【论文阅读 | AAAI 2025 | Mamba YOLO: 基于状态空间模型的目标检测简单基线】
论文阅读 | AAAI 2025 | Mamba YOLO: 基于状态空间模型的目标检测简单基线
- 1&&2. 摘要&&引言
- 3. 方法
- 3.1整体架构
- 3.2ODSSBlock
- 4.实验
- 5.结论

题目:Mamba YOLO: A Simple Baseline for Object Detection with State Space Model
期刊:AAAI(AAAI Conference on Artificial Intelligence)
论文:paper
代码:code
年份:2025
1&&2. 摘要&&引言
在深度学习技术的快速发展推动下,YOLO系列为实时目标检测器设立了新基准。此外,基于Transformer的结构已成为该领域最强大的解决方案,极大地扩展了模型的感受野并实现了显著的性能提升。
然而,这种改进是有代价的,因为自注意力机制的二次复杂度增加了模型的计算负担。
为了解决这个问题,我们引入了一种简单而有效的基线方法,称为Mamba YOLO。我们的贡献如下:
- 我们提出ODMamba主干网络引入具有线性复杂度的状态空间模型(SSM)来解决自注意力的二次复杂度问题。与其他基于Transformer和基于SSM的方法不同,ODMamba无需预训练,易于训练。
- 针对实时性要求,我们设计了ODMamba的宏观结构,确定了最佳阶段比例和缩放尺寸。+
- 我们设计了RG Block,它采用多分支结构对通道维度进行建模,解决了SSM在序列建模中可能存在的局限性,如感受野不足和图像定位能力弱。该设计更准确、更显著地捕获局部图像依赖关系。
本文的主要贡献可总结如下:
● 我们提出的基于SSM的Mamba YOLO具有简单高效的结构,具有线性内存复杂度,并且不需要在大规模数据集上进行预训练,为YOLO在目标检测中建立了新的基线。
● 我们提出了ODSSBlock来弥补SSM的局部建模能力。通过重新思考MLP层的设计,我们结合门控聚合思想与有效卷积和残差连接,引入了RG Block,有效捕获局部依赖关系并增强了模型鲁棒性。
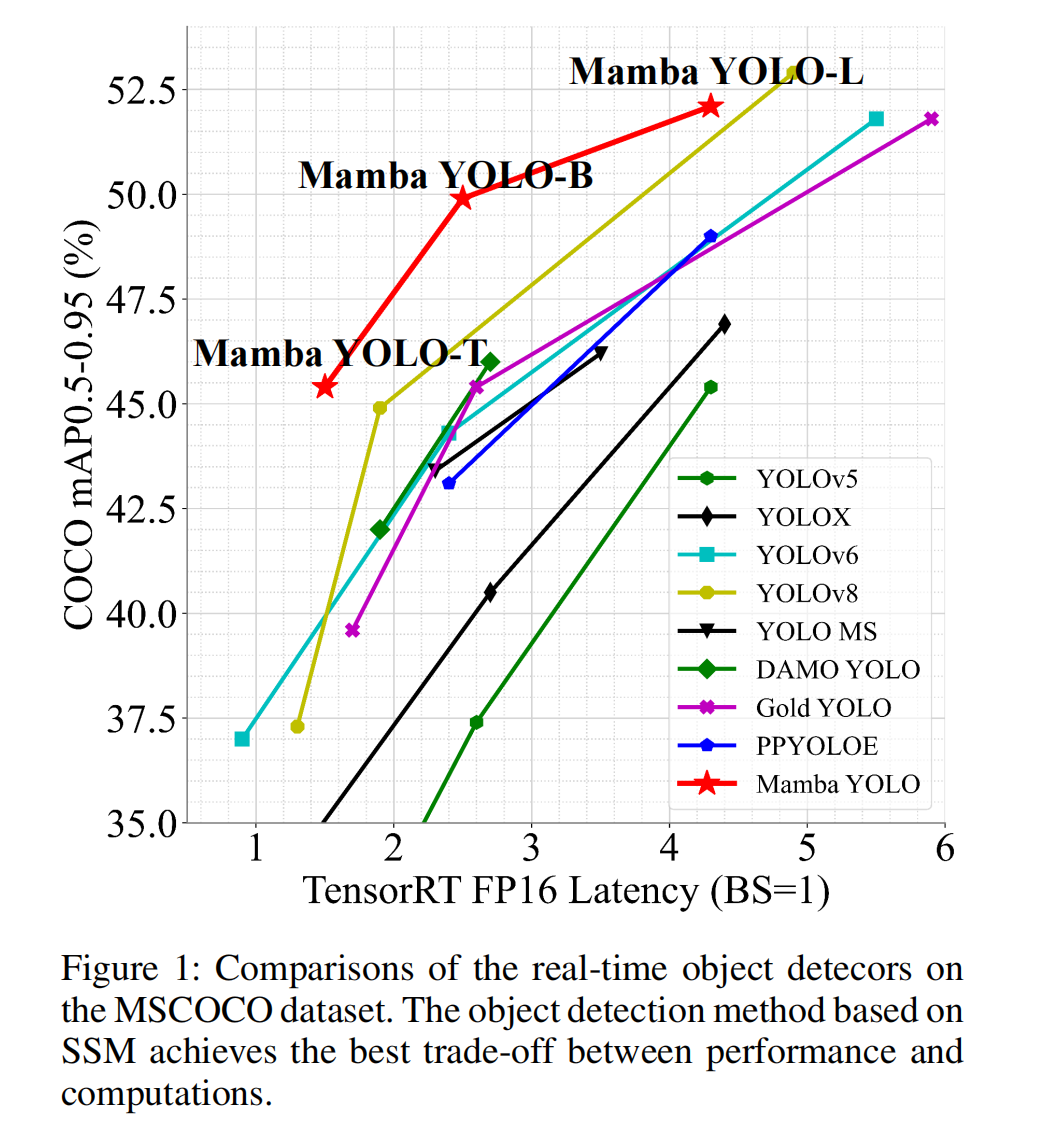
● 我们设计了一组不同尺度的模型,Mamba YOLO(Tiny/Base/Large),以支持不同规模和尺寸的任务部署。在MSCOCO上的实验,如图1所示,证明我们的Mamba YOLO与现有的最先进方法相比实现了显著的性能提升。
3. 方法
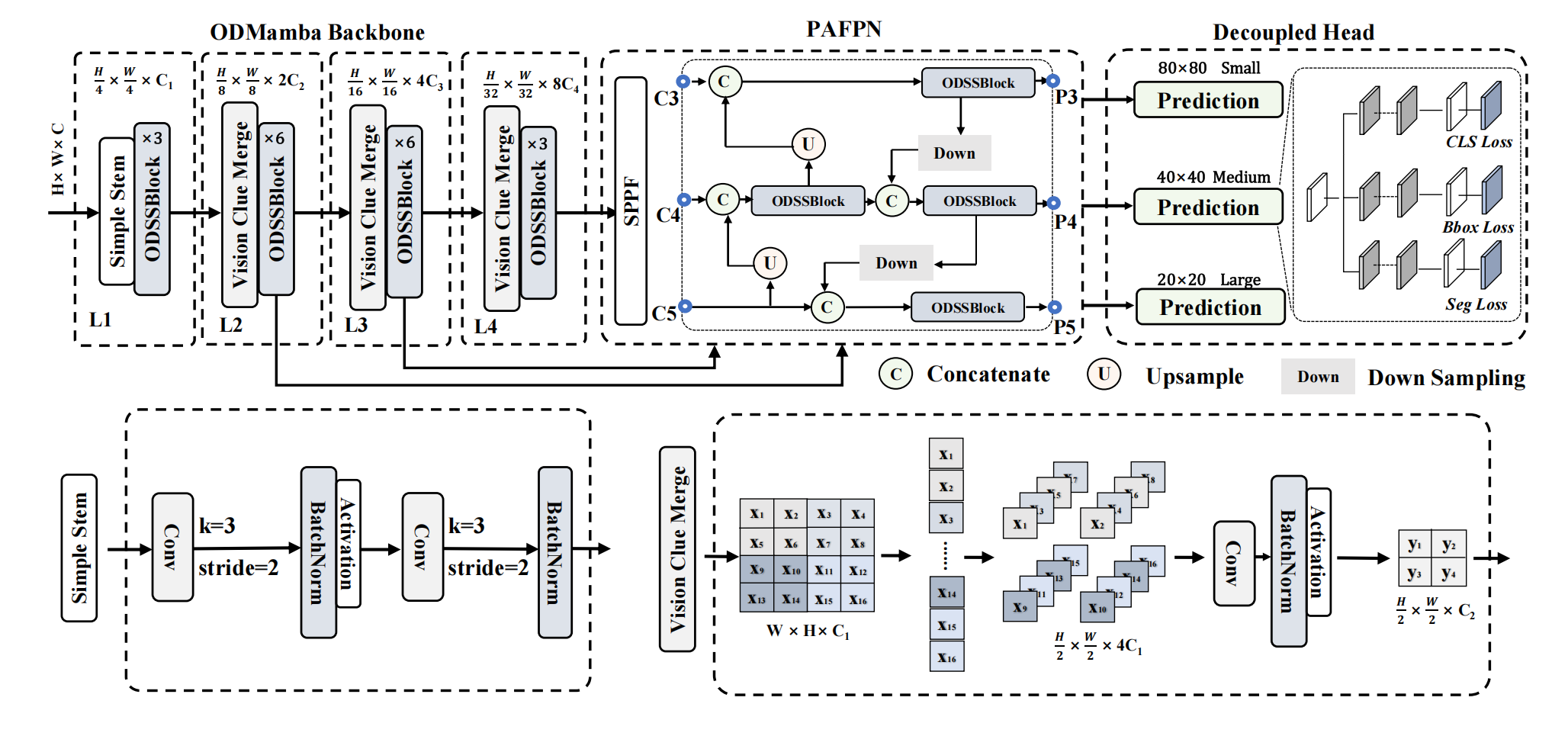
图2:Mamba YOLO架构示意图。Mamba YOLO采用含选择性SSM(序列状态机,Sequential State Machine)的ODSSBlock模块构建其骨干网络,通过简单主干模块(Simple Stem)将输入图像分割为多个patch(补丁/块),并使用视觉线索融合模块(Vision Clue Merge)执行下采样操作。从骨干网络中提取{C3, C4, C5}等多尺度特征后,将其融合到PAFPN(路径聚合特征金字塔网络)中;随后通过ODSSBlock对高层语义特征与低层空间特征进行优化和融合,最终输出{P3, P4, P5}特征至解耦头(Decoupled Head),以生成检测结果。
3.1整体架构
Mamba YOLO的架构概述如图2所示。我们的目标检测模型分为ODMamba主干网络和颈部(neck)部分。ODMamba由Simple Stem、下采样块(Downsample Block)和ODSSBlock组成。在颈部,我们遵循PAFPN的设计,使用ODSSBlock模块代替C2f来捕获更丰富的梯度信息流。主干网络首先通过Stem模块进行下采样,得到分辨率为H4×W4\frac{H}{4}\times\frac{W}{4}4H×4W的2D特征图。随后,所有模型都由ODSSBlock后接一个VisionClue Merge模块进行进一步下采样组成。在颈部,我们采用PAFPN的设计,使用ODSSBlock替换C2f,其中Conv仅负责下采样。
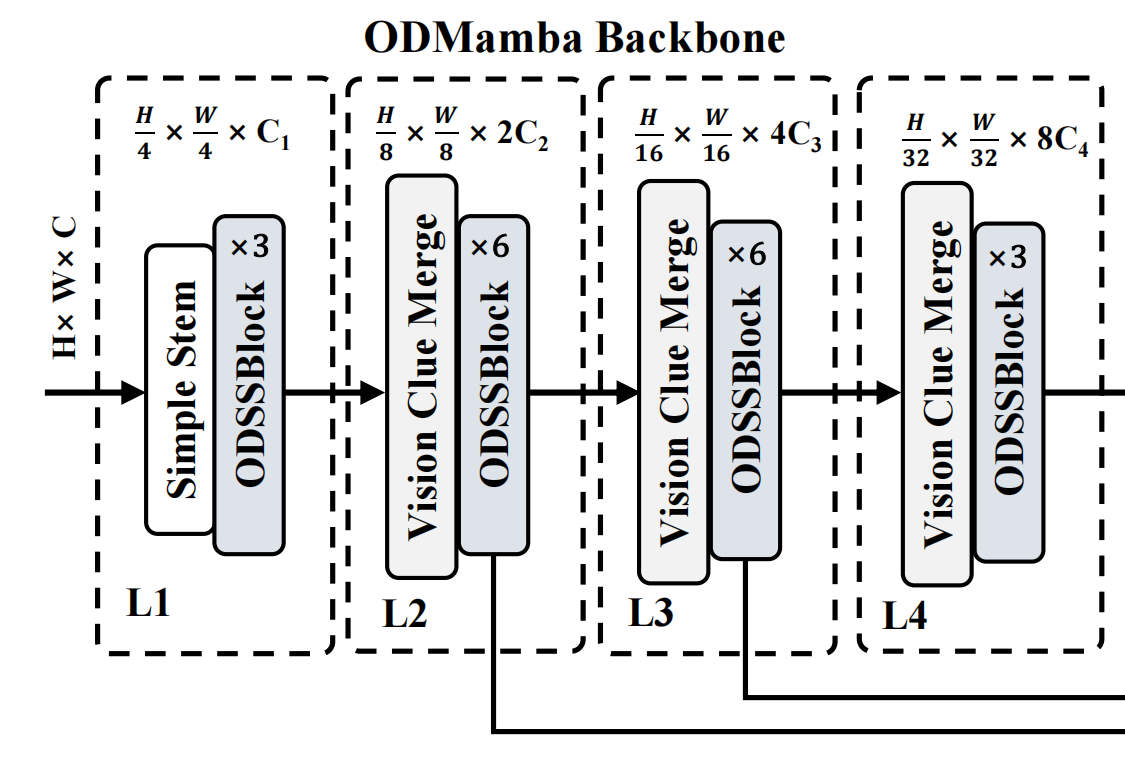
Simple Stem 现代ViT通常采用分块(patch)作为其初始模块,将图像分割成不重叠的块。这种分割过程是通过核大小为4、步长为4的卷积操作实现的。然而,最近的研究,如EfficientFormerV2表明,这种方法可能会限制ViT的优化能力,影响整体性能。为了在性能和效率之间取得平衡,我们提出了一个简化的stem层。我们不使用非重叠块,而是采用两个步长为2、核大小为3的卷积。
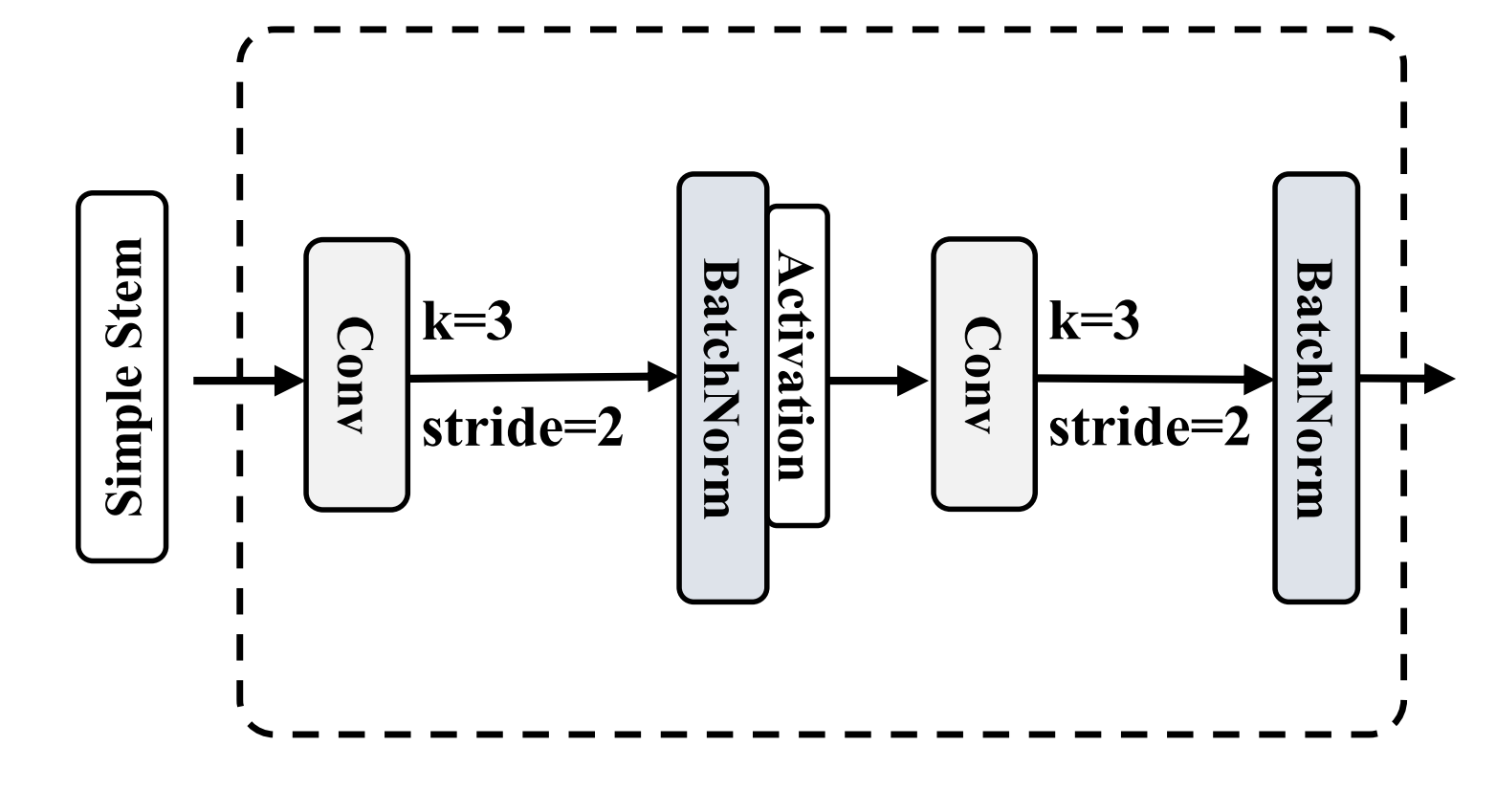
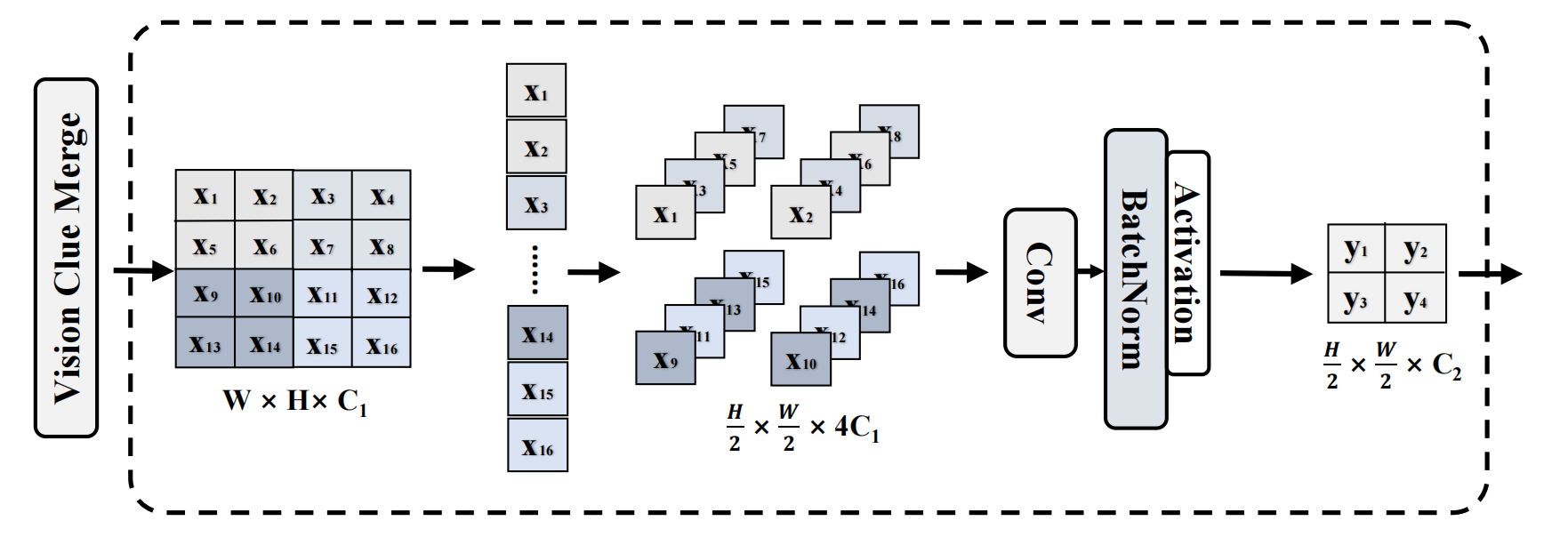
Vision Clue Merge 虽然CNN和ViT结构通常使用卷积进行下采样,但我们发现这种方法会干扰SS2D在不同信息流阶段的选择性操作。为了解决这个问题,VMamba将2D特征图拆分并使用1x1卷积降低维度。我们的研究结果表明,为SSM保留更多的视觉线索有利于模型训练。与传统的维度减半方法相比,我们通过以下方式简化此过程:
- 移除归一化(norm)。
- 拆分维度图。
- 将多余的特征图附加到通道维度。
- 利用4倍压缩的点wise卷积进行下采样。
与使用步长为2的3$\times$3卷积不同,我们的方法保留了前一层SS2D选择的特征图。
3.2ODSSBlock
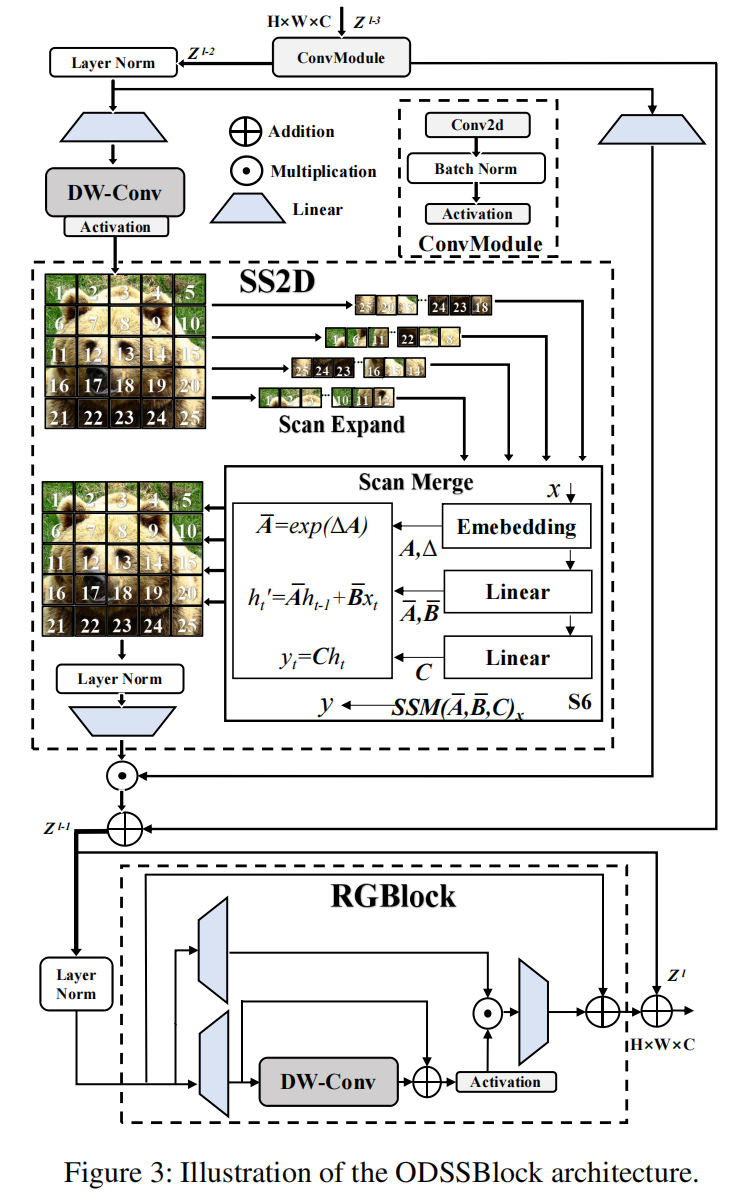
如图3所示,ODSSBlock是Mamba YOLO的核心模块,在输入阶段它通过一个ConvModule,使网络能够学习更深层、更丰富的特征表示,我们假设输入特征Zl−3Z^{l-3}Zl−3的形状为RC×H×WR^{C\times H\times W}RC×H×W,我们有:
Zl−2=σ(BatchNorm(ConvModule(Zl−3)))(9)Z^{l-2}=\sigma\left(BatchNorm\left(ConvModule(Z^{l-3})\right)\right)\qquad(9)Zl−2=σ(BatchNorm(ConvModule(Zl−3)))(9)
其中σ\sigmaσ表示激活函数(非线性SiLU)。ODSSBlock的层归一化(Layer Normalization)和残差连接设计借鉴了Transformer Blocks的风格架构,这使得模型在深度堆叠时能够高效流动和训练。
Zl−1=SS2D(LayerNorm(Zl−2))+Zl−2(10)Z^{l-1}=SS2D\left(LayerNorm(Z^{l-2})\right)+Z^{l-2}\qquad(10)Zl−1=SS2D(LayerNorm(Zl−2))+Zl−2(10)
Zl=RGBlock(LayerNorm(Zl−1))+Zl−1(11)Z^{l}=RGBlock\left(LayerNorm(Z^{l-1})\right)+Z^{l-1}\qquad(11)Zl=RGBlock(LayerNorm(Zl−1))+Zl−1(11)
ODSSBlock可以解耦为两个独立的功能组件SS2D(·)和RGBlock(·),分别用于全局空间信息传播和通道信息传播,其中Zl−1Z^{l-1}Zl−1表示SS2D之后的中间状态。
SS2D 扫描扩展(Scan Expansion)、S6块(S6 Block)和扫描合并(Scan Merge)是SS2D算法的三个主要步骤,其主要流程如图3所示。扫描扩展操作将输入图像扩展为一系列子图像,每个子图像表示一个特定方向,当从对角线视角观察时,扫描扩展操作沿着四个对称方向进行,分别是自上而下、自下而上、从左到右和从右到左。这种布局不仅全面覆盖了输入图像的所有区域,而且通过系统的方向变换为后续特征提取提供了丰富的多维信息基础,从而提高了图像特征多维捕获的效率和全面性。SS2D中的扫描合并操作将获得的序列作为S6块(Gu and Dao 2023)的输入,并合并来自不同方向的序列,以便将特征提取到全局特征。
RG Block 原始MLP仍然是最广泛采用的,VMamba架构中的MLP也遵循Transformer设计,对输入序列执行非线性变换以增强模型的表达能力。最近的研究表明,门控MLP在自然语言处理中表现出强大的性能,我们发现门控机制对视觉具有同样的潜力。在图3中,本文提出的残差门控块(Residual Gated Block, RG Block)的简单设计旨在以较低的计算成本提高模型性能,RG Block从输入fA′f^{\prime}_{A}fA′和fB′f^{\prime}_{B}fB′创建两个分支以分别保留全局和局部信息,T(⋅)\mathcal{T}(\cdot)T(⋅)表示线性层。
Rlocall−1=Tlocall−1(fA′)(12)\mathcal{R}^{l-1}_{ local}=\mathcal{T}^{l-1}_{ local}(f^{\prime}_{A})\qquad(12)Rlocall−1=Tlocall−1(fA′)(12)
Rgloball−1=Tgloball−1(fB′)(13)\mathcal{R}^{l-1}_{global}=\mathcal{T}^{l-1}_{global}(f^{\prime}_{B})\qquad(13)Rgloball−1=Tgloball−1(fB′)(13)
深度可分离卷积(Depth separable convolution)用作Rgloball−1\mathcal{R}_{\text{global}}^{l-1}Rgloball−1分支上的位置编码模块(Position Encoding Module),并通过残差连接在训练期间更有效地回流梯度,它具有较低的计算成本,并通过保留和利用图像的空间结构信息显著提高了性能。RG Block采用非线性GeLU作为激活函数来控制每一层的信息流。Y(x)\mathcal{Y}(x)Y(x)过程可以写为:
Y(x)=Φ(DWConv(x)⊕x)(14)\mathcal{Y}(x)=\Phi(DWConv(x)\oplus x)\qquad(14)Y(x)=Φ(DWConv(x)⊕x)(14)
通过Y(x)\mathcal{Y}(x)Y(x)的局部信息与Rgloball−1\mathcal{R}_{global}^{l-1}Rgloball−1的全局信息相乘,全局特征通过线性层进行细化以融合局部通道的信息,并允许残差连接与fA′f_{A}^{\prime}fA′的原始输入和隐藏层特征求和。RG Block在仅引起计算成本轻微增加的同时捕获了更多的全局和局部特征,得到的输出特征fRGf_{RG}fRG定义如下:
Rfusionl=Rgloball−1⊙Y(Rlocall−1)(15)\mathcal{R}^{l}_{\text{fusion}}=\mathcal{R}^{l-1}_{\text{global}}\odot\mathcal{Y}(\mathcal{R}^{l-1}_{\text{local}})\qquad(15)Rfusionl=Rgloball−1⊙Y(Rlocall−1)(15)
fRG=Tfusionl(Rfusionl)⊕fA′(16)f_{RG}=\mathcal{T}_{\text{fusion}}^{l}(\mathcal{R}_{\text{fusion}}^{l})\oplus f_{A}^{\prime}\qquad(16)fRG=Tfusionl(Rfusionl)⊕fA′(16)
其中Φ\PhiΦ表示激活函数(非线性GELU)。本文中,RG Block中的门控机制通过集成卷积操作保留了空间信息,同时使模型对图像中的细粒度特征更加敏感。与传统的MLP相比,RG Block将全局依赖关系和全局特征传递给每个像素以捕获相邻特征的依赖性,这使得上下文信息丰富,进一步增强了模型的表达能力。
4.实验
在本节中,我们对Mamba YOLO进行目标检测任务的全面实验。我们采用MSCOCO数据集来验证所提出的Mamba YOLO的优越性。我们所有的模型都在8个NVIDIA H800 GPU上进行训练。
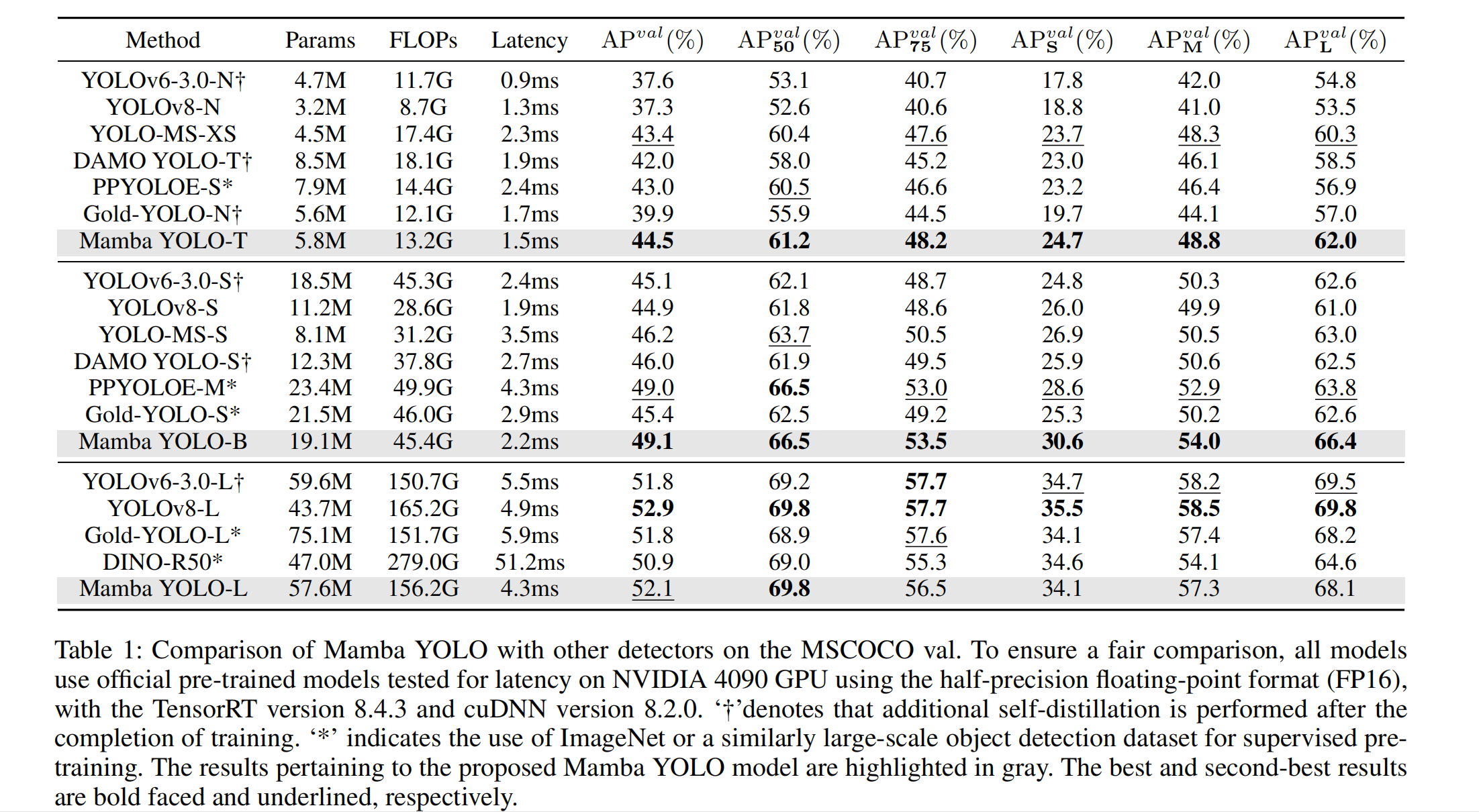
表1:Mamba YOLO与其他检测器在MSCOCO验证集(MSCOCO val)上的性能对比。为保证公平比较,所有模型均采用官方预训练模型,在NVIDIA 4090 GPU上以半精度浮点格式(FP16)测试延迟(性能指标),所用软件环境为TensorRT 8.4.3版本及cuDNN 8.2.0版本。其中,“†”表示在训练完成后额外执行了自蒸馏操作;“*”表示使用ImageNet数据集或类似规模的大型目标检测数据集进行有监督预训练。所提出的Mamba YOLO模型相关结果用灰色突出显示;最优结果和次优结果分别用粗体和下划线标注。
与最先进技术的比较 表1说明了MSCOCO val集上的结果,表明我们提出的方法在FLOPs、参数数量和精度以及测量的GPU延迟之间实现了最佳的整体权衡。具体来说,与高性能微型轻量模型如PPYOLOE-S(Long et al. 2020)/YOLO-MS-XS(Chen et al. 2023)相比,Mamba YOLO-T的AP显著提高了1.1%/1.5%,GPU推理延迟减少了0.9ms/0.2ms。与精度相似的基线模型YOLOv8-S相比,Mamba YOLO-T将参数数量减少了48%,FLOPs减少了53%,同时将GPU推理延迟降低了0.4ms。
Mamba YOLO-B与参数和FLOPs数量相似的Gold-YOLO-M相比,实现了3.7%的AP增益。即使与精度相当的PPYOLOE-M相比,Mamba YOLO-B将参数数量减少了18%,FLOPs减少了9%,GPU推理延迟减少了1.8ms。对于更大的模型,Mamba YOLO-L也在所有先进目标检测器中取得了更好或相当的性能。与性能最佳的Gold-YOLO-L(Wang et al. 2024)相比,Mamba YOLO-L将AP提高了0.3%,同时参数数量减少了0.9%。从该表可以看出,使用从头训练(scractch training)方法的Mamba YOLO-T性能优于所有其他训练方法。
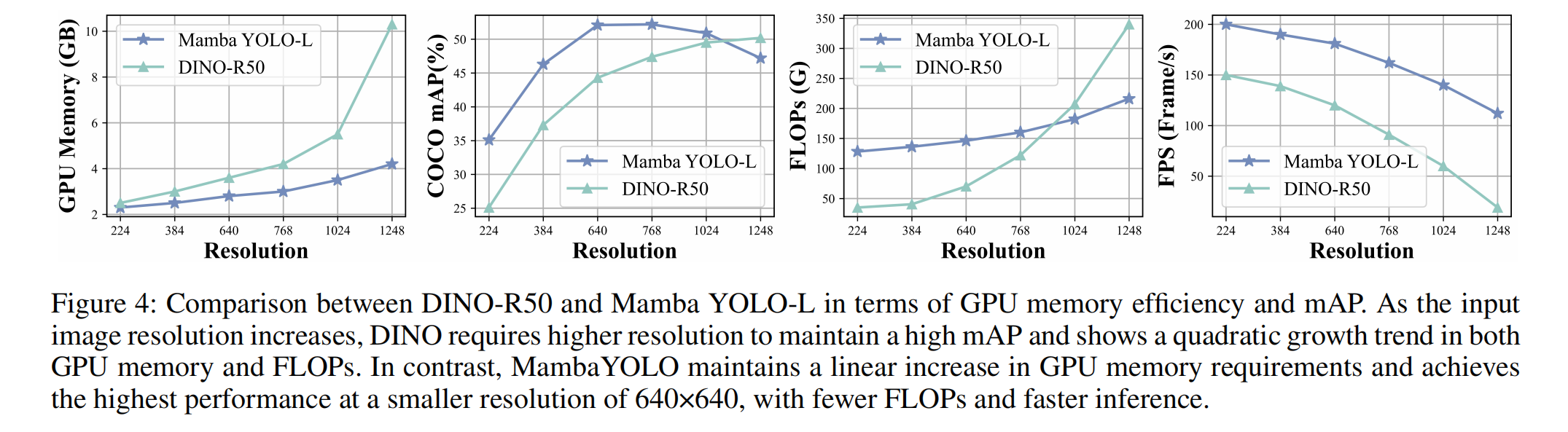
图4:DINO-R50与Mamba YOLO-L在GPU内存效率和mAP(平均精度均值,mean Average Precision)方面的对比。随着输入图像分辨率的提升,DINO需通过更高分辨率才能维持较高的mAP,且其GPU内存占用与FLOPs(浮点运算次数,Floating Point Operations)均呈现二次增长趋势。与之相反,Mamba YOLO的GPU内存需求保持线性增长,且在640×640这一更小分辨率下即可实现最高性能,同时具备更少的FLOPs和更快的推理速度(inference speed)。
此外,图4比较了Mamba YOLO-L和DINO-R50在每秒帧数(FPS)和GPU内存使用方面的表现,显示Mamba YOLO-L在增加分辨率时保持了更好的精度和速度,内存效率和FLOPs呈线性增长。这些比较结果表明,在不同规模的Mamba YOLO上,我们提出的模型相对于现有的最先进方法具有显著优势。
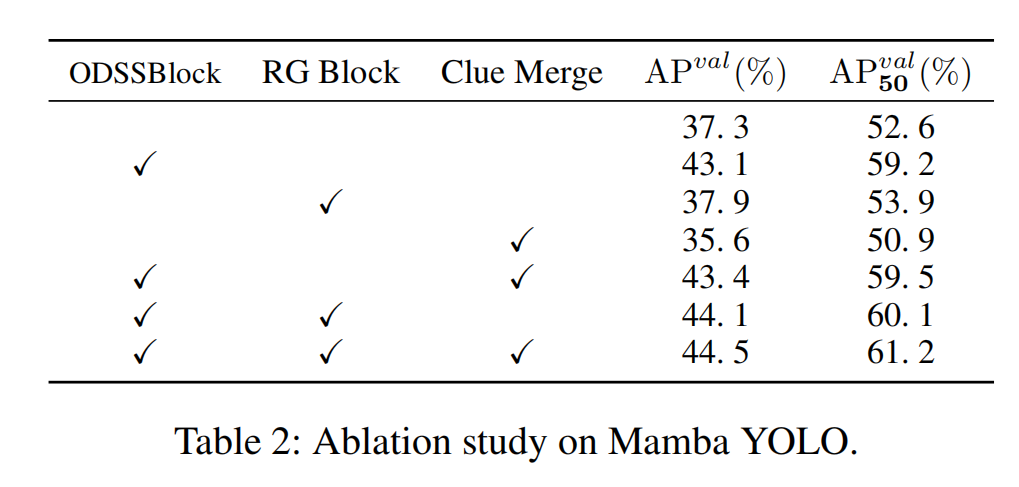
Mamba YOLO的消融研究 在本节中,我们独立检查ODSSBlock中的每个模块,并且在没有Clue Merge的情况下,我们使用传统卷积进行下采样,以评估Vision Clue Merge对精度的影响。我们在MSCOCO数据集上对Mamba YOLO-T模型进行了消融实验。我们的结果表2表明,线索合并为SSM保留了更多的视觉线索,同时也为ODSSBlock结构确实是最优的断言提供了证据。
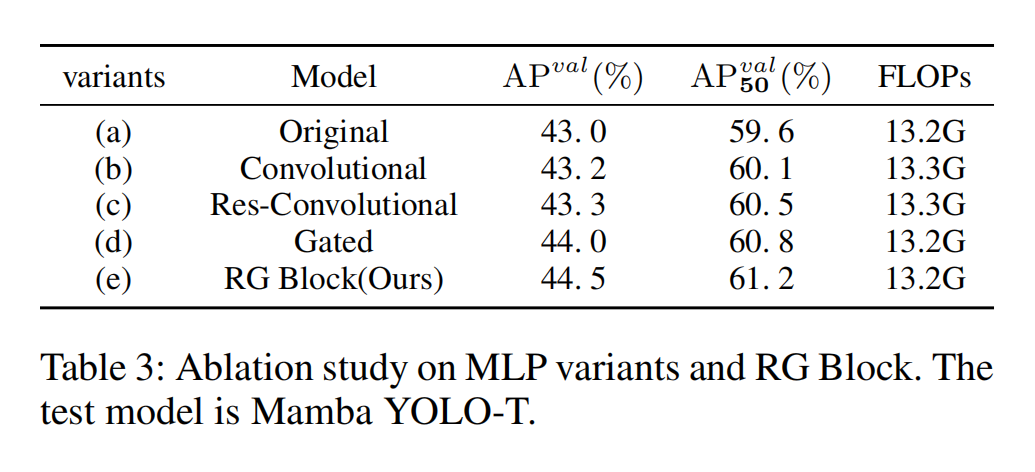
RG Block结构的消融研究 RG Block通过逐像素获取全局依赖关系和全局特征来捕获逐像素的局部依赖关系。RG Block使用多分支结构对通道维度进行建模,解决了SSM在序列建模中感受野不足和图像定位能力弱方面的局限性。关于RG Block的设计细节,我们还考虑了三种变体:
- 卷积MLP (Convolutional MLP),在原始MLP中添加DW-Conv。
- 残差卷积MLP (Res-Convolutional MLP),以残差连接的方式将DW-Conv添加到原始MLP中。
- 门控MLP (Gated MLP),在门控机制下设计的MLP变体。
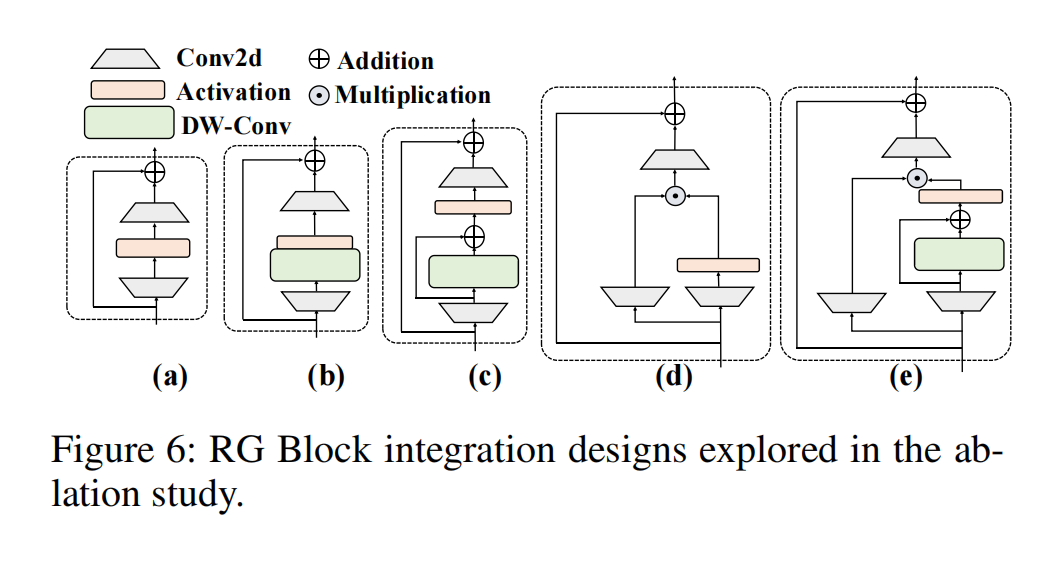
图 6:消融实验中所探索的 RG 模块(RG Block)集成设计
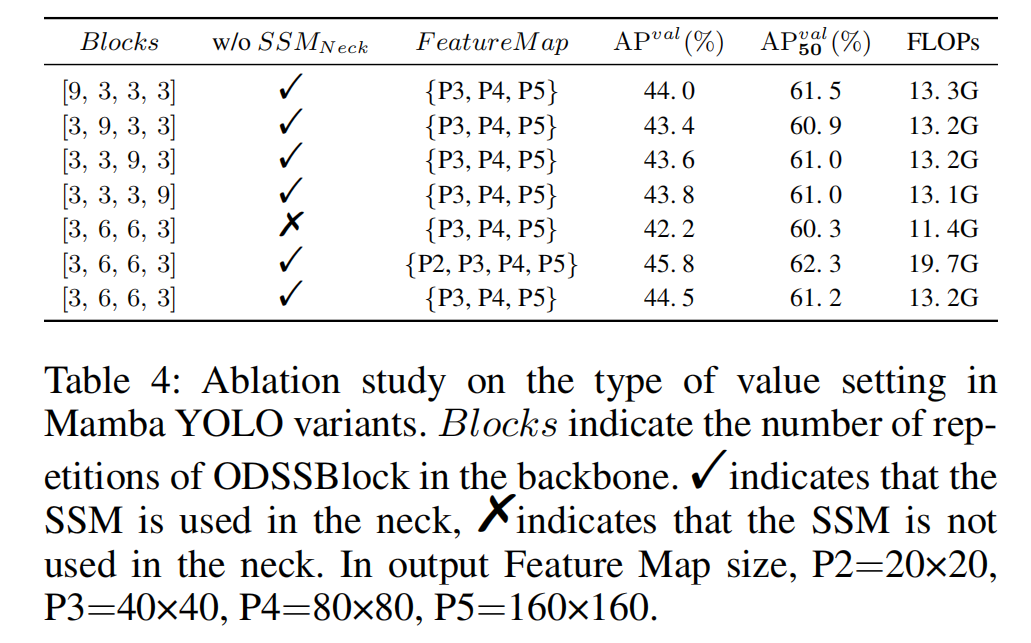
表 4:Mamba YOLO 变体模型中参数设置类型的消融实验。其中,“块数(Blocks)” 代表 ODSSBlock 在骨干网络(backbone)中的重复次数;“√” 表示在颈部网络(neck)中使用 SSM(序列状态机),“×” 表示在颈部网络中不使用 SSM。在输出特征图(Feature Map)尺寸方面,各特征层对应尺寸为:P2=20×20、P3=40×40、P4=80×80、P5=160×160。
Mamba YOLO变体中数值设置类型的消融研究 我们探索了主干网络中ODSSBlock重复次数的四种不同配置:[9, 3, 3, 3]施加了额外的计算开销,但并未带来相应程度的精度提升。[3,9,3,3]、[3,3,9,3]和[3,3,3,9]由于过度重复ODSSBlock实际上是冗余的。实验证明[3, 6, 6, 3]在Mamba YOLO中是更合理的配置。在颈部部分,虽然移除ODSSBlock可以实现更轻量的模型,但这不可避免地会降低模型精度,颈部部分的ODSSBlock可以提供丰富的梯度流和特征融合。选择输出特征图为{P2,P3,P4,P5}变体显著提高了精度,但不可避免地显著增加了GFLOPs。Mamba YOLO最终选择了Blocks=[3,6,6,3],特征图={P3,P4,P5}并在颈部使用了ODSSBlock。这种配置在精度和复杂度之间取得了更好的平衡,更适合高效执行实例分割任务。结果如表4所示。
可视化 为了进一步确认我们提出的检测框架的优势,我们从MSCOCO中随机选择了两个样本。图5显示了每种主流检测器与Mamba YOLO的可视化结果,可以看出Mamba YOLO能够在各种困难条件下实现准确检测,并在检测高度重叠、严重遮挡和复杂背景的物体方面表现出强大的能力,同时也显示出检测高度重叠和严重遮挡物体的强大能力。

5.结论
在本文中,我们提出了一种基于SSM设计并由YOLO扩展的检测器,其训练过程非常简单,因为它不需要在大型数据集上进行预训练。我们重新分析了传统MLP的局限性,并提出了RG Block,其门控机制和深度卷积残差连接旨在赋予模型在层次结构中传播重要特征的能力。我们的目标是建立YOLO的新基线,证明Mamba YOLO具有很强的竞争力。我们的工作是Mamba架构在实时目标检测任务中的首次探索,我们也希望为该领域的研究人员带来新的思路。