Linux学习笔记(五)--Linux基础开发工具使用
在Linux中软件包通常是指一个包含了软件程序、元数据、依赖关系信息和安装脚本的压缩文件。
因为在Linux上如果没有软件包管理器,那么想要下载软件会非常麻烦,不仅需要自己去手动编译和安装,而且难以卸载和管理,所以软件包的出现解决了这些问题.软件包一般是由程序文件(编译好的可执行文件、库文件等。)和配置文件(软件默认的配置。)元数据(包含软件名称、描述、版本、维护者等信息。) 依赖列表(列出该软件正常运行所必须的其他软件包。)以及安装前/后脚本(在安装或卸载前后自动运行的脚本,用于完成一些特定任务(如创建用户、启动服务等)。)
apt/dpkt--(Ubuntu中的软件包管理器)
dpkt:是底层的包管理工具,负责实际安装、查询、验证单个 .rpm文件。但它无法自动解决依赖关系。
apt:是高层的包管理工具,它基于 rpm,它的核心功能是自动解决依赖关系和从网络仓库获取软件包。yum 最终还是会调用 rpm命令来完成具体的安装和卸载操作。
apt常用命令:
功能 | Ubuntu / Debian (APT) | 说明 |
|---|---|---|
安装软件 | | 安装指定软件包 |
更新软件列表 | | 从软件源服务器获取最新的软件包列表( |
更新所有软件 | | 更新所有已安装的软件包(注意命令不同) |
卸载软件 | | 卸载软件包,保留配置文件 |
彻底卸载 | | 卸载软件包,同时删除配置文件 |
搜索软件 | | 在仓库中搜索软件包 |
列出已安装 | | 列出所有已安装的包 |
获取包信息 | | 显示软件包的详细信息 |
清理缓存 | | 清理下载的软件包缓存 |
关于rzsz工具:
rz和 sz是 Linux 系统中用于通过终端(命令行)进行文件上传和下载的两个实用工具,通常用于 ZMODEM 协议 的文件传输。它们特别适合在 SSH 终端(如 Xshell、SecureCRT、PuTTY 等)中使用,方便用户在不依赖 FTP/SFTP 的情况下快速传输文件。
作用:
命令 | 功能 | 适用场景 |
|---|---|---|
| Receive ZMODEM(接收文件) | 从本地计算机上传文件到远程 Linux 服务器 |
| Send ZMODEM(发送文件) | 从远程 Linux 服务器下载文件到本地计算机 |
使用rzsz:
(1)上传文件到Linux(rz)
在远程终端执行rz命令,跳转出一个选择文件的页面,点击你所需要上传的文件
(2)从Linux下载文件:
在远程终端执行:
sz <文件名>
你的终端会自动弹出文件保存对话框,选择保存位置即可下载。
Linux开发工具:
Linux编辑器--vim:
vim是 Linux/Unix 系统中最强大的文本编辑器之一
vim的基本模式:vim有三种主要模式,分别是命令模式(command mode)、插 入模式(Insert mode)和底行模式(last line mode),各模式的功能区分如下:
模式 | 进入方式 | 功能 |
|---|---|---|
普通模式(Normal Mode) | 启动 | 执行命令(如复制、粘贴、删除、保存等) |
插入模式(Insert Mode) | 按 | 输入/编辑文本(类似普通编辑器) |
命令行模式(Command Mode) | 在普通模式下按 | 执行保存、退出、搜索、替换等操作 |
基本操作:
(1)打开文件
vim 文件名 # 打开文件(如果不存在则新建)
vim +10 文件名 # 打开文件并跳转到第 10 行
vim -O2 文件1 文件2 # 左右分屏打开两个文件(2)保存和退出
命令 | 功能 |
|---|---|
| 保存文件 |
| 退出 vim |
| 保存并退出 |
| 强制退出(不保存) |
| 另存为新文件 |
(3)光标移动
按键 | 功能 |
|---|---|
| 左、下、上、右移动 |
| 向下/向上翻页 |
| 跳转到文件第一行 |
| 跳转到文件最后一行 |
| 跳转到第 10 行 |
| 跳转到行尾 |
| 跳转到行首 |
(4)编辑文本
按键 | 功能 |
|---|---|
| 在光标前进入插入模式 |
| 在光标后进入插入模式 |
| 在下一行插入新行并进入插入模式 |
| 删除当前行 |
| 复制当前行 |
| 粘贴 |
| 撤销(Undo) |
| 重做(Redo) |
(5)搜索和替换
命令 | 功能 |
|---|---|
| 向下搜索(按 |
| 向上搜索 |
| 全局替换(所有匹配) |
| 替换第 10-20 行的内容 |
(6)分屏操作
命令 | 功能 |
|---|---|
| 水平分屏 |
| 垂直分屏 |
| 切换分屏 |
| 关闭当前分屏 |
(7)末行模式命令集
vim的 末行模式(Command-Line Mode) 是在 普通模式(Normal Mode) 下输入 :进入的,用于执行文件操作、搜索替换、设置选项等高级命令。
| 命令 | 功能 | 作用 |
| set nu | 输入「set nu」后,会在文件中的每一行前面列出行号。 | 列出行号 |
| # | 「#」号表示一个数字,在冒号后输入一个数字,再按回车键就会跳到该行了,如输入数字15, 再回车,就会跳到文章的第15行。 | 跳到文件中的某一行 |
| /关键字 | 先按「/」键,再输入您想寻找的字符,如果第一次找的关键字不是您想要的,可以一直按 「n」会往后寻找到您要的关键字为止。 | 查找字符 |
| ?关键字 | 先按「?」键,再输入您想寻找的字符,如果第一次找的关键字不是您想要的,可以一直 按「n」会往前寻找到您要的关键字为止。 | 查找字符 |
| w | 在冒号输入字母「w」就可以将文件保存起来 | 保存文件 |
| q | 按「q」就是退出,如果无法离开vim,可以在「q」后跟一个「!」强制离开vim。 | 离开vim |
| wq | 一般建议离开时,搭配「w」一起使用,这样在退出的时候还可以保存文件 | 离开vim |
Linux编辑器:gcc/g++使用(用来编译C语言和C++程序)
(1)安装gcc/g++(Ubuntu)
sudo apt update
sudo apt install gcc g++ # 安装 gcc 和 g++(2)验证安装是否成功
gcc --version
g++ --version(3)背景知识
在C/C++中要想将代码转换成可执行文件需要经过预处理,编译,汇编和链接四个步骤.
预处理阶段:
作用:处理源代码中的 预处理指令(以 #开头的指令),比如 #include、#define、#ifdef等。
输入:.c或 .cpp文件
输出:.i文件(预处理后的代码)
主要操作:
宏替换(#define定义的宏会被展开)
头文件包含(#include的文件内容会被插入)
条件编译(#ifdef、#ifndef等决定哪些代码会被编译)
删除注释(所有注释 //和 /* */会被移除)
使用命令(示例):
gcc -E main.c -o main.i//-E表示只进行预处理编译阶段:
作用:将预处理后的代码 转换成汇编代码。
输入:.i文件(或直接 .c文件)
输出:.s文件(汇编代码)
主要操作:
词法分析
语法分析
语义分析
优化
生成汇编代码
使用命令(示例):
gcc -S main.i -o main.s//-S表示只编译汇编阶段:
作用:将汇编代码 转换成机器码(二进制目标文件)。
输入:.s文件
输出:.o文件(目标文件,Windows 上是 .obj)
主要操作:
将汇编指令 逐条翻译 成机器码(0和 1)
生成 可重定位目标文件
使用命令(示例)
gcc -c main.s -o main.o//-c表示只汇编链接阶段:
作用:将多个目标文件(.o)和库文件(.a或 .so) 合并成一个可执行文件。
输入:.o文件 + 库文件
输出:可执行文件(如 a.out或 .exe)
主要操作:
符号解析:找到所有函数和变量的定义
重定位:调整代码和数据的内存地址
合并库(如 libc.so、libstdc++.so)
使用命令(示例)
gcc main.o -o myprogram//-o表示只链接完整编译流程:(gcc会自动完成所有步骤)
gcc main.c -o myprogram(4)函数库
函数库是一组预编译的函数、类或变量的集合,可以被其他程序调用。函数库通常分为 静态库 和 动态库 两种形式。
特性 | 静态库( | 动态库( |
|---|---|---|
文件后缀 |
|
|
编译时行为 | 库代码直接嵌入到可执行文件中 | 库代码不嵌入,仅记录依赖信息 |
运行时行为 | 无需外部库文件 | 需动态库文件存在于系统路径 |
磁盘空间 | 可执行文件较大(重复库代码) | 可执行文件较小(共享库代码) |
内存占用 | 每个进程独立加载库代码 | 多个进程共享同一份库代码 |
更新库版本 | 需重新编译可执行文件 | 替换 |
加载速度 | 较快(无运行时加载开销) | 稍慢(需运行时加载) |
依赖管理 | 无外部依赖 | 需确保动态库存在于系统路径 |
创建静态库:
假设有两个源文件:
add.c:实现加法函数
sub.c:实现减法函数
编译为.o文件
gcc -c add.c -o add.o # 生成 add.o
gcc -c sub.c -o sub.o # 生成 sub.o打包为静态库.a
ar rcs libmath.a add.o sub.oar:归档工具(Unix 静态库打包命令)。
rcs:选项组合(r替换旧文件,c创建库,s生成索引)。
使用静态库:
gcc main.c -L. -lmath -o main-L.:指定库搜索路径(.表示当前目录)。
-lmath:链接名为 libmath.a的库(省略 lib前缀和 .a后缀)。
gcc/g++常用编译选项:
基础编译选项:
选项 | 作用 | 示例 |
|---|---|---|
| 指定输出文件名 |
|
| 只编译不链接,生成 |
|
| 只运行预处理器(生成预处理后的代码) |
|
| 只编译到汇编代码(生成 |
|
| 显示详细的编译过程(调试用) |
|
警告选项:
选项 | 作用 | 示例 |
|---|---|---|
| 开启所有常见警告 |
|
| 启用额外警告(比 |
|
| 将警告视为错误(强制修复) |
|
| 禁用特定警告 |
|
调试选项:
选项 | 作用 | 示例 |
|---|---|---|
| 生成调试信息(用于 GDB) |
|
| 生成更详细的 GDB 调试信息 |
|
| 生成性能分析(gprof 用) |
|
优化选项:
选项 | 优化级别 | 说明 |
|---|---|---|
| 无优化 | 编译速度快,适合调试 |
| 基础优化 | 平衡代码大小和执行速度 |
| 中等优化 | 推荐大多数场景使用 |
| 激进优化 | 可能增加代码体积 |
| 优化代码大小 | 嵌入式系统常用 |
| 激进优化(忽略严格标准) | 可能影响精度 |
Linux调试器--gdb的使用:
(1)安装gdb(Ubuntu)
sudo apt install gdb(2)启动gdb
gdb ./hello # 调试可执行文件(3)gdb基本命令
命令 | 功能描述 |
|---|---|
| 显示源代码。从指定行号(或上次位置)开始,每次列出10行。 |
| 列出指定函数的源代码。 |
| 开始运行程序。 |
| 单步执行(不进入函数体)。 |
| 单步执行(会进入函数体)。 |
| 在指定行设置断点。 |
| 在指定函数的开头设置断点。 |
| 查看所有已设置的断点信息(包括编号、位置等)。 |
| 持续执行直至当前函数返回,然后暂停。 |
| 打印表达式的值。表达式可为变量、或可调用函数。 |
| 打印变量的值。 |
| 修改变量的值。 |
| 从当前位置开始连续执行程序(而非单步),直到下一个断点或结束。 |
| 从头开始连续执行程序。 |
| 删除所有断点。 |
| 删除指定序号 n 的断点。 |
| 禁用所有断点(断点仍存在,但不会暂停)。 |
| 启用所有断点。 |
| 查看当前设置的所有断点信息。 |
| 持续跟踪查看一个变量,每次程序暂停时都会显示其值。 |
| 取消之前通过 |
| 持续运行直至指定行 X(用于跳出循环等场景)。 |
| 查看函数的调用栈(层层调用的关系)及参数。 |
| 查看当前函数栈帧内所有局部变量的值。 |
| 退出 GDB 调试器。 |
Linux项目自动化构建工具--make/Makefile
make是Linux/Unix系统中一个强大的自动化构建工具,它通过读取Makefile文件来自动化编译和构建过程。make工具的主要功能包括:自动确定需要重新编译的文件,根据依赖关系按正确顺序编译,只重新编译修改过的文件及其依赖项.make是一条命令,makefile是一个文件,两个搭配使用,完成项目自动化构建.
Makefile基础语法:
target: prerequisitesrecipe
target:通常是生成的文件名,也可以是一个操作名称(伪目标)
prerequisites:生成target所需的文件或目标
recipe:生成target需要执行的命令(必须以tab开头)
示例:
#include <stdio.h>int main(){printf("hello Makefile!\n");return 0;}makefile文件:
hello: hello.cgcc -o hello hello.cclean:rm -f hello那么make的工作原理是怎样的?
接下来为大家解释一下:
make会在当前目录下找名字叫“Makefile”或“makefile”的文件。如果找到,它会找文件中的第一个目标文件(target),在上面的例子中,他会找到“hello”这个文件, 并把这个文件作为最终的目标文件。如果hello文件不存在,或是hello所依赖的后面的hello.o文件的文件修改时间要比hello这个文件新(可 以用touch测试),那么,他就会执行后面所定义的命令来生成hello这个文件。如果hello所依赖的hello.o文件不存在,那么make会在当前文件中找目标为hello.o文件的依赖性,如果 找到则再根据那一个规则生成hello.o文件(这有点像一个堆栈的过程)。当然,你的C文件和H文件是存在的啦,于是make会生成 hello.o 文件,然后再用 hello.o 文件声明 make的终极任务,也就是执行文件hello了。这就是整个make的依赖性,make会一层又一层地去找文件的依赖关系,直到最终编译出第一个目标文件。在找寻的过程中,如果出现错误,比如最后被依赖的文件找不到,那么make就会直接退出,并报错, 而对于所定义的命令的错误,或是编译不成功,make根本不理。
流程图如下: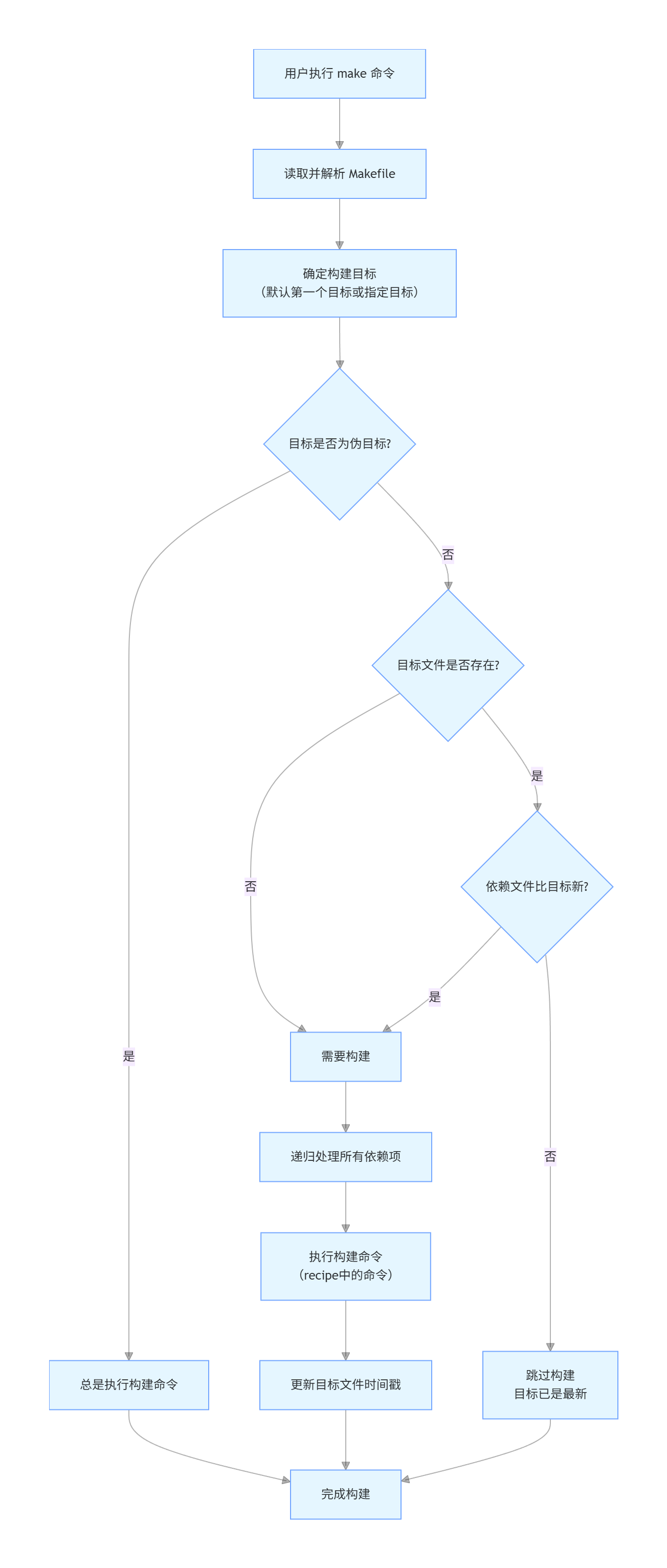
行缓冲区概念:
行缓冲区的三种类型:
行缓冲:遇到换行符\n时刷新缓冲区,或缓冲区填满时刷新(典型应用:终端标准输出)
核心特点:
#include <stdio.h>
int main() {printf("This will be buffered"); // 行缓冲,未遇到\n不立即显示printf(" until newline\n"); // 遇到\n,刷新缓冲区return 0;
}行缓冲触发的三种情况:
(1)遇到换行符\n
(2)缓冲区已满(通常1024或4096字节)
(3)主动调用fflush(stdout)
例:
#include <stdio.h>int main(){printf("hello Makefile!");fflush(stdout);sleep(3);return 0;}如果不调用fflush(),由于没有\n,进度条可能不会实时显示
编写自己的第一个Linux小程序--进度条:
(1)先在这里设定好的目录下建立一个cpp文件
vim progressbar.cpp(2)编译进度条代码
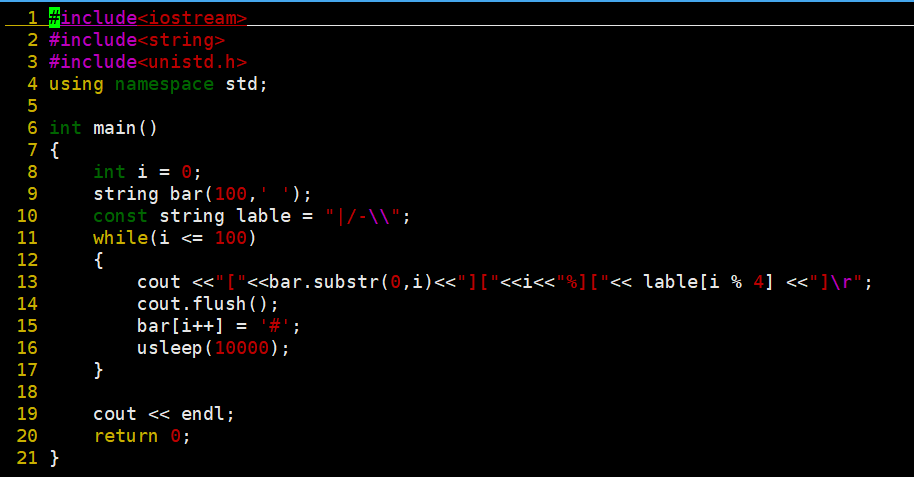
(3)编译文件
g++ -o progress progress.cpp(4)运行文件
./progress完成截图
![]()