RecSys: 推荐系统重排与多样性优化(MMR以及DPP算法)
摘要:深入解析如何通过重排技术有效平衡用户兴趣与内容多样性,从而显著提升推荐系统的核心业务指标。
核心摘要
推荐系统的多样性优化,特别是在重排阶段的有效处理,能够显著提升用户使用时长和留存率等关键业务指标。本文核心内容围绕两大关键点展开:
- 物品相似性度量:基于物品图文内容的向量表征(如CLIP模型)相较于传统的属性标签或双塔模型向量更为有效
- 多样性优化方法:采用MMR(最大边界相关)算法及其滑动窗口改进版本以及DPP算法:(工业界公认比较有用的方法之一),在保持高精排分数的前提下,显著提升推荐结果的多样性
1. 物品相似性度量
相似性计算是多样性优化的基础,目前主流方法包括三种:
| 方法 | 描述 | 优点 | 缺点 | 适用性 |
|---|---|---|---|---|
| 基于属性标签 | 使用类目、品牌、关键词等标签计算相似度(如Jaccard相似度) | 简单直观,可解释性强 | 粒度较粗,无法捕捉细粒度语义相似性(如"海边度假"和"滑雪"虽同属"旅游"但语义迥异) | 快速但效果有限的基线方法 |
| 基于双塔模型向量 | 使用召回阶段学到的物品向量计算余弦相似度 | 能捕捉用户行为层面的协同信号 | 头部效应严重,冷启动物品和长尾物品的向量表征质量差 | 不推荐用于多样性目的,会放大系统偏差 |
| 基于内容向量(CLIP) | 使用CLIP等预训练模型从物品的图片和文本内容中提取向量 | 效果最好,能深度理解内容语义,不受曝光偏差影响,完美处理冷启动问题 | 需要额外的模型部署和计算开销 | 当前业界最佳实践,特别适用于图文内容平台 |
CLIP工作原理详解
CLIP(Contrastive Language-Image Pre-training)是一种先进的图文多模态模型,其训练方式具有独特优势:
- 正样本构建:一篇笔记的图片与其自身文本配对作为正样本
- 负样本构建:该图片与同一训练批次(Batch)中其他笔记的文本随机配对作为负样本
- 训练目标:通过对比学习,让正样本的图文向量在表征空间中距离越来越近,负样本的越来越远
这种训练方式使得CLIP能够学习到丰富的内容语义表征,为物品相似度计算提供高质量的基础。
2. 多样性优化方法
问题根源:Pointwise排序的局限性
精排和粗排模型通常采用Pointwise打分方式,仅为每个物品独立预测得分(如reward_i表示点击率),追求的是总分最大化。这种机制必然导致推荐结果同质化——相似的高分物品集中出现,严重影响用户体验。
解决方案:重排阶段的后处理
在粗排(从几千选几百)和精排(从几百选几十)之后,引入后处理(重排)阶段,综合考量用户兴趣分数和多样性分数,实现更好的平衡。
MMR算法(Maximal Marginal Relevance)
算法目标:从大小为n的候选集R中,选出k个物品组成集合S,使得集合既具有较高的总reward,又具有较高的多样性。
算法流程:
-
初始化:已选集合
S = ∅,候选集R为全部n个物品 -
选择锚点物品:将精排分数
reward_i最高的物品放入S,确保起点的最优性 -
迭代选择(执行 k-1 次):
- 对于每个候选物品
i ∈ R,计算其边际相关分数:
MRi=θ⋅rewardi−(1−θ)⋅maxj∈Ssim(i,j)MR_i = \theta \cdot reward_i - (1-\theta) \cdot \max_{j \in S} sim(i, j)MRi=θ⋅rewardi−(1−θ)⋅j∈Smaxsim(i,j)
-
θ · reward_i:衡量物品自身价值 -
(1-θ) · max_sim(i, S):衡量物品与已选集合的最大相似度(冗余度) -
θ:调节相关性与多样性权重的超参数(0 ≤ θ ≤ 1) -
选择
MR分数最高的物品i*,将其从R移至S
- 对于每个候选物品
-
输出结果:最终
S中的k个物品即为重排后的推荐列表
滑动窗口MMR:工业级优化方案
原始MMR的缺陷:随着已选集合 S 扩大,max_{j ∈ S} sim(i, j) 项会趋近于1(因为总存在某个历史物品与当前候选相似),导致多样性项失效,算法退化为按精排得分排序。
创新解决方案:采用固定大小的滑动窗口 W(如只考虑最近选中的10个物品)来代替整个已选集合 S:
MRi=θ⋅rewardi−(1−θ)⋅maxj∈Wsim(i,j)MR_i = \theta \cdot reward_i - (1-\theta) \cdot \max_{j \in W} sim(i, j) MRi=θ⋅rewardi−(1−θ)⋅j∈Wmaxsim(i,j)
为什么滑动窗口更有效?
-
符合用户浏览习惯:用户通常顺序浏览推荐内容,只要连续看到的几个物品(1-2屏)不重复,就能感知到多样性。用户不会记忆较早前看过的内容,因此无需让第30个物品与第1个物品不相似。
-
提升计算效率:大幅降低计算复杂度,窗口大小固定为常数,使算法适合大规模线上场景。
-
实践效果验证:工业界应用表明,滑动窗口机制能更好地平衡相关性与多样性,显著提升用户体验和业务指标。
推荐系统重排阶段的多样性优化是一个系统工程,需要:
- 选择正确的相似度度量方法(基于内容的向量表征)
- 采用合适的多样性算法(MMR及其滑动窗口变种)
- 合理平衡相关性得分与多样性得分(调节超参数θ)
DPP多样性算法(上)
行列式点过程(Determinantal Point Process,DPP)是一种经典的机器学习算法,自2000年以来得到了快速发展。目前,DPP被公认为推荐系统重排任务中实现多样性的最佳方法之一。
在精排阶段,系统输出 nnn 个候选物品,已知它们的向量表征 v1,…,vn∈Rd\boldsymbol{v}_1, \dots, \boldsymbol{v}_n \in \mathbb{R}^dv1,…,vn∈Rd,以及精排给出的奖励分数 reward1,…,rewardn\text{reward}_1, \dots, \text{reward}_nreward1,…,rewardn。我们的目标是从中选出 kkk 个物品,组成集合 SSS,它是全集 [n]={1,…,n}[n] = \{1, \dots, n\}[n]={1,…,n} 的一个子集。
与MMR(Maximal Marginal Relevance)方法类似,DPP的目标是使集合 SSS 中的物品既具有较高的价值,又具备多样性。两者的主要区别在于衡量多样性的方式:MMR通过物品之间的两两相似度来衡量多样性,而DPP则使用整个集合 SSS 对应的行列式来度量多样性。
1.3.1 超平行体(Parallelepiped)
给定一组向量 v1,…,vk∈Rd\boldsymbol{v}_1, \dots, \boldsymbol{v}_k \in \mathbb{R}^dv1,…,vk∈Rd,且满足 k≤dk \leq dk≤d(例如,在三维空间中可构造二维平行四边形,但在二维空间中无法构造三维立方体),则在 Rd\mathbb{R}^dRd 空间中定义的 kkk 维超平行体为:
P(v1,…,vk)={a1v1+⋯+akvk∣0≤a1,…,ak≤1}.P(\boldsymbol{v}_1, \dots, \boldsymbol{v}_k) = \left\{ a_1 \boldsymbol{v}_1 + \dots + a_k \boldsymbol{v}_k \mid 0 \leq a_1, \dots, a_k \leq 1 \right\}. P(v1,…,vk)={a1v1+⋯+akvk∣0≤a1,…,ak≤1}.
这些向量 v1,…,vk\boldsymbol{v}_1, \dots, \boldsymbol{v}_kv1,…,vk 被称为超平行体的边,它们唯一确定了一个超平行体。超平行体中的点是这些向量的线性组合,系数 a1,…,aka_1, \dots, a_ka1,…,ak 取值于 [0,1][0,1][0,1]。如下图所示,平行四边形(k=2k=2k=2)和平行六面体(k=3k=3k=3)分别是二维和三维情况下的超平行体。
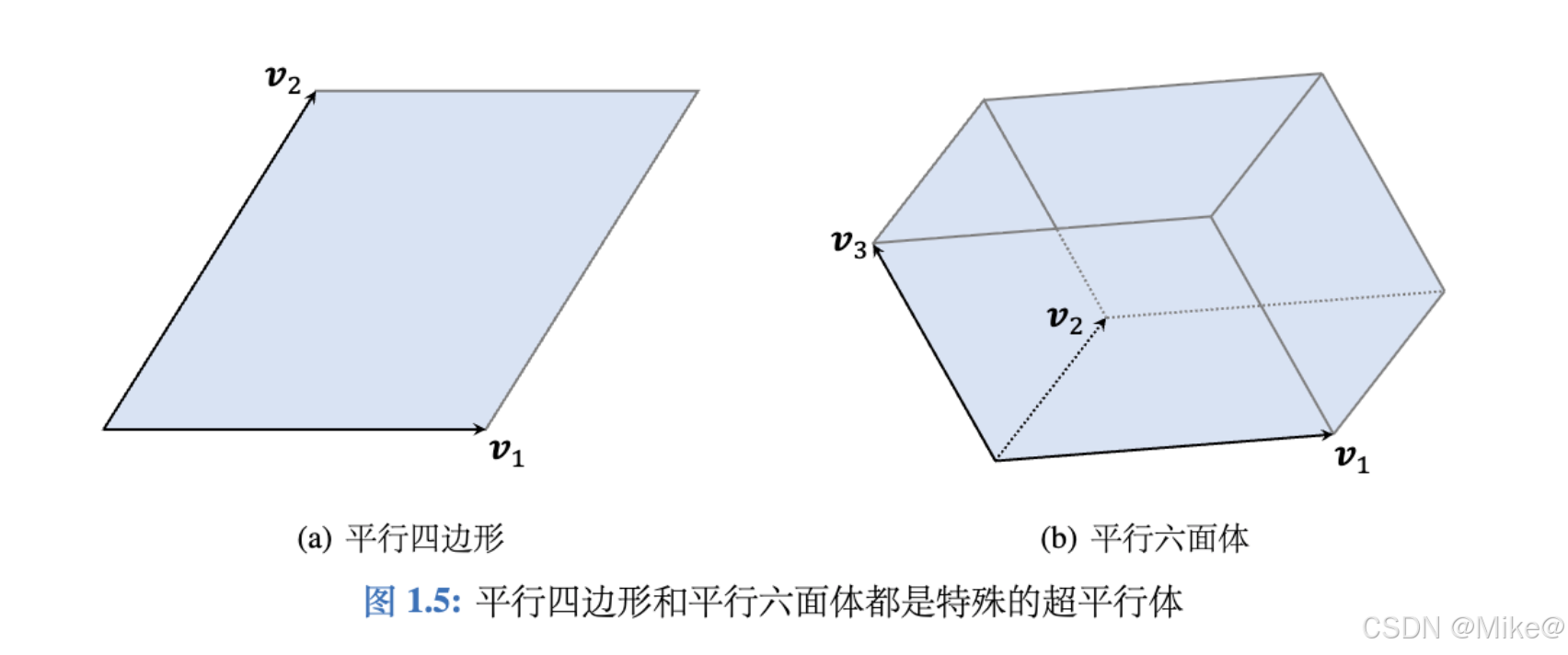
注意:仅当向量 v1,…,vk∈Rd\boldsymbol{v}_1, \dots, \boldsymbol{v}_k \in \mathbb{R}^dv1,…,vk∈Rd 线性无关时,超平行体才具有非零体积。若它们线性相关,则所有点将落在一个维度低于 kkk 的超平面中,此时超平行体的体积为零。
计算超平行体的体积
为计算超平行体的体积,需对向量进行正交化。以图1.6中的平行四边形为例,其面积等于底乘高。若以 v1\boldsymbol{v}_1v1 为底,则高为向量:
q2=v2−Projv1(v2),其中Projv1(v2)=⟨v1,v2⟩∥v1∥22v1.\boldsymbol{q}_2 = \boldsymbol{v}_2 - \text{Proj}_{\boldsymbol{v}_1}(\boldsymbol{v}_2), \quad \text{其中} \quad \text{Proj}_{\boldsymbol{v}_1}(\boldsymbol{v}_2) = \frac{\langle \boldsymbol{v}_1, \boldsymbol{v}_2 \rangle}{\|\boldsymbol{v}_1\|_2^2} \boldsymbol{v}_1. q2=v2−Projv1(v2),其中Projv1(v2)=∥v1∥22⟨v1,v2⟩v1.
可证明 v1\boldsymbol{v}_1v1 与 q2\boldsymbol{q}_2q2 正交(内积为零),因此平行四边形面积为:
vol(P)=∥v1∥2⋅∥q2∥2.\text{vol}(P) = \|\boldsymbol{v}_1\|_2 \cdot \|\boldsymbol{q}_2\|_2. vol(P)=∥v1∥2⋅∥q2∥2.
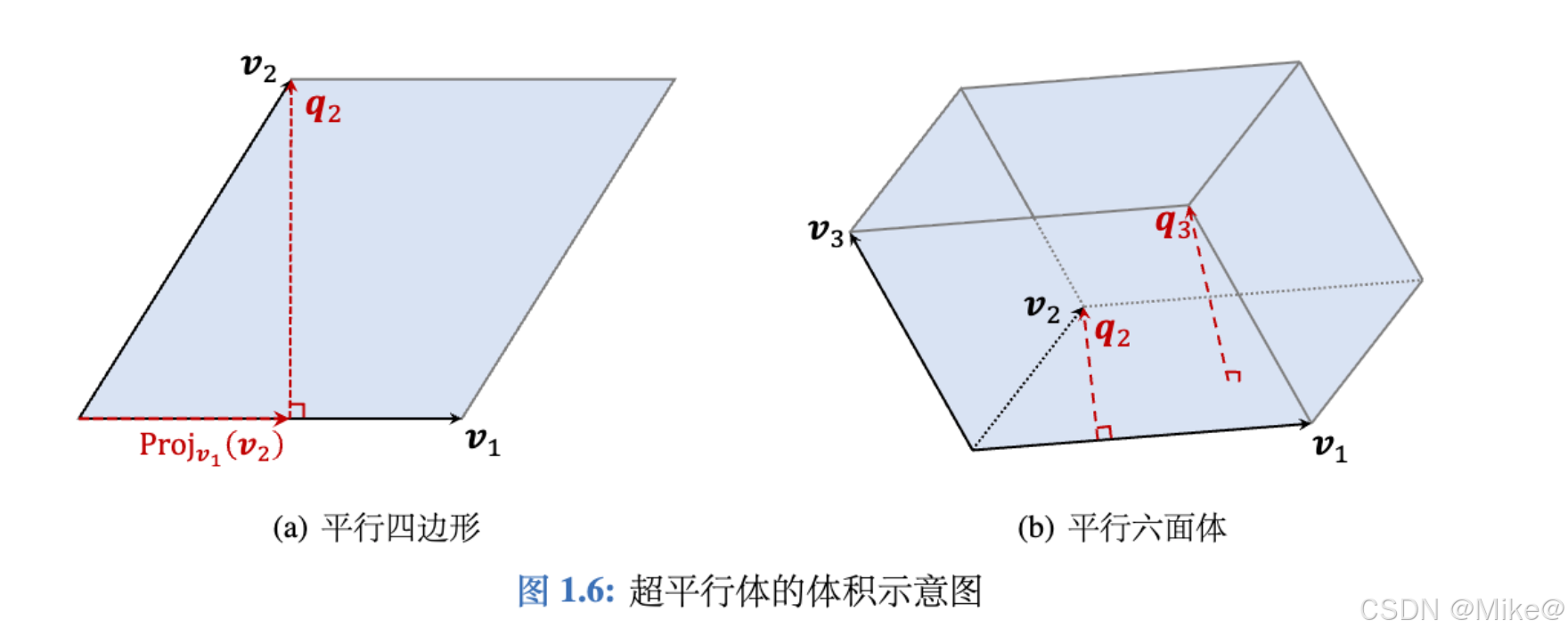
再以图1.6中的平行六面体为例,其体积等于底面积乘高。底面积为 ∥v1∥2⋅∥q2∥2\|\boldsymbol{v}_1\|_2 \cdot \|\boldsymbol{q}_2\|_2∥v1∥2⋅∥q2∥2,高为:
q3=v3−Projv1(v3)−Projq2(v3).\boldsymbol{q}_3 = \boldsymbol{v}_3 - \text{Proj}_{\boldsymbol{v}_1}(\boldsymbol{v}_3) - \text{Proj}_{\boldsymbol{q}_2}(\boldsymbol{v}_3). q3=v3−Projv1(v3)−Projq2(v3).
可证明 q3\boldsymbol{q}_3q3 与 v1\boldsymbol{v}_1v1 和 q2\boldsymbol{q}_2q2 均正交,因此平行六面体的体积为:
vol(P)=∥v1∥2⋅∥q2∥2⋅∥q3∥2.\text{vol}(P) = \|\boldsymbol{v}_1\|_2 \cdot \|\boldsymbol{q}_2\|_2 \cdot \|\boldsymbol{q}_3\|_2. vol(P)=∥v1∥2⋅∥q2∥2⋅∥q3∥2.
体积与行列式的关系
- 设 kkk 个物品被表征为单位向量 v1,…,vk∈Rd\boldsymbol{v}_1, \dots, \boldsymbol{v}_k \in \mathbb{R}^dv1,…,vk∈Rd(其中 d≥kd \geq kd≥k)。
- 使用超平行体的体积衡量物品的多样性,体积取值范围为 [0,1][0,1][0,1]。
- 若 v1,…,vk\boldsymbol{v}_1, \dots, \boldsymbol{v}_kv1,…,vk 两两正交(多样性好),则体积最大,vol(P)=1\text{vol}(P) = 1vol(P)=1。
- 若 v1,…,vk\boldsymbol{v}_1, \dots, \boldsymbol{v}_kv1,…,vk 线性相关(多样性差),则体积最小,vol(P)=0\text{vol}(P) = 0vol(P)=0。
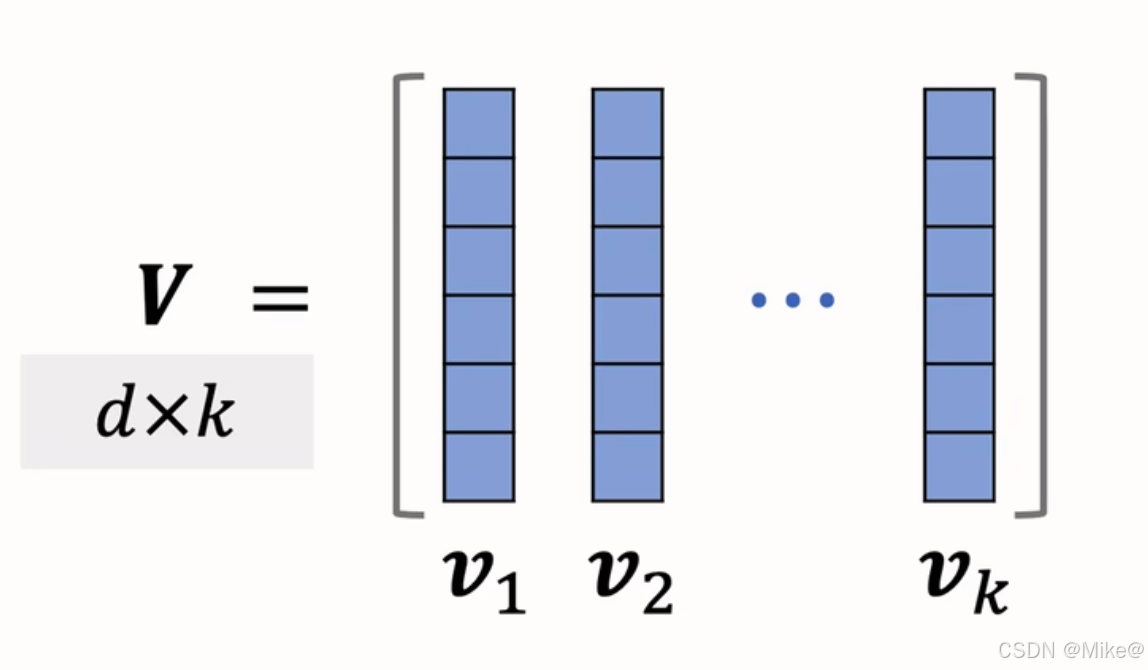
将这些向量作为列向量构成矩阵 V∈Rd×k\boldsymbol{V} \in \mathbb{R}^{d \times k}V∈Rd×k,当 d≥kd \geq kd≥k 时,行列式与体积满足如下关系:
det(VTV)=vol(P(v1,…,vk))2.\det(\boldsymbol{V}^T \boldsymbol{V}) = \text{vol}(P(\boldsymbol{v}_1, \dots, \boldsymbol{v}_k))^2. det(VTV)=vol(P(v1,…,vk))2.
因此,可使用行列式 det(VTV)\det(\boldsymbol{V}^T \boldsymbol{V})det(VTV) 来衡量向量集 {v1,…,vk}\{\boldsymbol{v}_1, \dots, \boldsymbol{v}_k\}{v1,…,vk} 的多样性。
DPP多样性算法(下)
在精排阶段,我们获得 nnn 个物品的奖励分数 reward1,…,rewardn\text{reward}_1, \dots, \text{reward}_nreward1,…,rewardn 和向量表征 v1,…,vn∈Rd\boldsymbol{v}_1, \dots, \boldsymbol{v}_n \in \mathbb{R}^dv1,…,vn∈Rd。目标是从中选出 kkk 个物品组成集合 SSS,使得:
- 价值最大化:集合中物品的奖励分之和 ∑j∈Srewardj\sum_{j \in S} \text{reward}_j∑j∈Srewardj 尽可能大;
- 多样性最大化:集合 SSS 中向量所构成的超平行体 P(S)P(S)P(S) 的体积尽可能大。
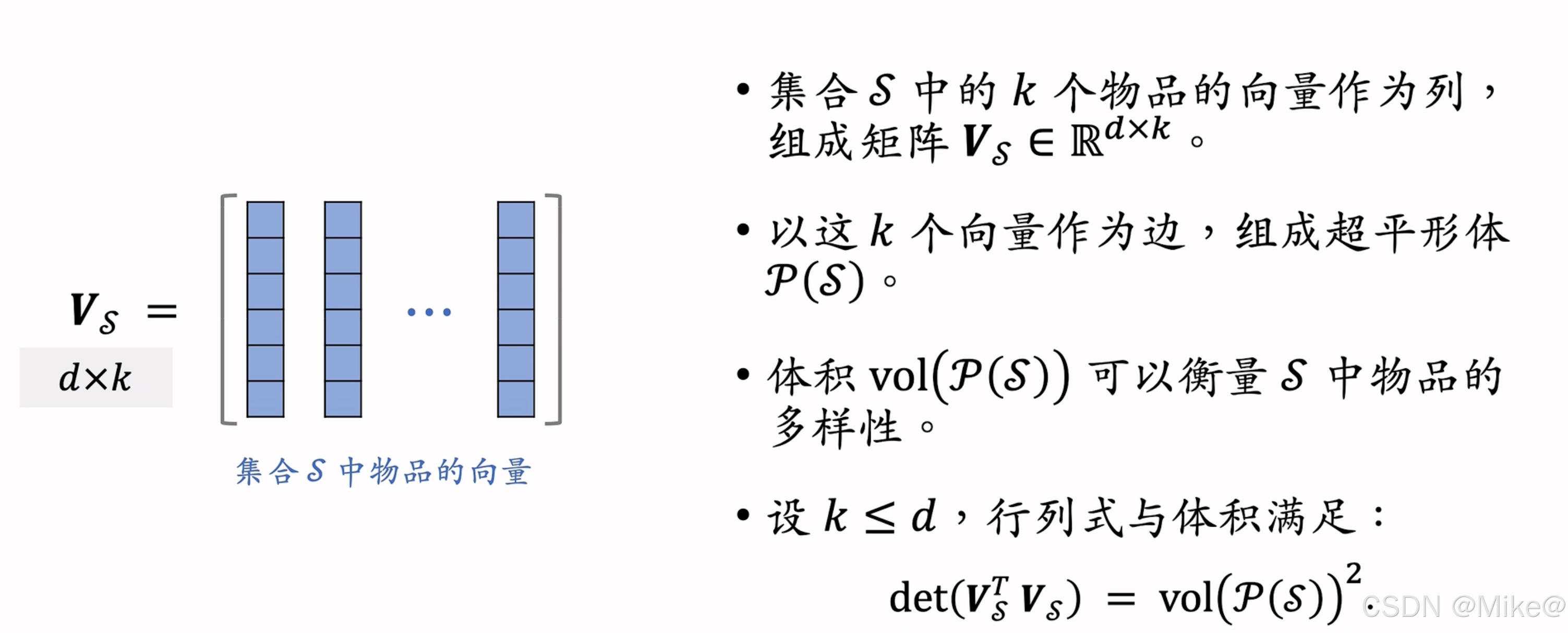
多样性度量
将集合 SSS 中的 kkk 个物品的向量作为列向量,构成矩阵 VS∈Rd×k\boldsymbol{V}_S \in \mathbb{R}^{d \times k}VS∈Rd×k,并以这些向量为边构成超平行体 P(S)P(S)P(S)。其体积 vol(P(S))\text{vol}(P(S))vol(P(S)) 可衡量 SSS 中物品的多样性。当 k≤dk \leq dk≤d 时,行列式与体积满足:
det(VSTVS)=vol(P(S))2.\det(\boldsymbol{V}_S^T \boldsymbol{V}_S) = \text{vol}(P(S))^2. det(VSTVS)=vol(P(S))2.
行列式点过程(DPP)
DPP是一种传统的统计机器学习方法,其基本形式为:
argmaxS:∣S∣=klogdet(VSTVS).\underset{S: |S| = k}{\text{argmax}} \log \det(\boldsymbol{V}_S^T \boldsymbol{V}_S). S:∣S∣=kargmaxlogdet(VSTVS).
Hulu的研究团队将DPP应用于推荐系统[1],提出了如下优化目标:
argmaxS:∣S∣=k{θ⋅(∑j∈Srewardj)+(1−θ)⋅logdet(VSTVS)}.\underset{S: |S| = k}{\text{argmax}} \left\{ \theta \cdot \left( \sum_{j \in S} \text{reward}_j \right) + (1 - \theta) \cdot \log \det(\boldsymbol{V}_S^T \boldsymbol{V}_S) \right\}. S:∣S∣=kargmax⎩⎨⎧θ⋅j∈S∑rewardj+(1−θ)⋅logdet(VSTVS)⎭⎬⎫.
文献来源:Chen et al. Fast Greedy MAP Inference for Determinantal Point Process to Improve Recommendation Diversity. In NeurIPS, 2018.
该论文的核心贡献在于提供了上述优化问题的高效求解算法。
矩阵表示与计算
定义矩阵 A∈Rn×n\boldsymbol{A} \in \mathbb{R}^{n \times n}A∈Rn×n,其元素为 aij=viTvja_{ij} = \boldsymbol{v}_i^T \boldsymbol{v}_jaij=viTvj。给定向量 v1,…,vn∈Rd\boldsymbol{v}_1, \dots, \boldsymbol{v}_n \in \mathbb{R}^dv1,…,vn∈Rd,计算 A\boldsymbol{A}A 的时间复杂度为 O(n2d)O(n^2 d)O(n2d)。
令 AS=VSTVS\boldsymbol{A}_S = \boldsymbol{V}_S^T \boldsymbol{V}_SAS=VSTVS,则 AS\boldsymbol{A}_SAS 是 A\boldsymbol{A}A 的一个 k×kk \times kk×k 子矩阵(其中行列索引属于 SSS)。推荐系统中的DPP问题可改写为:
argmaxS:∣S∣=k{θ⋅(∑j∈Srewardj)+(1−θ)⋅logdet(AS)}.\underset{S: |S| = k}{\text{argmax}} \left\{ \theta \cdot \left( \sum_{j \in S} \text{reward}_j \right) + (1 - \theta) \cdot \log \det(\boldsymbol{A}_S) \right\}. S:∣S∣=kargmax⎩⎨⎧θ⋅j∈S∑rewardj+(1−θ)⋅logdet(AS)⎭⎬⎫.
DPP是一个组合优化问题,需从 {1,…,n}\{1, \dots, n\}{1,…,n} 中选出大小为 kkk 的子集 SSS。该问题是NP难的,因此通常采用贪心算法进行近似求解。
贪心求解算法
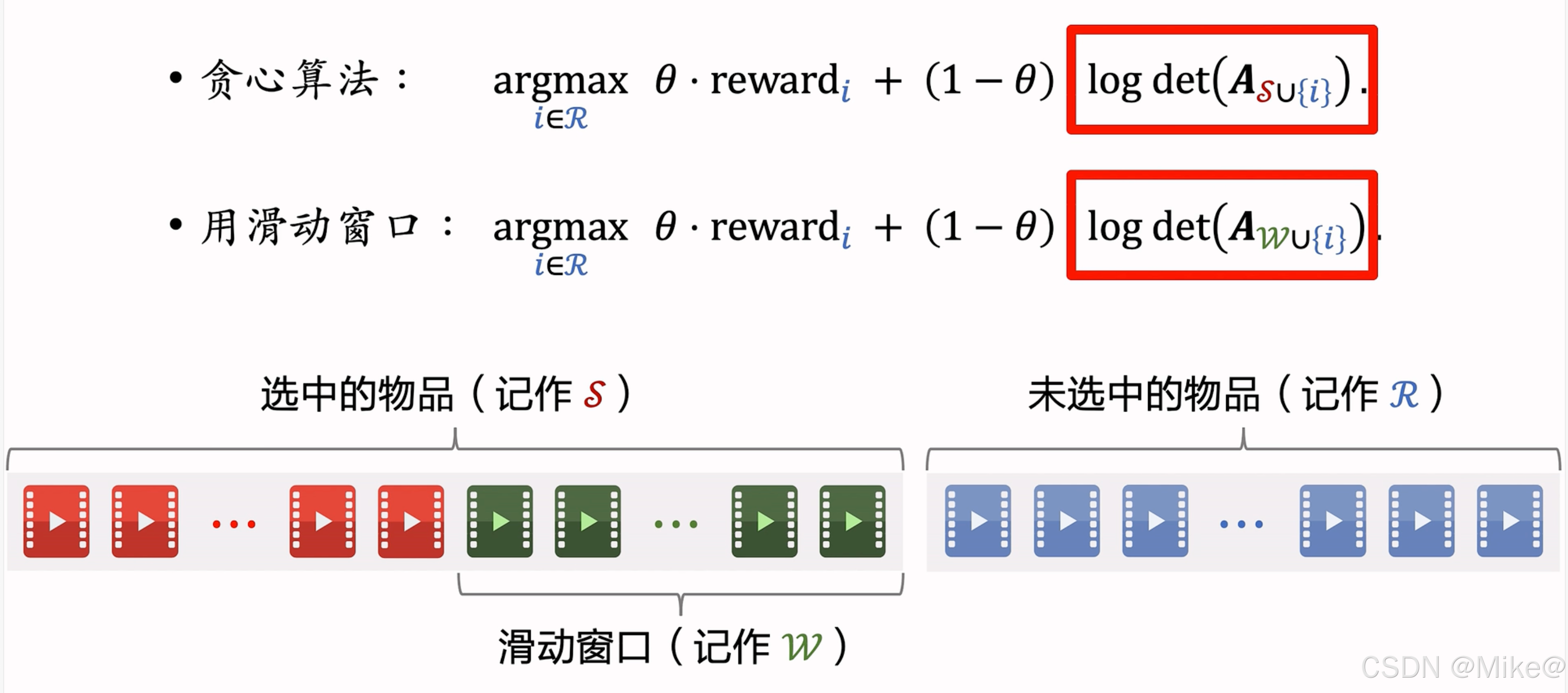
令 SSS 表示已选物品集合,RRR 表示未选物品集合。贪心算法在每轮迭代中求解:
argmaxi∈R{θ⋅rewardi+(1−θ)⋅logdet(AS∪{i})}.\underset{i \in R}{\text{argmax}} \left\{ \theta \cdot \text{reward}_i + (1 - \theta) \cdot \log \det(\boldsymbol{A}_{S \cup \{i\}}) \right\}. i∈Rargmax{θ⋅rewardi+(1−θ)⋅logdet(AS∪{i})}.
- 对单个 iii,计算 AS∪{i}\boldsymbol{A}_{S \cup \{i\}}AS∪{i} 的行列式需要 O(∣S∣3)O(|S|^3)O(∣S∣3) 时间(例如使用Cholesky分解或特征分解)。
- 对全部 i∈Ri \in Ri∈R,计算行列式需要 O(∣S∣3⋅∣R∣)O(|S|^3 \cdot |R|)O(∣S∣3⋅∣R∣) 时间。
- 需执行 kkk 轮迭代以选出 kkk 个物品,若暴力计算行列式,总时间复杂度为:
O(n2d+nk4).O(n^2 d + n k^4). O(n2d+nk4).
其中 O(n2d)O(n^2 d)O(n2d) 是计算矩阵 A\boldsymbol{A}A 的时间,O(nk4)O(n k^4)O(nk4) 是计算行列式的时间。
Hulu的快速算法
Hulu的论文设计了一种数值算法,将总时间复杂度降低至 O(n2d+nk2)O(n^2 d + n k^2)O(n2d+nk2):
- 计算矩阵 A\boldsymbol{A}A 仍需 O(n2d)O(n^2 d)O(n2d) 时间。
- 利用Cholesky分解高效计算行列式,仅需 O(nk2)O(n k^2)O(nk2) 时间。
Cholesky分解将 AS\boldsymbol{A}_SAS 分解为 LLT\boldsymbol{L} \boldsymbol{L}^TLLT,其中 L\boldsymbol{L}L 为下三角矩阵。则行列式可表示为:
det(AS)=det(L)2=∏ilii2.\det(\boldsymbol{A}_S) = \det(\boldsymbol{L})^2 = \prod_i l_{ii}^2. det(AS)=det(L)2=i∏lii2.
基本思路是:若已知 AS=LLT\boldsymbol{A}_S = \boldsymbol{L} \boldsymbol{L}^TAS=LLT,则可快速求出所有 AS∪{i}\boldsymbol{A}_{S \cup \{i\}}AS∪{i} 的Cholesky分解,从而快速计算其行列式。
算法流程
贪心算法求解:
argmaxi∈R{θ⋅rewardi+(1−θ)⋅logdet(AS∪{i})}.\underset{i \in R}{\text{argmax}} \left\{ \theta \cdot \text{reward}_i + (1 - \theta) \cdot \log \det(\boldsymbol{A}_{S \cup \{i\}}) \right\}. i∈Rargmax{θ⋅rewardi+(1−θ)⋅logdet(AS∪{i})}.
初始化时 SSS 仅包含一个物品,AS\boldsymbol{A}_SAS 为 1×11 \times 11×1 矩阵。在每轮循环中,基于上一轮计算的Cholesky分解 AS=LLT\boldsymbol{A}_S = \boldsymbol{L} \boldsymbol{L}^TAS=LLT,快速求出所有 AS∪{i}\boldsymbol{A}_{S \cup \{i\}}AS∪{i} 的Cholesky分解及行列式。
详细推导可参考:讲义链接
DPP的扩展
滑动窗口
随着集合 SSS 增大,其中相似物品增多,向量可能接近线性相关,导致行列式 det(AS)\det(\boldsymbol{A}_S)det(AS) 趋近于零,对数项趋于负无穷,从而降低DPP效果。解决方法之一是使用滑动窗口,仅考虑最近选中的物品:
argmaxi∈R{θ⋅rewardi+(1−θ)⋅logdet(AW∪{i})}.\underset{i \in R}{\text{argmax}} \left\{ \theta \cdot \text{reward}_i + (1 - \theta) \cdot \log \det(\boldsymbol{A}_{W \cup \{i\}}) \right\}. i∈Rargmax{θ⋅rewardi+(1−θ)⋅logdet(AW∪{i})}.
其中 WWW 是滑动窗口中的物品集合。
规则约束
贪心算法每轮从 RRR 中选出一个物品:
argmaxi∈R{θ⋅rewardi+(1−θ)⋅logdet(AW∪{i})}.\underset{i \in R}{\text{argmax}} \left\{ \theta \cdot \text{reward}_i + (1 - \theta) \cdot \log \det(\boldsymbol{A}_{W \cup \{i\}}) \right\}. i∈Rargmax{θ⋅rewardi+(1−θ)⋅logdet(AW∪{i})}.
可引入规则约束(如最多连续出现5篇视频笔记后必须插入图文笔记),将 RRR 限制为符合规则的子集 R′R'R′,然后求解:
argmaxi∈R′{θ⋅rewardi+(1−θ)⋅logdet(AW∪{i})}.\underset{i \in R'}{\text{argmax}} \left\{ \theta \cdot \text{reward}_i + (1 - \theta) \cdot \log \det(\boldsymbol{A}_{W \cup \{i\}}) \right\}. i∈R′argmax{θ⋅rewardi+(1−θ)⋅logdet(AW∪{i})}.

Reference
王树森 bilibili推荐系统