SQL分析-基础
文章目录
- 基础回顾
- 事务
- 数据库隔离级别
- MySQL架构介绍
- MySQL逻辑结构
- MySQL存储引擎
- MySQL查询过程
- 索引
- 简介
- 分类
- 索引结构
- 索引应用场景
基础回顾
事务
| 特点 | DBMS控制子系统 | |
|---|---|---|
| 原子性Atomicity | 指事务是一个不可再分割的工作单位,事务中的操作要么都执行,要么都不执行 | 事务管理子系统 |
| 一致性Consistency | 事务必须使数据库从一个一致性状态转换到另一个一致性状态 | 完整性子系统 |
| 隔离性Isolation | 并发执行的各个事务互不干扰,通过隔离级别来实现 | 并发控制子系统 |
| 持久性Durablity | 指一旦事务提交完成,它对数据库中数据的改变就是永久性的 | 恢复管理子系统 |
数据库隔离级别
数据库事务的隔离级别决定了多个并发事务之间的可见性与数据一致性程度!
脏读: 事务A读取事务B未提交的数据,若事务B回滚,则事务A读到的是无效数据。(读到了其他事务还没有提交的数据)
不可重复读:同一事务中多次读取同一数据,结果可能因其他事务提交而不同。(2次读取数据不一致)
幻读: 范围查询可能因其他事务插入/删除行而出现不一致。(范围查询数据不一致)#1 查看当前会话的隔离级别
select @@tx_isolation;
select @@transactions_isolation; // msyql8#2 查看系统的隔离级别
select @@global_isolation;#3 设置会话接的隔离界级别
set session transaction isolation level read committed;#4 设置全局的隔离界级别
set global transaction isolation level read committed;
| 隔离级别 | 特点 | 脏读 | 不可重复读 | 幻读 | 应用场景 |
|---|---|---|---|---|---|
| read uncommitted 读但未提交数据 | 允许事务读取未被其他事务提交的变更,仅确保事务原子性 | Y | Y | Y | 对数据一致性要求极低的高并发场景(如实时日志分析),MySQL中极少使用 |
| read committed 读已提交数据 【pg/oracle默认】 | 只允许事务读取已经被其他事务提交的变更 | N | Y | Y | 适用于多数Web应用系统,平衡一致性与性能 |
| repeatable read 可重复读 【mysql默认】 | 在事务执行期间,禁止其他事务对该字段进行更新。确保事务可以多次从一个字段读取相同的值。 | N | N | Y | 需要高数据一致性但对绝对隔离要求不苛刻的场景(如财务系统) |
| serialization 串行化 | 在事务执行期间,禁止其他事务对该表执行插入、更新、删除。确保事务可以多次从一个表中读取相同的行。但效率低下 | N | N | N | 对数据一致性要求极高且并发量低的场景(如银行核心交易系统) |
在mysql的innodb中,通过MVCC机制来解决脏读、不可重复读,通过MVCC+间隙锁来解决幻读(但无法完全避免)。
MySQL架构介绍
完整的MySQL优化需要很深的功底,由DBA专职,MySQL高级内容包括:MySQL内核结构、SQL语句优化、MySQL服务器优化、常见参数常量设定、主从复制、软硬件升级、容灾备份等。
MySQL逻辑结构
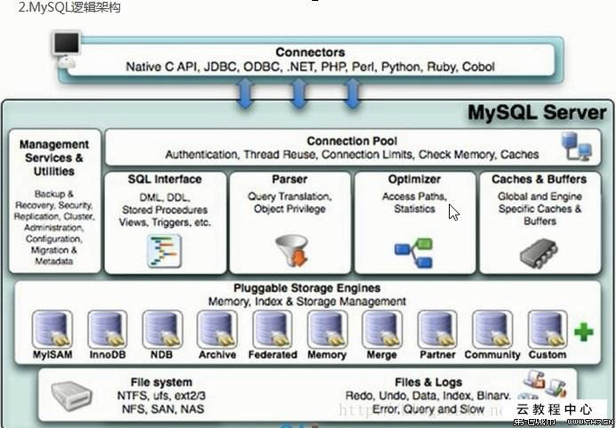
连接层连接层主要完成连接处理、授权认证、相关的安全方案。在该层上引入了线程池的概念,为通过认证安全接入的客户端提供线程。同样在该层上可以实现基于SSL的安全链接。服务器也会为安全接入的每个客户端验证它所具有的操作权限。服务层服务层主要完成数据库管理服务,包括SQL接口执行(SQL interface)、查询语句的解析(Parser)与优化(Optimizer),缓存的查询与设置(Caches & buffers)。所有跨存储引擎的功能也在这一层实现,如存储过程、函数等。在该层,服务器会解析查询并创建相应的内部解析树,并对其完成相应的优化,如确定表查询的顺序,是否利用索引等,最后生成相应的执行操作,如果是select语句,服务器还会查询内部的缓存。引擎层可插拔的存储引擎负责MySQL数据的存储和提取,服务器通过API与存储引擎进行通信。不同的存储引擎具有的功能不同,这样我们可以根据自己的实际需要进行选取。后面介绍MyISam和InnoDB存储层数据存储层,主要是将数据存储在运行于裸设备的文件系统之上,并完成与存储引擎的交互。
总结:和其它数据库相比,MySQL有点与众不同,它的架构可以在多种不同场景中应用并发挥良好作用。主要体现在存储引擎的架构上,可插拔的存储引擎架构将查询处理、其它的系统任务、数据的存储提取相分离,这种架构可以使用户根据实际业务需求选择合适的存储引擎,提高数据库系统的运行效率。
MySQL存储引擎
在mysql数据库中,将数据存储到文件或内存中的各种存储技术,常见的存储引擎包括InnoDB、myIsam、memory、Archive,通过show engines来查看,mysql默认InnoDB
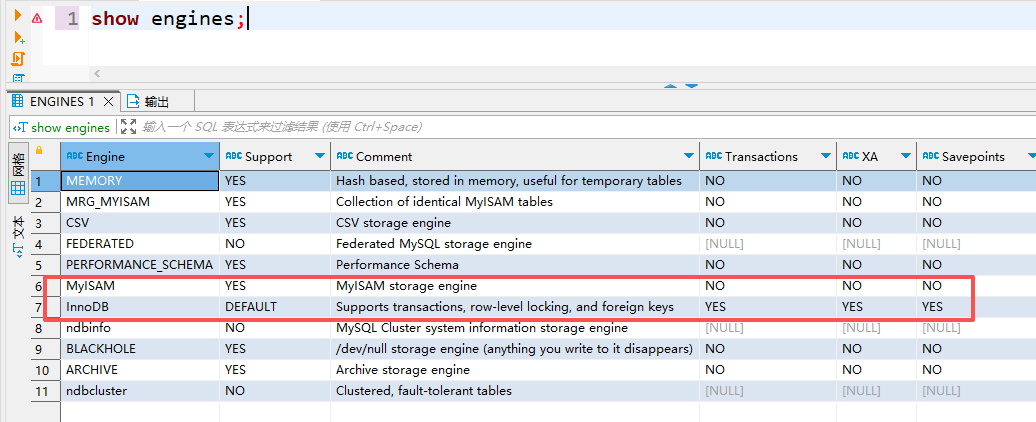
| 对比项 | InnoDB(mysql默认) | MyISAM |
|---|---|---|
| 主外键/事务 | 都支持,支持完整ACID事务 | 都不支持,仅支持单条语句原子性 |
| 锁机制 | 行锁,操作记录只锁某一行,适合高并发场景 | 表锁,操作记录锁住整张表 |
| 关注点 | 偏写操作(事务安全、高并发) | 偏读操作(简单高效、读优先) |
| 应用场景 | 1. 事务依赖型系统(银行转账、订单支付,需保证数据完整性和回滚能力) 2.高并发写入(适合用户评论、实时库存更新) 3. 需要外键或崩溃后快速恢复的系统 | 1. 只读或极少更新的静态数据表(如归档日志 2.无事务需求时,MyISAM内存占用更低(如嵌入式设备)。 |
MySQL查询过程
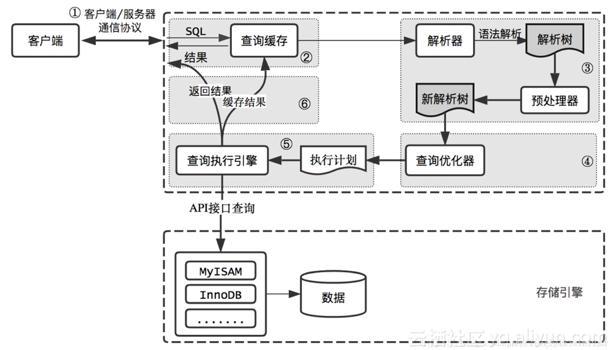
MySQL查询过程:
1、客户端将SQL查询请求发送到MySQL服务器;
2、MySQL服务器先查询缓存,如果命中,立即返回缓存中的结果;否则进入下一阶段;
3、MySQL服务器对SQL语句进行解析、预处理,再由查询优化器生成对应的执行计划;
4、MySQL根据执行计划调用存储引擎进行API接口查询;
5、服务器将结果返回给客户端,同时缓存查询结果。
SQL解析过程-执行顺序:from 表名1 1 // 基础查询 inner/left/right/full/cross join 表名2 2on 连接条件 3where 条件列表 4 // 条件查询group by 分组字段 5 // 分组查询having 分组之后的条件 6select 字段列表 7order by 排序 8 // 排序查询limit 分页限定 9
- 七种Join图
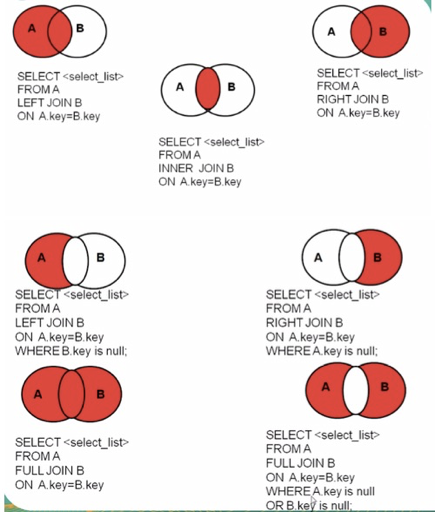
#0 笛卡尔积
select * from tbl_dept,tbl_emp;
#1 inner join 公有AB
select * from tbl_dept a inner join tbl_emp b on a.id=b.deptld;
#2 left join A独有+AB公有
select * from tbl_dept a left join tbl_emp b on a.id=b.deptld;
#3 right join B独有+AB公有
select * from tbl_dept a right join tbl_emp b on a.id=b.deptld;
#4 left join A独有
select * from tbl_dept a left join tbl_emp b on a.id=b.deptld where b.deptld is null;
#5 right join B独有
select * from tbl_dept a right join tbl_emp b on a.id=b.deptld where a.deptld is null;#6 full join A独有+AB公有+B独有(左连接union右连接)
#select * from tbl_dept a full join tbl_emp b on a.id=b.deptld; mysql不支持full join
select * from tbl_dept a left join tbl_emp b on a.id=b.deptld
union #自带去重功能
select * from tbl_dept a right join tbl_emp b on a.id=b.deptld;#7 cross join A独有+B独有
#select * from tbl_dept a full join tbl_emp b on a.id=b.deptld where a.id is null;
select * from tbl_dept a left join tbl_emp b on a.id=b.deptld where a.id is null
union #自带去重
select * from tbl_dept a right join tbl_emp b on a.id=b.deptld where b.id is null;
索引
简介
索引本质是"排好序的快速查找的数据结构",索引的目的在于提高查找效率,类比字典。
1. MySQL数据库除了存储数据本身,还维护着一个排好序的快速查找的数据结构【索引】,这些数据结构以某种方式指向数据,这样就可以在这些数据结构上实现高级快速查找算法。2. 一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在磁盘上。
我们平常所说的索引,如果没有特别指明,都是指B+树(多路搜索树,并不一定是二叉树)结构组织的索引。
PS:其中单值索引、复合索引、聚集索引、唯一索引,这些索引底层数据结构默认都是使用B+树。
当然,除了B+树这种类型的索引之外,还有哈希索引(hash-index)等。优势
- 提高数据查询的效率,降低数据库的IO成本 (类似大学图书馆建书目索引)
- 降低数据排序的成本,降低了CPU的消耗 (通过索引列对数据进行排序)略势
- 实际上索引也是一张表,该表保存了主键与索引字段关系,所以索引也是要占用空间的。
- 毫无疑问索引大大提高了查询速度,但是却会降低更新表的速度。如对表进行INSERT、UPDATE和DELETE操作,MySQL不仅要保存数据,还要调整因为更新所带来的键值变化后的索引信息。
分类
单值索引 即一个索引只包含单个列,一个表可以有多个单值索引,原则上一个表上的索引不超过5个
复合索引 即一个索引包含多个列
唯一索引 索引列的值必须唯一, 但允许有空值
聚簇索引 索引的逻辑顺序与磁盘上行的物理存储顺序不同
主键索引 是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值。一般是在建表的时候同时创建主键索引。
哈希索引基本语法create index 索引名称 on 表名(列名) 单值索引create unique index 索引名称 on 表名(列名) 唯一索引create index 索引名称 on 表名(列名1,列名2) 复合索引alter 表名 add [unique] index 索引名称 on 表名(列名1,列名2) 创建索引drop index 索引名 on 表名(列名) 删除索引show index from 表名 查看索引
索引结构
B+树:
1、非叶子结点不存储数据,只进行数据索引,所有数据存储在叶子结点
2、叶子结点存储相邻叶子结点的指针
3、叶子结点存储的数据从小到大排列
B+树索引结构:
B+树只有叶子节点存储数据,比如真实的数据存在于叶子节点即3、5、 9、10、19,所有的叶子结点使用链表相连,便于区间查找和遍历,所有非叶子节点不存储真实的数据,只存储指引搜索方向的数据项,如17、35并不真实存在于数据表中。
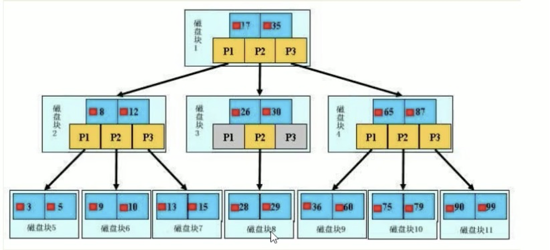
1.初始化介绍一颗B+树,浅蓝色的块我们称之为一个磁盘块,磁盘块包含几个数据项(深蓝色所示)和指针(黄色所示),如磁盘块1包含数据项17和35,包含指针P1、P2、P3,P1表示小于17的磁盘块,P2表示在17和35之间的磁盘块,P3表示大于35的磁盘块。2. 查找过程1、如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO; 2、在内存中用二分查找法确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过P2指针把磁盘块3由磁盘加载到内存,发生第二次IO;3、同样使用二分查找法确定29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。真实的情况是,3层的B+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,
性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,
显然成本非常非常高。
索引应用场景
哪些情况需要建立索引
1、主键自动建立唯一索引
2、查询中与其它表关联的字段,外键关系建立索引
3、频繁作为select查询条件的字段应该创建索引
4、频繁作为where条件的字段应该创建索引
5、频繁作为分组字段group by的字段应该创建索引
6、频繁作为排序字段order by的字段应该创建索引,排序字段若通过索引去访问将大大提高排序速度
7、单键/组合索引的选择问题,who? (在并发环境下倾向创建组合索引)
一句话,频繁使用的字段要优先建立索引,而且优先建立复合索引(主外键、select、where、group by、order by)
哪些情况不需要建立索引
1、表记录太少(低于三百万条纪录)
2、经常增删改的表(虽然提高了查询速度,但是却会降低更新表的速度)
3、数据重复且分布均匀的表字段(因此应该只为最经常查询和最经常排序的数据列建立索引)