有监督机器学习算法案例(Python)
线性回归预测房价
基于usa_housing_price.csv数据,简历线性回归模型,预测合理房价
- 以面积为输入变量,简历单因子模型,评估模型表现,可视化线性回归预测结果
- 以income、house age、numbers of rooms、population、area为输入变量,建立多因子模型,评估模型表现
- 预测Income=65000,House Age=5,Number if Room=5,Population=30000,size=200的合理房价
import pandas as pd
import numpy as np
%matplotlib inline
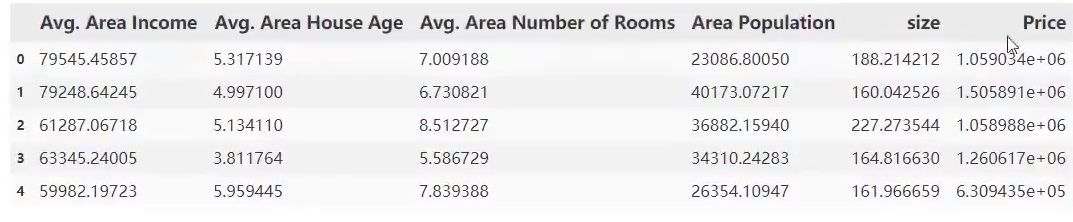
from matplotlib import pyplot as pltdata = pd.read_csv('usa_housing_price.csv')# data.head()fig = plt.figure(figsize=(10,10))
fig1 = plt.subplot(231) #2行3列第一个图
plt.scatter(data.loc[:,'AVG.Area Income'],data.loc[:,'Price'])
plt.title('Price VS Income')fig2 = plt.subplot(232)
plt.scatter(data.loc[:,'AVG.Area House Age'],data.loc[:,'Price'])
plt.title('Price VS House Age')fig3 = plt.subplot(233)
plt.scatter(data.loc[:,'AVG.Area Number of Rooms'],data.loc[:,'Price'])
plt.title('Price VS Number of Rooms')fig4 = plt.subplot(234)
plt.scatter(data.loc[:,'Area Polulation'],data.loc[:,'Price'])
plt.title('Price VS Area Polulation')fig5 = plt.subplot(235)
plt.scatter(data.loc[:,'size'],data.loc[:,'Price'])
plt.title('Price VS size')plt.show()
# 定义X,y
X = data.loc[:,'size']
y = data.loc[:,'Price']#print(X.shape) 维度X = np.array(X).reshape(-1,1) # 转换维度from sklearn.linear_model import LinearRegression
LR1 = LinearRegression() #创建模型实例LR1.fit(X,y) #训练模型
y_predict_1 = LR1.predict(X) #预测
print(y_predict_1)#评估模型
from sklearn.metrics import mean_squared_error,r2_score
mean_squared_error_1 = mean_squared_error(y,y_predict_1)
r2_score_1 = r2_score(y,y_predict_1)
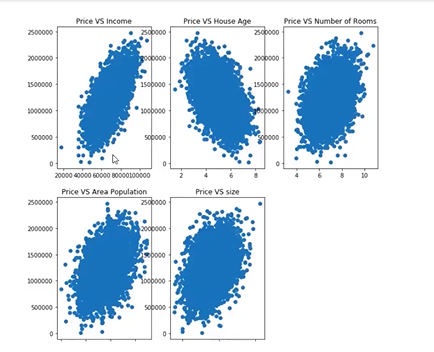
print(mean_squared_error_1,r2_score_1)fig6 = plt.figure(figsize=(8,5))
plt.scatter(X,y) #散点图
plt.plot(X,y_predict_1,'r') #绘制线图
plt.show()

多因子线性回归
'''data:原始数据集(通常是DataFrame)drop():删除指定列或行的函数['Price']:要删除的列名列表(此处只有'Price'列)axis=1:指定按列删除(axis=0表示按行删除)X_multi:结果变量,包含除价格外的所有特征
'''
X_multi = data.drop(['Price'],axis=1) #从数据集中移除价格列LR_multi = LinearRegression()
LR_multi.fig(X_multi,y)y_predict_multi = LR_multi.predict(X_multi)#评估模型
mean_squared_error_multi = mean)squared_error(y,y_predict_multi)
r2_score_multi = r2_score(y,y_predict_multi)
print(mean_squared_error_multi,r2_score_multi)#可视化
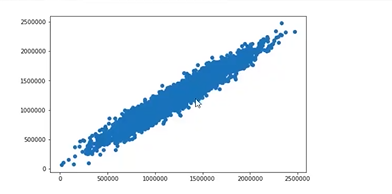
fig7 = plt.figure(figsize=(8,5))
plt.scatter(y,y_predict_multi)
plt.show()
X_test = [65000,5,30000,200]
X_test = np.array(X_test).reshape(1,-1)y_test_predict = LR_multi.predict(X_test)
print(y_test_predict)
逻辑回归预测考试通过
import pandas as pd
import numpy as np
data = pd.read_csv('examdata.csv')
data.head()

#可视化
%matplotlib inline
from matplotlib import pyplot as plt
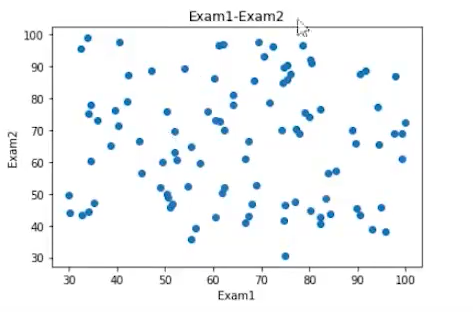
fig1 = plt.figure()
plt.scatter(data.loc[:,'Exam1'],data.loc[:,'Exam2'])
plt.title('Exam1-Exam2')
plt.xlabel('Exam1')
plt.ylabel('Exam2')
plt.show()
mask = data.loc[:,'Pass'] == 1
print(mask) # ~mask 表示取反

fig2 = plt.figure()
plt.scatter(data.loc[:,'Exam1'][mask],data.loc[:,'Exam2'][mask])
plt.title('Exam1-Exam2')
plt.xlabel('Exam1')
plt.ylabel('Exam2')
plt.show()
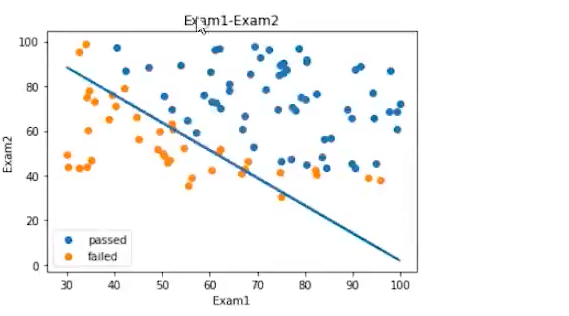
fig3 = plt.figure()
passed = plt.scatter(data.loc[:,'Exam1'][mask],data.loc[:,'Exam2'][mask])
failed = plt.scatter(data.loc[:,'Exam1'][~mask],data.loc[:,'Exam2'][~mask])
plt.title('Exam1-Exam2')
plt.xlabel('Exam1')
plt.ylabel('Exam2')
plt.legend((passed,failed),('passed','failed'))
plt.show()

# 定义X,y
X = data.drop(['Pass'],axis=1)
y = data.loc[:,'Pass']
X1 = data.loc[:,'Exam1']
X2 = data.loc[:,'Exam2']print(X.shape,y.shape)# 模型训练
from sklearn.linear_model import LogisticRegression
LR = LogisticRegression()
LR.fit(X,y)# 预测结果
y_predict = LR.predict(X)
print(y_predict)# 模型评估
from sklearn.metrics import acceracy_score
accuracy = accuracy_score(y,y_predict)
print(accuracy)# 测试 exam1=70 exam2=65 是否能通过考试
y_test = LR.predict([[70,65]])
print('passed' if y_test==1 else 'failed')
# 边界函数:
theta1,theta2 = LR.coef_[0][0],LR.coef_[0][1]
theta0 = LR.intercept_X2_new = -(theta0+theta1*X1)/theta2
print(X2_new)fig4 = plt.figure()
passed = plt.scatter(data.loc[:,'Exam1'][mask],data.loc[:,'Exam2'][mask])
failed = plt.scatter(data.loc[:,'Exam1'][~mask],data.loc[:,'Exam2'][~mask])
plt.plot(X1,X2_new)
plt.title('Exam1-Exam2')
plt.xlabel('Exam1')
plt.ylabel('Exam2')
plt.legend((passed,failed),('passed','failed'))
plt.show()

# 由于上述的边界函数的可视化结果并不准确,仅有80%
# 二阶边界函数重新获取数据集
X1_2 = X1*X1
X2_2 = X2*X2
X1_X2 = X1*X2X_new = {'X1':X1,'X2':X2,'X1_2':X1_2,'X2_2':X2_2,'X1:X2':X1:X2}
X_new = pd.DataFrame(X_new)
print(X_new)

# 训练模型
LR2 = LogisticRegression()
LR2.fit(X_new,y)y2_predict = LR2.predict(X_new)
accuracy2 = accuracy_score(y,y2_predict) # 计算分类模型准确率的函数theta0 = LR2.intercept_
theta1,theta2,theta3,theta4,theta5 = LR2.coef_[0][0],LR2.coef_[0][1],LR2.coef_[0][2],LR2.coef_[0][3],LR2.coef_[0][4]
KNN算法实现2D数据自动聚类
有监督机器学习算法,可用于分类和回归任务。它的核心假设是“相似的事物在特征空间中彼此靠近”。
核心思想:要判断一个未知样本的类别,就看它在特征空间中最接近的 K 个已知样本(邻居)属于什么类别,并通过“投票”(分类)或“平均”(回归)的方式做出预测。
数据来源与无监督学习中的Kmeans算法
from sklearn.neighbors import KNeighborsClassifier
KNN = KNeighborsClassifier(n_neighbors=3)
KNN.fit(X,y)#测试
y_predict_knn_test = KNN.predict([[80,60]])
y_predict_knn = KNN.predict(X)
print(y_predict_knn_test)
print('knn accuracy:',accuracy_score(y,y_predict_knn))#准确率#对比模型分布和实际分布
print(pd.value_counts(y_predict_knn),pd.value_counts(y))
金融风控欺诈检测
import numpy as np
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split, GridSearchCV, StratifiedKFold
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.metrics import (classification_report, confusion_matrix, roc_auc_score, roc_curve, precision_recall_curve)
import matplotlib.pyplot as plt
import seaborn as sns
from imblearn.over_sampling import SMOTE
from sklearn.datasets import make_classificationclass FraudDetectionSystem:def __init__(self):self.scaler = StandardScaler()self.model = Noneself.label_encoder = LabelEncoder()def generate_financial_data(self, n_samples=10000):"""生成模拟的金融交易数据"""# 创建不平衡数据集(欺诈交易占少数)X, y = make_classification(n_samples=n_samples,n_features=10,n_informative=8,n_redundant=2,n_clusters_per_class=1,weights=[0.99, 0.01], # 99% 正常,1% 欺诈random_state=42,flip_y=0.01 # 添加一些噪声)# 创建有意义的特征名称feature_names = ['Transaction_Amount', 'Hour_of_Day', 'Day_of_Week','User_Age', 'User_Income', 'Previous_Transactions','Location_Distance', 'Device_Type', 'Browser_Type', 'Session_Duration']df = pd.DataFrame(X, columns=feature_names)df['Is_Fraud'] = y# 调整数据范围使其更真实df['Transaction_Amount'] = np.abs(df['Transaction_Amount']) * 100 + 10df['User_Age'] = (np.abs(df['User_Age']) * 30 + 18).astype(int)df['User_Income'] = np.abs(df['User_Income']) * 50000 + 30000return dfdef explore_data(self, df):"""探索性数据分析"""print("=== 数据概览 ===")print(f"数据集形状: {df.shape}")print(f"欺诈交易比例: {df['Is_Fraud'].mean():.4f}")plt.figure(figsize=(15, 10))# 类别分布plt.subplot(2, 3, 1)fraud_counts = df['Is_Fraud'].value_counts()plt.pie(fraud_counts, labels=['正常', '欺诈'], autopct='%1.1f%%', colors=['lightgreen', 'lightcoral'])plt.title('交易类别分布')# 交易金额分布plt.subplot(2, 3, 2)plt.hist(df[df['Is_Fraud'] == 0]['Transaction_Amount'], alpha=0.7, label='正常', bins=30, color='green')plt.hist(df[df['Is_Fraud'] == 1]['Transaction_Amount'], alpha=0.7, label='欺诈', bins=30, color='red')plt.xlabel('交易金额')plt.ylabel('频次')plt.legend()plt.title('交易金额分布')# 相关性热力图plt.subplot(2, 3, 3)correlation = df.corr()sns.heatmap(correlation, annot=True, cmap='coolwarm', center=0)plt.title('特征相关性热力图')plt.tight_layout()plt.show()def preprocess_data(self, df):"""数据预处理"""X = df.drop('Is_Fraud', axis=1)y = df['Is_Fraud']# 处理类别不平衡smote = SMOTE(random_state=42)X_resampled, y_resampled = smote.fit_resample(X, y)print(f"重采样后数据形状: {X_resampled.shape}")print(f"重采样后类别分布: {pd.Series(y_resampled).value_counts().to_dict()}")# 数据标准化X_scaled = self.scaler.fit_transform(X_resampled)return train_test_split(X_scaled, y_resampled, test_size=0.3, random_state=42, stratify=y_resampled)def tune_hyperparameters(self, X_train, y_train):"""超参数调优"""param_grid = {'n_neighbors': [3, 5, 7, 9, 11],'weights': ['uniform', 'distance'],'metric': ['euclidean', 'manhattan', 'minkowski']}knn = KNeighborsClassifier()cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)grid_search = GridSearchCV(knn, param_grid, cv=cv, scoring='f1', n_jobs=-1, verbose=1)print("开始超参数调优...")grid_search.fit(X_train, y_train)print(f"最佳参数: {grid_search.best_params_}")print(f"最佳交叉验证分数: {grid_search.best_score_:.4f}")return grid_search.best_estimator_def train_model(self, X_train, y_train, use_grid_search=True):"""训练K-NN模型"""if use_grid_search:self.model = self.tune_hyperparameters(X_train, y_train)else:self.model = KNeighborsClassifier(n_neighbors=5, weights='distance', metric='manhattan')self.model.fit(X_train, y_train)return self.modeldef evaluate_model(self, X_test, y_test):"""评估模型性能"""y_pred = self.model.predict(X_test)y_pred_proba = self.model.predict_proba(X_test)[:, 1]print("=== 分类报告 ===")print(classification_report(y_test, y_pred, target_names=['正常', '欺诈']))# 混淆矩阵plt.figure(figsize=(15, 5))plt.subplot(1, 3, 1)cm = confusion_matrix(y_test, y_pred)sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=['正常', '欺诈'], yticklabels=['正常', '欺诈'])plt.ylabel('真实标签')plt.xlabel('预测标签')plt.title('混淆矩阵')# ROC曲线plt.subplot(1, 3, 2)fpr, tpr, _ = roc_curve(y_test, y_pred_proba)roc_auc = roc_auc_score(y_test, y_pred_proba)plt.plot(fpr, tpr, label=f'ROC曲线 (AUC = {roc_auc:.3f})')plt.plot([0, 1], [0, 1], 'k--')plt.xlabel('假正率')plt.ylabel('真正率')plt.title('ROC曲线')plt.legend()# 精确率-召回率曲线plt.subplot(1, 3, 3)precision, recall, _ = precision_recall_curve(y_test, y_pred_proba)plt.plot(recall, precision, label='PR曲线')plt.xlabel('召回率')plt.ylabel('精确率')plt.title('精确率-召回率曲线')plt.legend()plt.tight_layout()plt.show()return y_pred, y_pred_probadef feature_importance(self, df):"""分析特征重要性(基于模型性能)"""X = df.drop('Is_Fraud', axis=1)feature_names = X.columns# 使用排列重要性from sklearn.inspection import permutation_importanceX_scaled = self.scaler.transform(X)result = permutation_importance(self.model, X_scaled, df['Is_Fraud'], n_repeats=10, random_state=42)importance_df = pd.DataFrame({'feature': feature_names,'importance': result.importances_mean,'std': result.importances_std}).sort_values('importance', ascending=False)plt.figure(figsize=(10, 6))plt.barh(importance_df['feature'], importance_df['importance'], xerr=importance_df['std'])plt.xlabel('特征重要性')plt.title('K-NN模型特征重要性')plt.tight_layout()plt.show()return importance_df# 企业级应用示例
def run_fraud_detection():print("🚀 开始金融风控欺诈检测项目...")# 初始化fraud_system = FraudDetectionSystem()# 1. 生成金融数据print("📊 生成模拟交易数据...")transaction_data = fraud_system.generate_financial_data(10000)# 2. 探索性分析print("🔍 进行探索性数据分析...")fraud_system.explore_data(transaction_data)# 3. 数据预处理print("🔧 数据预处理中...")X_train, X_test, y_train, y_test = fraud_system.preprocess_data(transaction_data)# 4. 训练模型print("🤖 训练K-NN模型中...")model = fraud_system.train_model(X_train, y_train, use_grid_search=True)# 5. 评估模型print("📊 评估模型性能...")y_pred, y_pred_proba = fraud_system.evaluate_model(X_test, y_test)# 6. 特征重要性分析print("📈 分析特征重要性...")importance_df = fraud_system.feature_importance(transaction_data)print("\n=== 最重要的欺诈检测特征 ===")print(importance_df.head(10))return fraud_system, transaction_data, importance_df# 运行项目
if __name__ == "__main__":system, data, importance = run_fraud_detection()