(论文速读)KL-CLIP:零采样异常分割的K均值学习模型
论文题目:KL‑CLIP: a K‑means learning model for zero‑shot anomaly segmentation(用于零采样异常分割的K均值学习模型)
期刊:Multimedia Systems(CCF-C/ # if = 3.1)
摘要:最近,大规模的视觉语言模型,如CLIP,在零样本学习异常分割(ZSAS)任务中显示出了巨大的潜力。这些模型可以通过整合图像和文本特征来检测未见产品中的异常情况。然而,在具有高度重复纹理的地条钢等实际场景中,现有方法主要强调全局特征匹配。它们常常难以有效地捕获微小或微妙的异常,并且面临着文本线索与缺陷特征混淆的挑战,特别是考虑到带钢表面的各种缺陷类别。为了解决这些挑战,我们提出了基于CLIP的ZSAS任务K-means学习模型(KL-CLIP)。KL-CLIP将特征加权合并到CLIP中,并使用激活函数、注意机制和修改的损失函数来优化模型。我们提出了KM模块,该模块通过聚类特征来调整CLIP,生成加权因子,并有效地解决带钢表面的各种缺陷类别。在带钢缺陷数据集(FSSD-12)和其他工业缺陷数据集上进行的大量实验表明,KL-CLIP优于现有的ZSAS方法,并且在各种工业应用中具有更好的泛化性。在FSSD-12数据集上,KL-CLIP实现了1.5%的AP改进,1%的PRO改进和0.9%的像素级AUROC改进。
引言
在工业质量检测领域,异常检测和分割技术一直是核心挑战之一。传统方法往往需要大量标注数据和针对性训练,这在实际工业应用中既成本高昂又时间冗长。近年来,零样本异常分割(Zero-Shot Anomaly Segmentation, ZSAS)技术的兴起为这一问题提供了新的解决思路。
背景与挑战
零样本异常分割的重要性
零样本异常分割技术能够在不需要预先设计训练数据集的情况下,准确定位和分割新类别物品中的异常区域。这项技术在工业视觉检测中具有极高价值,因为它能够在不泄露数据隐私的前提下检测新产品中的异常。
现有方法的局限性
尽管CLIP等大规模视觉-语言模型在零样本任务中表现出色,但在实际工业场景中仍面临显著挑战:
全局特征匹配的局限:现有方法主要依赖全局特征匹配,在处理具有高度重复纹理的材料(如钢带)时效果有限
细微异常检测困难:难以有效捕获小型或细微的表面缺陷
文本-视觉特征混淆:文本描述容易与多样化的缺陷特征产生混淆,影响检测精度
KL-CLIP:创新的解决方案
整体架构设计
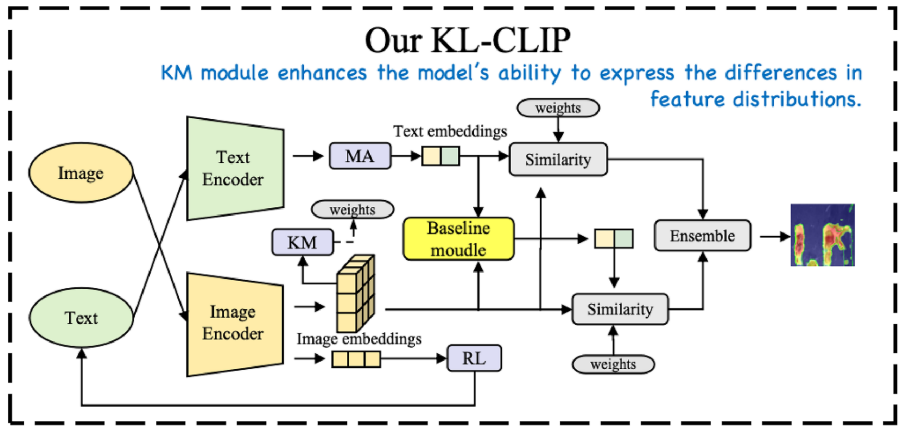
KL-CLIP模型基于CLIP框架构建,包含以下核心模块:
- RL模块:增强特征表达能力
- KM模块:基于聚类的特征加权
- MA模块:改进文本特征表示
- Post-VCP模块:后处理优化
核心创新技术
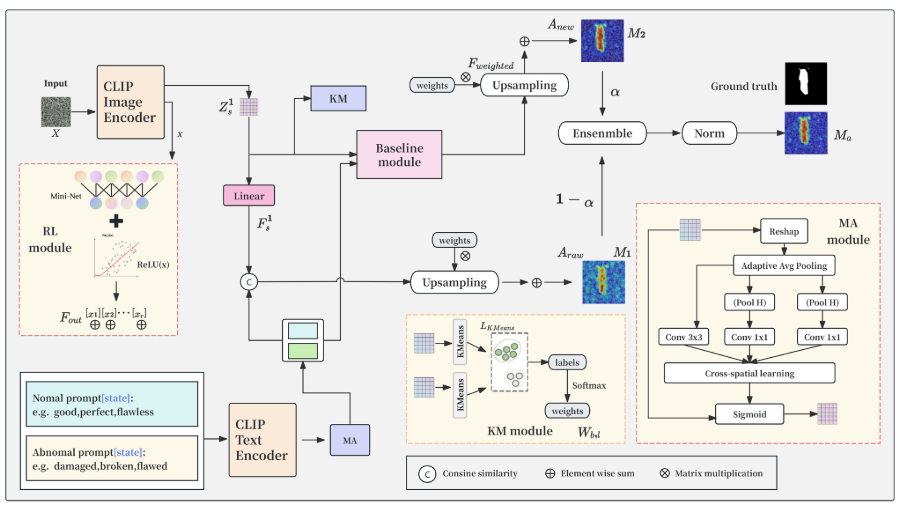
1. KM模块:聚类驱动的特征加权
KM模块是本论文的核心创新,它通过以下方式工作:
聚类分析:对图像特征矩阵进行无监督K-means聚类,生成k个聚类中心并为每个特征点分配权重。
自适应原型:将聚类中心视为自适应特征原型,基于像素级表示与聚类中心的相似性进行加权。
异常突出:正常特征通常形成密集且结构化的聚类,而异常往往表现为离群点或稀疏模式,通过聚类引导的重新加权能够更好地分离细微或重叠的异常。
2. RL模块:非线性特征增强
原始Pre-VCP模块仅使用线性变换处理全局特征,限制了对复杂非线性关系的建模能力。RL模块通过集成ReLU激活函数:
Fout = σ(Conv1D(F))
其中 σ(x) = max(0, x)
这种改进显著增强了模块建模稀疏和非线性特征关系的能力,特别是在钢带表面缺陷检测中,能够更准确地区分背景和缺陷区域的细微差异。
3. MA模块:多尺度注意力机制
MA模块基于EMA注意力机制,采用通道分组策略保留丰富的特征信息,并使用并行多分支卷积捕获细粒度和广泛的上下文线索。通过自适应加权机制,该模块能够:
- 丰富上下文信息
- 增强文本特征的表达能力
- 提高检测精度和可靠性
4. 损失函数优化:Tversky Loss
传统的Dice Loss对假阳性(FP)和假阴性(FN)预测给予相等权重,这在高度不平衡的数据集中往往导致精度较高但召回率降低。
KL-CLIP采用Tversky Loss,通过调整α和β参数(默认α=0.7, β=0.3)来平衡FP和FN的权重,从而:
- 减少漏检情况
- 提高像素级检测精度
- 更好地处理边界和小型异常
实验结果与性能表现
钢带表面缺陷检测

在FSSD-12数据集上的实验结果显示,KL-CLIP相比baseline VCP-CLIP取得了显著改进:
像素级性能:
- AUROC:91.7% (+0.9%)
- PRO:80.4% (+1.0%)
- AP:63.0% (+1.5%)
图像级性能:

- AUROC:97.9% (+1.3%)
- AP:99.5% (+0.4%)
- max-F1:99.0% (+0.6%)
跨领域泛化能力
KL-CLIP在多个工业缺陷数据集上均达到了最先进性能:
| 数据集 | AUROC | PRO | AP |
|---|---|---|---|
| MVTec-AD | 92.2% | 87.3% | 49.0% |
| VisA | 96.8% | 90.9% | 30.9% |
| BSD | 99.5% | 87.8% | 71.4% |
| RSDD | 99.6% | 97.9% | 45.3% |
| DAGM | 99.5% | 98.5% | 52.3% |
统计显著性验证
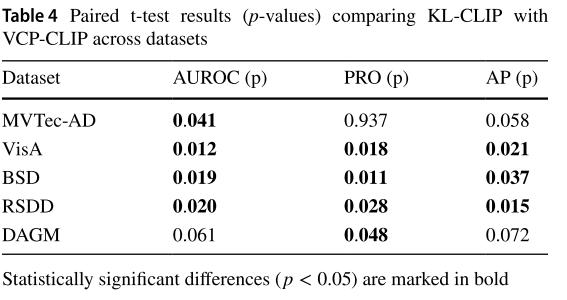
研究团队通过配对t检验验证了改进的统计显著性,大多数p值低于0.05阈值,证明了KL-CLIP的性能提升不仅一致,而且在统计学上可靠。
消融实验深度分析
KM模块的关键作用
消融实验显示,KM模块对性能提升起到关键作用:
- 在FSSD-12数据集上,像素级AUROC从90.2%提升至91.7%
- 通过聚类标签识别异常,能够更好地检测细微缺陷
各组件协同效应
当所有组件同时使用时,KL-CLIP达到最优性能:
- 移除Tversky Loss会导致像素级AUROC下降0.3%
- 各模块的协同作用确保了整体性能的最大化
聚类数量的鲁棒性
实验表明,KL-CLIP对聚类数量的选择具有鲁棒性,默认值nclusters=10在聚类粒度和稳定性之间提供了良好的平衡。