Java 网络原理(一)--- 自定义协议,UDP协议和TCP协议
文章目录
- 网络原理
- 应用层
- 自定义协议
- 几种开发中常见的组织格式
- 传输层(重点)
- UDP
- TCP(非常重要)
- 可靠传输
- 确认应答
- 超时重传
- 连接管理
- 滑动窗口
- 流量控制
- 拥塞控制
- 延时应答
网络原理
应用层
- 在应用层这里都是程序员自定义协议的,(但是也有一些现成的应用层协议)
- 协议,其实是约定,程序员约定好在代码中,数据如何进行传输
自定义协议
- 根据需求,明确要传输的信息
- 约定好信息按照什么形式来组织
自定义协议:请求和响应包含哪些信息,按照什么方式来组织

3. 文本方式构造的协议

几种开发中常见的组织格式
- xml
上古时期的数组数据的格式
现在很少用于网络通信了,但是在后面Java总还会有一些地方遇到
通过标签来组织数据

xml 的优势:让数据的可读性变得更好了
xml 的劣势:
标签写起来非常繁琐,传输的时候也占用更多的带宽(因为既要传输位置信息和用户id,又要传输标签,传输标签占用了带宽)
(maven,就会使用 xml 来管理项目配置了)
- json(当下最流行的一种数据组织的格式)[这个格式在后面会反复用到]

json的优势:可读性比较好,比 xml 更简洁
json的劣势:
同样也是会在网络传输中,消耗额外的带宽(需要把 key 也进行传输的)
即使如此,json还是在网络通信过程中非常流行,除非是一些对性能要求非常高的场景,不使用json外,其他很多地方都可以使用json
- protobuffer:相比于 json 和 xml 来说,protobuffer(简称pb)使用二进制的方式来组织数据,可以保证带宽占用最低(相当于把要传递的信息按照二进制的形式压缩了)
pb的优势:占用带宽最低,传输效率最高,非常适合于对于性能要求比较高的场景
pb的劣势:可读性不好(二进制数据,无法直接进行阅读),一定程度上影响了开发效率
应用层也有现成的应用层协议
其中最广泛使用的是 HTTP协议(超文本传输协议)
超文本(超出文本之外):不仅仅是文本这一个,还可以是图片,视频,音频,字体…
传输层(重点)
面试的考点,工作中常用到的内容
- UDP:无连接,不可靠,面向数据报,全双工
- TCP:有连接,可靠,面向字节流,全双工

也不是说,你有一个 http 的服务器,必须绑定 80 端口(这只是一个建议,完全可以不采纳)
UDP
-
报文格式:
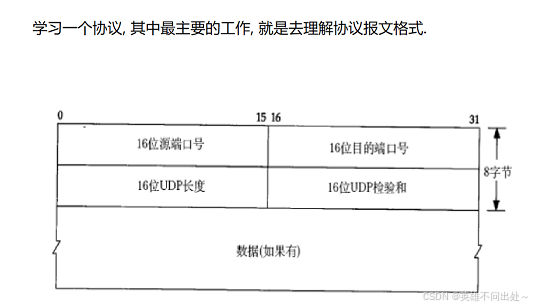
-
UDP 的报文长度为2个字节,0 - 65535
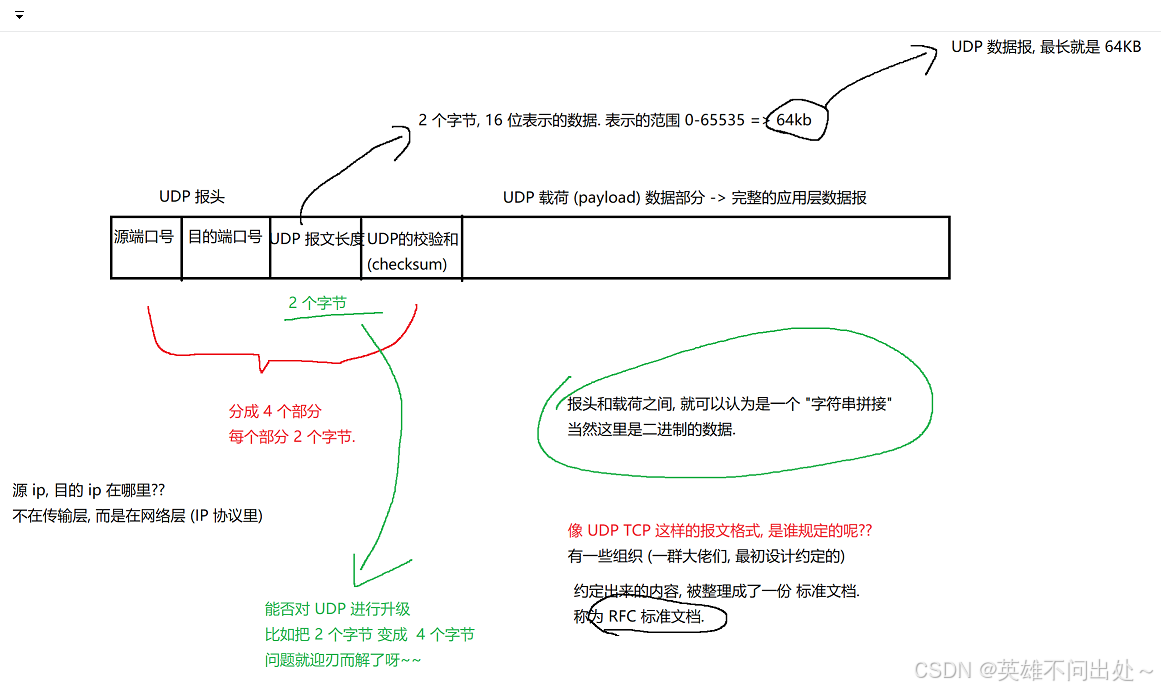
-
UDP的报文长度可以存储的数据大小(64KB - 8byte):

-
效验和的例子:

-
UDP的校验和,效验和是什么?
效验和是一种检查的手段
效验和可以对内容和字数进行检查

-
效验和的过程:

-
效验和是如何计算的?
计算校验和的算法有很多:
1.CRC算法计算UDP的效验和

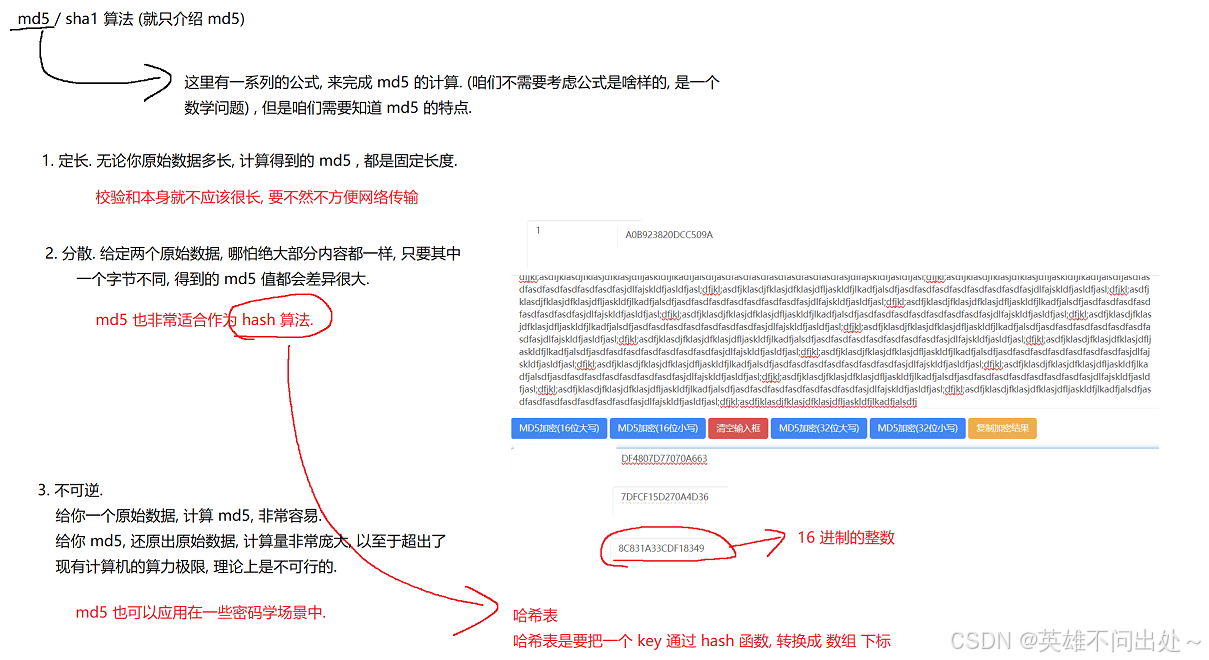
2.md5算法/ sha1算法(md5算法和sha1算法是差不多的,这里就介绍md5算法)
md5算法在工作中常用到
md5算法的特点:

8.UDP的特点(在代码中的体现)
以一个数据报为单位进行传输的
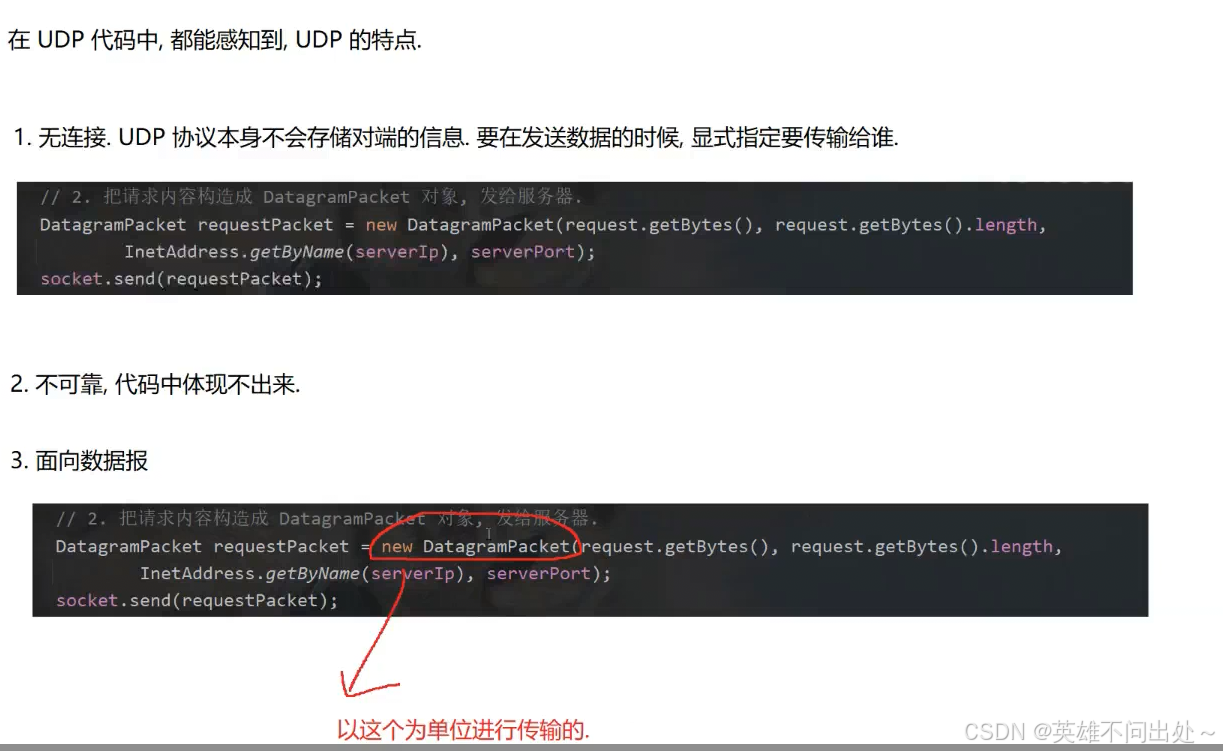
4. 全双工(双向通信)
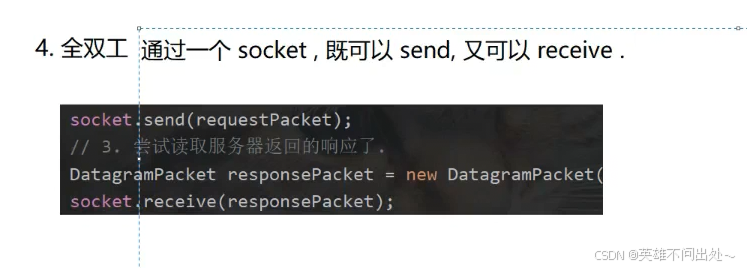
5. 有一些应用层协议是基于UDP进行实现的

TCP(非常重要)
-
TCP最大的特点就是可靠传输(TCP的初心)

-
TCP的报文格式:
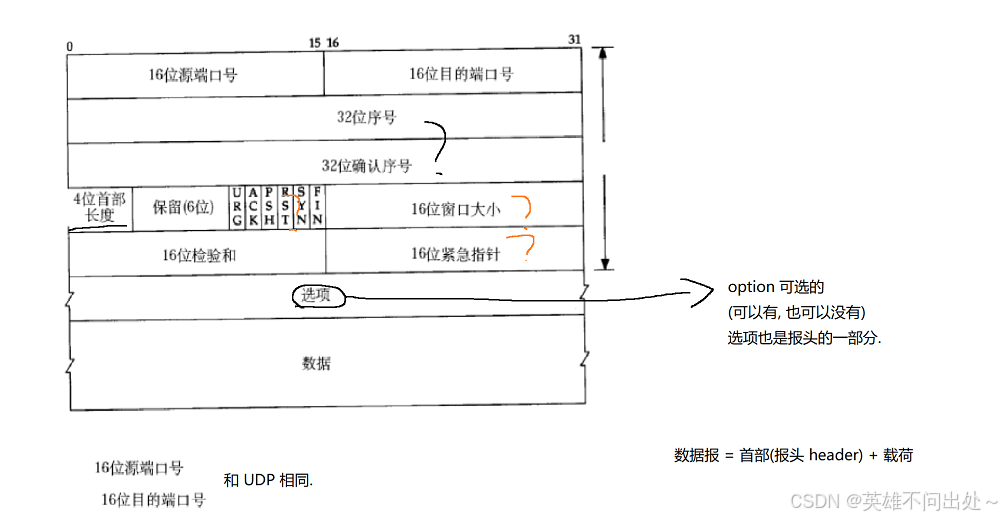

-
TCP的特性,在代码中的体现:
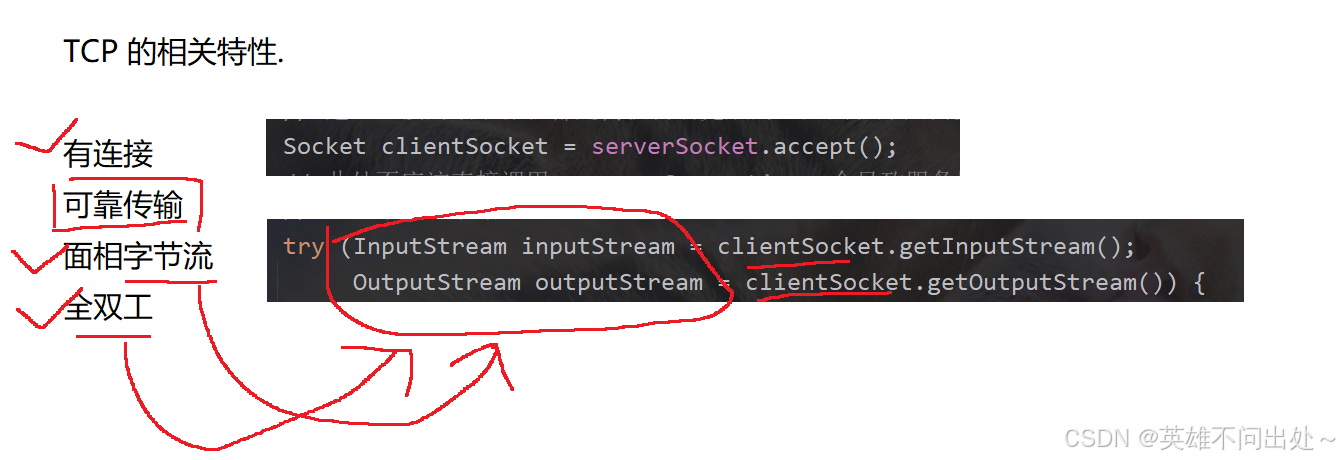
可靠传输
确认应答
- 确认应答
发送方,把数据发送给接收方之后,接收方收到数据就会给发送方返回一个 应答报文(acknowledge,ack)。
发送方如果收到这个应答报文了,就知道自己的数据是否发送成功了
例子:
发送短信消息

短信的后发先至
2. 下面两个条件可以确定发送信息的顺序和准确性

3. 发送信息的编号是按照字节来编号的
4. 字节流编号
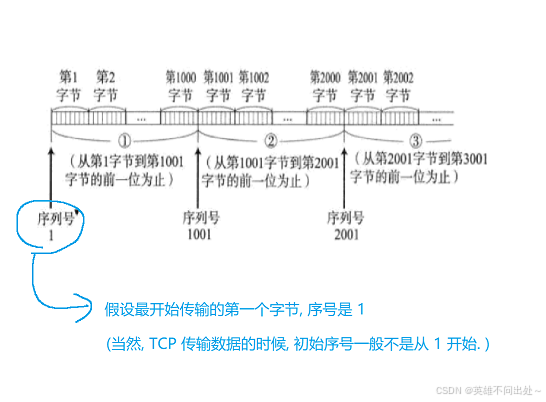
5. 确认应答的过程:
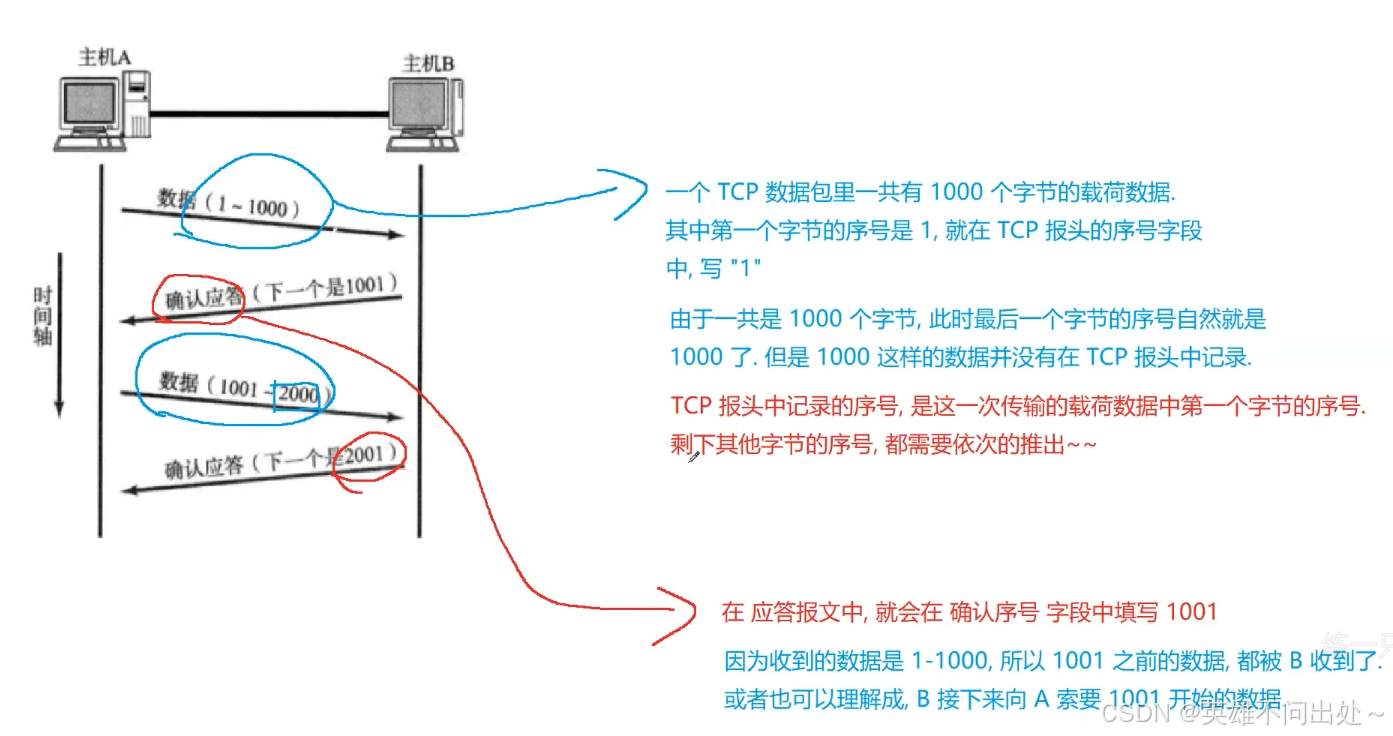
通过特殊的 ack 数据包,里面携带的 确认信号 告诉给发送方,哪些数据已经被确认收到了,此时发送方,就心中有数了,就知道刚发的数据是到了还是没有到,从而达到可靠传输
达成可靠传输的最核心的机制,就是确认应答
通过确认应答为核心的机制,再借助其他机制
辅助,从而达到了可靠传输
- 如何区分一个数据包是普通的数据,还是 ack 应答数据呢?

超时重传
-
确认应答是比较理想的情况,但是在网络传输数据过程中出现了数据丢包,发送方就无法收到应答报文了,超时重传机制,针对确认应答进行补充
-
为什么网络传输过程中会出现丢包?

这里的阻塞,逻辑上和阻塞队列是差不多的,但是实现可能不是我们想的那样

-
丢包是网络传输过程中出现的随机事件,因此在TCP传输过程中,会出现两种类型的丢包
1.传输的数据丢了
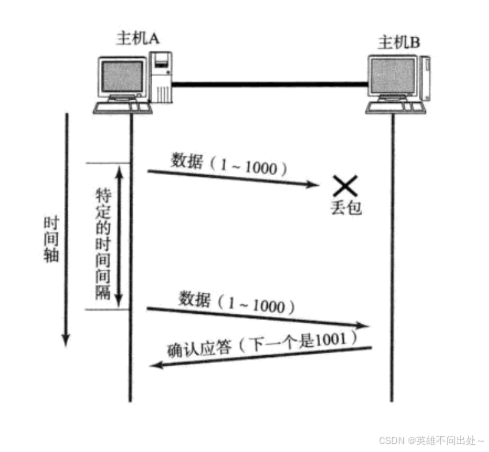
2.返回的ack丢了
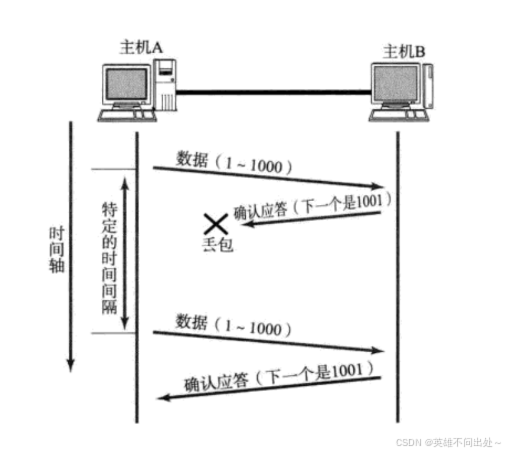
在发送方的角度,是无法区分因为哪种情况产生的丢包,所以无论出现上述哪种情况,发送方都会进行 重新传输,第一次丢了,重新传传试试,很大概率就能传过去
很大概率:假设,丢包的概率是 10%(比较大的数字了)在游戏中,你就玩不了了,
那么两次都丢包的概率是 1% ,所以重传可以大幅提高能够被传过去的概率
重传是一个很好的不就措施,但是引入了 '‘可靠性’’ 之后,也会有代价,有两方面:
1.传输效率下降了
2.复杂程度上升了
重传是得TDP的延迟比较高,而UDP比较小,代价小,延迟比较低
- 超时重传的等待时间:
超过了等待时间,再重传
发送方什么时候进行重传?
发送方,发出数据之后,会等待一段时间,如果这个时间之内,ack来了,此时就自然视为数据到达
如果达到这个时间之后,数据还没到,就会触发重传机制
1.初始的等待时间是可以配置的。不同的系统都不一定一样,也可以通过修改一些内核参数来引起这里的时间变化
2.等待的时间,也会动态变化。每多经历一次超时,等待的时间都会变长。

为什么等待的时间会变长?

数据丢了的情况:

5. 超时重传时,如果是在B的视角,就会收到两条一样的数据,这是如何解决的呢?
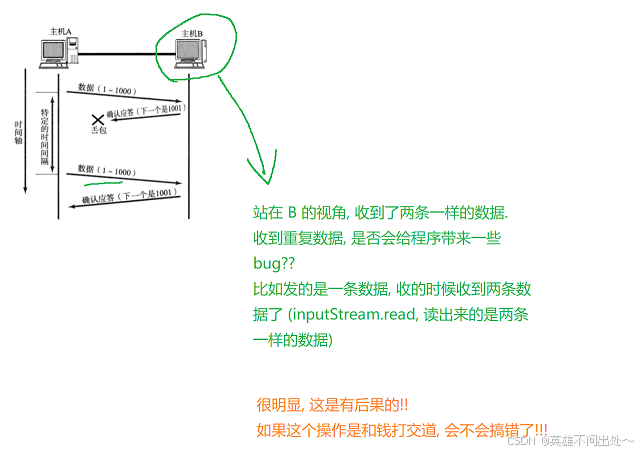
解决方案:TCP会进行去重和重新排序(按照之前发送的顺序来排序)

连接管理
-
连接管理 = 建立连接 + 断开连接
(面试中最经典的问题:三次握手(建立连接) + 四次挥手(断开连接)) -
什么是三次握手和四次挥手?
其实就是发个没有实际内容的数据包的过程
握手就是传输几个没有什么实际意义的数据包,来触发后续的逻辑

握手的例子:

-
TCP的三次握手,TCP在建立连接的过程中,需要通信双方一共 ‘‘打三次招呼’’ 才能够完成连接建立
A想和B建立连接,A就会主动发起握手的操作,实际开发中,主动发起的一方,就是
客户端 ,被动接收的一方,就是 服务器
传输的数据类型可以有:
段 segment
包 packet
报 datagram
帧 frame
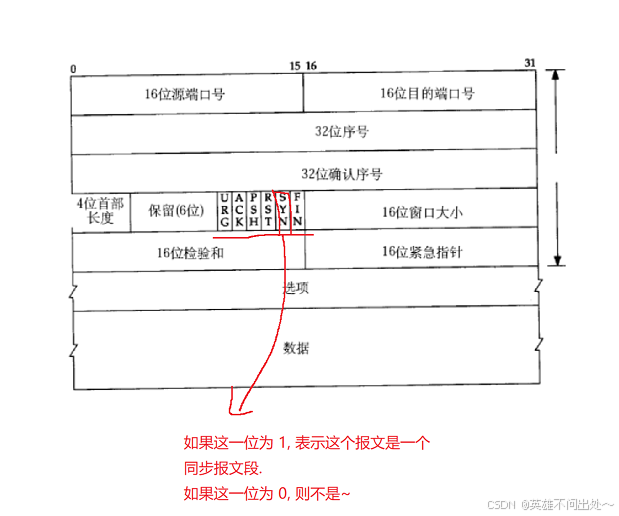
同步报文段:

三次握手建立连接的过程:
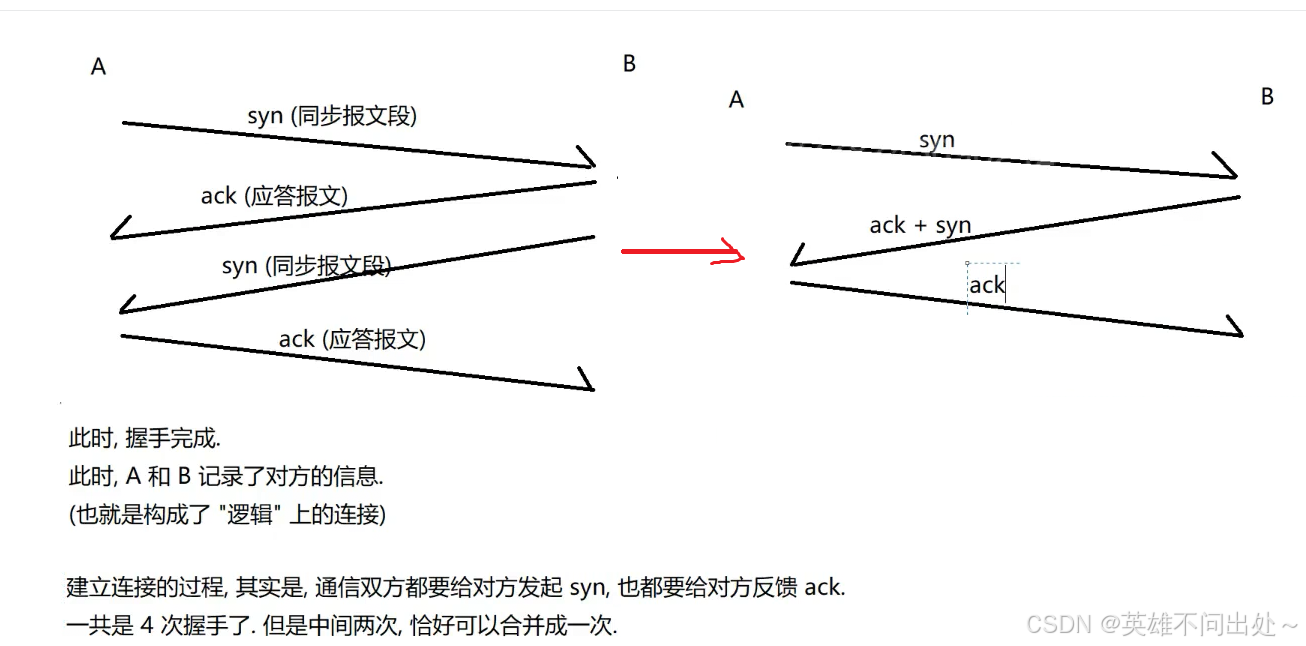
三次握手是网络中最经典的面试题
- 三次握手要解决什么问题?通过四次握手,是否可行?通过两次握手,是否可行呢?
四次握手是可以的,但是没有必要,两个数据合并成一个数据,效率更高,两次握手是不可以的,要让两边都知道对方的信息,第三次握手就是让对方也知道己方的信息的
TCP初心,是为了实现可靠传输,进行确认应答和超时重传的大前提,当前网络环境要是基本可用的,通畅的
如果当前网络已经存在重大故障了,此时,可靠传输无从谈起
三次握手的核心作用:
1.确认当前网络是否是畅通的
2.要让发送方和接收方都能确认自己的发送能力和接受能力均正常
三次握手的例子(非常形象):
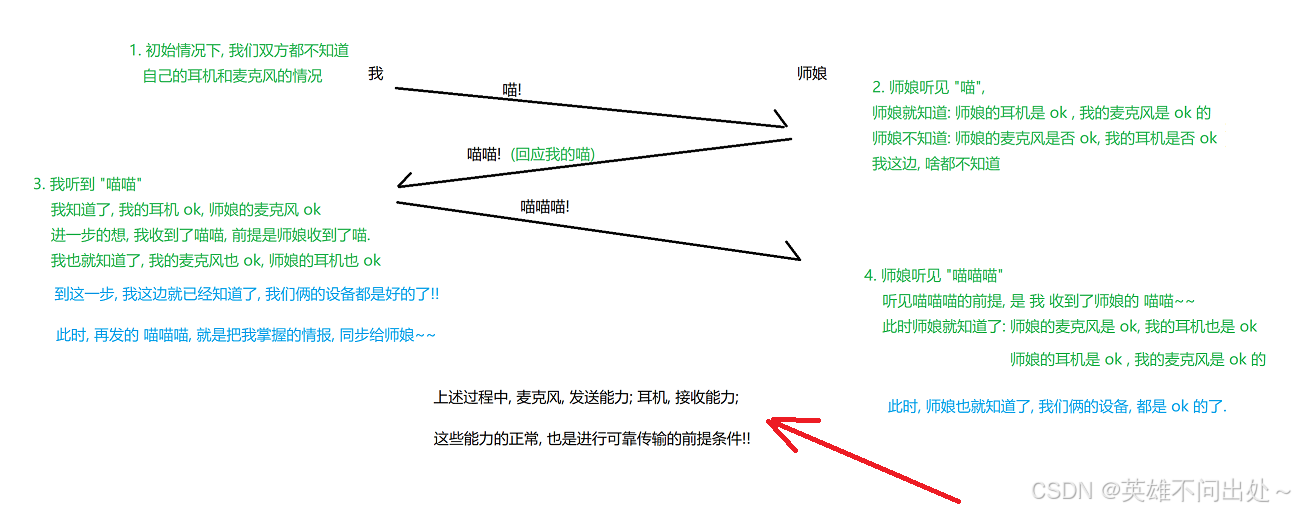
3.让通信双方,在握手的过程中,针对一些重要的参数,进行协商
协商参数的例子:

握手这里要协商的信息是有好几个的,但是我们不讨论,但是大家至少要知道,tcp 通信过程中的序号是从几开始的,这就是双方协商出来的(一般不是从 1 开始的)
每次连接建立的时候,都会协商出一个比较大的,和上次不一样的值
为什么会协商出一个比较大的,和上次不一样的值呢?
是为了区分上次的数据不要影响这次的数据

三次握手的状态
-
sun_sen和syn_rcvd都是很快出现,很快消失的状态
-
连接建立

-
连接断开(四次挥手)
建立连接,一般都是客户端主动发起的。
断开连接,客户端和服务器都可以主动发起。
FIN:结束报文段
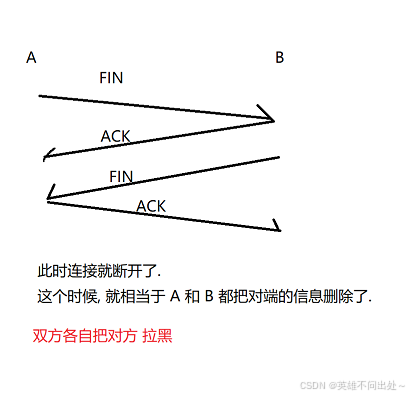
连接断开的过程(四次挥手):
和三次握手不同,此处的四次握手,能否把中间的两次交互合二为一?
不一定
不能的原因:
总的来说就是FIN需要再socket对象close之后,才能被发起,而ACK是系统内核的,能够立即被发起,如果close前面还有代码逻辑,那么他们就不是同一时机了

主要是看时机是否相同,才能够合并
像前面的三次握手,ACK和第二个syn都是内核触发的。同一时机,可以合并。这里的四次挥手,ACK是系统内核触发的,第二个FIN是应用程序执行的 close 触发的。时机不相同,不能合并

能够合并的原因:
TCP中还有一个机制,延时应答,能够拖延ACK的回应时间。一旦 ACK 滞后了,就有机会和下一个 FIN 合并在一起了。
四次挥手的状态:
TIME_WAIT状态的意义:
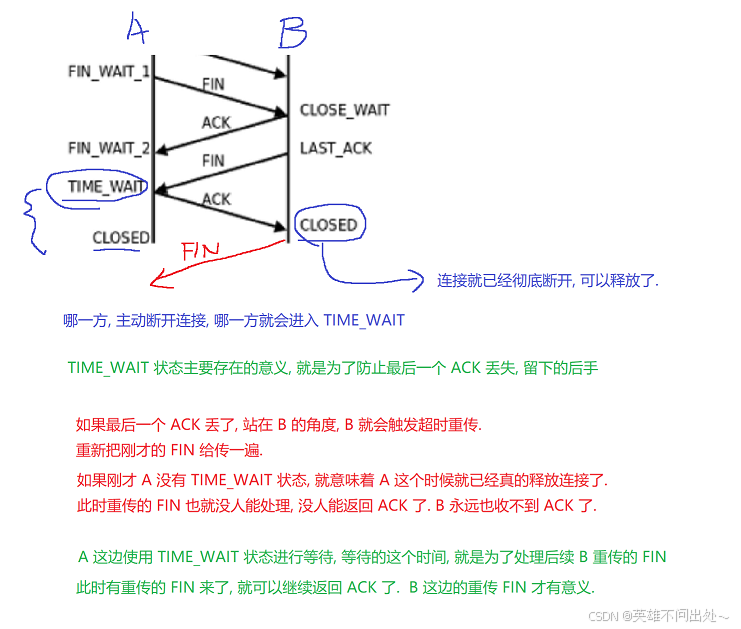
TIME_WAIT 要等待多久呢?
假设网络上两个节点通信消耗的最大时间为 MSL(可配置的参数,数值每台电脑都不太一样,可能是1min,90s这样)。
此时 TIME_WAIT 的时间就是 2 MSL(2 MSL已经是上限了,绝大部分的数据包不会达到这个时间的,都会比这个时间短很多)
面试的时候要把图给画出来,不要只是口述
滑动窗口
-
前面三个机制,都是在保证 tcp 的可靠性,
-
滑动窗口这个机制主要是为了提高效率 -> 亡羊补牢

-
滑动窗口是为了缩短确认应答的等待时间:
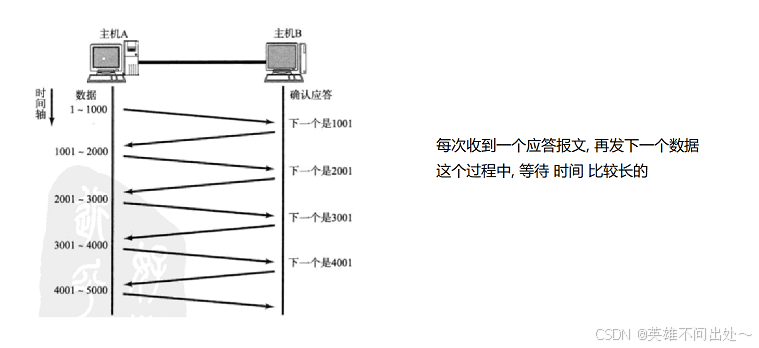
窗口大小(批量发送的数据量的大小):
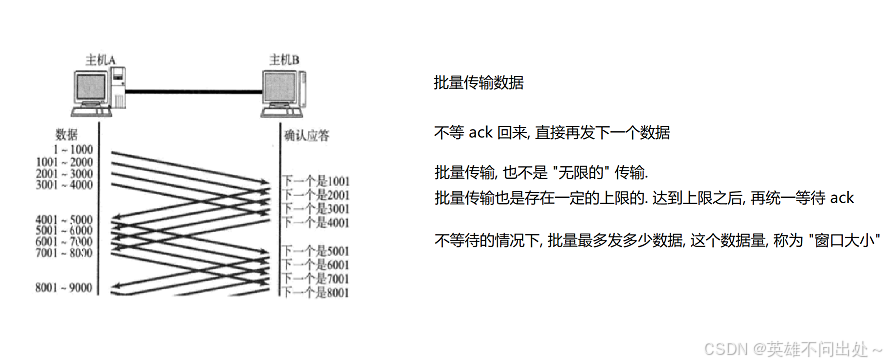
滑动窗口运行的过程:
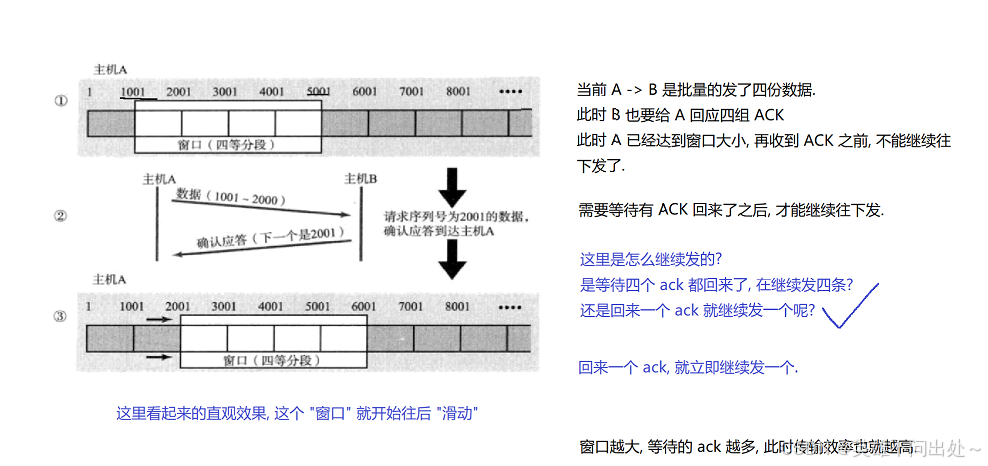
-
TCP的初心是 可靠传输,上面的滑动窗口中,确认应答是可以正常工作的。但是如果出现了丢包应该怎么办?
这里的重传和前面的超时重传,又有变化
分为以下几种情况:
情况一:ack 丢了
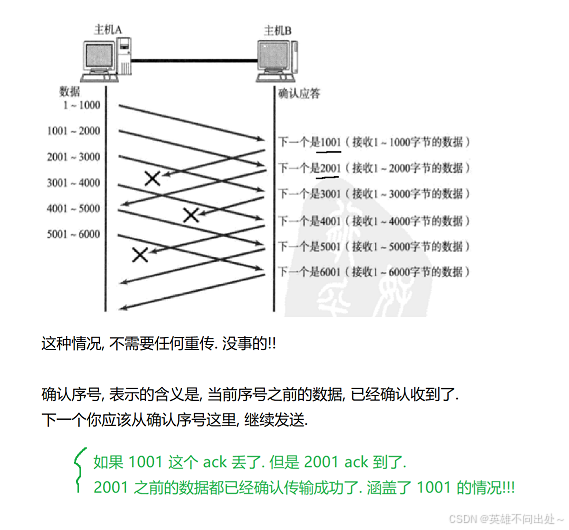
如果 ack 全都丢了呢?
平时丢包率达到 10%,就已经非常高了,现在这个全丢了,丢包率 100% 了,此时相当于网线断了,无从谈起 ‘‘可靠传输’’ 了
这种请况是不太可能出现的
情况二:数据包丢了
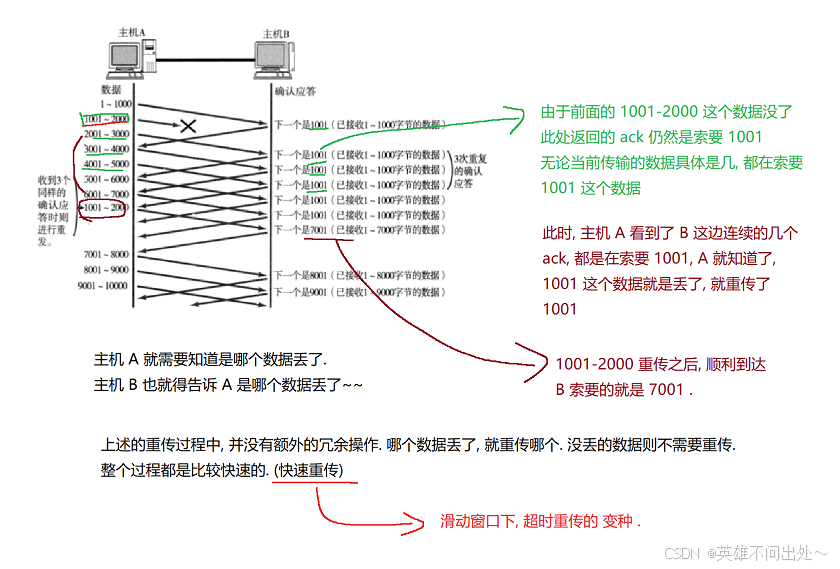
普通的超时重传和快速重传:
如果通信双方,传输的数据的量比较小,也不频繁,就仍然是普通的确认应答和普通的超时重传
如果通信双方,传输的数据量更大,也比较频繁,就会进入到滑动窗口模式,按照快速重传的方式处理
流量控制

- 流量控制:站在接收方的角度,反向制约发送方的传输速率。发送方发送的速率,不应该超过接收方的处理能力。
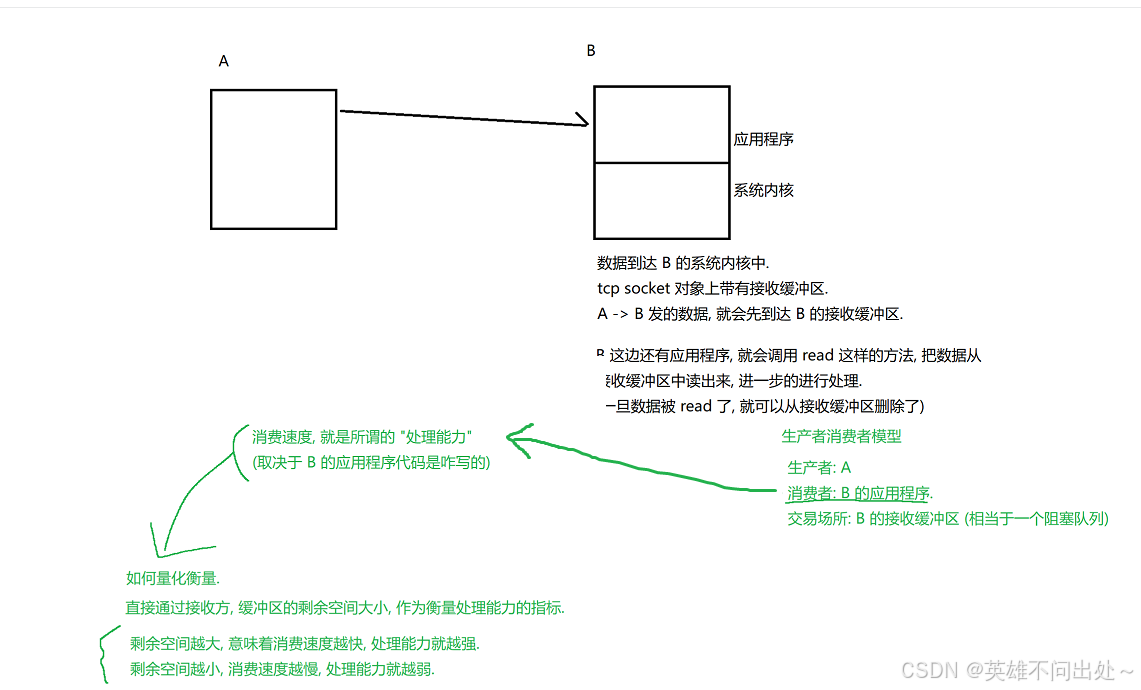
- 如何确认这个发送速率的大小?
接收方每次收到数据之后,都会把接收缓冲区剩余空间大小通过 ack 返回给发送方。发送方就会按照这个数值来调整下一轮的发送速度。
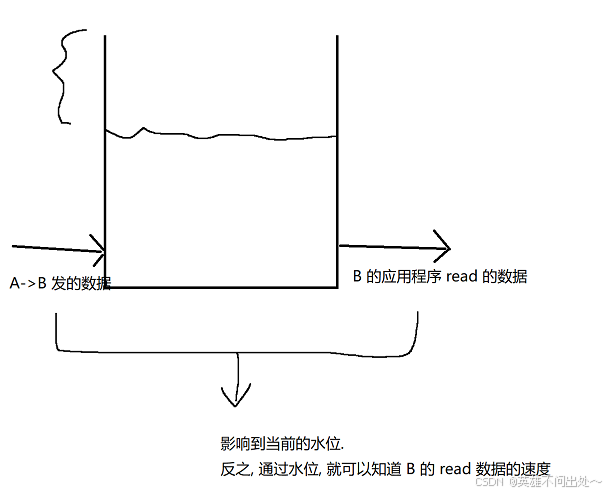
判断接收速率大小(read)的例子:
比如下面这个蓄水池
- 发送的过程:
确认接收方的速率,调整发送方的速率
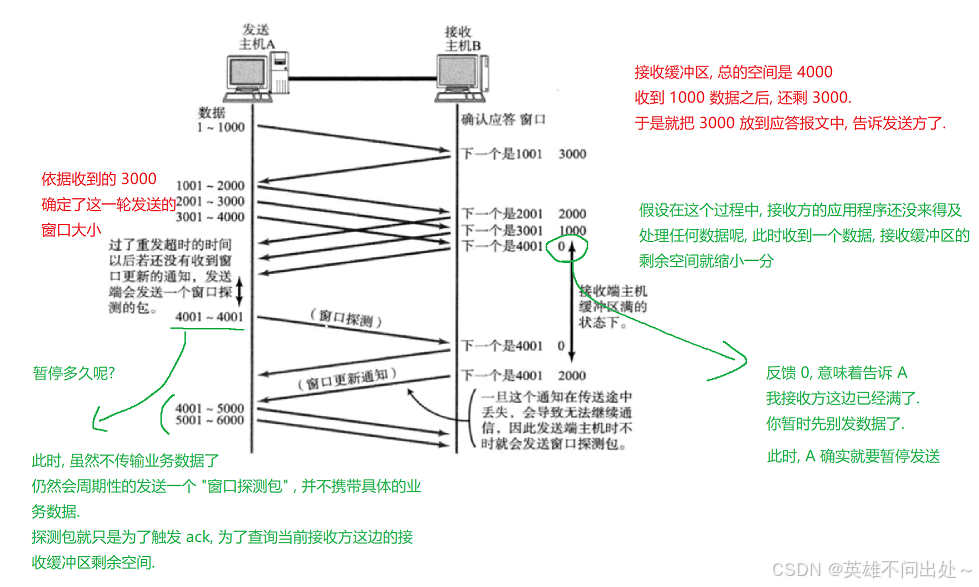
- 接收缓冲区的剩余空间大小:

拥塞控制
-
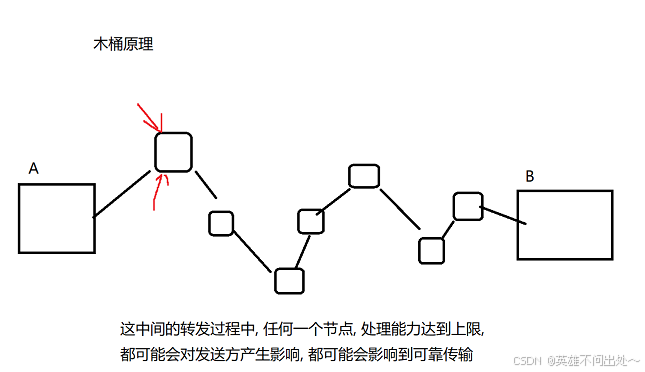
流量控制,是考虑接收方的处理能力。影响速率的,不仅仅是接收方,还有你整个通信的路径。
-
拥塞控制就是考虑通信过程中,中间节点的情况
-
有一个关键的问题:接收方的处理能力,可以量化,而中间节点的结构更复杂,更难直接地进行量化,因此要通过 实验 的方式,来找到合适的值
实验是怎么实验呢?
总得来说,就是如果没有出现丢包,就增大窗口大小,出现了丢包的情况,就缩小这个窗口大小,通过调整,来找到合适的值

4. 找到窗口的合适大小(拥塞控制)的过程:
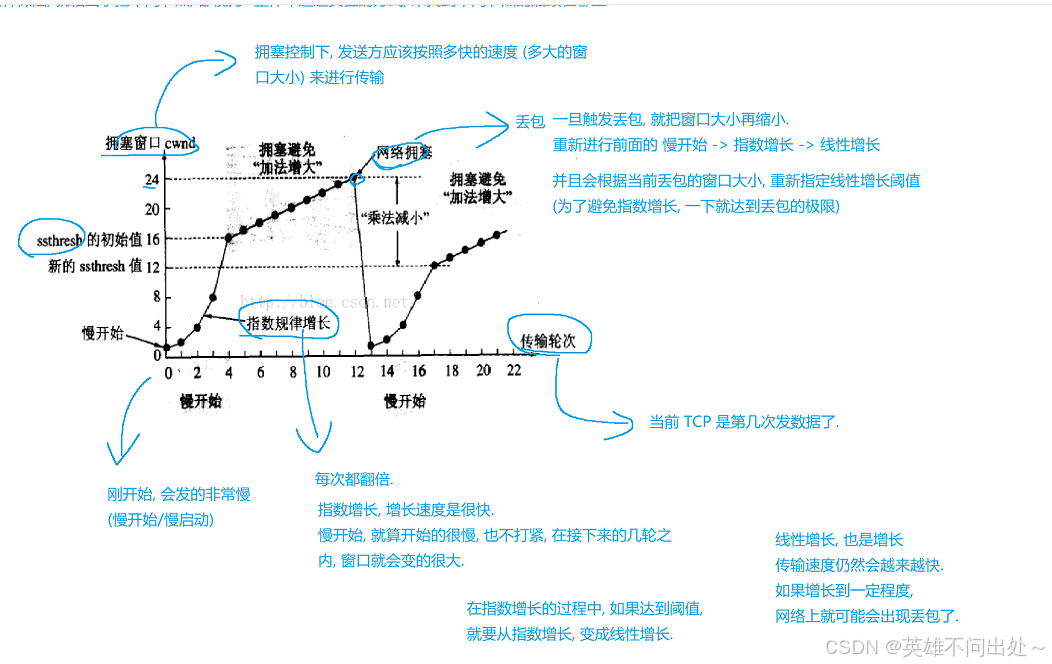
如果问到了上述拥塞控制的情况,要一边画图一边解释
举个例子:
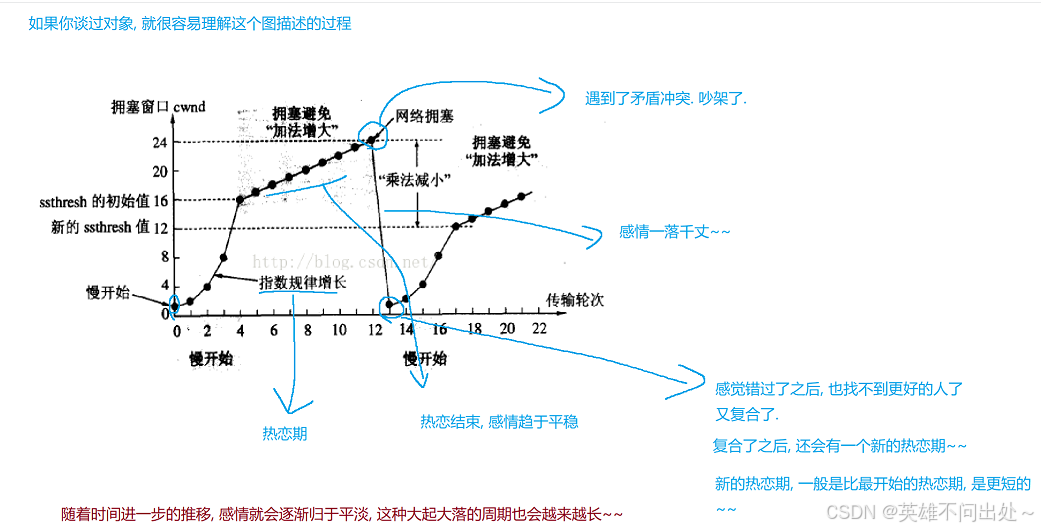
上述是经典版本的拥塞控制的过程:但是还有改进的版本,不要让速率下降这么快,而且前面的有些增长的过程是不会丢包的

5. 流量控制和拥塞控制,都是在限制发送窗口的大小,最终发送窗口的大小,是取 流量控制和拥塞控制 中窗口的较小值
延时应答
-
延时应答:
正常情况:A 把数据传给B,B就会立即返回 ack 给 A
延时应答:也有时候,A 传输给 B,B等一会再返回 ack 给A -
能够延时应答的过程:


-
延时应答才使得刚才的四次挥手,三次能够挥完(接收方延时回答的时间内,处理FIN的过程(代码上处理到close()的过程),然后和 ack 在此时机上一起合并发送给了发送方)