使用BLIP训练自己的数据集(图文描述)
本文介绍了基于COCO格式制作小型犬类图像数据集的完整流程。首先创建包含annotations和images的标准文件夹结构,图像需按"名称_索引.jpg"格式命名。通过CSV文件存储图像ID、描述文本和数据集划分信息,经脚本转换生成5个关键JSON文件,包括训练集、验证集和测试集。配置YAML文件指定路径和训练参数后,使用BLIP模型进行3个epoch的微调训练,并输出评估指标。最终模型权重和预测结果保存在output目录,可通过修改demo.py进行测试,为每张图像生成多个描述文本。整个流程展示了从小型数据集构建到模型训练测试的标准化方法。
数据集的制作
为了方便训练,数据集仿照COCO的格式进行的制作。我这里用了20张小狗的照片进行演示。数据集样例如下:

步骤1:新建my_blip_dataset文件夹,在里面分别建annotations和images文件夹。
步骤2:在images文件中新建“val2014”文件夹用于存储图像(把所有的图像放进去即可)。如下所示。
注意:为了方便训练,这里的图像命名方式有要求,格式为:图像名称_索引.jpg。例如dog_1.jpg、dog_2.jpg
步骤3:在annotations文件夹新建coco_gt文件夹,新建ann.csv文件,写入描述信息。
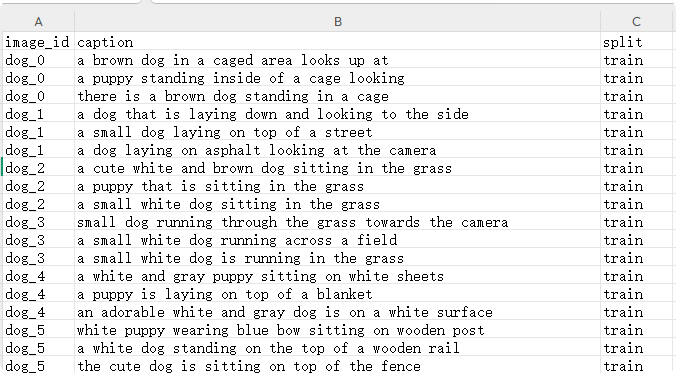
ann.csv内容如下,可以用WPS或者excel编写内容。三列,分别为图像id、caption、split(train为训练,val为验证,test为测试),image_id即把图像后缀去掉,仅仅保留图像名字。我这里是给每个图生成了3个描述,你也可以一个或者更多描述。
步骤4:运行tools/csv2json.py,生成5个json文件。目录格式如下,这里一定要检查是否正确,不然训练会报错!
annotations/
|-- ann.csv
|-- coco_gt
| |-- coco_karpathy_test_gt.json
| `-- coco_karpathy_val_gt.json
|-- coco_karpathy_test.json
|-- coco_karpathy_train.json
|-- coco_karpathy_val.json
其中coco_karpathy_train.json内容大体如下,即格式为{'caption','image','image_id'}
[{"caption": "a brown dog in a caged area looks up at","image": "val2014/dog_0.jpg","image_id": "dog_0"},{"caption": "a puppy standing inside of a cage looking","image": "val2014/dog_0.jpg","image_id": "dog_0"} ..................]
coco_karpathy_val.json中的格式为:{'image','caption','image_id'},大体内容如下:
(coco_karpathy_test.json和coco_karpathy_val.json格式一样)
[{"image": "val2014/dog_10.jpg","caption": ["a little brown dog laying on top of a table","a very cute little puppy laying on the floor","the dog is laying on the floor beside the computer"],"image_id": "dog_10"},{"image": "val2014/dog_11.jpg","caption": ["two small puppies on the grass together","two small dogs sitting on the grass and one of them","two puppies laying on a grass covered field"],"image_id": "dog_11"}...........................
]
coco_gt文件下的coco_karpathy_val_gt.json格式为:
{
"annotations":[{"image_id": 10,"caption": "a little brown dog laying on top of a table","id":0},{"image_id":11,"caption":.....,"id":1} ................]"images":[{"id":10},{"id":11}......]
}最终的目录形式如下:
|-- annotations(标签文件夹根目录)
| |-- ann.csv (存储标签即图像的描述信息)
| |-- coco_gt (存放真实的标签文件,用于后期评价指标的计算)
| |-- coco_karpathy_test.json (测试集)
| |-- coco_karpathy_train.json (训练集)
| |-- coco_karpathy_val.json (验证集)|
|-- images(图像文件夹根目录)
`-- val2014 (存储图像)
训练
步骤5:在configs/下新建caption_mydata.yaml,内容如下:
image_root: 'my_blip_dataset/images/'
ann_root: 'my_blip_dataset/annotations'
coco_gt_root: 'my_blip_dataset/annotations/coco_gt'pretrained: 'weights/model_base_caption_capfilt_large.pth'vit: 'base'
vit_grad_ckpt: False
vit_ckpt_layer: 0
batch_size: 2 # 小批量适合测试
init_lr: 1e-5image_size: 384max_length: 20
min_length: 5
num_beams: 3
prompt: 'a picture of 'weight_decay: 0.05
min_lr: 0
max_epoch: 3 # 少量epochs进行测试步骤6:在终端输入命令开启训练
python train_caption.py --config configs/caption_mydata.yaml
训练打印如下(部分):
Using downloaded and verified file: my_blip_dataset/annotations/coco_gt\coco_karpathy_test_gt.json
loading annotations into memory...
Done (t=0.00s)
creating index...
index created!
Loading and preparing results...
DONE (t=0.00s)
creating index...
index created!
tokenization...
setting up scorers...
computing Bleu score...
{'testlen': 28, 'reflen': 28, 'guess': [28, 25, 22, 19], 'correct': [16, 8, 5, 3]}
ratio: 0.9999999999642857
Bleu_1: 0.571
Bleu_2: 0.428
Bleu_3: 0.346
Bleu_4: 0.285
computing METEOR score...
METEOR: 0.225
computing Rouge score...
ROUGE_L: 0.492
computing CIDEr score...
CIDEr: 1.399
Bleu_1: 0.571
Bleu_2: 0.428
Bleu_3: 0.346
Bleu_4: 0.285
METEOR: 0.225
ROUGE_L: 0.492
CIDEr: 1.399
Training time 0:00:58
训练的权重和结果会在output下面,如下:
output/
`-- Caption_coco|-- checkpoint_best.pth|-- config.yaml|-- log.txt`-- result|-- test_epoch0.json|-- test_epoch0_rank0.json|-- test_epoch1.json|-- test_epoch1_rank0.json|-- test_epoch2.json|-- test_epoch2_rank0.json|-- val_epoch0.json|-- val_epoch0_rank0.json|-- val_epoch1.json|-- val_epoch1_rank0.json|-- val_epoch2.json`-- val_epoch2_rank0.json
测试
修改demo.py中的model_path和image_path,开启测试,我这里一个图生成3个描述。

a puppy that is looking up at the camera while in the kennel, with it's head tilted to the side
a small dog in a caged area with his owner behind him, wearing a red collar and leash
a dog inside of a cage looking up to it's ear and body in the air关于报错
如果报错如下:
tokenization...
Traceback (most recent call last):File "E:\BLIP\train_caption.py", line 208, in <module>main(args, config)File "E:\BLIP\train_caption.py", line 148, in maincoco_val = coco_caption_eval(config['coco_gt_root'],val_result_file,'val')File "E:\BLIP\data\utils.py", line 106, in coco_caption_evalcoco_eval.evaluate()File "D:\ProgramData\Anaconda3\envs\pytorch121\lib\site-packages\pycocoevalcap\eval.py", line 33, in evaluategts = tokenizer.tokenize(gts)File "D:\ProgramData\Anaconda3\envs\pytorch121\lib\site-packages\pycocoevalcap\tokenizer\ptbtokenizer.py", line 54, in tokenizep_tokenizer = subprocess.Popen(cmd, cwd=path_to_jar_dirname, \File "D:\ProgramData\Anaconda3\envs\pytorch121\lib\subprocess.py", line 858, in __init__self._execute_child(args, executable, preexec_fn, close_fds,File "D:\ProgramData\Anaconda3\envs\pytorch121\lib\subprocess.py", line 1327, in _execute_childhp, ht, pid, tid = _winapi.CreateProcess(executable, args,
FileNotFoundError: [WinError 2] 系统找不到指定的文件。
解决方案:
修改ptbtokenizer.py中的class PTBTokenizer如下:
class PTBTokenizer:"""Python wrapper of Stanford PTBTokenizer"""def __init__(self, verbose=True):self.verbose = verbose# 确保JAR路径正确self.jar_path = os.path.join(os.path.dirname(os.path.abspath(__file__)),'stanford-corenlp-3.4.1.jar')if not os.path.exists(self.jar_path):raise FileNotFoundError(f"找不到JAR文件: {self.jar_path}")def tokenize(self, captions_for_image):# 检查输入是否为空if not captions_for_image:print("警告: 输入的captions_for_image为空")return {}# 提取句子并检查sentences_list = []image_id = []for k, v in captions_for_image.items():for c in v:image_id.append(k)sentence = c['caption'].replace('\n', ' ').strip()sentences_list.append(sentence)if not sentences_list:print("警告: 提取的句子列表为空")return {}sentences = '\n'.join(sentences_list)# print(f"待处理的句子数量: {len(sentences_list)}")# print(f"第一个句子预览: {sentences_list[0][:50]}...")# 准备临时文件path_to_jar_dirname = os.path.dirname(os.path.abspath(__file__))try:# 使用更安全的临时文件处理with tempfile.NamedTemporaryFile(mode='w', delete=False,dir=path_to_jar_dirname,encoding='utf-8') as tmp_file:tmp_file.write(sentences)tmp_file_name = tmp_file.name# 验证临时文件是否创建成功if not os.path.exists(tmp_file_name):raise FileNotFoundError(f"临时文件未创建: {tmp_file_name}")# 构建命令 - 使用绝对路径cmd = ['java', '-cp', self.jar_path,'edu.stanford.nlp.process.PTBTokenizer','-preserveLines', '-lowerCase',os.path.basename(tmp_file_name)]# 执行命令 - 改进的方式# if self.verbose:# print(f"执行命令: {' '.join(cmd)}")# print(f"工作目录: {path_to_jar_dirname}")# 使用shell=True并捕获错误输出process = subprocess.Popen(cmd,cwd=path_to_jar_dirname,stdout=subprocess.PIPE,stderr=subprocess.PIPE,shell=True,text=True # 使用text模式替代universal_newlines)# 通信并获取结果stdout, stderr = process.communicate()# 检查是否有错误if process.returncode != 0:print(f"命令执行错误 (返回码: {process.returncode})")print(f"错误输出: {stderr}")return {}# if self.verbose and stderr:# print(f"命令警告输出: {stderr}")# 处理结果lines = stdout.split('\n')# 确保行数匹配if len(lines) != len(sentences_list):print(f"警告: 处理后的行数({len(lines)})与输入句子数({len(sentences_list)})不匹配")# 创建结果字典final_tokenized_captions_for_image = {}for k, line in zip(image_id, lines[:len(image_id)]): # 防止索引溢出if k not in final_tokenized_captions_for_image:final_tokenized_captions_for_image[k] = []# 移除标点并处理tokenized_caption = ' '.join([w for w in line.strip().split()if w and w not in PUNCTUATIONS])final_tokenized_captions_for_image[k].append(tokenized_caption)return final_tokenized_captions_for_imageexcept Exception as e:print(f"分词过程中发生错误: {str(e)}")return {}finally:# 确保临时文件被删除if 'tmp_file_name' in locals() and os.path.exists(tmp_file_name):try:os.remove(tmp_file_name)except Exception as e:print(f"删除临时文件失败: {str(e)}")