小杰机器学习(eight)——tensorflow进行线性回归——算法实现、数据加载、模型定义、模型保存与加载、查看网络结构。
TensorFlow官网
https://www.tensorflow.org/guide/keras/sequential_model
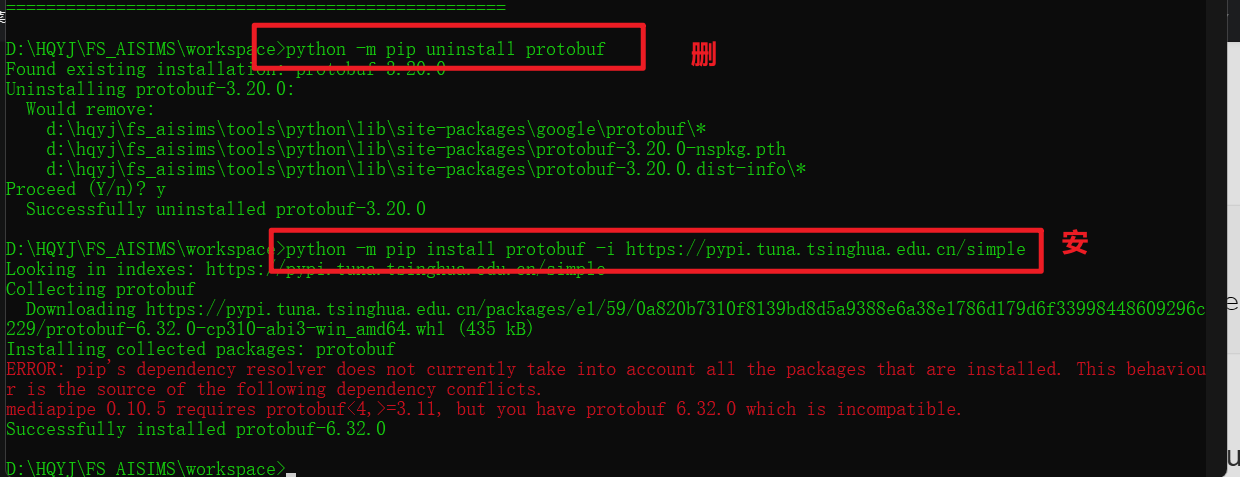
如果没有TensorFlow,可以先安装:
python -m pip install tensorflow -i https://pypi.tuna.tsinghua.edu.cn/simple/如果tf和protobuf库的版本不一致,需要手动更改protobuf的版本。
python -m pip uninstall protobufpython -m pip install protobuf -i https://pypi.tuna.tsinghua.edu.cn/simple
1. 算法实现
模拟之前Pytorch线性回归的写法,使用TensorFlow完成相同的功能。
import tensorflow as tf
import numpy as np# 1. 散点输入
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6],[0.4, 34.0], [0.8, 62.3]]
# data列表 10*2 十行两列
# 转换成numpy数组
data = np.array(data)
x_data = data[:, 0]
y_data = data[:, 1]# 转换成tf的张量
x_train = tf.constant(x_data, dtype=tf.float32)
y_train = tf.constant(y_data, dtype=tf.float32)
print(x_train)
print(y_train)# 2. 定义前向模型
# 参数是一个列表,因为可能会有多个网络,本例只有一个网络
model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=(1,))] # 第一个1输出1个,第2个1表示输入1个
)# 3. 定义损失函数和优化器
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01 # 学习率
)
# 编译模型:让模型与优化器适配
model.compile(optimizer, # 优化器loss="mean_squared_error" # MSE
)# 4. 开始迭代
epochs = 500
for n in range(1, epochs + 1):# 开始模型训练,返回值包含损失函数等数值history = model.fit(x_train,y_train,verbose=0 # 禁止训练时fit方法输出)# 5. 显示频率设置if n == 1 or n % 10 == 0:# 总的损失函数loss = history.history["loss"][0]print(f"epoch:{n},loss:{loss}")# w和bweights = model.layers[0].get_weights()# print(weights)w = weights[0][0][0]b = weights[1][0]print(f"w={w},b={b}")print("---------------")
上面的写法主要是为了更贴合之前的PyTorch的写法,实际上TensorFlow可以更简单:
import tensorflow as tf
import numpy as np# 1. 散点输入
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6],[0.4, 34.0], [0.8, 62.3]]
# data列表 10*2 十行两列
# 转换成numpy数组
data = np.array(data)
x_data = data[:, 0]
y_data = data[:, 1]# 转换成tf的张量
x_train = tf.constant(x_data, dtype=tf.float32)
y_train = tf.constant(y_data, dtype=tf.float32)
print(x_train)
print(y_train)# 2. 定义前向模型
# 参数是一个列表,因为可能会有多个网络,本例只有一个网络
model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=(1,))] # 第一个1输出1个,第2个1表示输入1个
)# 3. 定义损失函数和优化器
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01 # 学习率
)
# 编译模型:让模型与优化器适配
model.compile(optimizer, # 优化器loss="mean_squared_error" # MSE
)# 4. 开始迭代
epochs = 500
history = model.fit(x_train,y_train,epochs=epochs # 告诉fit迭代多少次,自动迭代
)# 【下面是仿Pytorch代码】
# for n in range(1, epochs + 1):
# # 开始模型训练,返回值包含损失函数等数值
# history = model.fit(
# x_train,
# y_train,
# verbose=0 # 禁止训练时fit方法输出
# )
#
# # 5. 显示频率设置
# if n == 1 or n % 10 == 0:
# # 总的损失函数
# loss = history.history["loss"][0]
# print(f"epoch:{n},loss:{loss}")
# # w和b
# weights = model.layers[0].get_weights()
# # print(weights)
# w = weights[0][0][0]
# b = weights[1][0]
# print(f"w={w},b={b}")
# print("---------------")
2. 数据集加载
import tensorflow as tf
import numpy as np# 【随机种子】
# torch.manual_seed(25)
tf.random.set_seed(25)# 1. 散点输入
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6],[0.4, 34.0], [0.8, 62.3]]
# data列表 10*2 十行两列
# 转换成numpy数组
data = np.array(data)
x_data = data[:, 0]
y_data = data[:, 1]# 转换成tf的张量
x_train = tf.constant(x_data, dtype=tf.float32)
y_train = tf.constant(y_data, dtype=tf.float32)
print(x_train)
print(y_train)# ----------------------start-------------------------# 打包x和y数据为Dataset
dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train)
)
# for item in dataset: # 十个点的xy数据
# print(item)# 打乱顺序,参数要大于等于样本数
dataset = dataset.shuffle(buffer_size=10)
# for item in dataset: # 打乱后的十个点的xy数据
# print(item)# 设置批次,一个批次5个数据
dataset = dataset.batch(5)# 预加载数据,参数可以加速,内部自动缓存
dataset = dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
for item in dataset: # 分批后的十个点的xy数据print(item)# ----------------------------end-------------------------------# 2. 定义前向模型
# 参数是一个列表,因为可能会有多个网络,本例只有一个网络
model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=(1,))] # 第一个1输出1个,第2个1表示输入1个
)# 3. 定义损失函数和优化器
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01 # 学习率
)
# 编译模型:让模型与优化器适配
model.compile(optimizer, # 优化器loss="mean_squared_error" # MSE
)# 4. 开始迭代
epochs = 500
for n in range(1, epochs + 1):# ---------------------start2------------------------total_loss = 0 # 总损失for batch_x, batch_y in dataset:# 分批次训练,返回值是一个批次的损失函数值history = model.train_on_batch(batch_x,batch_y)# print(history)# 累加损失total_loss += history# 一次训练epoch的平均损失avg_loss = total_loss / len(dataset)# 5. 显示频率设置if n == 1 or n % 10 == 0:# 总的损失函数print(f"epoch:{n},avg_loss:{avg_loss}")# w和bweights = model.layers[0].get_weights()# print(weights)w = weights[0][0][0]b = weights[1][0]print(f"w={w},b={b}")print("---------------")
3.1 方式1:在Sequential的构造函数中添加网络

3.2 方式2:调用add函数

3.3 方式3:先Input

3.4 方式4:自定义类
自定义类,可以继承 tf.keras.Model 类,与PyTorch不同的是,TensorFlow中这种方法不实用(一方面传参麻烦,另一方面模型保存不方便)
3.5 方式5:定义函数
import tensorflow as tf
import numpy as np# 【随机种子】
# torch.manual_seed(25)
tf.random.set_seed(25)# 1. 散点输入
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6],[0.4, 34.0], [0.8, 62.3]]
# data列表 10*2 十行两列
# 转换成numpy数组
data = np.array(data)
x_data = data[:, 0]
y_data = data[:, 1]# 转换成tf的张量
x_train = tf.constant(x_data, dtype=tf.float32)
y_train = tf.constant(y_data, dtype=tf.float32)
print(x_train)
print(y_train)# 打包x和y数据为Dataset
dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train)
)
# for item in dataset: # 十个点的xy数据
# print(item)# 打乱顺序,参数要大于等于样本数
dataset = dataset.shuffle(buffer_size=10)
# for item in dataset: # 打乱后的十个点的xy数据
# print(item)# 设置批次,一个批次5个数据
dataset = dataset.batch(5)# 预加载数据,参数可以加速,内部自动缓存
dataset = dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
for item in dataset: # 分批后的十个点的xy数据print(item)# --------------------start----------------------
# 2. 定义前向模型
# 参数是一个列表,因为可能会有多个网络,本例只有一个网络
def linear():# 先定义输入input = tf.keras.Input(shape=(1,), # 输入的形状dtype=tf.float32 # 类型)# 定义线性层1layer1 = tf.keras.layers.Dense(1)(input)# 定义模型并加载线性层model = tf.keras.models.Model(inputs=input, outputs=layer1)# # 定义线性层2# layer2 = tf.keras.layers.Dense(1)(layer1)# # 定义模型并加载线性层# model = tf.keras.models.Model(inputs=input, outputs=layer2)return model# 创建模型
model = linear()# --------------------end----------------------# 3. 定义损失函数和优化器
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01 # 学习率
)
# 编译模型:让模型与优化器适配
model.compile(optimizer, # 优化器loss="mean_squared_error" # MSE
)# 4. 开始迭代
epochs = 500
for n in range(1, epochs + 1):# ---------------------start2------------------------total_loss = 0 # 总损失for batch_x, batch_y in dataset:# 分批次训练,返回值是一个批次的损失函数值history = model.train_on_batch(batch_x,batch_y)# print(history)# 累加损失total_loss += history# 一次训练epoch的平均损失avg_loss = total_loss / len(dataset)# 5. 显示频率设置if n == 1 or n % 10 == 0:# 总的损失函数print(f"epoch:{n},avg_loss:{avg_loss}")# w和b# 【注意】此时layers[0]是输入层,layers[1]是输出层weights = model.layers[1].get_weights() # 在layer1中print(weights)w = weights[0][0][0]b = weights[1][0]print(f"w={w},b={b}")print("---------------")
4. 模型的保存与加载
4.1 保存
保存的格式为HDF5格式,扩展名为.h5
- 方案1:保存参数、模型结构、训练的配置等
- 方案2:只保存参数
import tensorflow as tf
import numpy as np# 1. 散点输入
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6],[0.4, 34.0], [0.8, 62.3]]
# data列表 10*2 十行两列
# 转换成numpy数组
data = np.array(data)
x_data = data[:, 0]
y_data = data[:, 1]# 转换成tf的张量
x_train = tf.constant(x_data, dtype=tf.float32)
y_train = tf.constant(y_data, dtype=tf.float32)
print(x_train)
print(y_train)# 2. 定义前向模型
# 参数是一个列表,因为可能会有多个网络,本例只有一个网络
model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=(1,))] # 第一个1输出1个,第2个1表示输入1个
)# 3. 定义损失函数和优化器
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01 # 学习率
)
# 编译模型:让模型与优化器适配
model.compile(optimizer, # 优化器loss="mean_squared_error" # MSE
)# 4. 开始迭代
epochs = 500
history = model.fit(x_train,y_train,epochs=epochs # 告诉fit迭代多少次,自动迭代
)# --------------------start------------------------
model.save('plan1_model.h5') # 方案1
model.save_weights('plan2.weights.h5') # 方案2
4.2 加载
方案1:保存时包含模型结构
与PyTorch相比,TensorFlow加载模型可以不手写类,因为模型文件里面有模型结构。
from keras import models
import numpy as np# 加载模型
loaded_model = models.load_model('plan1_model.h5')# 预测
input_data = np.array([1.5, 2.5, 3.5]) # 需要预测的数据
y_pre = loaded_model.predict(input_data) # 进行预测
print(y_pre)
方案2:如果保存时谁用方案2,没有保存模型结构只有模型参数,此时加载时是需要手写模型结构代码的。
from keras import models
import tensorflow as tf
import numpy as npdef linear():# 先定义输入input = tf.keras.Input(shape=(1,), # 输入的形状dtype=tf.float32 # 类型)# 定义线性层1layer1 = tf.keras.layers.Dense(1)(input)# 定义模型并加载线性层model = tf.keras.models.Model(inputs=input, outputs=layer1)return model# 创建模型对象
loaded_model = linear()
# 加载之前的训练参数
loaded_model.load_weights('plan2.weights.h5')# 预测
input_data = np.array([1.5, 2.5, 3.5]) # 需要预测的数据
y_pre = loaded_model.predict(input_data) # 进行预测
print(y_pre)
5. 查看网络结构
本节基于4.1的代码
import tensorflow as tf
import numpy as np# 1. 散点输入
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6],[0.4, 34.0], [0.8, 62.3]]
# data列表 10*2 十行两列
# 转换成numpy数组
data = np.array(data)
x_data = data[:, 0]
y_data = data[:, 1]# 转换成tf的张量
x_train = tf.constant(x_data, dtype=tf.float32)
y_train = tf.constant(y_data, dtype=tf.float32)
print(x_train)
print(y_train)# 2. 定义前向模型
# 参数是一个列表,因为可能会有多个网络,本例只有一个网络
model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=(1,))] # 第一个1输出1个,第2个1表示输入1个
)# 3. 定义损失函数和优化器
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01 # 学习率
)
# 编译模型:让模型与优化器适配
model.compile(optimizer, # 优化器loss="mean_squared_error" # MSE
)# 4. 开始迭代
epochs = 500
history = model.fit(x_train,y_train,epochs=epochs # 告诉fit迭代多少次,自动迭代
)
5.1 summary
import tensorflow as tf
import numpy as np# 1. 散点输入
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6],[0.4, 34.0], [0.8, 62.3]]
# data列表 10*2 十行两列
# 转换成numpy数组
data = np.array(data)
x_data = data[:, 0]
y_data = data[:, 1]# 转换成tf的张量
x_train = tf.constant(x_data, dtype=tf.float32)
y_train = tf.constant(y_data, dtype=tf.float32)
print(x_train)
print(y_train)# 2. 定义前向模型
# 参数是一个列表,因为可能会有多个网络,本例只有一个网络
model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=(1,))] # 第一个1输出1个,第2个1表示输入1个
)# 3. 定义损失函数和优化器
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01 # 学习率
)
# 编译模型:让模型与优化器适配
model.compile(optimizer, # 优化器loss="mean_squared_error" # MSE
)# 4. 开始迭代
epochs = 100
history = model.fit(x_train,y_train,epochs=epochs # 告诉fit迭代多少次,自动迭代
)# 输出网络结构
print(model.summary())

5.2 plot_model
使用前需要配置两个环境:pydot、graphviz
第一个环境:pydot
python -m pip install pydot==1.4.1 -i https://pypi.tuna.tsinghua.edu.cn/simple/
第二个环境:graphviz(复制下面的链接,粘贴浏览器地址中回车可下载)
https://lark-assets-prod-aliyun.oss-cn-hangzhou.aliyuncs.com/yuque/0/2025/zip/25766801/1750731820131-b30bd420-1263-4fa0-802e-24bd08ad3895.zip?OSSAccessKeyId=LTAI4GKnqTWmz2X8mzA1Sjbv&Expires=1756799149&Signature=9FSkY6qWMzv6bdfNELmYGQuzS6E%3D&response-content-disposition=attachment%3Bfilename*%3DUTF-8%27%27windows_10_cmake_Release_graphviz-install-10.0.1-win64.zip
解压缩之后双击安装包,安装过程注意:
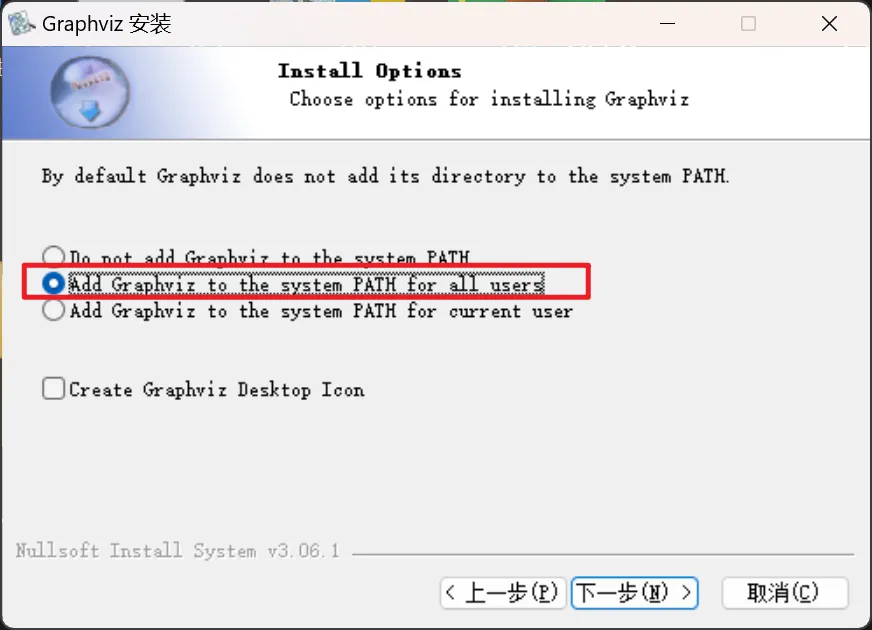
安装完成后重新启动PyCharm或Jupyter,通过下面的代码就可以保存网络结构了。
import tensorflow as tf
import numpy as np# 1. 散点输入
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6],[0.4, 34.0], [0.8, 62.3]]
# data列表 10*2 十行两列
# 转换成numpy数组
data = np.array(data)
x_data = data[:, 0]
y_data = data[:, 1]# 转换成tf的张量
x_train = tf.constant(x_data, dtype=tf.float32)
y_train = tf.constant(y_data, dtype=tf.float32)
print(x_train)
print(y_train)# 2. 定义前向模型
# 参数是一个列表,因为可能会有多个网络,本例只有一个网络
model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=(1,))] # 第一个1输出1个,第2个1表示输入1个
)# 3. 定义损失函数和优化器
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01 # 学习率
)
# 编译模型:让模型与优化器适配
model.compile(optimizer, # 优化器loss="mean_squared_error" # MSE
)# 4. 开始迭代
epochs = 100
history = model.fit(x_train,y_train,epochs=epochs # 告诉fit迭代多少次,自动迭代
)# 方案2:
tf.keras.utils.plot_model(model, # 模型对象to_file='model.png', # 保存的文件名show_shapes=True # 是否展示形状
)
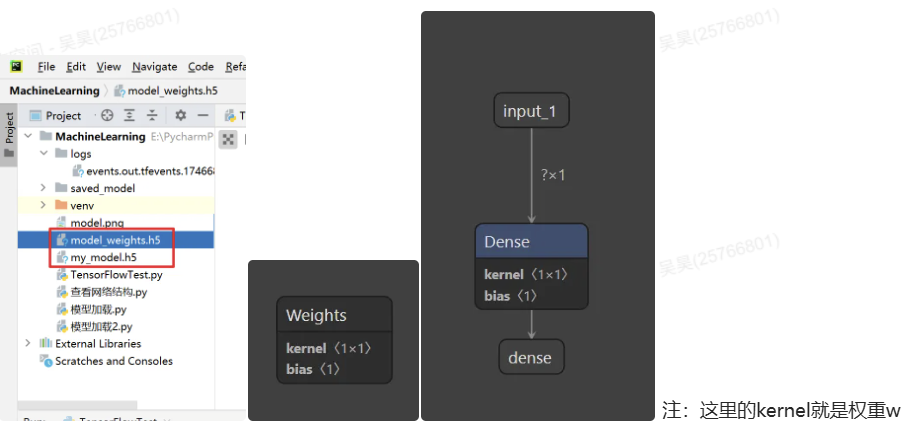
5.3 netron
支持直接打开.h5文件
5.4 Tensorboard
原本就是TensorFlow的工具,对tf的支持比Pytorch要好。
import tensorflow as tf
import numpy as np# 1. 散点输入
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6],[0.4, 34.0], [0.8, 62.3]]
# data列表 10*2 十行两列
# 转换成numpy数组
data = np.array(data)
x_data = data[:, 0]
y_data = data[:, 1]# 转换成tf的张量
x_train = tf.constant(x_data, dtype=tf.float32)
y_train = tf.constant(y_data, dtype=tf.float32)
print(x_train)
print(y_train)# 2. 定义前向模型
# 参数是一个列表,因为可能会有多个网络,本例只有一个网络
model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=(1,))] # 第一个1输出1个,第2个1表示输入1个
)# 3. 定义损失函数和优化器
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01 # 学习率
)
# 编译模型:让模型与优化器适配
model.compile(optimizer, # 优化器loss="mean_squared_error" # MSE
)# 4. 开始迭代
epochs = 500# 【方案4】保存模型
tensorboard_callbacks = tf.keras.callbacks.TensorBoard(log_dir='logs') # 参数为存储路径
model.fit(x_train,y_train,epochs=epochs, # 告诉fit迭代多少次,自动迭代callbacks=[tensorboard_callbacks] # 训练数据保存到logs中
)
运行后可以看到日志文件夹:
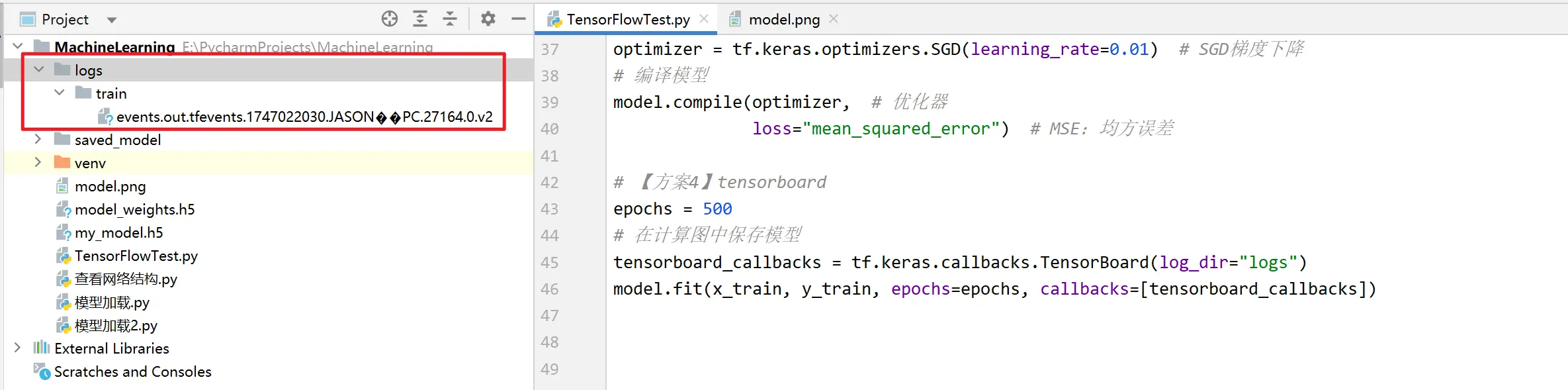
cd到工作目录(项目根目录),执行命令
"D:\HQYJ\FS_AISIMS\tools\Python\python.exe" "D:\HQYJ\FS_AISIMS\tools\Python\Scripts\tensorboard.exe" --logdir=logs

在浏览器中打开
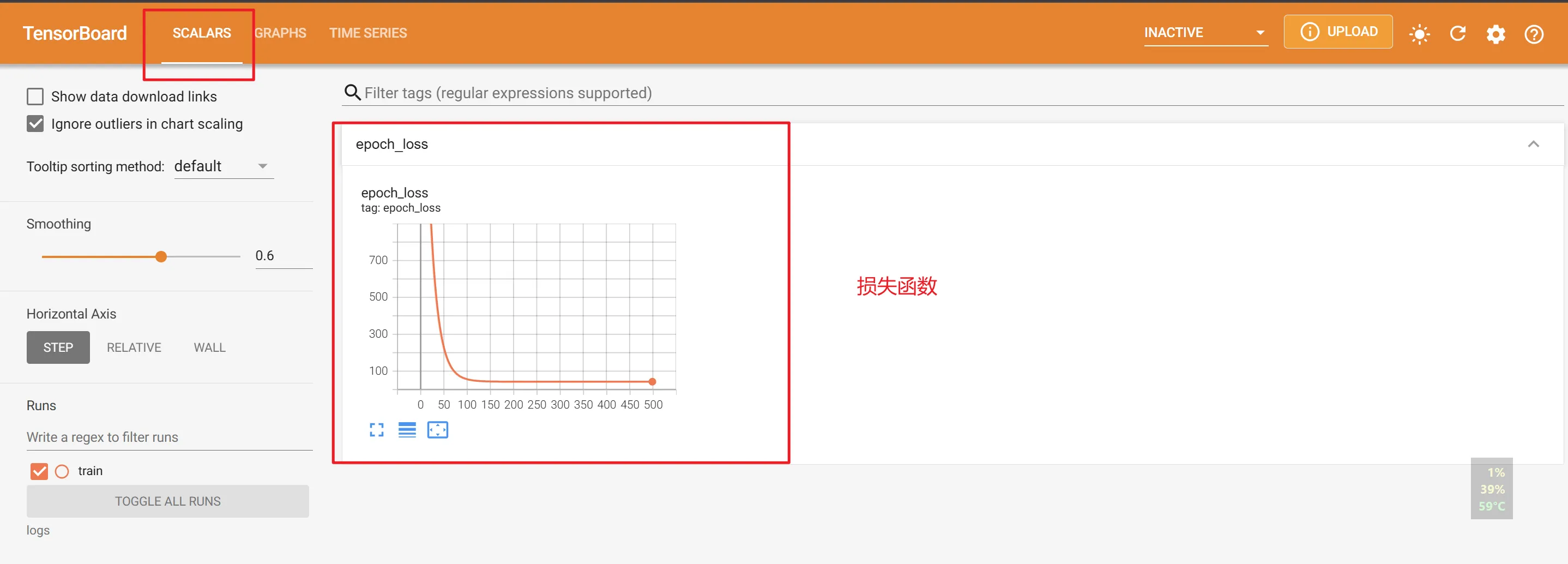
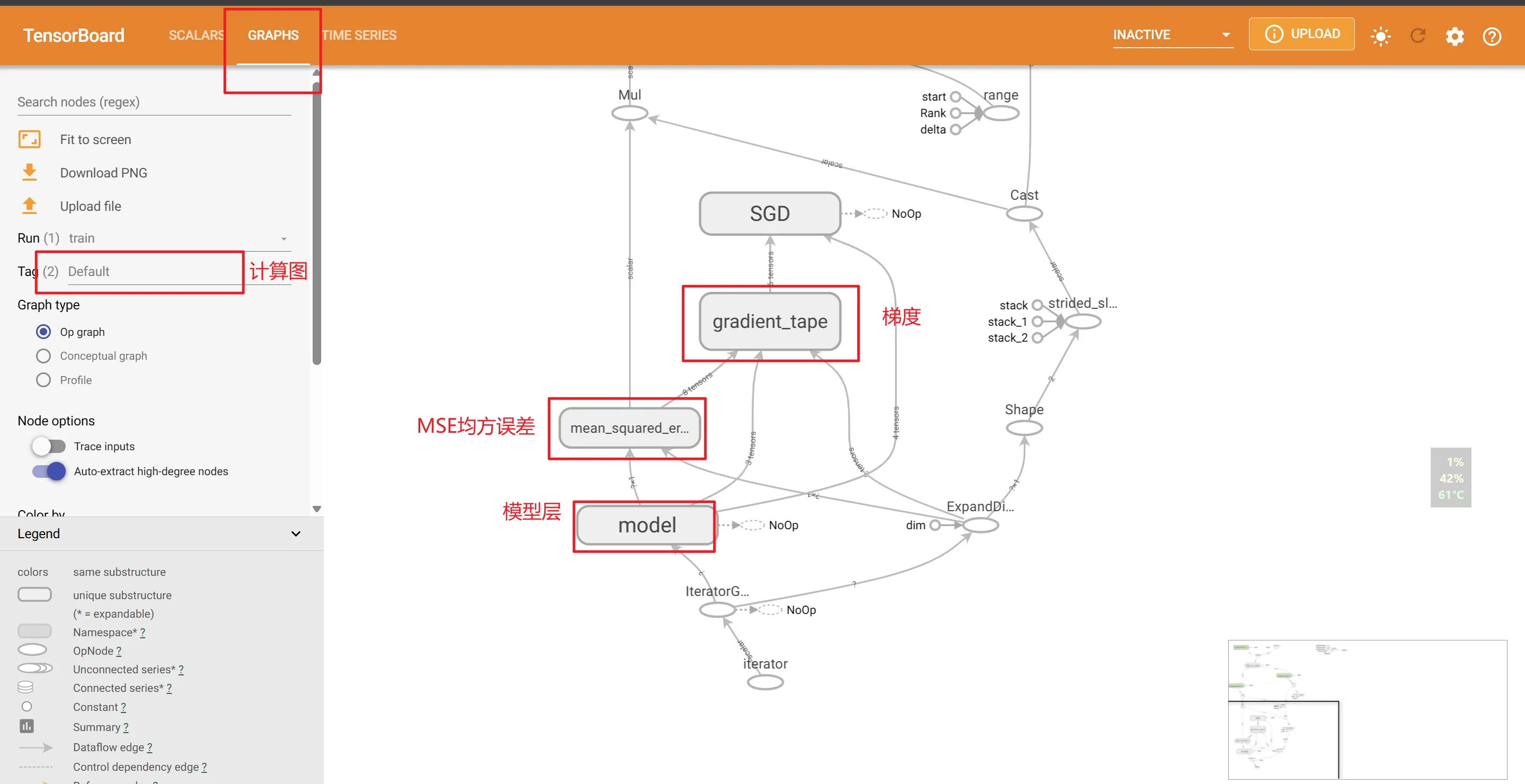
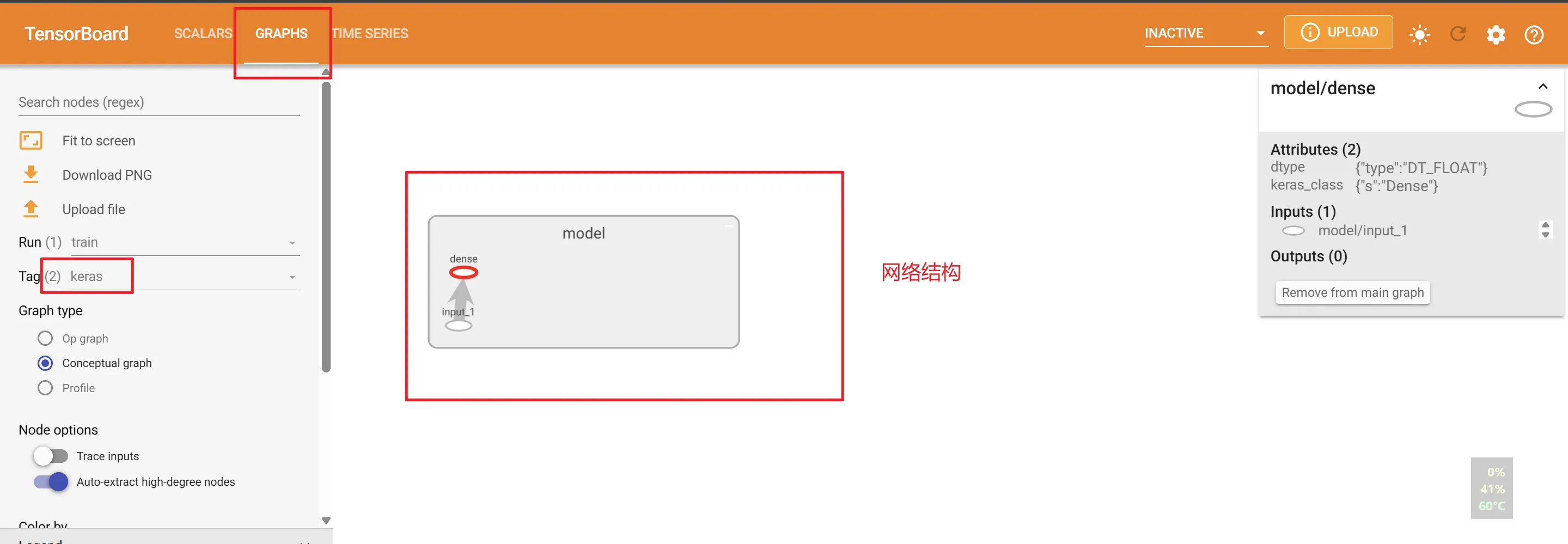
后面主要用tb观察损失函数的变化曲线,例如可以找到最合适的epochs,防止欠拟合或者过拟合的情况。