大模型应用开发4-MCP实战
1.MCP简介
1.1 MCP概念理解
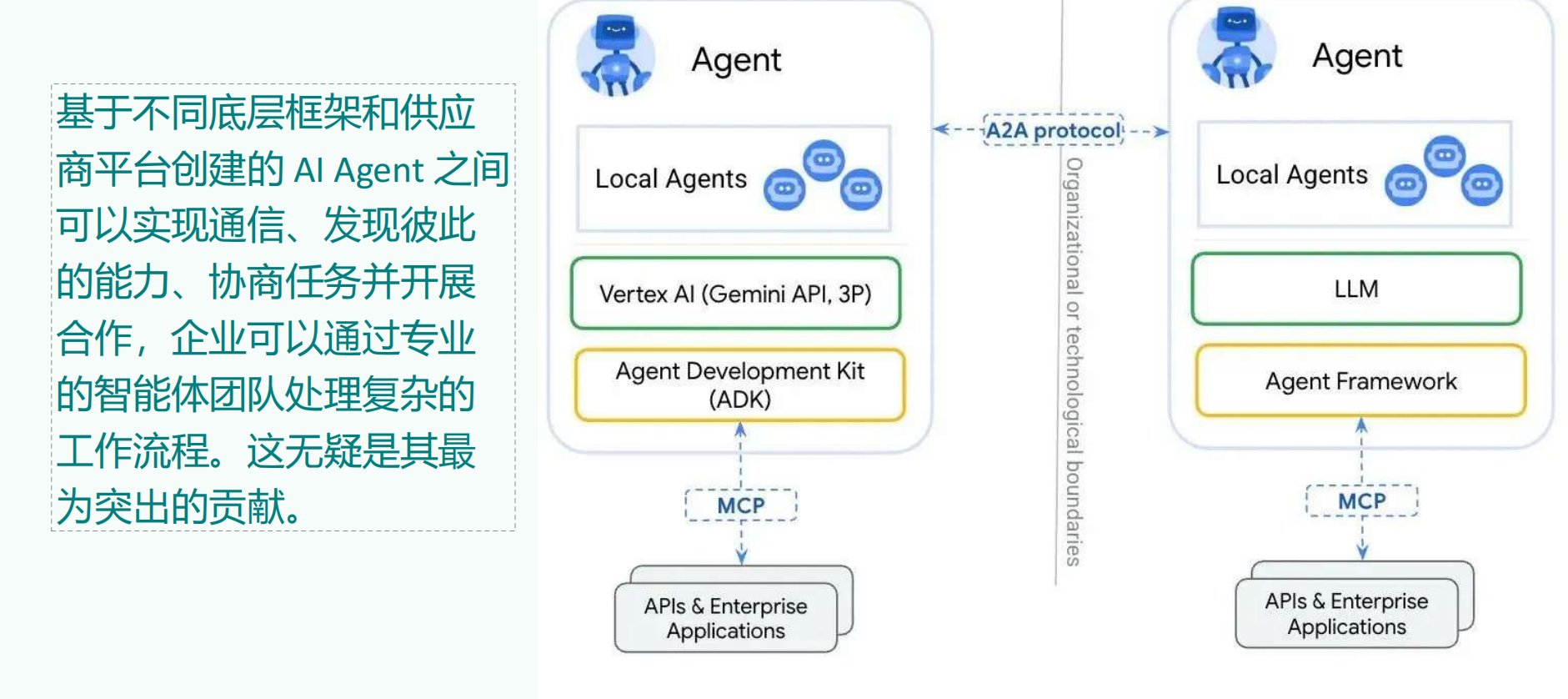
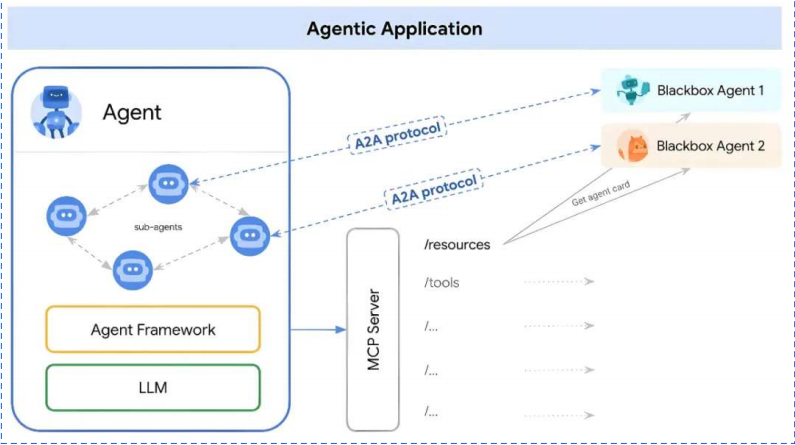
2025年是智能体元年,也注定是智能体集中爆发的一年,但是在AI互联领域中,存在两个重大挑战,一个是Agent与tool之间的交互,另一个是Agent与Agent之间的协作交互,而MCP协议就是为了解决第一个问题而生的。

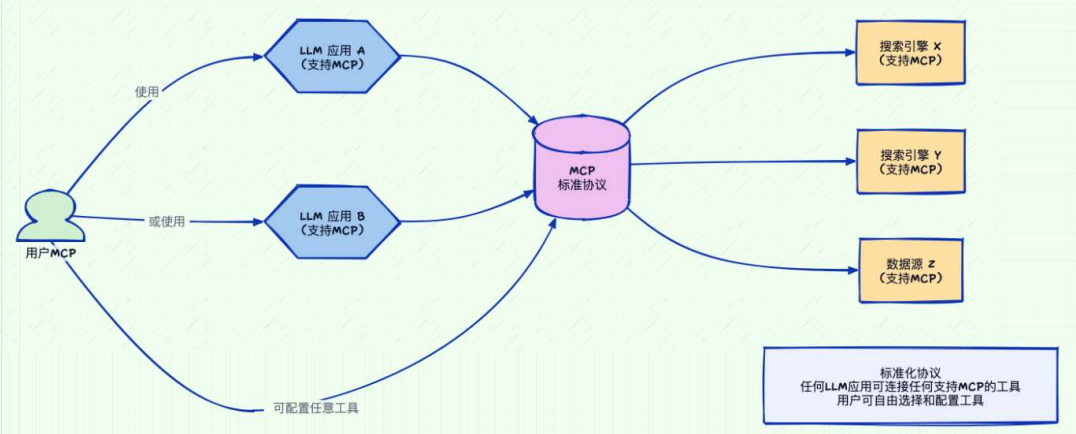
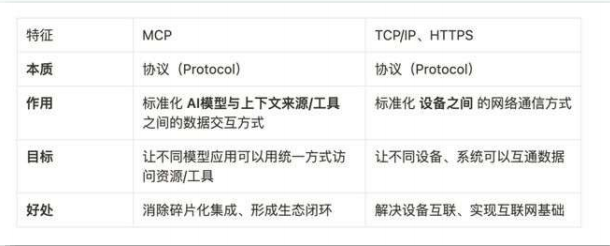
MCP(Model Context Protocol,模型上下文协议) ,2024年11月底,由Anthropic 推出的一种开放标准。旨在为大语言模型(LLM)提供统一的、标准化方式与外部数据源和工具之间进行通信
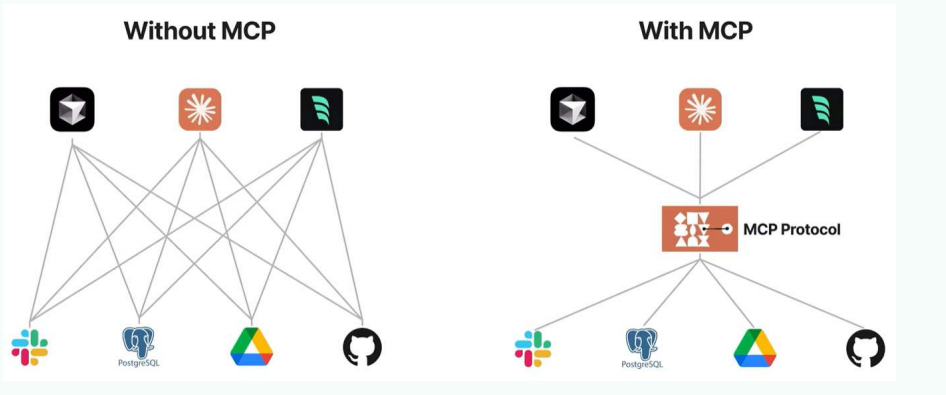
传统AI集成的问题:这种为每个数据源构建独立连接的方式,可以被视为一个M*N问题。
问题:架构碎片化,难以扩展,限制了AI获取必要上下文信息的能力
MCP解决方案:提供统一且可靠的方式来访问所需数据,克服了以往集成方法的局限性。
github查看:
• MCP官方资源:https://github.com/modelcontextprotocol/servers
• MCP热门资源:https://github.com/punkpeye/awesome-mcp-servers
其它平台:
• Glama:https://glama.ai/mcp/servers
• Smithery:https://smithery.ai
• cursor:https://cursor.directory
• MCP.so:https://mcp.so/zh
• 阿里云百炼:https://bailian.console.aliyun.com/?tab=mcp#/mcp-market
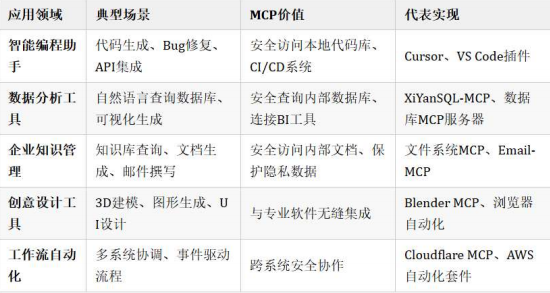
1.2 MCP应用场景:
1.3 MCP通信机制:
根据 MCP 的规范,当前支持两种通信机制(传输方式):
stdio(标准输入输出):主要用在本地服务上,操作你本地的软件或者本地的文件。比如 Blender 这种就只能用 Stdio 因为他没有在线服务。 MCP默认通信方式
优点
• 这种方式适用于客户端和服务器在同一台机器上运行的场景,简单。
• stdio模式无需外部网络依赖,通信速度快,适合快速响应的本地应用。
• 可靠性高,且易于调试
缺点
• Stdio 的配置比较复杂,我们需要做些准备工作,你需要提前安装需要的命令行工具。
• stdio模式为单进程通信,无法并行处理多个客户端请求,同时由于进程资源开销较大,不适合
在本地运行大量服务。(限制了其在更复杂分布式场景中的使用)
SSE(Server-Sent Events):主要用在远程通信服务上,这个服务本身就有在线的 API,比如访问你的谷歌邮件,天气情况等。
场景
• SSE方式适用于客户端和服务器位于不同物理位置的场景。
• 适用于实时数据更新、消息推送、轻量级监控和实时日志流等场景
• 对于分布式或远程部署的场景,基于 HTTP 和 SSE 的传输方式则更为合适。
优点
• 配置方式非常简单,基本上就一个链接就行,直接复制他的链接填上就行
2.MCP集成使用
2.1stdio本地环境安装:
stdio的本地环境有两种: 一种是Python 编写的服务, 一种用TypeScript 编写的服务,分别对应着uvx 和 npx 两种指令。
uvx安装:
第1种:若已配置Python环境,可使用以下命令安装:
pip install uv第2种:在Windows下可以通过PowerShell运行命令来安装uv。
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex”验证:重启终端并运行以下命令检查是否正常:
uv --version
uvx --help集成在node环境中,配置node环境即可。
2.2 MCP原理
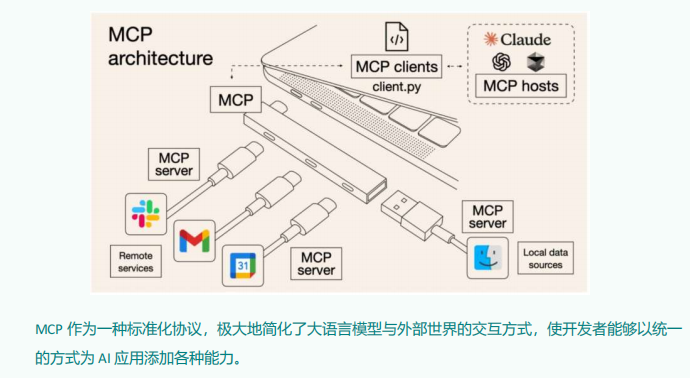
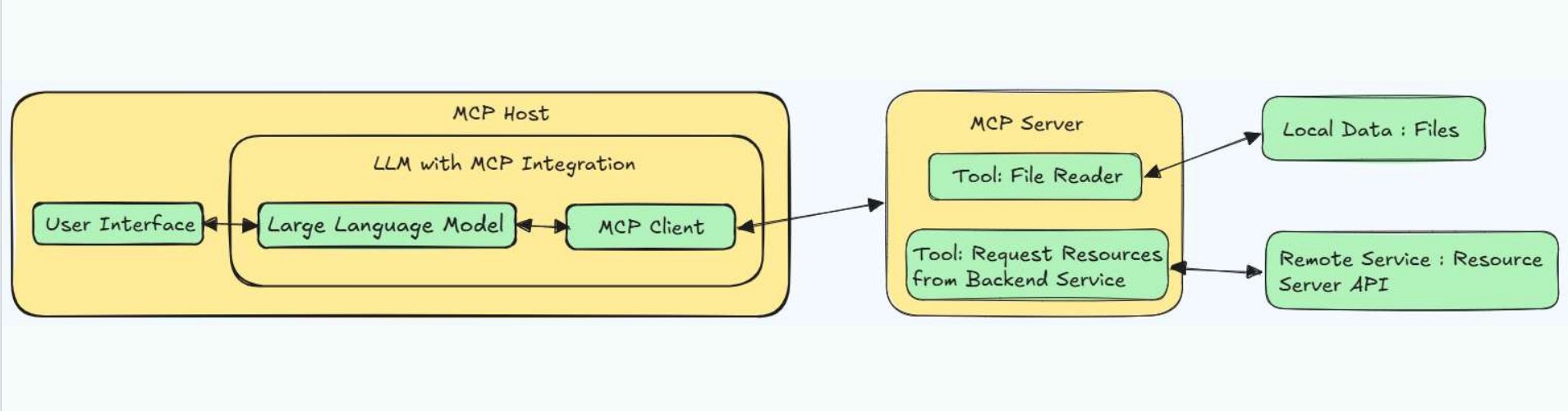
2.3.1 MCP的C-S架构:
MCP Host:
作为运行 MCP 的主应用程序,例如 Claude Desktop、Cursor、Cline 或 AI 工具。为用户提供与LLM交互的接口,同时集成 MCP Client 以连接 MCP Server。
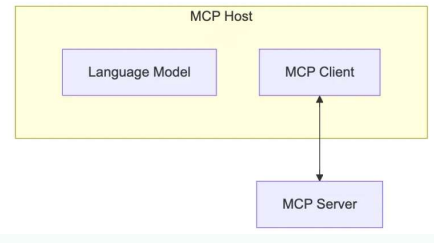
MCP client 充当 LLM 和 MCP server 之间的桥梁,嵌入在主机程序中,主要负责:
• 接收来自LLM的请求;
• 将请求转发到相应的 MCP server
• 将 MCP server 的结果返回给 LLM

MCP 官网(https://modelcontextprotocol.io/clients) 列出来一些支持 MCP 的 Clients。
分为两类:
• AI编程IDE:Cursor、Cline、Continue、Sourcegraph、Windsurf 等
• 聊天客户端:Cherry Studio、Claude、Librechat、Chatwise等
更多的Client参考这里:
MCP Clients:https://www.pulsemcp.com/clients
Awesome MCP Clients:https://github.com/punkpeye/awesome-mcp-clients/
MCPServer:
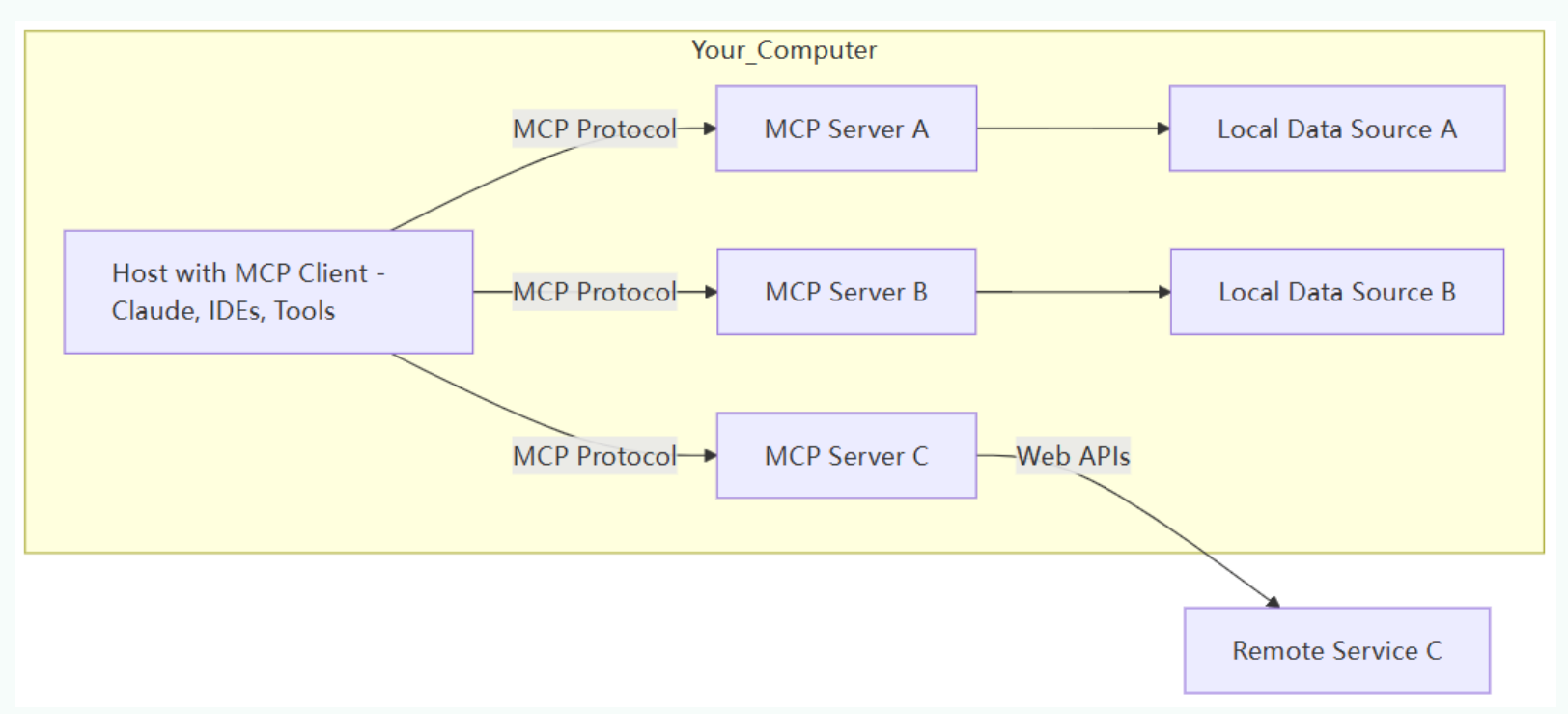
每个 MCP 服务器都提供了一组特定的工具,负责从本地数据或远程服务中检索信息。是 MCP 架构中的关键组件。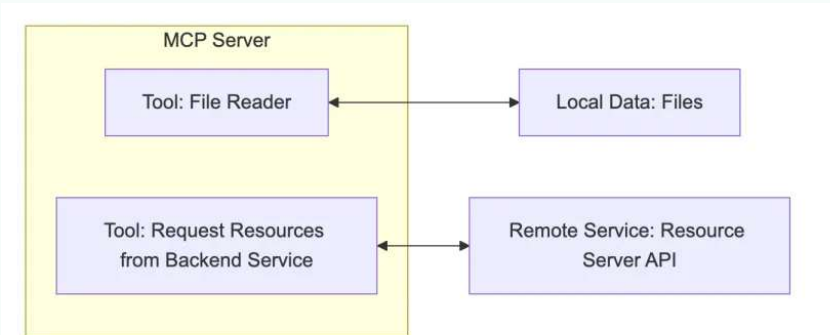
与传统的远程 API 服务器不同,MCP 服务器既可以作为本地应用程序在用户设备上运行,也可部署至远程服务器。其中本地应用程序采用stdio的方式,远程服务器采用SSE方式。
比如你让助手:
• “帮我查航班信息” → 它调用航班查询 API
• “算一下 37% 折扣后多少钱” → 它运行计算器函数
作用:让 LLM 不仅能“说”,还能“做”(执行代码、查询数据等)。
MCP Server本质是运行在电脑上的一个nodejs或python程序。可以理解为客户端用命令行调用了
电脑上的nodejs或python程序。
• 使用 TypeScript 编写的 MCP server 可以通过 npx 命令来运行
• 使用 Python 编写的 MCP server 可以通过 uvx 命令来运行。
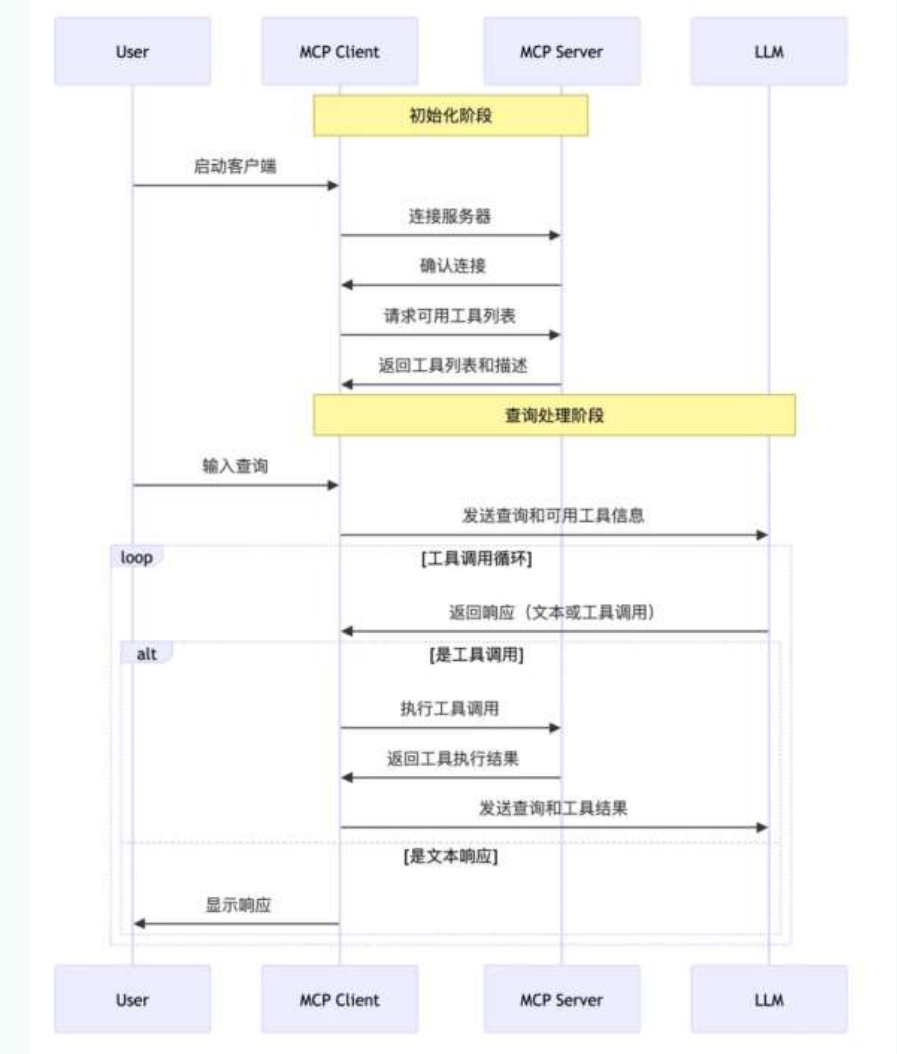
2.3.2 MCP工作流程
API 主要有两个
• tools/list:列出 Server 支持的所有工具
• tools/call:Client 请求 Server 去执行某个工具,并将结果返回
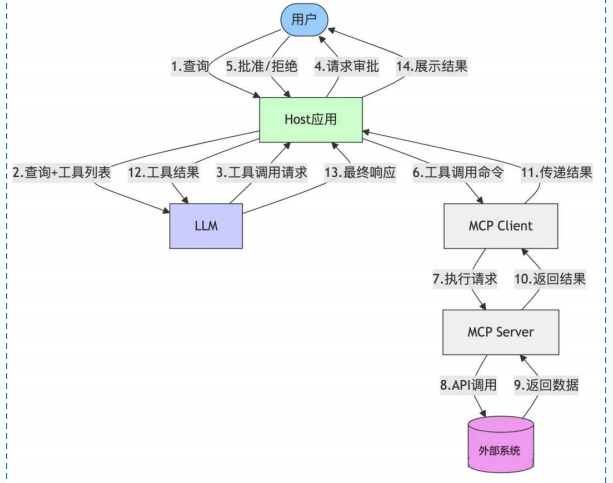
数据流向图:
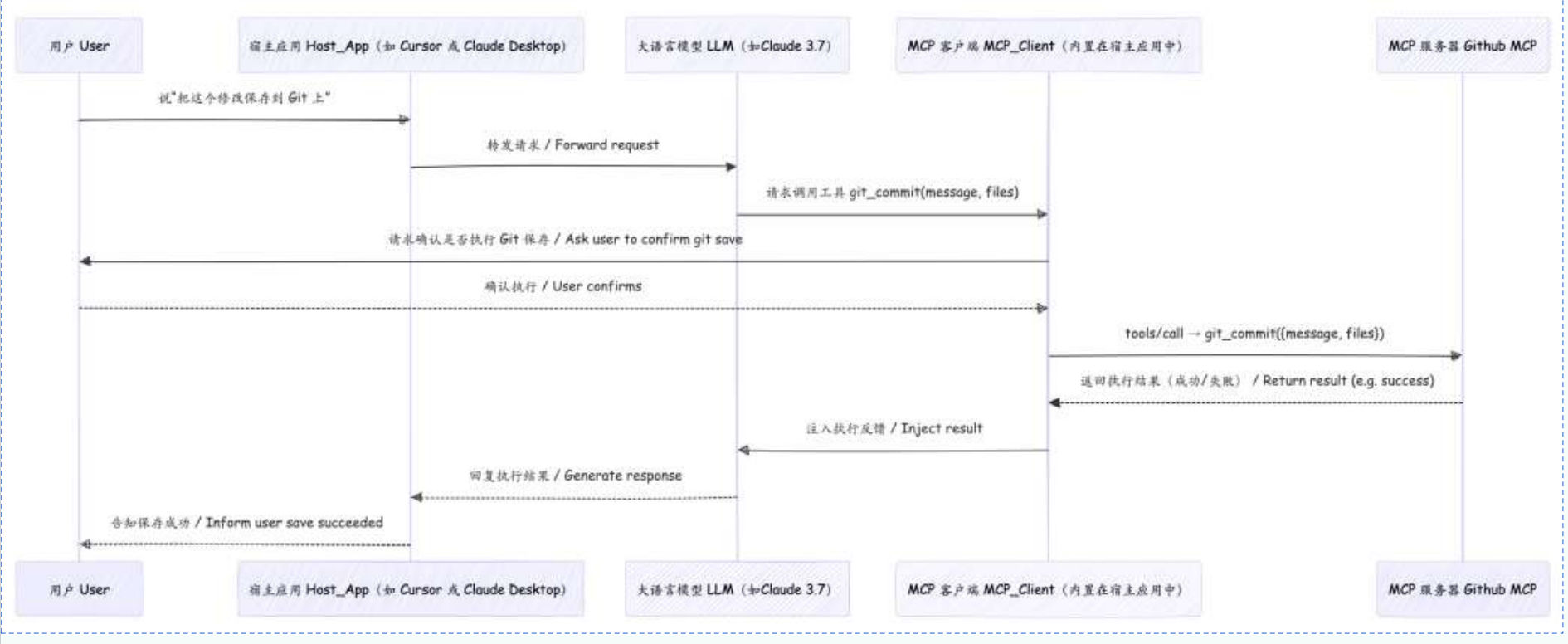
Cursor使用MCP:
3.手动开发MCP项目
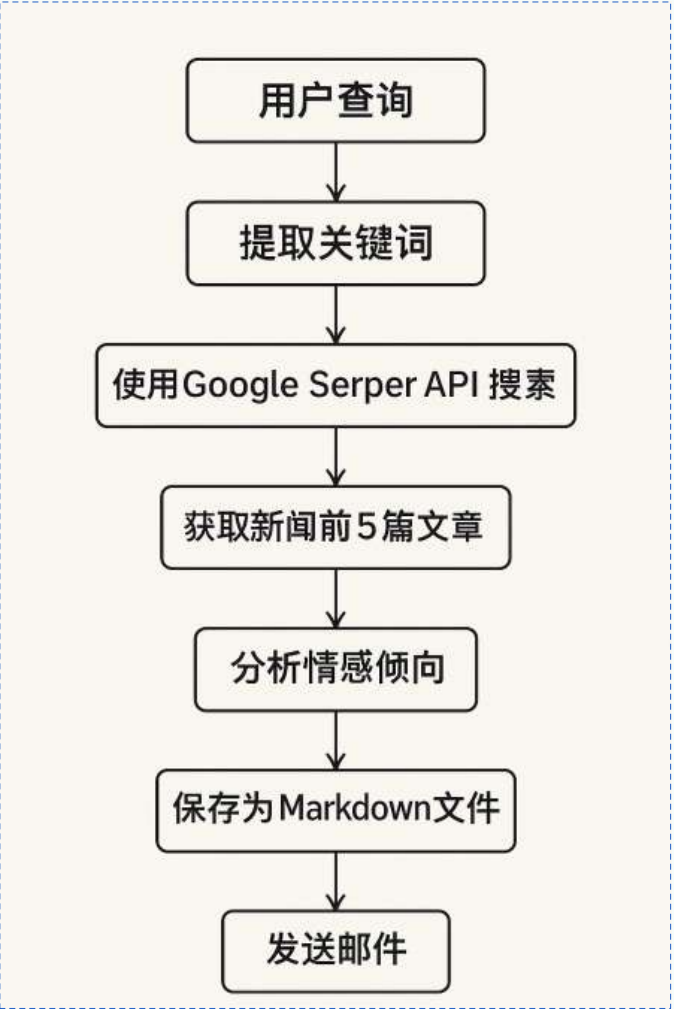
系统整体采用C-S架构
3.1 MCP环境准备
pip install uv
#或者
conda install uv #针对于安装了Anoconda环境的用户创建MCP项目:
uv init mcp-project
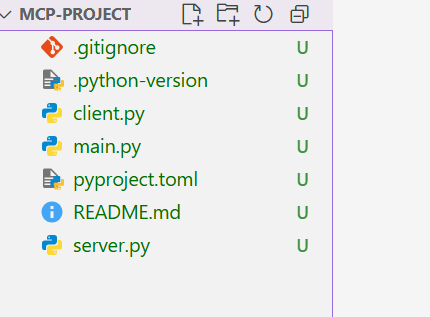
3.2 代码实现
3.2.1 配置大模型参数:
BASE_URL="https://dashscope.aliyuncs.com/compatible-mode/v1"
MODEL=qwen-plus
DASHSCOPE_API_KEY=""SERPER_API_KEY="618b99091160938bb51b5968aad7312428bbba76"
SMTP_SERVER=smtp.163.com
SMTP_PORT=465
EMAIL_USER=code14pudding@163.com
EMAIL_PASS=AZeDNekeCx6Ht3Vr3.2.2 client配置:
总体架构:

import asyncio
import os
import json
from typing import Optional, List
from contextlib import AsyncExitStack
from datetime import datetime
import re
from openai import OpenAI
from dotenv import load_dotenv
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
load_dotenv()class MCPClient:# 配置客户端def __init__(self):self.exit_stack = AsyncExitStack()self.openai_api_key = os.getenv("DASHSCOPE_API_KEY")self.base_url = os.getenv("BASE_URL")self.model = os.getenv("MODEL")if not self.openai_api_key:raise ValueError("❌ 未找到 OpenAI API Key,请在 .env 文件中设置 DASHSCOPE_API_KEY")self.client = OpenAI(api_key=self.openai_api_key, base_url=self.base_url)self.session: Optional[ClientSession] = None# 连接到服务器async def connect_to_server(self, server_script_path: str):# 对服务器脚本进行判断,只允许是 .py 或 .jsis_python = server_script_path.endswith('.py')is_js = server_script_path.endswith('.js')if not (is_python or is_js):raise ValueError("服务器脚本必须是 .py 或 .js 文件")# 确定启动命令,.py 用 python,.js 用 nodecommand = "python" if is_python else "node"# 构造 MCP 所需的服务器参数,包含启动命令、脚本路径参数、环境变量(为 None 表示默认)server_params = StdioServerParameters(command=command, args=[server_script_path], env=None)# 启动 MCP 工具服务进程(并建立 stdio 通信)stdio_transport = await self.exit_stack.enter_async_context(stdio_client(server_params))# 拆包通信通道,读取服务端返回的数据,并向服务端发送请求self.stdio, self.write = stdio_transport# 创建 MCP 客户端会话对象self.session = await self.exit_stack.enter_async_context(ClientSession(self.stdio, self.write))# 初始化会话await self.session.initialize()# 获取工具列表并打印response = await self.session.list_tools()tools = response.toolsprint("\n已连接到服务器,支持以下工具:", [tool.name for tool in tools])# 请求处理async def process_query(self, query: str) -> str:# 准备初始消息和获取工具列表messages = [{"role": "user", "content": query}]response = await self.session.list_tools()available_tools = [{"type": "function","function": {"name": tool.name,"description": tool.description,"input_schema": tool.inputSchema}} for tool in response.tools]# 提取问题的关键词,对文件名进行生成。# 在接收到用户提问后就应该生成出最后输出的 md 文档的文件名,# 因为导出时若再生成文件名会导致部分组件无法识别该名称。keyword_match = re.search(r'(关于|分析|查询|搜索|查看)([^的\s,。、?\n]+)', query)keyword = keyword_match.group(2) if keyword_match else "分析对象"safe_keyword = re.sub(r'[\\/:*?"<>|]', '', keyword)[:20]timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')md_filename = f"sentiment_{safe_keyword}_{timestamp}.md"md_path = os.path.join("./sentiment_reports", md_filename)# 更新查询,将文件名添加到原始查询中,使大模型在调用工具链时可以识别到该信息# 然后调用 plan_tool_usage 获取工具调用计划query = query.strip() + f" [md_filename={md_filename}] [md_path={md_path}]"messages = [{"role": "user", "content": query}]tool_plan = await self.plan_tool_usage(query, available_tools)tool_outputs = {}messages = [{"role": "user", "content": query}]# 依次执行工具调用,并收集结果for step in tool_plan:tool_name = step["name"]tool_args = step["arguments"]for key, val in tool_args.items():if isinstance(val, str) and val.startswith("{{") and val.endswith("}}"):ref_key = val.strip("{} ")resolved_val = tool_outputs.get(ref_key, val)tool_args[key] = resolved_val# 注入统一的文件名或路径(用于分析和邮件)if tool_name == "analyze_sentiment" and "filename" not in tool_args:tool_args["filename"] = md_filenameif tool_name == "send_email_with_attachment" and "attachment_path" not in tool_args:tool_args["attachment_path"] = md_pathresult = await self.session.call_tool(tool_name, tool_args)tool_outputs[tool_name] = result.content[0].textmessages.append({"role": "tool","tool_call_id": tool_name,"content": result.content[0].text})# 调用大模型生成回复信息,并输出保存结果final_response = self.client.chat.completions.create(model=self.model,messages=messages)final_output = final_response.choices[0].message.content# 对辅助函数进行定义,目的是把文本清理成合法的文件名def clean_filename(text: str) -> str:text = text.strip()text = re.sub(r'[\\/:*?\"<>|]', '', text)return text[:50]# 使用清理函数处理用户查询,生成用于文件命名的前缀,并添加时间戳、设置输出目录# 最后构建出完整的文件路径用于保存记录safe_filename = clean_filename(query)timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')filename = f"{safe_filename}_{timestamp}.txt"output_dir = "./llm_outputs"os.makedirs(output_dir, exist_ok=True)file_path = os.path.join(output_dir, filename)# 将对话内容写入 md 文档,其中包含用户的原始提问以及模型的最终回复结果with open(file_path, "w", encoding="utf-8") as f:f.write(f"🗣 用户提问:{query}\n\n")f.write(f"🤖 模型回复:\n{final_output}\n")print(f"📄 对话记录已保存为:{file_path}")return final_output# 用户和客户端交互的入口async def chat_loop(self):# 初始化提示信息print("\n🤖 MCP 客户端已启动!输入 'quit' 退出")# 进入主循环中等待用户输入while True:try:query = input("\n你: ").strip()if query.lower() == 'quit':break# 处理用户的提问,并返回结果response = await self.process_query(query)print(f"\n🤖 AI: {response}")except Exception as e:print(f"\n⚠️ 发生错误: {str(e)}")# 任务拆解async def plan_tool_usage(self, query: str, tools: List[dict]) -> List[dict]:# 构造系统提示词 system_prompt。# 将所有可用工具组织为文本列表插入提示中,并明确指出工具名,# 限定返回格式是 JSON,防止其输出错误格式的数据。print("\n📤 提交给大模型的工具定义:")print(json.dumps(tools, ensure_ascii=False, indent=2))tool_list_text = "\n".join([f"- {tool['function']['name']}: {tool['function']['description']}"for tool in tools])system_prompt = {"role": "system","content": ("你是一个智能任务规划助手,用户会给出一句自然语言请求。\n""你只能从以下工具中选择(严格使用工具名称):\n"f"{tool_list_text}\n""如果多个工具需要串联,后续步骤中可以使用 {{上一步工具名}} 占位。\n""返回格式:JSON 数组,每个对象包含 name 和 arguments 字段。\n""不要返回自然语言,不要使用未列出的工具名。")}# 构造对话上下文并调用模型。# 将系统提示和用户的自然语言一起作为消息输入,并选用当前的模型。planning_messages = [system_prompt,{"role": "user", "content": query}]response = self.client.chat.completions.create(model=self.model,messages=planning_messages,tools=tools,tool_choice="none")# 提取出模型返回的 JSON 内容content = response.choices[0].message.content.strip()match = re.search(r"```(?:json)?\\s*([\s\S]+?)\\s*```", content)if match:json_text = match.group(1)else:json_text = content# 在解析 JSON 之后返回调用计划try:plan = json.loads(json_text)return plan if isinstance(plan, list) else []except Exception as e:print(f"❌ 工具调用链规划失败: {e}\n原始返回: {content}")return []async def cleanup(self):await self.exit_stack.aclose()async def main():server_script_path = "E:\HeiMa\AI\MCP实战\舆情分析助手\mcp-project\server.py"client = MCPClient()try:await client.connect_to_server(server_script_path)await client.chat_loop()finally:await client.cleanup()if __name__ == "__main__":asyncio.run(main())
3.2.3 Server配置
import os
import json
import smtplib
from datetime import datetime
from email.message import EmailMessageimport httpx
from mcp.server.fastmcp import FastMCP
from dotenv import load_dotenv
from openai import OpenAI# 加载环境变量
load_dotenv()# 初始化 MCP 服务器
mcp = FastMCP("NewsServer")# @mcp.tool() 是 MCP 框架的装饰器,表明这是一个 MCP 工具。之后是对这个工具功能的描述
@mcp.tool()
async def search_google_news(keyword: str) -> str:"""使用 Serper API(Google Search 封装)根据关键词搜索新闻内容,返回前5条标题、描述和链接。参数:keyword (str): 关键词,如 "小米汽车"返回:str: JSON 字符串,包含新闻标题、描述、链接"""# 从环境中获取 API 密钥并进行检查api_key = os.getenv("SERPER_API_KEY")if not api_key:return "❌ 未配置 SERPER_API_KEY,请在 .env 文件中设置"# 设置请求参数并发送请求url = "https://google.serper.dev/news"headers = {"X-API-KEY": api_key,"Content-Type": "application/json"}payload = {"q": keyword}async with httpx.AsyncClient() as client:response = await client.post(url, headers=headers, json=payload)data = response.json()# 检查数据,并按照格式提取新闻,返回前五条新闻if "news" not in data:return "❌ 未获取到搜索结果"articles = [{"title": item.get("title"),"desc": item.get("snippet"),"url": item.get("link")} for item in data["news"][:5]]# 将新闻结果以带有时间戳命名后的 JSON 格式文件的形式保存在本地指定的路径output_dir = "./google_news"os.makedirs(output_dir, exist_ok=True)filename = f"google_news_{datetime.now().strftime('%Y%m%d_%H%M%S')}.json"file_path = os.path.join(output_dir, filename)with open(file_path, "w", encoding="utf-8") as f:json.dump(articles, f, ensure_ascii=False, indent=2)return (f"✅ 已获取与 [{keyword}] 相关的前5条 Google 新闻:\n"f"{json.dumps(articles, ensure_ascii=False, indent=2)}\n"f"📄 已保存到:{file_path}")# @mcp.tool() 是 MCP 框架的装饰器,标记该函数为一个可调用的工具
@mcp.tool()
async def analyze_sentiment(text: str, filename: str) -> str:"""对传入的一段文本内容进行情感分析,并保存为指定名称的 Markdown 文件。参数:text (str): 新闻描述或文本内容filename (str): 保存的 Markdown 文件名(不含路径)返回:str: 完整文件路径(用于邮件发送)"""# 这里的情感分析功能需要去调用 LLM,所以从环境中获取 LLM 的一些相应配置openai_key = os.getenv("DASHSCOPE_API_KEY")model = os.getenv("MODEL")client = OpenAI(api_key=openai_key, base_url=os.getenv("BASE_URL"))# 构造情感分析的提示词prompt = f"请对以下新闻内容进行情绪倾向分析,并说明原因:\n\n{text}"# 向模型发送请求,并处理返回的结果response = client.chat.completions.create(model=model,messages=[{"role": "user", "content": prompt}])result = response.choices[0].message.content.strip()# 生成 Markdown 格式的舆情分析报告,并存放进设置好的输出目录markdown = f"""# 舆情分析报告**分析时间:** {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}---## 📥 原始文本{text}---## 📊 分析结果{result}
"""output_dir = "./sentiment_reports"os.makedirs(output_dir, exist_ok=True)if not filename:filename = f"sentiment_{datetime.now().strftime('%Y%m%d_%H%M%S')}.md"file_path = os.path.join(output_dir, filename)with open(file_path, "w", encoding="utf-8") as f:f.write(markdown)return file_path@mcp.tool()
async def send_email_with_attachment(to: str, subject: str, body: str, filename: str) -> str:"""发送带附件的邮件。参数:to: 收件人邮箱地址subject: 邮件标题body: 邮件正文filename (str): 保存的 Markdown 文件名(不含路径)返回:邮件发送状态说明"""# 获取并配置 SMTP 相关信息smtp_server = os.getenv("SMTP_SERVER") # 例如 smtp.qq.comsmtp_port = int(os.getenv("SMTP_PORT", 465))sender_email = os.getenv("EMAIL_USER")sender_pass = os.getenv("EMAIL_PASS")# 获取附件文件的路径,并进行检查是否存在full_path = os.path.abspath(os.path.join("./sentiment_reports", filename))if not os.path.exists(full_path):return f"❌ 附件路径无效,未找到文件: {full_path}"# 创建邮件并设置内容msg = EmailMessage()msg["Subject"] = subjectmsg["From"] = sender_emailmsg["To"] = tomsg.set_content(body)# 添加附件并发送邮件try:with open(full_path, "rb") as f:file_data = f.read()file_name = os.path.basename(full_path)msg.add_attachment(file_data, maintype="application", subtype="octet-stream", filename=file_name)except Exception as e:return f"❌ 附件读取失败: {str(e)}"try:with smtplib.SMTP_SSL(smtp_server, smtp_port) as server:server.login(sender_email, sender_pass)server.send_message(msg)return f"✅ 邮件已成功发送给 {to},附件路径: {full_path}"except Exception as e:return f"❌ 邮件发送失败: {str(e)}"if __name__ == "__main__":mcp.run(transport='stdio')
4.CherryStdio集成MCP
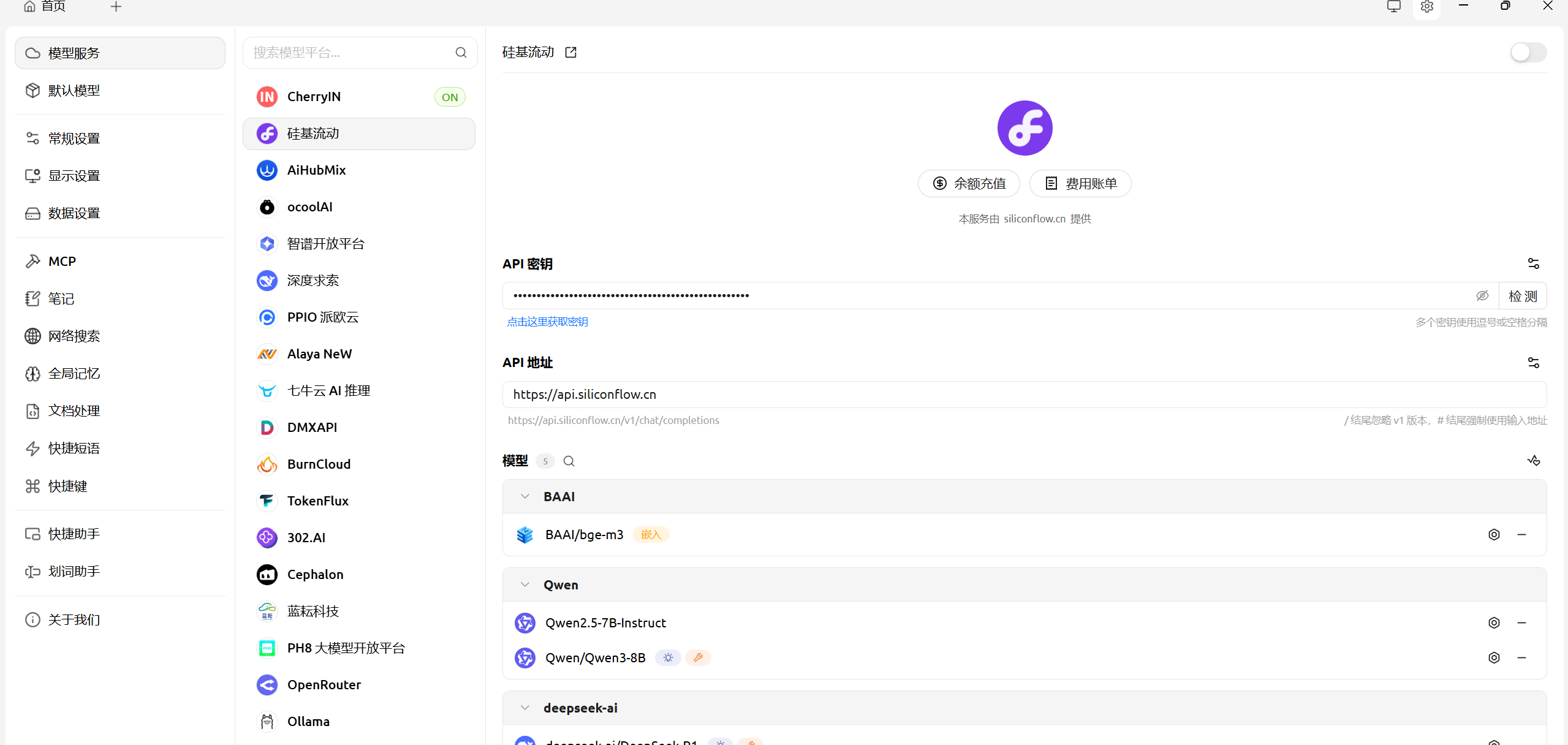
进入CherryStdio并配置平台及模型信息:
配置完成回首页便可调用大模型:
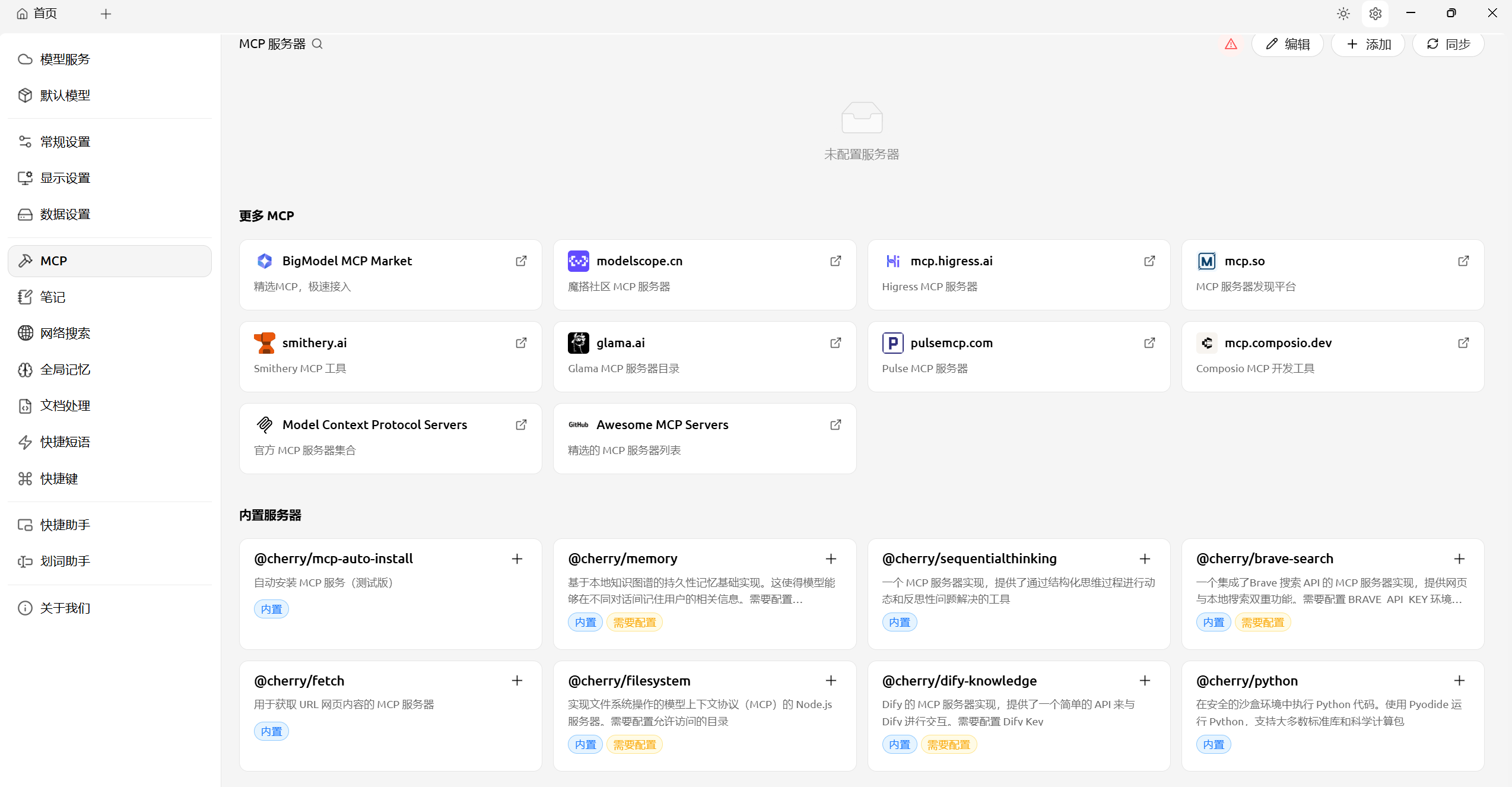
添加配置MCP服务器(多种可选创建方式):
安装环境依赖(该软件不会用操作系统已安装的环境):
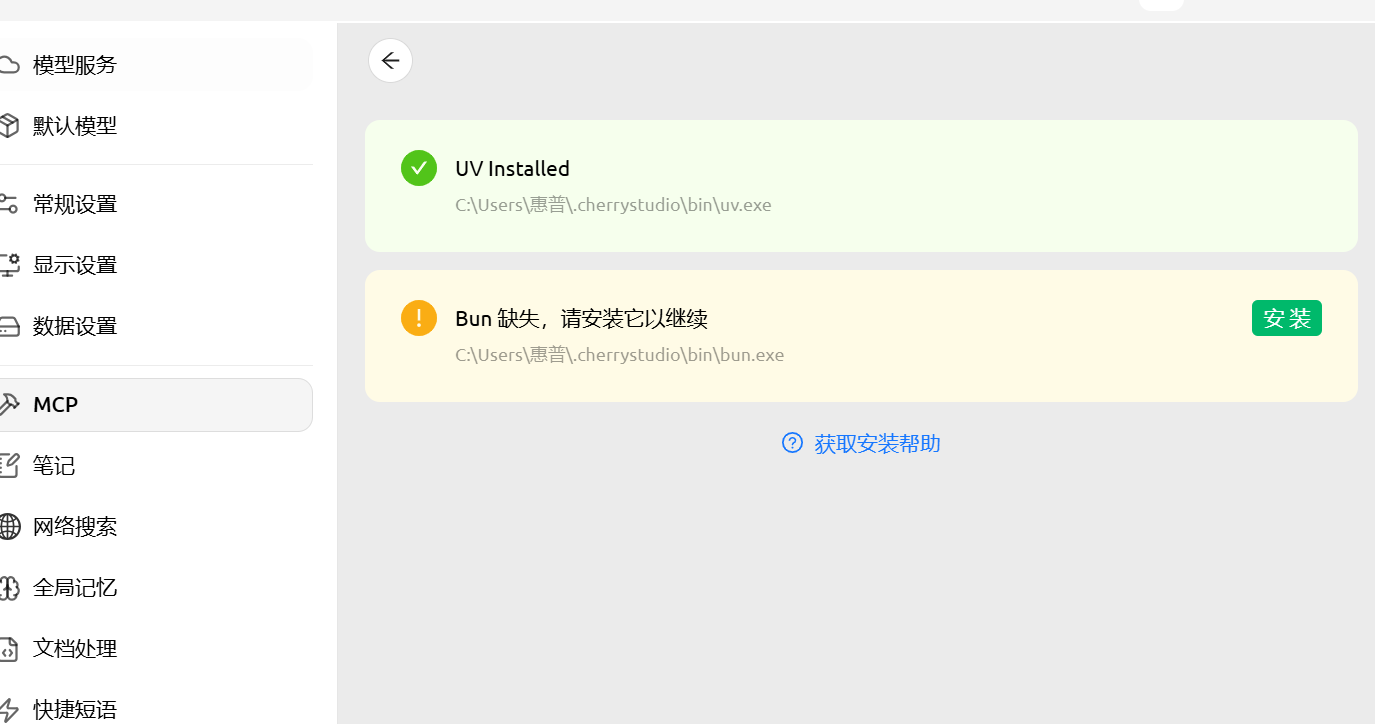
会话中添加MCP服务器(可选多个):
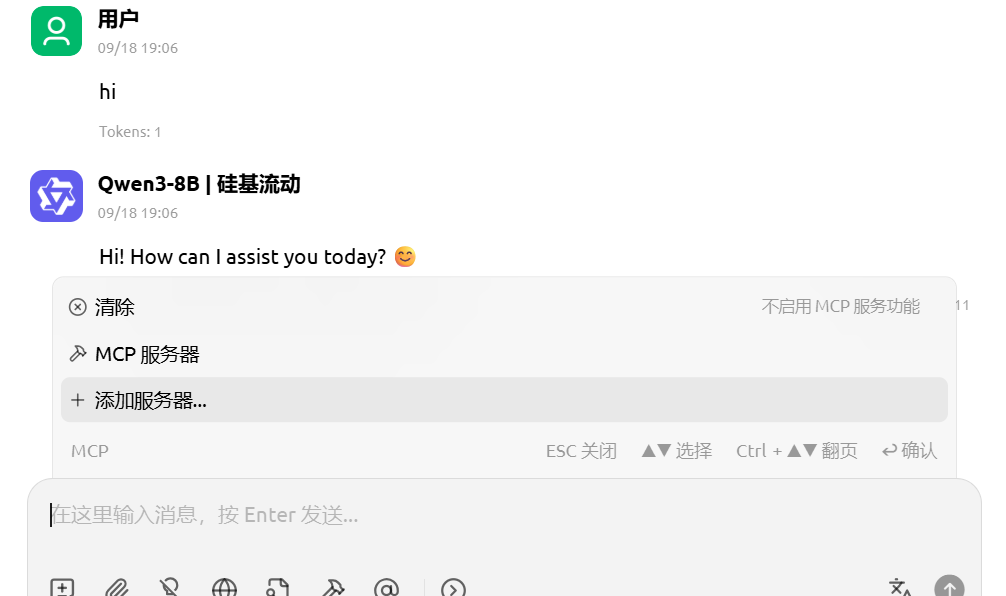
5.A2A协议