评论、话题指数三子模块,可独立运行;
- 情感分析:预置情感词典,支持后台上传自定义词表,负面情感占比超阈值自动邮件/站内预警;
- 舆情展示:热点发现、类别占比、地区统计、评论情感、高校舆情五大面板,管理员可在后台动态配置图表颜色、预警阈值、刷新频率;
- 用户中心:注册登录、个人信息、关键词搜索记录、历史报告下载,普通用户仅能查看,管理员可增删成员、重置密码、审核评论。
系统全程本地部署,不依赖外网接口,既保护数据隐私,又降低运维成本;模块化代码支持学生快速替换算法(如BERT情感模型)或接入其他数据源(如抖音、知乎),适合作为“数据科学”“NLP”“大数据开发”等课程的实践案例,也可直接用于毕业设计、数据竞赛或科研项目的baseline。通过开源代码与详细部署文档,项目期望吸引更多开发者关注舆情NLP任务,共同推动社会计算与情感计算的产学研深度融合。
4、核心代码
import json
from datetime import date, timedelta, datetime
from flask import Flask, session, jsonify, request
from database.config import db, SQLALCHEMY_DATABASE_URI
from model.User import User
from analysis import calculate
app = Flask(__name__)
app.config["SQLALCHEMY_DATABASE_URI"] = SQLALCHEMY_DATABASE_URI
app.config["TEMPLATES_AUTO_RELOAD"] = True
app.config["SECRET_KEY"] = 'weibo_topic'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
db.init_app(app)@app.before_first_request
def create_tables():db.create_all()@app.route('/recently', methods=['POST'])
def recently_topic():"""最近的本周舆情分析1.舆情指数2.舆情热搜分析:return:"""params = request.get_json()dateTime = '2022-5-11T01:10:01'dt = datetime.strptime(dateTime, '%Y-%m-%dT%H:%M:%S').date()data1 = calculate.weekly_hot_topic(dt=dt)data2 = calculate.weekly_topic_total(dt=dt)result = {'code': 20000, 'amount': data2, 'topics': data1}return jsonify(result)@app.route('/wordCloud', methods=['POST'])
def weekly_wc():"""热搜话题图谱:return:"""data = calculate.weekly_word_cloud()result = {'code': 20000, 'data': data}return jsonify(result)@app.route('/category', methods=['POST'])
def category():"""类别占比分析1.舆情话题的周类别分析2.正负舆情对比分析:return:"""param = request.get_json()dateTime = param['datetime']dateTime = dateTime.split('.')[0]dt = datetime.strptime(dateTime, '%Y-%m-%dT%H:%M:%S').date()data = calculate.weekly_topic_category(mode='week', dt=dt)result = {'code': 20000, 'data': data}return jsonify(result)@app.route('/pop', methods=['POST'])
def pop():"""正负舆情对比分析:return:"""param = request.get_json()dateTime = param['datetime']dateTime = dateTime.split('.')[0]dt = datetime.strptime(dateTime, '%Y-%m-%dT%H:%M:%S').date()# print('pop cal')data = calculate.PositiveOrPassive(dt=dt)return jsonify({'code': 20000, 'data': data})@app.route('/region', methods=['POST'])
def region():"""舆情地区统计:return:"""param = request.get_json()dateTime = param['datetime']dateTime = dateTime.split('.')[0]dt = datetime.strptime(dateTime, '%Y-%m-%dT%H:%M:%S').date()data = calculate.weekly_topic_region(dt=dt)return jsonify({'code': 20000, 'data': data})@app.route('/uni_param', methods=['POST', 'GET'])
def getUniversityParam():"""获取高校参数信息:return:"""data = calculate.getUniversityParam()result = {'code': 20000, 'data': data}return jsonify(result)@app.route('/comment', methods=['POST'])
def commentAnalysis():"""评论分析:return:"""params = request.get_json()topic = params['topic']data = calculate.getCommentData(topic)result = {'code': 20000, 'data': data}return jsonify(result)@app.route('/university', methods=['POST'])
def query_university():"""搜索大学热搜显示该学校的热门话题返回指定高校的热搜数据:return:"""param = request.get_json()name = param['name']data = calculate.getTopicByUniversity(name)result = {'code': 20000, 'data': data}return jsonify(result)@app.route('/logout', methods=['POST'])
def logout():"""注销"""session.clear()data = {'data': '', 'code': 20000}return jsonify(data)@app.route('/info', methods=['GET', 'POST'])
@app.route('/login', methods=['GET', 'POST'])
def login():data = request.get_json()if (request.method == 'GET') and (session.get('userid') is not None):user = User().userinfo(userid=session['userid'])data = {'data': user.serialize(), 'code': 20000}return jsonify(data)if request.method == 'POST':user = User()user = user.valid_login(username=data['username'], password=data['password'])if user:session['user'] = str(user.username)session['userid'] = str(user.id)data = {'data': user.serialize(), 'code': 20000}return jsonify(data)else:data['error'] = '错误的用户名或密码!'return data@app.route('/')
def hello_world():return 'Hello World!'if __name__ == '__main__':app.run()
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻