叠衣服的最优解:机器人如何用语言指令完成复杂家务
导读
语言引导的长时间操控可变形物体,尤其是衣物折叠,面临着高自由度、复杂动态和准确的视觉-语言对接等挑战。本文提出了一个统一的框架,结合了大语言模型(LLM)驱动的任务规划、视觉-语言模型(VLM)驱动的感知系统以及任务执行模块,旨在解决多步衣物折叠这一典型的可变形物体操控任务。具体来说,LLM驱动的规划器将高层语言指令分解为低层动作原语,弥合语义与执行之间的差距,增强了感知与动作的对齐及任务的泛化能力。VLM驱动的感知模块采用了SigLIP2编码器,结合新型的双向交叉注意力融合机制与基于权重分解的低秩自适应(DoRA)微调方法,实现了语言条件下的细粒度视觉对接。
实验结果表明,在仿真环境中,本文方法相较于现有基准方法取得了显著的提升,尤其在处理未见过的指令和任务时,表现出了强大的泛化能力。在实际机器人实验中,该方法能够可靠地执行多步衣物折叠任务,展示了其在实际场景中的稳健性。

图1|机器人叠T-Shirt演示

使机器人能够在物理世界中遵循自然语言指令,一直是机器人学和具身人工智能(AI)领域的长期目标。在众多需要此能力的领域中,衣物操控尤为具有挑战性。与刚性物体不同,衣物具有高自由度、自遮挡和形态变化,这使得感知和控制变得更加困难。与此同时,折叠衣物是日常生活和工业环境中常见的任务,通过语言指令实现无缝的人机交互能够大大提高操作的可用性。然而,如何将高层语言目标转化为低层操控指令,特别是在处理可变形物体时,仍然是一个尚未充分探索的问题。
近年来,随着视觉-语言基础模型(VLM)取得的成功,许多研究开始探索其在语言引导机器人操控中的应用。例如,CLIPort通过使用CLIP将语言目标映射到视觉区域,实现了开放词汇的操控。RT-2和RoboFlamingo进一步扩展了这一思路,训练了基于视觉-语言的策略,使用大规模机器人轨迹数据集。有研究者将这种范式应用于衣物操控任务,通过语言指令引导机器人动作。虽然这些模型在多种操控任务中展示了有前景的零-shot泛化能力,但它们在处理可变形材料和执行长期指令时仍然存在局限性。特别是在涉及多步骤衣物折叠指令(如“将T恤折叠成三分之一”)时,这些模型经常遇到困难。
与此同时,大语言模型(LLM)在机器人规划中的应用,如LiP-LLM,已展示了强大的能力,能够将长时间任务分解为原子动作或子目标。这些方法利用LLM的符号推理能力生成与人类意图对齐的任务计划。然而,大多数方法仅在刚性物体领域进行验证,它们在处理高视觉模糊性和物理可变形任务(如衣物折叠)时的通用性仍未得到充分探索。因此,如何有效地将LLM的推理能力与VLM的视觉对接能力结合起来,以提高衣物操控的泛化性和可解释性,仍然是一个亟待解决的挑战。
为了解决这一问题,作者提出了一个统一的框架,集成了语音驱动的任务输入、基于LLM的任务规划和基于VLM的多模态感知。具体来说,整个过程从语音命令开始,语音命令通过自动语音识别(ASR)模块转化为文本,然后通过基于LLM的规划器将其分解为可解释的子任务。例如,高层命令“将T恤的袖子折向内侧”被分解为两个精确的子任务:(1)抓住T恤的左袖并将其放置到左中部;(2)抓住T恤的右袖并将其放置到右中部。
在感知方面,作者利用预训练的大规模图像-文本对数据的SigLIP2编码器来从RGB-D观测和任务指令中提取丰富的语义特征。为了对齐这些模态,设计了一个双向交叉注意力融合模块,使得子任务指令能够集中于相关的视觉区域,同时允许视觉特征依赖于任务语义。此外,使用基于权重分解的低秩自适应(DoRA)方法对模型进行微调,专门优化针对布料任务的感知能力。通过仿真和实际环境的实验,验证了该方法的有效性。在仿真中,提出的方法超越了现有的最先进基准,能够在多任务衣物折叠基准测试中取得更好的结果。在实际UR5机器人实验中,能够生成可靠的长期任务规划,并为每个原子动作预测准确的末端执行器姿态,展示了其在不同布料配置下的稳健性。
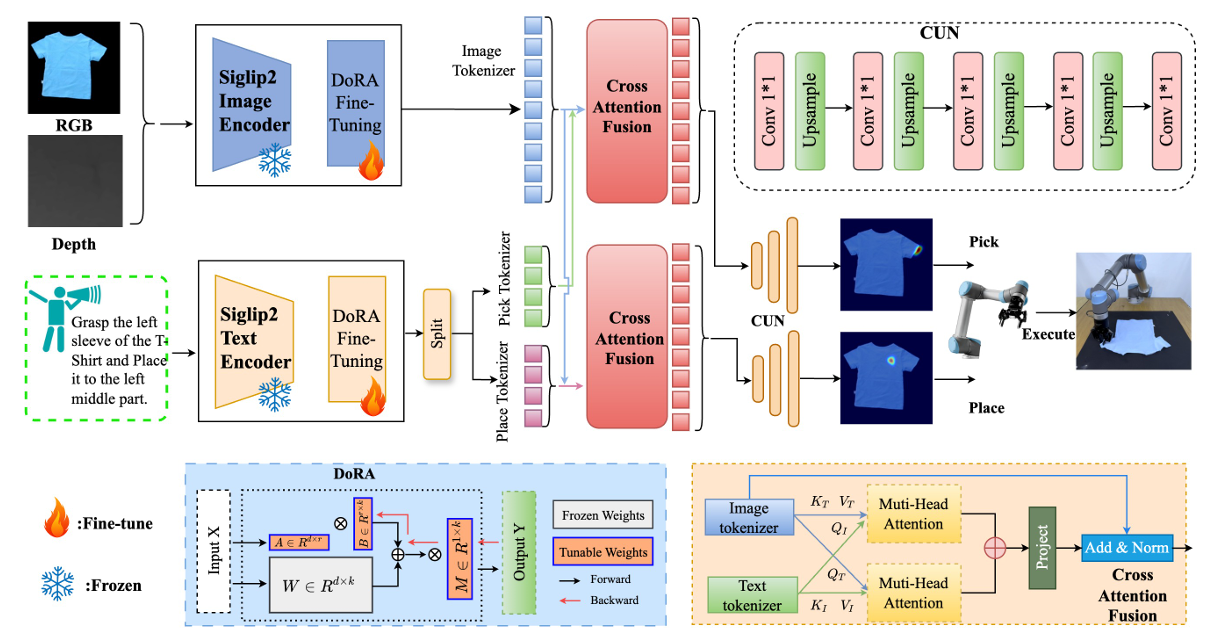
图2|方法概述:这张图展示了机器人臂具身的大语言模型系统在实际中的应用,展示了在衣物操控任务中,自动语音识别、任务规划、视觉感知和动作执行的集成工作流程

A. 问题定义
在每个时间步,给定一个高层用户指令和一个RGB-D观察数据,目标是将布料操控成指令中描述的折叠配置。整个过程包括四个主要模块:语音识别(ASR)模块、任务规划器、视觉模块和动作执行模块。首先,语音识别模块将语音输入转录为自然语言文本。接下来,任务规划器将这些文本指令解析为一系列细粒度的子任务,每个子任务描述一个具体的操作步骤。在每个步骤中,视觉模块将当前的观察和子任务指令作为输入,预测相应的低层次动作。然后,动作执行模块执行该动作,生成新的观察数据。这个感知-动作循环会持续进行,直到所有子任务完成,目标折叠配置达到。核心挑战在于将顺序的自然语言指令转化为准确、可靠的机器人动作,尽管布料本身具有很高的可变性和自由度。

图3|语言驱动的任务规划和执行算法框架
B. 任务规划模块
任务规划模块旨在解决执行长时间任务的挑战,这些任务要求对语言的上下文理解和精确的动作分解。给定语言指令和文本场景描述,使用大语言模型(LLM)将用户的指令分解为一系列子任务。该过程通过精心设计的提示,结合上下文指令学习和链式思维推理进行,确保每个子任务都能标准化并与机器人可以执行的操作对齐。任务规划器输出的子任务指令如“抓住裤子的左腰部并将其放置到右腰部”和“抓住裤子的左腿并将其放置到右腿”。这种结构化的分解策略为长时间衣物操控任务提供了解释性和可扩展的解决方案,灵感来自于以往基于LLM的规划工作。

图4|任务分解:使用基于LLM的规划器,从高层指令中进行任务分解的示例
C. 视觉感知模块
给定RGB-D场景图像和任务规划模块生成的对象特定指令,视觉模块使用图像-语言对齐模型检测与衣物相关的边界框,然后用这些边界框来启动另一种模型进行精确的图像分割。最终得到的分割掩码将衣物相关区域从原始图像中隔离出来,并在预定义的工作空间内进行裁剪。结合子任务指令,这些掩码和语言信息被送入视觉-语言编码器进行处理,从而推断出相应的操控点。该模块包含三个主要部分:多模态特征编码、跨模态融合和动作解码。
● 多模态特征编码:采用一个冻结的视觉-语言编码器,该编码器通过大量图像-文本对进行预训练,能够提取强大的视觉特征并实现精确的语言-视觉对齐。为了将其应用于衣物操控任务,同时保留预训练的知识,作者对编码器的部分权重进行微调,从而提高其在衣物操控上的适应性。
● 跨模态融合:为了融合视觉特征和语言特征,提出了双向交叉注意力机制。这一机制将视觉输入和语言输入进行联合处理,从而确保视觉信息和语言信息能够有效对接,为动作解码提供支持。
● 动作解码:设计了两个相同的解码器,一个用于“拾取”动作,另一个用于“放置”动作。每个解码器使用卷积层和上采样层进行堆叠,解码器根据融合后的特征生成空间概率图,并选择预测概率最高的像素位置作为最终动作。
D. 动作转换与执行
根据预测的拾取和放置位置,首先使用深度数据和相机内参将像素坐标投影到三维世界坐标中,然后通过外部校准将其转换为机器人基坐标系。动作执行模块随后依次执行三个原子操作:抓取(在拾取点关闭机械手以牢牢抓住目标区域)、移动到位置(在运输布料段时保持抓取稳定性)、放置(在放置点释放布料,并精准定位以达到所需配置)。
E. 实施细节
在SoftGym仿真器中,专家通过执行子指令收集了大量演示数据,共获得了15,750个演示样本(其中15,000用于训练,750用于测试)。每条轨迹数据由观察、语言指令和动作组成。训练时,使用二元交叉熵损失函数对预测的动作位置与真实数据进行对齐

仿真设置
该方法的仿真环境基于OpenAI Gym API和PyFleX绑定到NVIDIA FleX,通过SoftGym集成。该环境支持通过Python接口加载任意的布料网格,例如T恤和裤子。机器人夹爪被建模为一个自由移动的球形拾取器,在激活时会附着在最接近的布料粒子上。视觉观察通过OpenGL进行渲染,生成224×224分辨率的RGB-D图像。
任务与评估指标
为评估模型的表现,使用了以下三个评估指标:
1. 平均粒子距离(MPD):最终布料状态下的粒子与Ground Truth配置的粒子之间的平均欧几里得距离。
2. 平均交并比(MIoU):预测的布料掩码与Ground Truth掩码之间的平均交并比。
3. 成功率(SR):如果MPD小于0.0125米,则认为操作成功。
这些指标在五个布料操控任务上进行评估:双直折叠(TSF),将布料折叠成矩形;双三角折叠(DTF),将布料折叠成三角形;四角向内折叠(FCIF),将四个角折叠到中心;T恤折叠(TSF),先将袖子折叠到中心,再将底部折叠到肩部;裤子折叠(TF),将裤腿对折,再折叠一次。评估还在三个指令条件下进行:已见指令(SI)、未见指令(UI)和未见任务(UT)。
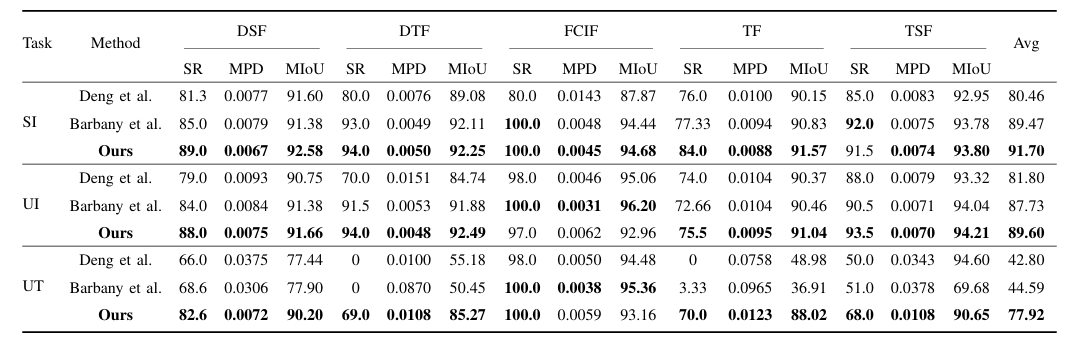
图5|仿真实验结果:在不同指令条件下,五个衣物折叠任务的表现(成功率(SR %)、平均粒子距离(MPD M)、平均交并比(MIoU %))。最佳结果用粗体表示©️【深蓝AI】编译
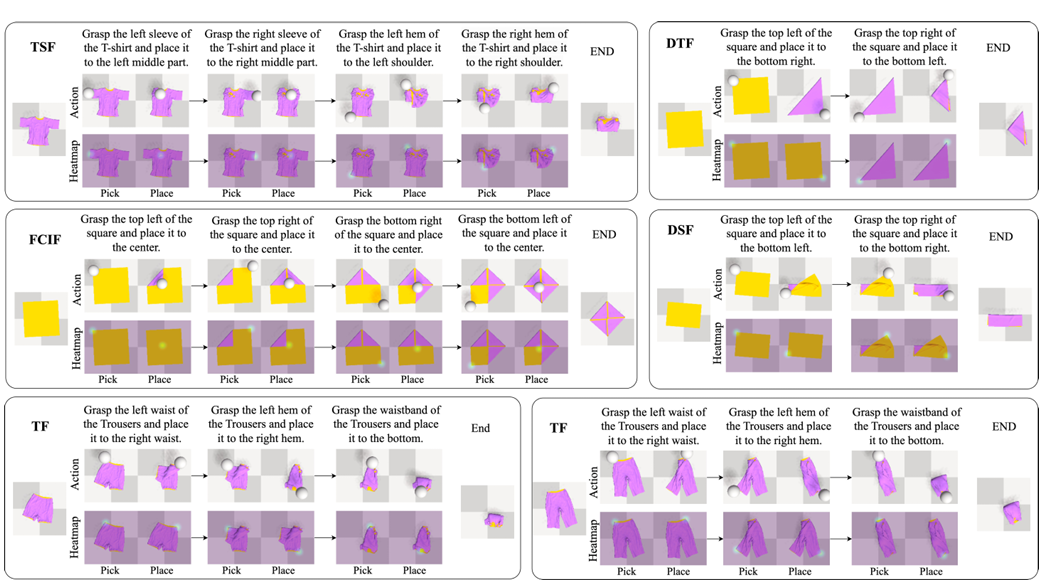
图6|基于已见指令的五个折叠任务的定性仿真结果:每个任务分为两行展示:第一行显示了通过顶部相机捕捉的俯视动作序列,第二行展示了网络预测的拾取和放置热图©️【深蓝AI】编译
结果与分析
图5展示了作者方法在五个布料操控任务中的定量结果,涵盖了三种指令条件。作者的方法在所有三项指标——MPD、MIoU和SR上均取得了最高的性能,持续超越了现有基准方法。在已见指令条件下,作者的方法达到了最高的平均成功率(91.7%),相较于对比方法提升巨大(80.46%)。在未见指令条件下,评估模型对新语言指令的泛化能力,作者的方法继续表现优秀,达到了89.6%,超过了SOTA方法(81.8%)。这证明了该方法对语言变化的鲁棒性。在未见任务条件下——这是三种条件中最具挑战性的——作者的方法达到了77.92%的成功率,远远超越了当前的SOTA方法(均值只有43%左右)。这表明作者的方法具有强大的泛化能力,特别是在像裤子折叠(TF)和T恤折叠(TSF)这样的复杂任务中,基准方法往往难以完成或完全失败。
消融研究
为了评估网络架构和参数高效微调的效果,进行了消融实验。图7展示了三种视觉-语言编码器(SigLIP2、BLIP2和CLIP)和两种融合策略:交叉注意力和基于变换器的融合。作者的方法(Talk2Fold-SigLIP2)在所有15个子任务中达到了最高的平均成功率(86.40%)。将交叉注意力模块替换为基于变换器的融合策略导致性能下降了2.01%,强调了交叉注意力在提取语言引导视觉特征方面的有效性。与CLIP和BLIP2相比,SigLIP2始终表现优异,展示了更强的泛化能力。

图7|架构模块和骨干网络的消融研究。最佳结果以粗体显示©️【深蓝AI】编译
在参数高效微调模块方面,图8展示了不同微调策略的效果:低秩自适应(LoRA)、IA3和DoRA。在这些策略中,仅使用DoRA方法达到了最高的平均成功率(86.40%),超过了LoRA(84.97%)和IA3(82.79%)。所有微调方法都显著优于没有微调的基准方法(75.38%),凸显了对语言条件模型进行微调的重要性。与其他方法相比,DoRA提供了更好的性能,是在作者设置中最合适的选择。

图8|参数高效微调模块的消融研究。最佳结果以粗体显示©️【深蓝AI】编译
高层任务规划
高层任务规划在作者的衣物操控框架中扮演着至关重要的角色。为了评估不同大语言模型(LLM)在该组件中的有效性,作者对四种最近的模型进行了基准测试:Doubao-1.5、Grok-3、DeepSeek-V3和GPT-4o。对于每个模型,作者进行5次任务试验,并收集专家注释以确定任务规划的成功率。根据下图的结果,GPT-4o达到了最高的平均成功率,表明其在推理和指令跟随方面在此领域的优势。基于这些结果,作者选择GPT-4o作为后续实验中的任务规划器。
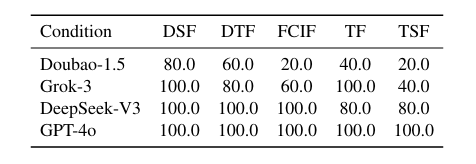
图9|大语言模型(LLMs)消融研究结果©️【深蓝AI】编译

本文提出了一种创新的框架,旨在通过语言引导的方式实现对布料的精确操控,特别是在衣物折叠任务中展现出强大的能力。该方法集成了语音驱动的任务输入、基于大语言模型(LLM)的任务规划和基于视觉-语言模型(VLM)的多模态感知系统,从而能够从高层次的语言指令到具体的动作执行进行高效转换。
实验结果表明,提出的方法在多个折叠任务中超越了现有的基准模型,展示了优秀的泛化能力和鲁棒性,特别是在未见指令和未见任务的条件下,能够保持较高的成功率。在仿真环境中,模型在指令的多样性和任务的复杂性面前仍然表现出色,显著提升了折叠任务的准确性和效率。通过消融研究,模型的各个组成部分——包括任务规划、视觉感知和动作解码——得到了充分验证,证明了模型架构的有效性,尤其是在参数高效微调和大语言模型的应用上。
在实际应用方面,本文框架的优越性得到了实物机器人实验的进一步验证,特别是在不同布料和配置下的稳定性和精确度。通过结合先进的视觉-语言理解和任务推理技术,本文展示了一个高效、通用且可扩展的语言引导机器人操控框架,为具身智能和物理交互的未来发展奠定了坚实基础。