《WINDOWS 环境下32位汇编语言程序设计》学习17章 PE文件(1)
PE格式是Windows下最常用的可执行文件格式,有些应用必须建立在了解PE文件的基础上,如可执行文件的加密解密、文件型病毒的查杀,等等。本章将具体讨论与PE文件相关的内容。
与PE文件格式相关的资料可以说是不少,但大多数只是列举了PE文件头中一些数据结构和字段含义的介绍,阅读后让读者很难有全局的概念,为了避免这种做法,本章将以一些PE文件的操作例子来举例说明如何对PE文件进行编程。
17.1 PE文件的结构
17.1.1 概论
在一个操作系统中,可执行的代码在被最终装入内存执行之前是以文件的方式存放在磁盘中的,DOS操作系统中的COM文件是最早的也是结构最简单的可执行文件,COM文件中仅仅包括可执行代码,没有附带任何“支持性”的数据,所以COM文件在使用方便的同时也存在诸多的限制:首先是没有附加数据来指定文件入口,这样,第一句执行指令必须安排在文件头部;再就是没有重定位信息,这样代码中不能有跨段操作数据的指令,造成代码和数据,甚至包括堆栈只能限制在同一个64 KB的段中。
为了更灵活地使用可执行代码,DOS系统中又定义了另一种可执行文件,那就是我们熟悉的EXE文件,EXE文件在代码的前面加了一个文件头,文件头中包括各种说明数据,如文件入口、堆栈的位置、重定位表等等,操作系统根据文件头中的信息将代码部分装入内存,根据重定位表修正代码,最后在设置好堆栈后从文件头中指定的入口开始执行。
显然,可执行文件的格式是操作系统工作方式的写照,因为可执行文件头部的数据是供操作系统装载文件用的,不同操作系统的运行方式各不相同,所以造成可执行文件的格式各不相同。
当Windows 3.x出现的时候,可执行文件中出现了32位代码,程序运行时转到保护模式之前需要在实模式下做一些初始化,这样实模式的16位代码必须和32位代码一起放在可执行文件中,旧的DOS可执行文件格式无法满足这个要求,所以Windows 3.x执行文件使用新的LE格式的可执行文件(Linear executable/线性可执行文件),Windows 9x中的VxD驱动程序也使用LE格式,因为这些驱动程序中也同时包括16位和32位代码。
而在Windows 9x,Windows NT,Windows 2000下,纯32位的可执行文件都使用微软设计的一种新的文件格式——PE格式(Portable Executable File Format/可移植的执行体)。
PE文件的基本结构如图17.1所示,在PE文件中,代码、已初始化的数据、资源和重定位信息等数据被按照属性分类放到不同的Section(节区/或简称为节)中,而每个节区的属性和位置等信息用一个IMAGE_SECTION_HEADER结构来描述,所有的IMAGE_SECTION_HEADER结构组成一个节表(Section Table),节表数据在PE文件中被放在所有节数据的前面。我们知道,Win32中可以对每个内存页分别指定可执行、可读写等属性,在PE文件中将同样属性的数据分类放在一起是为了统一描述这些数据装入内存后的页面属性。
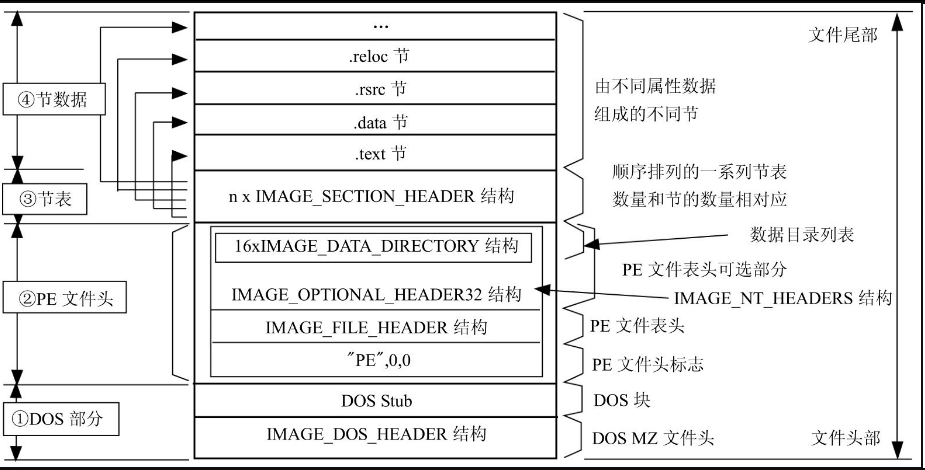
图17.1 PE文件的基本结构
由于数据是按照属性在节中放置的,不同用途但是属性相同的数据(如导入表、导出表以及.const段指定的只读数据)可能被放在同一个节中,所以PE文件中还用一系列的数据目录结构IMAGE_DATA_DIRECTORY来分别指明这些数据的位置,数据目录表和其他描述文件属性的数据合在一起称为PE文件头,PE文件头被放置在节和节表的前面。
上面介绍的这些部分是PE文件中真正用于Win32的部分,为了与DOS系统的文件格式兼容,在这部分的前面又加上了一个标准的DOS MZ格式的可执行部分,所有这些部分合起来组成了现在使用的PE文件。下面分别介绍这些组成部分。
17.1.2 DOS文件头和DOS块
PE文件中还包括一个标准的DOS可执行文件部分,如图17.1中左边的①所示,这看上去有些奇怪,但是这对于可执行文件的向下兼容性来说却是不可缺少的。
操作系统识别可执行文件的方法是按照文件格式而不是按照扩展名,所以,虽然DOS的传统EXE文件、LE格式和PE格式的可执行文件都沿用了.exe的扩展名,但是操作系统总是能够正确识别这些文件并按照正确的方法装入它们。如果文件头中的数据格式不符合任何已经定义的格式,那么系统按照COM文件的格式装入文件,也就是说将整个文件的数据全部当做代码装入执行。
这个规则说明了为什么很多非.exe扩展名的可执行文件(如LE格式的VxD文件、PE格式的.dll,.scr文件,等等)也能够被装入并正确运行,也说明了为什么把可执行文件的扩展名随意修改为.exe、.com或者.bat(甚至是.pif,.scr或者.bat),系统也能正确识别并执行的原因。
但是这种方法也存在一个问题,假如一个PE格式的可执行文件在Windows中执行,那没有任何异常,因为Windows能够识别PE文件头并正确装入,但如果将PE文件放入DOS执行,那么DOS系统肯定无法识别PE文件头,假如PE文件的头部不包括一个DOS部分的话,那么按照前面介绍的规则,PE文件头的数据会被DOS系统作为代码装入并执行,这种操作几乎可以肯定会让系统立刻挂起。
为了避免这种情况,PE文件的头部包括了一个标准的DOS MZ格式的可执行部分,这样万一在DOS下执行一个PE文件,系统可以将文件解释为DOS下的.exe可执行格式,并执行DOS部分的代码。
一般来说,DOS部分的执行代码只是简单地显示一个“This program cannot be run in DOS mode.”就退出了,这段简单的代码是编译器自动生成的。
如果对编译器内定的这段简单代码不满意的话,读者可以回忆一下第2章2.2.1节中介绍link.exe参数部分的内容,如果在link时使用/stub:dos_file_name.exe选项,读者完全可以用一个全功能的DOS程序来作为PE文件的DOS部分。
笔者就见过一个CD播放程序,在DOS下执行是一个文本界面的播放器,而在Windows下执行又是标准的Windows界面。我们知道,DOS和Windows下不管是界面还是CD操作都是完全不同的概念,它们不可能在同一段代码中完成。实际上,这个程序就是用这种方法插入了一个完全独立的DOS CD播放程序。
PE文件中的DOS部分由MZ格式的文件头和可执行代码部分组成,可执行代码被称为“DOS块”(DOS stub)。MZ格式的文件头由IMAGE_DOS_HEADER结构定义:
IMAGE_DOS_HEADER STRUCTe_magic WORD ? ;DOS可执行文件标记,为“MZ”e_cblp WORD ?e_cp WORD ?e_crlc WORD ?e_cparhdr WORD ?e_minalloc WORD ?e_maxalloc WORD ?e_ss WORD ? ;DOS代码的初始化堆栈段e_sp WORD ? ;DOS代码的初始化堆栈指针e_csum WORD ?e_ip WORD ? ;DOS代码的入口IPe_cs WORD ? ;DOS代码的入口CSe_lfarlc WORD ?e_ovno WORD ?e_res WORD 4 dup(?)e_oemid WORD ?e_oeminfo WORD ?e_res2 WORD 10 dup(?)e_lfanew DWORD ? ;指向PE文件头IMAGE_DOS_HEADER ENDSDOS文件头的前面部分并不陌生,第一个字段e_magic被定义成字符“MZ”(在Windows.inc文件中已经预定义为IMAGE_DOS_SIGNATURE)作为识别标志,后面的一些字段指明了入口地址、堆栈位置和重定位表位置等。
标准的DOS文件头的定义只到e_ovno字段位置,后面的这些字段是在Windows系统出现后为了定义LE、PE等文件格式而扩充的,DOS系统对这些字段不进行解释。对于PE文件来说,有用的是最后的e_lfanew字段,这个字段指出了真正的PE文件头(如图17.1中的②所示)在文件中的位置,这个位置总是以8字节为单位对齐的。
实际上,Windows中使用的其他几种可执行文件格式也是这样引出的,如果是LE,LX等格式的文件,那么e_lfanew字段指向的位置会是LE文件头和LX文件头。
17.1.3 PE文件头(NT文件头)
从DOS文件头的e_lfanew字段(文件头偏移003ch)得到真正的PE文件头位置后,现在来看看它的定义,PE文件头是由IMAGE_NT_HEADERS结构定义的:
IMAGE_NT_HEADERS STRUCTSignature DWORD ? ;PE文件标识FileHeader IMAGE_FILE_HEADER <>OptionalHeader IMAGE_OPTIONAL_HEADER32 <>IMAGE_NT_HEADERS ENDSPE文件头的第一个双字是一个标志,它被定义为00004550h,也就是字符“P”,“E”加上两个0,这也是“PE”这个称呼的由来,大部分的文件属性由标志后面的IMAGE_FILE_HEADER和IMAGE_OPTIONAL_HEADER32结构来定义,从名称看,似乎后面的这个PE文件表头结构是可选的(Optional),但实际上这个名称是名不符实的,因为它总是存在于每个PE文件中。
1.IMAGE_FILE_HEADER结构
IMAGE_FILE_HEADER结构的定义如下所示,字段后面的注释中标出了字段相对于PE文件头的偏移量,以供读者快速参考:
IMAGE_FILE_HEADER STRUCTMachine WORD ? ;0004h - 运行平台NumberOfSections WORD ? ;0006h - 文件的节数目TimeDateStamp DWORD ? ;0008h - 文件创建日期和时间PointerToSymbolTable DWORD ? ;000ch - 指向符号表(用于调试)NumberOfSymbols DWORD ? ;0010h - 符号表中的符号数量(用于调试)SizeOfOptionalHeader WORD ? ;0014h - IMAGE_OPTIONAL_HEADER32结构的长度Characteristics WORD ? ;0016h - 文件属性
IMAGE_FILE_HEADER ENDS几个关键字段的含义解释如下。
● Machine字段
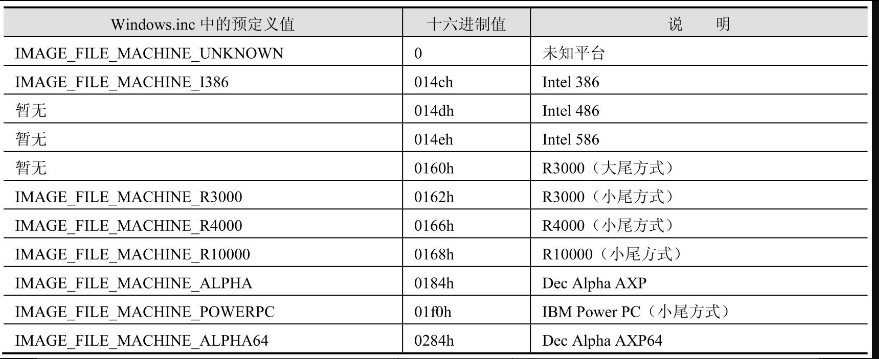
用来指定文件的运行平台,常见的定义值如表17.1所示。Windows可以运行在Intel和Sun等几种不同的硬件平台上,不同平台指令的机器码是不同的,为不同平台编译的可执行文件显然无法通用。如果Windows检测到这个字段指定的适用平台与当前的硬件平台不兼容,它将拒绝装入这个文件。
表17.1 运行平台识别码的定义(更多定义参见Windows.inc文件)
● NumberOfSections字段
指出文件中存在的节的数量(如图17.1中的④所示),同样,节表的数量(如图17.1中的③所示)也等于节的数量。
● TimeDateStamp字段
编译器创建此文件的时间,它的数值是从1969年12月31日下午4:00开始到创建时间为止的总秒数。
● PointerToSymbolTable和NumberOfSymbols字段
这两个字段并不重要,它们与调试用的符号表有关。
● SizeOfOptionalHeader字段
紧接在当前结构下面的IMAGE_OPTIONAL_HEADER32结构的长度,这个值等于00e0h。
● Characteristics字段
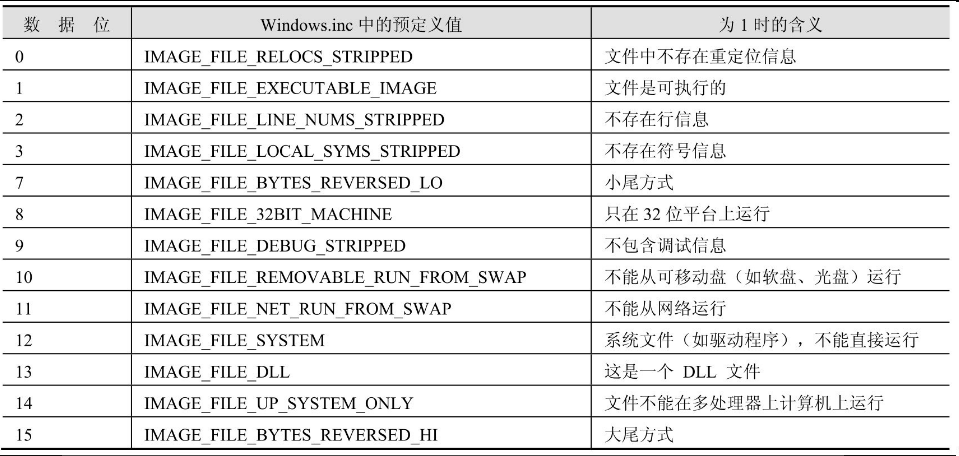
属性标志字段,它的不同数据位定义了不同的文件属性,具体内容如表17.2所示,这是一个很重要的字段,不同的定义将影响系统对文件的装入方式,比如,当位13为1时,表示这是一个DLL文件,那么系统将使用调用DLL入口函数的方式调用文件入口,否则的话,表示这是一个普通的可执行文件,系统直接跳到入口处执行。对于普通的可执行PE文件,这个字段的值一般是010fh,而对于DLL文件来说,这个字段的值一般是210eh。
表17.2 属性位字段的含义
2.IMAGE_OPTIONAL_HEADER32结构
定义IMAGE_OPTIONAL_HEADER32结构的本意在于让不同的开发者能够在PE文件头中使用自定义的数据,这就是结构名称中“Optional”一词的由来,但实际上IMAGE_FILE_HEADER结构不足以用来定义PE文件的属性,反而在这个“可选”的部分中有着更多的定义数据,对于读者来说,可以完全不必考虑这两个结构的区别在哪里,只要把它们当成是连在一起的“PE文件头结构”就可以了。
IMAGE_OPTIONAL_HEADER32结构的定义如下,同样,字段后面的注释中标出了字段本身相对于PE文件头的偏移量:
IMAGE_OPTIONAL_HEADER32 STRUCTMagic WORD ? ;0018h 107h=ROM Image,10Bh=exe ImageMajorLinkerVersion BYTE ? ;001ah链接器版本号MinorLinkerVersion BYTE ? ;001bhSizeOfCode DWORD ? ;001ch所有含代码的节的总大小SizeOfInitializedData DWORD ? ;0020h所有含已初始化数据的节的总大小SizeOfUninitializedData DWORD ? ;0024h所有含未初始化数据的节的大小AddressOfEntryPoint DWORD ? ;0028h程序执行入口RVABaseOfCode DWORD ? ;002ch代码的节的起始RVABaseOfData DWORD ? ;0030h数据的节的起始RVAImageBase DWORD ? ;0034h程序的建议装载地址SectionAlignment DWORD ? ;0038h内存中的节的对齐粒度FileAlignment DWORD ? ;003ch文件中的节的对齐粒度MajorOperatingSystemVersion WORD ? ;0040h操作系统主版本号MinorOperatingSystemVersion WORD ? ;0042h操作系统副版本号MajorImageVersion WORD ? ;0044h可运行于操作系统的最小版本号MinorImageVersion WORD ? ;0046hMajorSubsystemVersion WORD ? ;0048h可运行于操作系统的最小子版本号MinorSubsystemVersion WORD ? ;004ahWin32VersionValue DWORD ? ;004ch未用SizeOfImage DWORD ? ;0050h内存中整个PE映像尺寸SizeOfHeaders DWORD ? ;0054h所有头+节表的大小CheckSum DWORD ? ;0058hSubsystem WORD ? ;005ch文件的子系统DllCharacteristics WORD ? ;005ehSizeOfStackReserve DWORD ? ;0060h初始化时的堆栈大小SizeOfStackCommit DWORD ? ;0064h初始化时实际提交的堆栈大小SizeOfHeapReserve DWORD ? ;0068h初始化时保留的堆大小SizeOfHeapCommit DWORD ? ;006ch初始化时实际提交的堆大小LoaderFlags DWORD ? ;0070h未用NumberOfRvaAndSizes DWORD ? ;0074h下面的数据目录结构的数量DataDirectory IMAGE_DATA_DIRECTORY 16 dup(<>) ;0078hIMAGE_OPTIONAL_HEADER32 ENDS这个结构中的大部分字段都不重要,读者可以从注释中理解它们的含义,下面说明的这些字段是比较重要的。
● AddressOfEntryPoint字段
指出文件被执行时的入口地址,这是一个RVA地址(RVA的含义在下一节中详细介绍)。如果在一个可执行文件上附加了一段代码并想让这段代码首先被执行,那么只需要将这个入口地址指向附加的代码就可以了。
● ImageBase字段
指出文件的优先装入地址。也就是说当文件被执行时,如果可能的话,Windows优先将文件装入到由ImageBase字段指定的地址中,只有指定的地址已经被其他模块使用时,文件才被装入到其他地址中。链接器产生可执行文件的时候对应这个地址来生成机器码,所以当文件被装入这个地址时不需要进行重定位操作,装入的速度最快,如果文件被装载到其他地址的话,将不得不进行重定位操作,这样就要慢一点。
对于EXE文件来说,由于每个文件总是使用独立的虚拟地址空间,优先装入地址不可能被其他模块占据,所以EXE总是能够按照这个地址装入,这也意味着EXE文件不再需要重定位信息。对于DLL文件来说,由于多个DLL文件全部使用宿主EXE文件的地址空间,不能保证优先装入地址没有被其他的DLL使用,所以DLL文件中必须包含重定位信息以防万一。因此,在前面介绍的IMAGE_FILE_HEADER结构的Characteristics字段中,DLL文件对应的IMAGE_FILE_RELOCS_STRIPPED位总是为0,而EXE文件的这个标志位总是为1。
在链接的时候,可以通过对link.exe指定/base:address选项来自定义优先装入地址,如果不指定这个选项的话,一般EXE文件的默认优先装入地址被定为00400000h,而DLL文件的默认优先装入地址被定为10000000h。
● SectionAlignment字段和FileAlignment字段
SectionAlignment字段指定了节被装入内存后的对齐单位。也就是说,每个节被装入的地址必定是本字段指定数值的整数倍。而FileAlignment字段指定了节存储在磁盘文件中时的对齐单位。
● Subsystem字段
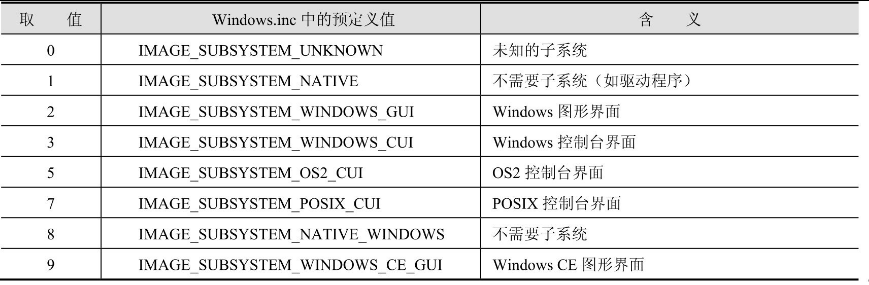
指定使用界面的子系统,它的取值如表17.3所示。这个字段决定了系统如何为程序建立初始的界面,链接时的/subsystem:xxx选项指定的就是这个字段的值,在前面章节的编程中我们早已知道:如果将子系统指定为Windows CUI,那么系统会自动为程序创建一个控制台窗口,而指定为Windows GUI的话,窗口必须由程序自己创建。
表17.3 界面子系统的取值和含义
● DataDirectory字段
这个字段可以说是最重要的字段之一,它由16个相同的IMAGE_DATA_DIRECTORY结构组成,虽然PE文件中的数据是按照装入内存后的页属性归类而被放在不同的节中的,但是这些处于各个节中的数据按照用途可以被分为导出表、导入表、资源、重定位表等数据块,这16个IMAGE_DATA_DIRECTORY结构就是用来定义多种不同用途的数据块的。IMAGE_DATA_DIRECTORY结构的定义很简单,它仅仅指出了某种数据块的位置和长度。
IMAGE_DATA_DIRECTORY STRUCTVirtualAddress DWORD ? ;数据的起始RVAisize DWORD ? ;数据块的长度
IMAGE_DATA_DIRECTORY ENDS如果将这16个IMAGE_DATA_DIRECTORY结构按照排列顺序编号为索引号0到15,那么其用途和索引号是一一对应的,其对应关系如表17.4所示。
表17.4 数据目录列表的含义
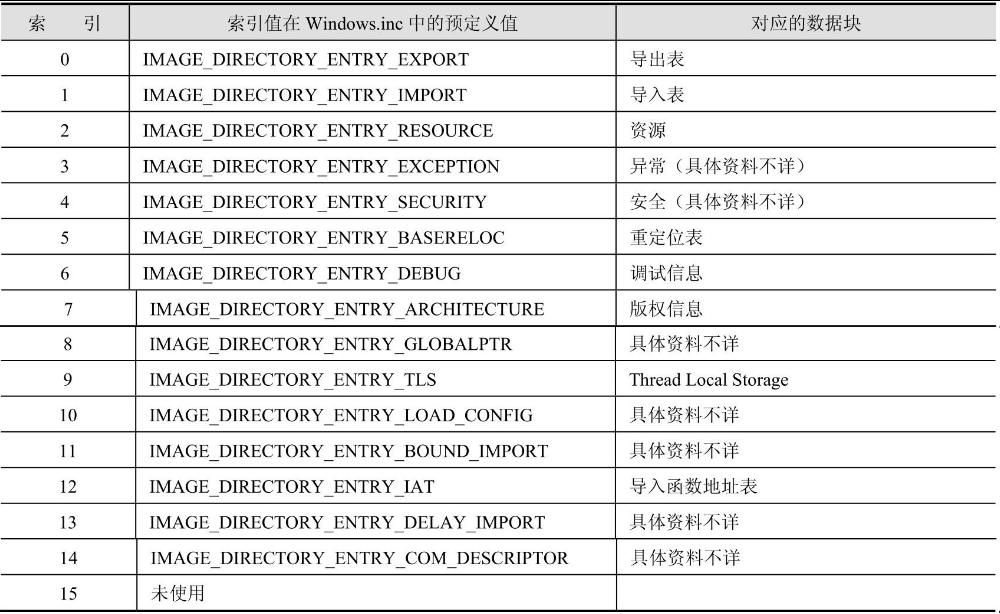
在PE文件中寻找特定的数据时就是从这些IMAGE_DATA_DIRECTORY结构开始的,比如要存取资源,那么必须从第3个IMAGE_DATA_DIRECTORY结构(索引为2)中得到资源数据块的大小和位置;同理,如果要查看PE文件导入了哪些DLL文件的哪些API函数,那就必须首先从第2个IMAGE_DATA_DIRECTORY结构得到导入表的位置和大小。
17.1.4 节表和节
从排列位置来看,PE文件在DOS部分和PE文件头部分以后就是节表和多个不同的节(如图17.1中的③和④所示)。要理解什么是节表,什么是节以及它们之间的关系,那就首先要了解Windows是如何将PE文件映射到内存的。
1.PE文件到内存的映射
在执行一个PE文件的时候,Windows并不在一开始就将整个文件读入内存,而是采用与内存映射文件类似的机制,也就是说,Windows装载器在装载的时候仅仅建立好虚拟地址和PE文件之间的映射关系,只有真正执行到某个内存页中的指令或者访问某一页中的数据时,这个页面才会被从磁盘提交到物理内存,这种机制使文件装入的速度和文件大小没有太大的关系。
但是系统装载可执行文件的方法又不完全等同于内存映射文件。当使用内存映射文件时,系统对“原著”非常忠实,如果将磁盘文件和内存映像对比一下,可以发现不管是数据本身还是数据之间的相对位置都是完全相同的。而装载可执行文件的时候,有些数据在装入前会被预先处理(如需要重定位的代码),而装入以后,数据之间的相对位置也可能改变,如图17.2所示,一个节的偏移和大小在装入内存前后可能是完全不同的。
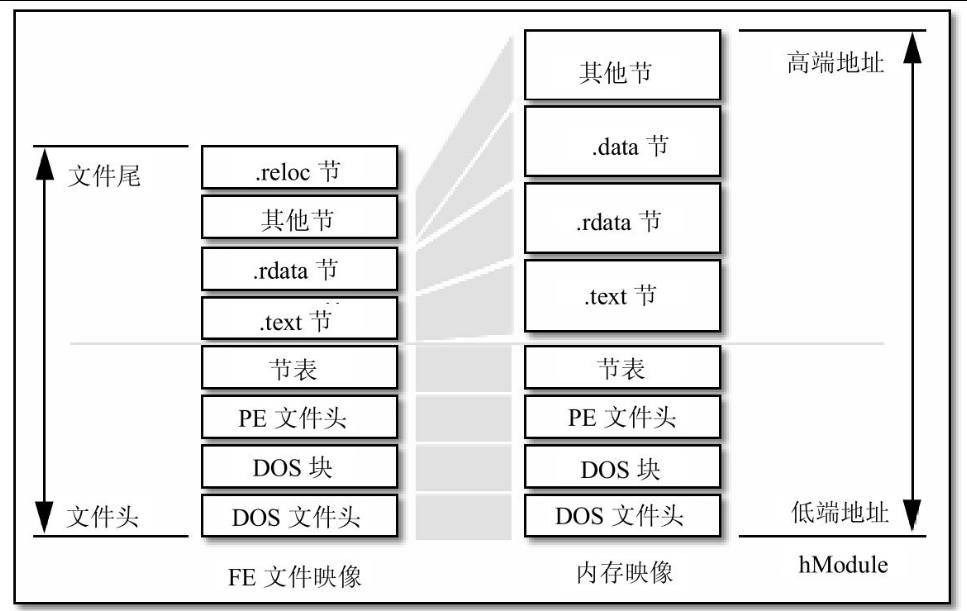
图17.2 PE文件到内存的映射
Windows装载器在装载DOS部分、PE文件头部分和节表部分时不进行任何处理,而装载节的时候将根据节的属性做不同的处理,一般需要处理以下几个方面的内容。
● 内存页的属性
对于磁盘映射文件来说,所有的页都是按照磁盘映射文件函数指定的属性设置的,但是装载可执行文件时,与节对应的内存页的属性要按照节的属性来设置。所以在同属一个模块的内存页中,从不同节映射过来的内存页的属性是不同的。
● 节的偏移地址
节的起始地址在磁盘文件中是按照IMAGE_OPTIONAL_HEADER32结构的FileAlignment字段的值对齐的,而被装载到内存中时是按照同一结构中的SectionAlignment字段的值对齐的,两者的值可能不同,所以一个节被装入内存后相对于文件头的偏移和在磁盘文件中的偏移可能是不同的。
节是相同属性数据的组合,当节被装入到内存中的时候,同一个节对应的内存页将被赋予相同的页属性,Windows系统对内存属性的设置是以页为单位来进行的,所以节在内存中的对齐单位必须至少是一个页的大小,对于Win32来说,这个值是4 KB(1000h),而对于Win64来说,这个值是8 KB(2000h)。节在磁盘文件中的对齐单位就没有最小4 KB的限制,为了减少磁盘文件的大小,文件对齐的单位一般要小于内存对齐的单位(FileAlignment的值一般为200h),这样,在磁盘中就不必为每个节最后的零头数据补足4 KB的大小了。
● 节的尺寸
对节尺寸的处理有两个方面,首先是由于磁盘映像和内存映像中节对齐单位的不同而造成的长度扩展;其次是对包含未初始化数据的节的处理(如图17.2中的.data节)。
对于未初始化数据来说(比如在源代码中定义的.data?段),没必要为它们在磁盘文件中预留空间,只要在可执行文件被装载到内存中后为它们分配空间就可以了,所以包含未初始化数据的节在磁盘文件中的长度被定义为0,但是被装载到内存中的地址和大小是被明确指定的。对于这种节来说,它所包含的内存页并没有磁盘文件内容与之对应,这些内存页是Windows装载器根据节的定义额外开辟出来的。
● 不进行映射的节
有些节中包含的数据仅仅在装载的时候用到,当文件装载完毕的时候,它们不会被递交到物理内存页。最典型的例子就是包含重定位数据的节(如图17.2中的.reloc节),重定位数据对于文件的执行代码来说是透明的,它只供Windows装载器使用,执行代码根本不会去访问它们,一旦装载完毕,继续为它们提交内存页是一种浪费。所以这些节存在于磁盘文件中,但并不会被映射到内存中。
2.节表
PE文件中所有节的属性都被定义在节表中,节表由一系列的IMAGE_SECTION_HEADER结构排列而成,每个结构用来描述一个节,结构的排列顺序和它们描述的节在文件中的排列顺序是一致的。
节表总是被存放在紧接在PE文件头的地方,也就是从PE文件头(注意:不是文件本身的头部)开始的偏移为00f 8h的地方。节表中IMAGE_SECTION_HEADER结构的总数由PE文件头IMAGE_NT_HEADERS结构中的FileHeader.NumberOfSections字段指定。
IMAGE_SECTION_HEADER结构的定义如下:
IMAGE_SECTION_HEADER STRUCTName1 db IMAGE_SIZEOF_SHORT_NAME dup(?) ;8个字节的节区名称union MiscPhysicalAddress dd ?VirtualSize dd ? ;节区的尺寸endsVirtualAddress dd ? ;节区的RVA地址SizeOfRawData dd ? ;在文件中对齐后的尺寸PointerToRawData dd ? ;在文件中的偏移PointerToRelocations dd ? ;在OBJ文件中使用PointerToLinenumbers dd ? ;行号表的位置(供调试用)NumberOfRelocations dw ? ;在OBJ文件中使用NumberOfLinenumbers dw ? ;行号表中行号的数量Characteristics dd ? ;节的属性
IMAGE_SECTION_HEADER ENDS结构中的有些字段是供COFF格式的obj文件使用的,对可执行文件来说不代表任何意义,在分析的时候可以不予理会,真正有用的几个字段说明如下。
● Name1字段
这个字段的字段名原来应该是“Name”,但是这个名称和MASM中的关键字冲突,所以在定义的时候改为“Name1”,Name1字段定义了节的名称,字段的长度为8个字节。
PE文件中的节的名称是一个由ANSI字符组成的字符串,但并没有规定以0结束,如果节的名称字符串长度小于8个字节的话,后面以0补齐,但是字符串长度达到8个字节的话,后面就没有0字符了,所以在处理的时候要注意字符串的结束方式。
每个节的名称是唯一的,不能有同名的两个节,但是节的名称不代表任何含义,它仅仅是为了查看方便而设置的一个标记而已,可以选择任何名称甚至将它空着也可以,将包含代码的节命名为“DATA”或者将包含数据的节命名为“CODE”都是合法的。
各种编译器都以自己的方式对节进行命名,所以,在PE文件中可以看到各式各样的节名称,比如,在MASM32产生的可执行文件中,代码节被命名为“.text”;可读写的数据节被命名为“.data”;包含只读数据、导入表以及导出表的节被命名为“.rdata”;而资源节被命名为“.rsrc”等。但是在其他一些编译器中,导入表被单独放在“.idata”中;而代码节可能被命名为“.code”。
当从PE文件中读取需要的节时,不能以节的名称作为定位标准,正确的方法是按照IMAGE_OPTIONAL_HEADER32结构中的数据目录字段定位。
笔者曾看过一篇介绍如何存取PE文件资源的文章,其中用查找“.rsrc”节的方法得到资源,虽然大部分情况下用这种方法也可以正确地找到资源,但是严格地讲,只有数据目录的IMAGE_DIRECTORY_ENTRY_RESOURCE项才永远正确地指向资源数据。
● VirtualSize字段
代表节的大小,这是节的数据在没有进行对齐处理前的实际大小。
● VirtualAddress字段
指出节被装载到内存中后的偏移地址,这是一个RVA地址。这个地址是按照内存页对齐的,它的数值总是SectionAlignment的值的整数倍。
● PointerToRawData字段
指出节在磁盘文件中的所处的位置。这个数值是从文件头开始算起的偏移量。
● SizeOfRawData字段
指出节在磁盘文件中所占的空间大小,这个数值等于VirtualSize字段的值按照FileAlignment的值对齐以后的大小。
依靠这4个字段的值,装载器就可以从PE文件中找出某个节(从PointerToRawData偏移开始的SizeOfRawData字节)的数据,并将它映射到内存中去(映射到从模块基地址开始偏移VirtualAddress的地方,并占用以VirtualSize的值按照页的尺寸对齐后的空间大小)。
● Characteristics字段
这是节的属性标志字段,其中的不同数据位代表了不同的属性,具体的定义如表17.5所示,这些数据位组合起来描述了节的属性。
表17.5 节的属性标志位含义

代码节的属性一般为60000020h,也就是可执行、可读和“节中包含代码”;数据节的属性一般为c0000040h,也就是可读、可写和“包含已初始化数据”;而常量节(对应源代码中的.const段)的属性为40000040h,也就是可读和“包含已初始化数据”;资源节的属性和常量节的属性一般是相同的。
当然节属性的定义不一定就是这些值,比如,当PE文件被压缩工具压缩以后,包含代码的节往往被同时设置了可执行、可读和可写属性,因为解压部分需要将解压后的代码回写到代码段中。读者可以做个实验:在程序中往代码段写数据,编译链接完成后执行一下肯定会引发异常,然而用Upx等压缩软件压缩后再执行,就会发现文件可以正常执行了,这就是因为压缩软件为了解压的需要而将节的属性设置为可写了。
3.RVA和文件偏移的转换
在前面的内容中已经多次提到“RVA”一词,对于初次接触PE文件的读者来说,RVA是个比较费解的概念,特别是在一开始就去接触RVA的情况下。RVA的概念是和PE文件从磁盘到内存的映射息息相关的,在了解了这方面的内容后,再来看RVA就不成问题了。
RVA是相对虚拟地址(Relative Virtual Address)的缩写,顾名思义,它是一个“相对”地址,也可以说是“偏移量”,PE文件的各种数据结构中涉及地址的字段大部分都是以RVA表示的。
准确地说,RVA就是当PE文件被装载到内存中后,某个数据的位置相对于文件头的偏移量。举个例子,如果Windows装载器将一个PE文件装入00400000h处的内存中,而某个节中的某个数据被装入0040xxxxh处,那么这个数据的RVA就是(0040xxxxh-00400000h)=xxxxh,反过来说,将RVA的值加上文件被装载的基地址,就可以找到数据在内存中的实际地址。
很明显,PE文件中出现RVA的概念是因为PE的内存映像和磁盘文件映像是不同的,如图17.3中的A和A'所示,同一数据相对于文件头的偏移量在内存中和在磁盘文件中可能是不同的,为了提高效率,PE文件头中使用的都是内存映像中的偏移量,也就是RVA。从图17.3中也可以得到另一个结论,那就是RVA仅仅是对于处于节中的数据而言的,对于文件头和节表来说无所谓RVA和文件偏移,因为它们在被映射到内存中后不管是大小还是偏移都不会有任何改变。
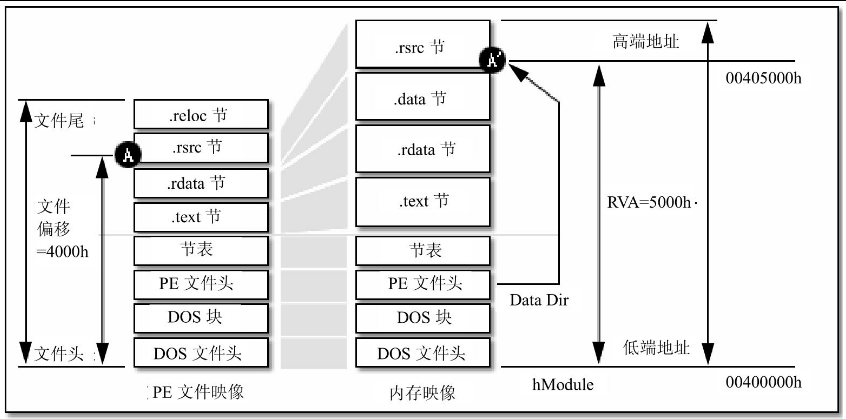
图17.3 RVA的含义
使用RVA,使文件装入内存后的数据定位变得方便,然而却给处理磁盘上的静态PE文件带来了很大的麻烦,举例来说,假如要读取PE文件中的资源(如图17.3中的A所示),第一个步骤就是从PE文件头的数据目录中访问第3个IMAGE_DATA_DIRECTORY结构,并从结构中得到资源所处的偏移量,但是这样得到的偏移量是个RVA,它只能用于在内存中查找由A'位置所指示的资源。用它直接在磁盘文件中定位A位置是错误的。
当处理PE文件时,任何的RVA必须经过到文件偏移的换算,才能用来定位并访问文件中的数据,但换算却无法用一个简单的公式来完成,事实上,唯一可用的方法就是最土最笨的方法:
(1)循环扫描节表并得到每个节在内存中的起始RVA(根据VirtualAddress字段),并根据节的大小(SizeOfRawData字段)算出节的结束RVA,最后比较判断目标RVA是否落在某个节之内。
(2)如果目标RVA处于某个节之内,那么用目标RVA减去节的起始RVA,这样就得到了目标RVA相对于节起始地址的偏移量RVA'。
(3)在节表中获取节在文件中所处的偏移(PointerToRawData字段),将这个偏移值加上上一步得到的RVA'值,这才是数据在文件中的真正偏移位置。
这里是两个通用的函数,其中_RVAToOffset函数将RVA转换成文件偏移,输入的参数是已经读取到内存中的文件头的地址和RVA的值;_GetRVASection函数用来获取RVA所在的节的名称。这两个函数被保存在_RvaToFileOffset.asm文件中,并将在以后的例子中用到,函数中使用的算法就是上面3个步骤中列出的算法。
.const
szNotFound db '无法查找',0
.code
;>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
; 将RVA转换成文件偏移
;>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
_RVAToOffset proc _lpFileHead,_dwRVAlocal @dwReturnpushadmov esi,_lpFileHeadassume esi:ptr IMAGE_DOS_HEADERadd esi,[esi].e_lfanew
;-------------------------------------------------------------------
; 得到PE文件头的位置,这个位置加上文件头长度就是节表的位置
;-------------------------------------------------------------------assume esi:ptr IMAGE_NT_HEADERSmov edi,_dwRVAmov edx,esiadd edx,sizeof IMAGE_NT_HEADERSassume edx:ptr IMAGE_SECTION_HEADERmovzx ecx,[esi].FileHeader.NumberOfSections
;-------------------------------------------------------------------
; 扫描每个节并判断RVA是否位于这个节内
;--------------------------------------------------------------------.repeatmov eax,[edx].VirtualAddressadd eax,[edx].SizeOfRawData.if (edi >= [edx].VirtualAddress) && (edi < eax)mov eax,[edx].VirtualAddresssub edi,eaxmov eax,[edx].PointerToRawDataadd eax,edijmp @F.endifadd edx,sizeof IMAGE_SECTION_HEADER.untilcxzassume edx:nothingassume esi:nothingmov eax,-1
@@:mov @dwReturn,eaxpopadmov eax,@dwReturnret
_RVAToOffset endp
;>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
; 获取RVA所在的节的名称
;>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
_GetRVASection proc _lpFileHead,_dwRVAlocal @dwReturnpushadmov esi,_lpFileHeadassume esi:ptr IMAGE_DOS_HEADERadd esi,[esi].e_lfanewassume esi:ptr IMAGE_NT_HEADERSmov edi,_dwRVAmov edx,esiadd edx,sizeof IMAGE_NT_HEADERSassume edx:ptr IMAGE_SECTION_HEADERmovzx ecx,[esi].FileHeader.NumberOfSections
;---------------------------------------------------------------------
; 扫描每个节区并判断RVA是否位于这个节内
;---------------------------------------------------------------------.repeatmov eax,[edx].VirtualAddressadd eax,[edx].SizeOfRawData.if (edi >= [edx].VirtualAddress) && (edi < eax)mov eax,edx.endifjmp @Fadd edx,sizeof IMAGE_SECTION_HEADER.untilcxzassume edx:nothingassume esi:nothingmov eax,offset szNotFound
@@:mov @dwReturn,eaxpopadmov eax,@dwReturnret
_GetRVASection endp
;>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
4.PEInfo例子
好了,到现在为止,相信读者对PE文件的结构应该有初步的了解了,现在尝试写一个程序来查看PE文件的一些信息,并列出所有节的名称和属性。例子代码在本书所附光盘的Chapter17\PeInfo目录中,其中包括资源文件Main.rc,界面源代码Main.asm和处理分析PE文件的源代码_ProcessPeFile.asm。为了节省篇幅,本章以后的几个例子中都将使用同样的界面文件Main.asm和Main.rc,只是处理PE文件的代码_ProcessPeFile.asm有所不同。
通用的界面资源文件Main.rc定义如下:
//>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
#include <resource.h>
//>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
#define ICO_MAIN 1000
#define DLG_MAIN 1000
#define IDC_INFO 1001
#define IDM_MAIN 2000
#define IDM_OPEN 2001
#define IDM_EXIT 2002
//>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
ICO_MAIN ICON "Main.ico"
//>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
DLG_MAIN DIALOG 50, 50, 250, 140
STYLE DS_MODALFRAME | WS_POPUP | WS_VISIBLE | WS_CAPTION | WS_SYSMENU
CAPTION "PE文件基本信息"
MENU IDM_MAIN
FONT 9, "宋体"
{
CONTROL "", IDC_INFO, "RichEdit20A", 196 | ES_WANTRETURN | WS_CHILD | ES_READONLY| WS_VISIBLE | WS_BORDER | WS_VSCROLL | WS_TABSTOP, 0, 0, 249, 140
}
//>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
IDM_MAIN menu discardable
BEGINpopup "文件(&F)"BEGINmenuitem "打开文件(&O)...", IDM_OPENmenuitem separatormenuitem "退出(&X)", IDM_EXITEND
END
//>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
文件中定义了一个作为主窗口的对话框,对话框上定义了一个菜单以及用来输出信息的RichEdit控件,实际运行的效果如图17.4所示。
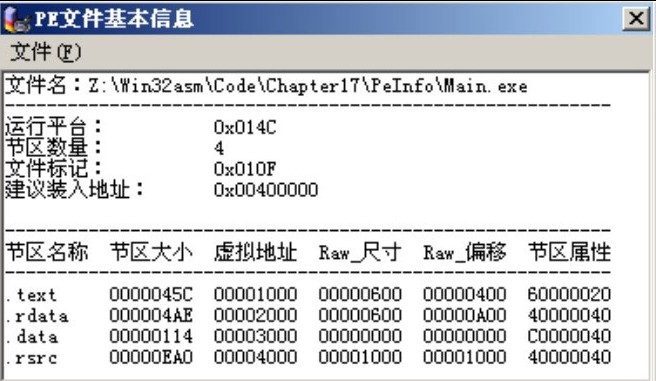
图17.4 PEInfo例子的实际运行界面
处理界面的汇编源文件Main.asm的内容如下:
; Main.asm ---- PE 文件操作演示的主程序,提供对话框界面和文件打开功能
;--------------------------------------------------------------------
; 使用 nmake 或下列命令进行编译和链接:
; ml /c /coff Main.asm
; rc Main.rc
; Link /subsystem:windows Main.obj Main.res
.386
.model flat,stdcall
option casemap:none ; include 文件定义
include c:/masm32/include/windows.inc
include c:/masm32/include/user32.inc
includelib c:/masm32/lib/user32.lib
include c:/masm32/include/kernel32.inc
includelib c:/masm32/lib/kernel32.lib
include c:/masm32/include/comdlg32.inc
includelib c:/masm32/lib/comdlg32.lib ; equ 等值定义
ICO_MAIN equ 1000
DLG_MAIN equ 1000
IDC_INFO equ 1001
IDM_MAIN equ 2000
IDM_OPEN equ 2001
IDM_EXIT equ 2002 ; 数据段
.data?
hInstance dword ?
hRichEdit dword ?
hWinMain dword ?
hWinEdit dword ?
szFileName byte MAX_PATH dup(?).const
szDllEdit byte 'RichEd20.dll',0
szClassEdit byte 'RichEdit20A',0
szFont byte '宋体',0
szExtPe byte 'PE Files',0,'*.exe;*.dll;*.scr;*.fon;*.drv',0byte 'All Files(*.*)',0,'*.*',0,0
szErr byte '文件格式错误!',0
szErrFormat byte '这个文件不是PE格式的文件!',0; 代码段
.code
_AppendInfo proc _lpsz local @stCR:CHARRANGE pushad invoke GetWindowTextLength, hWinEdit mov @stCR.cpMin, eax mov @stCR.cpMax, eax invoke SendMessage, hWinEdit, EM_EXSETSEL, 0, addr @stCR invoke SendMessage, hWinEdit, EM_REPLACESEL, FALSE, _lpsz popad ret
_AppendInfo endp include _ProcessPeFile.asm _Init proc local @stCf:CHARFORMAT invoke GetDlgItem, hWinMain, IDC_INFO mov hWinEdit, eax invoke LoadIcon, hInstance, ICO_MAIN invoke SendMessage, hWinMain, WM_SETICON, ICON_BIG, eax invoke SendMessage, hWinEdit, EM_SETTEXTMODE, TM_PLAINTEXT, 0 invoke RtlZeroMemory, addr @stCf, sizeof @stCf mov @stCf.cbSize, sizeof @stCf mov @stCf.yHeight, 9 * 20 mov @stCf.dwMask, CFM_FACE or CFM_SIZE or CFM_BOLD invoke lstrcpy, addr @stCf.szFaceName, addr szFont invoke SendMessage, hWinEdit, EM_SETCHARFORMAT, 0, addr @stCf invoke SendMessage, hWinEdit, EM_EXLIMITTEXT, 0, -1 ret
_Init endp ; 错误 Handler
_Handler proc C _lpExceptionRecord, _lpSEH, _lpContext, _lpDispatcherContext pushad mov esi, _lpExceptionRecord mov edi, _lpContext assume esi:ptr EXCEPTION_RECORD, edi:ptr CONTEXT mov eax, _lpSEH push [eax + 0ch]pop [edi].regEbp push [eax+8]pop [edi].regEip push eax pop [edi].regEsp assume esi:nothing, edi:nothing popad mov eax, ExceptionContinueExecution ret
_Handler endp _OpenFile proc local @stOF:OPENFILENAME local @hFile, @dwFileSize, @hMapFile, @lpMemory invoke RtlZeroMemory, addr @stOF, sizeof @stOF mov @stOF.lStructSize, sizeof @stOF push hWinMain pop @stOF.hwndOwner mov @stOF.lpstrFilter, offset szExtPe mov @stOF.lpstrFile, offset szFileName mov @stOF.nMaxFile, MAX_PATH mov @stOF.Flags, OFN_PATHMUSTEXIST or OFN_FILEMUSTEXIST invoke GetOpenFileName, addr @stOF .if !eax jmp @F .endif ;打开文件并建立文件 Mappinginvoke CreateFile, addr szFileName, GENERIC_READ, FILE_SHARE_READ or \FILE_SHARE_WRITE, NULL, OPEN_EXISTING, FILE_ATTRIBUTE_ARCHIVE, NULL .if eax != INVALID_HANDLE_VALUE mov @hFile, eax invoke GetFileSize, eax, NULL mov @dwFileSize, eax .if eax invoke CreateFileMapping, @hFile, NULL, PAGE_READONLY, 0, 0, NULL .if eax mov @hMapFile, eax invoke MapViewOfFile, eax, FILE_MAP_READ, 0, 0, 0.if eax mov @lpMemory, eax ;创建用于错误处理的 SEH 结构assume fs:nothing push ebp push offset _ErrFormat push offset _Handler push fs:[0]mov fs:[0], esp ;检测 PE 文件是否有效mov esi, @lpMemory assume esi:ptr IMAGE_DOS_HEADER .if [esi].e_magic != IMAGE_DOS_SIGNATURE jmp _ErrFormat .endif add esi, [esi].e_lfanew assume esi:ptr IMAGE_NT_HEADERS .if [esi].Signature != IMAGE_NT_SIGNATURE jmp _ErrFormat .endif invoke _ProcessPeFile, @lpMemory, esi, @dwFileSize jmp _ErrorExit
_ErrFormat: invoke MessageBox, hWinMain, addr szErrFormat, NULL, MB_OK
_ErrorExit:pop fs:[0]add esp, 0ch invoke UnmapViewOfFile, @lpMemory .endif invoke CloseHandle, @hMapFile .endif invoke CloseHandle, @hFile .endif .endif
@@:ret
_OpenFile endp _ProcDlgMain proc uses ebx edi esi hWnd, wMsg, wParam, lParam mov eax, wMsg .if eax == WM_CLOSE invoke EndDialog, hWnd, NULL .elseif eax == WM_INITDIALOG push hWnd pop hWinMain call _Init .elseif eax == WM_COMMAND mov eax, wParam .if ax == IDM_OPEN call _OpenFile .elseif ax == IDM_EXIT invoke EndDialog, hWnd, NULL .endif .else mov eax, FALSE ret .endif mov eax, TRUE ret
_ProcDlgMain endp ;main函数
main proc invoke LoadLibrary, offset szDllEdit mov hRichEdit, eax invoke GetModuleHandle, NULL mov hInstance, eax invoke DialogBoxParam, hInstance, DLG_MAIN, NULL, offset _ProcDlgMain, NULL invoke FreeLibrary, hRichEdit invoke ExitProcess, NULL
main endp
end main 源代码中没有任何新的概念:程序首先创建一个对话框,并在初始化的时候将RichEdit控件的字体设置为“宋体”。当用户选择“打开”文件菜单后,则显示一个打开文件通用对话框让用户选择一个文件。
最后,程序用内存映射文件的方法将PE文件映射到内存中以供处理,处理使用的代码就是根据具体的情况编写的_ProcessPeFile.asm文件。
在处理文件之前,程序使用第14章中介绍的SEH来设置一个异常处理回调函数,一旦发生异常的话,则将程序转移到_ErrFormat标号处执行并认为文件的格式存在异常。由于PE文件的分析中涉及很多指针操作,对任何一个指针都进行检测并判断它们是否已经越出了内存映射文件的范围是很麻烦的,使用SEH可以让这方面的工作开销最少。
当一切准备就绪后,程序要简单地判断一下打开的文件是否是一个合法的PE文件,详见下面的一段代码:
assume esi:ptr IMAGE_DOS_HEADER
.if [esi].e_magic != IMAGE_DOS_SIGNATUREjmp _ErrFormat
.endif
add esi,[esi].e_lfanew
assume esi:ptr IMAGE_NT_HEADERS
.if [esi].Signature != IMAGE_NT_SIGNATUREjmp _ErrFormat
.endif
invoke _ProcessPeFile, @lpMemory, esi, @dwFileSizeesi一开始被指向文件的头部,程序首先判断DOS文件头中的标识符是否和“MZ”(也就是IMAGE_DOS_SIGNATURE)符合,如果符合的话,那么从003ch处(也就是e_lfanew字段)取出PE文件头的偏移,并比较PE文件头的标识是否为IMAGE_NT_SIGNATURE,这两个步骤都通过的话,那么几乎可以认定这是一个合法的PE文件了,程序就真正开始分析工作——调用_ProcessPeFile.asm文件中的_ProcessPeFile子程序。
_ProcessPeFile.asm文件的内容如下所示:
; Peinfo 例子的 PE文件处理模块
.const
szMsg byte '文件名:%s',0dh,0ahbyte '----------------------------------------------------------',0dh,0ahbyte '运行平台: 0x%04X',0dh,0ahbyte '节区数量: %d',0dh,0ahbyte '文件标记: 0x%04X',0dh,0ahbyte '建议装入地址: 0x%08X',0dh,0ah,0ah,0
szMsgSection byte '----------------------------------------------------------',0dh,0ahbyte '节区名称 节区大小 虚拟地址 Raw_尺寸 Raw_偏移 节区属性',0dh,0ahbyte '----------------------------------------------------------',0dh,0ah,0
szFmtSection byte '%s %08X %08X %08X %08X %08X',0dh,0ah,0.code
_ProcessPeFile proc _lpFile, _lpPeHead, _dwSize local @szBuffer[1024]:byte, @szSectionName[16]:byte pushad mov edi, _lpPeHead assume edi:ptr IMAGE_NT_HEADERS ;显示 PE 文件头中的一些信息movzx ecx, [edi].FileHeader.Machine movzx edx, [edi].FileHeader.NumberOfSections movzx ebx, [edi].FileHeader.Characteristics invoke wsprintf, addr @szBuffer, addr szMsg, \addr szFileName, ecx, edx, ebx, \[edi].OptionalHeader.ImageBase invoke SetWindowText, hWinEdit, addr @szBuffer ;循环显示每个节区的信息invoke _AppendInfo, addr szMsgSection movzx ecx, [edi].FileHeader.NumberOfSections add edi, sizeof IMAGE_NT_HEADERS assume edi:ptr IMAGE_SECTION_HEADER .repeat push ecx ;节区名称invoke RtlZeroMemory, addr @szSectionName, sizeof @szSectionName push esi push edi mov ecx, 8 mov esi, edi lea edi, @szSectionNamecld @@:lodsb .if !al mov al, ' '.endif stosb loop @B pop edi pop esi invoke wsprintf, addr @szBuffer, addr szFmtSection, \addr @szSectionName, [edi].Misc.VirtualSize, \[edi].VirtualAddress, [edi].SizeOfRawData, \[edi].PointerToRawData, [edi].Characteristics invoke _AppendInfo, addr @szBuffer add edi, sizeof IMAGE_SECTION_HEADER pop ecx .untilcxz assume edi:nothing popad ret
_ProcessPeFile endp
程序首先显示了PE文件头中一些重要字段的数值,如Machine,NumberOfSections和Characteristics等字段,然后根据NumberOfSections的数值构造一个循环,并在循环中显示每个节的信息。
在子程序开始的地方,edi寄存器被赋值为PE文件头指针,当在循环开始前将edi加上IMAGE_NT_HEADERS结构的长度后,edi指向的就是节表的起始地址了,使用edi作指针就可以将每个节的名称、尺寸、RVA地址、在文件中的偏移以及大小显示出来。
读者可以用这个PEInfo程序打开不同的文件来验证一下本节中叙述的一些内容,并思考下面的问题,由此可以印证很多本节中讲述的内容:
(1)比较EXE文件和DLL文件的Characteristics字段的差异。
(2)EXE文件往往没有重定位节(一般名称为.reloc),而DLL文件中总是有这个节。
(3)看看代码节和数据节的属性有什么不同,再查看第11章中KeyHook例子中的DLL文件,看看包含共享数据的节的属性又有什么不同。
(4)编写一个有.data?段却没有.data段的程序并用PEInfo去查看,可以发现数据节在磁盘文件中的长度为0,但是被映射到内存中以后却不为0。
17.2 导入表
在开始下面几节的介绍前,先来复习一下17.1节中提出的两个概念。
首先,PE文件中的数据按照装入内存后的页面属性被划分成多个节,并由节表中的数据来描述这些节。一个节中的数据仅仅是属性相同而已,并不一定就是同一种用途的,比如导入表、导出表等就有可能和只读常量一起被放在同一个节中,因为它们的属性同是可读不可写的。
其次,由于不同用途的数据可能被放在同一个节中,仅仅依靠节表是无法确定它们的存放位置的,PE文件中依靠文件头中MAGE_OPTIONAL_HEADER32结构内的数据目录表来指出它们的位置,可以由数据目录表来定位的数据包括导入表、导出表、资源、重定位表和ITLS等15种数据。
好了,现在要引出这几节将要讲述的内容了:从数据目录表得到的仅仅是这些数据的RVA和数据块的尺寸,很明显,不同的数据块中的数据组织方式是不同的,比如导入表和资源数据块中的数据就完全是两码事情,要想深入了解PE文件就必须了解这些数据的组织方式,以及系统是如何处理它们的,这就是本节以及下面几节的内容。
本节将首先介绍导入表的格式,下面的几节将逐一介绍导出表、资源和重定位表的格式和使用方法。
17.2.1 导入表简介
在Win32编程中常常用到“导入函数”(Import functions),导入函数就是被程序调用但其执行代码又不在程序中的函数,这些函数的代码位于一个或者多个DLL中,在调用者程序中只保留一些函数信息,包括函数名及其驻留的DLL名等。
对于存储在磁盘上的PE文件来说,它无法得知这些导入函数会在内存的哪个地方出现,只有当PE文件被装入内存的时候,Windows装载器才将DLL装入,并将调用导入函数的指令和函数实际所处的地址联系起来,这就是“动态链接”的概念。动态链接是通过PE文件中定义的“导入表”(Import Table)来完成的,导入表中保存的正是函数名和其驻留的DLL名等动态链接所必需的信息。
1.调用导入函数的指令
程序被执行的时候是怎样使用导入函数的呢?先将第3章中那个简单的Hello World程序反汇编一把,看看调用导入函数的指令都是什么样子的,需要反汇编的两句源代码如下:
invoke MessageBox,NULL,offset szText,offset szCaption,MB_OK
invoke ExitProcess,NULL当使用W32Dasm反汇编以后,这两句代码变成了以下的指令:
:00401000 6A00 push 00000000
:004010026800304000 push 00403000
:00401007680F304000 push 0040300F
:0040100C 6A00 push 00000000
:0040100E E807000000 Call 0040101A ;MessageBox
:00401013 6A00 push 00000000
:00401015 E806000000 Call 00401020 ;ExitProcess
:0040101A FF2508204000 Jmp dword ptr [00402008]
:00401020 FF2500204000 Jmp dword ptr [00402000]反汇编后,对MessageBox和ExitProcess函数的调用变成了对0040101A和00401020地址的调用,但是这两个地址显然是位于程序自身模块而不是在DLL模块中的,实际上,这是由编译器在程序所有代码的后面自动加上的Jmp dword ptr [xxxxxxxx]类型的指令,这个指令是一个间接寻址的跳转指令,xxxxxxxx地址中存放的才是真正的导入函数的地址。在这个例子中,00402000地址处存放的就是ExitProcess函数的地址。
那么在没有装载到内存之前,PE文件中的00402000地址处的内容是什么呢?使用在17.1.4节中了解的方法来查看一下。
首先,使用17.1.4节的例子文件PEInfo.exe去查看一下Hello.exe文件,会得到以下的信息:
文件名:C:\Documents and Settings\Administrator\桌面\Hello.exe
----------------------------------------------------------
运行平台: 0x014C
节区数量: 3
文件标记: 0x010F
建议装入地址: 0x00400000
----------------------------------------------------------
节区名称 节区大小 虚拟地址 Raw_尺寸 Raw_偏移 节区属性
----------------------------------------------------------
.text 00000026 00001000 00000200 00000400 60000020
.rdata 00000092 00002000 00000200 00000600 40000040
.data 00000022 00003000 00000200 00000800 C0000040由于建议装入地址是00400000h,所以00402000h地址实际上处于RVA为2000h的地方,再看看各个节的虚拟地址,可以发现2000h开始的地方位于.rdata节内,而这个节的Raw_偏移项目为600h,也就是说00402000h地址的内容实际上对应PE文件中偏移600h处的数据。
现在随便找一个十六进制编辑器来看看文件0600h处的内容是什么:
0600 76 20 00 00 00 00 00 00-5C 20 00 00 00 00 00 00 v ......\ ......
0610 54 20 00 00 00 00 00 00-00 00 00 00 6A 20 00 00 T ..........j ..
0620 08 20 00 00 4C 20 00 00-00 00 00 00 00 00 00 00 . ..L ..........
0630 84 20 00 00 00 20 00 00-00 00 00 00 00 00 00 00 . ... ..........
0640 00 00 00 00 00 00 00 00-00 00 00 00 76 20 00 00 ............v ..
0650 00 00 00 00 5C 20 00 00-00 00 00 00 BB 01 4D 65 ....\ ........Me
0660 73 73 61 67 65 42 6F 78-41 00 55 53 45 52 33 32 ssageBoxA.USER32
0670 2E 64 6C 6C 00 00 75 00-45 78 69 74 50 72 6F 63 .dll..u.ExitProc
0680 65 73 73 00 4B 45 52 4E-45 4C 33 32 2E 64 6C 6C ess.KERNEL32.dll
0690 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 ................查看的结果是00002076h,这显然不会是内存中的ExitProcess函数的地址,慢着!将它作为RVA看会怎么样呢?查看节表可以发现RVA地址00002076h也处于.rdata节内,减去节的起始地址00002000h后得到这个RVA相对于节首的偏移是76h,也就是说它对应文件0676h开始的地方,接下来可以惊奇地发现,0676h再过去两个字节的内容正是函数名字符串“ExitProcess”!
这都有点搞糊涂了,Call ExitProcess指令被编译成了Call aaaaaaaa类型的指令,而aaaaaaaa处的指令是Jmp dword ptr [xxxxxxxx],而xxxxxxxx地址的地方只是一个似乎是指向函数名字符串的RVA地址,这一系列的指令显然是无法正确执行的!
但如果告诉你,当PE文件被装载的时候,Windows装载器会根据xxxxxxxx处的RVA得到函数名,再根据函数名在内存中找到函数地址,并且用函数地址将xxxxxxxx处的内容替换成真正的函数地址,那么所有的疑惑就迎刃而解了。
接下来看看如何去获取导入表的位置,以及导入表中的数据是如何组织以便Windows装载器能够顺利地进行上面的转换工作的。
2.获取导入表的位置
导入表的位置和大小可以从PE文件头中IMAGE_OPTIONAL_HEADER32结构的数据目录字段中获取,对应的项目是DataDirectory字段的第2个IMAGE_DATA_DIRECTORY结构(如表17.4所示)。
从IMAGE_DATA_DIRECTORY结构的VirtualAddress字段得到的是导入表的RVA值,如果在内存中查找导入表,那么将RVA值加上PE文件装入的基址就是实际的地址;如果在PE文件中查找导入表,那么需要首先使用17.1.4节中例举的_RVAToOffset子程序将RVA首先转换成文件偏移。
17.2.2 导入表的结构
1.PE文件中的导入表
现在得到了包含导入表的数据块,导入表由一系列的IMAGE_IMPORT_DESCRIPTOR结构组成,结构的数量取决于程序要使用的DLL文件的数量,每个结构对应一个DLL文件,例如,如果一个PE文件从10个不同的DLL文件中引入了函数,那么就存在10个IMAGE_IMPORT_DESCRIPTOR结构来描述这些DLL文件,在所有这些结构的最后,由一个内容全为0的IMAGE_IMPORT_DESCRIPTOR结构作为结束。
IMAGE_IMPORT_DESCRIPTOR结构的定义如下:
IMAGE_IMPORT_DESCRIPTOR STRUCTunionCharacteristics dd ?OriginalFirstThunk dd ?endsTimeDateStamp dd ?ForwarderChain dd ?Name1 dd ?FirstThunk dd ?
IMAGE_IMPORT_DESCRIPTOR ENDS结构中的Name1字段(使用Name1作为字段名同样是因为Name一词和MASM的关键字冲突)是一个RVA,它指向此结构所对应的DLL文件的名称,这个文件名是一个以NULL结尾的字符串。
OriginalFirstThunk字段和FirstThunk字段的含义现在可以看成是相同的(使用“现在”一词的含义马上会见分晓),它们都指向一个包含一系列IMAGE_THUNK_DATA结构的数组,数组中的每个IMAGE_THUNK_DATA结构定义了一个导入函数的信息,数组的最后以一个内容为0的IMAGE_THUNK_DATA结构作为结束。
一个IMAGE_THUNK_DATA结构实际上就是一个双字,之所以把它定义成结构,是因为它在不同的时刻有不同的含义,结构的定义如下:
IMAGE_THUNK_DATA STRUCTunion u1ForwarderString dd ?Function dd ?Ordinal dd ?AddressOfData dd ?ends
IMAGE_THUNK_DATA ENDS一个IMAGE_THUNK_DATA结构如何用来指定一个导入函数呢?当双字(就是指结构!)的最高位为1时,表示函数是以序号的方式导入的,这时双字的低位就是函数的序号。读者可以用预定义值IMAGE_ORDINAL_FLAG32(或80000000h)来对最高位进行测试,当双字的最高位为0时,表示函数以字符串类型的函数名方式导入,这时双字的值是一个RVA,指向一个用来定义导入函数名称的IMAGE_IMPORT_BY_NAME结构,此结构的定义如下:
IMAGE_IMPORT_BY_NAME STRUCTHint dw ?Name1 db ?
IMAGE_IMPORT_BY_NAME ENDS结构中的Hint字段也表示函数的序号,不过这个字段是可选的,有些编译器总是将它设置为0,Name1字段定义了导入函数的名称字符串,这是一个以0为结尾的字符串。
整个过程听起来有些复杂,其实以图17.5来说明就很清楚了,图中示意了可执行文件导入了Kernel32.dll中的ExitProcess,ReadFile,WriteFile和一个以序号为导入方式的函数(姑且称这个函数为ImportByNo)的情况,假设这4个函数的序号分别是02f6h,0111h,002bh和0010h。
现在来分析一下图17.5中的示例,导入表中IMAGE_IMPORT_DESCRIPTOR结构的Name1字段指向字符串“Kernel32.dll”,表明当前要从Kernel32.dll文件中导入函数,OriginalFirstThunk和FirstThunk字段指向两个同样的IMAGE_THUNK_DATA数组,由于要导入的是4个函数,所以数组中包含4个有效项目并以最后一个内容为0的项目作为结束。
第4个函数是以序号导入的,与其对应的IMAGE_THUNK_DATA结构的最高位等于1,和函数的序号0010h组合起来的数值就是80000010h,其余的3个函数采用的是以函数名导入的方式,所以IMAGE_THUNK_DATA结构的数值是一个RVA,分别指向3个IMAGE_IMPORT_BY_NAME结构,每个IMAGE_IMPORT_BY_NAME结构的第一个字段是函数的序号,后面就是函数的字符串名称了,一切就是这么简单!
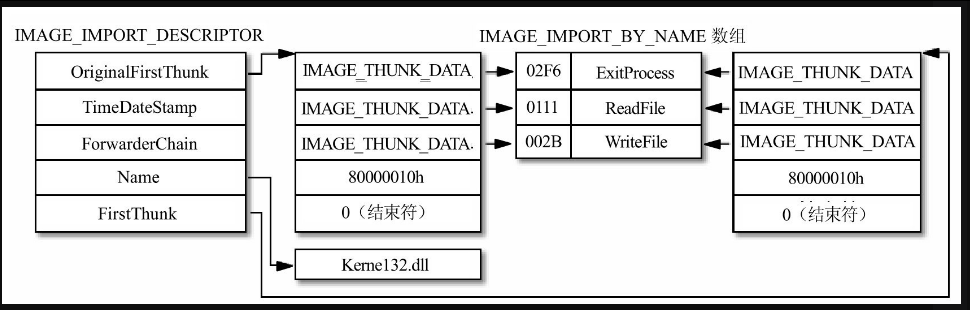
图17.5 函数的导入方法举例
2.内存中的导入表
为什么需要两个一模一样的IMAGE_THUNK_DATA数组呢?答案是当PE文件被装入内存的时候,其中一个数组的值将被改作他用,还记得前面分析Hello World程序时提到的吗?Windows装载器会将指令Jmp dword ptr [xxxxxxxx]指定的xxxxxxxx处的RVA替换成真正的函数地址,其实xxxxxxxx地址正是由FirstThunk字段指向的那个数组中的一员。
实际上,当PE文件被装入内存后,内存中的映像就被Windows装载器修正成了图17.6所示的样子,其中由FirstThunk字段指向的那个数组中的每个双字都被替换成了真正的函数入口地址,之所以在PE文件中使用两份IMAGE_THUNK_DATA数组的拷贝并修改其中的一份,是为了最后还可以留下一份拷贝用来反过来查询地址所对应的导入函数名。
3.导入地址表(IAT)
IMAGE_IMPORT_DESCRIPTOR结构中FirstThunk字段指向的数组最后会被替换成导入函数的真正入口地址,暂且把这个数组称为导入地址数组。在PE文件中,所有DLL对应的导入地址数组在位置上是被排列在一起的,全部这些数组的组合也被称为导入地址表(Import Address Table,或者简称为IAT),导入表中第一个IMAGE_IMPORT_DESCRIPTOR结构的FirstThunk字段指向的就是IAT的起始地址。
还有一个方法可以更方便地找到IAT的地址,那就是通过数据目录表。数据目录表中的第13项(索引值为12/ IMAGE_DIRECTORY_ENTRY_IAT)直接用来定义IAT数据块的位置和大小。
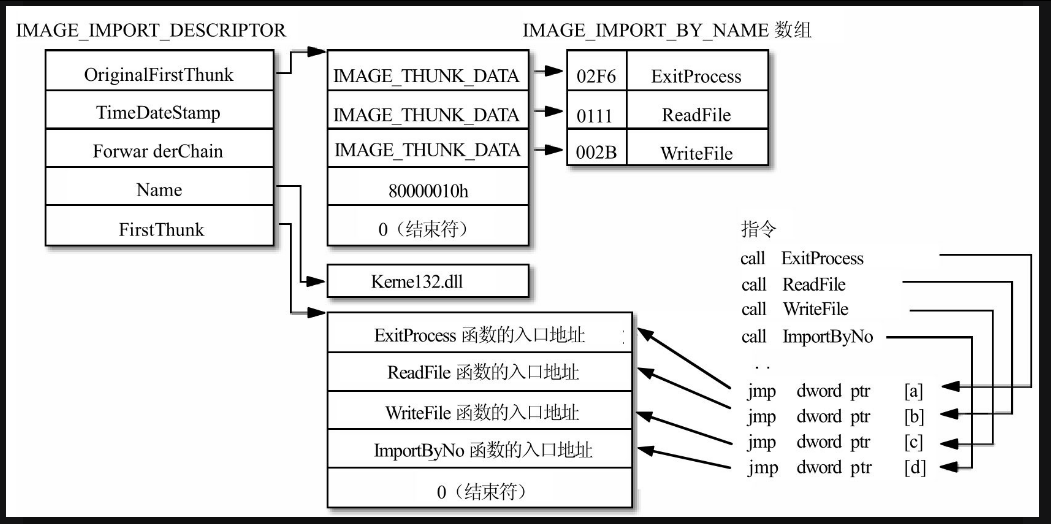
图17.6 导入表被装入内存后的样子
17.2.3 查看PE文件导入表举例
这里有一个查看PE文件所有导入函数信息的例子,例子的源代码在本书所附光盘的Chapter17\Import目录中,为了节省篇幅,例子的界面处理代码使用PEInfo例子中的Main.asm和Main.rc文件,只修改了其中的_ProcessPeFile.asm文件,另外,还使用了17.1.4节中例举的_RvaToFileOffset.asm文件。
; _RvaToFileOffset.asm .const
szNotFound byte '无法查找',0
.code
; 将 RVA 转换成实际的数据位置
_RVAToOffset proc _lpFileHead, _dwRVA local @dwReturn pushad mov esi, _lpFileHead assume esi:ptr IMAGE_DOS_HEADER add esi, [esi].e_lfanew assume esi:ptr IMAGE_NT_HEADERS mov edi, _dwRVA mov edx, esi add edx, sizeof IMAGE_NT_HEADERS assume edx:ptr IMAGE_SECTION_HEADER movzx ecx, [esi].FileHeader.NumberOfSections ;扫描每个节区并判断 RVA 是否位于这个节区内.repeat mov eax, [edx].VirtualAddress add eax, [edx].SizeOfRawData ;eax = Section End.if (edi >= [edx].VirtualAddress) && (edi < eax)mov eax, [edx].VirtualAddress ;eax= Section startsub edi, eax ;edi = offset in sectionmov eax, [edx].PointerToRawData add eax, edi ;eax = file offsetjmp @F .endif add edx, sizeof IMAGE_SECTION_HEADER .untilcxz assume edx:nothing assume esi:nothing mov eax, -1
@@:mov @dwReturn, eax popad mov eax, @dwReturn ret
_RVAToOffset endp ; 查找 RVA 所在的节区
_GetRVASection proc _lpFileHead, _dwRVA local @dwReturn pushad mov esi, _lpFileHead assume esi:ptr IMAGE_DOS_HEADER add esi, [esi].e_lfanew assume esi:ptr IMAGE_NT_HEADERS mov edi, _dwRVA mov edx, esi add edx, sizeof IMAGE_NT_HEADERS assume edx:ptr IMAGE_SECTION_HEADER movzx ecx, [esi].FileHeader.NumberOfSections ;扫描每个节区并判断 RVA 是否位于这个节区内.repeat mov eax, [edx].VirtualAddress add eax, [edx].SizeOfRawData ;eax = Section End.if (edi >= [edx].VirtualAddress) && (edi < eax)mov eax, edx ;eax= Section Namejmp @F .endif add edx, sizeof IMAGE_SECTION_HEADER .untilcxz assume edx:nothing assume esi:nothing mov eax, offset szNotFound
@@:mov @dwReturn, eax popad mov eax, @dwReturn ret
_GetRVASection endp _ProcessPeFile.asm文件的内容如下:
; _ProcessPeFile.asm ------- Import 例子的 PE文件处理模块
.const
szMsg byte '文件名: %s',0dh,0ahbyte '------------------------------------------------',0dh,0ahbyte '导入表所处的节:%s',0dh,0ah,0
szMsgImport byte 0dh,0ahbyte '------------------------------------------------',0dh,0ahbyte '导入库: %s',0dh,0ahbyte '------------------------------------------------',0dh,0ahbyte 'OriginalFirstThunk %08X',0dh,0ahbyte 'TimeDateStamp %08X',0dh,0ah byte 'ForwarderChain %08X',0dh,0ahbyte 'FirstThunk %08X',0dh,0ahbyte '------------------------------------------------',0dh,0ahbyte '导入序号 导入函数名称',0dh,0ahbyte '------------------------------------------------',0dh,0ah,0
szMsgName byte '%8u %s',0dh,0ah,0
szMsgOrdinal byte '%8u (按序号导入)',0dh,0ah,0
szErrNoImport byte '这个文件不使用任何导入函数',0.code
include _RvaToFileOffset.asm
_ProcessPeFile proc _lpFile, _lpPeHead, _dwSize local @szBuffer[1024]:byte, @szSectionName[16]:byte pushad mov edi, _lpPeHead assume edi:ptr IMAGE_NT_HEADERS mov eax, [edi].OptionalHeader.DataDirectory[8].VirtualAddress .if !eax invoke MessageBox, hWinMain, addr szErrNoImport, NULL, MB_OK jmp _Ret .endif invoke _RVAToOffset, _lpFile, eax add eax, _lpFile mov edi, eax assume edi:ptr IMAGE_IMPORT_DESCRIPTOR ;显示 PE 文件名invoke _GetRVASection, _lpFile, [edi].OriginalFirstThunk invoke wsprintf, addr @szBuffer, addr szMsg, addr szFileName, eax invoke SetWindowText, hWinEdit, addr @szBuffer ;循环处理 IMAGE_IMPORT_DESCRIPTOR 直到遇到全零的则结束.while [edi].OriginalFirstThunk || [edi].TimeDateStamp || \[edi].ForwarderChain || [edi].Name1 || [edi].FirstThunk invoke _RVAToOffset, _lpFile, [edi].Name1 add eax, _lpFile invoke wsprintf, addr @szBuffer, addr szMsgImport, eax, \[edi].OriginalFirstThunk, [edi].TimeDateStamp, \[edi].ForwarderChain, [edi].FirstThunk invoke _AppendInfo, addr @szBuffer ; 获取 IMAGE_THUNK_DATA 列表地址 ---> ebx.if [edi].OriginalFirstThunk mov eax, [edi].OriginalFirstThunk .else mov eax, [edi].FirstThunk .endif invoke _RVAToOffset, _lpFile, eax add eax, _lpFile mov ebx, eax ;循环处理所有的 IMAGE_THUNK_DATA.while dword ptr [ebx] ;按序号导入.if dword ptr [ebx] & IMAGE_ORDINAL_FLAG32 mov eax, dword ptr [ebx]and eax, 0FFFFh invoke wsprintf, addr @szBuffer, addr szMsgOrdinal, eax .else ;按函数名导入invoke _RVAToOffset, _lpFile, dword ptr [ebx]add eax, _lpFile assume eax:ptr IMAGE_IMPORT_BY_NAME movzx ecx, [eax].Hint invoke wsprintf, addr @szBuffer, \addr szMsgName, ecx, addr [eax].Name1assume eax:nothing .endif invoke _AppendInfo, addr @szBuffer add ebx, 4 .endw add edi, sizeof IMAGE_IMPORT_DESCRIPTOR .endw
_Ret:assume edi:nothing popad ret
_ProcessPeFile endp
运行结果:
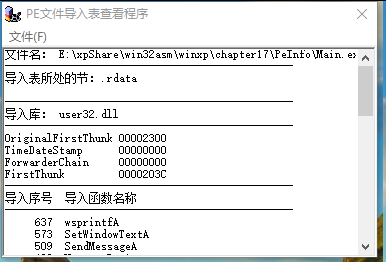
如果读者已经理解了17.2.1和17.2.2节中的内容,那么这段源程序是很容易看懂的,当_ProcessPeFile子程序在Main.asm中被调用的时候,输入参数_lpFile和_lpPeHead已经预先指向了被读到内存中的可执行文件头部和PE文件头的位置。程序首先查找数据目录表并得到导入表的地址,然后循环处理导入表中的每个IMAGE_IMPORT_DESCRIPTOR结构。
对于每个IMAGE_IMPORT_DESCRIPTOR结构,程序首先显示Name1字段指向的DLL文件名;然后继续构造一个循环来处理OriginalFirstThunk指向的IMAGE_THUNK_DATA数组,程序使用预定义值IMAGE_ORDINAL_FLAG32来测试IMAGE_THUNK_DATA结构的最高位,当最高位为1时显示导入函数的序号,当最高位为0时则显示导入函数的Hint值和函数名称。
在这个程序中读者经常提及的一个问题是为什么访问数据目录表的时候地址是DataDirectory[8].VirtualAddress,而不是DataDirectory[1].VirtualAddress,要知道,数据目录表中导入表的索引是1呀?答案是:这是MASM的语法决定的,在MASM中,不管数组中的单个数组项字节数是多少,括号中的数值都是字节地址而不是数组下标,所以数据目录表结构的长度是8的时候,访问第n个结构时要寻址的就是DataDirectory[n*8],所以上面的DataDirectory[8]实际上是DataDirectory[1*8]的意思,表示访问的是索引号为1的数组项。 -------------原来如此
17.3 导出表
当PE文件被执行的时候,Windows装载器将文件装入内存并将导入表中登记的DLL文件一并装入,再根据DLL文件中的函数导出信息对被执行文件的IAT表进行修正。在这些包含导出函数的DLL文件中,导出信息被保存在导出表中,通过导出表,DLL文件向系统提供导出函数的名称、序号和入口地址等信息,以便Windows装载器通过这些信息来完成动态链接的过程。
扩展名为.exe的PE文件中一般不存在导出表,而大部分的.dll文件中都包含导出表,但是这并不是必然的,比如,用做纯资源的.dll文件就不提供导出函数,文件中也就不存在导出表;另外,偶尔也可以见到包含导出函数和导出表的.exe文件。本节将介绍导出表的结构和使用方法。
17.3.1 导出表的结构
1.获取导出表的位置
导出表的位置和大小同样可以从PE文件头中的数据目录中获取,与导出表对应的项目是数据目录中的首个IMAGE_DATA_DIRECTORY结构,从这个结构的VirtualAddress字段得到的就是导出表的RVA值。如果在磁盘上的PE文件中查找导出表,那么使用_RVAToOffset子程序将RVA转换成文件偏移就可以了。
2.导出表的组成
导出表的功能是与导入表配合使用的,既然在导入表中可以用函数名或序号来导入,那么可以想象,导出表中必然也可以用函数名或序号这两种方法来导出函数。事实的确如此,导出表中为每个导出函数定义了导出序号,但函数名的定义是可选的。对于定义了函数名的函数来说,既可以使用名称导出,也可以使用序号导出;对于没有定义函数名的函数来说,只能使用序号来导出。
导出表的起始位置有一个IMAGE_EXPORT_DIRECTORY结构,与导入表中有多个IMAGE_IMPORT_DESCRIPTOR结构不同,导出表中只有一个IMAGE_EXPORT_DIRECTORY结构,这个结构的定义如下:
IMAGE_EXPORT_DIRECTORY STRUCTCharacteristics DWORD ? ;未使用,总是为0TimeDateStamp DWORD ? ;文件的产生时刻MajorVersion WORD ? ;未使用,总是为0MinorVersion WORD ? ;未使用,总是为0nName DWORD ? ;指向文件名的RVAnBase DWORD ? ;导出函数的起始序号NumberOfFunctions DWORD ? ;导出函数的总数NumberOfNames DWORD ? ;以名称导出的函数总数AddressOfFunctions DWORD ? ;指向导出函数地址表的RVAAddressOfNames DWORD ? ;指向函数名地址表的RVAAddressOfNameOrdinals DWORD ? ;指向函数名序号表的RVA
IMAGE_EXPORT_DIRECTORY ENDS这个结构中的一些字段并没有被使用,其余有意义的字段说明如下,读者可以参考图17.7来理解这些字段之间的关系。
● nName字段
这个字段是一个RVA值,指向一个定义了模块名称的字符串。这个字符串说明了模块的原始文件名,比如说,即使Kernel32.dll文件被改名为Ker.dll,仍然可以从这个字符串中的值得知它被编译时的文件名是“Kernel32.dll”。
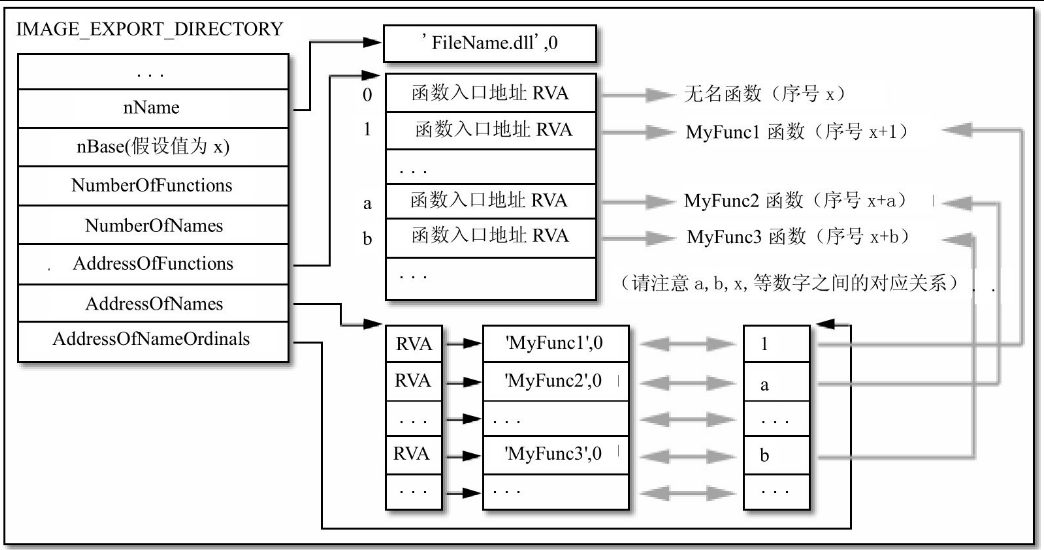
图17.7 函数导出的示意图
● NumberOfFunctions字段
文件中包含的导出函数的总数。
● NumberOfNames字段
被定义了函数名称的导出函数的总数。显然,只有这个数量的函数既可以用函数名方式导出,也可以用序号方式导出,剩下的NumberOfFunctions减去NumberOfNames数量的函数只能用序号方式导出。NumberOfNames字段的值只会小于或者等于NumberOfFunctions字段的值,如果这个值是0,表示所有的函数都是以序号方式导出的。
● AddressOfFunctions字段
这是一个RVA值,指向包含全部导出函数入口地址的双字数组,数组中的每一项是一个RVA值,数组的项数等于NumberOfFunctions字段的值。
● nBase字段
导出函数序号的起始值。将AddressOfFunctions字段指向的入口地址表的索引号加上这个起始值就是对应函数的导出序号,举例来说,假如nBase字段的值为x,那么入口地址表指定的第一个导出函数的序号就是x,第二个导出函数的序号就是x+1,总之,一个导出函数的导出序号等于nBase字段的值加上其在入口地址表中的位置索引值。
● AddressOfNames和AddressOfNameOrdinals字段
AddressOfNames字段的数值是一个RVA值,指向函数名字符串地址表,这个地址表是一个双字数组,数组中的每一项指向一个函数名称字符串的RVA,数组的项数等于NumberOfNames字段的值,所有有名称的导出函数的名称字符串都定义在这个表中。
那么这些函数名称究竟对应地址表中的那个函数呢?AddressOfNameOrdinals字段就派上用途了,这个字段也是一个RVA值,指向另一个word类型的数组(注意不是双字数组),数组的项目与文件名地址表中的项目一一对应,项目的值代表函数入口地址表的索引,这样函数名称与函数入口地址就关联起来了。
举例说明,假如函数名称字符串地址表的第n项指向一个字符串“MyFunction”,那么可以去查找AddressOfNameOrdinals字段指向的数组的第n项,假如第n项中存放的值是x,表示AddressOfFunctions字段描述的地址表中的第x项函数入口地址(假定入口地址值是aaaa)对应的函数名就是“MyFunction”,这时这个函数的全部信息就可以如下描述。
函数名称:MyFunction,导出序号:nBase的值+x,入口地址:aaaa
可以看到,AddressOfNameOrdinals字段描述的数组仅仅起了一个桥梁的作用。
3.从序号查找入口地址
下面来模拟一下Windows装载器查找导出函数入口地址的过程。如果已知函数的导出序号,如何得到入口地址呢?
步骤如下所示:
(1)定位到PE文件头。
(2)从PE文件头中的IMAGE_OPTIONAL_HEADER32结构中取出数据目录表,并从第一个数据目录中得到导出表的地址。
(3)从导出表的nBase字段得到起始序号。
(4)将需要查找的导出序号减去起始序号,得到函数在入口地址表中的索引。
(5)检测索引值是否大于导出表的NumberOfFunctions字段的值,如果大于后者的话,说明输入的序号是无效的。
(6)用这个索引值在AddressOfFunctions字段指向的导出函数入口地址表中取出相应的项目,这就是函数的入口地址RVA值,当函数被装入内存的时候,这个RVA值加上模块实际装入的基址,就得到了函数真正的入口地址。
4.从函数名称查找入口地址
如果已知函数的名称,如何得到函数的入口地址呢?与使用序号来获取入口地址相比,这个过程要相对复杂一点:
(1)最初的步骤是一样的,那就是首先得到导出表的地址。
(2)从导出表的NumberOfNames字段得到已命名函数的总数,并以这个数字作为循环的次数来构造一个循环。
(3)从AddressOfNames字段指向的函数名称地址表的第一项开始,在循环中将每一项定义的函数名与要查找的函数名相比较,如果没有任何一个函数名是符合的,表示文件中没有指定名称的函数。
(4)如果某一项定义的函数名与要查找的函数名符合,那么记下这个函数名在字符串地址表中的索引值,然后在AddressOfNameOrdinals指向的数组中以同样的索引值取出数组项的值,暂且假定这个值为x。
(5)最后,以x值作为索引值,在AddressOfFunctions字段指向的函数入口地址表中获取的RVA就是函数的入口地址。
从函数名称查找入口地址的代码在病毒中经常见到,因为病毒是作为一段额外的代码被附加到可执行文件中的,如果病毒代码中用到了某些API的话,这些API的地址不可能在宿主文件的导入表中为病毒代码准备,只能通过在内存中动态查找的办法来实现。关于这方面的具体实现,请参考本章的最后一节。
17.3.2 查看PE文件导出表举例
有一个查看PE文件导出表的例子,例子的界面处理源代码同样沿用前面使用的Main.asm和Main.rc文件,只是用来处理PE文件内容的_ProcessPeFile.asm文件有所不同,下面列出的就是这个文件的内容,如果读者需要完整的源代码,可以查看本书所附光盘的Chapter17\Export目录。
;_ProcessPeFile.asm ---- Export例子的 PE文件处理模块
.const
szMsg byte '文件名: %s',0dh,0ahbyte '------------------------------------------------',0dh,0ahbyte '导出表所处的节:%s',0dh,0ahbyte '------------------------------------------------',0dh,0ahbyte '原始文件名 %s',0dh,0ahbyte 'nBase %08X',0dh,0ahbyte 'NumberOfFunctions %08X',0dh,0ahbyte 'NumberOfNames %08X',0dh,0ahbyte 'AddressOfFunctions %08X',0dh,0ahbyte 'AddressOfNames %08X',0dh,0ahbyte 'AddressOfNameOrd %08X',0dh,0ahbyte '------------------------------------------------',0dh,0ahbyte '导出序号 虚拟地址 导出函数名称',0dh,0ahbyte '------------------------------------------------',0dh,0ah,0
szMsgName byte '%08X %08X %s',0dh,0ah,0
szExportByOrd byte '(按照序号导出)',0
szErrNoExport byte '这个文件中没有导出函数!',0.code
include _RvaToFileOffset.asm _ProcessPeFile proc _lpFile, _lpPeHead, _dwSize local @szBuffer[1024]:byte, @szSectionName[16]:byte local @dwIndex, @lpAddressOfNames, @lpAddressOfNameOrdinals pushad mov esi, _lpPeHead assume esi:ptr IMAGE_NT_HEADERS ;从数据目录中获取导出表的位置 根据表17.4得出 导出表的索引号为0,即DataDirectory[0*8]mov eax, [esi].OptionalHeader.DataDirectory.VirtualAddress .if !eax invoke MessageBox, hWinMain, addr szErrNoExport, NULL, MB_OK jmp _Ret .endif invoke _RVAToOffset, _lpFile, eax add eax, _lpFile mov edi, eax ;显示一些常用的信息assume edi:ptr IMAGE_EXPORT_DIRECTORY invoke _RVAToOffset, _lpFile, [edi].nName add eax, _lpFile mov ecx, eax invoke _GetRVASection, _lpFile, [edi].nName invoke wsprintf, addr @szBuffer, addr szMsg, addr szFileName, eax, ecx, [edi].nBase, \[edi].NumberOfFunctions, [edi].NumberOfNames, [edi].AddressOfFunctions, \[edi].AddressOfNames, [edi].AddressOfNameOrdinals invoke SetWindowText, hWinEdit, addr @szBuffer invoke _RVAToOffset, _lpFile, [edi].AddressOfNames add eax, _lpFile mov @lpAddressOfNames, eax invoke _RVAToOffset, _lpFile, [edi].AddressOfNameOrdinals add eax, _lpFile mov esi, eax ;esi --> 函数地址表;循环显示导出函数的信息mov ecx, [edi].NumberOfFunctions mov @dwIndex, 0
@@:pushad ;在按名称导出的索引表中mov eax, @dwIndex push edi mov ecx, [edi].NumberOfNames cld mov edi, @lpAddressOfNameOrdinals repnz scasw .if ZERO? ;找到函数名称sub edi, @lpAddressOfNameOrdinals sub edi, 2 shl edi, 1 add edi, @lpAddressOfNames invoke _RVAToOffset, _lpFile, dword ptr [edi]add eax, _lpFile .else mov eax, offset szExportByOrd .endif pop edi ;序号 --> ecxmov ecx, @dwIndex add ecx, [edi].nBase invoke wsprintf, addr @szBuffer, addr szMsgName, \ecx, dword ptr [esi], eax invoke _AppendInfo, addr @szBuffer popad add esi, 4 inc @dwIndex loop @B
_Ret:assume esi:nothing assume edi:nothing popad ret
_ProcessPeFile endp 程序一开始首先从数据目录表获取导出表的地址,然后显示一些文件的信息,如导出表中定义的原始文件名和导出表中的一些字段的值。
接下来程序显示每个导出函数的信息,包括序号、入口地址和函数名称(如果有的话),具体的处理方法如下:
按照NumberOfFunctions的数量循环处理导入函数地址表中的每个项目,在循环中每次用当前项目的索引值在AddressOfNameOrdinals指定的数组中查找,如果索引值没有包括在数组中,表示没有任何已定义的函数名称符合当前的函数入口地址,这时程序将显示“按照序号导出”的信息;如果在数组中找到当前索引值,表明有个函数名称对应当前的函数入口地址,程序记下在数组中找到当前索引的位置,并在AddressOfNames字段定义的函数名地址表的同样位置取出函数名称字符串的RVA,最后以这个RVA得到函数名称字符串并显示出来。
查找时使用的几句代码需要说明一下:
mov edi,@lpAddressOfNameOrdinals
repnz scasw
.if ZERO? ;找到函数名称sub edi,@lpAddressOfNameOrdinalssub edi,2shl edi,1add edi,@lpAddressOfNames首先,由于AddressOfNameOrdinals指定的数组是word类型的,所以查找指令用的是scasw而不是scasb或scasd,当查找结束后,如果标志位为0则表示查找成功,这时edi的值指向找到的项目后面一个word的位置,将edi减去数组的基址并减去2(一个word的长度),得到的就是找到的项目的位置偏移。由于这个数组是word类型的,而AddressOfNames指向的数组是dword类型的,所以还要将偏移乘以2来修正一下(使用shl edi,1指令),用修正后的偏移在AddressOfNames表中就可以得到指向函数名称字符串的RVA了。