一篇文章说清【布隆过滤器】
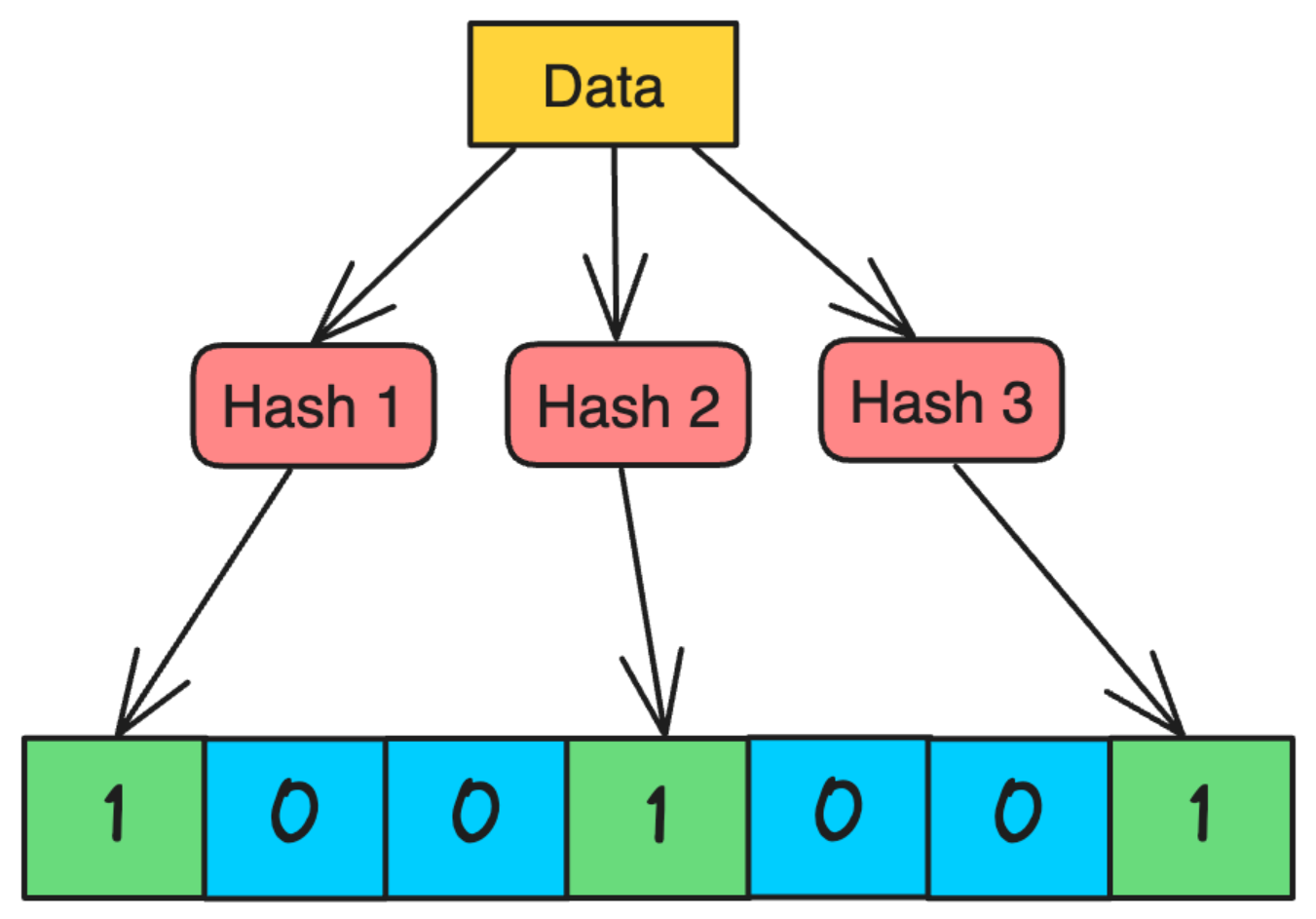
组成
- 由二进制数组作为底层存储结构,初始元素值都为0
- 由0、1表示存在关系
- 需要n个彼此独立、输出范围不同的哈希函数。每个函数能将输入的任意元素(如字符串、数字等)映射到位数组的某个索引位置。
工作过程
插入:
当插入元素A,经过n个哈希函数的计算,得到A的n个哈希值,将其在数组中哈希值对应的索引的值改为1。
查询:
查询元素A,经过n个哈希函数,得到A的n个哈希值,查询其在数组的位置。如果有一个不为1,说明元素A不存在。
删除:
很容易误删:由于多个元素可能共享同一位,删除一个元素时若将其对应的位设为 0,可能会破坏其他元素的标记,导致后续查询出错。
优缺点
优点:
- 使用二进制数组,只存储0、1,占用的空间小
- 基于数组实现,查询、插入速度快
- 保密性好,只存储0、1而不是元素本身
缺点:
- 删除操作容易误删
- 存在误判情况,数据A和数据B的哈希值集合相同
如何减少误判率?
变长存储0、1的数组,同时增加哈希函数的数量。减少不同数据哈希值的集合完全重合的概率。
缺点:
- 占用空间增大
- 计算时间增长
如何防止Redis缓存穿透?
- 先通过布隆过滤器查询数据库有没有数据,如果没有直接返回空值,之后再由业务具体代码处理
- 如果有数据再查询Redis缓存,如命中返回结果
- Redis没有命中,再查询数据库,返回数据。如不存在数据,返回空值(这种情况即为布隆过滤器的 “假阳性” 误判,概率极低)
防止查询空数据频繁访问数据库
布隆过滤器的变种
为解决传统布隆过滤器的缺陷,出现了多种功能增强的变种:
- 计数布隆过滤器(Counting Bloom Filter):将二进制位数组替换为 “计数数组”(每个元素存储整数),插入时计数 + 1,删除时计数 - 1,支持删除操作,但空间占用更高(通常每个位置需 4 位或 8 位)。
- 布谷鸟过滤器(Cuckoo Filter):基于 “布谷鸟哈希” 原理,支持删除和插入,且假阳性率更低,但实现更复杂,插入时可能存在 “哈希冲突导致的重定位开销”。
- 分层布隆过滤器(Layered Bloom Filter):按元素插入时间分层存储,支持 “过期元素自动淘汰”,适合时序数据场景。