O3.6opencv风格迁移和人脸识别
一·风格迁移
图片风格迁移
逻辑
- 图像读取与显示
python
image = cv2.imread('car.png')
cv2.imshow('yuan tu', image)
cv2.waitKey(0)
使用cv2.imread函数读取名为car.png的图像,并通过cv2.imshow函数在名为yuan tu的窗口中显示该图像。cv2.waitKey(0)等待用户按下任意键,以便用户观察原始图像。
- 图像预处理
python
(h, w) = image.shape[:2]
blob = cv2.dnn.blobFromImage(image, 1, (w, h), (0, 0, 0), swapRB=False, crop=False)
- 获取图像的高度
h和宽度w。 - 使用
cv2.dnn.blobFromImage函数对图像进行预处理,以构建一个符合神经网络输入格式的四维块(blob)。image为输入的原始图像。scalefactor = 1表示对图像像素值不进行缩放。size = (w, h)表示输出 blob 的宽度和高度与原始图像相同。mean = (0, 0, 0)表示不对图像的 B、G、R 通道减去均值。swapRB = False表示不交换通道顺序,因为原始图像在 OpenCV 中通常是 BGR 格式,这里保持不变。crop = False表示在调整大小后不进行居中裁剪。
- 加载模型
python
net = cv2.dnn.readNetFromTorch(r'.\model\candy.t7')
使用cv2.dnn.readNetFromTorch函数加载一个基于 PyTorch 训练的模型,这里加载的是名为candy.t7的模型,该模型用于将输入图像转换为类似糖果风格的图像。代码中还注释了其他可能的模型路径,可通过切换加载不同风格的模型。
- 设置输入与前向传播
python
net.setInput(blob)
out = net.forward()
- 使用
net.setInput(blob)将预处理后的图像 blob 设置为神经网络的输入。 - 调用
net.forward()对输入图像进行前向传播,得到模型的输出结果out。
- 输出处理与显示
python
out_new = out.reshape(out.shape[1], out.shape[2], out.shape[3])
cv2.normalize(out_new, out_new, norm_type=cv2.NORM_MINMAX)
result = out_new.transpose(1, 2, 0)
cv2.imshow('Stylized Image', result)
cv2.waitKey(0)
cv2.destroyAllWindows()
out_new = out.reshape(out.shape[1], out.shape[2], out.shape[3])将输出结果out从四维(B * C * H * W)重塑为三维(C * H * W),忽略第一维(通常为 batch 大小,这里设为 1)。cv2.normalize(out_new, out_new, norm_type=cv2.NORM_MINMAX)对输出进行归一化处理,将其数值范围映射到 0 到 1 之间,以增强图像显示效果。result = out_new.transpose(1, 2, 0)转置输出结果的维度,将通道维度放到最后,使其符合 OpenCV 图像显示的格式(H * W * C)。- 使用
cv2.imshow('Stylized Image', result)在名为Stylized Image的窗口中显示风格化后的图像。 cv2.waitKey(0)等待用户按键,之后通过cv2.destroyAllWindows()关闭所有 OpenCV 窗口。
import cv2
# 读取输入图像
image = cv2.imread('car.png')
# 显示输入图像
cv2.imshow('yuan tu', image)
cv2.waitKey(0)
'''----------图片预处理-------------------'''
(h, w) = image.shape[:2] # 获取图像尺寸
# 函数cv2.dnn.blobFromImage:实现图像预处理,从原始图像构建一个符合人工神经网络输入格式的四维块。
# blob = cv2.dnn.blobFromImage(image, scalefactor=None, size=None, mean=None, swapRB=None, crop=None)
# 参数:
# image:表示输入图像。
# scalefactor:表示对图像内的数据进行缩放的比例因子。具体运算是每个像素值*scalefactor,该值默认为 1。
# size:用于控制blob的宽度、高度。
# mean:表示从每个通道减去的均值。 (0, 0, 0):表示不进行均值减法。即,不对图像的B、G、R通道进行任何减法操作。
# 若输入图像本身是B、G、R通道顺序的,并且下一个参数swapRB值为True,
# 则mean值对应的通道顺序为R、G、B。· opencv BGR RGB
# swapRB:表示在必要时交换通道的R通道和B通道。一般情况下使用的是RGB通道。而OpenCV通常采用的是BGR通道。
# 因此可以根据需要交换第1个和第3个通道。该值默认为 False。
# crop:布尔值,如果为 True,则在调整大小后进行居中裁剪。
# 返回值:blob: 表示在经过缩放、裁剪、减均值后得到的符合人工神经网络输入的数据。该数据是一个四维数据,
# 布局通常使用N(表示batch size)、C(图像通道数,如RGB图像具有三个通道)、H(图像高度)、W(图像宽度)表示
blob = cv2.dnn.blobFromImage(image, 1, (w, h), (0, 0, 0), swapRB=False, crop=False)
"""----------加载模型------------------------"""
# 加载模型net=cv2.dnn.readNet( model[, config[, framework]] )
# 各参数的含义如下:
# model:神经网络的实际结构和功能,它定义了数据如何通过网络流动,如何进行训练,如何进行推理。
# config:一组超参数和设置,帮助控制模型的行为,包括网络架构、训练过程、优化器等内容。
# framework:DNN框架,可省略,DNN模块会自动推断框架种类。
# net:返回值,返回网络模型对象。
# 支持的模型格式有Torch,TensorFlow,Caffe,DartNet,ONNX和Intel OpenVINO
# model参数 | config参数 | framework参数 | 函数名称
# *.caffemodel | *.prototxt | caffe | readNetFremoCaffe
# *.pd | *.pbtxt | tensorflow | readNetFromTensorFlow
# *.t7 | *.net | torch | readNetFromTorch
# *.weight | *.cfg | darknet | readNetFromDarknet
# *.bin | *.xml | dldt | readNetFromModelOptimizer
# *.onnx | | onnx | readNetFromONNX# net = cv2.dnn.readNet(r'model\starry_night.t7') #得到一个pytorch训练之后的星空模型
# net=cv2.dnn.readNetFromTorch(r'.\model\la_muse.t7')
net=cv2.dnn.readNetFromTorch(r'.\model\candy.t7')
# net=cv2.dnn.readNetFromTorch(r'.\model\composition_vii.t7')
# net=cv2.dnn.readNetFromTorch(r'.\model\feathers.t7')
# net=cv2.dnn.readNetFromTorch(r'.\model\udnie.t7')
# net=cv2.dnn.readNetFromTorch(r'.\model\the_scream.t7')# 设置神经网络的输入
net.setInput(blob)
# 对输入图像进行前向传播,得到输出结果
out = net.forward()
# 将输出结果转换为合适的格式
# out是四维的:B*C*H*W
# B:batch图像数量(通常为1),C:channels通道数,H:height高度、W:width宽度
# ======输出处理=========
# 重塑形状(忽略第1维),4维变3维
# 调整输出out的形状,模型推理输出out是四维BCHW形式的,调整为三维CHW形式
out_new = out.reshape(out.shape[1], out.shape[2], out.shape[3])
#对输入的数组(或图像)进行归一化处理,使其数值范围在指定的范围内
cv2.normalize(out_new, out_new, norm_type=cv2.NORM_MINMAX)
# 转置输出结果的维度
result = out_new.transpose(1, 2, 0)
# 显示转换后的图像
cv2.imshow('Stylized Image', result)
cv2.waitKey(0)
cv2.destroyAllWindows()效果展示

视频风格迁移
逻辑
- 初始化部分
- 打开摄像头:
python
cap = cv2.VideoCapture(0)
使用cv2.VideoCapture(0)打开默认摄像头,若要读取视频文件,可将参数替换为视频文件路径(如'cxk.mp4')。
- 加载模型:
python
net = cv2.dnn.readNetFromTorch(r'.\model\starry_night.t7')
利用cv2.dnn.readNetFromTorch函数加载基于 PyTorch 训练的starry_night.t7模型,该模型用于将输入图像转换为星空风格。
- 检查摄像头是否成功打开:
python
if not cap.isOpened():print("摄像头启动失败")exit()
检查摄像头是否成功打开,如果未成功打开,打印提示信息并退出程序。
- 主循环部分
- 读取视频帧:
python
ret, frame = cap.read()
if not ret:print("不能读取摄像头")break
在循环中不断从摄像头读取视频帧,ret表示是否成功读取,frame为读取到的当前帧图像。如果读取失败,打印提示信息并退出循环。
- 图像预处理:
python
(h, w) = frame.shape[:2]
blob = cv2.dnn.blobFromImage(frame, 1, (w, h), (0, 0, 0), swapRB=True, crop=False)
获取当前帧图像的高度h和宽度w。然后使用cv2.dnn.blobFromImage对当前帧图像进行预处理,生成符合神经网络输入格式的四维 blob 数据。
frame为输入的当前帧图像。scalefactor = 1表示对图像像素值不进行缩放。size = (w, h)表示输出 blob 的宽度和高度与原始图像相同。mean = (0, 0, 0)表示不对图像的 B、G、R 通道减去均值。swapRB = True表示交换通道顺序,因为 OpenCV 默认图像是 BGR 格式,而这里模型可能期望 RGB 格式,所以交换通道。crop = False表示在调整大小后不进行居中裁剪。模型推理:
python
net.setInput(blob)
out = net.forward()
将预处理后的 blob 数据设置为神经网络的输入,然后通过net.forward()进行前向传播,得到模型的输出结果out。
- 输出处理:
python
out_new = out.reshape(out.shape[1], out.shape[2], out.shape[3])
cv2.normalize(out_new, out_new, norm_type=cv2.NORM_MINMAX)
result = out_new.transpose(1, 2, 0)
out_new = out.reshape(out.shape[1], out.shape[2], out.shape[3])将输出结果out从四维(B * C * H * W)重塑为三维(C * H * W),忽略第一维(通常为 batch 大小,这里设为 1)。cv2.normalize(out_new, out_new, norm_type=cv2.NORM_MINMAX)对输出进行归一化处理,将其数值范围映射到 0 到 1 之间,以增强图像显示效果。result = out_new.transpose(1, 2, 0)转置输出结果的维度,将通道维度放到最后,使其符合 OpenCV 图像显示的格式(H * W * C)。显示结果:
python
cv2.imshow('result', result)
在名为result的窗口中显示风格转换后的图像。
- 按键检测:
python
key_pressed = cv2.waitKey(10)
if key_pressed == 27:break
使用cv2.waitKey(10)等待 10 毫秒,检查是否有按键按下。如果按下的是esc键(ASCII 码为 27),则退出循环。
- 资源释放部分
python
cap.release()
cv2.destroyAllWindows()
循环结束后,释放摄像头资源,并关闭所有 OpenCV 窗口。
import cv2cap = cv2.VideoCapture(0) # 0 #'cxk.mp4'
net=cv2.dnn.readNetFromTorch(r'.\model\starry_night.t7')
if not cap.isOpened(): # 打开失败print("摄像头启动失败")exit()
while True:ret, frame = cap.read() # 如果正确读取帧,ret为Trueif not ret: # 读取失败,则退出循环print("不能读取摄像头")break# gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 图像处理-转换为灰度图(h, w) = frame.shape[:2]blob = cv2.dnn.blobFromImage(frame, 1, (w, h), (0, 0, 0), swapRB=True, crop=False)net.setInput(blob)out = net.forward()out_new = out.reshape(out.shape[1], out.shape[2], out.shape[3])cv2.normalize(out_new, out_new, norm_type=cv2.NORM_MINMAX)result = out_new.transpose(1, 2, 0)cv2.imshow('result', result)key_pressed = cv2.waitKey(10) #60if key_pressed == 27: # 如果按下esc键,就退出循环break
cap.release() # 释放捕获器
cv2.destroyAllWindows() # 关闭图像窗口效果展示

这个是动的,想象一下
二·人脸识别
人脸检测
逻辑
静态图片人脸检测部分
python
# import cv2
# image = cv2.imread('people.png')
# gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# faceCascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
# faces = faceCascade.detectMultiScale(gray, scaleFactor=1.05, minNeighbors=9, minSize=(8, 8))
# print("发现{0}张人脸!".format(len(faces)))
# print("其位置分别是:", faces)
# for (x, y, w, h) in faces:
# cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)
# cv2.imshow("result", image)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
- 图像读取与灰度转换:
image = cv2.imread('people.png'):读取名为people.png的图像。gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY):将彩色图像转换为灰度图像,因为 Haar 级联分类器通常在灰度图像上工作。
- 加载分类器:
faceCascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml'):加载预训练的 Haar 级联分类器模型,该模型用于检测正面人脸。
- 人脸检测:
faces = faceCascade.detectMultiScale(gray, scaleFactor=1.05, minNeighbors=9, minSize=(8, 8)):使用加载的分类器在灰度图像上进行人脸检测。scaleFactor = 1.05:表示在前后两次相继扫描中搜索窗口的缩放比例,即每次搜索窗口的大小增加 5%。minNeighbors = 9:表示构成检测目标的相邻矩形的最小个数,这里设置为 9,意味着有 9 个以上的检测标记存在时才认为存在人脸,此设置可提高检测准确率,但可能会遗漏一些人脸。minSize = (8, 8):目标的最小尺寸,小于这个尺寸的目标将被忽略。
faces是一个包含检测到的人脸矩形框信息的列表,每个矩形框信息为(x, y, w, h),分别表示人脸矩形框的左上角 x 坐标、y 坐标,以及矩形框的宽度w和高度h。
- 结果输出与标注:
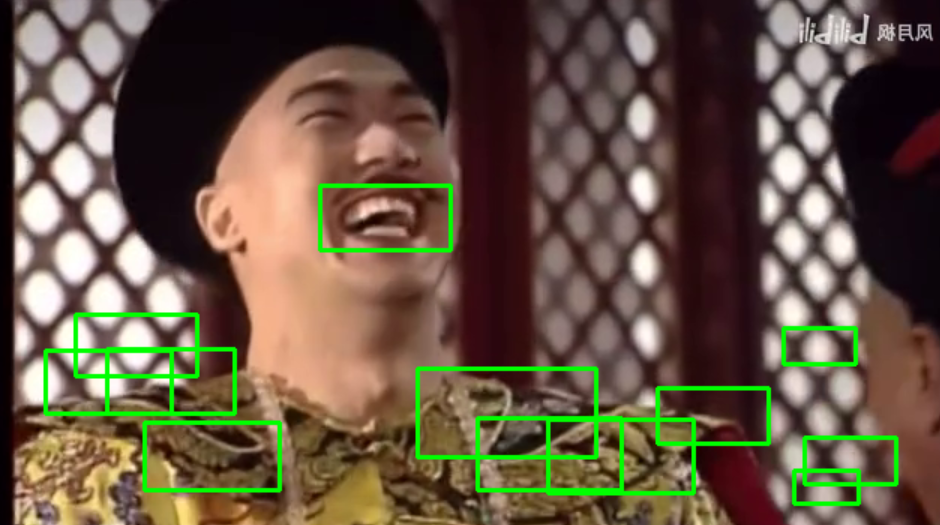
print("发现{0}张人脸!".format(len(faces)))和print("其位置分别是:", faces):打印检测到的人脸数量和人脸矩形框的位置信息。for (x, y, w, h) in faces:循环遍历检测到的每个人脸矩形框。cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2):在原始彩色图像上绘制绿色((0, 255, 0))矩形框标注出人脸位置,线宽为 2。
- 图像显示与资源释放:
cv2.imshow("result", image):显示标注了人脸的图像。cv2.waitKey(0):等待用户按下任意键。cv2.destroyAllWindows():关闭所有 OpenCV 窗口。
摄像头实时检测部分
python
import cv2faceCascade = cv2.CascadeClassifier('haarcascade_smile.xml')
cap = cv2.VideoCapture(0)
while True:ret, image = cap.read()image = cv2.flip(image, 1)if ret is None:breakgray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)faces = faceCascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=16, minSize=(5, 5))for (x, y, w, h) in faces:cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)cv2.imshow('cv_xml', image)key = cv2.waitKey(10)if key == 27:break
cap.release()
cv2.destroyAllWindows()
- 初始化部分:
faceCascade = cv2.CascadeClassifier('haarcascade_smile.xml'):加载用于检测微笑的 Haar 级联分类器模型。cap = cv2.VideoCapture(0):打开默认摄像头,若要读取视频文件,可将参数替换为视频文件路径(如'xiao.mp4')。
- 主循环部分:
- 读取帧并处理:
ret, image = cap.read():从摄像头读取一帧图像,ret表示是否成功读取,image为读取到的当前帧图像。image = cv2.flip(image, 1):对读取的图像进行水平翻转,这里设置参数 1 表示水平翻转,这一步可以使显示的画面与实际情况更符合用户习惯(类似镜子效果)。if ret is None::检查是否成功读取帧,如果未成功读取则退出循环。gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY):将彩色图像转换为灰度图像。
- 微笑检测:
faces = faceCascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=16, minSize=(5, 5)):使用微笑检测分类器在灰度图像上检测微笑。scaleFactor = 1.1:每次搜索窗口的大小增加 10%。minNeighbors = 16:设置较高的相邻矩形最小个数,以提高微笑检测的准确性。minSize = (5, 5):忽略小于此尺寸的目标。
- 结果标注与显示:
for (x, y, w, h) in faces:循环遍历检测到的每个微笑矩形框。cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2):在原始彩色图像上绘制绿色矩形框标注出微笑位置。cv2.imshow('cv_xml', image):在名为cv_xml的窗口中显示标注后的图像。
- 按键检测:
key = cv2.waitKey(10):等待 10 毫秒,检查是否有按键按下。if key == 27::如果按下esc键(ASCII 码为 27),则退出循环。
- 读取帧并处理:
- 资源释放部分:
cap.release():释放摄像头资源。cv2.destroyAllWindows():关闭所有 OpenCV 窗口。
代码
# import cv2
# image = cv2.imread('people.png')
# gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# # '''-------------------加载分类器------------------------'''
# faceCascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
# # """------------------- 分类器检测实现人脸识别 ------------------------"""
# # # objects = cv2.CascadeClassifier.detectMultiScale( image[,scaleFactor
# # # [,minNeighbors[, flags[, minSize[,maxSize]]]]] )
# # # 其中,各个参数及返回值的含义如下。
# # # ·image:待检测图像,通常为灰度图像。
# # # ·scaleFactor:表示在前后两次相继扫描中搜索窗口的缩放比例。识别,扫描,按照不同比例来进行扫描
# # # ·minNeighbors:表示构成检测目标的相邻矩形的最小个数。在默认情况下,该参数的值为 3,
# # # 表示有 3 个以上的检测标记存在时才认为存在人脸。如果希望提高检测的准确率可以将该参数的值设置得更大,
# # # 但这样做可能会让一些人脸无法被检测到。
# # # flags: 该参数通常被省略。在使用低版本 OpenCV (OpenCV 1.X 版本)时,该参数可能会被设置为
# # # CV_HAAR_DO_CANNY_PRUNING,表示使用 Canny 边缘检测器拒绝一些区域。
# # # ·minSize: 目标的最小尺寸,小于这个尺寸的目标将被忽略。
# # # ·maxSize: 目标的最大尺寸,大于这个尺寸的目标将被忽略。通常情况下,将该可选参数省略即可。
# # # 若 maxSize 和 minSize 大小一致,则表示仅在一个尺度上查找目标。
# # # ·objects: 返回值,目标对象的矩形框向量组。该值是一组矩形信息,
# # # 包含每个检测到的人脸对应的矩形框的信息 (x轴方向位置、y轴方向位置、宽度、高度)。
# faces = faceCascade.detectMultiScale(gray, scaleFactor=1.05,minNeighbors=9, minSize=(8, 8))
# print("发现{0}张人脸!".format(len(faces)))
# print("其位置分别是:", faces)
# """-------------- 标注人脸及显示 -------------------"""
# for (x, y, w, h) in faces:
# cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)
# cv2.imshow("result", image)
# cv2.waitKey(0)
# cv2.destroyAllWindows()# 人脸检测 摄像头
import cv2faceCascade=cv2.CascadeClassifier('haarcascade_smile.xml')
cap=cv2.VideoCapture(0) #'xiao.mp4' # 0
while True:ret,image=cap.read()image=cv2.flip(image,1)if ret is None:breakgray=cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)faces=faceCascade.detectMultiScale(gray,scaleFactor=1.1,minNeighbors=16,minSize=(5,5))for (x,y,w,h) in faces:cv2.rectangle(image,(x,y),(x+w,y+h),(0,255,0),2)cv2.imshow('cv_xml',image)key=cv2.waitKey(10)if key==27:break
cap.release()
cv2.destroyAllWindows()
#
#
#
#
#
#
#
#
#
#
#
haarcascade_eye.xml:用于检测人眼。haarcascade_frontalcatface.xml:用于检测正面的猫脸。haarcascade_frontalface_alt.xml、haarcascade_frontalface_alt2.xml等:用于检测正面的人脸,不同后缀的文件是针对人脸检测的不同优化版本(比如对不同角度、遮挡等情况的适应性不同)。haarcascade_fullbody.xml:用于检测人体全身。haarcascade_lowerbody.xml:用于检测人体下半身。haarcascade_upperbody.xml:用于检测人体上半身。haarcascade_smile.xml:用于检测微笑的表情。haarcascade_license_plate_rus_16s.xml、haarcascade_russian_plate_number.xml:用于检测俄罗斯车牌。
效果
微笑检测
- 初始化部分:
- 加载分类器:
python
faceCascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
smile = cv2.CascadeClassifier("haarcascade_smile.xml")
加载两个 Haar 级联分类器,haarcascade_frontalface_default.xml用于检测人脸,haarcascade_smile.xml用于检测微笑。
- 初始化摄像头或打开视频文件:
python
cap = cv2.VideoCapture('xiao.mp4')
使用cv2.VideoCapture初始化摄像头,如果传入的参数是视频文件路径(这里是'xiao.mp4'),则打开该视频文件用于后续处理。
- 主循环部分:
- 读取帧并处理:
python
while True:ret, image = cap.read()image = cv2.flip(image, 1)if ret is None:breakgray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
在循环中不断读取视频的每一帧。ret表示是否成功读取帧,image为读取到的当前帧图像。如果读取失败(ret为None),则退出循环。
cv2.flip(image, 1)对读取的图像进行水平翻转,使显示的画面更符合用户习惯(类似镜子效果)。然后将彩色图像image转换为灰度图像gray,因为 Haar 级联分类器通常在灰度图像上工作。
- 人脸检测:
python
faces = faceCascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=10, minSize=(5, 5))
使用人脸检测分类器faceCascade在灰度图像gray上进行人脸检测。
scaleFactor = 1.1:表示每次搜索窗口的大小增加 10%,用于多尺度检测不同大小的人脸。minNeighbors = 10:设置构成检测目标的相邻矩形的最小个数为 10,该值越大,检测的准确性越高,但可能会遗漏一些人脸。minSize = (5, 5):忽略小于此尺寸的目标。faces是一个列表,包含检测到的每个人脸的矩形框信息,每个矩形框信息为(x, y, w, h),分别表示人脸矩形框的左上角 x 坐标、y 坐标,以及矩形框的宽度w和高度h。- 处理每个人脸:
python
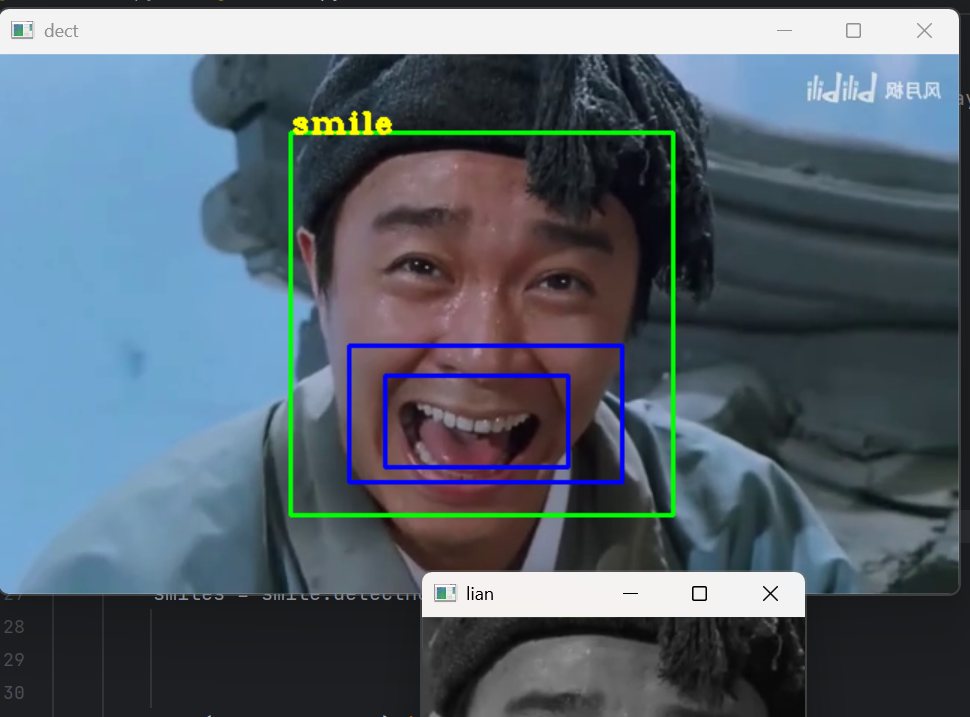
for (x, y, w, h) in faces:cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)roi_gray_face = gray[y:y + h, x:x + w]smiles = smile.detectMultiScale(roi_gray_face, scaleFactor=1.5, minNeighbors=9, minSize=(50, 50))for (sx, sy, sw, sh) in smiles:a = x + sxb = y + sycv2.rectangle(image, (a, b), (a + sw, b + sh), (255, 0, 0), 2)cv2.putText(image, "smile", (x, y), cv2.FONT_HERSHEY_COMPLEX_SMALL, 1, (0, 255, 255), thickness=2)
遍历检测到的每个人脸矩形框:
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2):在原始彩色图像上绘制绿色((0, 255, 0))矩形框标注出人脸位置,线宽为 2。roi_gray_face = gray[y:y + h, x:x + w]:提取人脸区域的灰度图像,用于后续在人脸区域内进行微笑检测。smiles = smile.detectMultiScale(roi_gray_face, scaleFactor=1.5, minNeighbors=9, minSize=(50, 50)):在提取的人脸灰度区域内使用微笑检测分类器smile进行微笑检测。scaleFactor = 1.5:每次搜索窗口的大小增加 50%,由于是在人脸区域内检测微笑,这个值相对较大。minNeighbors = 9:设置构成微笑检测目标的相邻矩形的最小个数为 9。minSize = (50, 50):忽略小于此尺寸的目标,确保检测到的微笑具有一定的尺寸。
- 对于检测到的每个微笑矩形框:
a = x + sx和b = y + sy:计算微笑矩形框在原始图像中的实际位置。cv2.rectangle(image, (a, b), (a + sw, b + sh), (255, 0, 0), 2):在原始彩色图像上绘制蓝色((255, 0, 0))矩形框标注出微笑位置,线宽为 2。cv2.putText(image, "smile", (x, y), cv2.FONT_HERSHEY_COMPLEX_SMALL, 1, (0, 255, 255), thickness=2):在人脸矩形框的左上角位置显示文字 “smile”,表示检测到微笑。
- 显示结果:
python
cv2.imshow("dect", image)
key = cv2.waitKey(25)
if key == 27:break
在名为dect的窗口中显示标注了人脸和微笑的图像。cv2.waitKey(25)等待 25 毫秒,检查是否有按键按下。如果按下esc键(ASCII 码为 27),则退出循环。
- 资源释放部分:
python
cap.release()
cv2.destroyAllWindows()
循环结束后,释放摄像头(或视频文件)资源,并关闭所有 OpenCV 窗口。
代码
# 人脸微笑检测 (摄像头)
import cv2
faceCascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
smile = cv2.CascadeClassifier("haarcascade_smile.xml")
cap = cv2.VideoCapture('xiao.mp4') # 初始化摄像头
while True: # 处理每一帧ret, image = cap.read() # 读取一帧image = cv2.flip(image, 1) # 图片翻转,水平翻转(镜像)# 没有读到,直接退出if ret is None:breakgray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 灰度化(彩色BGR-->灰度Gray)faces = faceCascade.detectMultiScale(gray, # 人脸检测scaleFactor=1.1,minNeighbors=10,minSize=(5, 5))# ==================处理每个人脸=======================for (x, y, w, h) in faces:cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)# 提取人脸所在区域,多通道形式# roiColorFace=image[y:y+h,x:x+w]# 提取人脸所在区域,单通道形式roi_gray_face = gray[y:y + h, x:x + w]cv2.imshow('lian',roi_gray_face)# 微笑检测,仅在人脸区域内检测smiles = smile.detectMultiScale(roi_gray_face,scaleFactor=1.5,minNeighbors=9,minSize=(50, 50))for (sx, sy, sw, sh) in smiles:# 绘制微笑区域a = x + sxb = y + sycv2.rectangle(image, (a, b),(a + sw, b + sh), (255, 0, 0), 2)# 显示文字“smile”表示微笑了cv2.putText(image, "smile", (x, y), cv2.FONT_HERSHEY_COMPLEX_SMALL, 1,(0, 255, 255), thickness=2)# 显示结果cv2.imshow("dect", image)key = cv2.waitKey(25)if key == 27:break
cap.release()
cv2.destroyAllWindows()效果