PPO算法-强化学习
一、定义
- 定义
- PPO 自定义模型
- 参数解释
- 训练时数据采集与训练
二、实现
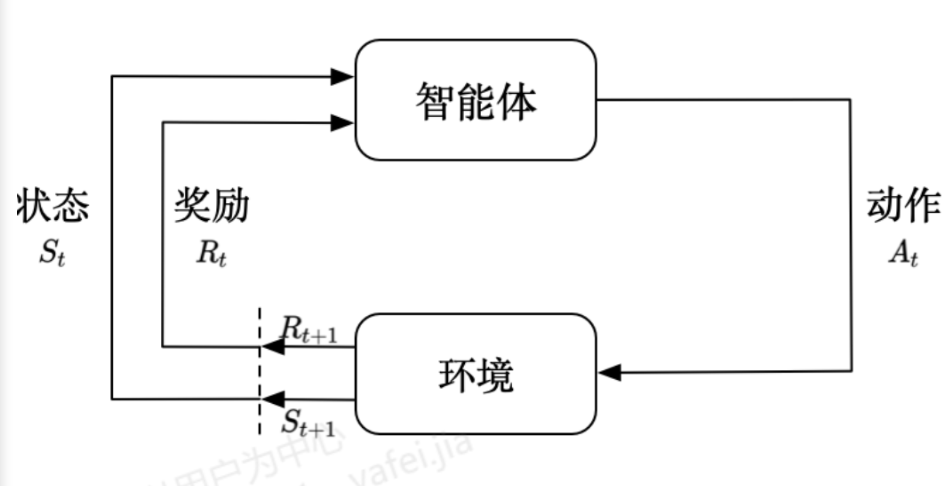
强化学习示意图
- 定义
PPO 的模型 = 一个深度神经网络,既当“Actor”(输出动作分布),又当“Critic”(输出状态价值),通过策略梯度 + 剪切更新(Clipped Update)来学习最优策略。

- PPO 自定义模型
import torch as th
import torch.nn as nn
import gym
import numpy as np
from stable_baselines3 import PPO
from stable_baselines3.common.torch_layers import BaseFeaturesExtractor# ===============================
# 自定义特征提取器: CNN + MLP 融合
# ===============================
class CNN_MLP_Extractor(BaseFeaturesExtractor):def __init__(self, observation_space: gym.spaces.Dict, features_dim: int = 256):# observation_space 是字典,包括:# "image": Box(...)# "params": Box(...)super(CNN_MLP_Extractor, self).__init__(observation_space, features_dim)# ---- CNN 分支 (处理图像输入) ----n_input_channels = observation_space["image"].shape[0] # e.g. 1 或 3self.cnn = nn.Sequential(nn.Conv2d(n_input_channels, 32, kernel_size=3, stride=2, padding=1),nn.ReLU(),nn.Conv2d(32, 64, kernel_size=3, stride=2, padding=1),nn.ReLU(),nn.Conv2d(64, 128, kernel_size=3, stride=2, padding=1),nn.ReLU(),nn.Flatten(),)# 计算 CNN 输出维度with th.no_grad():sample_img = th.as_tensor(observation_space["image"].sample()[None]).float()cnn_out_dim = self.cnn(sample_img).shape[1]# ---- MLP 分支 (处理工艺参数输入) ----params_dim = observation_space["params"].shape[0]self.mlp = nn.Sequential(nn.Linear(params_dim, 64),nn.ReLU(),nn.Linear(64, 64),nn.ReLU(),)# ---- 融合层 ----self.linear = nn.Sequential(nn.Linear(cnn_out_dim + 64, features_dim),nn.ReLU(),)def forward(self, observations) -> th.Tensor:img = observations["image"]params = observations["params"]# CNN + MLPcnn_out = self.cnn(img)mlp_out = self.mlp(params)# 融合concat = th.cat([cnn_out, mlp_out], dim=1)return self.linear(concat)# ===============================
# 自定义环境 (字典输入示例)
# ===============================
class InjectionMoldingEnv(gym.Env):def __init__(self):super(InjectionMoldingEnv, self).__init__()self.observation_space = gym.spaces.Dict({"image": gym.spaces.Box(low=0, high=255, shape=(1, 64, 64), dtype=np.uint8), # 温度/压力分布图"params": gym.spaces.Box(low=-1, high=1, shape=(10,), dtype=np.float32), # 静态工艺参数})self.action_space = gym.spaces.Box(low=-1, high=1, shape=(3,), dtype=np.float32) # 调参动作def reset(self):obs = {"image": np.random.randint(0, 255, (1, 64, 64), dtype=np.uint8),"params": np.random.uniform(-1, 1, (10,)).astype(np.float32)}return obsdef step(self, action):reward = -np.sum(np.square(action)) # 示例:动作越小越好obs = {"image": np.random.randint(0, 255, (1, 64, 64), dtype=np.uint8),"params": np.random.uniform(-1, 1, (10,)).astype(np.float32)}done = np.random.rand() < 0.05return obs, reward, done, {}# ===============================
# 使用 PPO 训练
# ===============================
env = InjectionMoldingEnv()policy_kwargs = dict(features_extractor_class=CNN_MLP_Extractor,features_extractor_kwargs=dict(features_dim=256),
)model = PPO("MultiInputPolicy", env, policy_kwargs=policy_kwargs, verbose=1)
model.learn(total_timesteps=10000)# 保存模型
model.save("ppo_injection_cnn_mlp")
- 参数解释

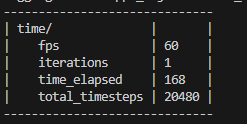
|fps | 54 | Frames Per Second(每秒处理的帧数)。这是衡量训练速度的一个关键指标。这里的 54 表示你的训练程序每秒能够处理 54个环境帧(或称为步骤、样本)。这个值越高,代表训练速度越快。 |
| iterations | 1 | 迭代次数。在强化学习中,一次“迭代”通常包含收集一批数据、并用这批数据更新模型参数的过程。这里的 1 表示当前报表统计的是第1次迭代期间的数据。 |
| time_elapsed | 187 | 已用时间。单位通常是秒(s)。这里的 187 表示从训练开始到当前这个时刻,总共已经过去了 187秒(约3分钟7秒)。 |
| total_timesteps | 10240 | 总时间步数。这是整个训练过程中,环境与智能体交互的总次数。
-
训练时数据采集与训练
model.learn() 模型开始训练—>collect_rollouts(通过交互回合,进行数据采集)–>每次采集(n_step)条后,进行训练self.train()。
其中collect_rollouts 数据采集为:self.policy(obs_tensor)—>env.step(clipped_actions), 通过环境的step 进行采集。terminated 训练时,不计算损失。
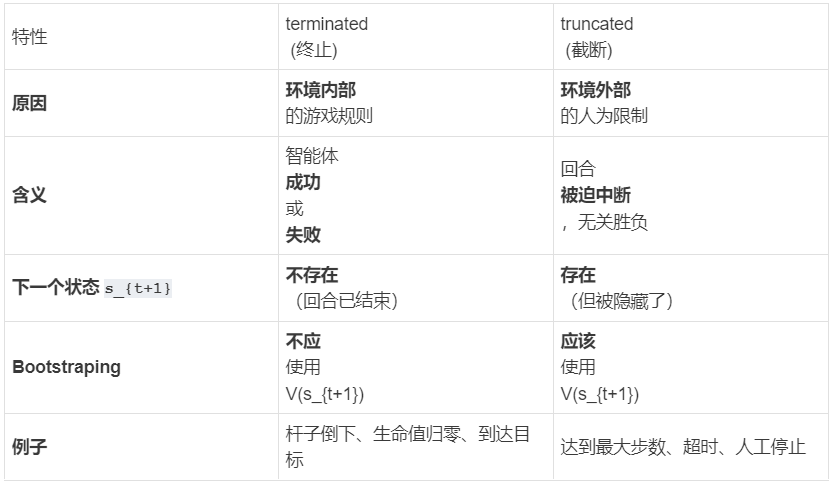
训练数据变化:
cycles—>采集数据量: self.n_epoch —>self.batch_size
1个cycles 训练数据量为: self.n_epoch * 采集数据量