使用 NVIDIA GPU 加速让 XGBoost 快速提升 46 倍
Stop Waiting: Make XGBoost 46x Faster with One Parameter Change文章主要解释了NVIDIA GPU 如何让xgboost进行加速推理。
文章目录
- 1 机器学习中最昂贵的成本是你的时间
- 2 “魔法”参数:轻松启用 GPU 加速
- 4 实测效果:Amex 违约预测实现 46 倍加速
- 4 GPU 加速的最佳实践
- 4.1 从合适大小的数据开始
- 4.2 注意显存容量:确保数据能装进 GPU 显存
- 4.3 优化数据类型以减少内存占用
- 4.4 端到端加速:用 cudf.pandas 优化数据准备
- 4.5 数据集超出显存时:使用外部内存功能
- 5 超越显存限制:用 XGBoost 3.0 训练 TB 级数据集
- 6 夺回你的时间
我花了比愿意承认的更多时间盯着进度条发呆。
你肯定遇到过这样的场景:数据清洗完成,特征工程做完,逐列核对无误,终于运行了 model.fit(X, y)。然后……什么都没发生。
CPU 慢得让人痛苦。
你去喝杯咖啡,查看 Slack,回来后它还在卡着。时间像被无限拉长,进度停滞,灵感在你测试之前就溜走了。每一次停滞的实验,都像是一次小小的失败。
起初,我以为问题出在我或模型上。
也许我做错了特征工程,也许超参数没调好。几周过去后,我才意识到真正的罪魁祸首根本不是算法,而是训练方式。
其实有更聪明的方法。
只需一个小参数的改变,加上 GPU 加速,就能把小时级的等待缩短到分钟。你马上回到状态,持续测试、迭代、学习。不再“看机器”,而是真正解决问题。
这正是本文要讲的内容。

1 机器学习中最昂贵的成本是你的时间
XGBoost 被誉为梯度提升的强力引擎,是表格数据的黄金标准。但它的强大伴随着代价。当数据量达到百万级别,训练时间会从几分钟膨胀到数小时。
大多数实践者不知道,XGBoost 有一个参数可以彻底改变这种体验。打开它,你的模型训练速度能提升 5 到 15 倍。无需改算法,无需新库,只需在配置里加一行。
这个改变让你从一天完成一次实验,到一天能跑好几个。曾经拖了好几天的超参数搜索,现在几小时就结束。你不必再盯着进度条,保持思路连贯,快速验证想法。
在很多情况下,CUDA 加速是完成任务和永远做不完之间的分水岭。
2 “魔法”参数:轻松启用 GPU 加速
XGBoost 内置支持 NVIDIA CUDA,利用 GPU 加速不需要新库或重写代码。通常只需改一个参数。
下面是典型的 CPU 工作流程:
import xgboost as xgb
model = xgb.XGBClassifier( ... tree_method="hist"
)
model.fit(X_train, y_train)
想用 GPU,只需把 tree_method 改成 "gpu_hist":
import xgboost as xgb
model = xgb.XGBClassifier( ... tree_method="gpu_hist"
)
model.fit(X_train, y_train)
或者对于回归器,设置 device="cuda":
import xgboost as xgb
xgb_model = xgb.XGBRegressor(device="cuda")
xgb_model.fit(X, y)
就是这么简单。
无论是 XGBClassifier 还是 XGBRegressor,添加 device="cuda" 就告诉 XGBoost 使用所有可用的 NVIDIA GPU 资源。这个小改动能让大规模数据集训练速度提升 5 到 15 倍。
4 实测效果:Amex 违约预测实现 46 倍加速
为了展示加速效果,我们在美国运通违约预测数据集的一个 550 万行(50GB)子集上,训练了 XGBoost 分类器,包含 313 个特征。
训练环境分为两种:
- CPU:M3 Pro 12 核 CPU。
- GPU:NVIDIA A100 GPU。
训练时间对比如下:
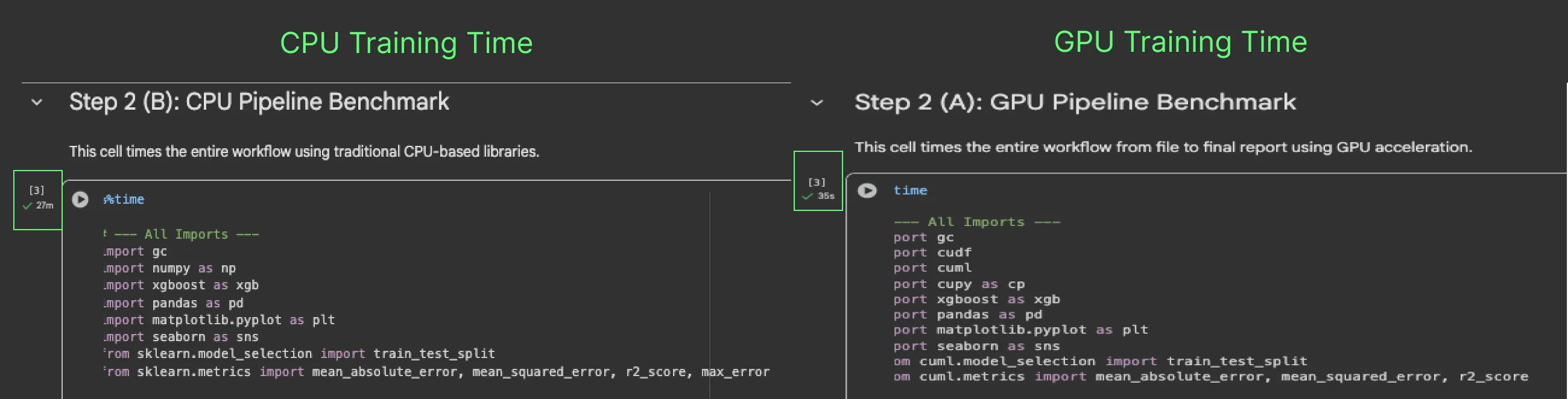
- CPU 训练时间:27 分钟
- NVIDIA GPU 训练时间:35 秒
性能几乎完全一致。
GPU 优势随着数据规模增大而更明显。对于 5000 万或 5 亿行数据,CPU 训练时间可能长达数天,而 GPU 则能轻松应对,时间增长非常有限。
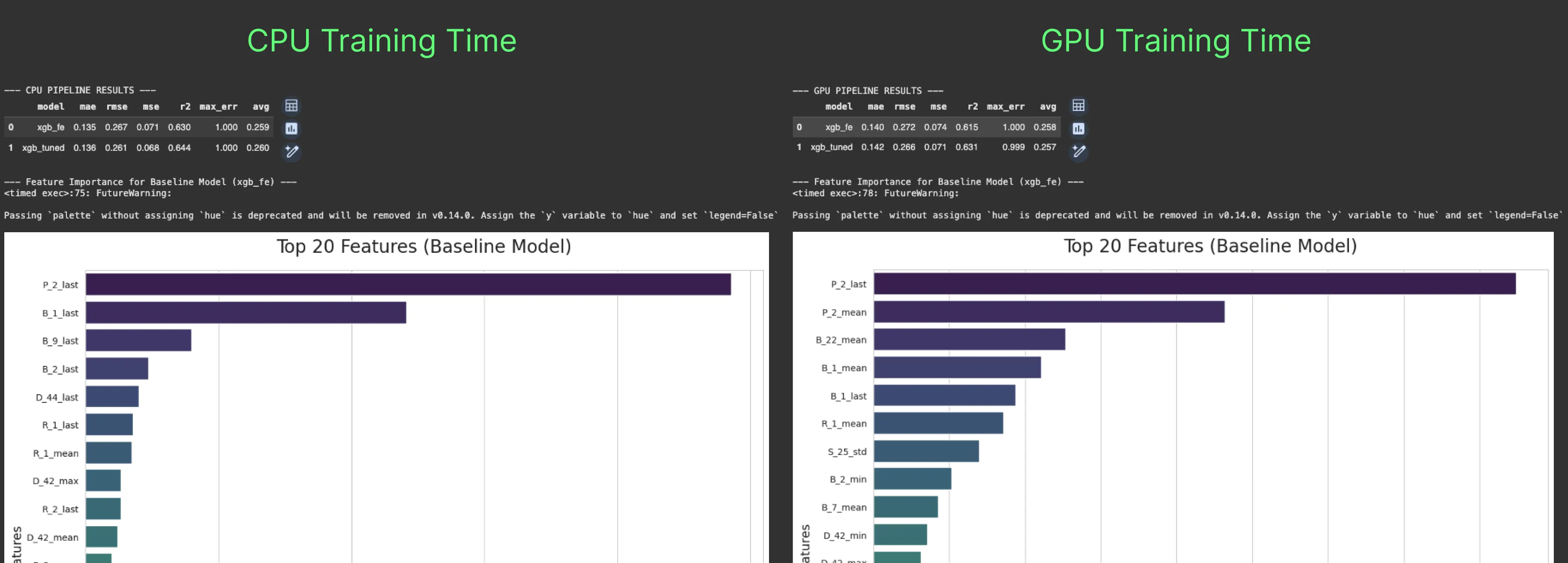
在 R²、RMSE、MAE 等指标上,CPU 和 GPU 模型差异极小,无论是基线模型还是调优后的模型。因此,你不会为了速度牺牲准确度。相反,你可以在更短时间内完成更多实验和迭代。
在特征重要性方面,两者都认为 P-2_last 是最重要的特征,B_1_last 也进入前五。
但之后开始出现差异:
CPU 模型侧重 _last 特征,关注最新值;GPU 模型偏爱聚合的 _mean 特征,如 P-2_mean、B-22_mean 和 B-1_mean,这些特征在 CPU 模型前五中未出现。
这暗示了一个假设:CPU 模型捕捉的是短期风险信号,反应最新事件;GPU 模型则捕捉长期模式,评估客户的整体风险。换句话说,CPU 回答“这个客户现在有风险吗?”,GPU 回答“这个客户长期来看是否存在风险?”。
我们预计在更大规模(TB 级)数据集上,GPU 由于能一次处理更多数据,可能带来稍微更好的指标表现。但主要优势仍是速度:秒级训练代替小时。
动手试试: 运行这份 Notebook,亲自感受性能差异。
4 GPU 加速的最佳实践
添加 device="cuda" 是第一步。要最大化 GPU 加速效果,请注意以下几点:
4.1 从合适大小的数据开始
GPU 加速最适合数据量大到足以抵消数据从系统内存传输到 GPU 显存的开销。通常数据大小在 4GB 到 24GB 之间效果最佳,2-4GB 也可能看到收益。
对于非常小的数据集,传输和并行计算的开销可能超过训练时间,导致 CPU 训练更快。务必针对具体工作负载做基准测试。
4.2 注意显存容量:确保数据能装进 GPU 显存
GPU 有独立的高速显存(VRAM),与系统内存分开。训练时,数据集必须完全装入显存。可以用 nvidia-smi 命令查看显存使用情况。
经验法则:如果你的 DataFrame 占用 10GB 系统内存,GPU 显存最好超过 10GB。常用的 GPU 如 NVIDIA A10G(24GB)和 A100(40-80GB)适合大规模任务。若遇到内存不足错误,说明数据集超出显存容量。
4.3 优化数据类型以减少内存占用
节省显存最简单方法是使用更高效的数据类型。Pandas 默认用 64 位类型(float64、int64),通常精度超过需求。
将列转换为 32 位类型(float32、int32)可以大约减半内存使用,且不影响模型准确度。例如:df['my_column'].astype('float32')。这个小调整对大数据集尤其重要。
4.4 端到端加速:用 cudf.pandas 优化数据准备
通常,训练本身不是最大瓶颈,数据准备才是。CPU 与 GPU 之间频繁传输数据会增加开销,拖慢流程。
cudf.pandas 库提供 GPU 版的 pandas 替代品。只需脚本开头写 import cudf.pandas as pd,所有数据加载和特征工程操作都在 GPU 上执行。把这个 GPU 原生 DataFrame 传给 XGBoost,能消除传输开销,实现端到端的巨大加速。
4.5 数据集超出显存时:使用外部内存功能
如果数据集有 100GB,但 GPU 只有 24GB 显存怎么办?XGBoost 3.0 支持外部内存,可以分块从系统内存或磁盘读取数据,边读边处理。
这让单 GPU 训练 TB 级数据成为可能,无需降采样,也不用回退到慢速 CPU。我们将在下一节详细介绍这个功能。
5 超越显存限制:用 XGBoost 3.0 训练 TB 级数据集
过去,数据集大小受限于 GPU 显存,超过显存就只能降采样或用 CPU 训练。
XGBoost 3.0 推出了外部内存能力,允许从系统内存或磁盘流式读取数据到 GPU 处理,数据无需全部装入显存。
这使得单 GPU 上可扩展梯度提升成为现实,之前需要大规模分布式集群才能完成的任务,现在单机就能搞定。在 NVIDIA Grace Hopper Superchip 等现代硬件上,速度可比多核 CPU 系统快 8 倍,且性能和准确度保持不变。
该功能使用核心的 DMatrix 对象,而非 Scikit-Learn 封装,但参数配置依旧熟悉。你只需指向磁盘上的数据集:
配合 cudf.pandas 进行数据准备,整个 TB 级数据集工作流都能跑在 GPU 上。大规模数据带来更强模型,同时训练时间大幅缩短。
6 夺回你的时间
在机器学习中,最大的成本是等待时间。等待模型训练、数据处理、实验完成,都会拖慢你验证想法、发现洞察、创造价值的速度。
NVIDIA GPU 加速帮你夺回这部分时间。
只需改一个参数,就能让模型训练快 5-15 倍,数据管道端到端跑在 GPU 上,甚至处理超出显存的数据集。速度提升让你快速迭代,边测试边处理数据,不再被长时间等待拖累。
工具齐全,集成无缝,设置简单。更快的迭代意味着更多实验、更多发现,最终造就更好的模型。
接下来,你可以选择:
- 跟随 NVIDIA 注释的 Notebook 逐步学习。
- 观看完整讲解的 YouTube 视频。
- 深入官方的 XGBoost 文档,探索所有
cuda配置选项。
别只听我说,运行我的 Amex notebook,亲自感受你的工作流能快多少。