MySQL数据库(五)—— Mysql 备份与还原+慢查询日志分析
文章目录
- 前言
- 一、数据备份的重要性
- 二、数据库备份类型
- 2.1 物理备份
- 2.1.1 冷备份(脱机备份)
- 2.1.2 热备份(联机备份)
- 2.1.3 温备份
- 2.2 逻辑备份
- 2.2.1 完全备份
- 2.2.2 差异备份
- 2.2.3 增量备份
- 2.3 备份策略对比表
- 三、常见备份方法
- 3.1 物理冷备
- 3.2 专用备份工具 mysqldump 或 mysqlhotcopy
- 3.3 二进制日志增量备份
- 3.4 第三方工具
- 四、MySQL完全备份
- 4.1 核心特点
- 4.2 优缺点分析
- 五、数据库完全备份分类
- 5.1 物理冷备份与恢复
- 5.2 mysqldump备份与恢复
- 六、实战案例
- 6.1 环境准备
- 6.2 完全备份与恢复
- 6.2.1 物理冷备恢复
- 6.2.2 mysqldump 备份与恢复(温备份)
- 6.2.3 Mysql 完全恢复
- 6.3 MySQL 增量备份与恢复
- 6.3.1 MySQL数据库增量恢复类型
- 6.3.2 MySQL 增量备份
- 6.3.2.1 开启二进制日志功能
- 6.3.2.2 进行完全备份
- 6.3.2.3 可每天进行增量备份操作
- 6.3.2.4 插入新数据,以模拟数据的增加或变更
- 6.3.2.5 再次生成新的二进制日志文件
- 6.3.3 MySQL增量恢复
- 6.3.3.1 一般恢复
- 6.3.3.2 基于位置恢复
- 6.3.3.3 基于时间点恢复
- 七、慢查询日志分析
- 7.1 开启慢查询
- 方法 A:通过配置文件(推荐生产环境)
- 方法 B:运行时开启(临时生效,重启失效)
- 7.2 查看慢查询日志
- 7.3 使用 `mysqldumpslow` 分析慢查询日志
- 7.4 使用 `pt-query-digest` 分析(更专业)
- 7.5 临时检查当前正在运行的慢查询
- 总结
前言
数据是企业的核心资产,而数据库备份是守护这份资产的最后防线。无论程序错误、人为失误还是硬件故障,一旦数据丢失,后果不堪设想。
本文全面解析MySQL备份与恢复的核心技术,涵盖物理/逻辑备份、冷/热/温备份、全量/增量/差异备份策略,并通过实战案例手把手教你如何应对数据灾难。无论你是DBA还是开发者,都能从中掌握企业级数据保护方案。
一、数据备份的重要性
-
灾难恢复核心手段
备份是数据丢失后的唯一救命稻草,尤其在硬件故障、自然灾害等场景下。 -
保障数据安全
生产环境中,数据直接关联业务价值,备份是安全体系的基石。 -
数据丢失的严重后果
财务损失、法律风险、客户信任崩塌等连锁反应。 -
常见数据丢失原因
- 程序逻辑错误
- 人为误操作(如误删表)
- 硬件故障(磁盘损坏)
- 自然灾害(火灾、地震)
- 安全事件(黑客攻击、勒索病毒)
二、数据库备份类型
2.1 物理备份
直接备份数据库物理文件(数据文件、日志文件等),适用于快速恢复大型数据库。
2.1.1 冷备份(脱机备份)
- 原理:关闭数据库的时候进行(如
tar命令) - 优点:简单全面,无需额外资源
- 缺点:必须停服,影响业务连续性
- 适用场景:可接受停机维护的离线系统
2.1.2 热备份(联机备份)
- 原理:数据库处于运行状态时直接备份,依赖于数据库的日志文件(mysqlhotcopy mysqlbackup)
- 优点:24×7无间断,业务零影响
- 缺点:实现复杂,消耗系统资源
- 适用场景:金融、电商等高可用系统
2.1.3 温备份
- 原理:数据库锁定表格(不可写入但可读)的状态下进行备份操作(mysqldump)
- 特点:平衡冷备与热备,折中方案
- 适用场景:可容忍短暂只读的业务系统
2.2 逻辑备份
备份数据库逻辑结构(SQL语句),适用于跨版本迁移或部分恢复。
2.2.1 完全备份
- 操作:每次备份整个数据库,会导致空间占用巨大,并且有许多重复数据
- 特点:每次都进行完全备份,会导致备份文件占用空间巨大,并且有大量的重复数据
- 恢复公式:直接使用全备文件还原
2.2.2 差异备份
- 操作:每次差异备份,都会备份上一次完全备份之后的全部数据,可能会出现重复数据。
- 特点:空间占用适中,恢复需全备+最新差异备
- 恢复流程:全量恢复 → 应用最新差异备份
2.2.3 增量备份
- 操作:增量备份只会备份自上次备份以后的新数据。
- 特点:空间占用最小,恢复依赖完整备份链
- 恢复流程:全量恢复 → 按顺序应用所有增量备份
2.3 备份策略对比表
| 备份方式 | 空间占用 | 恢复速度 | 恢复复杂度 | 适用场景 |
|---|---|---|---|---|
| 完全备份 | 高 | 快 | 低 | 小型数据库 |
| 差异备份 | 中 | 中 | 中 | 中型业务系统 |
| 增量备份 | 低 | 慢 | 高 | 大型高频更新系统 |
📊 最佳实践:
合理值区间 ⭐⭐⭐
一周一次的全备,全备的时间需要在不提供业务的时间区间进行 PM 10点 ~ AM 5:00之间进行全备(凌晨2/3点左右)
增量:3天/2天/1天一次增量备份
差异:选择特定的场景进行备份
一个处理(NFS)提供额外空间给与mysql 服务器用
三、常见备份方法
3.1 物理冷备
备份时数据库处于关闭状态,直接打包数据库文件(tar)
备份速度快,恢复时也是最简单的
3.2 专用备份工具 mysqldump 或 mysqlhotcopy
-
mysqldump(温备份):
-
mysqlhotcopy(仅MyISAM引擎和 ARCHIVE 表)
3.3 二进制日志增量备份
进行增量备份,需要启用二进制日志
-- 启用二进制日志
[mysqld]
log-bin=/var/log/mysql/mysql-bin.log
MySQL支持增量备份,进行增量备份时必须启用二进制日志。
二进制日志文件支持数据库复制功能,记录备份时间点后的所有数据变更信息,便于恢复操作。执行增量备份(包含上次完整或增量备份后的数据修改)时,必须刷新二进制日志。
3.4 第三方工具
- Percona XtraBackup mysqlbackup:开源热备工具
- MySQL Enterprise Backup:官方企业级方案
四、MySQL完全备份
4.1 核心特点
- 是对整个数据库、数据库结构和文件结构的备份
- 保存的是备份完成时刻的数据库
- 是差异备份与增量备份的基础
4.2 优缺点分析
| 优点 | 缺点 |
|---|---|
| 恢复操作简单 | 占用大量磁盘空间 |
| 无需复杂依赖 | 备份和恢复时间长 |
| 数据完整性高 | 重复数据多 |
五、数据库完全备份分类
5.1 物理冷备份与恢复
1、关闭MySQL数据库
2、使用tar命令直接打包数据库文件夹
3、直接替换现有MySQL目录即可
5.2 mysqldump备份与恢复
1、MySQL自带的备份工具,可方便实现对MySQL的备份
2、可以将指定的库、表导出为SQL 脚本
3、使用命令mysq|导入备份的数据
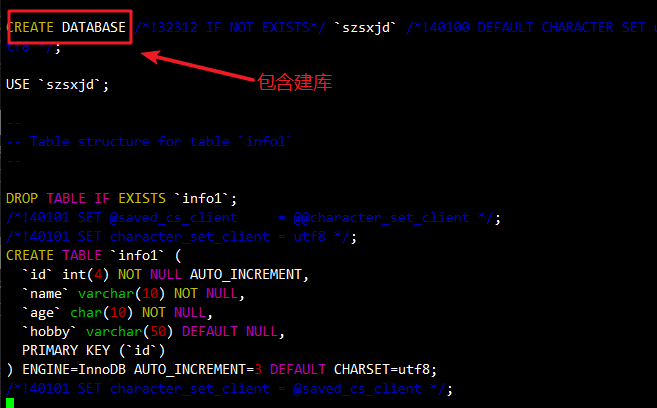
⚠️ 注意:使用
--databases参数备份则包含创库语句,否则需手动建库
六、实战案例
6.1 环境准备
create database szsxjd;
use szsxjd;
create table if not exists info1 (
id int(4) not null auto_increment,
name varchar(10) not null,
age char(10) not null,
hobby varchar(50),
primary key (id));insert into info1 values(1,'user1',20,'running');
insert into info1 values(2,'user2',30,'singing');
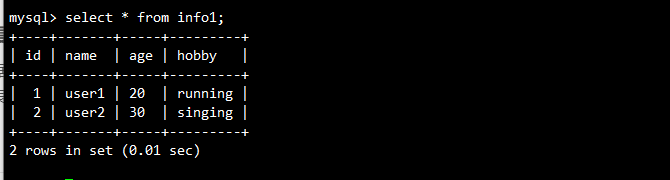
6.2 完全备份与恢复
InnoDB 存储引擎的数据库在磁盘上存储成三个文件: db.opt(表属性文件)、表名.frm(表结构文件)、表名.ibd(表数据文件)。
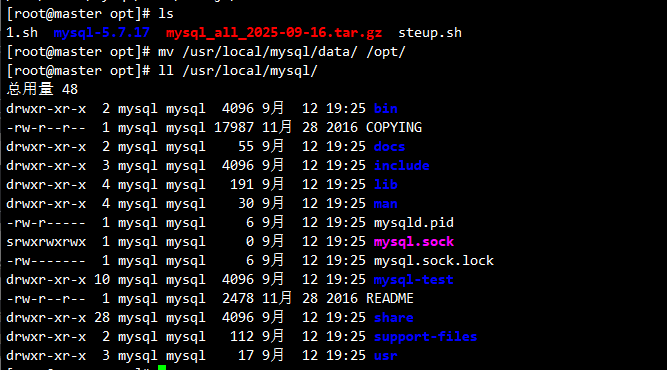
6.2.1 物理冷备恢复
systemctl stop mysqld
#压缩备份
tar zcvPf /opt/mysql_all_$(date +%F).tar.gz /usr/local/mysql/data/
mv /usr/local/mysql/data/ /opt/
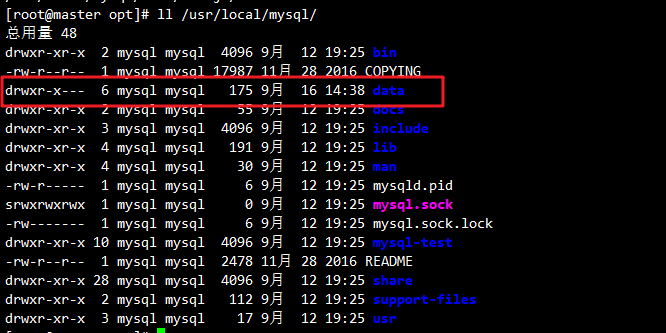
#解压恢复
tar zxvPf /opt/mysql_all_2025-09-16.tar.gz -C /usr/local/mysql/
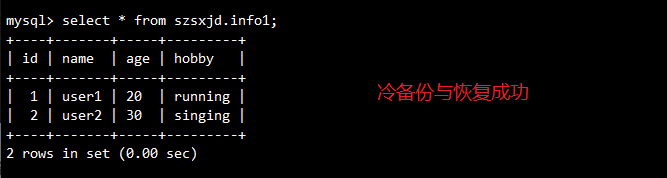
6.2.2 mysqldump 备份与恢复(温备份)
create table info2 (id int,name char(10),age int,sex char(4));
insert into info2 values(1,'user',11,'性别');
insert into info2 values(2,'user',11,'性别');(1)、完全备份一个或多个完整的库 (包括其中所有的表)
mysqldump -u root -p[密码] --databases 库名1 [库名2] ... > /备份路径/备份文件名.sql #导出的就是数据库脚本文件
例:
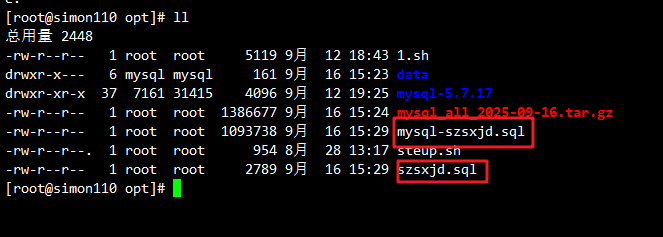
mysqldump -u root -p --databases szsxjd > /opt/szsxjd.sql #备份一个szsxjd库 结构和数据
mysqldump -u root -p --databases mysql szsxjd > /opt/mysql-szsxjd.sql #备份mysql与szsxjd两个库结构和数据
(2)、完全备份 MySQL 服务器中所有的库
mysqldump -u root -p[密码] --all-databases > /备份路径/备份文件名.sql
例:
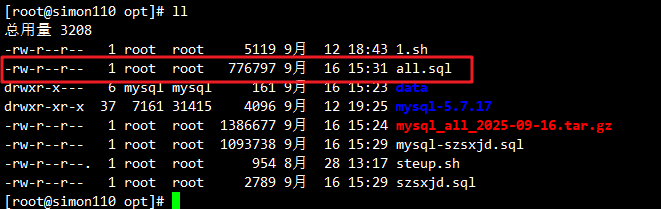
mysqldump -u root -p --all-databases > /opt/all.sql
(3)、完全备份指定库中的部分表
mysqldump -u root -p[密码] 库名 [表名1] [表名2] ... > /备份路径/备份文件名.sql
例:
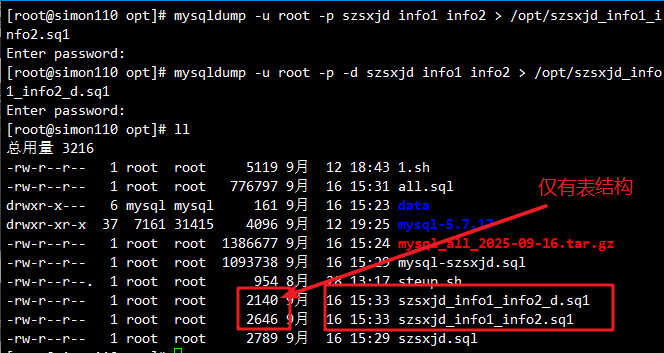
mysqldump -u root -p [-d] szsxjd info1 info2 > /opt/szsxjd_info1_info2.sql
#使用“-d”选项,说明只保存数据库的表结构
#不使用“-d"选项,说明表数据也进行备份
#做为一个表结构模板
(4)查看备份文件
grep -v "^--" /opt/szsxjd_info1_info2.sql | grep -v "^/" | grep -v "^$"
grep -v "^--" /opt/szsxjd_info1_info2_d.sql | grep -v "^/" | grep -v "^$"
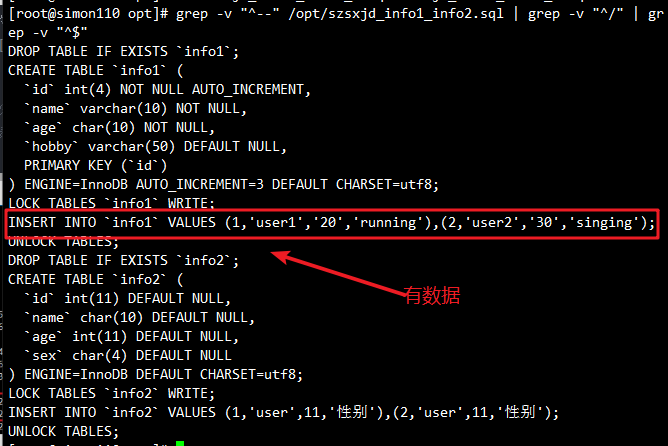
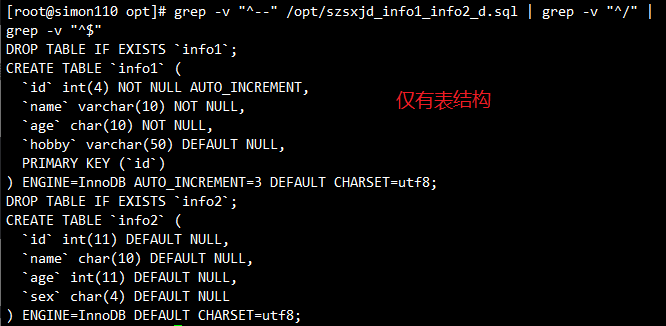
⚠️ 注意:使用
--databases参数备份则包含创库语句,否则需手动建库
6.2.3 Mysql 完全恢复
#恢复数据库
1.使用mysqldump导出的文件,可使用导入的方法
source命令
mysql命令2.使用source恢复数据库的步骤登录到MySQL数据库
执行source备份sql脚本的路径3.source恢复的示例MySQL [(none)]> source /backup/all-data.sql
使用source命令恢复数据:
1.模拟数据库出现问题
mysql -uroot -p登录数据库
mysql> show databases; 查看数据库信息

应用示例:
创建备份(对表进行备份)
mysqldump -uroot -p szsxjd info1 > /opt/info1.sql
mysql -uroot -p -e 'drop table szsxjd.info1;' #删除数据库的表
mysql -uroot -p 登录数据库查看


恢复数据表:
> source /opt/info1.sql # 查看表信息
mysql> show tables in szsxjd;
# 或者免交互方式:
mysql -uroot -p123456 -e 'show tables in szsxjd;'

方式二:
mysql -uroot -p szsxjd < /opt/info1.sql #恢复info1表
mysql -uroot -p -e 'show tables in szsxjd;' #查看info1表
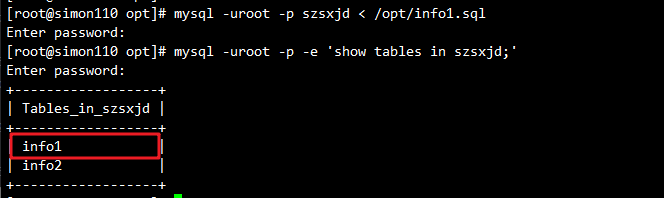
PS:mysqldump 严格来说属于温备份,会需要对表进行写入的锁定
在全量备份与恢复中,假设现有szsxjd库,szsxjd库中有一个info1表,需要注意:
①当备份时加 --databases ,表示针对于szsxjd库
#备份命令
mysqldump -uroot -p123456--databases szsxjd > /opt/szsxjd_01_all.sql 备份库后
#恢复命令过程为:
mysql -uroot -p123456
drop database szsxjd ;
exit
mysql -uroot -p123456 < /opt/szsxjd_01_all.sql
② 当备份时不加 --databases,表示针对szsxjd库下的所有表
#备份命令
mysqldump -uroot -p123456 szsxjd > /opt/szsxjd_02_all.sql
#恢复过程:
mysql -uroot -p123456
drop database szsxjd;
create database szsxjd; # 手动创建库
exit
mysql -uroot -p123456 szsxjd < /opt/szsxjd_02_all.sql #查看szsxjd_01.sql 和szsxjd_02.sql
主要原因在于两种方式的备份(前者会从"create databases"开始,而后者则全是针对表格进行操作)
在生产环境中,可以使用Shell脚本自动实现定时备份(时间频率需要确认)
0 1 * * 6 /usr/local/mysql/bin/mysqldump -uroot -p123456 szsxjd info1 > ./szsxjd_infol_$(date +%Y%m%d).sql ;/usr/local/mysql/bin/mysqladmin -u root -p flush-logs
6.3 MySQL 增量备份与恢复
6.3.1 MySQL数据库增量恢复类型
-
一般恢复: 将所有备份的二进制日志内容全部恢复
-
基于位置恢复
- 数据库在某一时间点可能既有错误的操作也有正确的操作
- 可以基于精准的位置跳过错误的操作
- 发生错误节点之前的一个节点,上一次正确操作的位置点停止
-
基于时间点恢复
- 跳过某个发生错误的时间点实现数据恢复
- 在错误时间点停止,在下一个正确时间点开始
6.3.2 MySQL 增量备份
6.3.2.1 开启二进制日志功能
1、开启二进制日志功能
vim /etc/my.cnf
[mysqld]
log-bin=mysql-bin
binlog_format = MIXED #可选,指定二进制日志(binlog)的记录格式为MIXED(混合输入)
server-id = 1 #可加可不加该命令
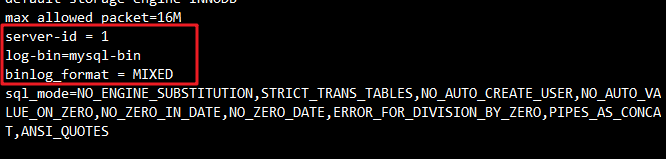
#二进制日志(binlog)有3种不同的记录格式: STATEMENT (基于SQL语句)、ROW(基于行)、MIXED(混合模式),默认格式是STATEMENT
① STATEMENT(基于SQL语句):
所有修改数据的SQL语句都会被记录在binlog中。
缺点:在使用sleep()函数、last_insert_id()以及用户自定义函数(UDF)时,或在主从复制等架构中记录日志时会出现问题。总结:通过SQL语句执行增删改查操作时,在高并发场景下可能出现错误。由于时间差异或延迟的影响,实际执行顺序可能与预期不符,比如删除操作可能先于修改操作执行,导致数据准确性降低。② ROW(基于行)
仅记录发生变动的数据行,不保存 SQL 语句的上下文信息。
缺点:日志量过大,若执行类似 UPDATE...SET...WHERE TRUE 这类全表更新操作,会导致 binlog 文件体积持续增长。总结:针对 UPDATE、DELETE 等多行操作,仅记录实际变动的数据行,不记录sql的上下文环境。比如sql语句记录一行,但是ROW就可能记录10行,记录精度高。高并发场景下由于写入量大,可能影响性能③ MIXED 推荐使用
一般的语句使用statement,函数使用ROW方式存储。
2、重启数据库
# 重启数据库
systemctl restart mysqld

3、查看二进制日志文件的内容
cp /usr/local/mysql/data/mysql-bin.000001 /opt/
mysqlbinlog --no-defaults --base64-output=decode-rows -v /opt/mysql-bin.000001二进制日志中需要关注的部分:
- at :开始的位置点
- end_log_pos:结束的位置
- 时间戳: 250916 18:48:25
- SQL语句
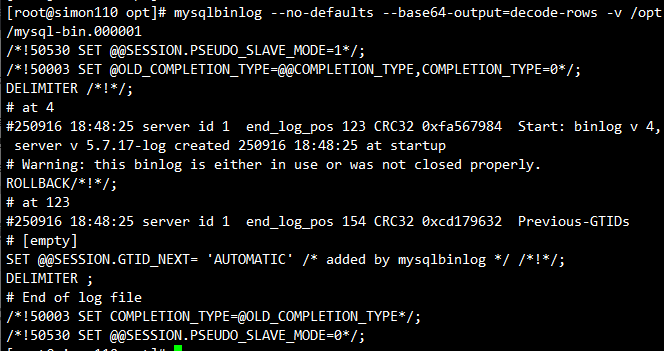
--base64-output=decode-rows:使用64位编码机制去解码(decode)并按行读取(rows)
-v: 显示详细内容
--no-defaults : 默认字符集(不加会报UTF-8的错误)
PS: 可以将解码后的文件导出为txt格式,方便查阅
mysqlbinlog --no-defaults --base64-output=decode-rows -v /opt/mysql-bin.000001 > /opt/mysql-bin.000001.txt

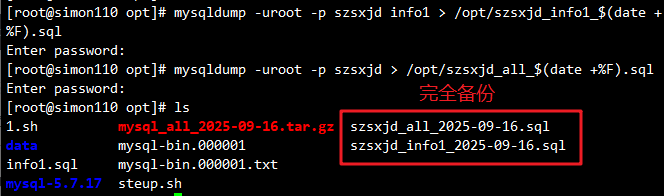
6.3.2.2 进行完全备份
增量备份时基于完全备份的,所以我们直接完全备份数据库
mysqldump -uroot -p szsxjd info1 > /opt/szsxjd_info1_$(date +%F).sql
mysqldump -uroot -p szsxjd > /opt/szsxjd_all_$(date +%F).sql
6.3.2.3 可每天进行增量备份操作
可每天进行增量备份操作,生成新的二进制日志文件(例如:mysql-bin.000002)
mysqladmin -u root -p flush-logs

6.3.2.4 插入新数据,以模拟数据的增加或变更
PS:在第一次完全备份之后刷新二进制文件,在第二个二进制文件中记载着"增量备份的数据"
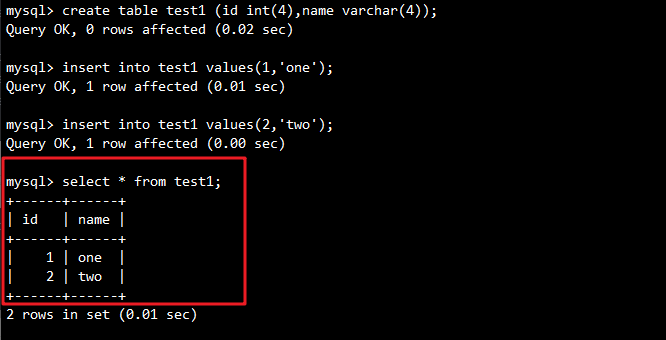
mysql> create database yjs0805;
mysql> use yjs0805;
mysql> create table test1 (id int(4),name varchar(4));
mysql> insert into test1 values(1,'one');
mysql> insert into test1 values(2,'two');
mysql> select * from test1;
6.3.2.5 再次生成新的二进制日志文件
mysqladmin -u root -p flush-logs
#之前的步骤4的数据库操作会保存到mysql-bin.000002文件中
#之后我们测试删除szsxjd库的操作会保存在mysql-bin.000003文件中
#(以免当我们基于mysql-bin.000002日志进行恢复时,依然会删除库)

6.3.3 MySQL增量恢复
6.3.3.1 一般恢复
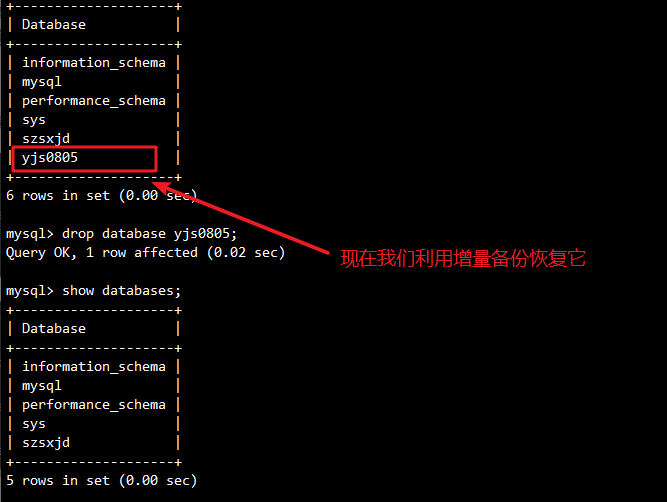
模拟丢失所有数据的恢复步骤:
#模拟丢失所有数据
mysql -uroot -p
mysql> show databases;
mysql> drop database yjs0805;
mysql> exit
# 基于mysql-bin.000002恢复
# 备份日志文件
cp /usr/local/mysql/data/mysql-bin.000002 /opt/
#查看日志文件
mysqlbinlog --no-defaults --base64-output=decode-rows -v mysql-bin.000002
# 使用日志文件进行一般恢复
mysqlbinlog --no-defaults /opt/mysql-bin.000002 | mysql -u root -p

6.3.3.2 基于位置恢复
① 插入三条数据
mysql> use yjs0805;
mysql> select * from test1;
mysql> insert into test1 values(3,'true');
mysql> insert into test1 values(4,'f');
mysql> insert into test1 values(5,'t');
mysql> select * from test1;
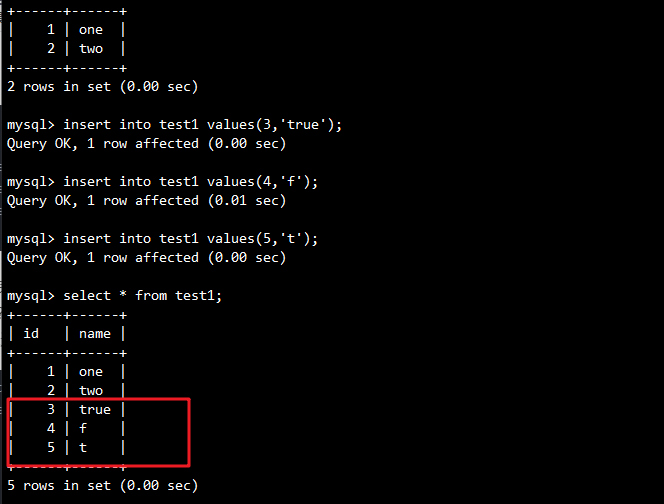
例如:有一个需求test1表中id =3的开始的数据操作失误,需要跳过,应该如何操作?
② 确认位置点,刷新二进制日志并删除test1表
cp /usr/local/mysql/data/mysql-bin.000003 /opt/
mysqlbinlog --no-defaults --base64-output=decode-rows -v /opt/mysql-bin.000003例如:
at 1417
#250916 19:30:04
insert into test1 values(3,'true')
at 1712
#250916 19:30:09
insert into test1 values(4,'f')#刷新日志
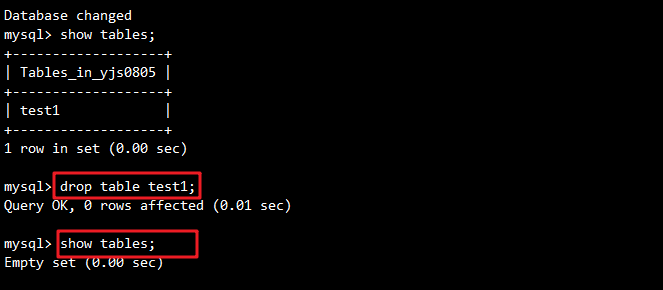
mysqladmin -uroot -p flush-logs# 删除test1表
mysql> use yjs0805;
mysql> show tables;
mysql> drop table yjs0805.test1;
③ 基于位置点恢复
#仅恢复到操作 ID 为“1417"之前的数据,即不恢复从"user3"开始的数据
mysqlbinlog --no-defaults --stop-position='1417' /opt/mysql-bin.000003 | mysql -uroot -p
#恢复从"user4"开始的的数据,跳过"user3"的数据恢复
mysqlbinlog --no-defaults --start-position='1712' /opt/mysql-bin.000003 | mysql -uroot -p

#恢复从位置为1417开始到位置为1712为止,仅恢复user3
mysqlbinlog --no-defaults --start-position='1417' --stop-position='1712' /opt/mysql-bin.000003 | mysql -uroot -p
6.3.3.3 基于时间点恢复
和基于位置的恢复很类似:
mysqlbinlog [--no-defaults] --start-datetime='年-月-日 小时:分钟:秒' --stop-datetime='年-月-日小时:分钟:秒' 二进制日志 | mysql -u 用户名 -p 密码
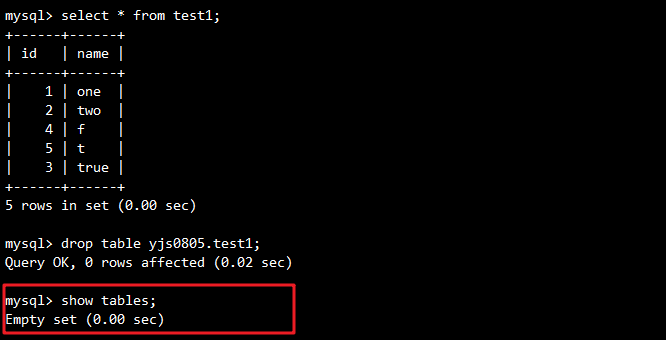
# 先删除test1表
drop table yjs0805.test1;
#仅恢复到16:41:24 之前的数据,即不恢复"user3"开始的数据
mysqlbinlog --no-defaults --stop-datetime='2025-09-16 19:30:04' /opt/mysql-bin.000003 | mysql -uroot -p

#仅恢复"user4"开始的数据,跳过"user3"的数据恢复
mysqlbinlog --no-defaults --start-datetime='2025-09-16 19:30:09' /opt/mysql-bin.000003 | mysql -uroot -p

mysqlbinlog --no-defaults --start-datetime='2025-09-16 19:30:04' --stop-datetime='2025-09-16 19:30:09'/opt/mysql-bin.000003 | mysql -uroot -p

七、慢查询日志分析
7.1 开启慢查询
方法 A:通过配置文件(推荐生产环境)
编辑 MySQL 配置文件 my.cnf(或 my.ini):
[mysqld]
slow_query_log = ON # 开启慢查询日志
slow_query_log_file = /var/log/mysql/mysql-slow.log # 日志文件路径
long_query_time = 2 # 超过多少秒认为是慢查询(默认 10s)
log_queries_not_using_indexes = ON # 可选:记录未使用索引的查询
然后重启 MySQL 服务:
systemctl restart mysqld
方法 B:运行时开启(临时生效,重启失效)
-- 开启慢查询日志
SET GLOBAL slow_query_log = 'ON';-- 设置慢查询阈值,例如 2 秒
SET GLOBAL long_query_time = 2;-- 可选:记录未使用索引的查询
SET GLOBAL log_queries_not_using_indexes = 1;-- 查看当前设置
SHOW VARIABLES LIKE '%slow_query_log%';
SHOW VARIABLES LIKE '%long_query_time%';
7.2 查看慢查询日志
- 日志默认路径在
/var/log/mysql/mysql-slow.log(Linux) - 可以直接
cat、tail或用less查看:
tail -f /var/log/mysql/mysql-slow.log
日志内容示例:
# Time: 2025-09-14T22:00:00.000000Z
# User@Host: root[root] @ localhost [127.0.0.1]
# Query_time: 3 Lock_time: 0 Rows_sent: 1000 Rows_examined: 100000
use testdb;
SELECT * FROM big_table WHERE name LIKE '%abc%';
- Query_time:查询耗时(秒)
- Lock_time:锁等待时间
- Rows_sent / Rows_examined:发送行数 / 扫描行数
7.3 使用 mysqldumpslow 分析慢查询日志
mysqldumpslow -s t -t 10 /var/log/mysql/mysql-slow.log
参数说明:
| 参数 | 含义 |
|---|---|
-s t | 按时间排序 |
-s r | 按扫描行数排序 |
-t 10 | 显示前 10 条 |
7.4 使用 pt-query-digest 分析(更专业)
pt-query-digest 是 Percona Toolkit 工具,可以详细分析慢查询日志:
pt-query-digest /var/log/mysql/mysql-slow.log
输出包含:
- 最慢的 SQL
- 出现次数
- 平均耗时
- 索引使用情况
7.5 临时检查当前正在运行的慢查询
SHOW FULL PROCESSLIST;
- 查看所有正在执行的 SQL
Time列表示已经运行了多少秒- 可以通过
KILL <id>终止长时间运行的查询
建议:
- 慢查询日志一般用于优化 SQL 或索引,不要频繁修改全局参数,生产环境建议通过
my.cnf配置固定策略。 - 配合 EXPLAIN 分析 SQL 执行计划,可以找出瓶颈。
总结
MySQL备份恢复是DBA的核心技能,关键要点总结:
- 备份策略选择:根据业务需求选择冷/热/温备和全量/增量/差异组合
- 备份验证:定期进行恢复演练,确保备份有效性
- 日志管理:二进制日志是实现增量备份的基础,需定期清理
- 监控告警:监控备份任务状态,失败时即时告警
- 加密存储:对敏感数据备份进行加密,防止泄露
🚀 终极建议:采用「全备+增量+二进制日志」的三层保护策略,结合自动化脚本实现每日备份,将数据丢失风险降至最低。记住:没有经过恢复验证的备份,不是真正的备份!