SFR-DeepResearch: 单智能体RL完胜复杂多智能体架构
研究背景
在大语言模型(LLM)与工具结合的智能体研究中,目前存在两种主要架构:单智能体系统和多智能体系统。多智能体系统虽然功能强大,但存在预定义工作流程过于僵化、系统复杂度高、错误传播等问题。相比之下,单智能体系统具有更强的灵活性和泛化能力,能够根据上下文动态决定下一步行动,而无需外部指令。
本论文专注于**深度研究(Deep Research, DR)**任务——这类任务需要大量的搜索和推理能力来处理多个信息源。研究者们希望开发出能够自主进行复杂研究的单智能体系统,让模型在最少的工具集合(网络搜索、网页浏览、Python解释器)下实现强大的研究能力。

- 论文:Towards a Unified View of Large Language Model Post-Training
- 链接:https://arxiv.org/pdf/2509.04419
相关工作
深度研究智能体发展现状
深度研究智能体可以分为两类:
- 单智能体系统:如OpenAI的DeepResearch、Kimi-Researcher等,由单个配备工具的LLM自主决策
- 多智能体系统:如OpenManus、Open DR等,采用复杂的工作流程,多个智能体承担不同角色(协调者、规划者、编程者、研究者等)
智能体强化学习训练方法
现有的智能体训练通常从基础模型或指令调优模型开始,通过冷启动指令调优和强化学习来提升能力。但本研究选择从已经过推理优化的"思考型"模型开始,这样既能利用其强大的逐步推理能力,又能赋予新的智能体功能。
核心方法
3.1 智能体推理架构设计
工具集设计
研究者故意选择了最小化工具集,旨在让智能体在训练中面临足够挑战:
- search_internet(query:str): 基础搜索API,返回前10个搜索结果
- browse_page(url:str, section_id:int): 网页抓取工具,将HTML转换为Markdown格式
- code_interpreter(code:str): 本地Python解释器,无状态执行
单智能体工作流程
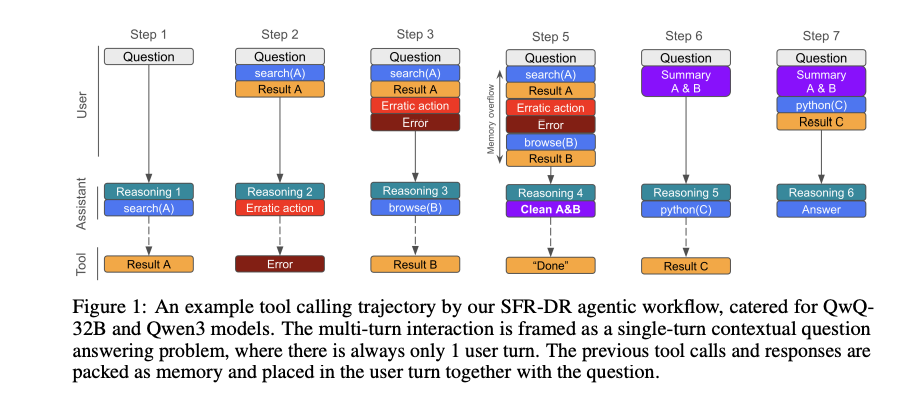
对于不同的基础模型,采用不同的推理架构:
- QwQ-32B和Qwen3模型:将传统的多轮对话重新构建为迭代式单轮任务
- gpt-oss模型:保持原有的多轮对话格式
长上下文管理
创新性地让智能体自主管理内存:
- 提供
clean_memory(content:str)工具,让模型自己决定保留哪些重要信息 - 当内存即将超出预定义限制时,强制模型进行内存清理
- 实现了虚拟无限上下文窗口
3.2 训练数据合成
研究团队发现现有的多跳推理数据集对初始模型来说太简单,因此采用迭代方法构建更具挑战性的数据:
- 短问答任务:多跳事实寻求问题 + 传统数学和代码推理任务
- 长报告写作:开放性问题的指令和评分标准
数据集的挑战性体现在:OpenAI Deep Research with o3在短问答数据集上仅达到65%准确率,最佳基线智能体得分不到40%。
3.3 端到端强化学习配方
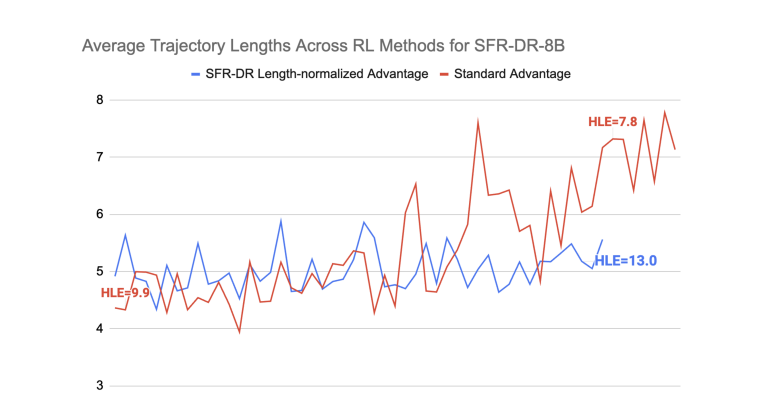
长度归一化RL目标
提出了关键的轨迹长度归一化方法:
Ai,j=Ai=ri−mean(Rˉ)std(Rˉ)⋅TiA_{i,j} = A_i = \frac{r_i - \text{mean}(\bar{R})}{\text{std}(\bar{R}) \cdot T_i}Ai,j=Ai=std(Rˉ)⋅Tiri−mean(Rˉ)
其中TiT_iTi是轨迹长度。这个归一化项确保长轨迹的步骤具有较低的绝对优势幅度,防止模型陷入重复调用工具的退化行为。
轨迹过滤策略
- 过滤无效轨迹(截断或格式错误的响应)
- 维持正负样本比例在预定义范围内
- 重用部分轨迹作为新的初始状态
实验效果
主要评估结果
在三个基准测试中的表现:
| 模型 | FRAMES | GAIA | HLE/HLE-500 |
|---|---|---|---|
| SFR-DR-8B | 63.3 | 41.7 | 13.2/14.0 |
| SFR-DR-32B | 72.0 | 52.4 | 16.2/17.1 |
| SFR-DR-20B | 82.8 | 66.0 | 28.7 |
核心亮点:
- SFR-DR-20B在所有测试中都达到了业界领先水平
- 在HLE基准上相比基础模型gpt-oss-20b提升了65%
- 甚至在某些测试中超越了使用o3的OpenAI Deep Research
消融实验分析
工作流程有效性
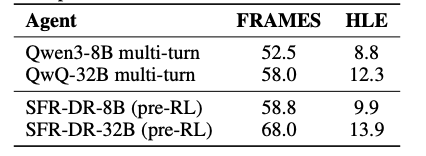
单智能体工作流程显著提升了性能,在FRAMES测试中32B模型获得了10%的绝对提升。
工具使用分析
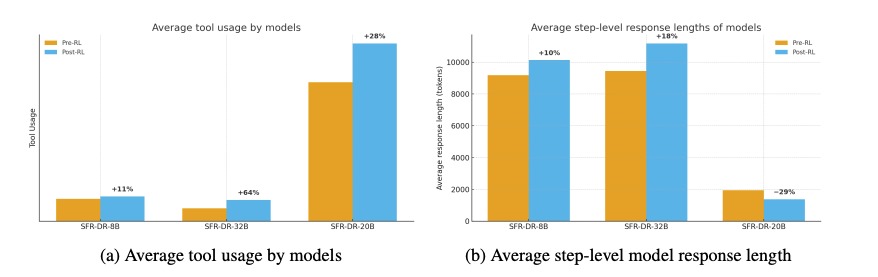
研究发现:
- 更多工具调用≠更好的分数:没有长度归一化的训练导致模型退化为重复调用相同工具
- 模型行为差异:gpt-oss-20b比Qwen系列模型调用工具频率高10倍,但生成的CoT更短更高效
论文总结
这项研究成功证明了简单的强化学习配方配合智能的上下文和长度管理,能够让单智能体获得与多智能体脚手架相媲美的研究能力。主要贡献包括:
- 架构创新:提出了适应不同推理模型的单智能体工作流程
- 训练方法:开发了稳定的多轮RL训练配方,包括长度归一化和轨迹过滤
- 性能突破:在多个基准测试中达到了业界领先水平
- 实用价值:证明了单智能体系统在复杂任务中的有效性
核心伪代码生成
class SFRDeepResearchAgent:def __init__(self, base_model, tools, memory_limit):self.model = base_modelself.tools = {'search_internet': SearchTool(),'browse_page': BrowseTool(), 'code_interpreter': CodeTool(),'clean_memory': MemoryTool()}self.memory_limit = memory_limitself.context_buffer = []def inference_step(self, question, context_memory):"""单步推理过程"""# 检查内存是否超限if len(context_memory) > self.memory_limit:return self.force_memory_cleanup()# 构建单轮提示(针对QwQ/Qwen模型)prompt = f"{question}; {context_memory}"# 模型生成响应(包含工具调用)response = self.model.generate(prompt)# 解析和执行工具调用if self.is_tool_call(response):tool_result = self.execute_tool(response)context_memory.append((response, tool_result))return self.inference_step(question, context_memory)else:return response # 最终答案def execute_tool(self, tool_call):"""执行工具调用"""try:tool_name, params = self.parse_tool_call(tool_call)result = self.tools[tool_name](**params)return resultexcept Exception as e:return f"Error: {str(e)}"def rl_training_step(self, trajectories):"""强化学习训练步骤"""# 计算长度归一化优势for traj in trajectories:length_norm = traj.lengthtraj.advantage = (traj.reward - mean_reward) / (std_reward * length_norm)# 轨迹过滤valid_trajectories = self.filter_trajectories(trajectories)# 策略优化self.update_policy(valid_trajectories)# 训练循环
def train_agent():agent = SFRDeepResearchAgent(base_model, tools, memory_limit)for epoch in range(num_epochs):# 生成轨迹trajectories = []for question in training_data:traj = agent.rollout(question)trajectories.append(traj)# 奖励评估for traj in trajectories:traj.reward = evaluate_trajectory(traj)# RL更新agent.rl_training_step(trajectories)
观点和讨论
根据推特上的讨论,这项研究引发了AI研究社区的广泛关注和讨论:
技术验证
推特用户@BrandGrowthOS指出:“这验证了我在生产环境中看到的现象——拥有适当工具访问权限的单个智能智能体始终优于复杂的多智能体编排。智能体群体中的协调开销、上下文泄露和错误传播通常不值得。”
简洁性的力量
@sridharfyi观察到:"简单的RL设置超越复杂框架表明,在AI研究中优雅往往胜过过度工程。"这呼应了本研究"少即是多"的设计哲学。
实用性考量
@omarsar0总结的核心要点对AI开发者很有价值:
- 限制工具以强制策略学习:通过给智能体提供最小工具集,迫使其学会更有效的策略
- RL归一化的重要性:防止智能体陷入工具滥用的陷阱
- 基础模型选择的影响:gpt-oss-20B比Qwen系列模型更适合智能体训练
未来发展方向
@Arindam_1729提出了一个关键问题:"这种趋势能否扩展?还是说当任务变得复杂时,我们仍然需要多智能体编排?"这个问题触及了单智能体系统可扩展性的核心问题。
技术深度分析
@BLRAAI注意到:“轨迹归一化+内存清理的方法很突出。这与我使用的扩展RL(稳定性控制、漂移控制)相符,并提供了新的探索角度。”
批判性思考
虽然社区反响积极,但需要注意的是,这项研究仍有一些局限性:
- 评估基准的局限性:当前的基准测试可能无法完全反映真实世界研究任务的复杂性
- 工具集的简化:虽然最小工具集有训练优势,但在实际应用中可能需要更丰富的工具支持
- 模型规模依赖:研究结果主要基于特定规模的模型,扩展到更大或更小模型的效果尚不明确
总的来说,这项研究代表了智能体系统设计的一个重要转向——从复杂的多智能体协作回归到更简洁但更智能的单智能体系统。这种转向不仅在技术上具有优势,也为未来的智能体系统开发提供了新的思路。