pandas在AI中与其他库的协作
在AI和数据科学领域,pandas很少单独使用。它通常是数据预处理的核心,然后与其他专门化的库配合,构建起完整的工作流。以下是几个与pandas配合最紧密的核心库及其协作方式。
核心协作库概览
这些库围绕pandas,构成了Python数据科学生态系统的中坚力量:
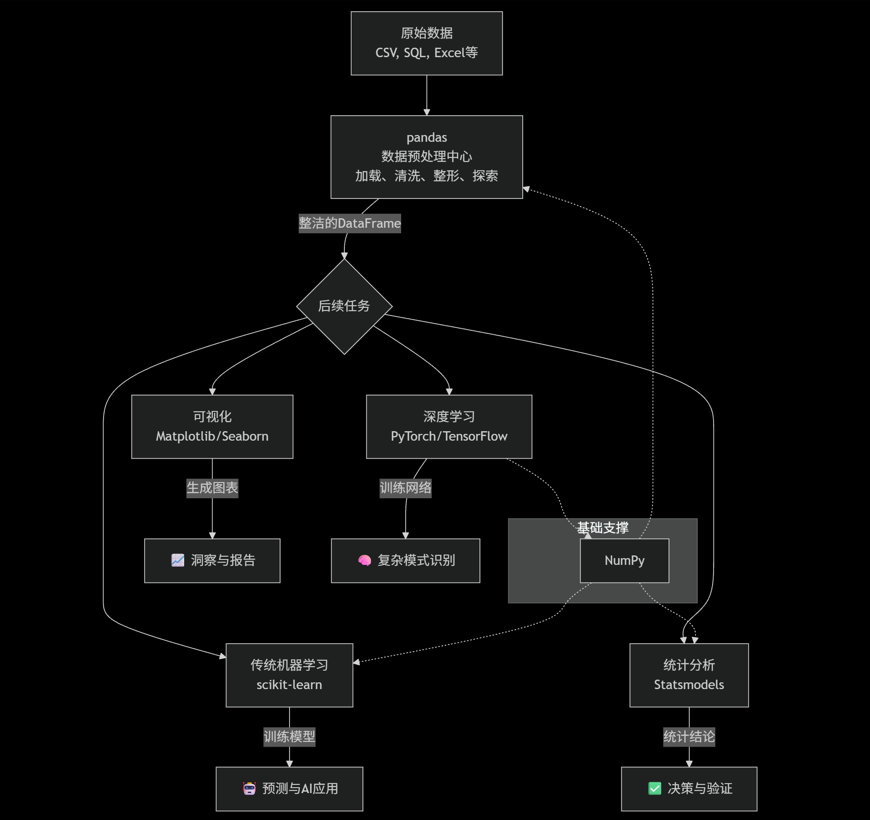
各库详细说明与配合方式
1. NumPy & SciPy (数值计算基础)
用途:NumPy 提供高性能的多维数组对象和数学函数,是几乎所有数值计算库的基础。SciPy 基于 NumPy,提供更高级的科学计算功能(如优化、积分、线性代数)。
与pandas的配合:
底层依赖:pandas 的
DataFrame和Series在内部大量使用 NumPy 数组进行存储和计算。数据转换:
import pandas as pd import numpy as np# pandas DataFrame 转换为 NumPy 数组(用于输入其他库) df = pd.DataFrame({'a': [1,2,3], 'b': [4,5,6]}) numpy_array = df.values # 或 `df.to_numpy()` print(type(numpy_array)) # <class 'numpy.ndarray'># NumPy 数组转换为 pandas DataFrame(用于数据整理和展示) new_array = np.random.randn(5, 3) new_df = pd.DataFrame(new_array, columns=['X', 'Y', 'Z'])函数协作:直接在 pandas Series 上使用 NumPy 函数。
df['a_squared'] = np.square(df['a']) # 对列应用NumPy的平方函数
2. scikit-learn (传统机器学习)
用途:Python中最著名的传统机器学习库,提供了从数据预处理、特征选择、模型训练到评估的完整工具链,支持分类、回归、聚类等算法。
与pandas的配合(这是最经典的流程):
pandas进行数据加载与清洗:读取原始数据、处理缺失值、编码分类变量(如将“男/女”转换为0/1)。
pandas/NumPy进行特征和目标分离:将DataFrame拆分为特征矩阵
X和目标变量y。scikit-learn进行模型训练:将
X和y输入到model.fit()中。pandas进行结果分析:将预测结果
y_pred添加回DataFrame,用于分析。
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.preprocessing import LabelEncoder# 1. 用pandas加载数据 data = pd.read_csv('titanic.csv')# 2. 用pandas进行数据清洗和特征工程 data['Age'].fillna(data['Age'].median(), inplace=True) # 填充缺失值# 3. 使用scikit-learn的预处理工具(也可用pandas的get_dummies) le = LabelEncoder() data['Sex_encoded'] = le.fit_transform(data['Sex']) # 性别编码# 4. 准备特征X和目标y(最终转换为NumPy数组) features = ['Pclass', 'Sex_encoded', 'Age', 'SibSp'] X = data[features] # pandas DataFrame y = data['Survived'] # pandas Series# 5. 划分数据集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)# 6. 训练模型(scikit-learn接手) model = RandomForestClassifier() model.fit(X_train, y_train) # 内部使用NumPy数组进行计算# 7. 预测并将结果放回pandas DataFrame进行分析 y_pred = model.predict(X_test) test_results = X_test.copy() # 创建一个测试集的DataFrame副本 test_results['Actual'] = y_test test_results['Predicted'] = y_pred test_results['Correct'] = test_results['Actual'] == test_results['Predicted'] print(test_results.head()) # 用pandas方便地查看和分析预测结果
3. PyTorch / TensorFlow (深度学习)
用途:用于构建和训练深度学习模型(如神经网络),处理图像、文本、语音等复杂数据。
与pandas的配合:
pandas进行表格数据预处理:对于结构化数据(CSV表格),依然用pandas进行初始的加载、清洗和特征工程。
转换为张量(Tensor):将处理好的pandas DataFrame或NumPy数组转换为PyTorch或TensorFlow所需的张量格式。
深度学习库进行训练:张量被送入模型进行训练。
转换回pandas进行解释:将训练结果(如预测值、损失曲线)转换回pandas格式,便于分析和可视化。
import pandas as pd import torch import numpy as np# 1. pandas 读取和预处理 data = pd.read_csv('sales_data.csv') X = data[['feature1', 'feature2']].values # 转换为NumPy数组 y = data['target'].values# 2. 转换为PyTorch张量 X_tensor = torch.from_numpy(X.astype(np.float32)) y_tensor = torch.from_numpy(y.astype(np.float32))# 3. ... 构建模型、训练循环等(由PyTorch完成) ...# 4. 预测后,转换回pandas进行分析 with torch.no_grad():predictions = model(X_tensor).numpy() # 张量转NumPyresults_df = data.copy() results_df['NN_Prediction'] = predictions print(results_df.corr()) # 用pandas计算预测值与真实值的相关性
4. Matplotlib / Seaborn (数据可视化)
用途:Matplotlib是基础的绘图库,Seaborn是基于它的高级接口,提供更美观、更简单的统计图表绘制。
与pandas的配合:无缝衔接。pandas DataFrame 和 Series 对象可以直接作为数据源传入绘图函数。
import pandas as pd import matplotlib.pyplot as plt import seaborn as snsdf = pd.read_csv('iris.csv')# 直接使用pandas绘图(底层是matplotlib) df['sepal_length'].plot(kind='hist') # 绘制一列的直方图 df.plot(kind='scatter', x='sepal_length', y='sepal_width') # 散点图# 使用Seaborn绘图,数据参数直接传入DataFrame sns.boxplot(data=df, x='species', y='sepal_length') # 按物种分组绘制萼片长度的箱线图 sns.pairplot(data=df, hue='species') # 直接绘制整个DataFrame的成对关系图plt.show()
5. Statsmodels (统计分析)
用途:专注于执行经典的统计测试和探索性数据分析,如线性回归、时间序列分析(ARIMA)、假设检验等。它比scikit-learn提供更详细的统计推断信息。
与pandas的配合:与scikit-learn类似,接受DataFrame作为输入,并输出包含详细统计结果(p值、置信区间等)的对象,这些结果可以方便地提取到DataFrame中。
import pandas as pd import statsmodels.api as sm# 准备数据 data = pd.read_csv('economic_data.csv') X = data[['GDP', 'Inflation']] y = data['Unemployment']# 添加常数项(截距) X = sm.add_constant(X)# 拟合OLS模型 model = sm.OLS(y, X).fit()# 获取详细的总结报告(包含在一个可读的表格中) print(model.summary())# 将预测结果添加到原始DataFrame data['Predicted_Unemployment'] = model.predict(X)
总结:典型的AI工作流
一个典型的AI项目流程清晰地展示了这些库是如何协做的:
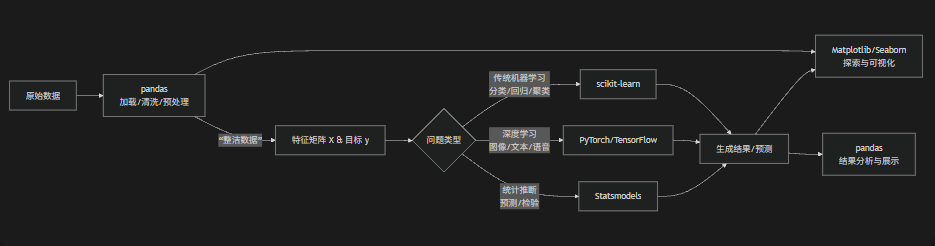
在这个工作流中,pandas 始终是数据处理的起点和中心,负责将原始数据整理成“整洁数据”(Tidy Data),为下游的各个专业库提供标准化的输入。处理结果最终又常常会回到 pandas 的 DataFrame 中,利用其强大的数据操作能力进行后续分析和展示。