Scrapy框架入门:快速掌握爬虫精髓
爬虫进阶-scrapy01
Scrapy框架
学习目标
-
理解Scrapy框架的基本概念和优缺点
-
掌握Scrapy框架的架构和工作流程
-
安装和配置Scrapy框架
-
创建和管理Scrapy项目、制作爬虫、运行爬虫和调试、数据存储
-
实战:爬取某招聘网站信息
前言
随着网络爬虫应用越来越多,互联网中涌现了一些网络爬虫框架,这些框架将网络爬虫的一些常用功能和业务逻辑进行了封装。在这些框架的基础上,只需要按照需求添加少量代码,就可实现一个网络爬虫。Scrapy是目前流行的Python网络爬虫框架之一,能帮助开发人员高效地开发网络爬虫程序。
回顾之前的爬虫流程
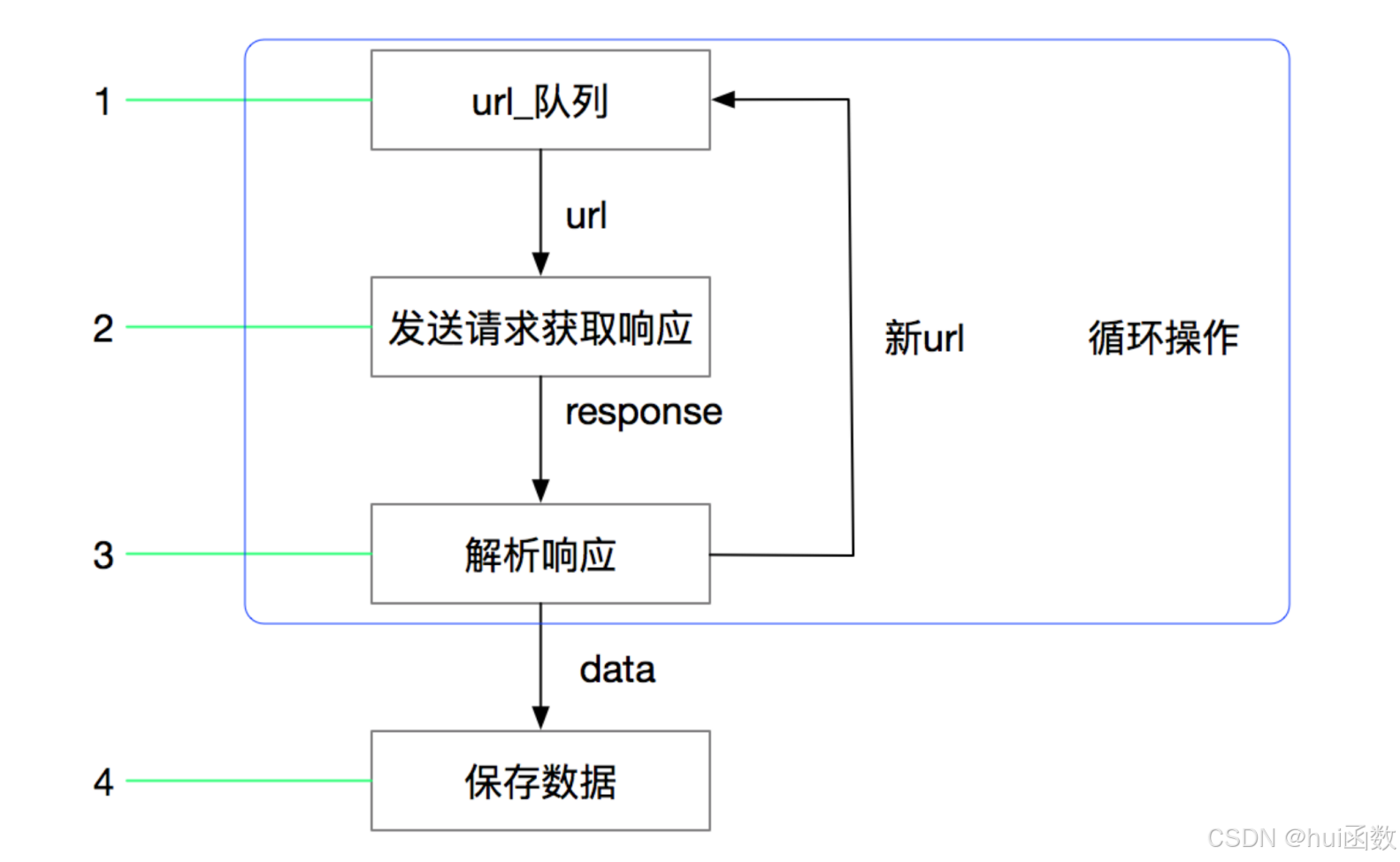
上面的流程可以改写为:
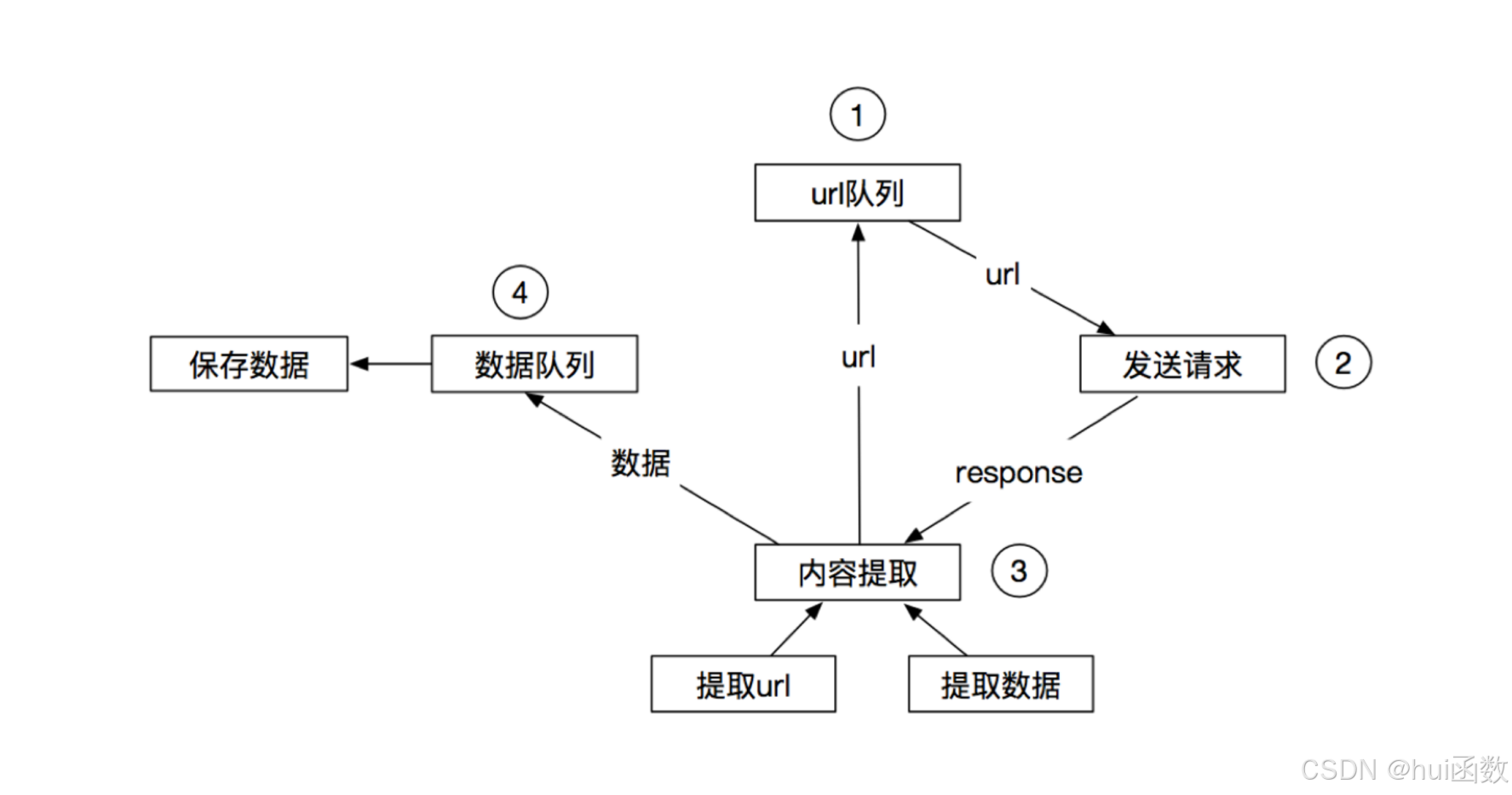
1. 什么是Scrapy
Scrapy是一个纯使用Python语言开发、开源的网络爬虫框架,用于抓取网站页面,并从页面中提取结构化数据。Scrapy最初是为了页面抓取而设计的,可以简单、快速地从网站页面中提取所需的数据,如今Scrapy具备更加广泛的用途,可以被应用到诸如数据挖掘、数据监测、自动化测试等领域以及通用网络爬虫中。Scrapy 0.24 文档 — Scrapy 0.24.6 文档
是基于Twisted框架开发的,Twisted是一个流行的基于事件驱动的网络引擎框架,采用了异步代码实现并发功能。Twisted负责处理网络通信,这样不仅加快页面的下载速度,而且减少手动实现异步操作。
2. Scrapy框架优点
Scrapy框架功能如此强大,离不开其自身具备的如下几个优点:
-
具有丰富的文档、良好的社区以及庞大的用户群体。
-
Scrapy支持并发功能,可以灵活地调整并发线程的数量。
-
采用可读性很强的XPath技术解析网页,解析速度更加快速。
-
具有统一的时间件,可以对数据进行过滤。
-
支持Shell工具,方便开发人员独立调试程序。
-
通过管道将数据存入数据库,灵活方便,且可以保存为多种形式。
-
具有高度的可定制化功能,经过简单改造后,便可以实现具有特定功能的网络爬虫。
3. Scrapy框架缺点
虽然Scrapy框架功能强大,但自身仍存在几个缺点:
-
自身无法实现分布式爬虫。
-
去重效果差,极易消耗内存。
-
无法获取采用JavaScript技术进行动态渲染的页面内容。
为弥补Scrapy框架这些缺点,产生了许多框架插件进行解决,如Scrapy-Redis库解决了Scrapy框架不支持分布式爬虫的问题,Scrapy-Splash库解决了Scrapy框架不支持JavaScript动态渲染的问题等。
4. Scrapy框架架构
Scrapy框架的强大功能,离不开众多组件的支撑,这些组件相互协作,共同完成整个采集数据的任务。 Scrapy框架的架构图如下图所示:
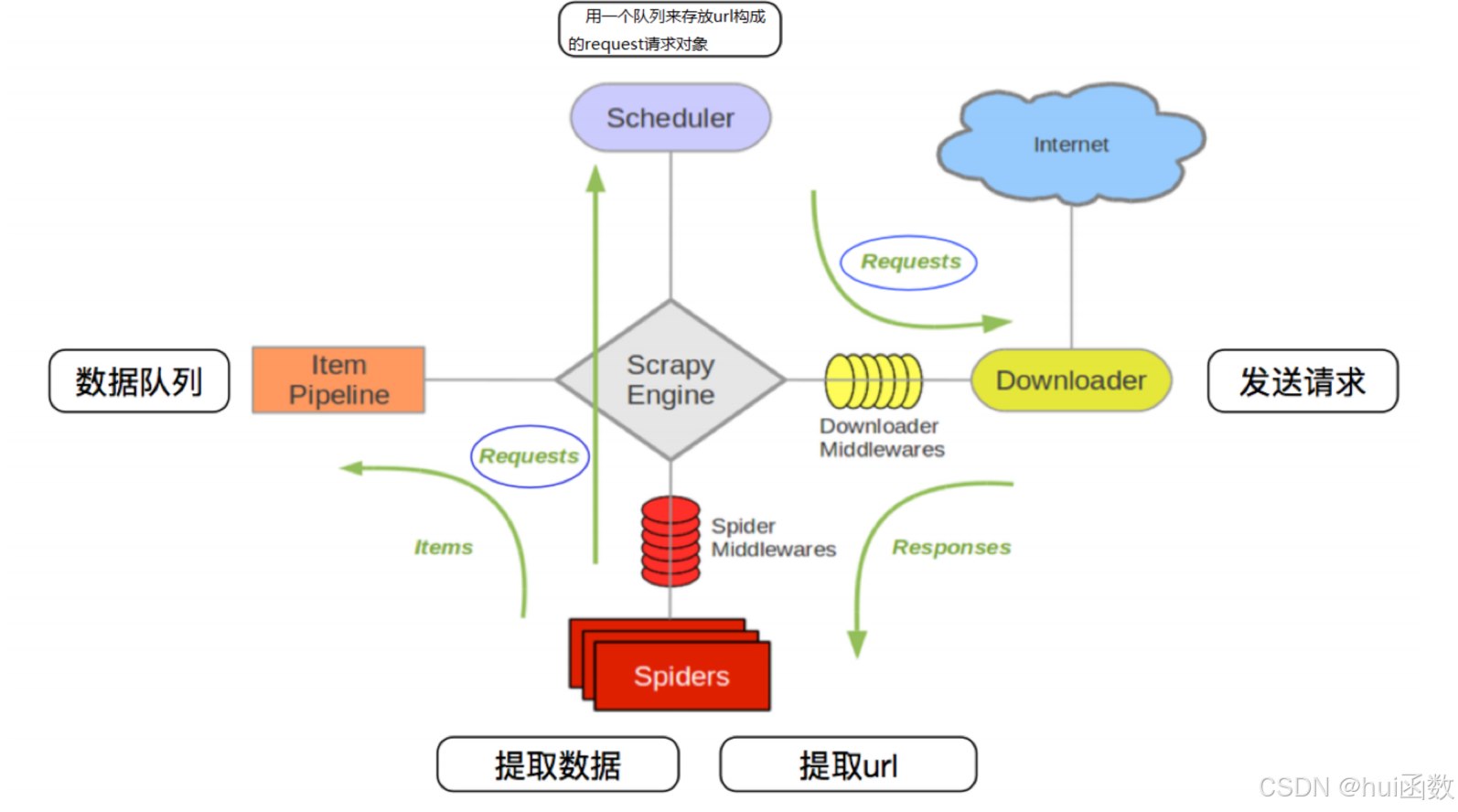
4.1 其流程可以描述如下:
-
爬虫中起始的url构造成request对象-->爬虫中间件-->引擎-->调度器
-
调度器把request-->引擎-->下载中间件-->下载器
-
下载器发送请求,获取response响应-->下载中间件-->引擎-->爬虫中间件-->爬虫
-
爬虫提取url地址,组装成request对象-->爬虫中间件-->引擎-->调度器,重复步骤2
-
爬虫提取数据-->引擎-->管道处理和保存数据
-
注意:
-
图中中文是为了方便理解后加上去的
-
图中绿色线条的表示数据的传递
-
注意图中中间件的位置,决定了其作用
-
-
注意其中引擎的位置,所有的模块之前相互独立,只和引擎进行交互
-
4.2 scrapy的三个内置对象
-
request请求对象:由url method post_data headers等构成
-
response响应对象:由url body status headers等构成
-
item数据对象:本质是个字典
4.3 scrapy中每个模块的具体作用
-
Scrapy Engine(引擎):总指挥,负责数据和信号的在不同模块间的传递
-
Scheduler (调度器):一个队列,存放引擎发过来的request请求(scrapy已实现)
-
Downloader (下载器):下载把引擎发过来的request请求,并返回给引擎(scrapy已实现)
-
Spider (爬虫):处理引擎发来的response,提取数据,提取url,并交给引擎(需要手写)
-
Item Pipeline(管道):处理引擎传过来的数据,比如存储(需要手写)
-
Downloader Middlewares(下载中间件):可以自定义的下载扩展,比如设置代理(一般不用手写)
-
Spider Middlewares(爬虫中间件):可以自定义request请求和进行response过滤(一般不用手写)
注意:
-
爬虫中间件和下载中间件只是运行逻辑的位置不同,作用是重复的:如替换UA等
小结
-
scrapy的概念:Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用程序
-
scrapy框架的运行流程以及数据传递过程:
-
爬虫中起始的url构造成request对象->爬虫中间件->引擎->调度器
-
调度器把request->引擎->下载中间件->下载器
-
下载器发送请求,获取response响应->下载中间件->引擎->爬虫中间件->爬虫
-
爬虫提取url地址,组装成request对象->爬虫中间件->引擎->调度器,重复步骤2
-
爬虫提取数据->引擎->管道处理和保存数据
-
-
scrapy框架的作用:通过少量代码实现快速抓取
-
掌握scrapy中每个模块的作用:
-
引擎(engine):负责数据和信号在不同模块间的传递
-
调度器(scheduler):实现一个队列,存放引擎发过来的request请求对象
-
下载器(downloader):发送引擎发过来的request请求,获取响应,并将响应交给引擎
-
爬虫(spider):处理引擎发过来的response,提取数据,提取url,并交给引擎
-
管道(pipeline):处理引擎传递过来的数据,比如存储
-
下载中间件(downloader middleware):可以自定义的下载扩展,比如设置代理IP
-
爬虫中间件(spider middleware):可以自定义request请求和进行response过滤,与下载中间件作用重复
-
5. Scrapy框架安装
由于Windows系统默认没有安装Python,所以在安装Scrapy框架之前,需要保证Windows系统下已经安装了Python。
在命令提示符窗口中使用pip工具安装Scrapy框架。
pip install scrapy
在Windows系统下安装Scrapy框架常见的两个问题是缺少Microsoft Visual C++ 14.0组件和Twisted安装出错。
缺少Microsoft Visual C++ 14.0组件,报如下错误:
error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": http://landinghub.visualstudio.com/visual-cpp-build-tools
需要注意的是,在Visual Studio 2015组件安装完成之后需要重新启动计算机。
Twisted安装出错,报如下错误:
fatal error c1083: Cannot open include file: 'basetsd.h': No such file or directory error: command 'C:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\BIN\x86_amd64\c1.exe' failed with exit status 2
在Twisted下载页面中选择适合自己电脑的安装包进行安装。
安装命令如下:
pip install Twisted-20.3.0-cp36-cp36m-win_amd64.whl
5.1 创建Scrapy项目
新建Scrapy项目是使用Scrapy框架的第一步,将前面提到的各个组件整合到一起后,方便进行统一管理。
新建Scrapy项目需要使用如下命令:
scrapy startproject 项目名称
例如,使用创建爬虫项目创建mySpider爬虫项目。
管理员:C:\Windows\system32\cmd.exe E:\PythonProject>scrapy startproject mySpider New Scrapy project 'mySpider', using template directory 'c:\programdata\anaconda3\lib\site-packages\scrapy\templates\project', created in:E:\PythonProject\mySpider You can start your first spider with:cd mySpiderscrapy genspider example example.com E:\PythonProject>
mySpider项目的目录结构如下所示。
mySpider/scrapy.cfgmySpider/__init__.pyitems.pymiddlewares.pypipelines.pysettings.pyspiders/__init__.py...
-
mySpider/: 项目的Python模块,将会从这里引用代码。 -
mySpider/spiders/: 存放爬虫代码的目录。 -
mySpider/items.py: 项目的实体文件,用于定义项目的目标实体。 -
mySpider/middlewares.py: 项目的中间件文件,用于定义爬虫中间件。 -
mySpider/pipelines.py: 项目的管道文件,用于定义项目使用的管道。 -
mySpider/settings.py: 项目的设置文件,用于存储项目的设置信息。 -
scrapy.cfg: 配置文件,用于存储项目的配置信息。
5.2 制作爬虫
制作爬虫的流程一般可以分为3步,分别是创建爬虫、抓取网页数据和解析网页数据。
创建爬虫
创建爬虫是为爬虫起一个名称,并规定该爬虫的爬取域,也就是要爬取的域名范围。
scrapy genspider 爬虫名称 "爬取域"
例如,在命令行窗口中切换当前的目录为子目录mySpider/spiders,创建一个名称为baidu、爬取域为baidu.com的爬虫。
在PyCharm中打开mySpider/spiders目录,可以看到新创建的baidu.py,该文件的内容已经自动生成。
import scrapy
# 继承 scrapy.Spider
class BaiduSpider(scrapy.Spider):# 爬虫名称name = "baidu"# 允许的域 相当于过滤操作allowed_domains = ["baidu.com"]# 起始开始的urlstart_urls = ["https://www.baidu.com"]def parse(self, response):# 定义对于网站的操作 response是响应返回的数据# 如果出现DEBUG: Forbidden by robots.txt: <GET http://www.baidu.com># 说明百度网站的 robots.txt 禁止了大多数爬虫访问# Scrapy 默认设置 ROBOTSTXT_OBEY = True 的规则,因此自动屏蔽了对百度的请求。# 修改settings.py# ROBOTSTXT_OBEY = False # 关闭 robots.txt 规则检查
with open('baidu.html', 'wb') as f:f.write(response.body)BaiduSpider是自动生成的类,它继承自scrapy.Spider类。
其中:
-
name属性:爬虫名称。爬虫名称必须是唯一的,不同爬虫需要有不同名称。 -
allowed_domains属性:爬虫搜索的域名范围。该属性用于规定,爬虫只能抓取指定域名范围内的网页,忽略不属于该域名范围内的网页。 -
start_urls属性:包含起始URL的元组或列表,指定爬虫首次从哪个网页开始抓取。 -
parse(self, response)方法:用于解析网页数据(response.body),返回抽取的数据或者新生成的要跟进的URL。该方法会在每个初始URL完成下载后被调用,被调用时传入从该URL返回的Response对象作为唯一参数。
抓取网页数据
确定了初始化URL之后就可以运行爬虫,让爬虫根据该URL抓取网页数据了。运行爬虫的命令格式如下:
scrapy crawl 爬虫名称
例如,在命令行窗口中切换当前目录为baidu.py文件所在的目录,运行爬虫baidu,命令如下:
scrapy crawl baidu