AI 的耳朵在哪里?—— 语音识别
AI 的耳朵在哪里?—— 语音识别
上篇聊到 AI 的 “核心密码”算法就像机器的“智能说明书”,让机器可以解决各种问题。可 AI 光有 “说明书” 还不够 —— 想听懂咱们说 “我想吃冰淇淋”“帮我查天气”,得有能 “听声音” 的 “耳朵” 才行!今天咱们就来拆一拆:AI 的耳朵到底藏在哪里?它又是怎么一步步听懂人类说话的?
一、先回顾:AI 的 “耳朵” 离不开算法这个 “基座”
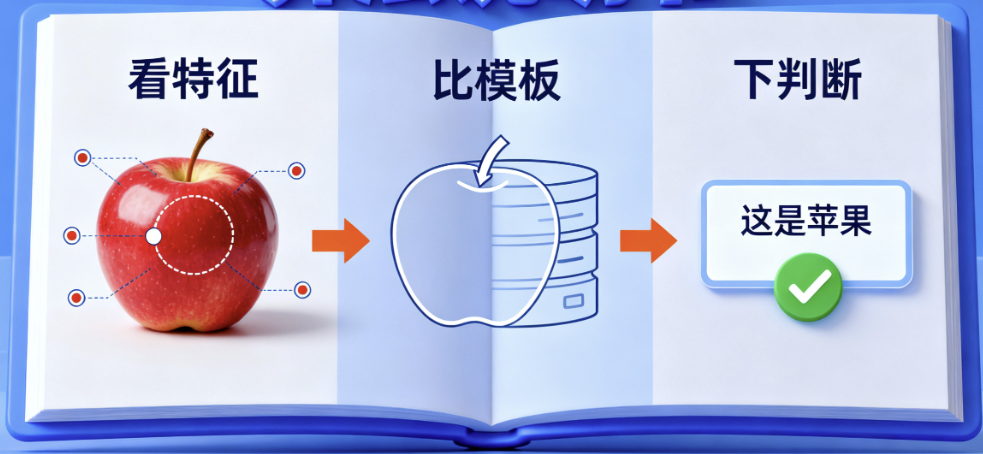
上次咱们说,算法是 AI 的 “智能说明书”—— 比如训练 AI 识别苹果时,算法会教它 “看特征、比模板、下判断”。而语音识别,其实就是算法给 AI 定制的 “听声说明书”:从 “抓得住声音” 到 “读得懂意思”,每一步都靠算法来指挥。就像你想听懂同学说话,得先有耳朵(抓声音)、再学拼音(拆发音)、最后懂语境(猜意思),AI 的 “听声步骤”,和咱们学说话的逻辑特别像!
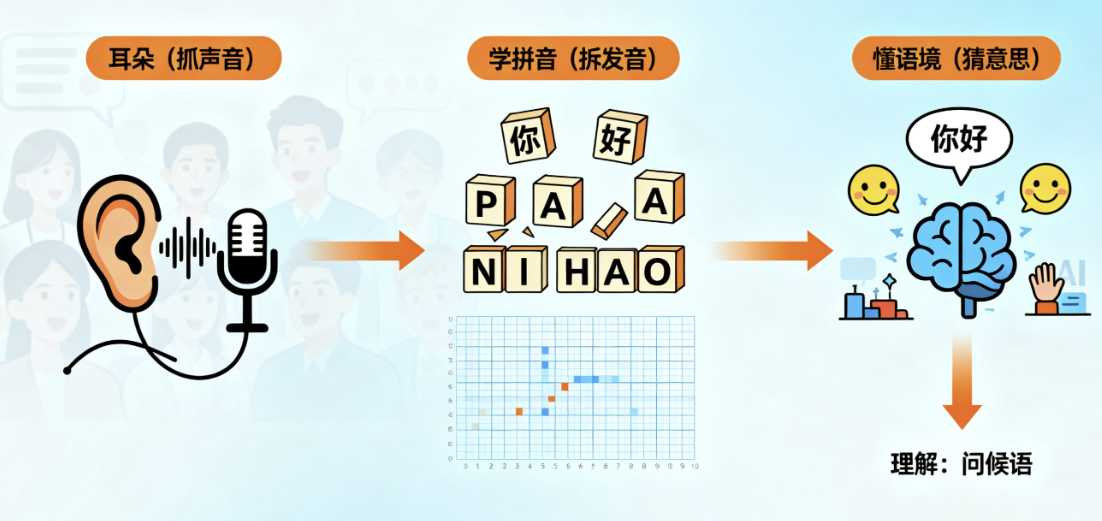
- 语音识别的 “三步魔法”:AI 是怎么 “听” 懂话的?
AI 的 “耳朵” 不是真的肉耳朵,而是靠算法把 “看不见的声音” 变成 “能理解的意思”,这背后有三个关键步骤,咱们用生活里的例子慢慢说~
第一步:把 “看不见的声音” 变成 “看得见的数字”—— 搞定 “声音音频”
你喊一声 “老师好”,声音会变成声波—— 就像你往池塘里扔石子,水面荡开的一圈圈波纹,只不过声波是在空气里 “荡”,咱们看不见摸不着。那 AI 怎么 “抓” 到这圈 “空气波纹” 呢?
靠的是麦克风(就像 AI 的 “耳朵外壳”)!麦克风会先把声波变成电信号,再像 “画波浪画” 一样,把电信号变成屏幕上的 “音频波形图”—— 声音大的时候,波形的 “山峰” 就高;声音小的时候,“山谷” 就浅;说话快的时候,波形挤得密;说话慢的时候,波形分得疏。

最后,算法会把这张 “波浪图” 上的每个点,都换成数字(比如波峰标 120,波谷标 - 80)—— 就像给声音编了一串 “数字密码”!这样一来,看不见的声音就变成了 AI 能 “读” 懂的数字,是不是像给声音拍了一串 “慢动作照片”?
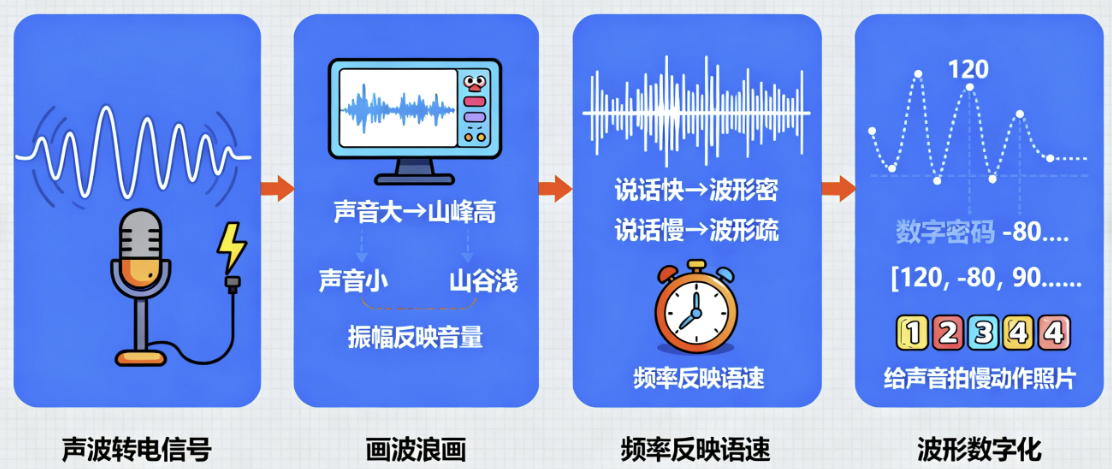
比如你说 “啊 ——”,屏幕上会出现一条长长的、平缓的波形;你说 “哒哒哒”,就会出现三个短而尖的波形 —— 下次你用手机录音时,可以看看录音 APP 里的波形,就能直观看到自己声音的 “样子” 啦!
第二步:把 “完整的话” 拆成 “最小发音零件”—— 认识 “音素”
拿到 “数字密码” 后,AI 不会直接猜 “整句话是什么”,而是先把声音拆成音素—— 就像你用积木拼小房子,得先把大积木拆成小方块、小长条;咱们说的每句话,也能拆成一个个最简短的 “小发音”。
音素是语音的 “最小零件”,比如 “爸爸”(bà bà)拆成音素,就是 “b” 和 “à” 两个;“西瓜”(xī guā)拆成音素,就是 “x”“ī”“g”“uā” 四个;就算是长句子 “我今天要上学”,也能拆成 “wǒ”“jīn”“tiān”“yào”“shàng”“xué” 对应的一个个小音素。

AI 会对照自己的 “音素字典”(里面记着每个音素的 “数字特征”),确认你说的每个 “小发音” 到底是什么 —— 就像你拼积木前,先认清 “这个是方积木,那个是长积木”;也像你学拼音时,先练会 “b、p、m、f”,才能拼出完整的字。
比如你含糊地说 “shuāng”,AI 会拆出 “sh”“u”“āng” 三个音素,再对应到 “双” 这个字 —— 要是少了一个音素,比如只拆出 “sh”“āng”,AI 可能就会猜成 “商” 啦!
第三步:靠 “经验” 猜意思 ——AI 的 “概率模型小侦探”
拆完音素,AI 还会遇到一个问题:有些音素拼起来,可能对应好几个意思,怎么选对呢?这时候就需要概率模型帮忙 —— 它就像 AI 的 “语言小侦探”,会用 “平时学过的经验”,猜哪个意思最可能。
比如你说 “wǒ yào qù”,后面没说完,AI 怎么知道是 “我要去公园” 还是 “我要去吃饭”?其实 AI 的 “概率模型” 里,记着咱们平时说话的习惯:比如小朋友说 “我要去”,后面接 “公园”“学校”“家里” 的次数,比接 “月球”“海底” 多得多 —— 所以 “我要去公园” 的概率更高,AI 就会优先按这个意思回应。
再比如你说 “今天天气真 yáng”,AI 会猜是 “晴”(qíng)还是 “阳”(yáng)?因为 “天气晴朗” 是咱们常说的话,概率比 “天气真阳” 高太多,所以 AI 会直接选 “晴”。
这就像你听到同学说 “明天要带”,不用问也能猜到大概率是 “带课本”“带作业”,而不是 “带小仓鼠”—— 因为你知道同学平时的习惯,AI 的概率模型,就是把这种 “习惯” 变成了能计算的 “概率”!
三、课堂小实验:亲手 “摸一摸” AI 的耳朵!
想亲身体验语音识别的步骤吗?老师可以带大家做三个简单的小实验,材料都是咱们身边常见的东西,动手又动脑~
实验 1:声波大发现 —— 看声音的 “样子”
- 准备工具:电脑(或平板)、免费音频软件(比如 “Audacity”,老师提前下载好)。
- 怎么做:
- 老师打开软件,让学生轮流对着麦克风说一句话(比如 “你好”“我爱科学”),屏幕上会出现对应的波形图;
- 让学生试试 “大声说” 和 “小声说”—— 观察波形的 “高低” 变化(大声时波峰更高);
- 再试试 “快说” 和 “慢说”—— 观察波形的 “疏密” 变化(快说时波形更挤)。
- 小发现:原来不同的声音,“长” 得不一样!AI 就是靠认这些 “不一样的波形”,抓住咱们的声音的。
实验 2:模糊语音挑战 —— 测测 AI 的 “概率模型”
- 准备工具:CSK6 大模型开发板+大模型语音交互示例。
- 怎么做:
- 让学生轮流 “故意说模糊”:比如小声说 “明天要带数学书”、快说 “我想吃草莓冰淇淋”、带点口音说 “今天星期几”;
- 看看语音助手能不能猜对意思,把结果记在纸上;
- 大家一起讨论:“AI 为什么能猜对?”“哪些话 AI 容易猜错?为什么?”(比如 “带数学书” 比 “带玩具车” 常见,所以 AI 更容易猜对)。
- 小发现:AI 不是 “万能耳”,但它会靠 “平时学的习惯” 猜意思 —— 这就是概率模型的魔法!
其实 AI 的 “耳朵”,一点都不神秘:它靠麦克风抓声波,靠算法拆音素,靠概率模型猜意思,而这一切的基础,都是咱们上次聊到的 AI 算法。下次你用语音助手发消息、问问题时,不妨多观察:它是不是能听懂你的小声话?能不能猜对你没说完的话?这背后,都是今天咱们拆明白的 “语音识别小秘密”~ 说不定以后你还能设计出更厉害的 “AI 耳朵”,让它听懂更多语言呢!
- 其他资料
以上图片内容仅作参考,可以根据实际讲解场景进行更换。后续会继续推出相关内容。
有先提前学习的朋友可以先参考这份课程设计参考:https://docs2.listenai.com/x/xNA3G4J8h
演示硬件参考:https://docs2.listenai.com/x/nTn9kMMCU