从零开始的指针(5)
一.函数指针数组
1.1理解函数指针数组
函数指针数组听名字好长,他到底是个啥?咱们前面学了很多指针和数组。我们不妨进行类比一下。 
类比得出结论,函数指针数组是数组,里面存放的是函数指针。
1.2函数指针数组的类型
我们现在知道了函数指针数组是用来存放函数指针的数组。那函数指针数组是怎样初始化的呢?
int Add(int x, int y)
{return x + y;
}
int Sub(int x, int y)
{return x - y;
}
int Mul(int x, int y)
{return x * y;
}
int Div(int x, int y)
{return x / y;
}
int (*pf1)(int,int) = Add;
int (*pf2)(int, int) = Sub;
int (*pf3)(int, int) = Mul;
int (*pf4)(int, int) = Div;
以这段代码为例。我们把四个加减乘除的函数分别用四个指针指向。那初始化的话我们只需把四个指针存在一个数组里面,这个数组就是函数指针数组。
int Add(int x, int y)
{return x + y;
}
int Sub(int x, int y)
{return x - y;
}
int Mul(int x, int y)
{return x * y;
}
int Div(int x, int y)
{return x / y;
}
int (*pf1)(int,int) = Add;
int (*pf2)(int, int) = Sub;
int (*pf3)(int, int) = Mul;
int (*pf4)(int, int) = Div;
ptr[4] = {pf1,pf2,pf3,pf4};//未写出函数指针类型。
这里我们就完成了函数指针数组的初始化,把函数指针存放到数组里。但是我们还没写出函数指针数组的类型。那函数指针数组类型该怎么写呢?
int(*ptr)(int,int) = {pf1,pf2,pf3,pf4};函数指针类型
我们先把函数指针数组写成函数指针类型先,我们在对他进行改造。现在ptr是个指针,我们不希望他是个指针,而是个数组。那我们该怎么做呢?
int (*ptr[4])(int, int) = { pf1,pf2,pf3,pf4};//函数指针数组类型
我们在ptr后面写个方括号,ptr先和方块结合说明他是个数组,把ptr【】去掉后,剩下的就是数组元素类型。类型未函数指针类型,说明这个数组的每个元素是函数指针,所以这个数组就是函数指针数组。
如何区分数组类型以及指针类型?
在 C 语言中,要确定数组和指针的类型,可以通过「逐步拆解声明」的方法,核心是遵循 运算符优先级规则(() 和 [] 优先级高于 *)。
一、确定数组的类型
数组的类型由「元素类型」和「数组大小」共同决定,格式为:元素类型 (*)[数组大小](注意括号的作用)。
拆解步骤:
- 找到数组名,先与
[]结合(因为[]优先级更高),确定这是一个数组。 - 去掉数组名和
[],剩下的部分就是数组元素的类型。 - 数组的完整类型 = 「元素类型」+「数组标记」。
示例:
int arr[5]; // 数组
int (*p_arr)[5]; // 指向该数组的指针(用于说明数组类型)
- 拆解
arr:arr与[5]结合 → 是数组;去掉arr[5],剩下int→ 元素类型是int。 - 结论:
arr是「int类型的数组,大小为 5」,其类型可表示为int [5]。 - 指针
p_arr的类型是「指向int [5]类型数组的指针」,即int (*)[5]。
二、确定指针的类型
指针的类型由「指向的数据类型」决定,格式为:数据类型 *。
拆解步骤:
- 找到指针名,先与
*结合(需注意括号强制改变优先级的情况)。 - 去掉指针名和
*,剩下的部分就是指针指向的数据类型。 - 指针的完整类型 = 「指向的数据类型」+「指针标记
*」。
示例:
int *p1; // 指针1
int (*p2)[5]; // 指针2(数组指针)
int (*p3)(int, float); // 指针3(函数指针)
拆解
p1:p1与*结合 → 是指针;去掉*p1,剩下int→ 指向int类型。
结论:p1的类型是「指向int的指针」,即int *。拆解
p2:p2被括号强制先与*结合 → 是指针;去掉*p2,剩下int [5]→ 指向「int [5]类型的数组」。
结论:p2的类型是「指向int [5]数组的指针」,即int (*)[5]。拆解
p3:p3被括号强制先与*结合 → 是指针;去掉*p3,剩下int (int, float)→ 指向「参数为(int, float)、返回值为int的函数」。
结论:p3的类型是「指向该函数的指针」,即int (*)(int, float)。
三、关键原则:优先级与括号
- 无括号时:
[]和()优先于*,所以int *arr[5]是「指针数组」(先结合[],元素是int *指针)。 - 有括号时:
(*变量名)强制先结合*,所以int (*arr)[5]是「数组指针」(先确定是指针,再指向数组)。
通过这种「先结合高优先级运算符,再逐步剥离」的方法,就能清晰判断数组和指针的具体类型。
二.转移表
2.1转移表的概念
现在我们懂了什么是函数指针数组,真所谓学以致用。现在我们用我们刚学到的热乎知识来写一个转移表。
什么是转移表?
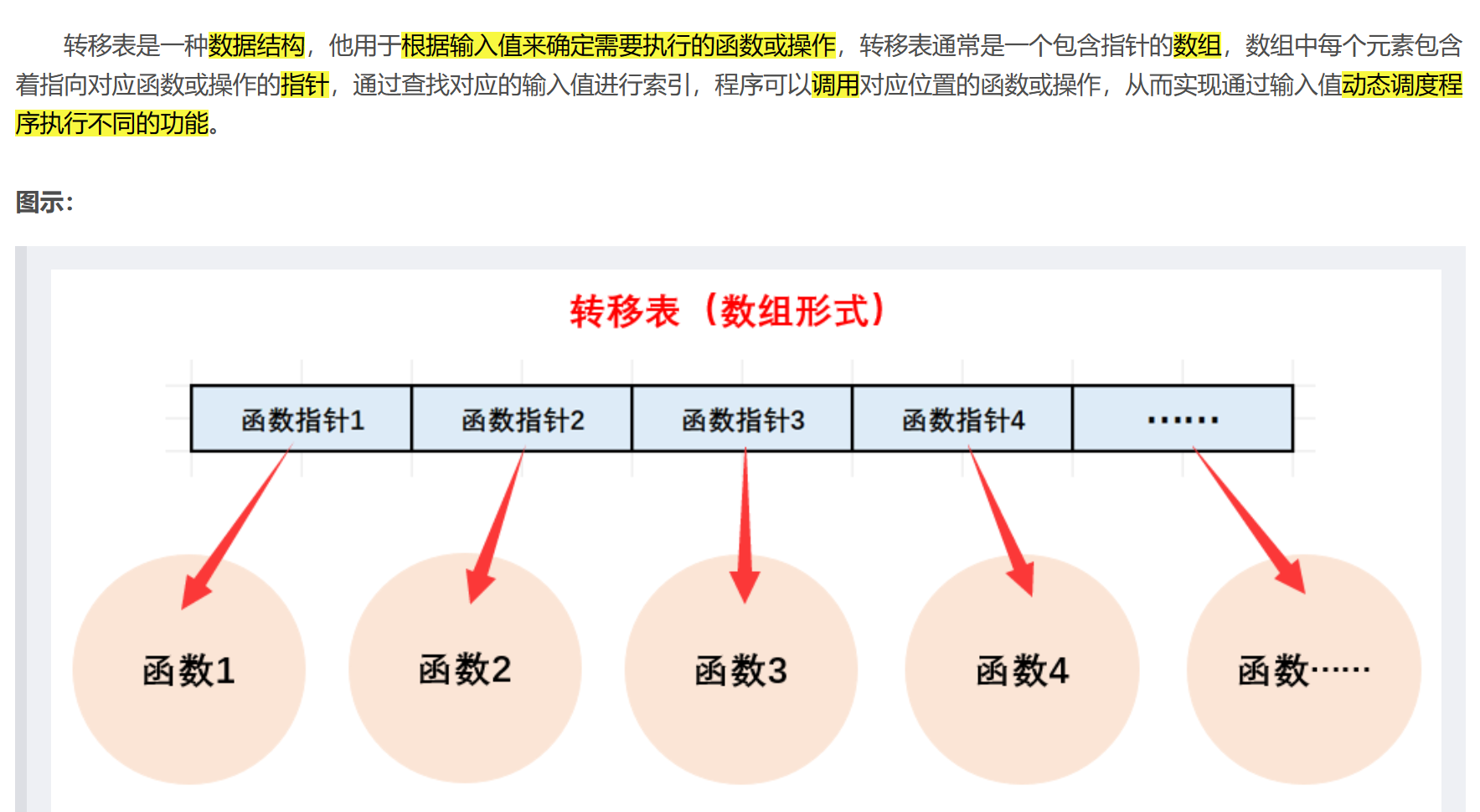
简单来说转移表就是使用一个函数指针数组来访问函数,这个函数指针数组就像一个踏板一样,可以帮你跳转到其他函数,这就是转移表。
2.2计算器
现在假如我们想写一个计算器,这个计算器能完成两个数的加减乘除运算。我们的代码简单粗暴的话一般会这么写。
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
void menu()
{printf("============================\n");printf("===== 1.Add 2.Sub =====\n");printf("===== 3.Mul 4.Div =====\n");printf("===== 0.exit =====\n");printf("============================\n");
}
int Add(int x, int y)
{return x + y;
}
int Sub(int x, int y)
{return x - y;
}
int Mul(int x, int y)
{return x * y;
}
int Div(int x, int y)
{return x / y;
}
int main()
{int x, y;int input;do{menu();printf("请选择:");scanf("%d", &input);switch (input){case 1:printf("请输入两个操作数~\n");scanf("%d%d", &x, &y);printf("%d\n", Add(x, y));break;case 2:printf("请输入两个操作数~\n");scanf("%d%d", &x, &y);printf("%d\n", Sub(x, y));break;case 3:printf("请输入两个操作数~\n");scanf("%d%d", &x, &y);printf("%d\n", Mul(x, y));break;case 4:printf("请输入两个操作数~\n");scanf("%d%d", &x, &y);printf("%d\n", Div(x, y));break;case 0:printf("退出计算器~");break;default:printf("输入错误,请重新输入~");break;}} while (input);return 0;
}
我们的思路就是先把菜单函数写出来,在把实现运算的加减乘除代码封装成一个函数。再用do_while循环实现循环计算,switch根据输入选择调用哪个函数,分情况调整即可。
但是大家是不是发现了一个问题,就是这样写出来的代码非常的长。那为什么会这么长呢?
原因在于这段代码有着许多重复性的代码,他们之间唯一不同的就是调用的函数。那我们有没有什么办法既能完成运算又能是代码简洁精炼呢?这就需要用到我们刚学到的函数指针数组的知识啦!
2.3函数指针数组的应用
现在我们想把这个代码简化。这段代码冗余部分区别就在于调用的函数不同,那我们前面说了转移表可以帮我们跳转到不同的函数。所以我们可以用转移表帮我们跳转到不同的函数,之后调用即可,这样一来就不用把每种函数调用的情况列举,直接把冗余代码合并成一段代码即可。
int (*ptr[5])(int, int) = { NULL,Add,Sub,Mul,Div };//为了与函数的菜单
// 序号对齐,多加入Null
int main()
{int n = 0;do{menu();printf("请选择:");scanf("%d", &n);if (n < 5 && n>0){int x, y;printf("请输入两个操作数~");//输出两个操作数scanf("%d%d", &x, &y);int res = ptr[n](x, y);//调用转移表调用函数printf("%d\n", res);}else if (n == 0){printf("退出计算器~");//退出计算器break;}elseprintf("请重新输入~\n");//输入错误} while (n);return 0;
}
这里我们思路和之前差不多,但是我们创建了一个函数指针数组,为了函数指针数组的下标与菜单函数的数字对其,我们在数组前加入NULL。接着把冗余部分用转移表整合成一段代码即可。之后对输入数用 if分情况修改即可。这就是转移表。
大家可以看到我们学的这些指针的知识还是很有用的,只是我们还不能熟练运用,所以我们更加需要好好学习!
三.回调函数:简化计算器代码
回调函数,本质上是通过函数指针调用的函数。当我们将一个函数的指针(地址)作为参数传递给另一个函数,且这个指针被用来调用其所指向的函数时,被调用的函数就是回调函数。它并非由自身的实现方直接调用,而是在特定事件或条件触发时,由其他程序调用以响应对应事件或条件。
在计算器实现的代码中,存在明显的冗余问题。观察代码可发现,不同运算(加法、减法、乘法、除法)的处理逻辑里,输入操作数、输出计算结果的代码反复出现,唯一的差异仅在于调用的具体运算函数。这种 “重复框架 + 差异核心” 的结构,恰好可以通过回调函数进行优化。
核心思路在于:将重复的输入输出逻辑封装成一个通用函数,而把有差异的运算函数以指针形式作为参数传递给这个通用函数。通用函数通过接收的函数指针,动态调用对应的运算函数 —— 这正是回调函数的典型应用场景。
改造前:冗余的代码结构
改造前的代码中,main函数的switch语句里,每个case分支都重复实现了 “提示输入→读取参数→调用运算函数→输出结果” 的流程,冗余代码占据了大量篇幅:
// (仅展示核心冗余部分)
switch (input)
{
case 1:printf("输入操作数:");scanf("%d %d", &x, &y);ret = add(x, y);printf("ret = %d\n", ret);break;
case 2:printf("输入操作数:");scanf("%d %d", &x, &y);ret = sub(x, y);printf("ret = %d\n", ret);break;
// 乘法、除法分支的代码与上述结构一致,仅调用的函数不同改造后:回调函数实现代码复用
我们定义了一个通用的calc函数,它接收一个指向 “两个 int 参数、返回 int” 的函数指针作为参数(即回调函数的指针)。在calc函数内部,统一实现输入输出逻辑,再通过函数指针调用具体的运算函数:
// 计算函数(使用回调函数)
void calc(int(*pf)(int, int))
{int ret = 0;int x, y;printf("输入操作数:");scanf("%d %d", &x, &y);ret = pf(x, y); // 调用回调函数printf("ret = %d\n", ret);
}此时main函数的switch分支只需传递对应运算函数的地址即可,代码瞬间简洁清晰:
switch (input)
{
case 1:calc(add); // 传递加法函数地址作为回调break;
case 2:calc(sub); // 传递减法函数地址作为回调break;
case 3:calc(mul); // 传递乘法函数地址作为回调break;
case 4:calc(div); // 传递除法函数地址作为回调break;
// 退出与错误处理分支通过回调函数的改造,原本重复的输入输出代码被提炼为通用逻辑,不仅精简了代码篇幅,更提升了可维护性 —— 若后续需要添加新运算(如取余),只需新增运算函数,再在switch中增加一个调用calc的分支即可,无需重复编写输入输出代码。这种 “分离通用逻辑与核心差异” 的思想,正是回调函数在代码优化中的核心价值所在。
四.指针知识梳理
指针相关的知识内容丰富且容易混淆,学完后及时梳理十分必要,毕竟 “好记性不如烂笔头”。像我写这篇内容,也是经过复习、加深理解后,把所学知识整理出来分享给大家,这个过程能进一步强化对知识点的认知。现在我们就来回顾下学过的指针相关内容,我整理了一个简单的思维导图(大家也可以尝试自己绘制)。这里教大家一个区分含 “指针”“数组” 名称的类型的小技巧:只需看名称最后的名词,若是 “指针”,那就是指针,前面的内容说明该指针指向的对象;若是 “数组”,那就是数组,前面的内容说明该数组每个元素的指针类型。
我们学习的指针相关内容大致如下:
- 一级指针:用于存储普通变量的地址,比如
int* p = &a;(假设a是int型变量),int*是整型指针类型,char*是字符指针类型等。 - 二级指针:用来存放一级指针的地址,例如
int** pp = &p;(假设p是一级整型指针),类型为int**,字符型二级指针类型为char**。 - 数组指针:存储数组的地址,像
int (*p)[5] = arr;(arr是int型数组,长度为 5),是整型数组指针,类型为int (*)[5],字符数组指针类型为char (*)[5],要注意数组长度(这里的5)不可省略。需要注意的是,除了sizeof(数组名)和&数组名的情况外,数组名表示数组首元素的地址。 - 函数指针:存放函数的地址,函数名本身就代表函数地址,比如
int (*p)(int, int) = Add;(Add是接收两个int参数、返回int的函数),类型为int (*)(int, int)。 - 指针数组:是指针元素的集合,每个元素都是指针。比如
int* arr[5];是整型指针数组,char* arr[5];是字符指针数组,还有浮点型指针数组float* arr[5];、双精度型指针数组double* arr[5];等。 - 函数指针数组:本质也是指针数组,只不过数组的每个元素是函数指针。例如
char* (*pfarr[5])(int, char*);,它是一个函数指针数组,数组的每个元素都是char* (*)(int, char*)类型的函数指针。 - 函数指针数组指针:函数指针数组也有自己的地址,把这个地址存放到一个指针里,这个指针就是函数指针数组指针,比如
char* (*(*pfarr)[5])(int, char*);。

五.qsort的模拟实现
5.1冒泡排序
冒泡排序相信很多小伙伴都已经耳熟能详了。这里简单讲一下。冒泡排序的思想就是,进行n躺比较,每趟比较进行相邻两数的比较,满足条件就交换位置。每次比较后比较数移动。每趟比较将待排序数中最大或最小的数排序好。具体代码如下:
for (int i = 0; i < n - 1; i++)//趟数
{for (int j = 0; j < n - 1 - i; j++)//待排序数{if (a[j] > a[j + 1])//比较{int tmp = a[j];//交换a[j] = a[j + 1];a[j + 1] = tmp;}}
}
5.2qsort函数介绍

qsort函数是用来排序的库函数,直接可以用来排序数据,并且最厉害的地方可以排序任意类型的数据。底层的采用的是快速排序的方式。函数有四个参数
- void* base 指针,指向待排序数组的第一个元素
- size_t num 正整数,代表待排序数组元素个数
- size_t size 正整数,代表待排序数组元素的大小,单位是字节
- int (compar)(const void,const void*) 比较函数指针,由这个函数完成数据的比较
5.3冒泡排序实现qsort
现在我们想用冒泡排序算法实现qsort的功能。如果按照原来的冒泡排序写法,只能比较整型,可是qsort函数需要完成任意类型数组的比较。那我们就需要对原来的代码进行改造,那怎么改造呢?我们来思考一下。
现在我们知道比较和交换的地方需要改造,我们把它封装成函数之后再调用这些函数来完成比较和交换的功能。
排序的数据可能时整型数组,还可能是结构体。所以我们就写出多个对应比较函数。
5.3.1比较函数
我们这里统一以函数的返回值作为判断大小的标准,qsort函数对比较函数的返回直接也是这么要求的。
如果返回值为大于0说明前一个数大于后一个数,等于说明两个数相等,小于0说明前一个数小于后一个数。那我们可以直接让两个数作差,大于的话作差之后返回的是大于0的数,等于作差返回0,小于的话作差返回的数小于0的数。那函数就可以这样写。
- 整形比较
int cmp_int(const void* p1, const void* p2)
{return *(int*)p1 - *(int*)p2;//p1p2分别指向// 两个比较数
}
- 结构体字符串
如果我们比较结构体字符串的话,比如比较名字,名字就是字符串。字符串的比较可以用库函数strcmp比较。
strcmp的返回值也是根据字符串的大小来决定返回值是大于,等于,还是小于0。那这个函数是怎么比较字符串的大小?

事实上和qsort比较逻辑一样
- 前者 > 后者 → 返回正数
- 前者 = 后者 → 返回 0
- 前者 < 后者 → 返回负数
知道这些我们直接调用strcmp函数比较字符串即可,又因为它是根据字符串大小返回值。所以我们直接return strcmp的返回值即可。那比较结构体字符串的话,我们就把指针强制类型转化结构体指针,再用间接访问操作符访问结构体成员即可。
int cmp_stu_by_name(const void* p1, const void* p2)//结构体字符串比较函数
{return strcmp(((struct stu*)p1)->name, ((struct stu*)p2)->name);
}
- 结构体整型
如果我们要比较结构体年龄的话,年龄用整型表示,那就是比较整形。那思路和我们的整型比较函数一样。但是结构体的话,就把指针强制类型转化为结构体类型,再用间接访问操作符访问结构体成员即可。
int cmp_stu_by_age(const void* p1, const void* p2)//结构体整形比较函数
{return ((struct stu*)p1)->age - ((struct stu*)p2)->age;
}
5.3.2元素base指针位置的确定
我们要比较两个元素,需要把指针位置传给比较函数。所以我们需要根据base确定出指针位置。那该怎么算呢?
关键逻辑拆解
void*的局限性:void*是 “无类型指针”,它能指向任意数据,但不能直接解引用(因为编译器不知道它指向的数据占几个字节、是什么类型)。比如图中arr是int数组,但base是void*,直接用*base无法得到9(int占 4 字节,void*不知道该取几个字节)。用「字节」作为通用访问单位:
内存的最小单位是字节,不管数据类型(int/short/ 结构体等),最终都以字节的形式存在内存中。因此,只要知道每个元素占多少字节(width),就能通过「字节偏移」来定位元素。通过
width计算元素位置:
数组在内存中是连续存储的。假设数组起始地址是base,每个元素占width字节,那么:- 第
j个元素的地址 =base + j * width(字节偏移); - 第
j+1个元素的地址 =base + (j+1) * width。
这样,不管元素是int(width=4)、short(width=2)还是自定义结构体(width是结构体大小),都能通过width准确找到下一个元素的位置。
- 第
举个例子
如果 arr 是 int 数组(int 占 4 字节,即 width=4):
- 第 0 个元素地址:
base + 0 * 4→ 对应arr[0](值为9); - 第 1 个元素地址:
base + 1 * 4→ 对应arr[1](值为8); - 以此类推,能遍历整个数组。
如果 arr 是 short 数组(short 占 2 字节,即 width=2):
- 第 0 个元素地址:
base + 0 * 2; - 第 1 个元素地址:
base + 1 * 2;
同样能正确定位。
总结
qsort 利用 void* 兼容任意类型 + width 指定元素字节大小,绕开了 “必须知道具体类型” 的限制,通过 “字节级偏移” 实现了对任意类型数组的通用访问,为后续的排序(比较、交换元素)打下基础。
5.3.3交换函数
比较后,如果满足条件就需要交换元素位置。那我们就把元素指针位置传给函数。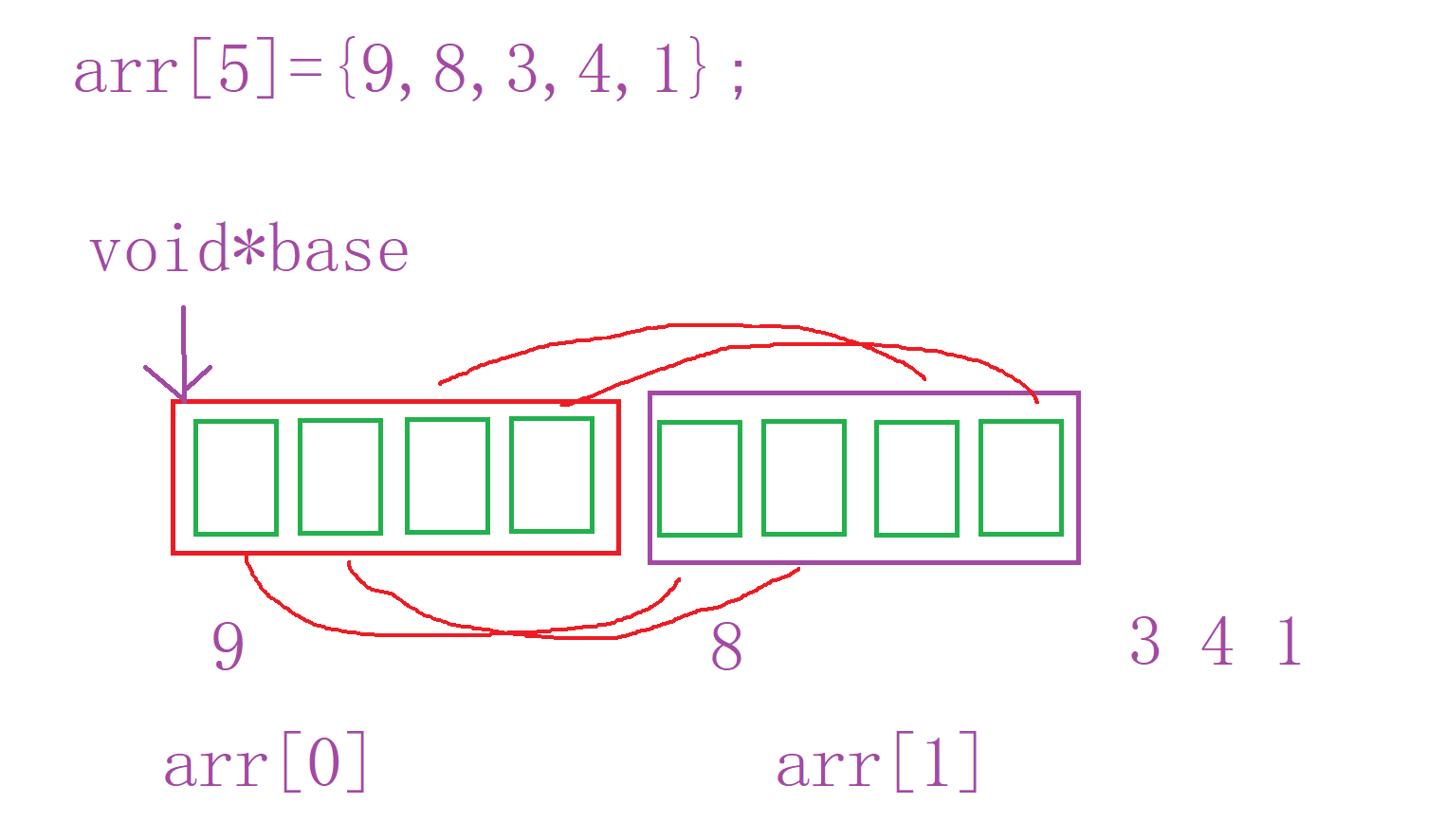
当我们将 base 转换为 char* 类型的指针后,就可以基于字节来操作数据了。以图中的整型数组为例,因为一个 int 类型通常占 4 个字节,所以要交换 arr[0](值为 9)和 arr[1](值为 8)这两个元素,只需要交换它们各自对应的 4 个字节即可。
为了实现对任意类型元素的交换(不同类型元素占用的字节数不同,比如 short 占 2 字节,double 占 8 字节等),我们需要把表示元素字节大小的 width 参数传递给交换函数。然后,在交换函数内部,通过一个 for 循环,逐个交换两个元素对应位置的字节,这样就能完成对任意类型元素的交换操作了。
void swap(char* p1, char* p2, int with)//交换函数
{for (int i = 0; i < with; i++){char tmp = *p1;*p1 = *p2;*p2 = tmp;p1++;p2++;}
}
5.3.4冒泡版本的qsort
之后我们就把这些函数放在一起,再修改下参数就可完成qsort函数的模拟啦。
int cmp_int(const void* p1, const void* p2)//整形比较函数
{return *(int*)p1 - *(int*)p2;//p1p2分别指向// 两个比较数
}
int cmp_stu_by_name(const void* p1, const void* p2)//结构体字符串比较函数
{return strcmp(((struct stu*)p1)->name, ((struct stu*)p2)->name);
}
int cmp_stu_by_age(const void* p1, const void* p2)//结构体整形比较函数
{return ((struct stu*)p1)->age - ((struct stu*)p2)->age;
}
void swap(char* p1, char* p2, int with)//交换函数
{for (int i = 0; i < with; i++){char tmp = *p1;*p1 = *p2;*p2 = tmp;p1++;p2++;}
}
void bubble_sort(void* base, int n, int width, int(*p1)(const void*, const void*))
{for (int i = 0; i < n; i++){for (int j = 0; j < n - 1 - i; j++){if (p1((char*)base + j * width, (char*)base + (j + 1) * width) > 0){swap((char*)base + j * width, (char*)base + (j + 1) * width, width);}}}
}
后言
到这里咱们就把指针的内容全部学完啦!虽然过程艰辛,但我始终相信能让你变优秀的事情没有一件是轻松的!大家回去好好消化理解下指针的内容,今天就分享到这里,咱们下期见!拜拜~