【AI论文】SAIL-VL2技术报告
摘要:我们推出SAIL-VL2——一款面向全面多模态理解与推理的开源视觉语言基础模型(LVM)。作为SAIL-VL的升级版,SAIL-VL2在20亿(2B)和80亿(8B)参数规模下,于各类图像和视频基准测试中均取得了最优性能,展现出从细粒度感知到复杂推理的强大能力。其卓越表现得益于三大核心创新:
首先,我们构建了大规模数据整理流水线,通过评分与筛选策略,全面提升了图像描述、光学字符识别(OCR)、问答及视频数据的质量与分布多样性,进而提高了训练效率。
其次,我们采用渐进式训练框架:从强大的预训练视觉编码器(SAIL-ViT)起步,经多模态预训练逐步推进,最终形成“思考-融合”策略下的监督微调-强化学习(SFT-RL)混合范式,系统性地强化了模型能力。
最后,我们在模型架构上实现突破,不仅采用稠密大语言模型(LLM),还拓展至高效的稀疏专家混合(Mixture-of-Experts,MoE)设计。
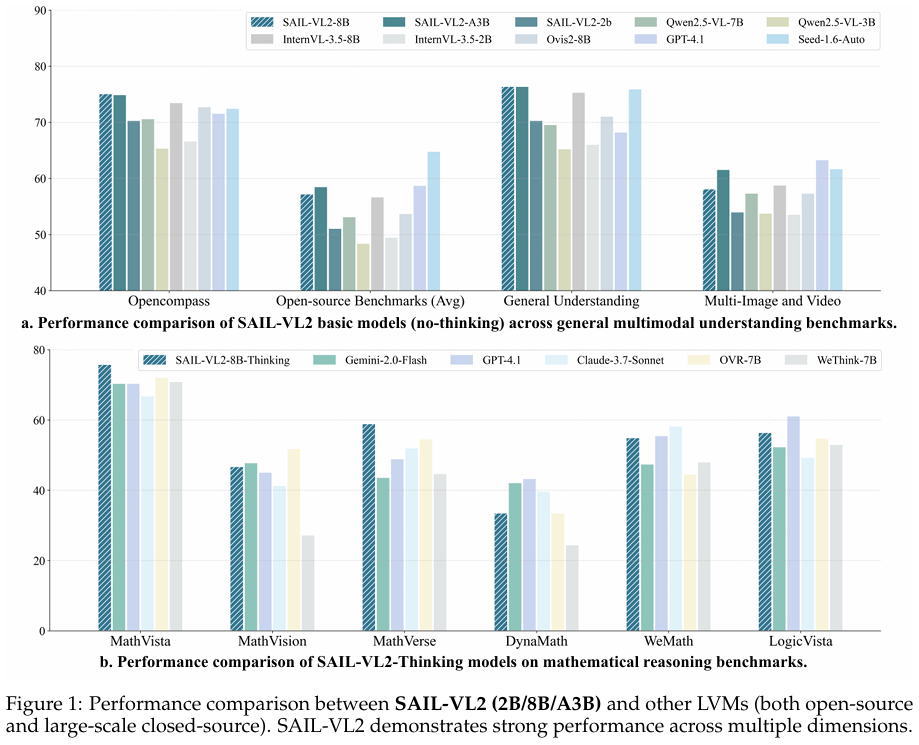
凭借上述贡献,SAIL-VL2在106个数据集上展现出强劲竞争力,并在MMMU和MathVista等高难度推理基准测试中取得最优结果。此外,在OpenCompass排行榜上,SAIL-VL2-2B在40亿参数规模以下的官方开源模型中位居榜首,同时为开源多模态社区提供了高效且可扩展的基础模型。
Huggingface链接:Paper page,论文链接:2509.14033
研究背景和目的
研究背景:
随着人工智能技术的飞速发展,大规模视觉语言模型(Large Vision-Language Models, LVMs)在连接视觉与语言模态方面展现出巨大潜力。这些模型通过将视觉表示与语言描述整合到一个共享的语义空间中,模仿了人类与世界交互的方式,推动了多模态理解和推理的进步。近年来,随着大型语言模型(LLMs)和视觉表示技术的不断突破,LVMs已经从早期的粗粒度视觉理解迈向了细粒度多模态推理的新阶段。
然而,当前LVMs的发展路径主要依赖于扩大模型参数和训练数据规模,这一策略虽然显著提升了模型性能,但也带来了计算资源需求、训练成本及部署成本的急剧增加。例如,一些领先的LVMs动辄拥有数十亿甚至上百亿的参数,需要庞大的计算集群和长时间训练,这限制了它们在资源有限环境下的应用。因此,如何在保持模型性能的同时,降低计算需求和训练成本,成为LVMs研究领域的重要课题。
研究目的:
本研究旨在通过创新数据管理、渐进式训练框架和架构设计,开发出一种高效且强大的LVM——SAIL-VL2。具体目标包括:
- 提升模型效率:通过引入稀疏的Mixture-of-Experts(MoE)设计和优化训练策略,减少模型在推理过程中的计算量,提高计算效率。
- 增强多模态理解与推理能力:通过设计全面的数据评分和过滤管道,以及采用渐进式训练框架,提升模型在细粒度感知和复杂推理任务上的表现。
- 推动开源多模态社区发展:通过发布完整的SAIL-VL2模型套件及其推理代码,为开源多模态社区提供一个高效且可扩展的基础模型,促进相关领域的研究和应用。
研究方法
1. 数据管理:
- 大规模数据整理管道:设计了全面的数据评分和过滤管道,涵盖从字幕、OCR、问答到视频数据的全光谱多模态输入。通过质量评分和过滤策略,提高了训练数据的质量和多样性,从而提升了训练效率。
- SAIL-Caption2升级:在原有SAIL-Caption数据集的基础上进行升级,引入了自动字幕质量评估和过滤机制,使用强大的LVM API进行初步筛选,并训练了两个判断模型(Score Judge和Yes-or-No Judge)来进一步提高数据质量。此外,还收集了大规模的图表字幕数据,增强了模型对图表和表格的理解能力。
2. 渐进式训练框架:
- 三阶段训练策略:提出了一个三阶段的渐进式训练策略,包括预热适应阶段、细粒度对齐阶段和世界知识注入阶段。每个阶段都通过注入不同粒度的知识并利用相应的训练数据,逐步将视觉编码器与LLM的表示空间对齐。
- 基础多模态预训练:在预训练阶段,使用预训练的SAIL-ViT视觉编码器和语言预训练的LLM,训练一个随机初始化的MLP适配器,以弥合视觉和语言模态之间的差距。
- 多任务预训练:在基础预训练之后,进行多任务预训练,以全面增强SAIL-VL2的视觉理解和指令跟随能力。此阶段联合优化所有模型参数,并整合了指令调优数据集,以增强模型的视觉指令跟随能力和语言能力。
3. 架构设计:
- 稀疏Mixture-of-Experts(MoE)设计:采用了稀疏的MoE架构,通过用并行专家模块替换标准的MLP层,实现了参数规模的扩展同时保持了计算效率。通过平衡专家激活和分布感知调优策略,确保了训练的稳定性和可扩展性。
- 高效视觉编码器:基于Vision Transformer(ViT)架构,设计了SAIL-ViT视觉编码器,通过渐进式训练管道逐步将视觉特征与LLM的表示空间对齐。同时,支持任意分辨率的输入,提高了模型的灵活性和适应性。
研究结果
1. 模型性能:
- SAIL-VL2在2B和8B参数规模下,在106个数据集上实现了最先进的性能,特别是在MMMU和Math-Vista等具有挑战性的推理基准测试中表现突出。
- 在OpenCompass排行榜上,SAIL-VL2-2B在4B参数规模以下的官方发布开源模型中排名第一,展示了其作为高效且强大LVM的竞争力。
2. 细粒度感知能力:
- SAIL-VL2在OCR、高分辨率文档布局分析和复杂图表解释等任务中表现出色,实现了超越同类规模模型的详细视觉定位。
3. 复杂推理能力:
- 通过开发SAIL-VL2-Thinking变体,采用先进的Chain-of-Thought(CoT)和强化学习策略,显著提升了模型在复杂推理任务上的性能,往往能够匹配或超越参数规模更大的模型。
研究局限
1. 数据依赖:
- 尽管SAIL-VL2在数据管理和质量提升方面进行了创新,但仍依赖于大规模的多模态数据进行训练。未来研究可探索更少依赖大规模标注数据的方法,如自监督学习或弱监督学习,以进一步降低数据依赖。
2. 计算资源需求:
- 尽管采用了稀疏MoE设计,但在处理高分辨率图像和复杂视频时,计算资源需求仍然较高。未来可研究更高效的注意力机制或量化技术,以减少推理过程中的计算量。
3. 域适应性和泛化能力:
- 当前研究主要关注英语和中文数据集,未来可探索跨语言或多语言数据集,以增强模型对不同文化和背景的理解能力。同时,可研究如何提升模型在低资源环境下的性能,如模型剪枝、知识蒸馏等,以扩大其应用范围。
未来研究方向
1. 跨模态和跨语言多模态理解:
- 当前研究主要关注英语和中文数据集,未来可探索跨语言或多语言数据集,以增强模型对不同文化和背景的理解能力。。
2. 多模态交互:
- 未来可研究视频、音频等多模态数据的融合,以实现更丰富的多模态应用场景。同时,可探索多模态交互中的情感理解和共情分析,以提升用户体验。
3. 强化自监督督学习:
- 开发自监督学习算法,减少对大规模标注数据的依赖,提高模型训练效率。同时,可研究如何结合弱监督学习和强化学习,以进一步提升模型性能。
4. 持续优化数据质量和多样性:
- 构建更全面的数据评分和过滤机制,确保数据的有效性和多样性,从而提升模型在多模态任务上的泛化能力。
5. 探索新的应用场景:
- 除了传统的图像和视频理解外,未来可探索更多应用场景,如医疗、教育、工业检测等,以验证模型的泛化能力和鲁棒性。