从零开始的云计算生活——第六十四天,志存高远,性能优化模块
一.Jemeter压力测试
1、前言
压力测试是每一个Web应用程序上线之前都需要做的一个测试,他可以帮助我们发现系统中的瓶颈问题,减少发布到生产环境后出问题的几率;预估系统的承载能力,使我们能根据其做出一些应对措施。所以压力测试是一个非常重要的步骤,下面我带大家来使用一款压力测试工具JMeter。
2、关于JMeter
ApacheJMeter是Apache组织开发的基于Java的压力测试工具。用于对软件做压力测试,它最初被设计用于Web应用测试,但后来扩展到其他测试领域。它可以用于测试静态和动态资源,例如静态文件、Java小服务程序、CGI脚本、Java对象、数据库、FTP服务器,等等。JMeter可以用于对服务器、网络或对象模拟巨大的负载,来自不同压力类别下测试它们的强度和分析整体性能。另外,JMeter能够对应用程序做功能/回归测试,通过创建带有断言的脚本来验证你的程序返回了你期望的结果。为了最大限度的灵活性,JMeter允许使用正则表达式创建断言。 Apachejmeter可以用于对静态的和动态的资源(文件,Servlet,Perl脚本,java对象,数据库和查询,FTP服务器等等)的性能进行测试。它可以用于对服务器、网络或对象模拟繁重的负载来测试它们的强度或分析不同压力类型下的整体性能。你可以使用它做性能的图形分析或在大并发负载测试你的服务器/脚本/对象。
-
官网:ApacheJMeter-DownloadApacheJMeter
3、准备工作
因为JMeter是使用JAVA写的,所以使用JMeter之前,先安装JAVA环境
安装JDK。
解压下载的二进制包,进入bin目录,双击jmeter.bat启动程序。
启动之后会有两个窗口,一个cmd窗口,一个JMeter的GUI。前面不要忽略CMD窗口的提示信息:
启动后会看到JMeter界面,如下:
更改语言为中文
官方默认为我们提供了简体中文。通过【Options】->【ChooseLanguage】变更为简体中文
优化安装Jemeter的windows主机
调整最大TCP连接数限制
Windows 对并发 TCP 连接数有默认限制,可通过注册表修改:
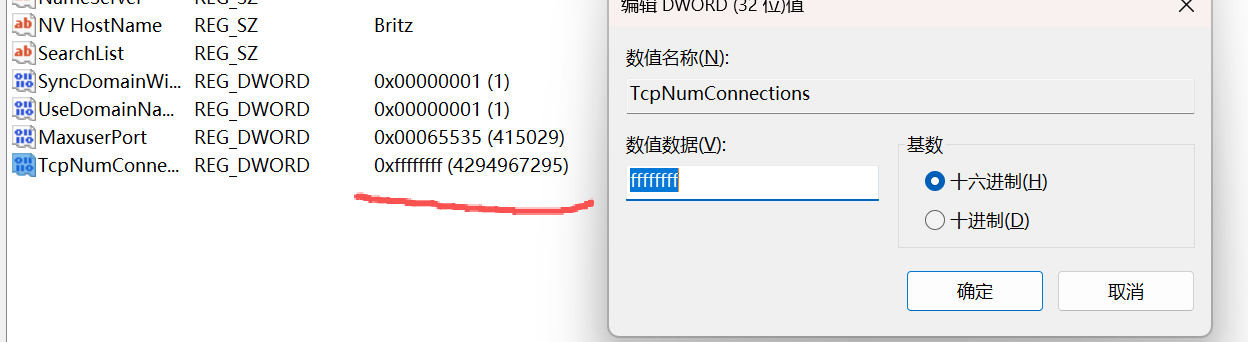
1.打开注册表编辑器:regedit
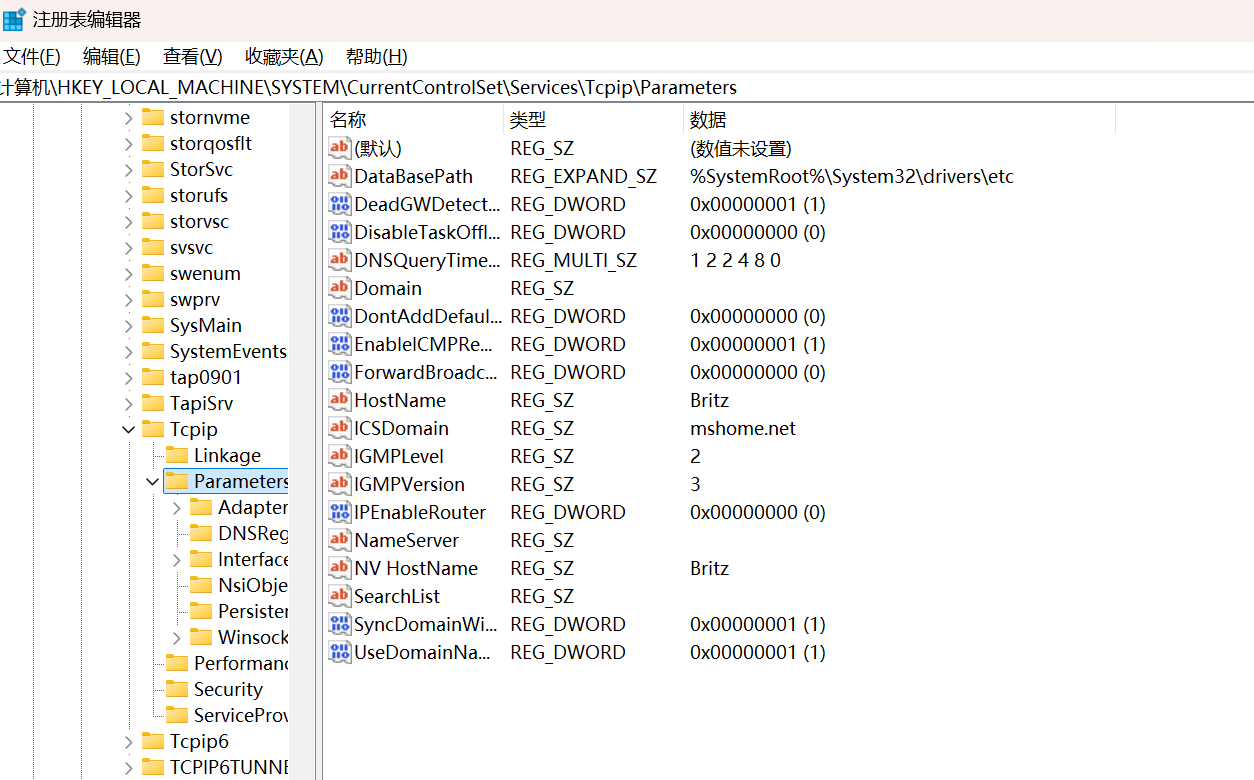
2.定位到:HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Service\Tcpip\Parameters
3.新建以下键值(若不存在):
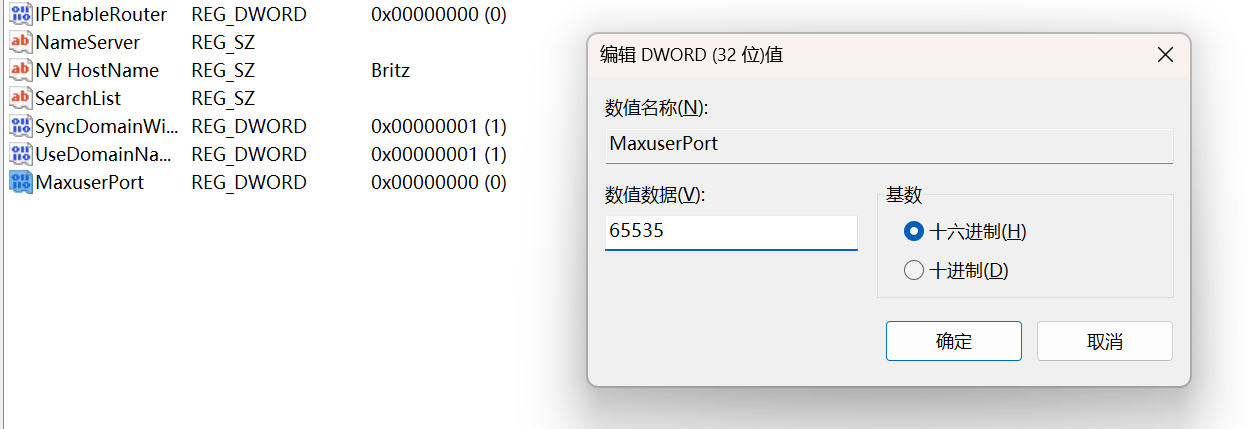
MaxuserPort(REG_DWORD):设置最大端口号(建议与动态端口范围的结束值一致,如 65535)TcpNumConnections(REG_DWORD):设置系统最大TCP 连接数(最大值为 0xFFFFFFFF,即约 42 亿)
4、创建测试
4.1、创建线程组
在“测试计划”上右键【添加】–>【Threads(Users)】–>【线程组】
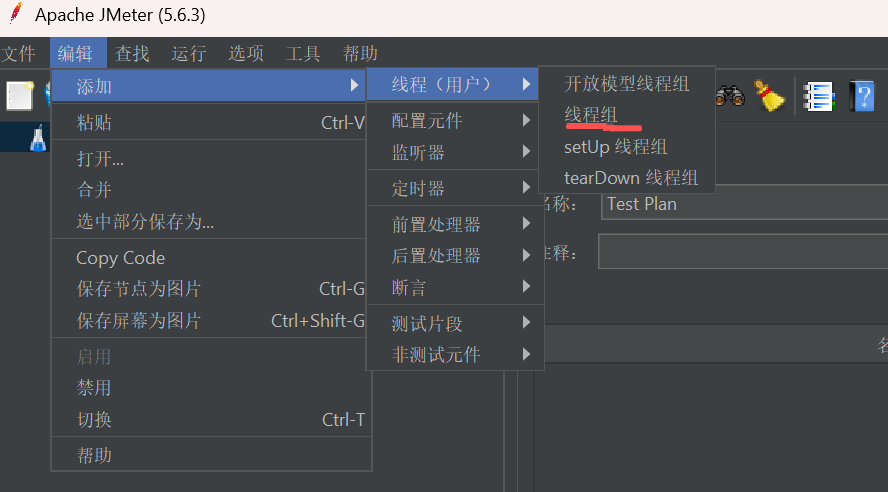
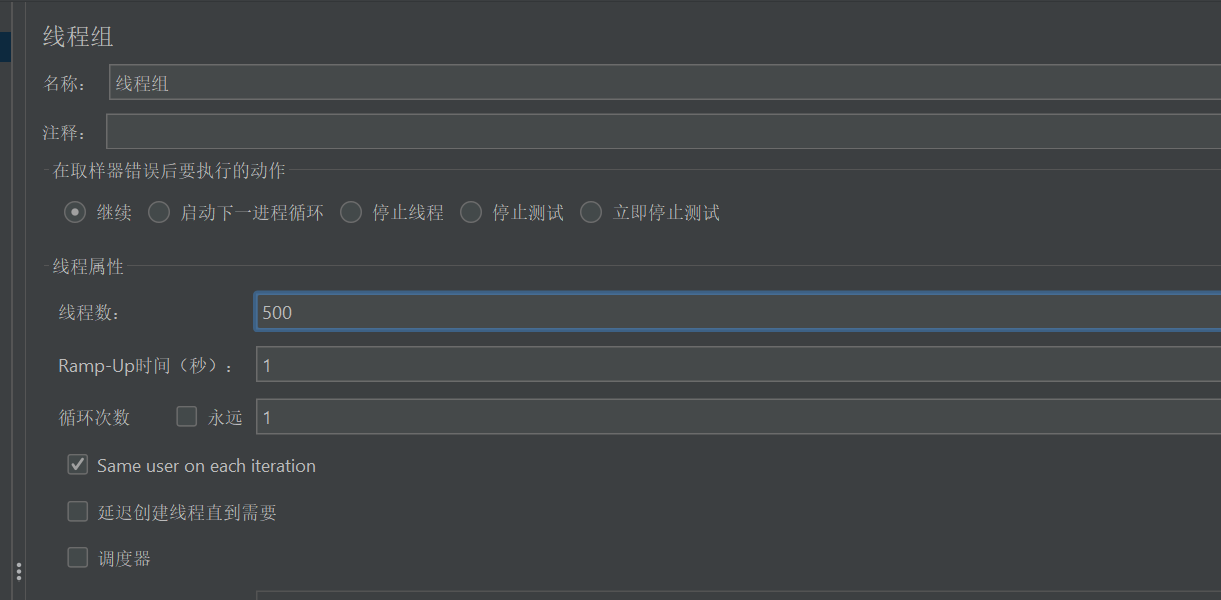
设置线程数和循环次数。我这里设置线程数为500,循环一次
4.2、配置元件
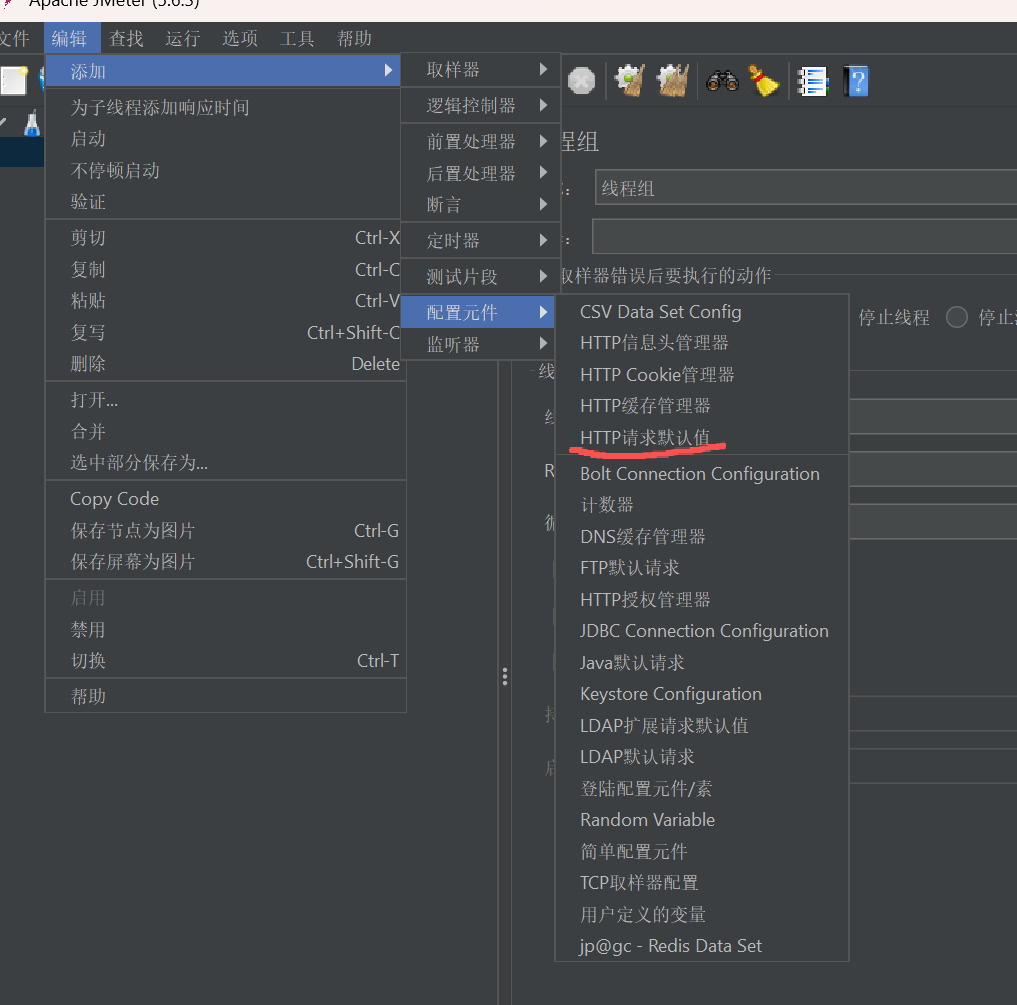
配置我们需要进行测试的程序协议、地址和端口
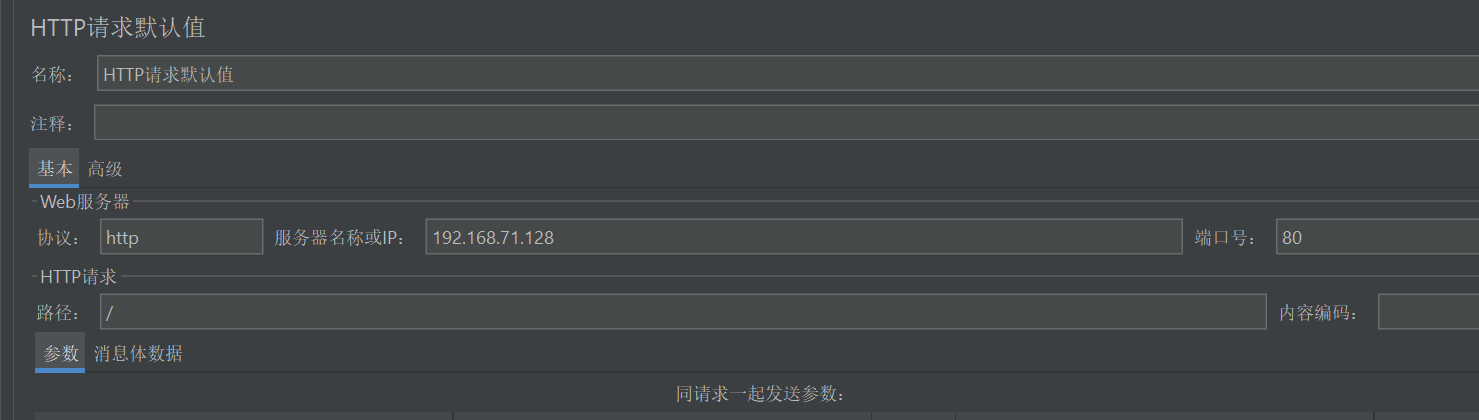
注意:当所有的接口测试的访问域名和端口都一样时,可以使用该元件,一旦服务器地址变更,只需要修改请求默认值即可
4.3、构造HTTP请求
在“线程组”右键【添加-】->【取样器】–>【HTTP请求】设置我们需要测试的API的请求路径和数据。
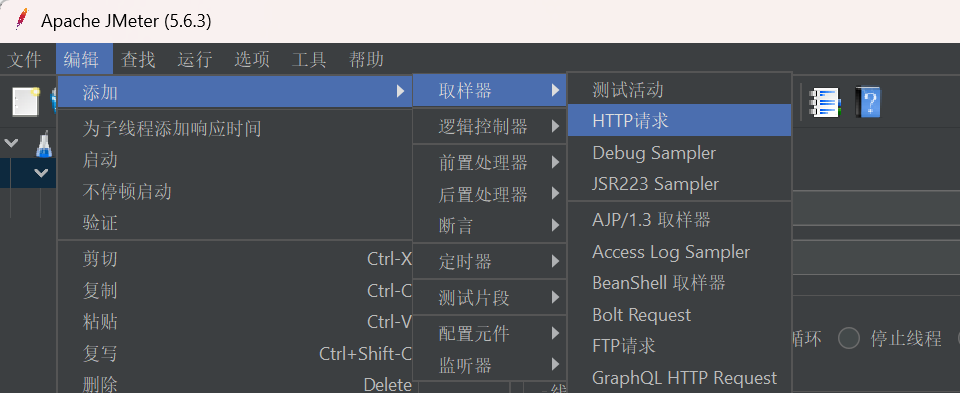
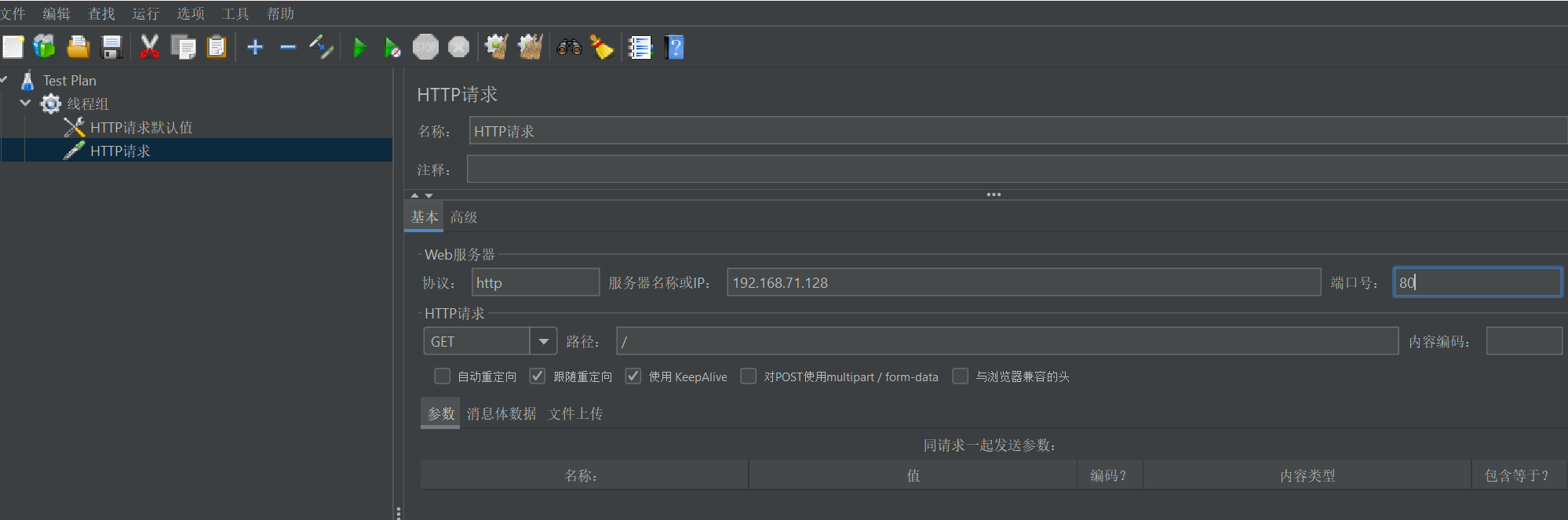
4.4、添加HTTP请求头
在我们刚刚创建的线程组上右键【添加】–>【配置元件】–>【HTTP信息头管理器】。
设置一个Content-Type:text/html
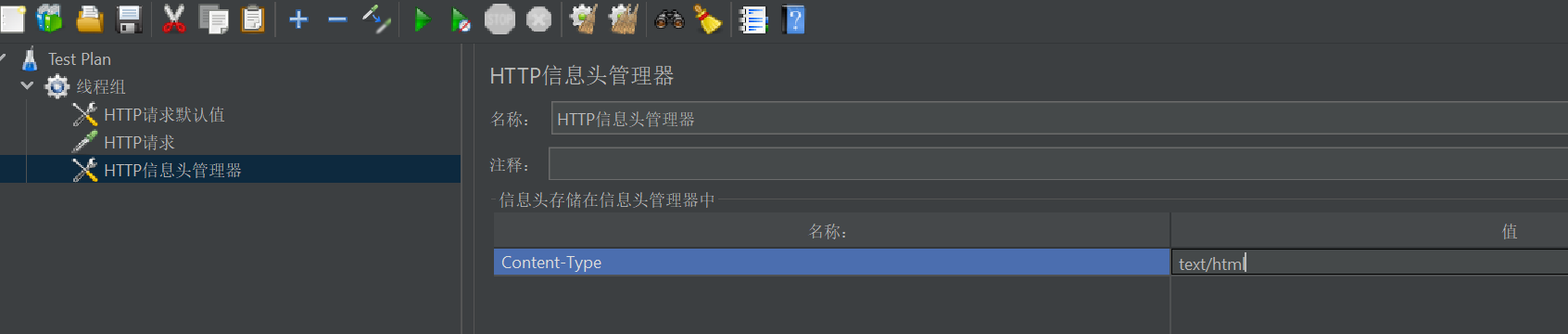
4.5、添加断言
-
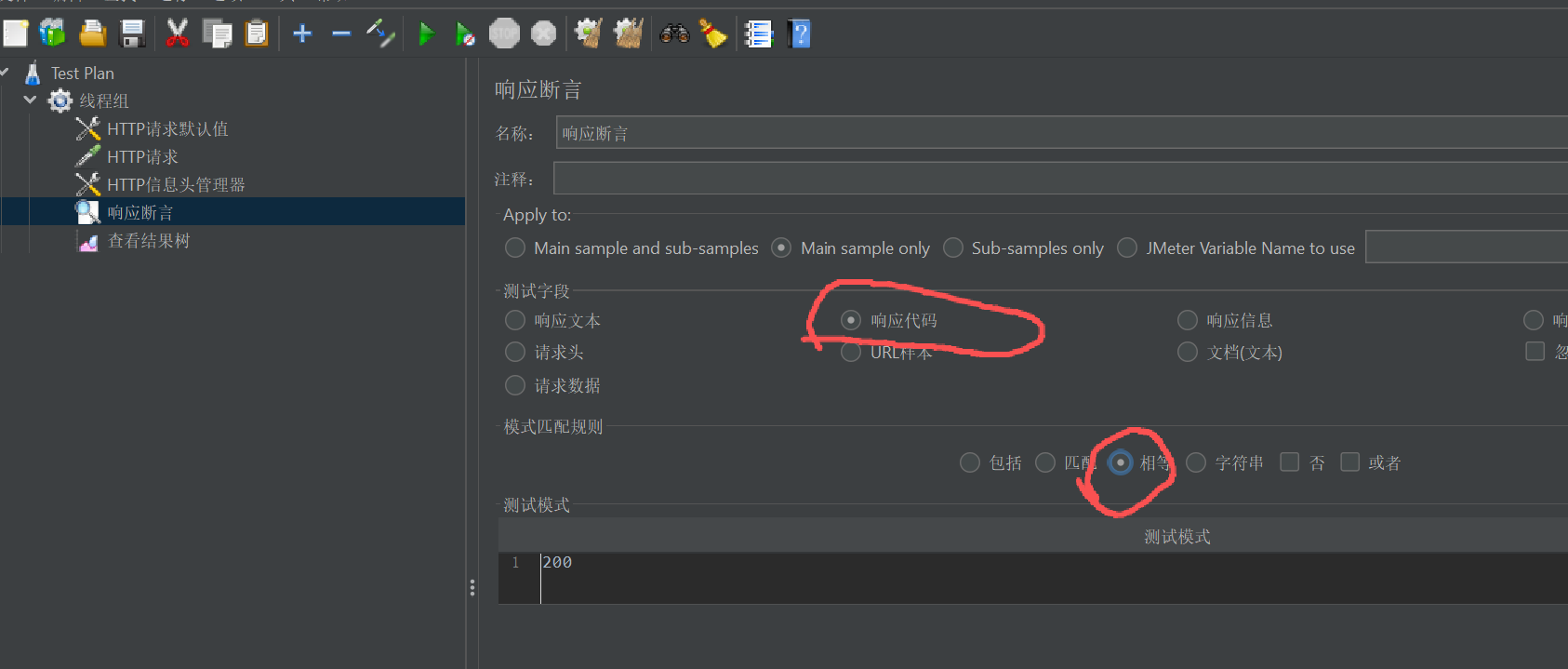
在我们刚刚创建的线程组上右键【添加】–>【断言】–>【响应断言】。
-
根据响应的数据来判断请求是否正常。我在这里只判断的响应代码是否为200。还可以配置错误信息
4.6、添加察看结果树
-
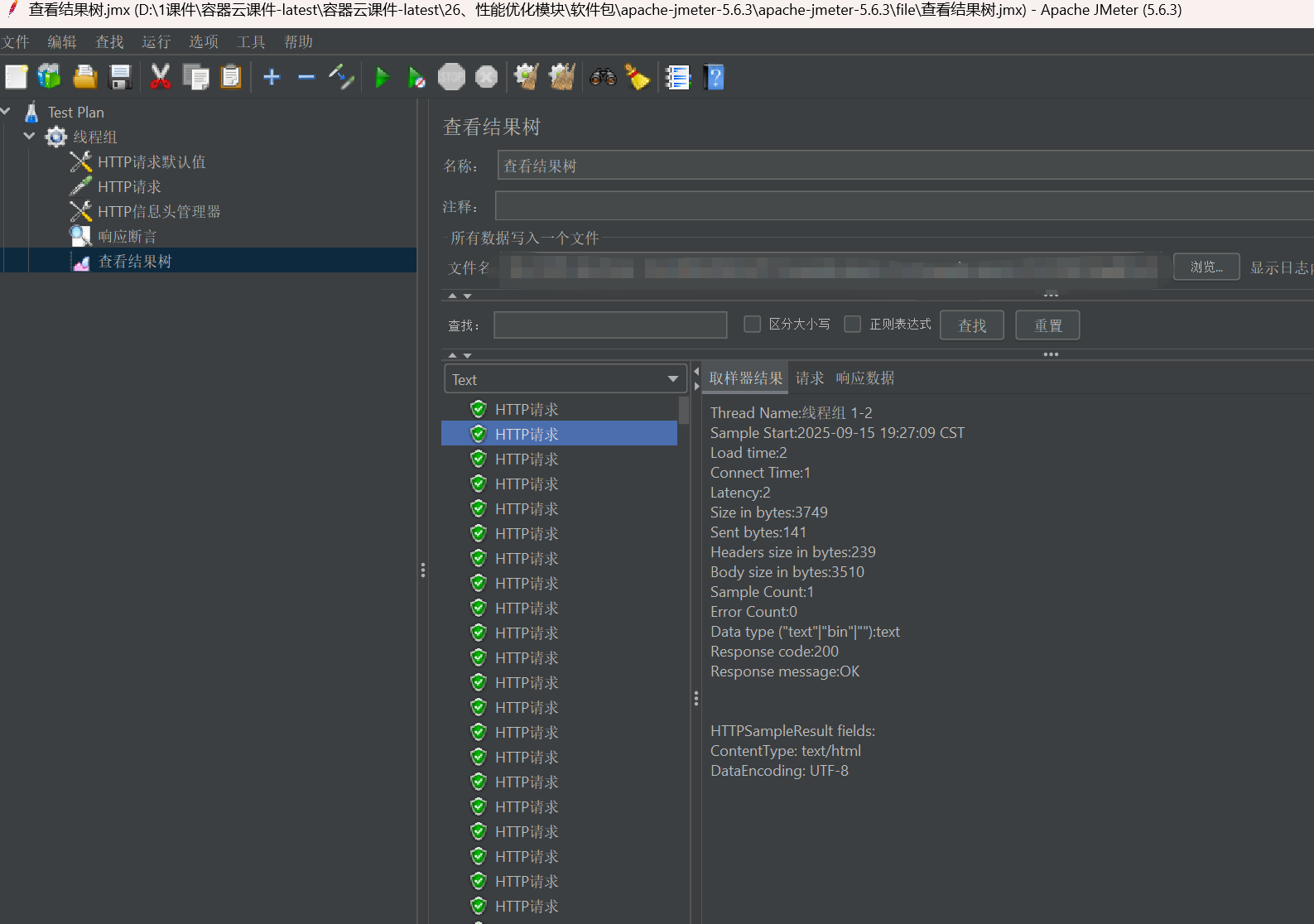
在我们刚刚创建的线程组上右键【添加】–>【监听器】–>【察看结果树】。
-
直接添加,然后点击运行按钮就可以看到结果了。
4.7、添加SummaryReport
-
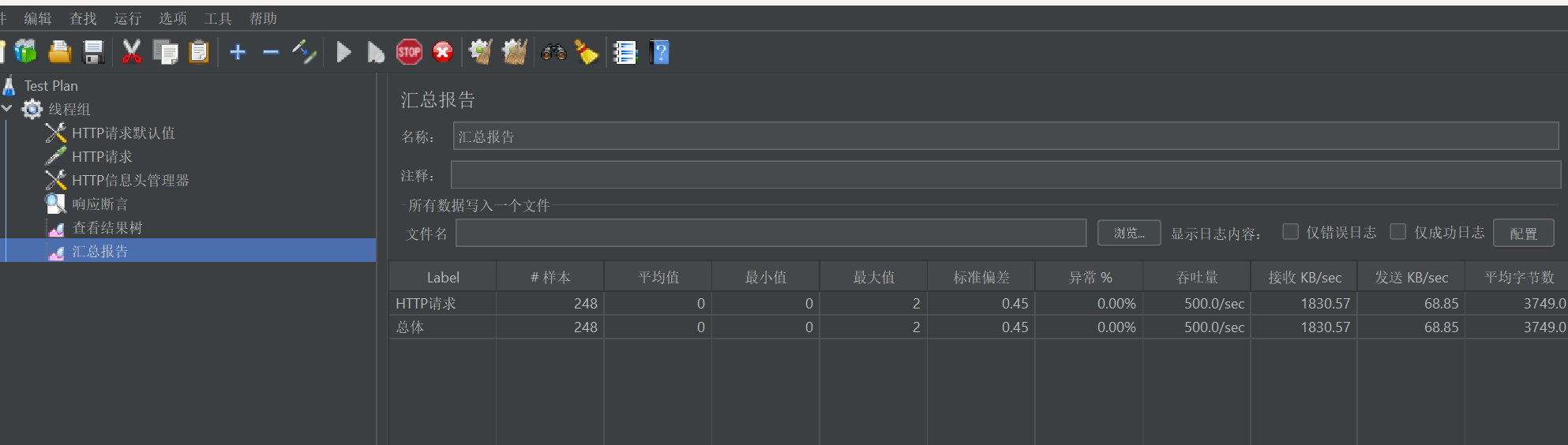
在我们刚刚创建的线程组上右键【添加】–>【监听器】–>【SummaryReport】。
-
直接添加,然后点击运行按钮就可以看到结果了。
4.8、测试计划创建完成
记得点保存,这时候会生成一个pem的文件
二.Nginx性能优化
1、当前系统结构瓶颈
首先需要了解的是当前系统瓶颈,用的是什么,跑的什么业务。里面的服务是什么样子,每个服务最大支持多少并发。比如针对Nginx而言,我们处理静态资源最高的瓶颈是多大。
可以通过查看当前cpu负荷,内存使用率,进程使用率来做简单判断。还可以通过操作系统的一些工具来判断当前系统性能瓶颈,如分析对应日志,查看请求数量。
也可以通过nginx vts模块来查看对应的来凝结数,总握手次数,总请求数。以对上线进行压力测试,来了解当前的系统的性能,并发数,做好性能评估。
2、了解业务模式
虽然我们是在做性能优化,但还是要熟悉业务,最终目的都是为了业务服务的。我们要了解每一个接口业务类型是什么样的业务,比如电子商务抢购模式,这种情况下平时流量会很小,但是到了抢购时间,流量一下子就会猛涨。也要了解系统层级结构,每一层中间层做的是代理还是动静分离,还是后台进行直接服务。需要我们对业务接入层和系统层次要有一个梳理。
3、系统与Nginx性能优化
大家对相关的系统瓶颈及现状有了一定的了解之后,就可以根据邮箱性能方面做一个全体的优化。
-
网络(网络流量、是否有丢包、网络的稳定性都会邮箱用户请求)
-
系统(系统负载、饱和、内存使用率、系统的稳定性、硬盘磁盘是否损坏)
-
服务(连接优化、内核性能优化、http服务请求优化都可以在nginx中根据业务来进行设置)
-
程序(接口性能、处理请求速度、每个程序的执行效率)
-
数据库、底层服务
上面列举出来每一级都会有关联,也会邮箱整体性能,这里主要关注的是Nginx服务这一层。
a、文件句柄
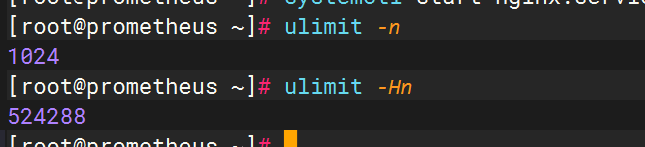
linux/unix,一切皆文件,每一次用户发起请求就会生成一个文件句柄,文件句柄可以理解为就是一个索引,所有文件句柄就会随着请求量的增多,而进程调用的频率增加,文件句柄的产生就会越多,系统对文件句柄默认的限制是1024个,对于nginx来说非常小了,需要改大一点
ulimit -n #可以查看系统设置的最大文件句柄
(1)设置方式
系统全局性修改
用户局部性修改
进程局部性修改
(2)系统全局性修改和用户局部性修改
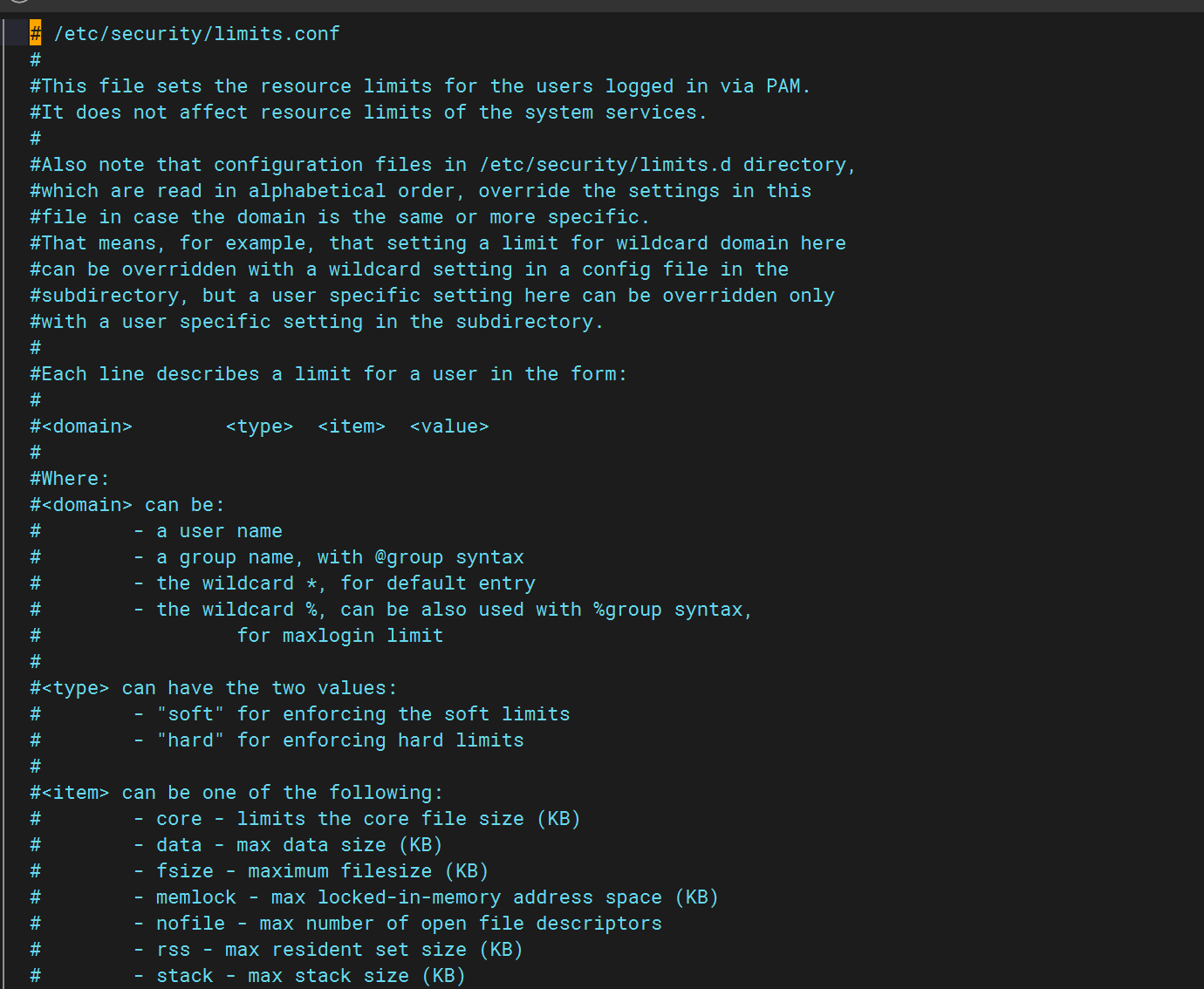
vim /etc/security/limits.conf
-
soft:软控制,到达设定值后,操作系统不会采取措施,只是发提醒
-
hard:硬控制,到达设定值后,操作系统会采取机制对当前进行进行限制,这个时候请求就会受到影响
-
root:这里代表root用户(系统全局性修改)*:代表全局,即所有用户都受此限制(用户局部性修改)
-
nofile:指限制的是文件数的配置项。后面的数字即设定的值,一般设置10000左右
尤其在企业新装的系统,这个地方应该根据实际情况进行设置,可以设置全局的,也可以设置用户
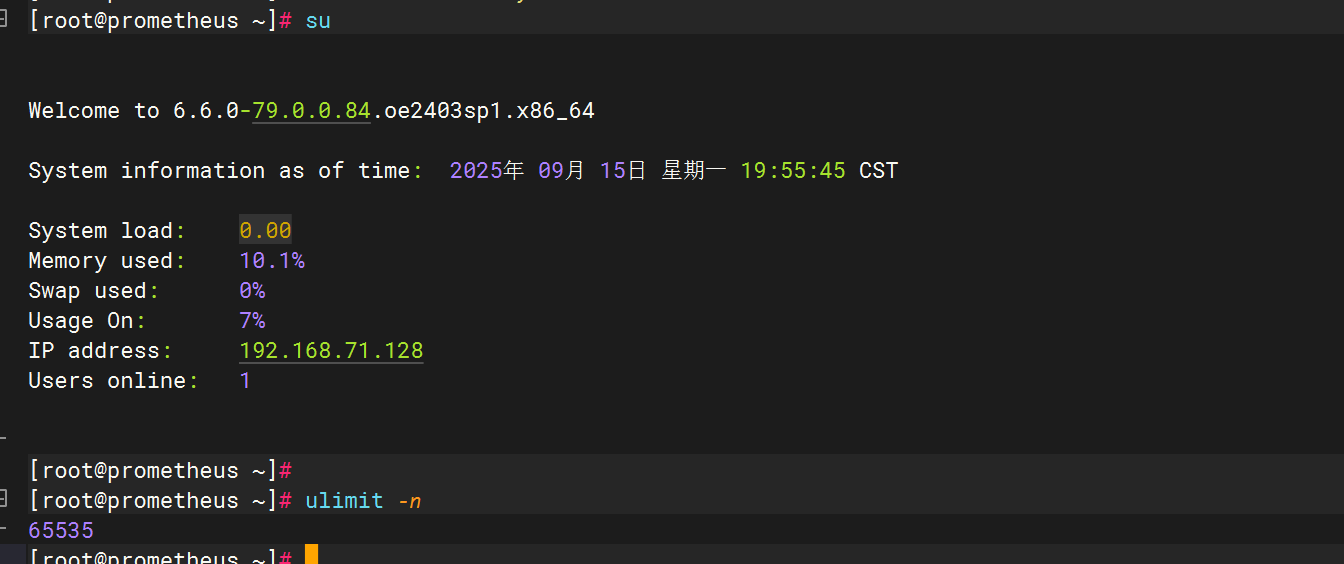
su #刷新以下环境
ulimit -n #再次查看系统最大文件句柄
(3)进程局部性修改
vim /etc/nginx/nginx.conf
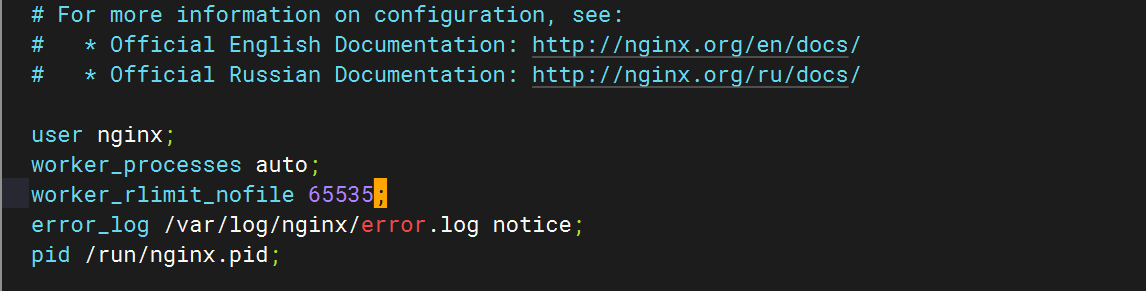
每个进程的最大文件打开数,所以最好与ulimit -n的值保持一致。
b、cpu的亲和配置
cpu的亲和能使nginx对于不同的work工作进程绑定到不同的cpu上面去。就能够减少在work间不断切换cpu,把进程通常不会在处理器之间频繁迁移,进程迁移的频率小,来减少性能损耗。
具体设置
Nginx允许工作进程个数一般设置CPU的核心或者核心数*2。如果不了解cpu核数,可以使用top后按1看出来,也可以查看/proc/cpuinfo文件
cat /proc/cpuinfo | grep ^processor | wc -l #查看cpu核数

随后进入nginx配置文件进行修改。需要知道的就是nginx 1.9版本之后,就帮我们自动绑定了cpu;
所以我们只需要打开cpu亲和就行
vim /etc/nginx/nginx.conf
user nginx;
worker_processes 4;
worker_cpu_affinity auto;
#当然也可以改为 worker_cpu_affinity 0001 0010 0100 1000;
worker_rlimit_nofile 65535;
worker_rlimit_nofile更改worker进程的最大打开文件数限制。如果没设置的话,这个值为操作系统的限制。设置后你的操作系统和Nginx可以处理比“ulimit -a”更多的文件,使用把这个值设高,这样nginx就不会由 “too many open files”问题了。
重启一下nginx,查看一下nginx worker进程绑定对应的cpu
ps -eo pid,args,psr | grep -v grep | grep nginx
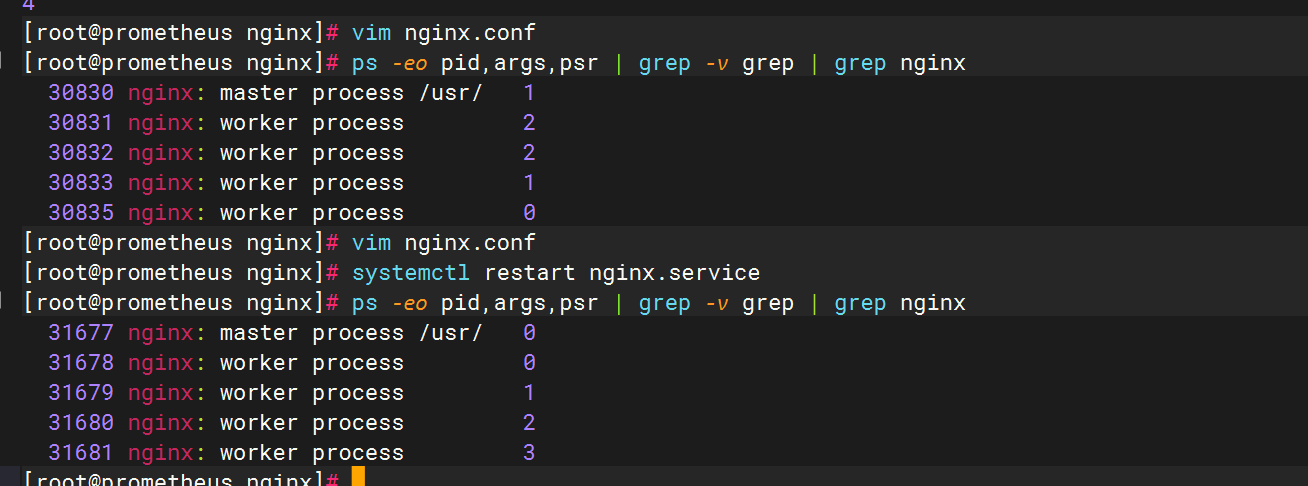
这样就能看到nginx的子进程都绑定到了哪些cpu核上。
c、事件处理模型优化
nginx的连接处理机制在于不同的操作系统会采用不同的I/O模型,Linux下,nginx使用epoll的I/O多路复用模型,在freebsd(类unix操作系统)使用kqueue的I/O多路复用模型,在Solaris(unix系统的一个重要分支操作系统)使用/dev/pool方式的I/O多路复用模型,在windows使用的icop等等。要根据系统类型不同选择不同的事物处理模型,我们使用的是centos,因此讲nginx的事件处理模型调整为epoll。
进入配置文件再进行修改
events {
worker_connections 10240;
multi_accept on;
use epoll;
}
multi_accept 告诉nginx收到一个新连接通知后接受尽可能多的连接,默认是on,设置为on后,多个worker按串行 方式来处理连接,也就是一个连接只有一个worker被唤醒,其他的处于休眠状态,设置为off后,多个worker按并行 方式来处理连接,也就是一个连接会唤醒所有的worker,直到连接分配完毕,没有取得连接的继续休眠。当你的服 务器连接数不多时,开启这个参数会让负载有一定的降低,但是当服务器的吞吐量很大时,为了效率,可以关闭这个参数。
d、设置work_connections连接数
work_connections表示每个worker(子进程)可以创建多少个连接,默认1024,最大是65535.
这里我自己改为10240(这个参数与服务器性能相关)
worker_connections 10240;
e、keepalive timeout会话保持时间
keepalive_timeout 65;
#keepalive其他的一些配置:
#keepalive:像上游服务器的保留连接数
#keepalive_disable:是指把某些浏览器禁用掉
#keepalive_requests:这个表示当我们建立一个可复用长连接,在当前这一个连接里可以并发接收多少个请求,默认1000个
#send_timeout:在向客户端发送数据时,建立好连接后,超过两次活动时间(服务器很长时间没有返回数据)那么就会将这个连接关掉
#keepalive_time:一个tcp连接的总时长,超过这个时间要再请求连接一下
这里先解释一下什么是keepalive,keepalive就是建立一下长连接,这个timeout就是,当浏览器建立一个连接之后,这个连接最长能存在多少时间不给他关闭,这个65也不是说建立65s连接后就直接关闭,而是一个活跃时间,就是第一次请求和下一次请求都会刷新这个65s,在65s内没有再请求数据才会真的关闭这个连接,所以这个时间也不应该太长,60s左右也差不多了。
f、GZIP压缩性能优化
gzip on; #表示开启压缩功能
gzip_min_length 1k; #表示允许压缩的页面最小字节数,页面字节数从header头的Content-Length中获取,默认值为0,表示不管页面多大都进行压缩,设置建议设大于1k。如果小于1k可能会越压越大。
gzip_buffers 4 32k; #压缩缓存区大小
gzip_http_version 1.1; #压缩版本
gzip_comp_level 6; #压缩比率,一般选择4-6,为了性能gzip_typs text/css text/xml application/javascript; #指>定压缩的类型 gzip_vary on; #vary header支持;
gzip_types text/plain text/css text/javascript application/json application/javascript;
gzip_vary on; #varyheader支持,改选项可以让前端的缓存服务器缓存经过GZIP压缩的页面,例如用Squid缓存经过nginx压缩的数据。
1.gzip_min_length 1k :设置允许压缩的页面最小字节数,页面字节数从header头的Content-Length中获取,默认值是0,不管页面多大都进行压缩,建议设置成大于1K,如果小与1K可能会越压越大。
2.gzip_buffers 4 32k :压缩缓冲区大小,表示申请4个单位为32K的内存作为压缩结果流缓存,默认值是申请与原始数据大小相同的内存空间来存储gzip压缩结果。
3.gzip_http_version 1.1 :压缩版本,用于设置识别HTTP协议版本,默认是1.1,目前大部分浏览器已经支持GZIP解压,使用默认即可。
4.gzip_comp_level 6 :压缩比例,用来指定GZIP压缩比,1压缩比最小,处理速度最快,9压缩比最大,传输速度快,但是处理慢,也比较消耗CPU资源。
5.gzip_types text/css text/xml application/javascript :用来指定压缩的类型,‘text/html’类型总是会被压缩。默认值: gzip_types text/html (默认不对js/css文件进行压缩),压缩类型,匹配MIME型进行压缩;
g、连接超时时间
其目的是保护服务器资源,cpu,内存没控制连接数,因为建立连接也是需要消耗资源的。
keepalive_timeout 60;
tcp_nodelay on;
client_header_buffer_size 4k;
open_file_cache max=102400 inactive=20s;
open_file_cache_valid 30s;
open_file_cache_min_uses 1;
client_header_timeout 15;
client_body_timeout 15;
reset_timedout_connection on;
send_timeout 15;
server_tokens off;
client_max_body_size 10m;
-
keepalived_timeout :客户端连接保持会话超时时间,超过这个时间,服务器断开这个链接。
-
tcp_nodelay:也是防止网络阻塞,不过要包涵在keepalive参数才有效。
-
client_header_buffer_size 4k:客户端请求头部的缓冲区大小,这个可以根据你的系统分页大小来设置,一般一个请求头的大小不会超过 1k,不过由于一般系统分页都要大于1k,所以这里设置为分页大小。分页大小可以用命令getconf PAGESIZE取得。
-
open_file_cache max=102400 inactive=20s :这个将为打开文件指定缓存,默认是没有启用的,max指定缓存数量,建议和打开文件数一致,inactive 是指经过多长时间文件没有被请求,后删除缓存。
-
open_file_cache_valid 30s:这个是指多长时间检查一次缓存的有效信息。
-
open_file_cache_min_uses 1 :open_file_cache指令中的inactive 参数时间内文件的最少使用次数,如果超过这个数字,文件描述符一直是在缓存中打开的,如上例,如果有一个文件在inactive 时间内一次没被使用,它将被移除。
-
client_header_timeout : 设置请求头的超时时间。我们也可以把这个设置低些,如果超过这个时间没有发送任何数据,nginx将返回request time out的错误。
-
client_body_timeout设置请求体的超时时间。我们也可以把这个设置低些,超过这个时间没有发送任何数据,和上面一样的错误提示。
-
reset_timeout_connection :告诉nginx关闭不响应的客户端连接。这将会释放那个客户端所占有的内存空间。
-
send_timeout :响应客户端超时时间,这个超时时间仅限于两个活动之间的时间,如果超过这个时间,客户端没有任何活动,nginx关闭连接。
-
server_tokens :并不会让nginx执行的速度更快,但它可以关闭在错误页面中的nginx版本数字,这样对于安全性是有好处的。
-
client_max_body_size:上传文件大小限制。
h、proxy超时设置
proxy_connect_timeout 90; #后端服务器连接的超时时间,发起握手等候响应超时时间
proxy_send_timeout 90; #后端服务器数据回传时间,就是在规定时间内后端服务器必须传完所有的数据
proxy_read_timeout 90; #连接成功后,等候后端服务器响应时间,其实已经进入后端的排队之中等候处理(也可以说是后端服务器处理请求的时间,页面等待服务器响应时间)
proxy_buffers 4 32k; #4是数量 32k是大小 该指令设置缓存区的大小和数量,从被代理的后端服务器取得的第一部分响应内容,会放置到这里,默认情况下,一个缓存区的大小等于内存页面大小,可能是4k也可能是8k取决于平台
proxy_busy_buffers_size 64k; #nginx在收到服务器数据后,会分配一部分缓冲区来用于向客户端发送数据,这个缓存区大小由proxy_busy_buffers_size决定的。大小通常是proxy_buffers单位大小的两倍,官网默认是8k/16k。
buffer工作原理
1.所有的proxy buffer参数都是作用到每一个请求的。每一个全球有会按照参数的配置获得自己的buffer。proxy buffer不是global(全局配置),而是per request(在请求前执行的操作(如时间戳、签名))的
2、proxy_buffering是为了开启response buffering of the proxied server(反向代理服务器响应数据的缓存),开启后proxy_buffers和proxy_busy_buffers_size参数才会起作用
3、无论peoxy_buffer是否开启,proxy_buffer_size都是工作的,proxy_buffer_size所设置的buffer_size的作用是用来存储upstream端response的header。
4、在proxy_buffering 开启的情况下,Nginx将会尽可能的读取所有的upstream端传输的数据到buffer,直到proxy_buffers设置的所有buffer们被写满或者数据被读取完(EOF)。此时nginx开始向客户端传输数据,会同时传输这一整串buffer们。同时如果response的内容很大的话,Nginx会接收并把他们写入到temp_file里去。大小由proxy_max_temp_file_size控制。如果busy的buffer传输完了会从temp_file里面接着读数据,直到传输完毕。
5、一旦proxy_buffers设置的buffer被写入,直到buffer里面的数据被完整的传输完(传输到客户端),这个buffer将会一直处在busy状态,我们不能对这个buffer进行任何别的操作。所有处在busy状态的buffer size加起来不能超过proxy_busy_buffers_size,所以proxy_busy_buffers_size是用来控制同时传输到客户端的buffer数量的。
i、proxy_set_header
proxy_set_header用来设定被代理服务器接收到的header信息。
语法:proxy_set_header field value;
-
field :为要更改的项目,也可以理解为变量的名字,比如host
-
value :为变量的值
-
如果不设置proxy_set_header,则默认host的值为proxy_pass后面跟的那个域名或者IP(一般写IP)
proxy_set_header X-Real-IP $remote_addr;和proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
用来设置被代理端接收到的远程客户端IP,如果不设置,则header信息中并不会透传远程真实客户端的IP地址。
j、高效传输模式
sendfile on; #开启高效文件传输模式。
tcp_nopush on;#需要在sendfile开启模式才有效,防止网络阻塞,积极的减少网络报文段的数量。将响应头和正文的开始部分一起发送,而不是一个接一个的发送(也就是说数据包不会马上传出等到数据包最大时一次性传)
tcp_nodelay on; #只要有数据包产生,不管大小多少,就尽快传输
k、fastcgi调优
fastcgi_connect_timeout 600;
fastcgi_send_timeout 600;
fastcgi_read_timeout 600;
fastcgi_buffer_size 64k;
fastcgi_buffers 4 64k;
fastcgi_busy_buffers_size 128k;
fastcgi_temp_file_write_size 128k;
fastcgi_temp_path /usr/local/nginx1.22/nginx_tmp;
fastcgi_intercept_errors on;
fastcgi_cache_path/usr/local/nginx1.22/fastcgi_cache levels=1:2
keys_zone=cache_fastcgi:128minactive=1d max_size=10g;
-
fastcgi_connect_timeout 600 :指定连接到后端FastCGI的超时时间。
-
fastcgi_send_timeout 600 :向FastCGI传送请求的超时时间。
-
fastcgi_read_timeout 600 :指定接收FastCGI应答的超时时间。
-
fastcgi_buffer_size 64k :指定读取FastCGI应答第一部分需要用多大的缓冲区,默认的缓冲区大小为。fastcgi_buffers指令中的每块大小,可以将这个值设置更小。
-
fastcgi_buffers 4 64k :指定本地需要用多少和多大的缓冲区来缓冲FastCGI的应答请求,如果一个php脚本所产生的页面大小为256KB,那么会分配4个64KB的缓冲区来缓存,如果页面大小大于256KB,那么大于256KB的部分会缓存到fastcgi_temp_path指定的路径中,但是这并不是好方法,因为内存中的数据处理速度要快于磁盘。一般这个值应该为站点中php脚本所产生的页面大小的中间值,如果站点大部分脚本所产生的页面大小为256KB,那么可以把这个值设置为“8 32K”、“4 64k”等。
-
fastcgi_busy_buffers_size 128k :建议设置为fastcgi_buffers的两倍,繁忙时候的buffer。
-
fastcgi_temp_file_write_size 128k :在写入fastcgi_temp_path时将用多大的数据块,默认值是fastcgi_buffers的两倍,该数值设置小时若负载上来时可能报502BadGateway。
-
fastcgi_temp_path :缓存临时目录。
-
fastcgi_intercept_errors on :这个指令指定是否传递4xx和5xx错误信息到客户端,或者允许nginx使用error_page处理错误信息。注:静态文件不存在会返回404页面,但是php页面则返回空白页!
-
fastcgi_cache_path /usr/local/nginx1.10/fastcgi_cachelevels=1:2 keys_zone=cache_fastcgi:128minactive=1d max_size=10g :fastcgi_cache缓存目录,可以设置目录层级,比如1:2会生成16*256个子目录,cache_fastcgi是这个缓存空间的名字,cache是用多少内存(这样热门的内容nginx直接放内存,提高访问速度),inactive表示默认失效时间,如果缓存数据在失效时间内没有被访问,将被删除,max_size表示最多用多少硬盘空间。
-
fastcgi_cache cache_fastcgi :#表示开启FastCGI缓存并为其指定一个名称。开启缓存非常有用,可以有效降低CPU的负载,并且防止502的错误放生。cache_fastcgi为proxy_cache_path指令创建的缓存区名称。
-
fastcgi_cache_valid 200 302 1h :#用来指定应答代码的缓存时间,实例中的值表示将200和302应答缓存一小时,要和fastcgi_cache配合使用。
-
fastcgi_cache_valid 301 1d :将301应答缓存一天。
-
fastcgi_cache_valid any 1m :将其他应答缓存为1分钟。
-
fastcgi_cache_min_uses 1 :该指令用于设置经过多少次请求的相同URL将被缓存。
-
fastcgi_cache_key http://host hosthostrequest_uri :该指令用来设置web缓存的Key值,nginx根据Key值md5哈希存储.一般根据h o s t ( 域 名 ) 、 host(域名)、host(域名)、request_uri(请求的路径)等变量组合成proxy_cache_key 。
-
fastcgi_pass :指定FastCGI服务器监听端口与地址,可以是本机或者其它。
总结:
nginx的缓存功能有:proxy_cache / fastcgi_cache
-
proxy_cache的作用是缓存后端服务器的内容,可能是任何内容,包括静态的和动态。
-
fastcgi_cache的作用是缓存fastcgi生成的内容,很多情况是php生成的动态的内容。
-
proxy_cache缓存减少了nginx与后端通信的次数,节省了传输时间和后端宽带。
-
fastcgi_cache缓存减少了nginx与php的通信的次数,更减轻了php和数据库(mysql)的压力。
l、访问限流
我们构建网站是为了让用户访问它们,我们希望用于合法访问。所以不得不采取一些措施限制滥用访问的用户。这种滥用指的是从同一IP每秒到服务器请求的连接数。因为这可能是在同一时间内,世界各地的多台机器上的爬虫机器人多次尝试爬取网站的内容。
#限制用户连接数来预防DOS攻击
limit_conn_zone $binary_remote_addr zone=perip:10m;
limit_conn_zone $server_name zone=perserver:10m;
#限制同一客户端ip最大并发连接数
limit_conn perip 2;
#限制同一server最大并发连接数
limit_conn perserver 20;
#限制下载速度,根据自身服务器带宽配置
limit_rate 300k;
4、内核参数优化
vim /etc/sysctl.conf #进入这个文件修改
sysctl -p #让修改的内核信息生效#################################################fs.file-max = 999999
net.ipv4.ip_forward = 0
net.ipv4.conf.default.rp_filter = 1
net.ipv4.conf.default.accept_source_route = 0
kernel.sysrq = 0
kernel.core_uses_pid = 1
net.ipv4.tcp_syncookies = 1
kernel.msgmnb = 65536
kernel.msgmax = 65536
kernel.shmmax = 68719476736
kernel.shmall = 4294967296
net.ipv4.tcp_max_tw_buckets = 6000
net.ipv4.tcp_sack = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_rmem = 10240 87380 12582912
net.ipv4.tcp_wmem = 10240 87380 12582912
net.core.wmem_default = 8388608
net.core.rmem_default = 8388608
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.core.netdev_max_backlog = 262144
net.core.somaxconn = 40960
net.ipv4.tcp_max_orphans = 3276800
net.ipv4.tcp_max_syn_backlog = 262144
net.ipv4.tcp_timestamps = 0
net.ipv4.tcp_synack_retries = 1
net.ipv4.tcp_syn_retries = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_mem = 94500000 915000000 927000000
net.ipv4.tcp_fin_timeout = 1
net.ipv4.tcp_keepalive_time = 30
net.ipv4.ip_local_port_range = 1024 65000-
fs.file-max = 999999:这个参数表示进程(比如一个worker进程)可以同时打开的最大句柄数,这个参数直线限制最大并发连接数,需根据实际情况配置。
-
net.ipv4.tcp_max_tw_buckets = 6000 :这个参数表示操作系统允许TIME_WAIT套接字数量的最大值,如果超过这个数字,TIME_WAIT套接字将立刻被清除并打印警告信息。该参数默认为180000,过多的TIME_WAIT套接字会使Web服务器变慢。注:主动关闭连接的服务端会产生TIME_WAIT状态的连接
-
net.ipv4.ip_local_port_range = 1024 65000 :允许系统打开的端口范围。
-
net.ipv4.tcp_tw_recycle = 1 :启用timewait快速回收。
-
net.ipv4.tcp_tw_reuse = 1 :开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接。这对于服务器来说很有意义,因为服务器上总会有大量TIME-WAIT状态的连接。
-
net.ipv4.tcp_keepalive_time = 30:这个参数表示当keepalive启用时,TCP发送keepalive消息的频度。默认是2小时,若将其设置的小一些,可以更快地清理无效的连接。
-
net.ipv4.tcp_syncookies = 1 :开启SYN Cookies,当出现SYN等待队列溢出时,启用cookies来处理。
-
net.core.somaxconn = 40960 :web 应用中 listen 函数的 backlog 默认会给我们内核参数的。
-
net.core.somaxconn :限制到128,而nginx定义的NGX_LISTEN_BACKLOG 默认为511,所以有必要调整这个值。注:对于一个TCP连接,Server与Client需要通过三次握手来建立网络连接.当三次握手成功后,我们可以看到端口的状态由LISTEN转变为ESTABLISHED,接着这条链路上就可以开始传送数据了.每一个处于监听(Listen)状态的端口,都有自己的监听队列.监听队列的长度与如somaxconn参数和使用该端口的程序中listen()函数有关。somaxconn定义了系统中每一个端口最大的监听队列的长度,这是个全局的参数,默认值为128,对于一个经常处理新连接的高负载 web服务环境来说,默认的 128 太小了。大多数环境这个值建议增加到 1024 或者更多。大的侦听队列对防止拒绝服务 DoS 攻击也会有所帮助。
-
net.core.netdev_max_backlog = 262144 :每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目。
-
net.ipv4.tcp_max_syn_backlog = 262144 :这个参数标示TCP三次握手建立阶段接受SYN请求队列的最大长度,默认为1024,将其设置得大一些可以使出现Nginx繁忙来不及accept新连接的情况时,Linux不至于丢失客户端发起的连接请求。
-
net.ipv4.tcp_rmem = 10240 87380 12582912 :这个参数定义了TCP接受缓存(用于TCP接受滑动窗口)的最小值、默认值、最大值。
-
net.ipv4.tcp_wmem = 10240 87380 12582912:这个参数定义了TCP发送缓存(用于TCP发送滑动窗口)的最小值、默认值、最大值。
-
net.core.rmem_default = 6291456:这个参数表示内核套接字接受缓存区默认的大小。
-
net.core.wmem_default = 6291456:这个参数表示内核套接字发送缓存区默认的大小。
-
net.core.rmem_max = 12582912:这个参数表示内核套接字接受缓存区的最大大小。
-
net.core.wmem_max = 12582912:这个参数表示内核套接字发送缓存区的最大大小。
-
net.ipv4.tcp_syncookies = 1:该参数与性能无关,用于解决TCP的SYN攻击。
三.Redis调优
1.最大物理内存
设置Redis使用的最大物理内存,即Redis在占用maxmemory大小的内存之后就开始拒绝后续的写入请求,该参数可以确保Redis因为使用了大量内存严重影响速度或者发生OOM(out-of-memory,发现内存不足时,它会选择杀死一些进程(用户态进程,不是内核线程),以便释放内存)。
此外,可以使用info命令查看Redis占用的内存及其它信息
# maxmemory <bytes>
2.键名简短(存储key)
键的长度越长,Redis需要存储的数据也就越多
3.请求超时时间
设置超时时间,防止无用的连接占用资源。设置如下命令:
//redis配置文件调整
timeout 150
tcp-keepalive 150 (定时向client发送tcp_ack包来探测client是否存活的。默认不探测)//项目优化调整
redis.timeout=10s
4.数据持久化策略
数据磁盘尽可能减少性能损坏,以空间换时间。设置如下命令:
//对于存储到磁盘中的快照,可以设置是否进行压缩存储。如果是的话,redis会采用LZF算法进行压缩。如果
//你不想消耗CPU来进行压缩的话,可以设置为关闭此功能,但是存储在磁盘上的快照会比较大。
rdbcompression no : 默认值是yes//在存储快照后,我们还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消
//耗,如果希望获取到最大的性能提升,可以关闭此功能。
rdbchecksum no : 默认值是yes。
5.优化AOF和RDB
减少占用CPU时间 主库可以不进行dump操作或者降低dump频率。 取消AOF持久化。
appendonly no
6.监控客户端的连接
因为Redis是单线程模型(只能使用单核),来处理所有客户端的请求,但由于客户端连接数的增长, 处理请求的线程资源开始降低分配给单个客户端连接的处理时间
7.限制客户端连接数
在Redis-cli工具中输入info clients可以查看到当前实例的所有客户端连接信息
//可以通过在Redis-cli工具上输入 config set maxclients去设置最大连接数。根据连接数负载的情况
maxclients 10000
四.Redis性能优化
-
避免慢查询命令
当发现redis性能变慢的时候,可以通过redis日志,或者是latency monitor工具,查询变慢的请求,根据请求对应的具体命令以及官方文档,确认下是否采用了复杂度高的查询,如果确实存在大量的慢查询命令则优化
-
用其他高效的命令替代
-
eg:当需要返回一个set中的所有成员时,使用sscan多次迭代返回代替smembers(避免一次返回大量数据,造成线程阻塞)
-
当需要执行排序、并集、交集操作时,可以在客户端完成,而不要使用sort、sunion、sinter这些命令,以拖慢redis实例
-
-
生产环境禁用keys命令
keys命令是慢查询命令,因为keys命令需要遍历存储的键值对,所以操作的时延很高,在生产环境使用可能导致redis阻塞
-
keys需要设置过期时间
redis作为内存数据库,一切的数据都是在内存中,一旦内存占用过大则会大大影响性能。因此需要设置过期时间,这样redis能够定时的删除过期的数据
-
禁止批量的给keys设置相同的过期时间
默认情况下,Redis每100毫秒会删除一些过期key
-
采样ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP个数的key,并将其中过期的key全部删除
-
如果超过25%的key过期了,则重复删除过程,直到过期key的比例降至25%以下
ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP是redis的一个参数,默认是20,一秒内基本有200个过期key会被删除。这一策略对清除过期key、释放内存空间很有帮助,而且并不会对redis的性能造成太大的影响
-
但是如果触发了第2条,redis就会一直删除以释放内存空间。删除操作是阻塞的(redis4.0后可以用异步线程机制来减少阻塞影响)所以,一旦该条件触发,redis的线程就会一直执行删除,会导致无法正常呢服务其他键值操作,就会进一步引起其他键值操作的延迟增加,redis就会变慢。
-
频繁使用带有相同时间参数的EXPIRE命令设置过期key将会触发第2条,这就会导致在一秒内存在大量的keys过期
-
-
-
谨慎选择数据结构
redis常用的数据结构一共有5种:string、hash、list、set、zset
扩展类型
-
string:单个的缓存结果,不与其他的KV之间有联系
-
hash:一个Object包含很多属性,且这些属性需要单独存储。这种情况下如果使用string会占据更多的内存
-
list:一个Object包含很多数据,且这些数据允许重复、要求有顺序性
-
set:一个Object包含很多数据,不要求数据有顺序,旦不允许重复
-
zset:一个Object包含很多数据,且这些数据自身还包含一个权重值,可以利用这个权重值来排序
-
HyperLogLog:适用于基数统计,比如PV,UV的统计,存在误差,不适合精确统计
-
BitMap:适合二值状态的统计,比如签到打卡,要么打卡了,要么未打卡
-
-
检查持久化策略
由于写入磁盘有IO性能瓶颈,因此不是将redis作为数据库的话(可以从后端恢复),建议禁用持久化或者调整持久化策略
-
AOF日志:采用文件追加的方式将命令记录在日志中的策略
-
RDB快照:以快照的方式,将某一时刻的内存数据,以二进制的方式写入磁盘
-
AOF和RDB混用:结合两种各自的优点,在RDB快照的时间段内使用AOF日志记录这段时间操作的命令,这样一旦发生宕机,将不会丢失两段快照中间的数据
-
-
采用高速的固态硬盘作为日志写入设备
由于AOF日志的重写对磁盘的压力较大,可能会阻塞,如果需要使用到持久化,建议使用高速的固态硬盘作为日志写入设备
-
使用物理机而非虚拟机
由于虚拟机增加了虚拟化软件层,与物理机相比,虚拟机本身就存在性能的开销
-
增加机器内存或使用redis集群
物理机器的内存不足将会导致操作系统内存的swap
-
内存swap是操作系统里将内存数据在内存和磁盘间来回换入和换出的机制、涉及到磁盘的读写,所以一旦触发swap,无论是被换入数据的进程,还是被换出数据的进程,其性能都会受到慢速磁盘读写的影响
-
redis是内存数据库,内存使用量大,如果没有控制好内存的使用量,或者其他内存需求大的应用一起运行了,就可能受到swap的影响,从而导致性能变慢
-
正常情况下,redis的操作是直接通过访问内存就能完成,一旦swap被触发了,redis的请求操作需要等到磁盘数据读写完成才行。swap触发后影响的是redis主io线程,这会极大地增加redis的响应时间
因此增加机器的内存或者使用redis集群能够有效的解决操作系统内存的swap,提高性能
-
-
使用Pipeline批量操作数据
Pipeline(管道技术)是客户端提供的一种批处理技术,用于一次处理多个redis命令,从而提高整个交互的性能
-
客户端优化使用
在客户端的使用上除了要尽量使用Pipeline的技术外,还需要注意尽量使用redis连接池,而不是频繁创建和销毁redis连接,这样可以减少网络传输的次数和减少了非必要调用指令
-
使用分布式架构来增加读写速度
-
主从复制
使用主从同步功能我们可以把写入放在主库上执行,把读功能转移到从服务上,因此就可以在单位时间内处理更多的请求,从而提升redis的整体运行速度
-
哨兵模式
此模式是对主从功能的升级,当主节点奔溃之后,无需人工干预就能自动恢复redis的正常使用
-
redis cluster集群
redis cluster是首选方案,它可以把读写压力自动的分担给更多的服务器,并且具有自动容灾的能力
-
通过将数分散存储到多个节点上,来平衡各个节点的负载压力
-
采用虚拟哈希槽分区,所有的键根据哈希函数映射到0~16383整数槽内,计算公式:slot = CRC16(key) & 16383,每一个节点负责维护一部分槽以及槽所映射的键值数据,这样redis就可以把读写压力从一台服务器,分散给多台服务器,大大的提高性能
-
-
-
避免内存碎片
频繁的新增修改会导致内存碎片增多,因此需要时刻的清理内存碎片
redis查看内存的使用信息的命令:INFO memory
当men_fragmentation_ratio大于1.5,这表明内存碎片率已经超过了50%,这个时候需要采取一些措施来降低内存碎片率
-
men_fragmentation_ratio:内存碎片率
-
used_memory_rss:操作系统实际分配给redis的物理内存空间
-
used_memory:redis为了保存数据实际申请使用的空间
-
五.MySQL 8.0.41 InnoDB引擎优化字段
以下是MySQL 8.0.41版本中InnoDB引擎的主要优化相关字段和参数:
性能优化相关字段
-
innodb_buffer_pool_size - InnoDB缓冲池大小,用于缓存表数据和索引
-
innodb_buffer_pool_instances - 缓冲池实例数量,提高并发性能
-
innodb_io_capacity - I/O容量设置,影响后台操作速度
-
innodb_io_capacity_max - 最大I/O容量
-
innodb_read_io_threads - 读I/O线程数
-
innodb_write_io_threads - 写I/O线程数
-
innodb_thread_concurrency - 并发线程数限制
-
innodb_adaptive_hash_index - 自适应哈希索引开关
事务优化相关字段
-
innodb_flush_log_at_trx_commit - 事务提交时日志刷新方式
-
innodb_sync_spin_loops - 自旋等待次数
-
innodb_spin_wait_delay - 自旋等待延迟
-
innodb_lock_wait_timeout - 锁等待超时时间
-
innodb_deadlock_detect - 死锁检测开关
日志和恢复优化
-
innodb_log_file_size - 重做日志文件大小
-
innodb_log_files_in_group - 重做日志文件数量
-
innodb_log_buffer_size - 日志缓冲区大小
-
innodb_flush_neighbors - 邻接页刷新优化
-
innodb_doublewrite - 双写缓冲开关
内存优化
-
innodb_buffer_pool_dump_at_shutdown - 关闭时保存缓冲池状态
-
innodb_buffer_pool_load_at_startup - 启动时加载缓冲池状态
-
innodb_change_buffer_max_size - 变更缓冲最大大小
其他优化参数
-
innodb_adaptive_flushing - 自适应刷新控制
-
innodb_page_cleaners - 页面清理线程数
-
innodb_purge_threads - 清除操作线程数
-
innodb_read_ahead_threshold - 预读阈值
-
innodb_random_read_ahead - 随机预读开关
-
innodb_stats_persistent - 持久化统计信息
-
innodb_stats_auto_recalc - 自动重新计算统计信息
这些参数可以通过MySQL配置文件(my.cnf/my.ini)或运行时SET GLOBAL命令进行调整,以优化InnoDB引擎的性能表现。
六. 总结
本文系统介绍了主流系统组件的性能优化方法:1.JMeter压力测试工具的使用方法,包括线程组配置、HTTP请求构建、结果分析等;2.Nginx的多维度优化策略,涵盖文件句柄、CPU亲和、事件模型、连接数、缓存压缩等;3.Redis的调优技巧,包括内存管理、数据结构选择、持久化策略、集群部署等;4.MySQL InnoDB引擎的关键优化参数,涉及缓冲池、I/O线程、日志系统等。通过针对性的优化配置,可显著提升系统整体性能,保障高并发场景下的服务稳定性。