【STL源码剖析】从源码看 list:从迭代器到算法

文章目录
- 前言
- 一. list 概述
- 二. list 的节点
- 三. list 迭代器
- 3.1 定义
- 3.2 构造
- 3.3 重载
- 四. list 数据结构
- 五. list 的构造和内存管理
- 六. list 的接口
本文并不适合STL初学者。对于那些熟练掌握 C++ 模板和 STL 的日常使用,理解内存分配与对象生命周期,并且有扎实的数据结构基础,希望深刻了解STL实现细节,从而得以提升对STL的扩充能力,或是希望藉由观察STL源代码,学习世界一流程序员身手,并藉此彻底了解各种被广泛运用之数据结构和算法的人,本文可能更适合你。
本文的源码主要来自 SGI STL(Silicon Graphics, Inc. 实现的 STL 版本);
关于源码可以到在线网站查看:源码网站,也可以下载源码压缩包:压缩包
前言
学过数据结构得大概都知道,vector得头插和头删的效率很低O(N),但是list的头插和头删操作都能做到O(1),并且list的任意位置插入和删除也可以做到O(1),并且list的每个节点都是独立的,并不是连续线性地址空间,所以list并不会出现迭代器失效的情况(除非你使用已经删除的节点),并且list还不会像vector一样二倍扩容,list就是使用一个开辟一个。
本文将从6个板块对list的源码进行剖析:
- list 概述;
- list 节点;
- list 的迭代器;
- list 的数据结构;
- list 的构造和内存管理;
- list 的接口。
本文的源码主要来自 SGI STL(Silicon Graphics, Inc. 实现的 STL 版本);
关于源码可以到在线网站查看:源码网站,也可以下载源码压缩包:压缩包
一. list 概述
在前言部分关于list的大致优势都已经谈到了,此处简单说一些劣势:
- list不能进行索引操作,没有vector的
[]重载,所以对元素的操作没有vector方便; - list数据存储并不是集中存储的,所以其内存局部存储性差,缓存利用率低;
- 内存开销更大,除了存储数据,每一个节点还要存储两个指针;
二. list 的节点
学过基础数据结构的应该都知道,list的节点和list本身是两个不同的结构,需要分开设计,下面看看list节点的设计:
template <class T>
struct __list_node {typedef void* void_pointer; // 库中使用的是void*来存储地址,使用__listnode<T>*也是可以的void_pointer next; // 存储下一个节点的地址void_pointer prev; // 存储上一个节点的地址T data; // 存储有效数据
};
从上面的节点的结构就可以看出,list是一个双向循环链表。
三. list 迭代器
3.1 定义
list的每个节点并不是连续存放的,迭代器的加减操作是将为了从一个节点跳到另一个节点位置,因此不能像vector一样用普通指针作为迭代器。
list的节点存储的是上一个节点和下一个节点的地址,所以list的迭代器应该是Bidirectional Iterators双向迭代器。
下面看看list迭代器都定义了什么成员:
template<class T, class Ref, class Ptr> // Ref和Ptr决定的该迭代器是否是常量迭代器
struct __list_iterator {typedef __list_iterator<T, T&, T*> iterator; // 普通迭代器typedef __list_iterator<T, const T&, const T*> const_iterator; // 常量迭代器typedef __list_iterator<T, Ref, Ptr> self; // 自己typedef T value_type;typedef Ptr pointer;typedef Ref reference;typedef __list_node<T>* link_type;typedef size_t size_type;typedef ptrdiff_t difference_type;link_type node; // 存储该迭代器指向的节点}
};
list的迭代器成员就只有一个:当前节点的地址。list迭代器主要是把迭代器的++,–等操作进行重载。
3.2 构造
构造就比较简单:无参构造,用节点地址构造,迭代器的拷贝构造。
__list_iterator(link_type x) : node(x) {}__list_iterator() {}__list_iterator(const iterator& x) : node(x.node) {}
3.3 重载
对于== , !=可以直接比较迭代器中的node成员的地址,++,--则都是指向下一个或上一个节点的地址。
template<class T, class Ref, class Ptr>
struct __list_iterator {typedef __list_node<T>* link_type;link_type node;bool operator==(const self& x) const { return node == x.node; }bool operator!=(const self& x) const { return node != x.node; }reference operator*() const { return (*node).data; }
#ifndef __SGI_STL_NO_ARROW_OPERATORpointer operator->() const { return &(operator*()); }
#endif /* __SGI_STL_NO_ARROW_OPERATOR */self& operator++() { node = (link_type)((*node).next);return *this;}self operator++(int) { self tmp = *this;++*this;return tmp;}self& operator--() { node = (link_type)((*node).prev);return *this;}self operator--(int) { self tmp = *this;--*this;return tmp;}
};四. list 数据结构
list不仅是一个双向链表,list头尾相连,是一个循环双向链表,并且在起始位置/结束为止还有一个哨兵位,即空白节点,通过该空白节点就可以满足STL对于"前闭后开"区间的要求。
list中只需要存储哨兵位就可以对整个数组进行操作了。
template <class T, class Alloc = alloc>
class list {
protected:typedef void* void_pointer;typedef __list_node<T> list_node;typedef list_node* link_type;
protected:link_type node; // 记录哨兵位节点的地址
};
list的示意图:
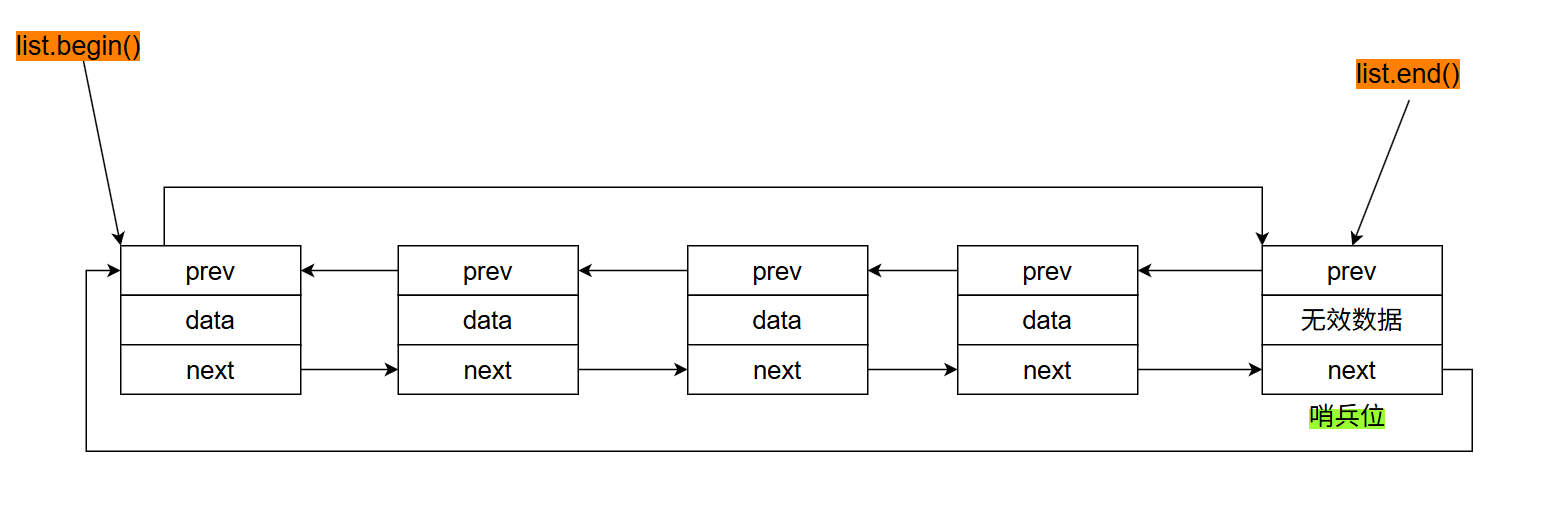
根据上图begin()不就是node->next,end()不就是node,以及在判断链表是否为空,链表的元素个数都可以通过该哨兵位作为标记进行处理。
template <class T, class Alloc = alloc>
class list {
public:iterator begin() { return (link_type)((*node).next); } iterator end() { return node; }bool empty() const { return node->next == node; } // 判断是不是只有哨兵位size_type size() const { // 遍历一遍链表size_type result = 0;distance(begin(), end(), result);return result;}reference front() { return *begin(); } // 取迭代器对应的数据reference back() { return *(--end()); }
protected:link_type node;
};
五. list 的构造和内存管理
list缺省使用alloc作为空间配置器,并据此定义出了一个list_node_allocator专门以一个节点的大小进行空间配置。
template <class T, class Alloc = alloc>
class list {
protected:typedef simple_alloc<list_node, Alloc> list_node_allocator;link_type get_node() { return list_node_allocator::allocate(); }void put_node(link_type p) { list_node_allocator::deallocate(p); }
};
template<class T, class Alloc>
class simple_alloc {
public:static T *allocate(size_t n){ return 0 == n? 0 : (T*) Alloc::allocate(n * sizeof (T)); }static T *allocate(void){ return (T*) Alloc::allocate(sizeof (T)); }static void deallocate(T *p, size_t n){ if (0 != n) Alloc::deallocate(p, n * sizeof (T)); }static void deallocate(T *p){ Alloc::deallocate(p, sizeof (T)); }
};
get_node是list中专门用来开辟一个节点空间的接口,而put_node则是专门用来释放一个接待点的。
template <class T, class Alloc = alloc>
class list {
protected:link_type create_node(const T& x) {link_type p = get_node(); // 开辟一个节点__STL_TRY { construct(&p->data, x); // 用x对空间进行初始化}__STL_UNWIND(put_node(p));return p;}void destroy_node(link_type p) {destroy(&p->data); // 析构对象put_node(p); // 释放空间}
};
creat_node用来创建一个节点,带有元素值,destory_node销毁(析构 + 释放空间)一个节点。
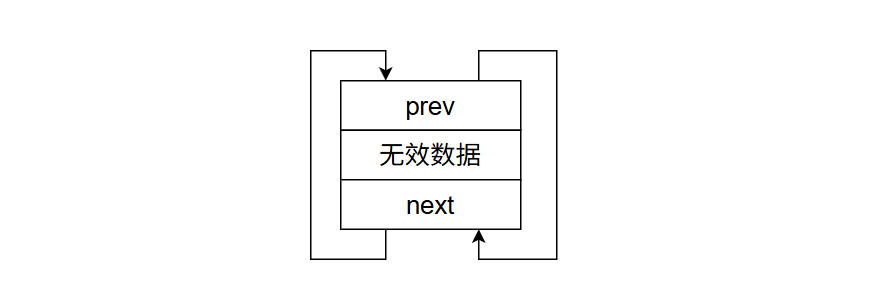
list的有一个无参构造,这并不代表该链表内部不用开辟空间,即使是空链表内部也有一个哨兵位,并且该哨兵节点指向自己。
六. list 的接口
list的接口太多了,此处只列举几个最频繁,最重要的几个。
iterator insert(iteraetor position , const T% x)
插入节点分为两步:
- 开辟空间,创建节点;
- 将节点插入到目标为止。
iterator insert(iterator position, const T& x) {link_type tmp = create_node(x); // 为新节点开辟空间tmp->next = position.node; // 将新节点加入到链表tmp->prev = position.node->prev;(link_type(position.node->prev))->next = tmp; position.node->prev = tmp; return tmp;}
insert示意图如下: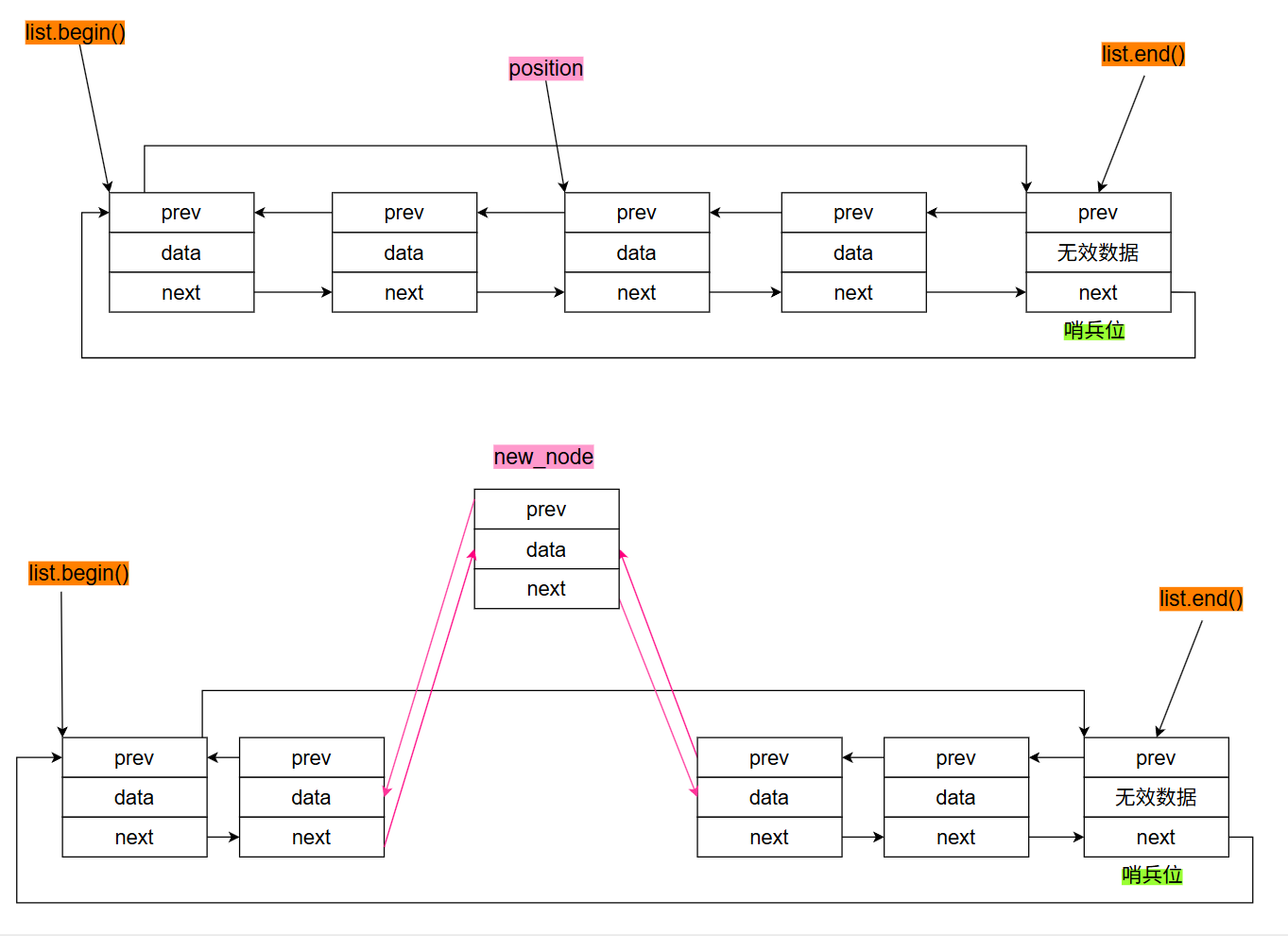
对于push_back() , push_front()都是调用insert实现的。
void push_front(const T& x) { insert(begin(), x); }void push_back(const T& x) { insert(end(), x); }
iterator erase(iterator position)指定为止删除:
当删除一个节点,分为两步:
- 将前一个节点与后一个节点相连,将目标节点移除链表;
- 实现节点空间。
iterator erase(iterator position) {link_type next_node = link_type(position.node->next); link_type prev_node = link_type(position.node->prev);prev_node->next = next_node; // 将前一个节点与后一个节点相连next_node->prev = prev_node;destroy_node(position.node); // 销毁节点return iterator(next_node);}
同理pop_back() , pop_front()也调用erase()实现的。
void pop_front() { erase(begin()); }void pop_back() { iterator tmp = end(); // tmp是哨兵位erase(--tmp);}
void clear() 清除所有节点:
将所有节点都进行销毁,将哨兵节点头尾相连。
template <class T, class Alloc>
void list<T, Alloc>::clear()
{link_type cur = (link_type) node->next; // 从头结点开始while (cur != node) {link_type tmp = cur;cur = (link_type) cur->next; // 移动到下一个节点destroy_node(tmp); // 销毁}node->next = node; // 哨兵节点头尾相连node->prev = node;
}
void remove(const T& value)将链表中值为value的节点都删除。因为前面已经有erase了,所以在找到value节点时,可以直接进行删除。
template <class T, class Alloc>
void list<T, Alloc>::remove(const T& value) {iterator first = begin();iterator last = end();while (first != last) { // 遍历链表iterator next = first;++next;if (*first == value) erase(first); // 删除该位置first = next;
}
void unique(),移除数值相同的连续元素,只有"连续且相同的元素"才会被移除剩一个。
template <class T, class Alloc>
void list<T, Alloc>::unique() {iterator first = begin(); iterator last = end();if (first == last) return;iterator next = first;while (++next != last) { // 从头到尾遍历链表if (*first == *next) // first和下一个位置相同,删除下一个位置erase(next);elsefirst = next; // 不相同,让first走到下一个位置 next = first; // 让next再赋值为first使得next与first比较的时候永远在first的下一个位置}
}
在上述比较的时候,如果first后面的next于first相同,就将next移除,此时first后面的节点就是第三个节点了,可能还是于first相同,所以不能移动first的位置。
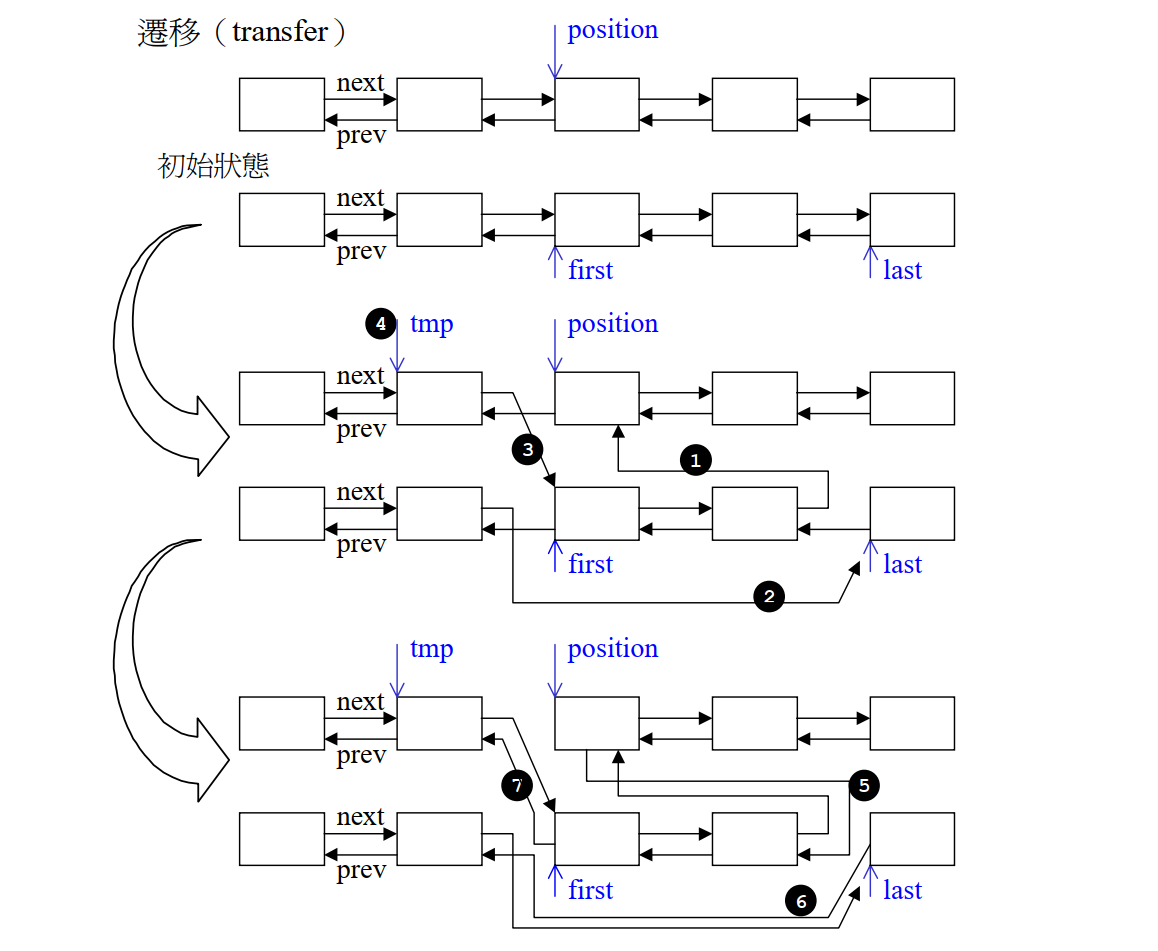
list内部提供了一个所谓的迁移操作transfer,可以将某一个链表的一部分进行进行迁移,迁移到当前链表的其他位置,或另一个链表上,这个操作也为后续的splice,sort,merge奠定了良好的基础,下面是transfer的源码:
template <class T, class Alloc>
class list {
protected:void transfer(iterator position, iterator first, iterator last) {if (position != last) {(*(link_type((*last.node).prev))).next = position.node;(*(link_type((*first.node).prev))).next = last.node;(*(link_type((*position.node).prev))).next = first.node; link_type tmp = link_type((*position.node).prev);(*position.node).prev = (*last.node).prev;(*last.node).prev = (*first.node).prev; (*first.node).prev = tmp;}}
};
实际上transfer就是将指针的指向进行的一定的修改,将[first , last)移动到position位置之前,一共要修改6个指针的指向:
position + 1 , position中间插入[frist , last - 1]需要改变4个指针指向,分别是first.prev , position.prev , (last - 1).next , (position + 1).next;- 还要将
first - 1 , last连接起来;
流程图如下:
在上面的源码中,我们也看到了transfer时protected的,并没有向外公开,实际上对外公开的是另一个接口splice,该函数有三个重载,分别可以满足将整条list迁移到指定位置,将一个节点迁移到指定位置,将一个区间迁移到指定位置。
public:void splice(iterator position, list& x) { // x必须于*this不同if (!x.empty()) transfer(position, x.begin(), x.end());}void splice(iterator position, list&, iterator i) { // x可以在*this上iterator j = i;++j;if (position == i || position == j) return;transfer(position, i, j);}void splice(iterator position, list&, iterator first, iterator last) {if (first != last) // position不能在区间内transfer(position, first, last);}
有了transfer这个接口,merge()的实现也就不难了,merge()可以将两个递增的链表进行合并,合并后的链表依旧有序:
public:
template <class T, class Alloc>
void list<T, Alloc>::merge(list<T, Alloc>& x) {iterator first1 = begin();iterator last1 = end();iterator first2 = x.begin();iterator last2 = x.end();while (first1 != last1 && first2 != last2) // 遍历两个链表if (*first2 < *first1) { // first2下,将其迁移到first1前 iterator next = first2; transfer(first1, first2, ++next);first2 = next;}else++first1;if (first2 != last2) transfer(last1, first2, last2); // first2还没遍历完,直接迁移到first1末尾
}
list中提供了一个reverse()接口,可以将链表进行逆置,时间上就是对链表中的节点进行迁移,将起始位置后面的节点依次迁移到起始节点前面:
public:
template <class T, class Alloc>
void list<T, Alloc>::reverse() {if (node->next == node || link_type(node->next)->next == node) return;iterator first = begin();++first;while (first != end()) {iterator old = first;++first;transfer(begin(), old, first);}
}
list的迭代器不是随机随机迭代器,属于双向迭代器,依次不能直接使用库中提供的sort进行排序,list类中实现了自己的排序算法。
list的排序底层逻辑采用的是归并排序,只不过这种归并是自底向上的,即省略了上层分割的操作,直接从底依次拼接出完整的链表,示意图如下,下图中的分割阶段并不包含:
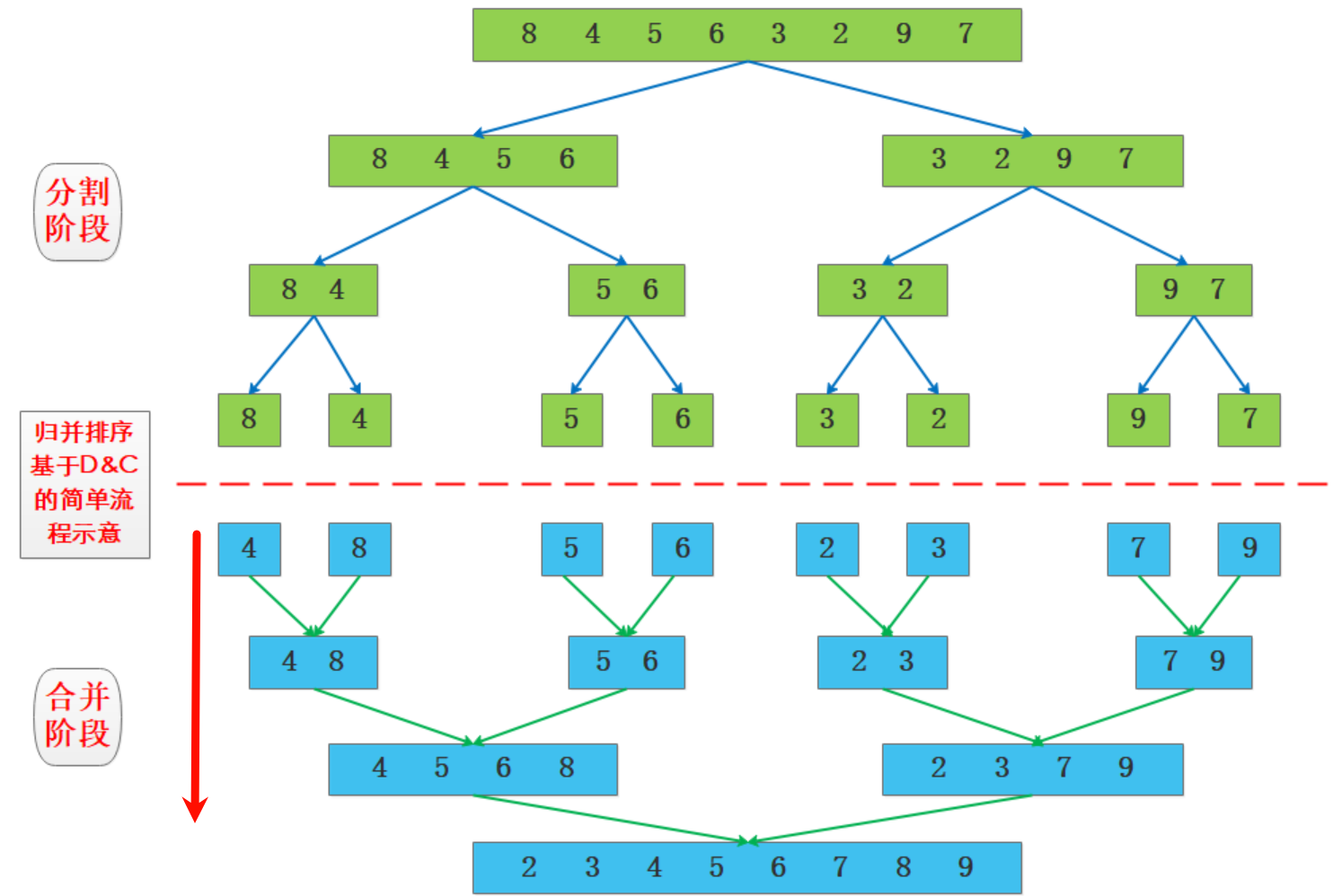
carray存放要进行合并的链表;counter[i]存放长度为 2i2^{i}2i 还没进行归并的链表,让carray来归并;fill存储counter的最大索引,还没使用的最小位置。
实际步骤:
- 先从
*this中那节点放到carray上,此时carray有一个节点; - 看
counter[0]是否存在链表,如果有就让counter[0]和carray归并; - 将归并的结果放到
carray中,再判断counter[1]是否有链表,如果有继续归并; - 重复上面的操作;
- 最后
counter中存放着不同长度但是都是有序的链表,再将这些链表进行归并即可。
public:
template <class T, class Alloc>
void list<T, Alloc>::sort() {if (node->next == node || link_type(node->next)->next == node) return;list<T, Alloc> carry; // 临时存储还未排序的链表,但是该链表内部必须递增list<T, Alloc> counter[64]; // 存储已经排序的链表int fill = 0;while (!empty()) {carry.splice(carry.begin(), *this, begin());// 拿出一个节点int i = 0;while(i < fill && !counter[i].empty()) {counter[i].merge(carry); // carray和对应相同长度的链表进行归并放到counter[i]上carry.swap(counter[i++]); // 将count[i]交换到carray上,让carray继续向上去归并}carry.swap(counter[i]); // 将carray已经排好的数据放回counter[i]中 if (i == fill) ++fill; // } for (int i = 1; i < fill; ++i) counter[i].merge(counter[i-1]);swap(counter[fill-1]);
}