java面试Day1 | redis缓存穿透、击穿、雪崩、持久化、双写一致性、数据过期策略、数据淘汰策略、分布式锁、redis集群
目录
应届生如何找到合适的练手项目
面试形式
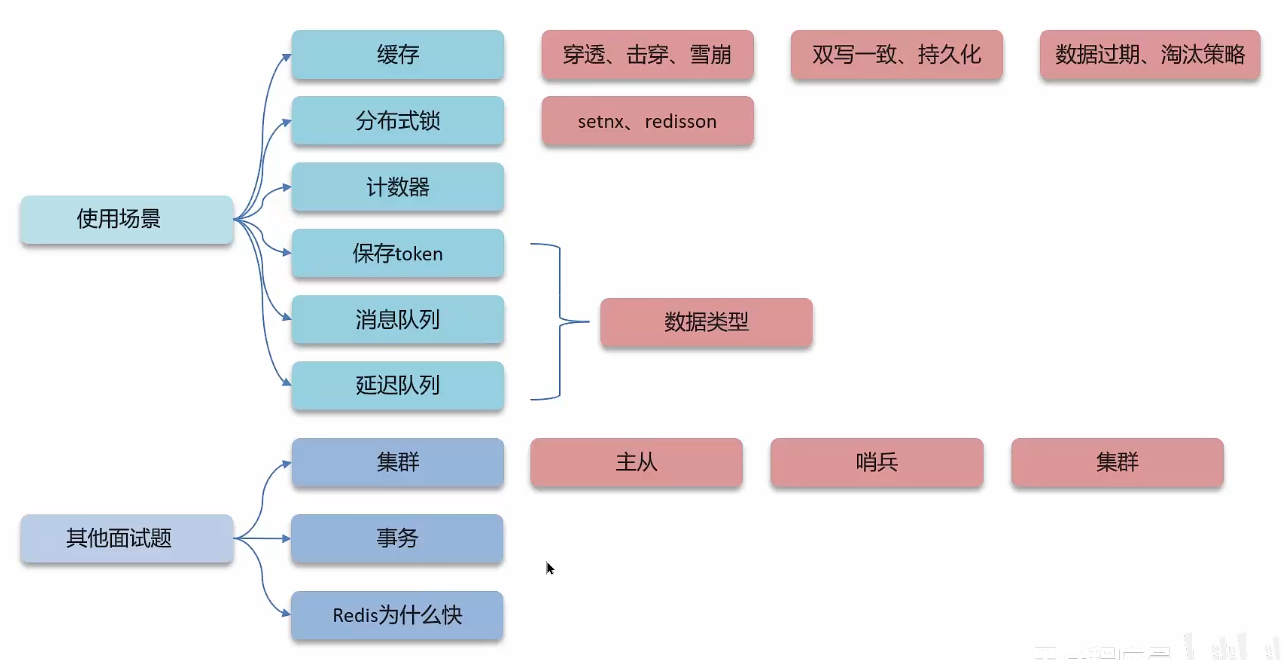
Redis篇
redis使用场景-缓存-缓存穿透
补充知识:布隆过滤器
1. 初始化
2. 插入元素(以元素 “Apple” 为例)
3. 查询元素(判断 “Banana” 是否在集合中)
redis使用场景-缓存-缓存击穿
redis使用场景-缓存-缓存雪崩
redis使用场景-缓存-双写一致性
情况一:分布式锁/读写锁:保证数据强一致性,但性能低
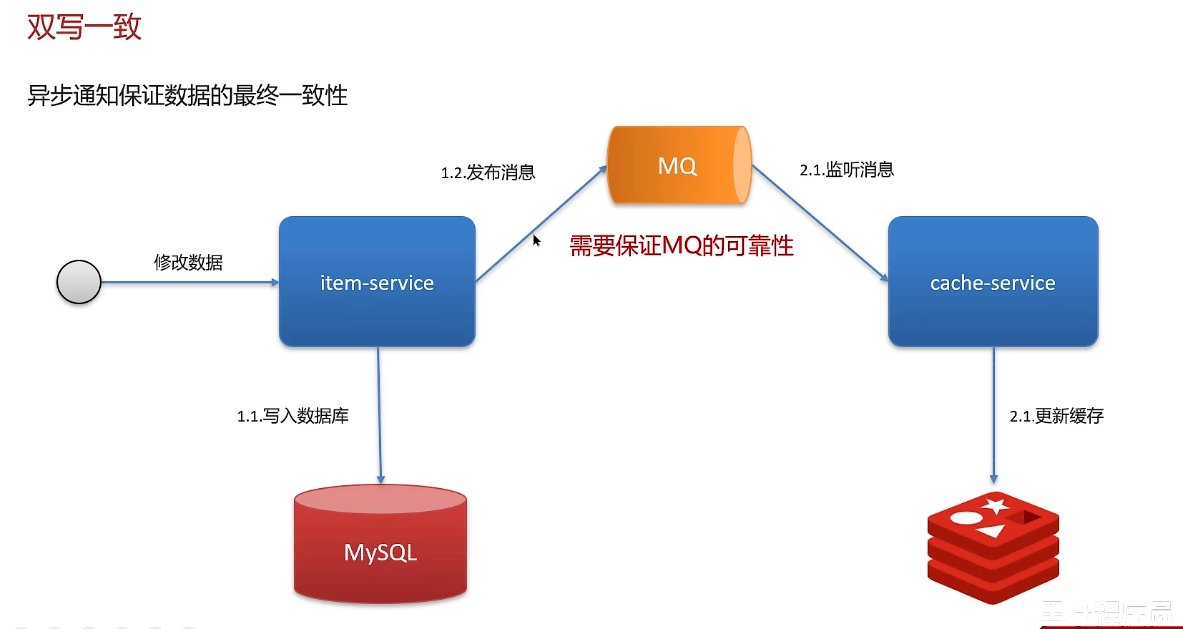
情况二:允许延迟一致/保证数据的最终一致性
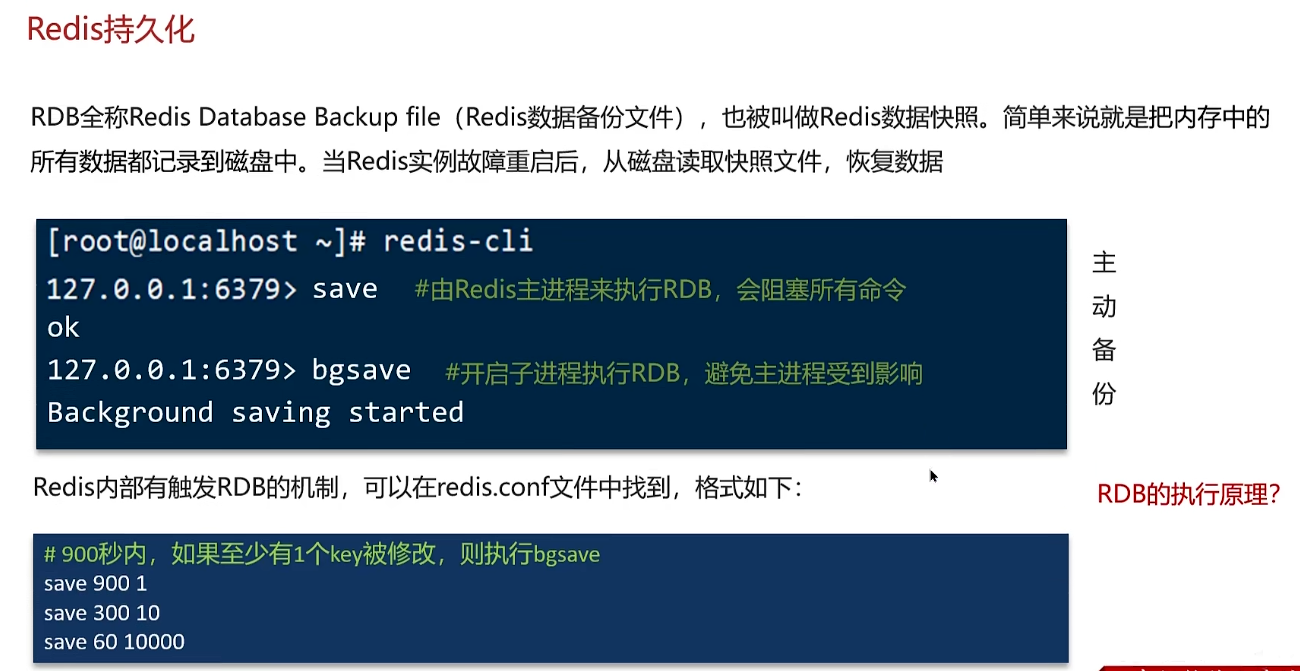
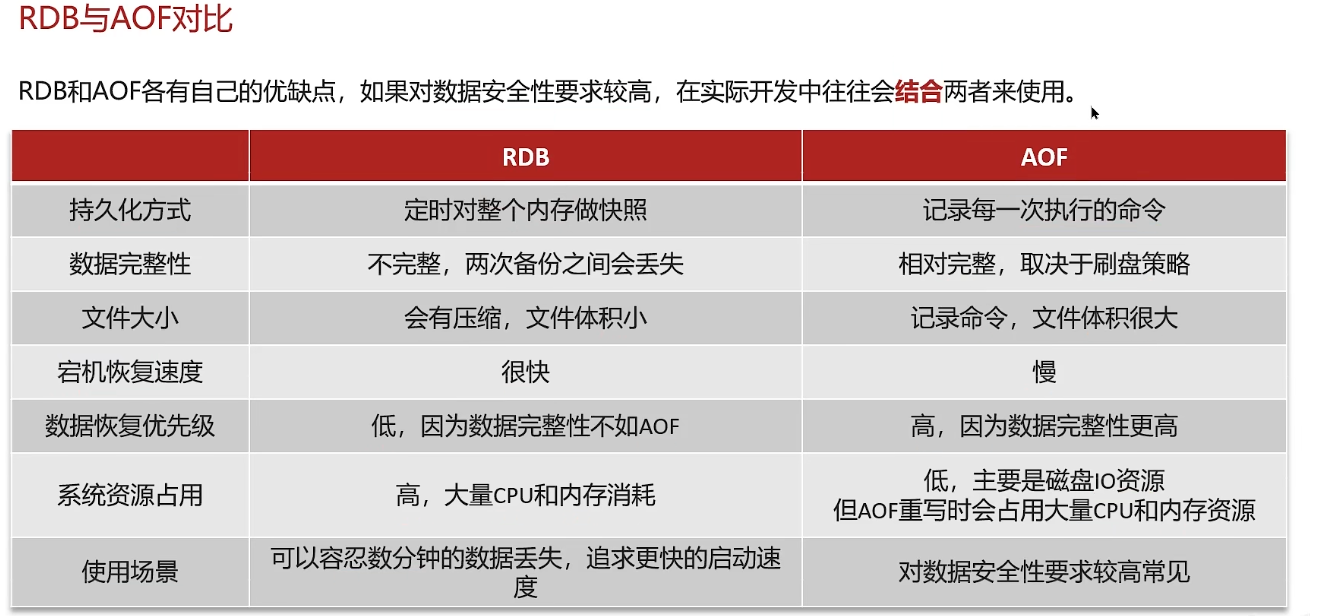
redis使用场景-缓存-持久化
RDB数据快照
AOF追加文件
redis使用场景-缓存-数据过期策略
1. 惰性删除
2. 定期删除
redis使用场景-缓存-数据淘汰策略
redis分布式锁-使用场景
redis分布式锁-实现原理(setnx、redission)
1. setnx
2. redisson
redisson实现的分布式锁--可重入
redisson实现的锁--主从一致性
redis其他面试问题--主从复制、主从同步流程
1. 主从复制:解决高并发问题,缺点是不能保证高可用
2. 哨兵模式、集群脑裂:哨兵模式解决高可用问题
3. 分片集群结构:解决海量数据、高并发写的问题
redis其他面试题:redis是单线程的,为什么还这么快?
应届生如何找到合适的练手项目
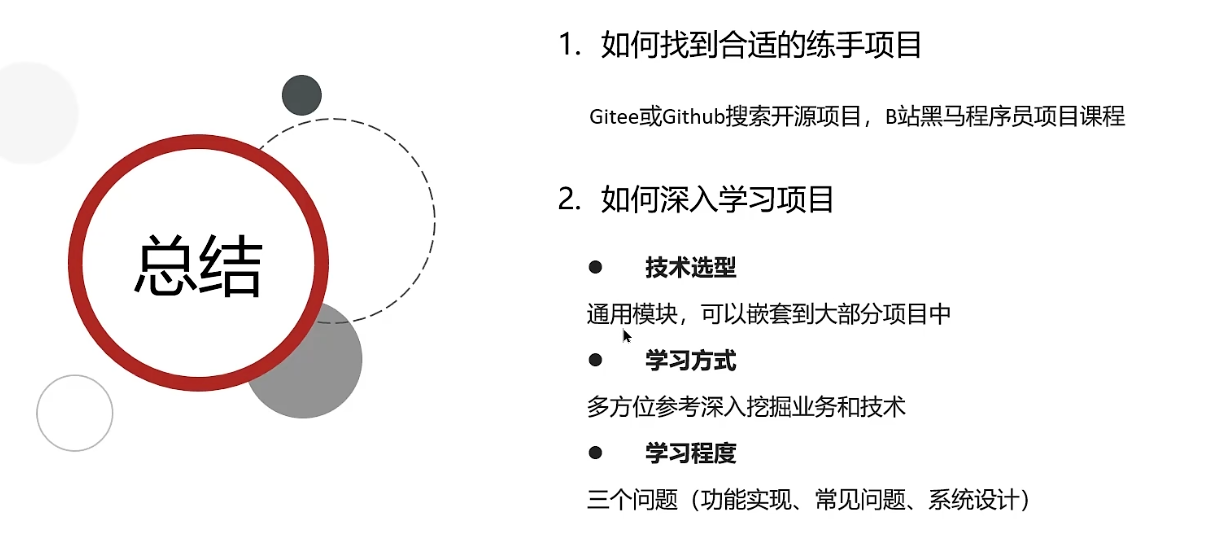
参考多个项目深挖某一个功能的实现
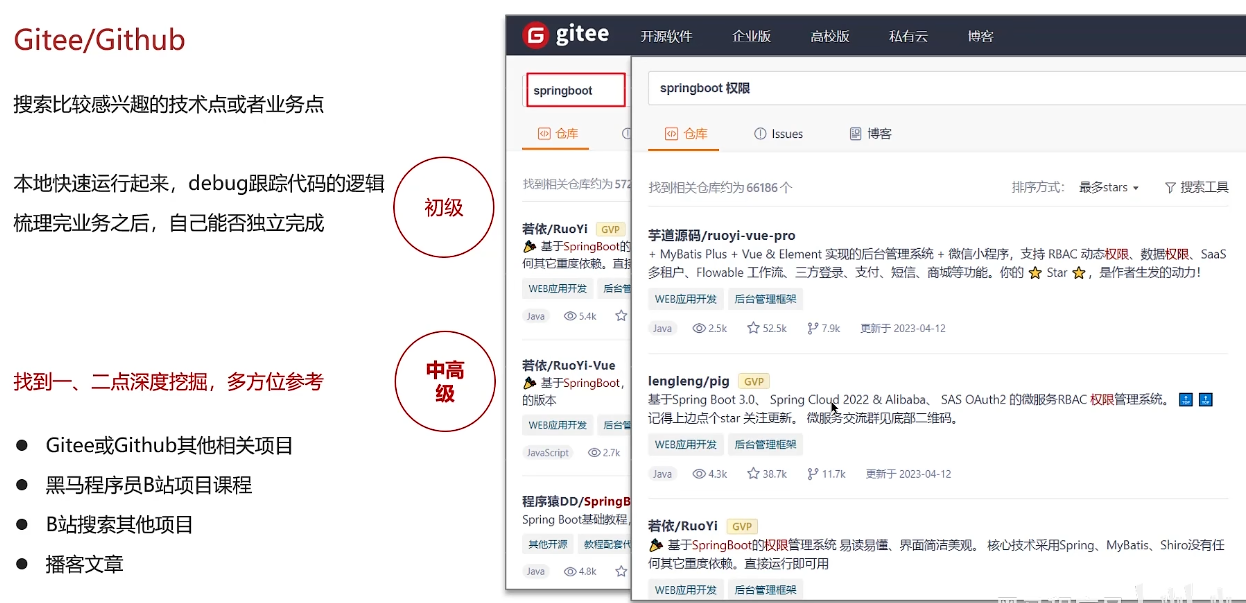


面试形式


多查看招聘网站


Redis篇

redis使用场景-缓存-缓存穿透


补充知识:布隆过滤器
布隆过滤器的本质是一个二进制数组(bit array) + 多个哈希函数(Hash Function),核心逻辑分两步:插入元素和查询元素。
1. 初始化
先创建一个长度为 m 的二进制数组(初始时所有位都设为 0),并选定 k 个独立的哈希函数(哈希函数需满足 “均匀分布”,避免哈希碰撞集中)。
例:假设 m=10,k=2,初始数组为 [0,0,0,0,0,0,0,0,0,0]。
2. 插入元素(以元素 “Apple” 为例)
对插入的元素,用 k 个哈希函数分别计算出 k 个哈希值,再将这些哈希值对数组长度 m 取模,得到 k 个 “数组下标”,最后将数组中这些下标的值从 0 改为 1。
- 例:用哈希函数 1 计算 “Apple” 得哈希值
15,15 mod 10 = 5→ 下标 5 设为 1; - 用哈希函数 2 计算 “Apple” 得哈希值
23,23 mod 10 = 3→ 下标 3 设为 1; - 插入后数组变为
[0,0,0,1,0,1,0,0,0,0]。
3. 查询元素(判断 “Banana” 是否在集合中)
对查询的元素,同样用 k 个哈希函数计算 k 个下标,然后检查数组中这些下标的值:
- 若所有下标都是 1:元素 “可能存在”(存在假阳性);
- 若有任意一个下标是 0:元素 “绝对不存在”(无假阴性)。
- 例:查询 “Banana”,哈希后得到下标
2和7,数组中这两个位置都是 0 → 判定 “Banana 绝对不在集合中”; - 若查询某个元素,哈希后得到下标
3和5(均为 1)→ 判定 “该元素可能在集合中”(无法 100% 确定,因为其他元素的哈希也可能覆盖这两个位置)。
| 特性 | 说明 |
|---|---|
| 空间效率极高 | 仅用二进制位存储,无需存储元素本身。例如,存储 100 万条数据,仅需约 1MB 内存(传统集合需数十 MB)。 |
| 查询速度极快 | 仅需执行 k 次哈希计算和数组访问,时间复杂度为 O(k)(k 通常是个位数,如 3-5)。 |
| 无假阴性 | 只要元素确实在集合中,查询结果一定是 “存在”,不会漏判。 |
| 有假阳性 | 元素不在集合中时,可能因哈希碰撞被误判为 “存在”,假阳性率可通过参数调节。 |
| 不支持删除元素 | 二进制位是 “共享” 的(一个位可能被多个元素标记),删除一个元素会导致其他元素的标记被破坏,进而引发假阴性。 |
假阳性率(False Positive Rate, FPR)是布隆过滤器的核心指标,主要由三个参数决定:
m:二进制数组的长度(越长,FPR 越低);k:哈希函数的个数(过少会导致碰撞多,过多会增加查询时间和 FPR);n:集合中实际存储的元素数量(越多,FPR 越高)
通过数学公式可计算理论假阳性率:
FPR ≈ (1 - e^(-kn/m))^k
实际应用中,通常会根据需求先确定 n 和可接受的 FPR,再反推 m 和 k 的最优值。例如:
- 若需存储
n=100万条数据,接受FPR=0.1%,则最优m≈140万位(约 170KB),k=10。
布隆过滤器的特性使其特别适合 “过滤不存在的元素”,减少后续高成本操作,常见场景包括:
-
缓存穿透防护(最经典场景)
缓存穿透:用户请求不存在的数据(如查询 ID=-1 的用户),导致请求直接穿透缓存,冲击数
解决方案:将数据库中所有存在的 ID 存入布隆过滤器,据库。请求先经过过滤器 —— 若判定 “不存在”,直接返回空结果;若判定 “可能存在”,再查缓存和数据库,避免无效数据库查询。 -
分布式系统去重
例如:分布式爬虫去重(判断 URL 是否已爬取)、消息队列去重(判断消息 ID 是否已消费)—— 无需在多个节点间同步完整数据集,仅需共享布隆过滤器即可快速去重。 -
LevelDB/RocksDB 等数据库
这类嵌入式数据库的底层用布隆过滤器优化 “不存在 key 的查询”:先查布隆过滤器,若判定 “不存在”,直接返回,无需读取磁盘(磁盘 IO 成本远高于内存查询)。 -
黑名单校验
例如:垃圾邮件过滤(校验发件人邮箱是否在黑名单)、IP 黑名单(拦截恶意 IP)—— 无需存储完整黑名单,仅用布隆过滤器快速过滤,再对 “可能存在” 的情况做二次校验(降低假阳性影响)。
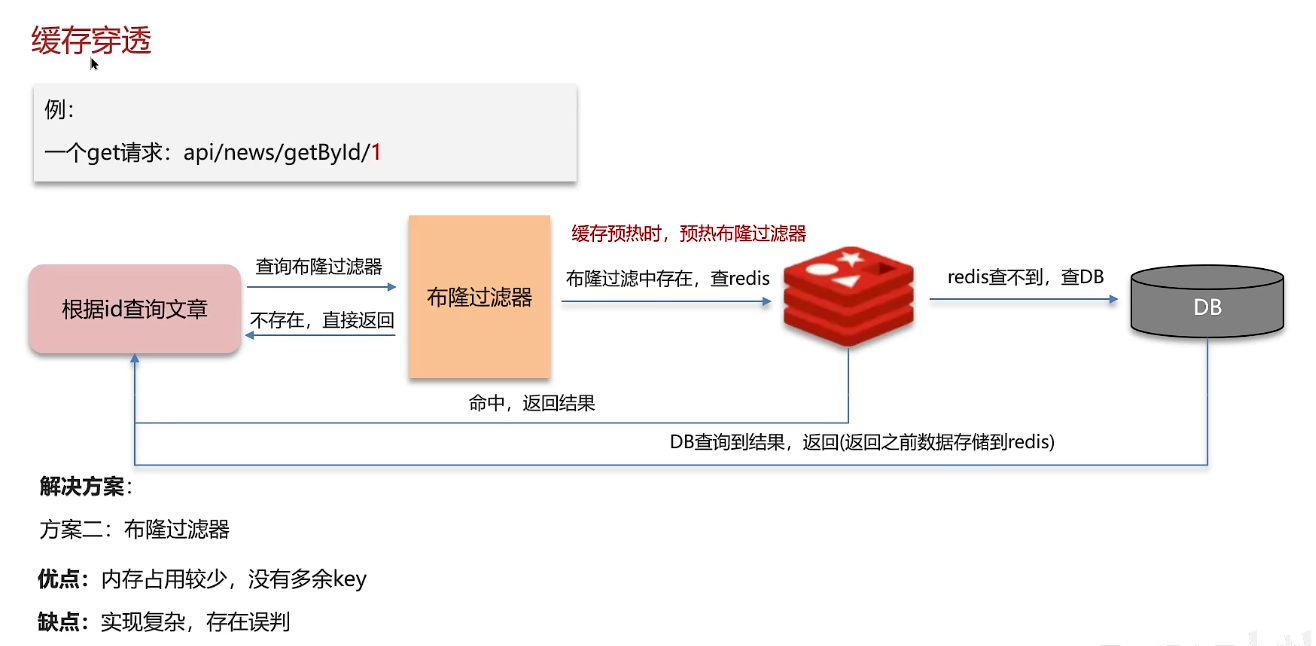
布隆过滤器:拦截不存在的数据。检索一个元素是否在一个集合中,但可能出现假阳性
缓存预热时,要同时预热布隆过滤器

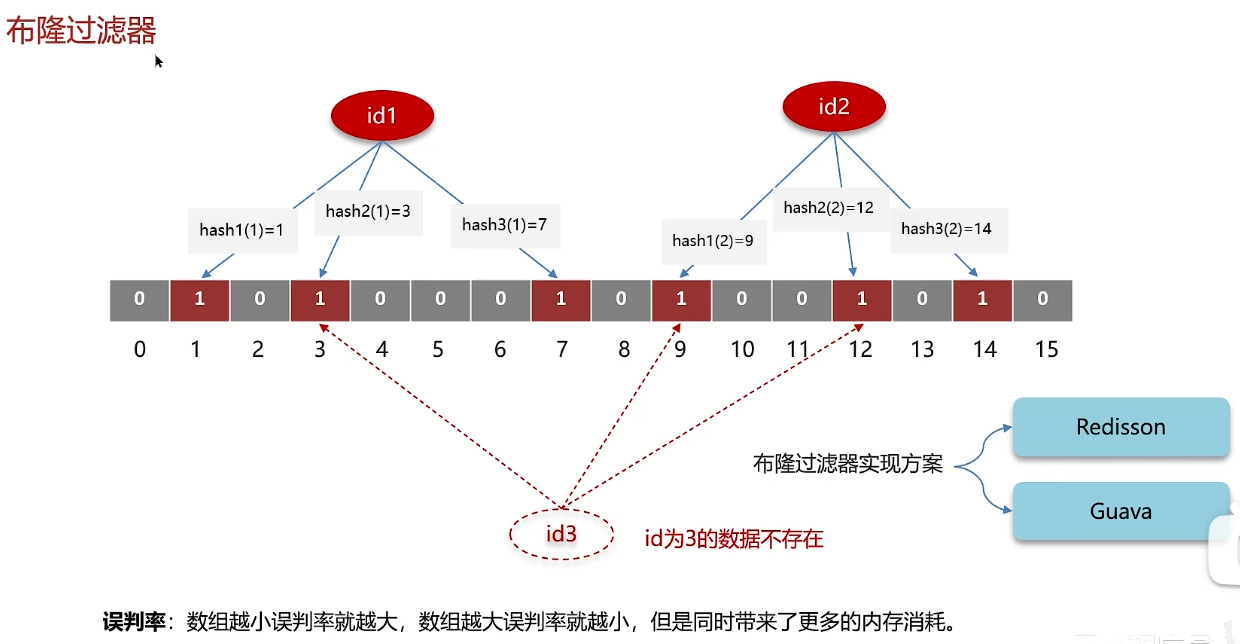
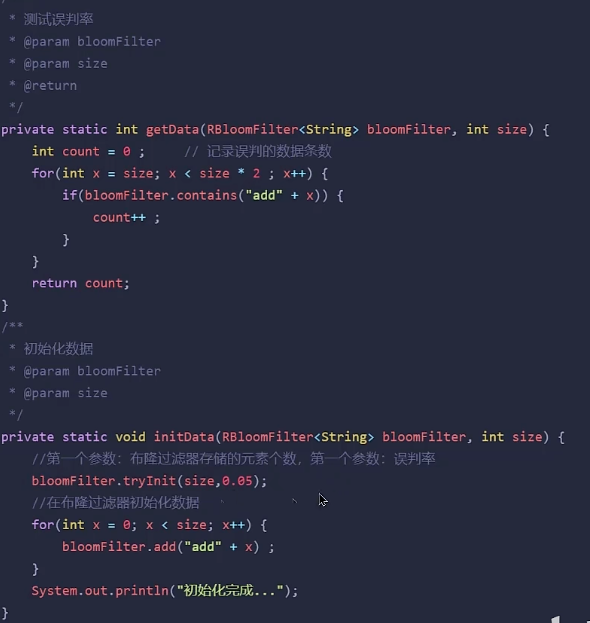
误判率可以在使用布隆过滤器的时候设置,一般项目5%可以接受

redis使用场景-缓存-缓存击穿

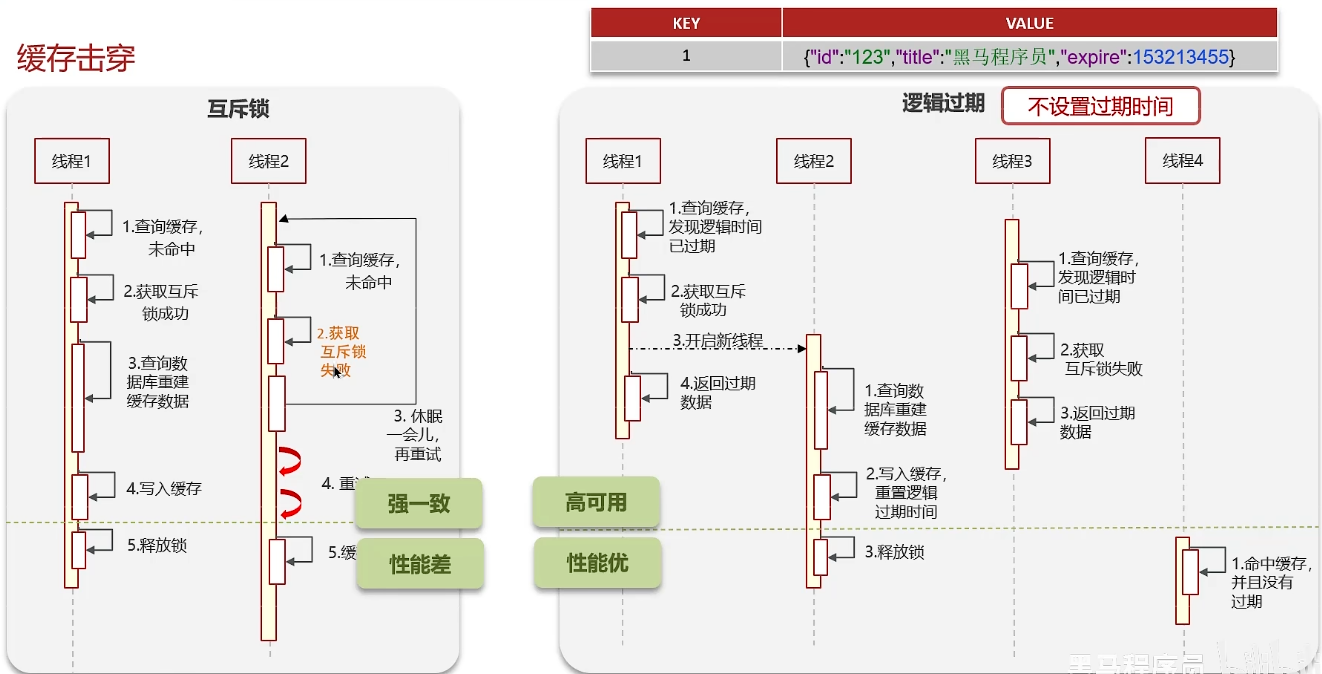
互斥锁:强一致、性能差
逻辑过期:高可用、性能优


redis使用场景-缓存-缓存雪崩



redis使用场景-缓存-双写一致性

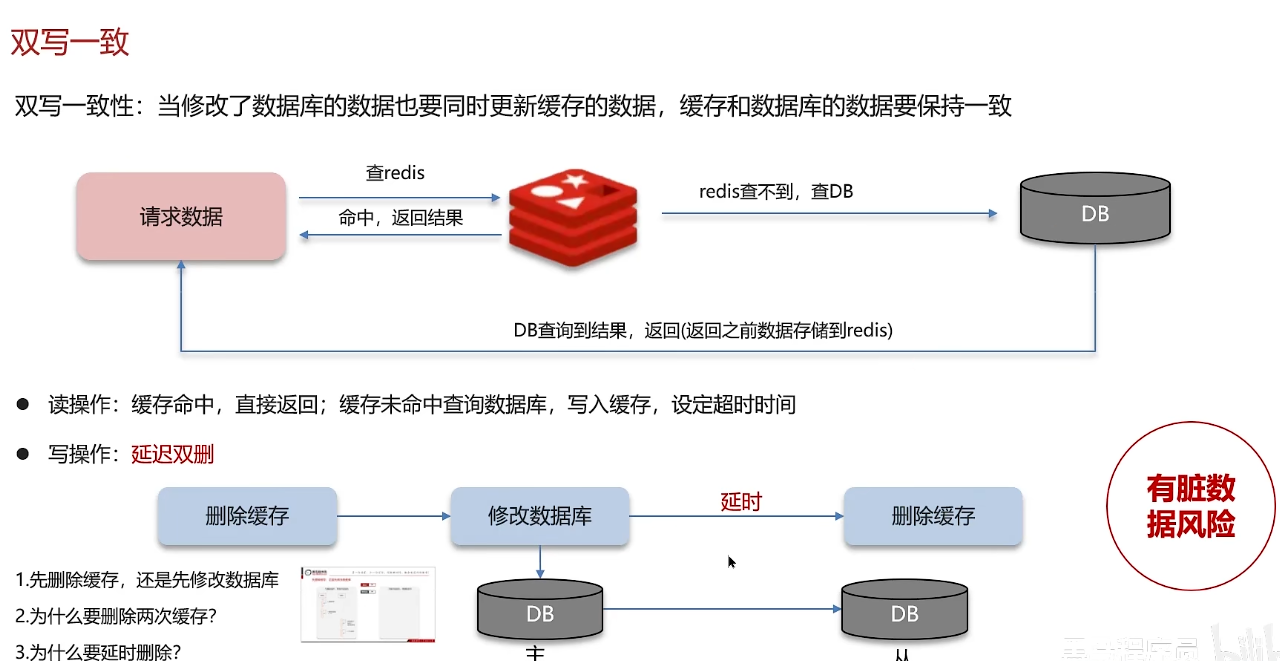
写操作:延迟双删
1. 不管是先删除缓存还是先修改数据库,都会出现问题、数据不一致的情况
2. 为什么删除两次缓存?
先删缓存再删数据库会有脏数据,所以要再次删除缓存,减少脏数据的出现
3. 为什么要延迟双删?
一般情况下,数据库是主从模式,读写分离,需要延时一会,让数据从主节点同步到从节点。但是延时也可能出现问题,因为延时的时间不好控制,在延时过程中仍然可能出现脏数据。所以延时双删极大控制了脏数据的风险,但也只是控制了一部分,做不到绝对强一致
情况一:分布式锁/读写锁:保证数据强一致性,但性能低
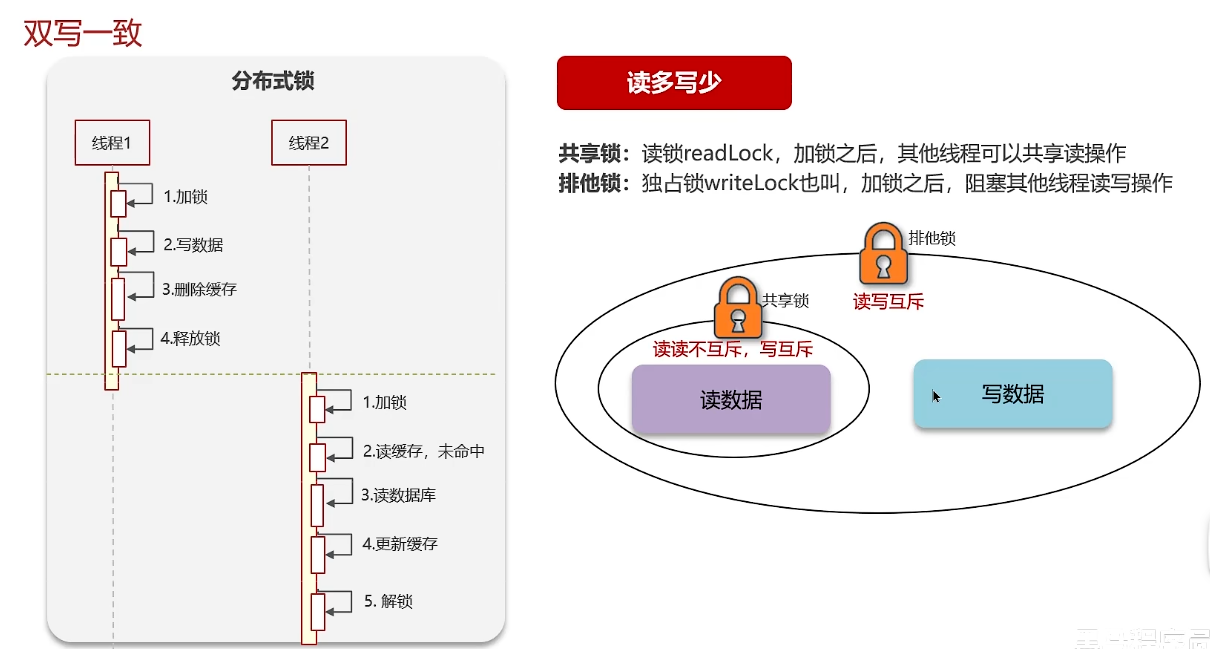
一般放入缓存中的数据都是读多写少,读:加共享锁,写:加排他锁
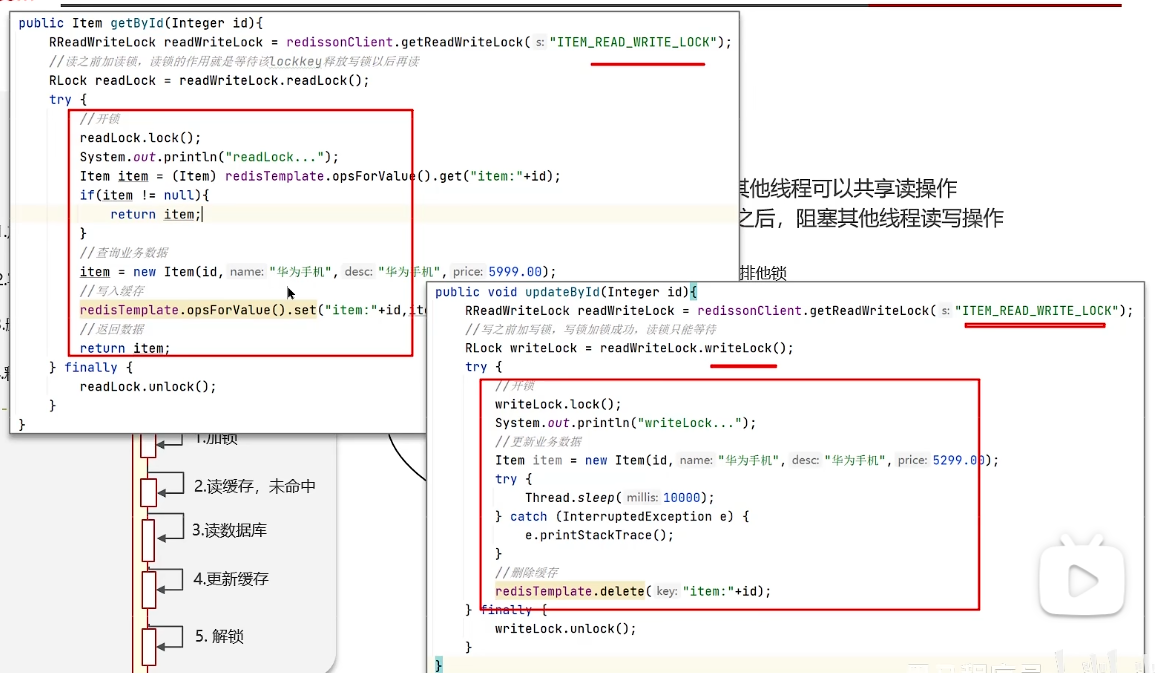
情况二:允许延迟一致/保证数据的最终一致性
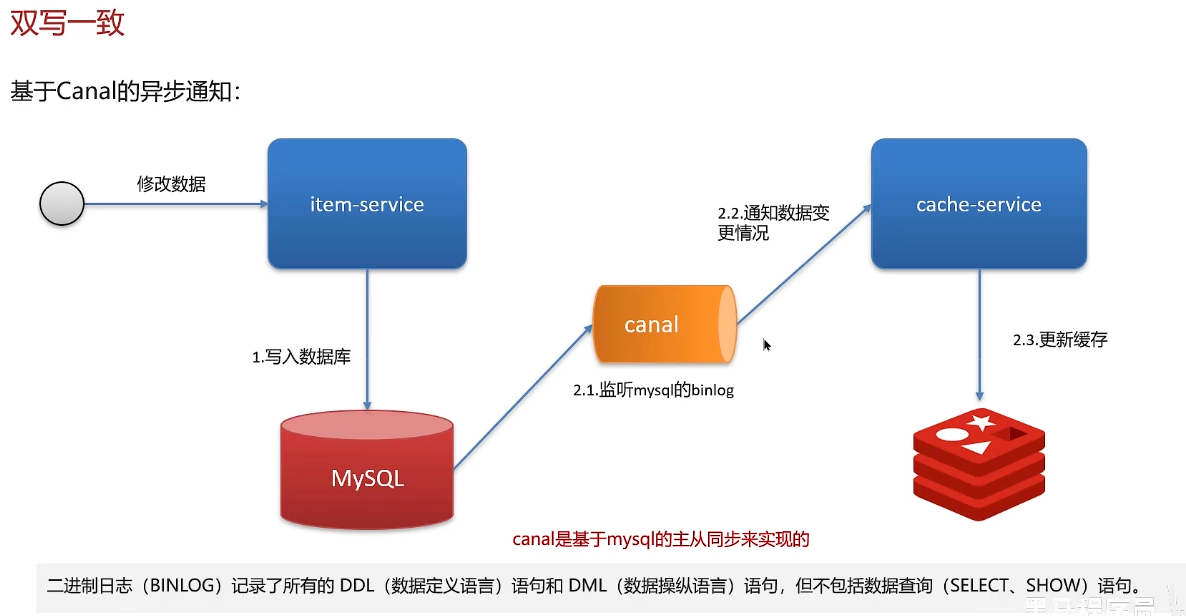
如果可以接受项目短暂延时,canal基于二进制日志binlog是一个不错的选择。其实只有在大并发的情况下才会出现短暂的不一致
好处:对于业务代码是0侵入的


redis使用场景-缓存-持久化

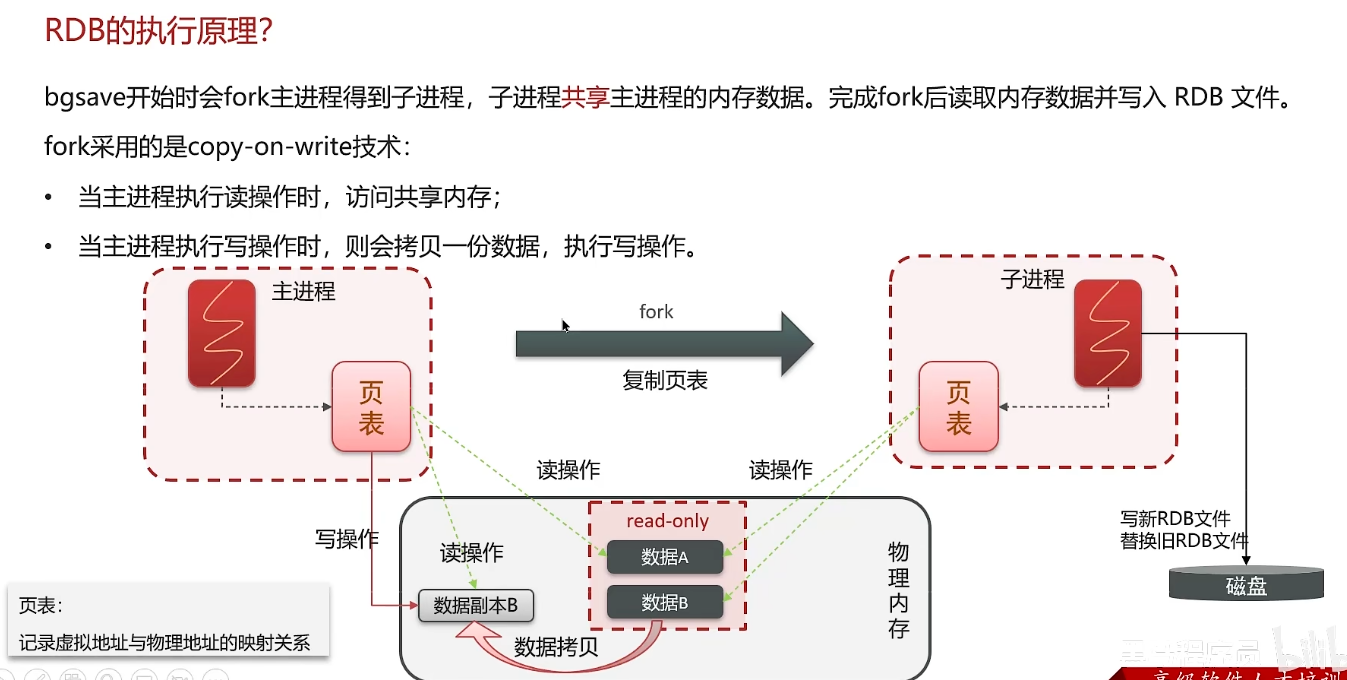
RDB数据快照
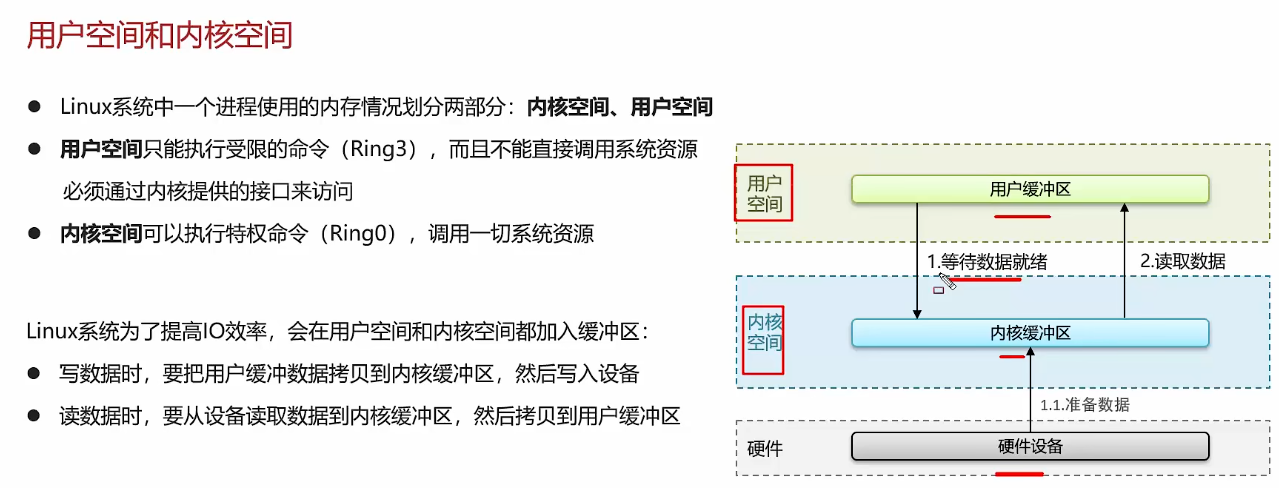
操作系统维护一个虚拟内存和物理内存的映射关系表:页表
主进程操作页表

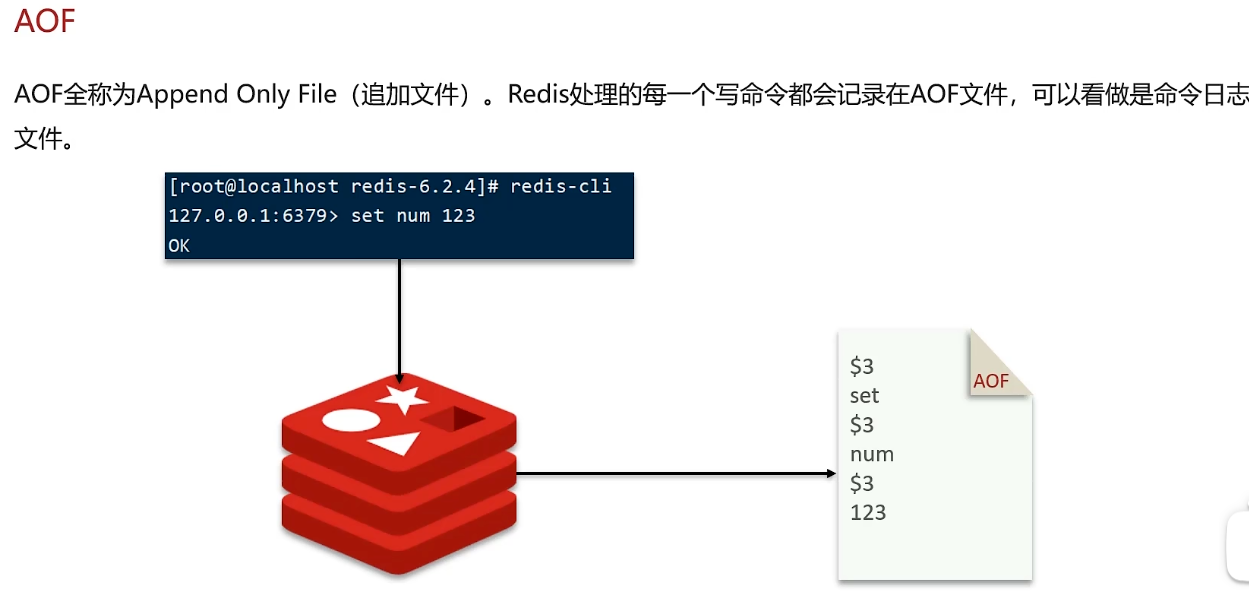
AOF追加文件
Redis处理的每个写命令都会记录在AOF文件。 AOF默认是关闭的,需要在redis.conf配置文件中开启AOF



redis使用场景-缓存-数据过期策略

惰性删除、定期删除
1. 惰性删除

2. 定期删除



redis使用场景-缓存-数据淘汰策略






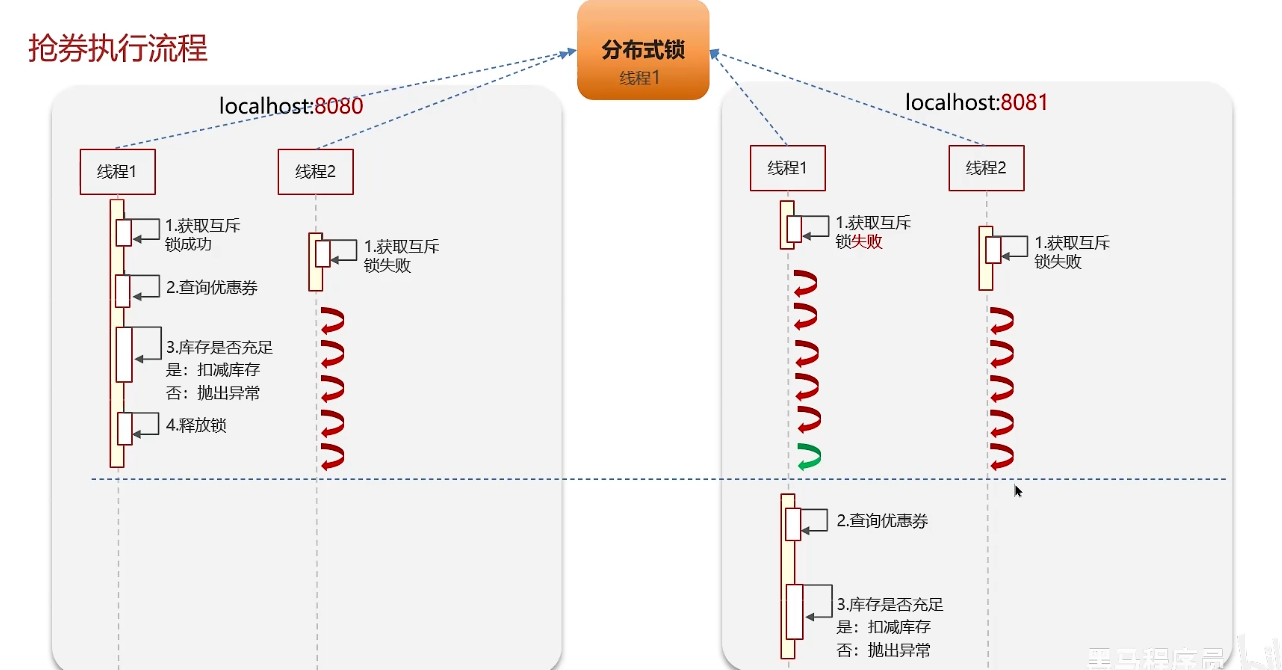
redis分布式锁-使用场景

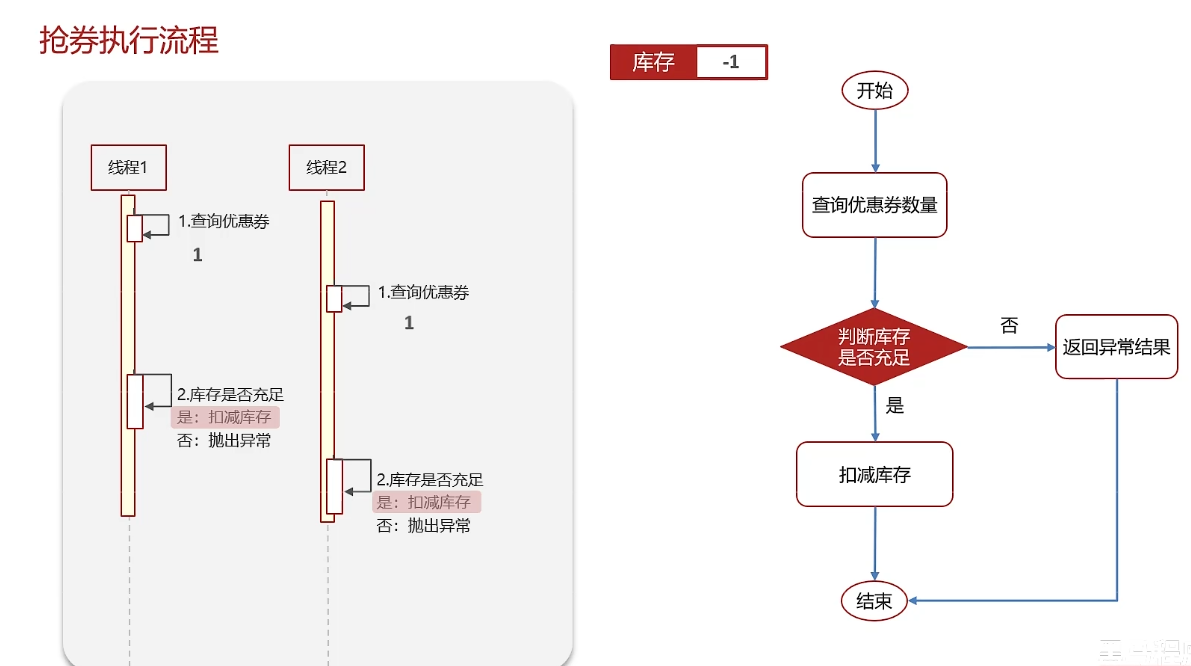
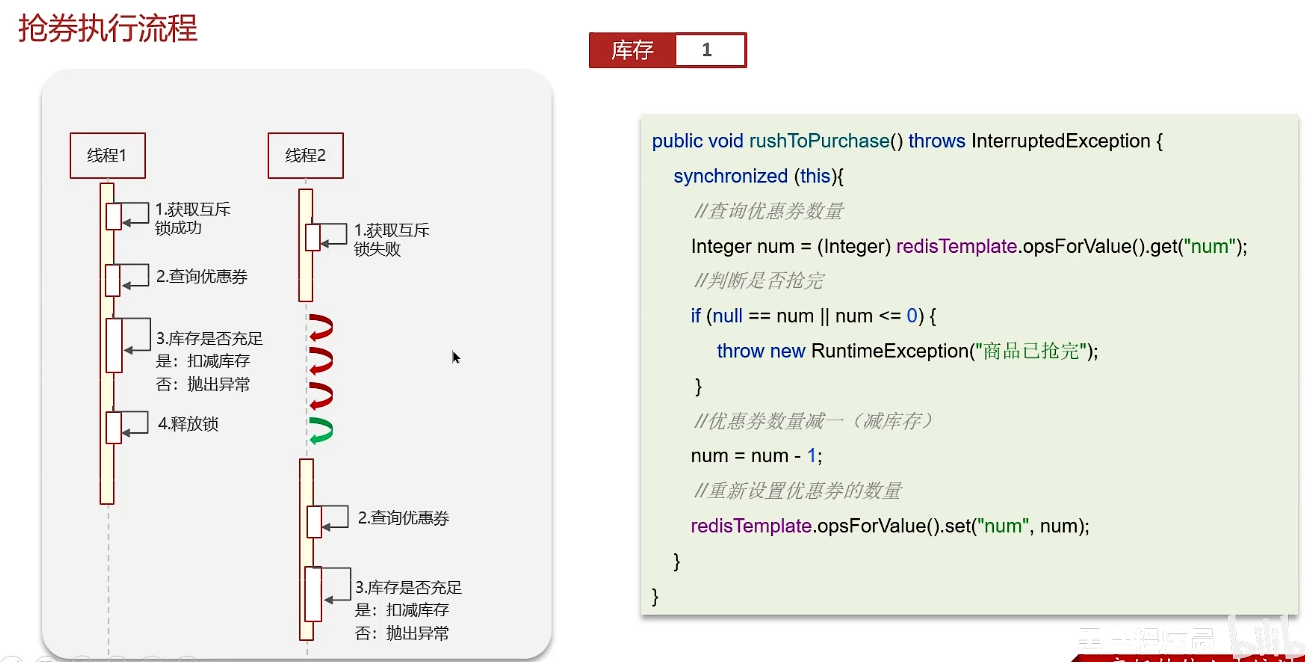
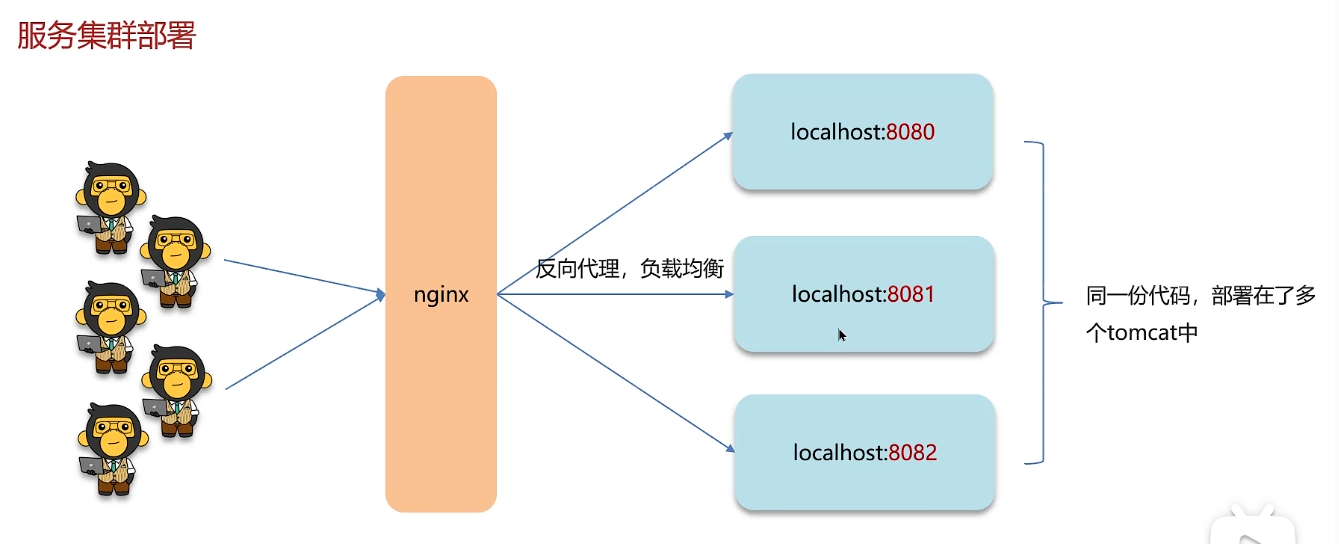
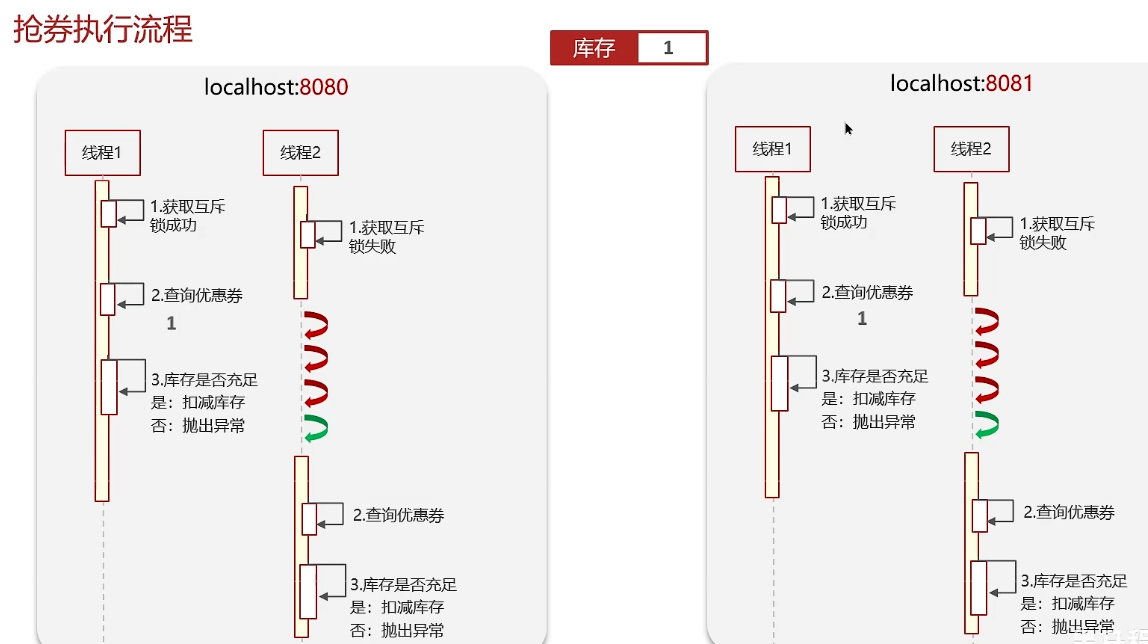
但是有可能服务集群部署,同一份代码部署在了多个tomcat中,所以这种方法只能解决同一个JVM下线程的互斥,不能解决多个JVM下线程的互斥。
在这种情况下就需要使用外部的锁:分布式锁
redis分布式锁-实现原理(setnx、redission)
1. setnx
设置失效时间防止死锁:防止当前获得锁的进程业务超时或服务宕机,没人释放锁

2. redisson
redis是一个高性能的键值存储、内存数据库,redisson是基于redis的java客户端框架。
redis用setnx实现的分布式锁是不可重入的,redisson实现的分布式锁是可重入的
重试机制
watchdog给锁续期
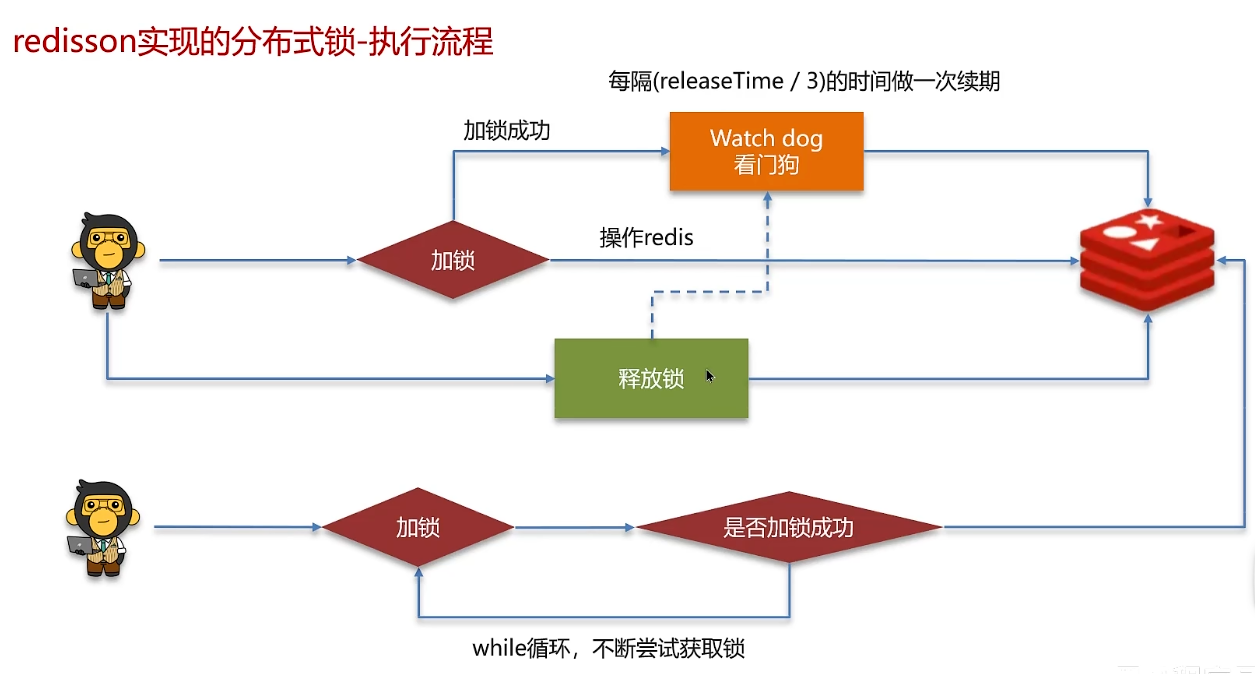
tryLock的第一个参数: while循环尝试的最大等待时间
第二个参数:如果设置了锁自动释放时间,就不安排watch dog了;如果没设置,就安排watch dog做锁的续期
加锁、设置过期时间等(redisson)操作都是基于lua脚本完成的,用来保证操作的原子性

redisson实现的分布式锁--可重入
可重入:在分布式环境下,支持同一个线程多次获取同一把锁
redis是一个高性能的键值存储、内存数据库,redisson是基于redis的java客户端框架。
redis用setnx实现的分布式锁是不可重入的,redisson实现的分布式锁是可重入的

field存储pid,
value:当前线程重入次数,get时+1,unlock时-1,当value=0就可以删除锁信息
每个线程在执行时都有一个唯一的线程ID做标识 pid,如果是同一个线程就可以成功获取锁
可重入用处:
1. 业务比较复杂,锁的粒度比较细,用到锁的重入
2. 避免多个锁之间产生死锁的问题
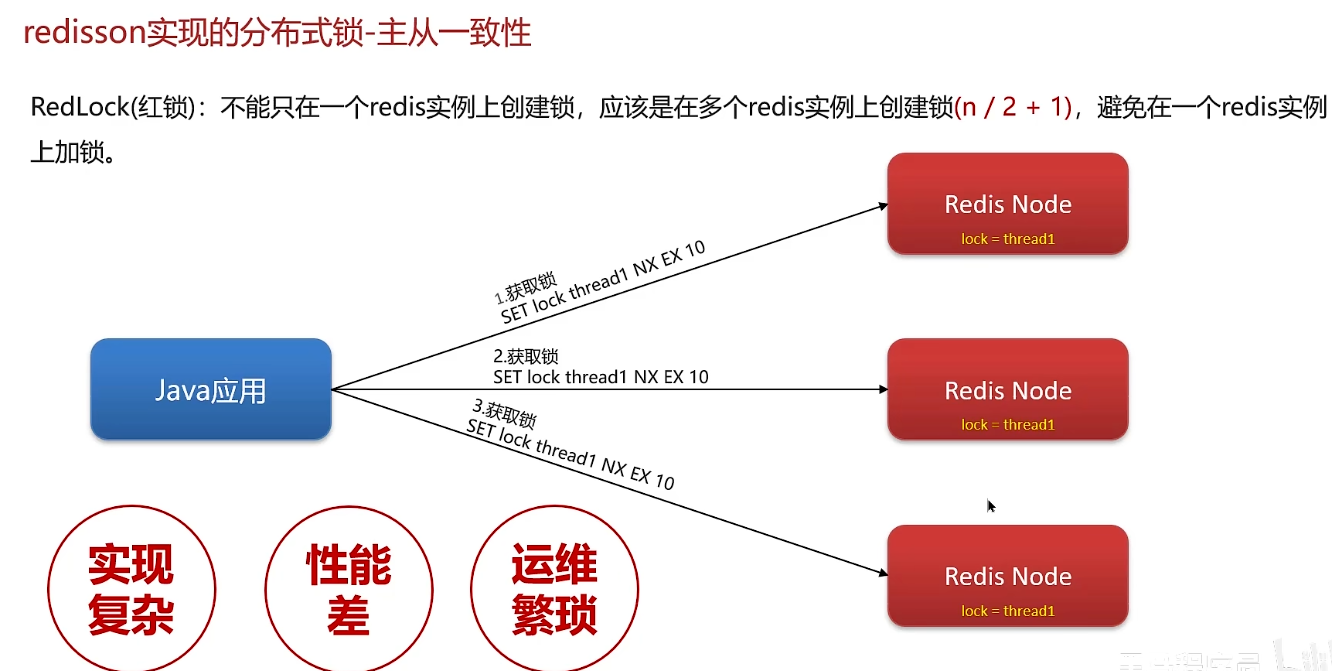
redisson实现的锁--主从一致性
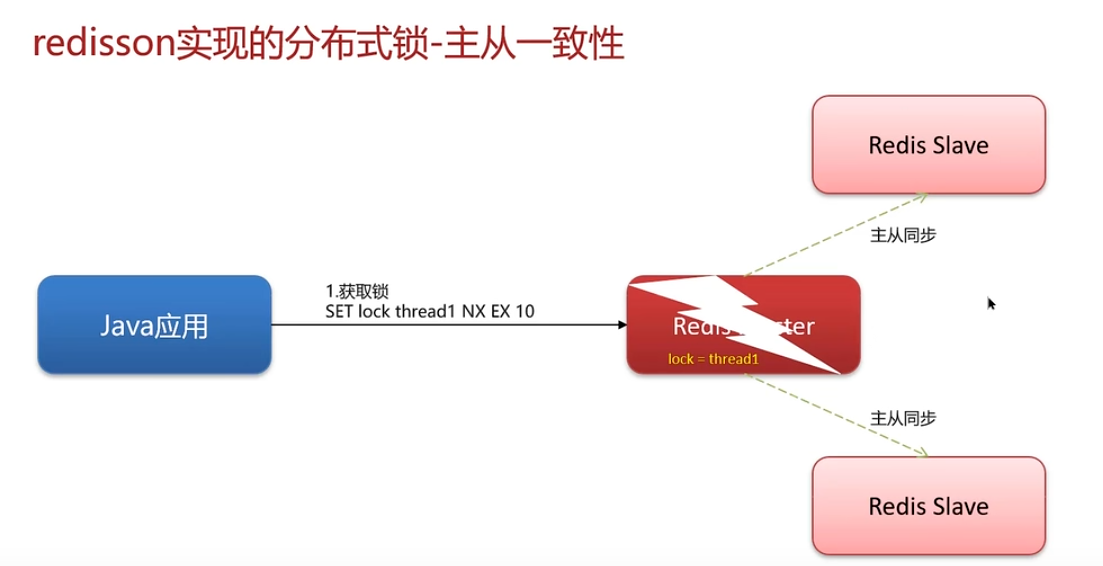
主节点master主要负责写操作,从节点slave主要做读操作
当主节点进行数据改变就要同步给从节点
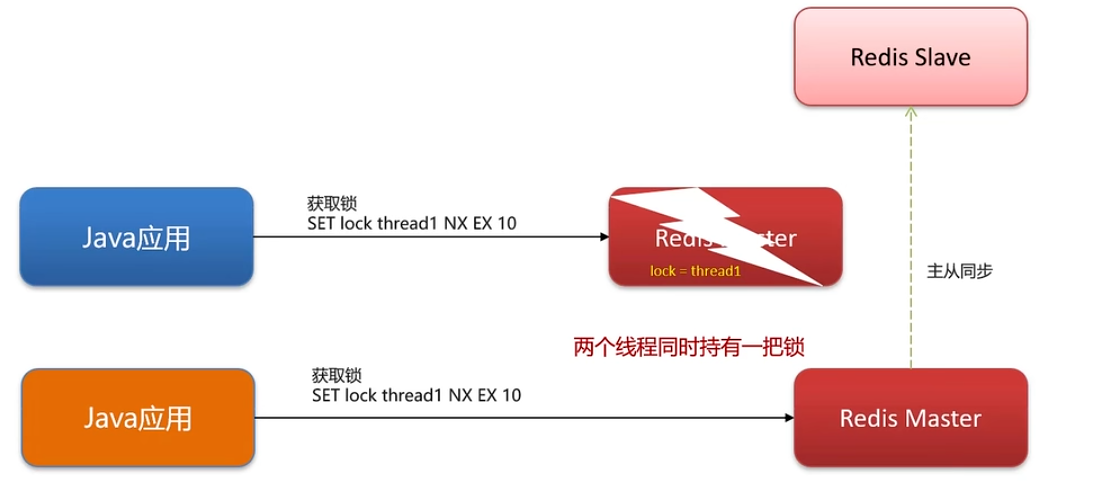
如果主节点宕机了,就从从节点中选出一个当做主节点,当有新的线程来了,就请求新的主节点。
这样两个线程都持有锁,破坏了锁的互斥性,可能会导致脏数据
红锁很少使用:实现复杂(需要多个节点同时持有锁),性能差,运维繁琐
redis:AP思想,主要保证高可用性
如果非要保证某些数据的强一致性,可以使用zookeeper的CP思想,实现分布式锁

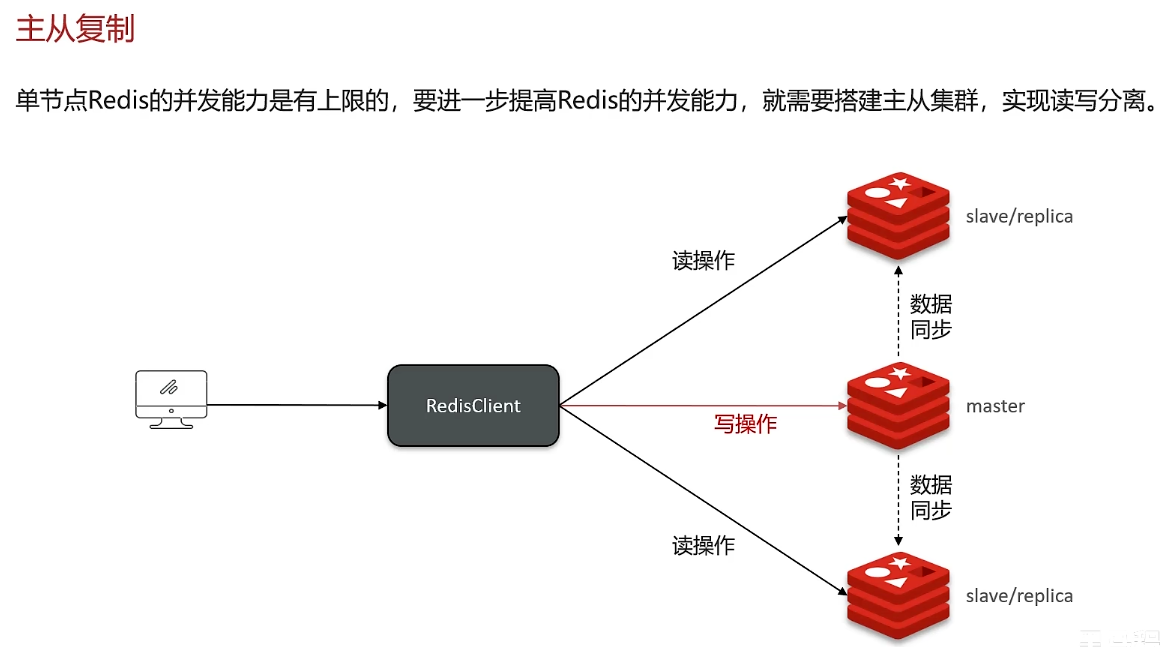
redis其他面试问题--主从复制、主从同步流程

redis的集群方案:主从复制、哨兵模式、分片集群
1. 主从复制:解决高并发问题,缺点是不能保证高可用
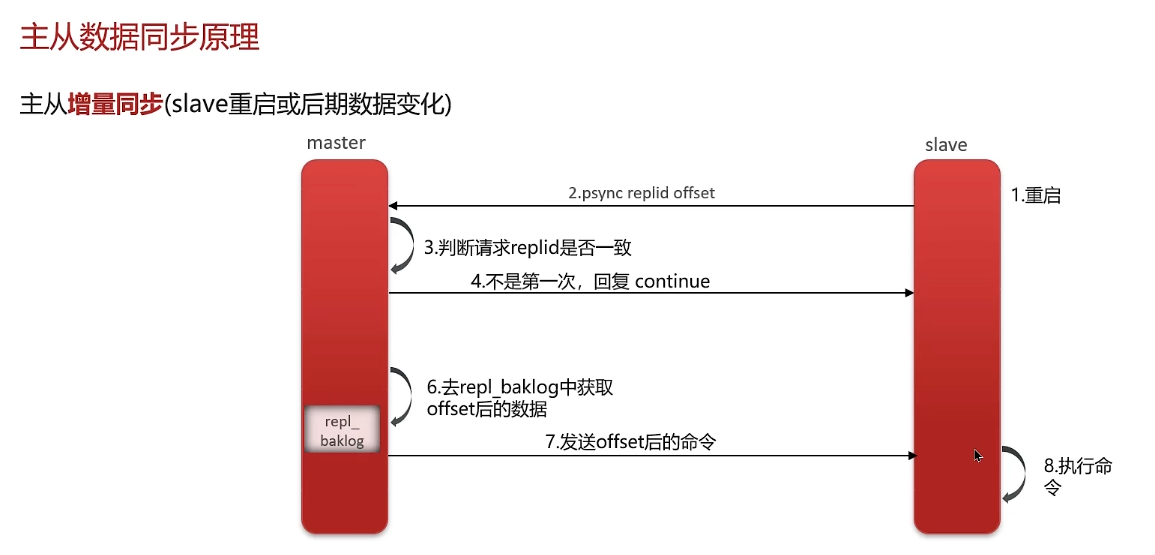
主从全量同步:

主从增量同步:(slave重启或后期数据变化)


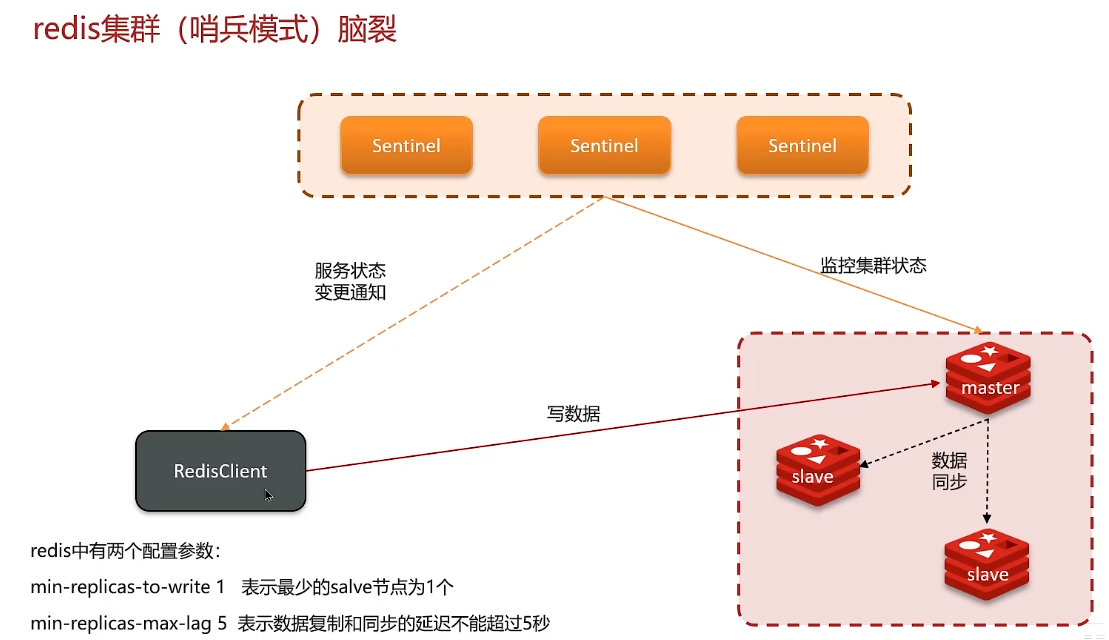
2. 哨兵模式、集群脑裂:哨兵模式解决高可用问题
哨兵由多个redis节点组成,也是一个集群,一般至少部署三台哨兵
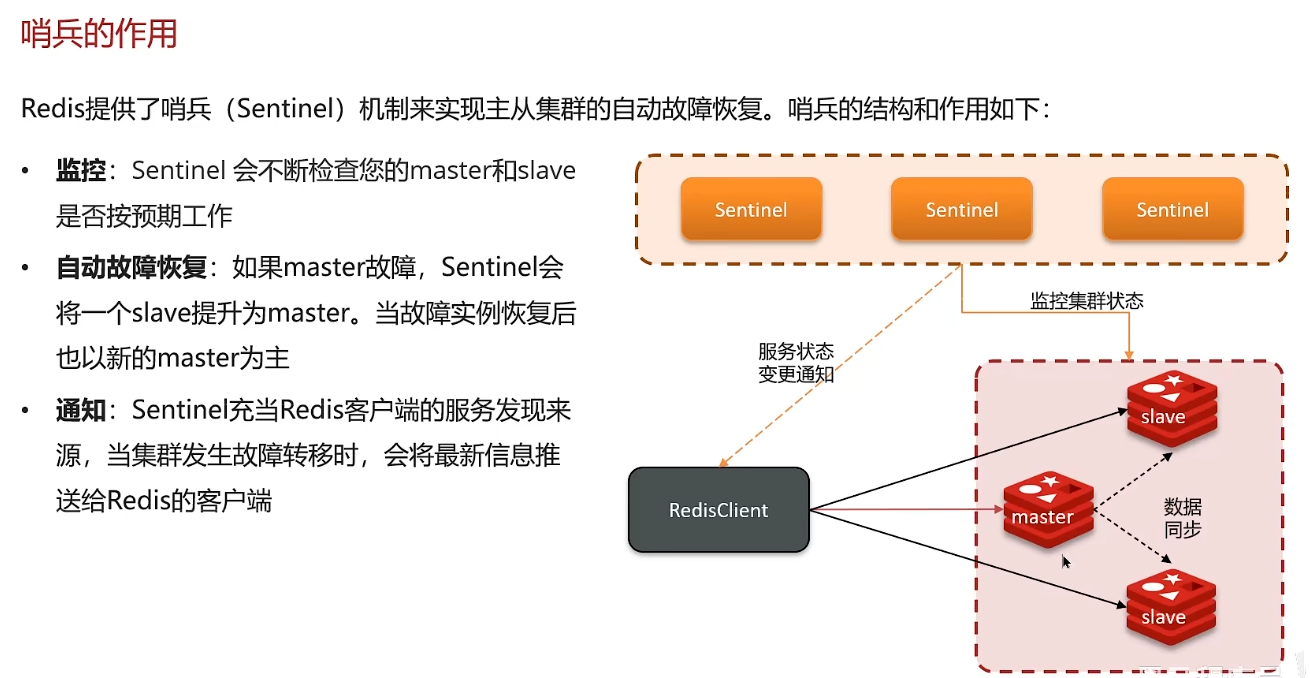

问题:脑裂会导致数据丢失
redis单节点的写并发在8万左右,redis单节点的读数据是10万左右
如果redis内存不足可以给不同服务分配独立的redis主从节点


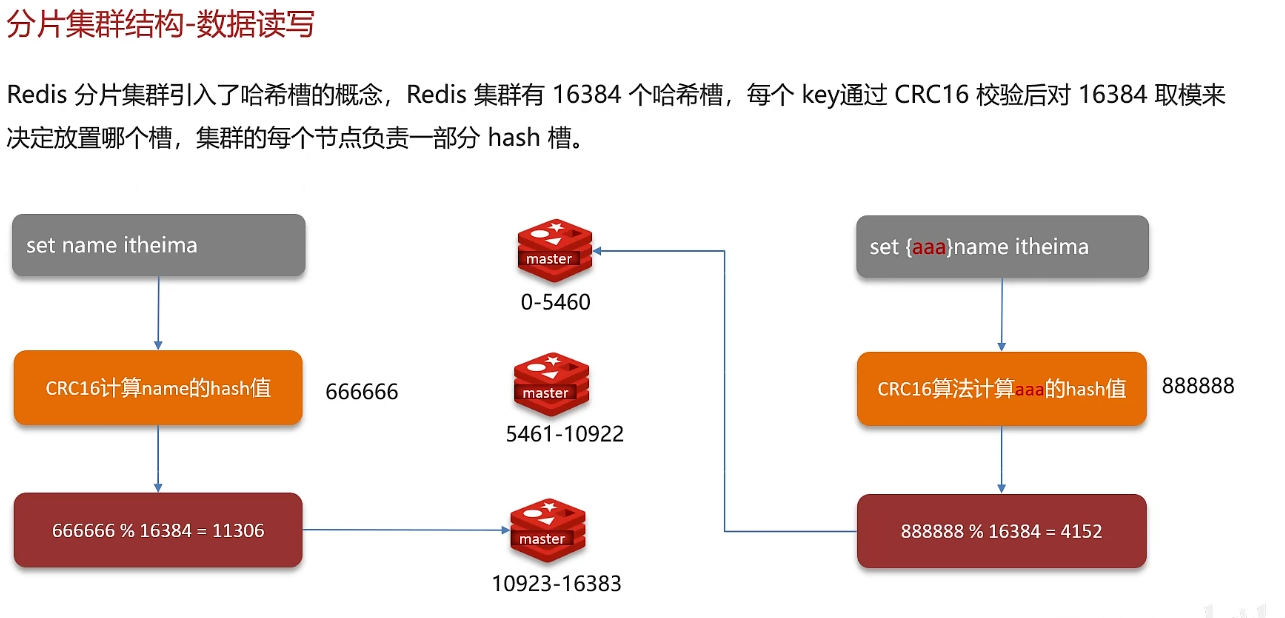
3. 分片集群结构:解决海量数据、高并发写的问题


redis其他面试题:redis是单线程的,为什么还这么快?

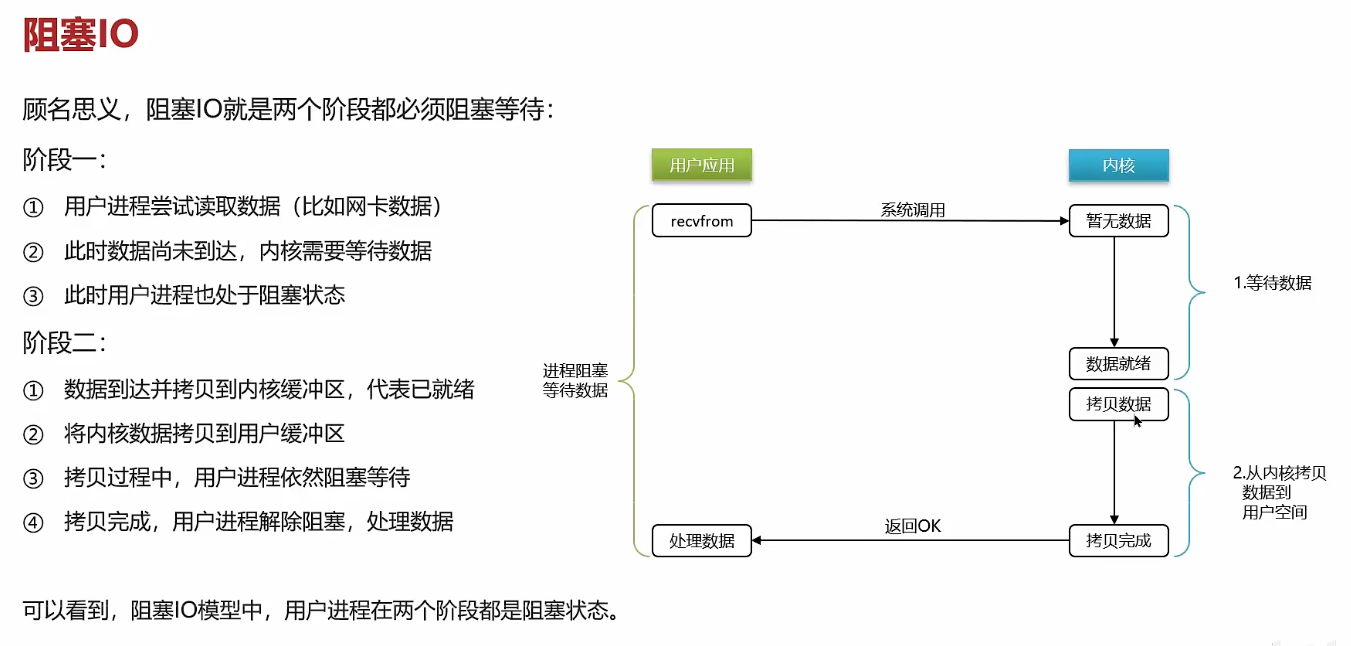
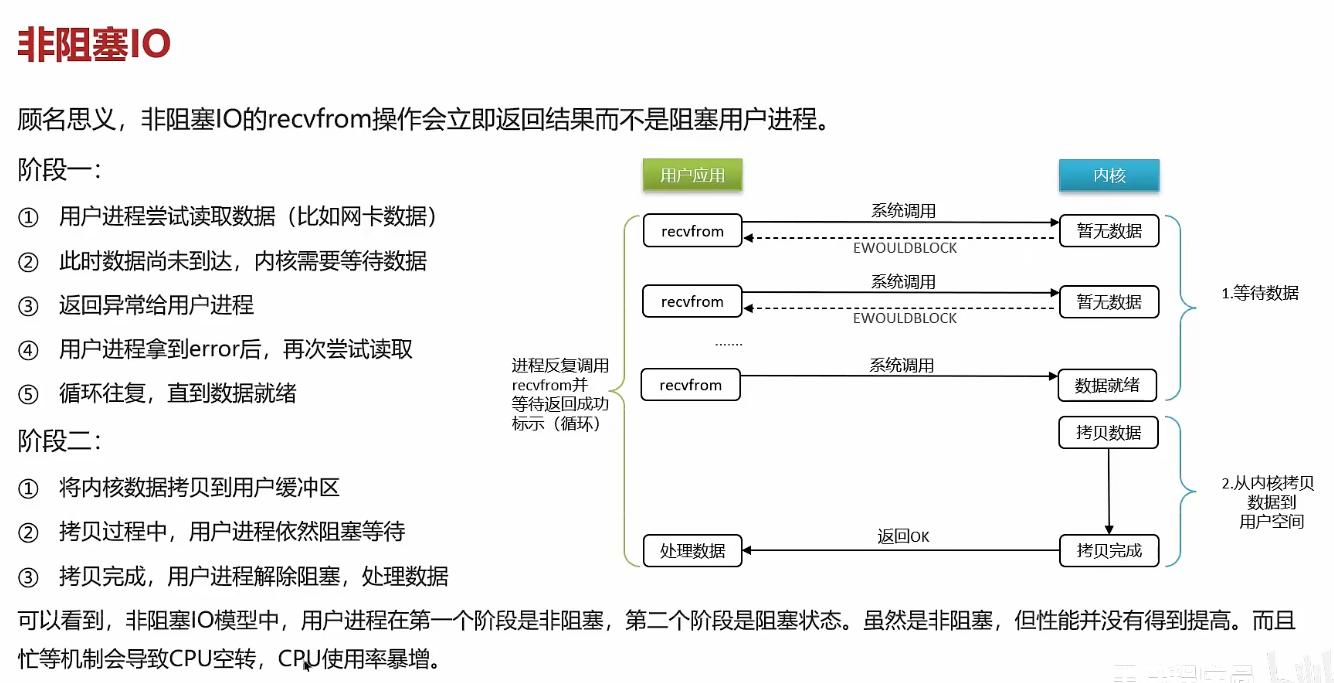
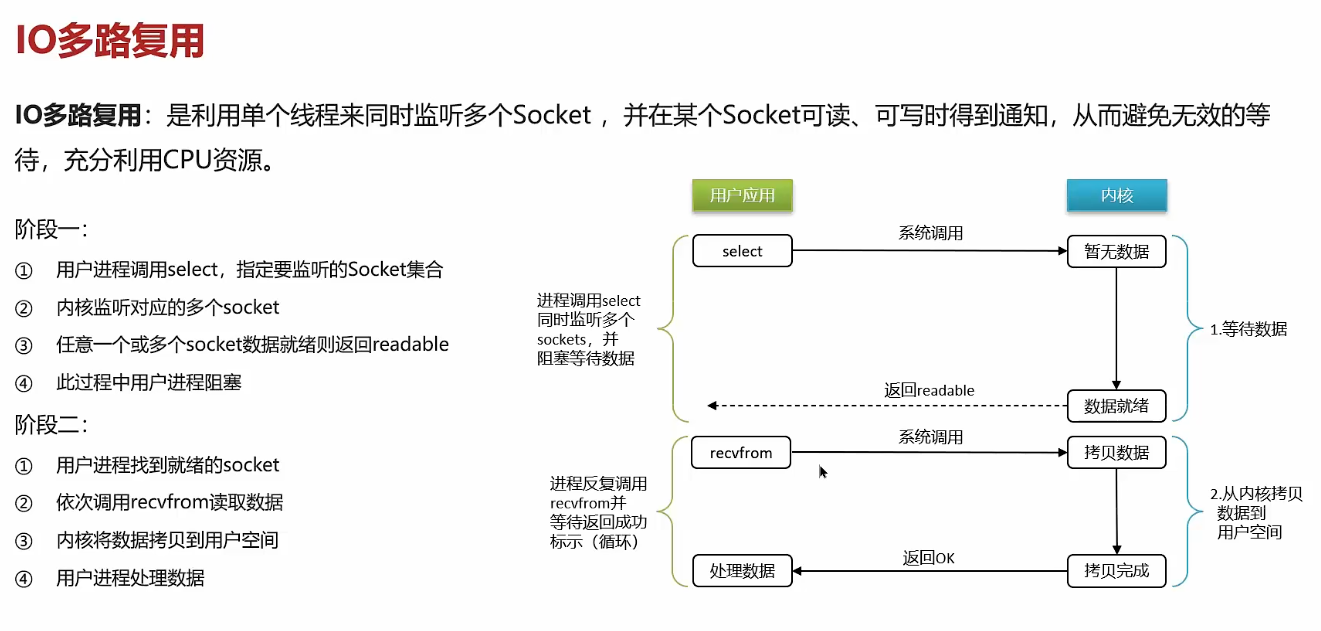
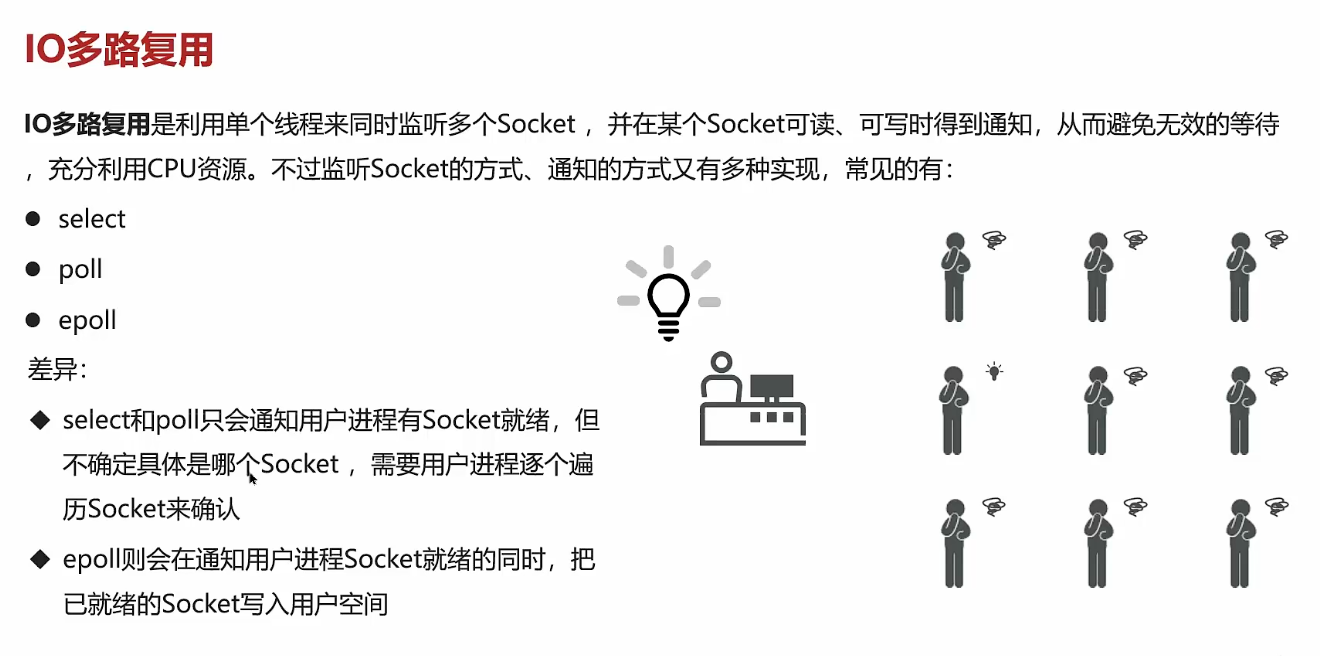
非阻塞IO:用户进程在等待数据阶段是非阻塞的,在数据拷贝阶段是阻塞的
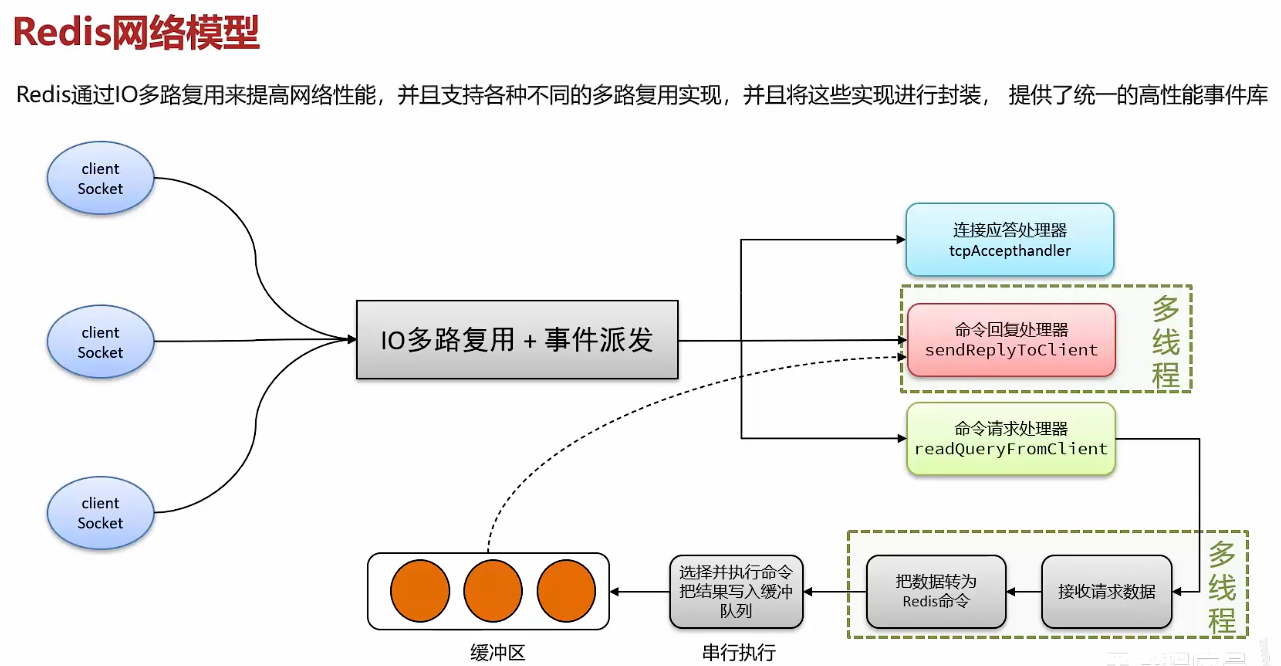
影响性能的永远是IO,比如网络相应和延迟,所以在接受请求数据、命令回复处理器两个部分开了多线程。

