LLM-LLM大语言模型快速认识
基础概念:
- 定义: LLM(Large Language Model)指通过海量数据训练得到的具有强大语言理解和生成能力的人工智能模型
- 企业价值: 可显著提升工作效率,实现智能客服、内容生成等业务场景的自动化
市场现状:
- 需求分析: 当前市场对LLM应用开发人才需求旺盛,企业落地案例快速增长
- 典型案例: 包括智能写作助手、代码自动生成等实际应用场景
实践入门:
- 工具使用: 将学习注册和使用ChatGPT等主流AI工具
- 局限性: 在使用过程中会分析大模型存在的不足和边界
行业影响:
- 软件开发: 探讨LLM对传统软件开发范式的革新
- 职业机遇: 分析AI 2.0时代程序员面临的新机会和发展方向
研究领域:
- 基础研究: 聚焦底层大模型的技术突破和算法优化
- 应用研究: 重点探索大模型在实际场景中的落地应用
专业术语:
- 核心概念: 包括Token(文本处理单元)、AI Agent(智能代理)、向量数据库等
- 应用开发: 指基于大模型API或框架构建实际应用系统的过程
交互演进:
- 模式变革: 分析自然语言交互将如何重塑传统软件交互方式
- 未来趋势: 探讨更智能、更自然的AI交互界面发展方向
什么是大语言模型?
- 核心概念:大语言模型(LLM)全称Large Language Model,是通过海量数据训练的深度学习模型,能够根据输入预测并生成相应输出
- 工作流程:输入(文本/音频/视频等) → LLM处理 → 预测输出(极简工作流程)
大语言模型大在哪?
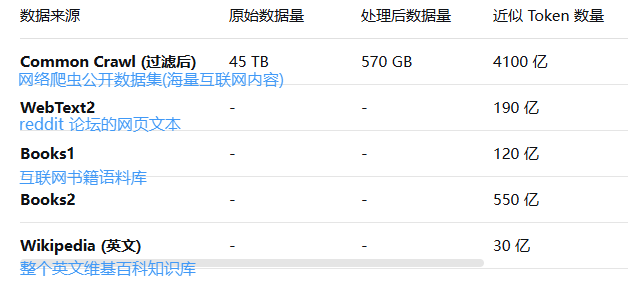
大:训练模型大
GPT-3公开训练数据
大:参数大
参数增长趋势:
GPT-1:1.17亿参数
GPT-2:15亿参数(增长约13倍)
GPT-3:1750亿参数(增长约100倍)
GPT-4:业内估算达万亿级参数
得益于海量数据和参数规模: 通用任务
大语言模型(LLM)的“通用任务”是指其能够理解和响应人类的各种指令,完成跨越不同领域的多种任务,而无需为每个特定任务重新训练模型。这种“通用性”或“泛化能力”是其最核心的价值。
这些通用任务主要可以通过 “提示词”(Prompt) 来激发和引导。以下是大模型能够处理的通用任务的详细分类和说明:
1. 内容生成(Generation)
这是大模型最基础的能力,即根据给定的上下文或指令,生成连贯、相关且富有创造性的文本。
• 文本续写与补全:给定开头,完成文章、故事、邮件等。
• 创意写作:创作诗歌、小说、歌词、剧本、广告文案等。
• 代码生成:根据自然语言描述生成代码片段(如 Python, SQL, JavaScript 等)。
• 数据格式化:将非结构化的信息转换为结构化格式(如 JSON, 表格)。
2. 信息问答与摘要(Question Answering & Summarization)
从给定的上下文或依托其内部知识库(训练数据),提取和整合信息。
• 开放域问答:回答常识性问题或基于训练数据知识的问题(需注意可能过时或不准确)。
• 基于上下文的问答:提供一段文本(如一篇新闻),让模型根据该文本回答问题。
• 摘要:将长篇文章、报告或会议记录总结为简短的核心要点。
• 信息提取:从文本中提取特定实体(如人名、地点、日期)或关键信息。
3. 语言转换与翻译(Translation & Transformation)
改变文本的形式或风格,而不改变其核心含义。
• 机器翻译:在多种语言之间进行互译。
• 风格转换:将文本转换为正式、口语化、商务、幽默等不同风格。
• 语气调整:将文本语气变得更积极、更中立或更谨慎。
• 格式转换:将要点列表扩展成流畅的段落,或将段落压缩成列表
4. 对话与角色扮演(Conversation & Role-playing)
以特定身份或角色与用户进行多轮、有上下文理解的对话。
• 开放聊天:进行日常的、自由的对话。
• 角色扮演:扮演历史人物、专家(如律师、医生、财务顾问)、虚构角色等。
• 客服机器人:回答产品相关问题,处理用户咨询。
• 面试练习:扮演面试官,向用户提出模拟面试问题。
5. 推理与逻辑(Reasoning & Logic)
展示出一定的逐步思考和解决复杂问题的能力,也称为“思维链”(Chain-of-Thought)。
• 常识推理:回答需要日常常识的问题(如“如果把冰块放在阳光下会怎样?”)。
• 逻辑推理:解决简单的逻辑谜题和脑筋急转弯。
• 多步问题解决:将复杂问题分解为多个步骤并依次解决(如数学应用题、规划行程)。
• 因果推断:分析事件之间的因果关系。
6. 文本分析与评估(Analysis & Evaluation)
对给定的文本进行深入审视、解读和评判。
• 情感分析:判断一段文本的情感倾向(积极、消极、中性)。
• 主题提取:识别一篇文章的核心主题或话题。
• 文本校对与润色:检查语法错误、拼写错误,并提出修改建议以提升文笔。
• 内容审查:识别文本中是否存在仇恨言论、暴力内容或偏见。
7. 复杂任务与智能体(Complex Tasks & AI Agents)
将上述能力组合起来,通过一系列步骤和工具调用完成更复杂的、目标导向的任务。
• 工具使用:学习使用外部工具(如计算器、搜索引擎、API)来获取更准确的信息或执行动作。
• 任务分解:将用户模糊的复杂指令分解为清晰的可执行步骤列表。
• 自动化流程:编写脚本、制定计划、生成待办事项列表。
示例提示:
“帮我研究一下最新的iPhone和三星Galaxy手机的对比,并生成一个对比表格。”
“为我创建一个学习Python的四周计划,每周列出要学习的主题和资源。
核心要点总结
- 提示词即接口:所有这些任务都通过自然语言提示(Prompt) 来激活。设计精准的提示词是有效使用大模型的关键技能(即提示词工程)。
- 零样本/少样本学习:大模型无需额外训练,就能在“零样本”(直接指令)或“少样本”(提供几个示例)的情况下理解并执行新任务。
- 能力源于训练:这些通用能力并非编程而来,而是模型在训练过程中从海量、多样化的数据中学习到的统计模式和知识关联。
- 并非完美:模型可能会产生“幻觉”(即编造虚假信息),其知识和能力也受限于训练数据的截止日期。对于关键信息, always需要人工核实。
总而言之,大语言模型就像一个具备广博知识和强大语言能力的万能助手,其通用任务范围几乎覆盖了所有以语言为核心的脑力劳动领域。
大语言模型基础单位Token
1. 什么是 Token?
- Token 是模型用来理解和生成文本的基本单位。它并不完全等同于一个英文单词或一个汉字。模型在接收你的输入时,会先将文本切分(Tokenize)
成一系列的 Token,处理完毕后再将生成的 Token 转换回人类可读的文本。 - 你的输入 -> 拆分成Token -> 模型处理 -> 生成新的Token -> 组合成输出文本
2. Token 是如何产生的?(分词 / Tokenization)
模型使用一种叫做分词器(Tokenizer) 的工具来将文本切分成 Token。常见的策略包括:
-
单词级(Word-level):将一个单词作为一个 Token。(现在较少使用) ◦
- 例如:“Hello world!” -> [“Hello”, “world”, “!”] (3个tokens)
-
子词级(Subword-level):这是目前最主流的方法(例如 GPT 系列使用的 Byte Pair Encoding, BPE)。它的核心思想是:
-
将常见单词作为一个 Token(例如 “the”, “apple”)。
-
将不常见或复杂的单词拆分成更小的、有意义的子词单元(例如 “unhappiness” -> [“un”, “happiness”])。
-
中文的分词更为复杂:
-
一个汉字通常会被当作一个独立的 Token(因为汉字本身有含义)。
- 常见的词语或成语也可能被组合成一个Token。
3. 如何计算 Token 数量?
使用官方工具:
-
OpenAI 提供了一个简单的 Tokenizer 工具 来可视化分词。
-
在其 API 中,使用 tiktoken 库可以精确计算。
大语言模型词表
语言模型的词表(Vocabulary) 是一个定义了模型所能“认识”的所有基本文本单位(Token)的列表。
它是模型与文本之间的桥梁,是模型处理和理解语言的基础字典。
1. 词表到底是什么?
想象一下教一个婴儿说话。你首先会教他最基本的发音和单词,比如“爸”、“妈”、“水”。这些基础单元集合就是他的“词表”。大语言模型也是如此。
技术定义:词表是一个巨大的映射表,它将每一个可能的 Token(文本片段)映射到一个唯一的整数ID(Token ID)。
例如:
◦ " cat" -> 1234
◦ “。” -> 567
◦ “ization” -> 8910
◦ “深度学习” -> 1122
模型看到的不是“Hello world”这个句子,而是类似于 [15496, 995] 这样的数字序列。这个词表文件(通常是一个.json或类似格式文件)在模型训练之前就已确定,并且在训练和推理过程中保持不变。
2. 词表是如何构建的?(核心算法)
词表不是人工编写的,而是通过统计算法从海量训练数据中自动学习得到的。最主流的算法是:
Byte Pair Encoding (BPE) - 字节对编码
BPE 是一种数据压缩算法,被巧妙地应用于NLP的分词任务。其核心思想是:迭代地合并训练语料中最频繁出现的相邻字节对(或字符对)。
BPE 构建词表的简化过程:
1.初始化:将词表初始化为所有基本的字节(256个)或字符(例如所有英文字母、中文字符)。
2. 计数:在训练数据中统计所有连续字节对出现的频率。
3. 合并:找到频率最高的字节对(例如 “e” 和 “s” 经常连在一起出现为 “es”),将它们合并成一个新的符号(Token),并加入到词表中。
4. 重复:重复步骤2和3,直到词表达到我们预设的大小(例如32,000次合并后,词表大小就是 256 + 32,000 = 32,256)
举个例子:
假设单词 “low”, “lower”, “newest”, “widest” 频繁出现。
5. 初始词表:所有字母 l, o, w, e, r, n, s, t, i, d, …
6. 统计发现 “e” 和 “s” 经常连在一起,合并 “es” 加入词表。
7. 接着发现 “es” 和 “t” 经常连在一起,合并 “est” 加入词表。
8. 最终,单词 “lowest” 可能不会被当作一个整体,而是被高效地拆分为 [“low”, “est”] 两个Token,因为 “low” 和 “est” 在其它单词中也很有用。
3.其他算法:
除了BPE,还有 WordPiece(用于BERT)、Unigram、SentencePiece(谷歌推出,可以更好地处理带空格的语言和多种语言)等
4.词表里有什么?(Content)
一个训练好的大语言模型词表通常包含:
• 常见单词:如 " the", " of", " and"(注意前面的空格通常很重要)。
• 子词单元:如词根、前缀、后缀 “ing”, “tion”, “pre”, “un”。
• 单个字符:所有字母、数字、标点符号。
• 常见符号和表情:$, #, ©, ❤️。
• 多语言字符:中文字符、日文假名、韩文字母等。
• 特殊控制Token:如 <|endoftext|>(文本结束)、[SEP](分隔符)、[CLS](分类符),这些用于模型理解文本的结构和边界。
中英文词表差异:
• 英文:由于单词由空格分隔,词表包含大量子词,这使得模型能高效处理生僻词(如 “antidisestablishmentarianism” 会被拆成多个已知子词)。
• 中文:没有自然空格,分词更复杂。词表中会包含大量常见词语和成语(如“经济”、“人工智能”、“守株待兔”)作为独立Token,同时也包含单个汉字。一个中文句子通常会被分成“词”和“字”的混合序列。
5.词表大小的影响 (Size Matters)
词表大小是一个需要精心权衡的超参数:
• 词表过大(缺点):
◦ 增加模型参数(词表本身就是一个巨大的嵌入矩阵)。
◦ 可能导致过拟合,模型记住了罕见的Token而不是学习通用的组合规律。
◦ 计算效率降低。
• 词表过小(缺点):
◦ 任何文本都会被拆分成非常细碎的片段,序列长度变长,影响计算效率。
◦ 模型需要处理更长的依赖关系,学习难度增加。
◦ 可能丢失语义信息(例如,将人名拆碎后可能失去其唯一性)。
因此,选择合适的词表大小(例如32k, 50k, 100k)是模型设计中的一项重要艺术。
6.如何查看和理解词表?
对于开源模型(如 LLaMA, ChatGLM),你可以直接找到其词表文件(通常是 tokenizer.json 或 vocab.json)。你也可以使用 Hugging Face 的 transformers 库来加载分词器并实验:
总结
• 词表是模型的语言字典,定义了模型认知世界的基本单位。
• 它通过统计算法(如BPE) 从数据中学习得到,是文本与数字ID之间的映射表。
• 词表的内容和大小直接影响模型的效率、性能和对不同语言、生僻词的处理能力。
• 理解词表是理解大模型如何“阅读”和“写作”的第一步,也是进行提示词优化和模型微调的重要基础。
大语言模型预测token的机制
简单来说,这是一个 “猜词游戏”:模型根据你之前说过的所有话(上下文),计算出下一个最可能出现的词(Token)是什么,并不断重复这个过程。
为了更直观地理解这个复杂的过程,我们可以将其核心机制分解为几个关键步骤。下图展示了大语言模型预测下一个 Token 的完整工作流程:

1. 编码输入(Input Encoding)
模型首先使用分词器(Tokenizer) 将输入文本转换为一个 Token ID 序列。
每个 Token ID 会被映射为一个高维数值向量(称为 “词嵌入” - Word Embedding)。
同时,还会加上位置编码(Positional Encoding),因为 Transformer 结构本身没有顺序概念,需要这个步骤来告诉模型每个词的位置。
2. 上下文理解(核心计算)
这些向量被送入模型的核心——Transformer 解码器栈。
-
自注意力机制(Self-Attention):这是最关键的一步。它让序列中的每一个 Token 都与其他所有 Token进行交互。通过复杂的数学计算,模型会为每个 Token 分配不同的“注意力权重”,从而判断哪些上下文词语对预测下一个词最重要
- 例如:在“吃了一个美味的____”中,“吃”和“美味的”会获得很高的权重,因为它们强烈暗示下一个词是食物。
-
前馈网络(Feed-Forward Network):注意力层的输出会再经过一个前馈网络进行进一步的非线性变换,提取更复杂的特征。
以上过程会在一层又一层的 Transformer 块中重复进行,每一层都能捕捉到更抽象、更复杂的语言关系。
3. 输出概率分布(Output Distribution)
经过所有层处理后,模型会得到序列中最后一个 Token 的一个最终高维表示向量。这个向量包含了之前所有上下文的信息。
这个向量会被送入一个 线性层(Linear Layer) + Softmax 函数,从而被转换成一个概率分布:
-
这个概率分布覆盖了整个词表(Vocabulary)(可能包含数万个 Token)。
-
词表中的每一个 Token 都有一个对应的概率值,所有概率之和为 1。
-
例如:在“猫坐在____上”之后,概率可能是:“地毯”(0.15)、“沙发”(0.1)、“椅子”(0.08)、“床”(0.07)……“月亮”(0.0000001)。
4.采样(Sampling)
如果模型总是选择概率最高的那个 Token(即贪婪搜索 - Greedy Search),生成的内容会非常机械、重复且缺乏创意。
因此,实际应用中会引入采样策略,从概率分布中随机抽取下一个 Token,从而增加生成内容的多样性:
• Temperature(温度):
◦ 温度 → 0:模型变得更确定,总是选择最高概率的 Token(更保守、可预测)。
◦ 温度 → 1:使用原始概率分布。
◦ 温度 > 1:模型更不确定,概率分布被拉平,低概率的 Token 也有更多机会被选中(更有创意,但也更冒险、可能产生 nonsense)。
• Top-p(核采样):
◦ 只从概率最高的一小部分 Token 中(累积概率刚好超过 p,例如 p=0.9)进行抽样。这能动态地控制候选池的大小,排除那些概率极低的荒唐选项。
5.循环(Loop)
被选中的新 Token 会被追加(Append) 到原始输入序列的末尾,形成一个更长的序列。然后,这个新的、更长的序列再次作为输入送给模型,去预测再下一个 Token。
这个过程会不断重复,直到:
- 生成了一个表示结束的特殊 Token(如 <|endoftext|>)。
- 达到了预设的最大生成长度。
- 用户手动停止。
一个简单的比喻
你可以把大模型想象成一个顶级完形填空高手。
你给他一句话:“今天天气真好,我们去公园____。”
他基于毕生所学(训练数据),分析“天气好”、“去公园”这些上下文,算出最可能的词是“玩”、“散步”、“野餐”等,并给出每个词的概率。
他根据某个策略(比如想有点新意),从“野餐”、“放风筝”等选项中选择了“野餐”。
现在句子变成了:“今天天气真好,我们去公园野餐。”
他把这个新句子作为输入,继续做下一个填空:“今天天气真好,我们去公园野餐。____”。
如此循环下去,直到写完整个段落或故事。
核心要点总结
- 自回归(Autoregressive):这是这种“基于上文预测下一个”机制的学术名称。GPT 就是 Autoregressive 的缩写。
- 概率模型:模型的输出本质上是所有可能 Token 的一个概率分布。它不是“知道”答案,而是“计算”出最可能的答案。
- 上下文是关键:模型在每一步的预测都依赖于整个之前的上下文序列。注意力机制使其能够权衡所有上文信息的重要性。
- 采样引入随机性:采样策略是控制生成内容创造性和多样性的关键旋钮。
正是这个看似简单的“猜下一个词”的机制,在巨大模型参数和海量训练数据的加持下,涌现出了令人惊叹的复杂理解和生成能力。
大语言模型训练
大语言模型的训练是一个庞大而复杂的系统工程,其目标是将一个初始化的“空白”模型,通过“学习”海量数据,转变为能够理解和生成自然语言的“智能”系统。

上述流程中的每一个阶段都有其独特的目标和方法。
1. 预训练 (Pre-training) - 获取“世界知识”
这是最耗时、耗力、耗钱的阶段,目标是让模型打下坚实的语言基础和知识基础。
- 数据:使用海量无标注文本(如书籍、网页、代码等),规模可达数万亿个Token(GPT-3用了约3000亿Token,后续模型更大)。
- 任务:下一个Token预测 (Next Token Prediction)。这是一种自监督学习:模型被要求根据给定的上文,预测序列中下一个最可能出现的Token。
- 例如:输入“今天天气真___”,模型应学会预测“好”。
- 所学能力
- 语言语法:学会词汇、句法、语法规则。
- 世界知识:在学习文本的过程中,模型隐式地记住了大量事实性知识(例如“巴黎是法国的首都”)。
- 推理能力:初步学习到一些逻辑和常识关联(例如“如果下雨,地面会湿”)。
- 产出:基础模型 (Base Model)。如 LLaMA-Base,
GPT-3-Base。这个模型就像一个“博览群书但未经世事的学者”,它拥有大量知识,但还不会很好地遵循指令或进行对话,也可能输出有害或不准确的内容。
2. 有监督微调 (Supervised Fine-Tuning, SFT) - 学习“对话与指令”
这个阶段的目标是教会基础模型如何与人类互动,理解并执行指令。
-
数据:数量较少(几万到十几万条)但质量极高的数据。由人类标注者精心编写的指令-回答对 (Instruction-Response
Pairs)。- 例如:
指令: “写一首关于秋天的五言绝句”
回答: “秋风扫落叶,明月照松间。寒鸦栖孤枝,金菊映山颜。” -
任务:有监督学习。模型输入是指令,其输出的Token序列被期望与人类提供的标准答案尽可能接近。它是在模仿人类老师的示范。
-
所学能力:
-
指令理解:学会解析用户的意图。
-
对话格式:学会遵循多轮对话的格式(如User, Assistant的角色标签)。
-
输出风格:学会生成有用、格式正确的回答。
-
-
产出:SFT 模型 (Chat Model)。例如 LLaMA-Chat,
GPT-3.5-turbo-instruct。此时的模型已经能进行对话,但可能 still have issues with
harmfulness or consistency,因为它的审美(什么是最好的回答)还没有被完全校准。
3. 从人类反馈中强化学习 (Reinforcement Learning from Human Feedback, RLHF) - 对齐“人类偏好”
这是让ChatGPT等模型变得如此“好用”、“贴心”和“安全”的关键一步。其目标是让模型的输出不仅正确,还要符合人类的价值观和偏好( helpful, honest, harmless)。
RLHF 通常分为三个子步骤:
a)
训练奖励模型 (Reward Model, RM)
-
目标:训练一个可以替代人类、自动给模型回答打分的“裁判”模型。
-
数据:收集人类偏好数据。向标注者展示同一个指令的多个不同回答,让他们对这些回答进行排序。
- 例如:对于指令“解释黑洞”,回答A和回答B哪个更好?
-
任务:训练一个模型,让它学习人类的评判标准,能够预测对于任何一个给定的指令-回答对,人类会给出多高的分数(奖励)。
b)
使用强化学习进行优化 (Reinforcement Learning - Proximal Policy Optimization, PPO)
-
目标:用训练好的奖励模型作为“指南针”,来微调SFT模型的政策(即其参数)。
-
过程:
1.SFT模型针对一个指令生成一个回答。
2.奖励模型对这个回答进行打分(奖励值)。
3.强化学习算法(PPO) 根据这个奖励值来更新SFT模型的参数。■ 核心思想:如果某个生成了高奖励的回答,就调整模型参数,使其未来更可能产生类似的回答。反之,对于低奖励的回答,就降低其产生概率。
4.不断重复这个过程,模型的输出策略会逐渐向“高奖励”(即符合人类偏好)的方向进化。
所学能力:
- 有帮助性 (Helpfulness):提供用户真正想要的信息,而不是机械地重复问题。
- 无害性 (Harmlessness):拒绝生成危险、不道德或有偏见的内容。
- 诚实性 (Honesty):减少“幻觉”(编造事实),对于不知道的事情会说“我不知道”。
产出:
最终的对齐模型 (Aligned Model)。例如 ChatGPT, Claude。
训练中的关键技术概念
-
损失函数 (Loss Function):
一个衡量模型预测(Output)与真实目标(Target)之间差距的函数。训练的目标就是最小化这个损失值。 -
梯度下降 (Gradient Descent) & 反向传播 (Backpropagation):
模型通过计算损失函数相对于自身参数的梯度(导数),来确定如何微小地调整参数才能降低损失。然后通过反向传播算法将误差从输出层逐层反向传递,更新每一层的参数。 -
迭代 (Iteration) / 周期 (Epoch):
模型会多次遍历训练数据,每次遍历都会持续优化参数。
用一个非常生动的例子——“培养一名顶级厨艺大师”——来完整展示大语言模型的训练过程。
这个比喻能完美对应大模型训练的预训练、有监督微调(SFT) 和从人类反馈中强化学习(RLHF) 这三个核心阶段。
阶段一:预训练 (Pre-training) - “博览群书,积累海量菜谱知识”
目标: 让模型获得通用的“世界知识”。
过程:
想象一个天赋异禀的学徒(基础模型),他被关在世界上最大的图书馆里,这个图书馆存有古今中外所有的菜谱、美食杂志、食材百科和烹饪教程(海量无标注文本数据)。
他的任务很简单但也无比枯燥:“完形填空”。
• 他拿起一本菜谱,上面写着:“要做麻婆豆腐,需要先将豆腐切块,然后______。”
• 他根据之前看过的无数文本,预测最可能的下一个步骤是“焯水”或“过油”。
• 他不断地重复这个过程,翻阅数百万本书,预测下一个词、下一个步骤、下一个食材。
最终成果:
几年后,他出关了。他现在是一个 “知识渊博的烹饪学者”。
• 他知道所有菜系的几乎所有做法。
• 他知道所有食材的特性(豆腐很嫩,牛肉要逆纹切)。
• 他懂得所有烹饪术语(焯水、煸炒、焗、 Sous-vide)。
但他的问题很大:
• 你问他:“今晚请客,我该做什么菜?”他可能会开始喋喋不休地背诵一整本《法国烹饪百科》的目录,因为他不知道如何理解指令和与人对话。
• 他可能会推荐一些极其昂贵或不现实的菜(“推荐您做一道佛跳墙,需要准备鱼翅、干鲍、金华火腿……”),因为他不懂实用性和人类偏好。
这就好比一个刚读完互联网所有文本的Base模型,有知识但不会交流。
**
阶段二:有监督微调 (SFT) - “拜师学艺,学习如何待客”
**
目标: 教会模型如何遵循指令和进行对话。
过程:
现在,这位“学者”被送到一位德高望重的顶级大厨(人类标注员) 门下当学徒。
大厨的教学方式是示范教学。他给出指令,并亲自演示完美的回答。
• 大厨(指令): “为客户设计一份温馨的二人周年纪念日晚餐菜单,要有浪漫氛围。”
• 大厨(演示): “好的,为您设计以下菜单:前菜:香煎带子配柠檬黄油汁;主菜:惠灵顿牛排;甜点:心形熔岩巧克力蛋糕。并建议搭配一款黑皮诺红酒。需要我为您详细介绍任何一道菜的做法吗?”
• 学徒(模型): 仔细观察师父的措辞、语气、菜单结构,并努力模仿师父的输出。
他们进行了数万次这样的练习,覆盖从“家常小炒”到“国宴料理”的各种指令。
最终成果:
他现在进化成了一个 “技能娴熟的厨房员工”。
• 他能理解指令了(你要浪漫晚餐,他不会给你推荐麻辣火锅)。
• 他能用得体的方式交流了(输出格式正确、有用)。
• 他能生成完整的菜单而不仅仅是背诵菜谱。
但他还有不足:
• 他的审美是模仿老师的,但到底什么才是‘最好’的回答? 他可能不太确定。
• 为了显示能耐,他可能会把菜单设计得过于复杂,忽略了客户可能更想要简单易做的菜(即不符合人类真实偏好)。
这就好比经过了SFT的Chat模型,能用了,但品味和安全性还需要打磨。
阶段三:人类反馈强化学习 (RLHF) - “接受食评家考验,成为真正大师”
目标: 让模型的输出符合人类的价值观和偏好。
过程:
现在,这位员工要独立面对顾客了。餐厅聘请了一位神秘食评家(奖励模型 RM) 来给他反馈。
a) 训练食评家(训练奖励模型):
• 厨房每次出菜(模型生成多个回答),食评家都会尝一口,然后根据自己的专业标准(人类偏好数据)给这些菜排序。
• 例如,对于指令“做一道健康的早餐”:
◦ 回答A: “一份希腊酸奶配格兰诺拉麦片和新鲜莓果。” 👍👍(高奖励)
◦ 回答B: “煎培根、香肠、黄油炒蛋和烤吐司。” 👎(低奖励)
◦ 回答C: “早餐很重要,应该吃富含蛋白质和纤维的食物…” 👎(空洞、不实用)
• 通过无数次排序,食评家内部形成了一套精准的、符合大众口味的评判标准。
b) 强化学习优化(PPO):
• 现在,员工每做一道菜(模型生成一个回答),食评家都会立刻给出一个分数(奖励值)。
• 员工有一个核心目标:最大化食评家给出的总分。
• 如果他做了一道“希腊酸奶”(高奖励),他就会记住这个做法,以后多往这个方向努力。
• 如果他做了一份“油腻的培根”(低奖励),他就会想:“看来客人不喜欢太油腻的,我下次得调整。”
• 他不断地微调自己的做菜习惯(模型参数),不再是为了模仿师父,而是为了获得食评家的最高奖励。
最终成果:
经历了这一切之后,他终于成为一名 “体贴入微的厨艺大师”:
• 有帮助的:你问早餐,他给你简单、健康、美味的方案,而不是一篇关于早餐重要性的论文。
• 无害的:你不会得到“建议生吃豆角”这种危险答案。
• 符合偏好的:他的推荐总是那么贴心、实际,深得顾客欢心。
这就是经历了RLHF的最终模型,如ChatGPT,它不仅有用,而且安全、体贴。