打包数据集解析及大模型强化学习拓展阅读(96)
打包数据集解析及大模型强化学习拓展阅读
- 填充标记的一生
- packing 技术解析
- 瞧!你的序列就这样完成打包了!
- “等一下……这样做难道不会把有些样本在句子中间截断吗?”
- 那打包后的序列应该设为多长呢?”
- 关键概念补充
- 拓展材料
填充标记的一生
“打包好你的tokens,出发!”
颇具讽刺意味的是,那些“必须被送走”的tokens,实际上正是填充token(padding tokens)。不妨试想一下填充token的“一生”:它被添加到序列头部(或尾部,具体取决于填充策略),唯一目的就是让序列长度达标,却很快就会被模型判定为“不含任何有用信息的输入部分”而忽略。毫不夸张地说,它只是在白白占用GPU内存中宝贵且“昂贵”的空间(注:GPU内存资源有限,训练时需高额成本,填充token的无效占用会降低资源利用率)。
packing 技术解析
这时候,“打包”(packing)技术就登场了!打包的思路非常简单直接:
- 将所有序列首尾相连(中间需加入分隔符,避免不同序列的token混淆);
- 把拼接后的长序列切分成等长的片段(片段长度即训练时设定的“序列长度”,如512、1024等);
- 对切分后的片段进行打乱。
瞧!你的序列就这样完成打包了!
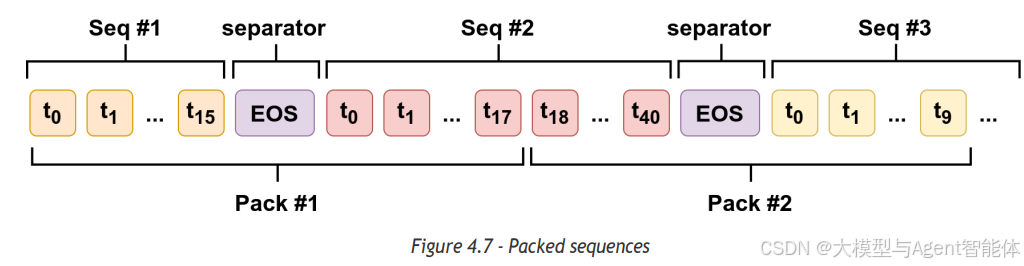
“等一下……这样做难道不会把有些样本在句子中间截断吗?”
没错!
“那我们岂不是会丢失一些信息?这难道不糟糕吗?”
确实会丢失信息,但未必是坏事。有