如何实现静态库与动态库的制作
在之前的博客中我们老是提到C语言的库可以封装底层调用接口,从而使得我们使用系统调用接口的成本逐渐降低(只需要使用C标准库给我们提供的函数就可以直接实现相应的功能),但是现在,我就想知道这个库到底是怎么做的,既然现在我已经了解了这么多的系统调用接口,那么我自己能不能做一个库呢,做完这个库我能不能也发送给大家,让大家使用我写的库呢?答案是当然可以,因为C语言库也是封装了人家系统调用接口的函数才是先相应的功能,那么我们又何尝不可以呢,今天,我们就创建一个简单的动静库,让大家明白这些所谓的库,到底是通过什么样的方式制作出来的。
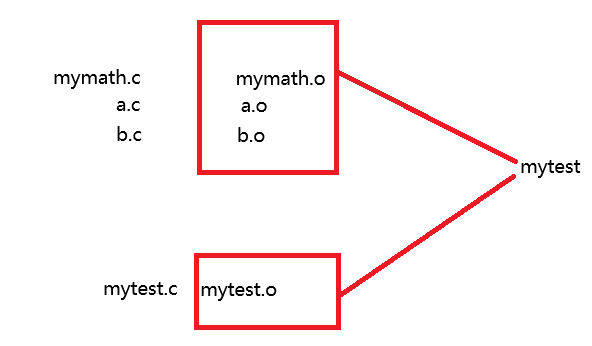
形成一个可执行程序的整个过程
在了解制作库之前,我们先来了解一些基础知识。
我们先通过一段代码感受一下一个C语言程序编译运行的整个阶段
#include <stdio.h>
#define N 10
#define MY_SELFint main()
{
#ifdef MY_SELF// 去注释,预编译之后你就看不到我了。printf("hello buluo : %d\n", N);printf("hello 408\n");
#else//由于我已经定义了MY_SELF,所以在预编译的时候你是看不到我的printf("你看不到我!!!\n");
#endif
}
- 预编译
- 去注释:去除源代码中的注释。
- 头文件展开:将
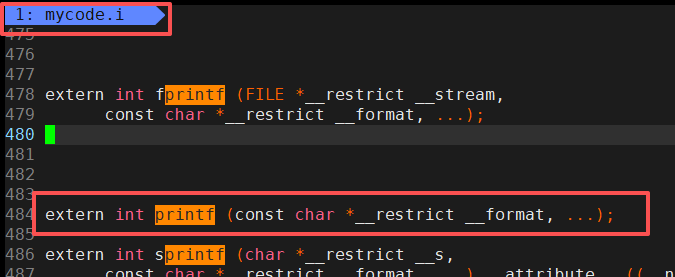
#include指定的头文件内容插入到源文件中。 - 条件编译:根据
#ifdef、#ifndef等条件决定是否编译某段代码。 - 宏替换 :将#define定义的宏替换为实际值。
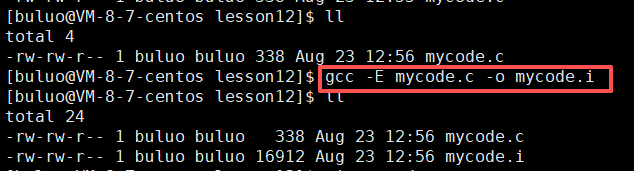
首先,我们先将我们的文件mycode.c通过这样的命令进行预编译,形成我们的预编译文件mycode.i
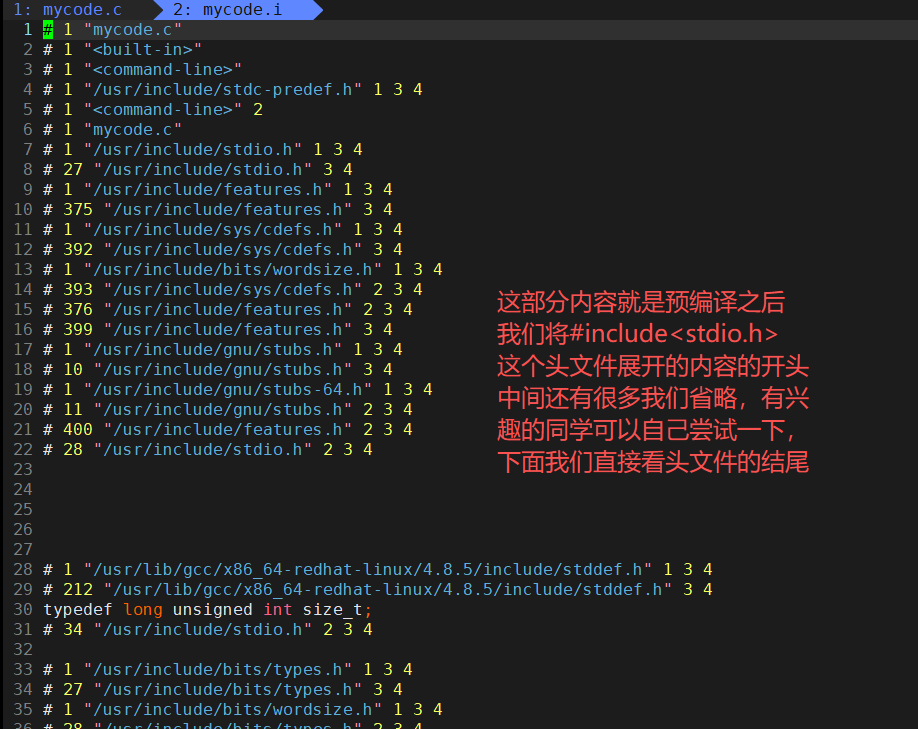
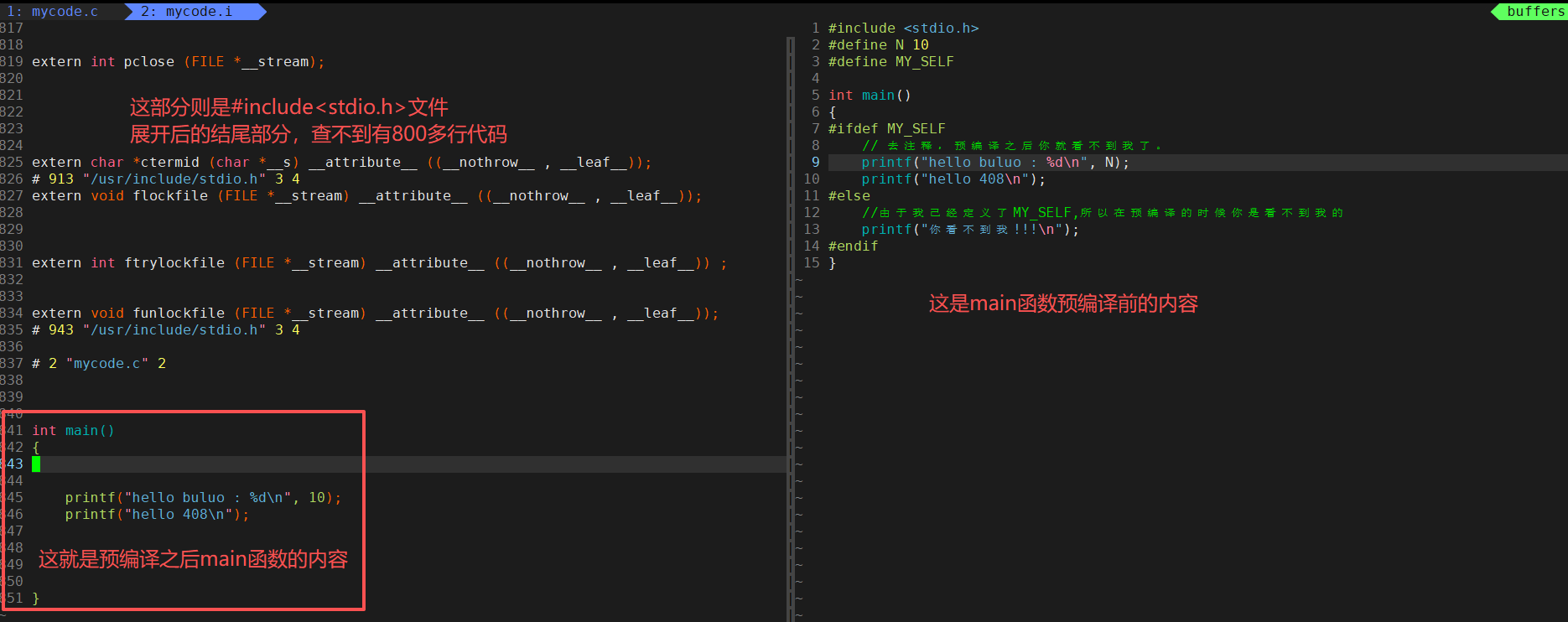
通过两幅图的对比,我们可以直观的看到预处理阶段我们完成的功能,但是针对预处理的阶段的条件编译这部分内容我想补充一点就是,在真实的项目的条件编译不是这样使用的,真实的项目中的条件编译运用于不用的平台,比如我们可以让条件编译的一个条件中的内容是Windows平台下可以运行的,另一个条件编译则是在Linux平台下可以运行的。一般类似于这种场景的时候,我们才会使用条件编译,这样就可以不必使用两套代码去完成不同平台下程序的使用。
- 编译阶段
- 词法分析:将源代码分解为词法单元(如标识符、关键字)。
- 语法分析:检查语法结构是否符合语言规范,生成抽象语法树(AST)。
- 语义分析:检查类型匹配、变量声明等语义规则。
- 优化:对中间代码进行优化(如常量折叠、死代码删除)。
- 生成汇编代码:输出与目标平台相关的汇编代码(
.s文件)。
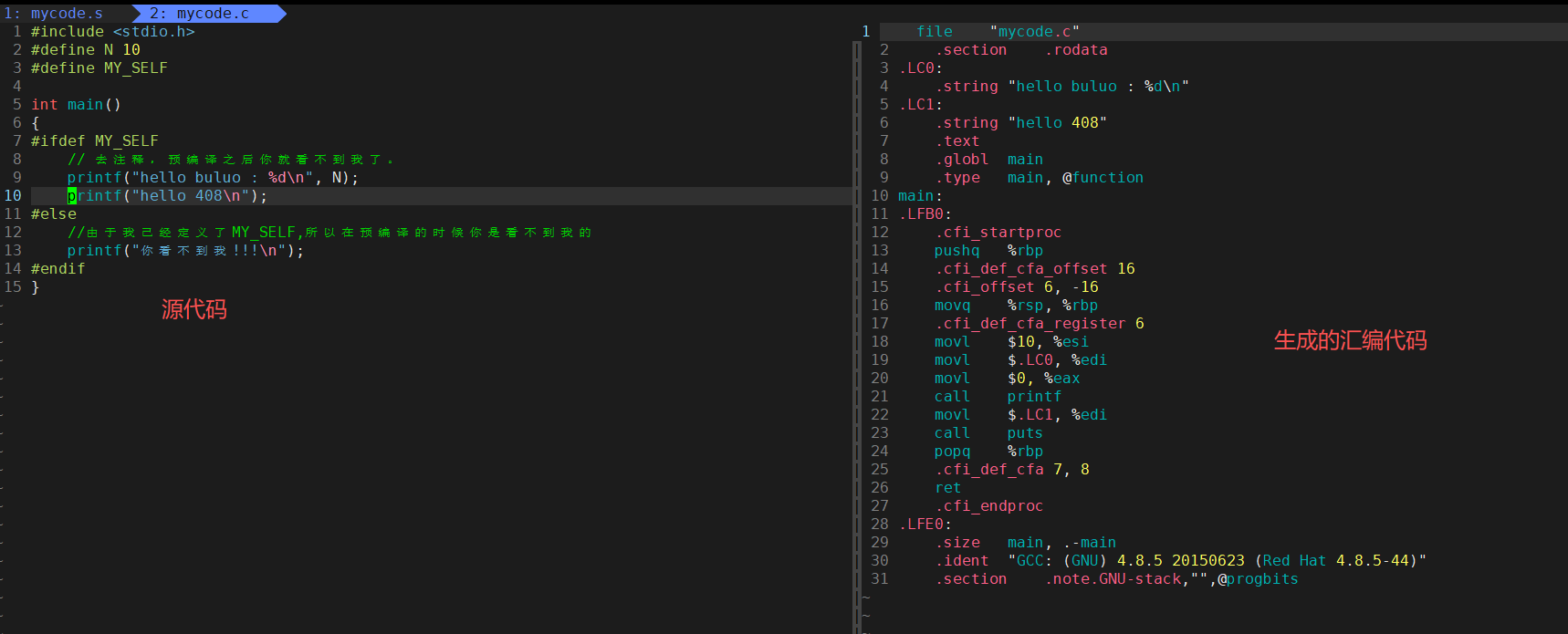
接下来的这个编译阶段就是将我们预编译之后的代码转换为汇编语言
 、
、
接着,就是将我们的文件mycode.i通过这样的命令进行编译,形成我们的汇编代码mycode.s
- 汇编阶段
- 指令转换:将汇编指令逐条翻译为机器指令。
- 符号表生成:记录函数和变量的地址信息。
- 生成目标文件:输出
.o(Unix/Linux)或.obj(Windows)文件,包含二进制代码和重定位信息。
紧接着,汇编阶段就是将我们的汇编代码转换为机器码(目标文件)。
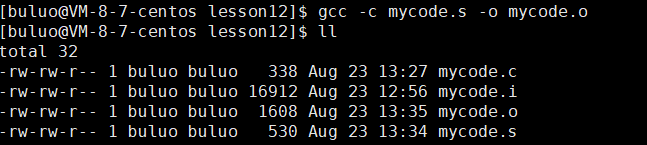
接着,就是将我们的汇编代码mycode.s通过这样的命令进行汇编,形成我们的目标文件mycode.o,也叫可重定位目标二进制文件,简称目标文件。
插一个小插曲:其实这个就是考408的同学,在学习操作系统的时候的动态重定位是一样的,也就是这个目标文件内部使用的依旧是逻辑地址,即使是装入内存之后依旧是逻辑地址,直到运行的时候会配合我们内存中的重定位寄存器,再将我们的逻辑地址转换为物理地址从而可以正确执行我们的代码。(重定位寄存器的值(即程序在内存中的基址)也会保存在 PCB 中,方便进程切换时恢复。)

- 链接
- 符号解析:确保所有符号(函数、变量)有明确定义。
- 地址重定位:调整指令中的地址偏移量,使程序能正确加载到内存。
- 生成可执行文件:输出如
a.out(Unix/Linux)或.exe(Windows)文件。
链接阶段将多个目标文件和库文件合并为可执行文件。主要分为两种方式:
- 静态链接:将库代码直接复制到可执行文件中,生成独立的二进制文件。
- 动态链接:在运行时加载共享库(如
.so或.dll文件),减少内存占用。
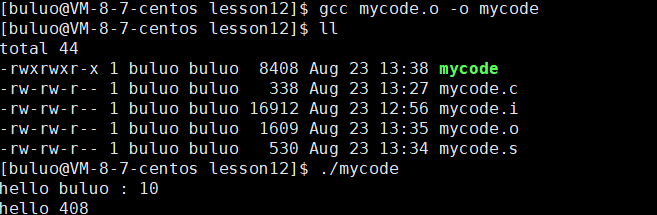
最后,我们通过链接,将我们的可重定向二进制文件(也就是目标文件)与我们的库进行链接形成可执行程序。
现在大家有没有想过一个问题就是在预编译阶段包含的#include<stdio.h>中也只有函数的声明,而没有具体实现,那么在哪里实现的printf的函数的呢?
其实答案就是:我们的系统一般默认都会把这些库实现的函数放在一个名为libc.so.6的库文件中去,在没有特别指定的时候,gcc会到系统默认的搜索路径"/usr/lib64"下进行查找(在之前博客中讲环境变量时我们有所了解),这样就可以链接到libc.so.6库文件中去,这样就可以实现printf,而这也就是链接的作用。
![]()

C语言的标准库,本质上就是一个文件,在Linux中动态库(.so)和静态库(.a),而在Windows中的动态库(.dll)和静态库(.lib)
而其实库就是把源文件(.c),经过一定的翻译,然后打包。给你的时候只需要将这个库给你即可,不需要将太多的源文件给你,同时也达到了隐藏源文件的目的(就比如说最近有个博主举报王者荣耀的匹配机制有问题这一事件,这就是一个很好的证明,如何王者荣耀给你使用一个客户端之后,让你能看到王者荣耀的源代码,那王者荣耀人家还怎么运转,所以封装成库,也有一部分原因就是对源代码的保护)。
所以现在我们就明白了一点就是头文件提供方法的声明,库文件实现方法的实现 + 我们的代码 = 我们写的程序。
浅谈动静态链接的特性
接下来我们再来了解一下我们的目标文件(.o)是如何与库进行链接的?(动态链接和静态链接)
- 动态链接
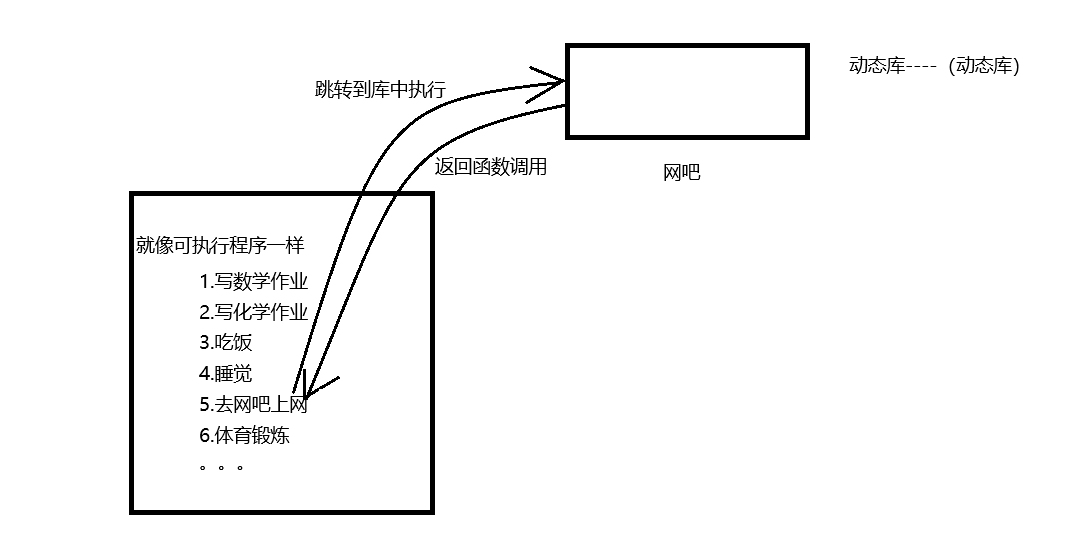
先举个例子:假设现在在我们是刚上高中的学生,有的学校是寄宿制的,现在你以上高中就像,这三年都是寄宿的,平时也回不了家,玩不了电脑,这生活还有什么乐趣呀,并且我现在还有一个游戏的任务快要完成了,完成了我就可以获得一个绝世的工具,这个时候开学了玩不上电脑,一切都毁了,这个时候,我们本着决不放弃的原则,你一到学校的时候,管他三七二十一,赶紧认识了了一个高三即将毕业的学长,追着学长问,咱们在这里有没有什么科学上网的办法,而学长作为了一个经历了三年摸爬滚打的生活,早已经对周边的地区了如指掌,于是就告诉哦你附近有一所网吧,你可以在周末的时候去科学上网,这样,你就获得了第一手的科学上网的资料,于是在第一个周末就开始实施,因为自己这个游戏的活动快要结束了,刻不容缓,于是你再写完数学作业,在写完化学作业,吃完饭,午休一段时间后,精力充沛去了网吧,开始完成你心心念念的任务,最后获取到想要的装备之后,心满意足的回到学校继续做你该做的事情,这其实就是一个动态库。
我们写的可执行程序就是这样,先按照我们程序的顺序进行,当使用到C标准库中的函数的时候,就去动态库中找到如何使用该函数,使用完之后,再回到我们的主程序中继续执行。
而学校想上网,想要搞装备的不止你一个人,有好几千人呢,这个时候他们都只需要去这个网吧去上网即可。所以这就意味着,我们写的程序也是如此,无论哪个程序,只需要去C标准库中去实现即可,所以我们的动态库有一份即可,这个大家就可以共享这个标准库。
现在有一天,我们的帽子叔叔去到这个网吧查看是否有未成年人上网,结果一看这么多,直接就把这家店查封了,这个时候,你就再也玩不了电脑了,而且不止是你,和你一样的小伙伴都玩不了了。
这就意味着动态库不能确实,一旦缺失,影响的不仅仅是一个程序,可能会导致很多程序都无法运行,这就是动态库。
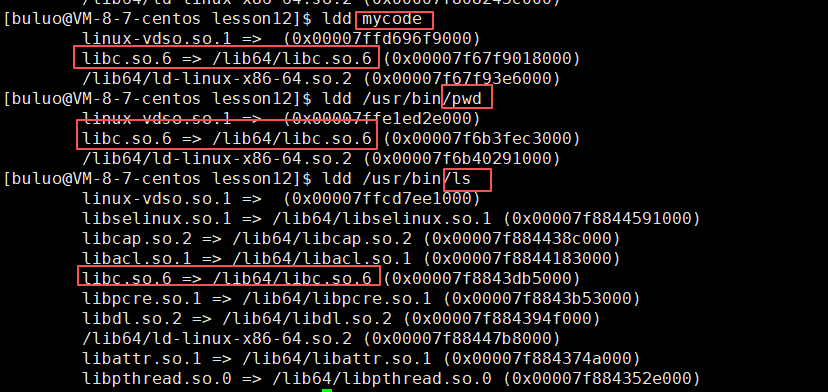
可以明显看到在Linux中有很多的程序就是使用的C标准库。
- 静态链接
还是之前的例子,现在我们学校附近的网吧已经被关闭了,但是我们使用电脑的欲望这是只增不减,而网吧老板也考虑到了这个情况,鉴于自己的网吧生意已经被帽子叔叔盯上了,自己也干不了了,总不能让自己这些东西砸手里吧,于是低价开始卖二手电脑,而你听到这个这个消息,于是就开始盘算着自己的计划,每天开始省吃俭用,直到你已经凑足了钱,去老板那里买了一台电脑,这个时候你就有了一台属于自己的电脑,等下次周末的时候,在写完数学作业,化学作业,吃饭,睡觉之后不需要再去网吧上网了,因为你现在已经有了一台属于自己的电脑了,而你的同学看到你这么幸福的使用电脑,开始逐一效仿,不久每个人就都有了一台电脑,这样就再也不需要去网吧上网了。
这种我们将网吧上网的这种功能复制到我们的程序中,就是静态链接。
而现在假如有一天这个老板已经将自己的全部电脑都卖光了,这个时候这个老板也就离开了这个是非之地,而那么也根本不关心这个老板还在不在,因为你们现在已经人手一个电脑了,所以不在关心这个老板还能不能干下去,所以忘本这一块。。。。
这也就是我们的编译器在使用静态库进行链接的时候,会将静态库中的方法拷贝到程序中,这样这个程序就不再依赖静态库了。这就是静态链接。
而在Linux中,我们的默认生成的可执行文件是动态链接的,现在我们就来使用静态链接的命令进行观察一下。
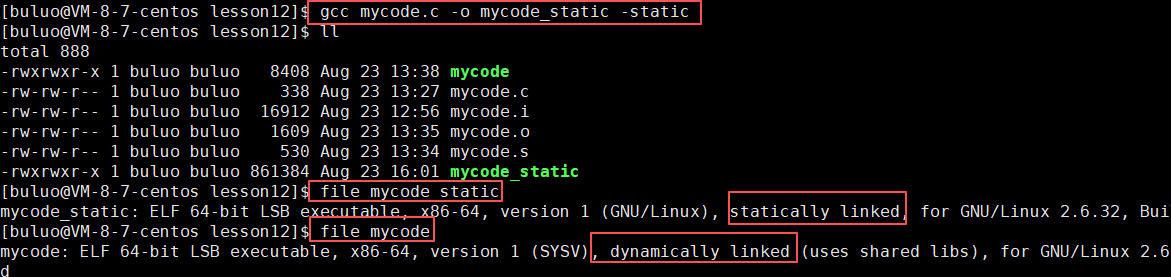
这样就可以实现静态链接,同时细心的同学也是可以看到,我们的静态链接(861384)后的可执行文件明显是要比动态链接(8408)的可执行文件要大的多,这就是因为我们的将静态库中的方法拷贝进我们的程序中,这就导致我们静态链接后的可执行文件很大。
制作库
现在一般情况下,我们自定义静态库的命名规则为libXXX.a(XXX是静态库的名字),自定义动态库的命名规则为libXXX.so(其中XXX是动态库的名字)。
静态库
现在我们下来制作一下静态库
首先我们将我们的源代码和头文件进行分离:
- 头文件(mymath.h)
#pragma once
#include <stdio.h>extern int myerrno;int add(int x, int y);
int sub(int x, int y);
int mul(int x, int y);
int div(int x, int y);- 源文件(mymath.c)
#include "mymath.h"int myerrno = 0;int add(int x, int y)
{return x + y;
}
int sub(int x, int y)
{return x - y;
}
int mul(int x, int y)
{return x * y;
}
int div(int x, int y)
{if(y == 0){myerrno = 1;return -1;}return x / y;
}现在我们就将我们的源代码进行打包,让他看不到我们的源代码具体是如何实现的,毕竟作为一个程序员,我们写的程序就和我们的内裤一样,我们怎么能随便将我们的内裤就让别人看到呢,所以我们必须将我们的源程序封装成库,这样他就看不到我们的底裤了,但是我们还必须让他知道这个库是如何使用的,所以我们也得提供头文件,虽然不像让他知道我们得底裤,但是让他看看头文件还是可以得,毕竟看看头文件也发现不了什么。
那么我们如何让他们看不到我们的底裤呢?其实在使用静态库的时候,无非就是将他们写的源代码(main.c)和我们写的库中的方法(mymath.c)都经过编译之后形成可重定向二进制文件,最后链接形成可执行文件,所以我们完全可以将我们的mymath.c直接编译形成可重定向二进制文件不就可以了么,反正可重定向二进制文件都是二进制,没人看的懂,所以我们只需要将我们mymath.c变为mymath.o,然后将其封装成库,然后和头文件一起打包发给其他人使用即可。
![]()
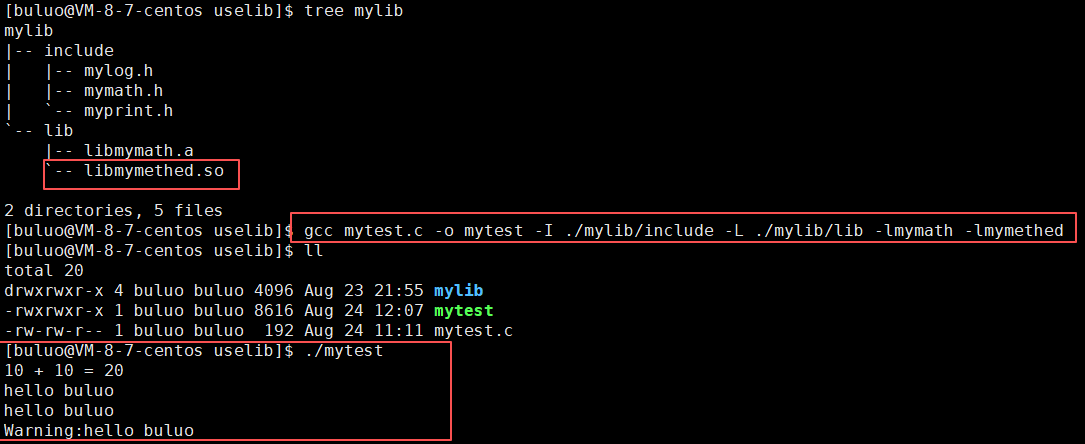
我们制作静态库使用Linux中的命令就是ar,ar是GNU的归档工具,选项rc表示(replace和create),这样我们就做好了一个静态库,现在我们只需要将这个静态库和mymath.h这个头文件一起打包就可以了,为了命名规范,我们将头文件和静态库分别放在两个目录下。
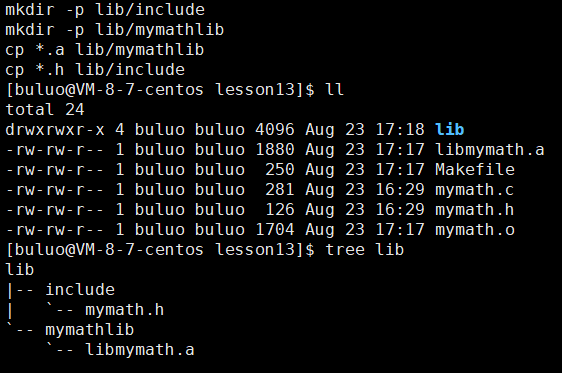
这个lib就相当于我们打包好的文件,现在我们将这个拷贝到另一个目录下进行使用(这个就是我们平时的下载,我们下载的过程就是进行拷贝的过程)。
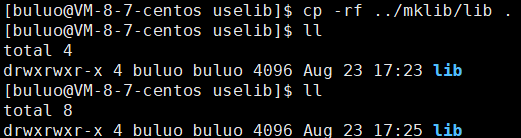
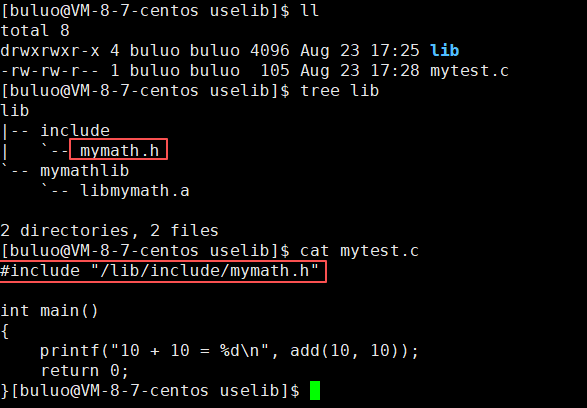
现在已经下载完成,我们开始通过自己写一个程序进程测试,看看能不能成功。
#include "/lib/include/mymath.h"int main()
{printf("10 + 10 = %d\n", add(10, 10));return 0;
}
静态库的链接细节
接下来我们开始编译链接形成可执行文件,但是注意因为这个时候我们使用的不是系统文件(平时C标准库在我们下载之后就我们的系统文件中就有了,Linux则会在自己的/usr/include/ 和/usr/lib64/的系统文件路径下默认寻找,所以我们不必指明),但是我们下载写的是自己的库,那么这个时候就需要我们手动指明我们使用的头文件和库文件的路径,这样编译器在寻找的时候才能正确找到头文件和库,所以我们在进行编译链接时增加两个选项:
- -I(大写的 i) 指明头文件存放的路径
- -L 指明库文件存放的路径
- -l(小写的L)指明具体的库名(这个时候需要去掉库的前缀和后缀,只保留库的名字)
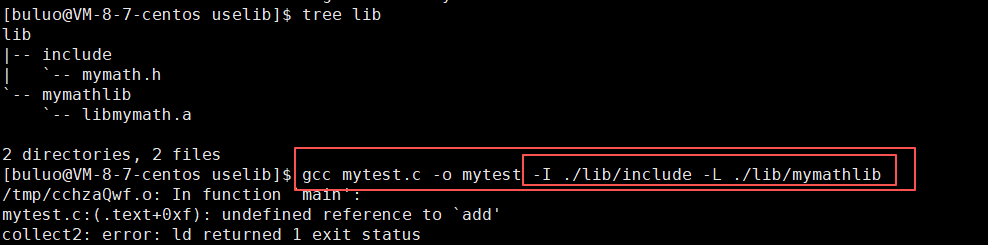
可以看到我们在不知名具体库的名字的时候,编译链接错误。
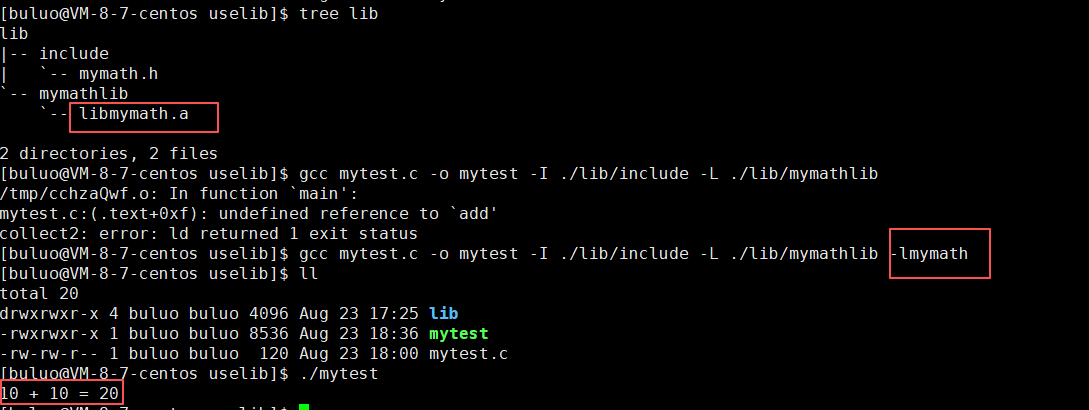
指明具体库的名称之后,我们的程序就可以完美的编译链接成功了。那么为什么头文件和库的处理方式不同?
头文件只是文本展开,预处理阶段根据
#include指令就能找到,编译器只需要知道“在哪些目录里可能有”。库文件是真正的二进制实现,链接器必须明确知道“需要从哪个库里提取符号”。
不指定 -lmymath → 链接器不知道 add() 在哪个库里,就报
undefined reference to 'add'。指定 -lmymath → 链接器才会去
libmymath.a或libmymath.so里找add的实现。
通俗一点来讲就是假如现在我们写的程序特别大,不仅有一个库,会有需许许多多的库,那么那么多库中到底哪个库里有具体的实现,编译器是无法弄清楚的,所以我们必须指明,不能让编译器去猜(这就好比你女朋友老师让你猜她的心思,但是一个人的心思又那么复杂,这就算是福尔摩斯来了也不一定猜的准,所以最好就是直接明示,开个玩笑)。
现在一个静态库我们就做好了,但是唯一一点不好的就是每次gcc链接头文件和库的时候都要写一大堆,有没有什么好的办法,让我们可以不要写那么多的东西,就可以形成可执行文件呢?答案是肯定有的,我们现在就先来试试两种办法
- 将我们写的库也放在gcc默认搜索路径就可以了
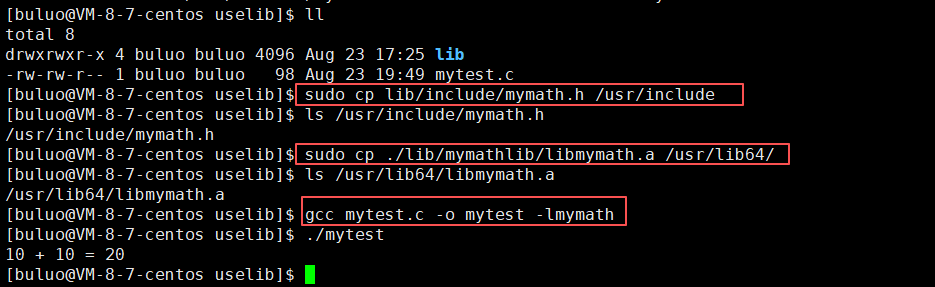
我们只需要将我们写的头文件和库放到系统默认的搜索路劲上,我们就可以不必每次写的时候带头文件和库的所在路径,但是我们依旧要指明要链接哪一个库,因为我们毕竟是属于第三方库,而其实我们平时在Windows上下载东西也是这样的原理,她都是将它的代码和数据都拷贝到你的本地电脑上,并将必要的东西配置到你的系统环境中,然后同时将它所需要的路径自动配置到你电脑中的环境变量中,这样就不需要你花时间折腾,直接使用就可以了。(但是这种方式我们一般不推荐,因为我们写的毕竟还是我们的写的,不如人家专业人员写的,并且我们的命名分格等习惯可能会对人家配置好的文件造成一定的污染,所以一般不推荐这种方式)。
- 通过在gcc默认搜索路径创建软连接
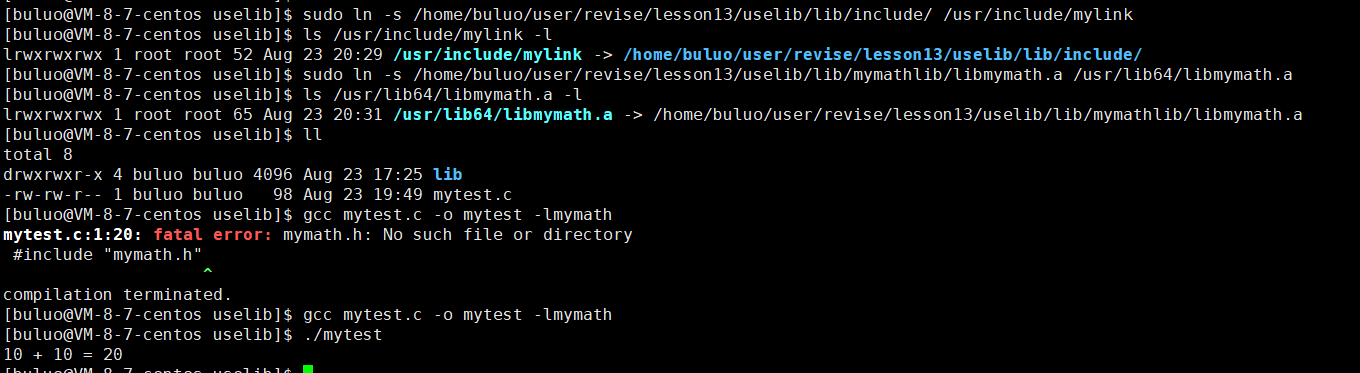
通过创建软连接的方式(软连接的存储内容就是“目标文件的路径字符串”),我们gcc的默认搜索路径依旧可以找到我们对应的头文件和库,但是这里出现了一个小插曲,为什么第一次编译的时候没有编译成功呢?
#include "mylink/mymath.h"int main()
{printf("10 + 10 = %d\n", add(10, 10));return 0;
}这是因为这次我们创建的是软连接,所以我们要重新修改一下我们程序中的头文件,这样才能编译成功。(但是这种方式依旧不推荐,原因如上),这是使用软连接,同时也可以让大家明白我们的软连接的用处所在。
仅仅只是看完静态库的创建,我相信大家已经对所谓的库已经有所了解了,不再像老师之前只抛给我们一些虚无缥缈的概念好多了。简单来讲就是对方写好对应的方法封装成库然后和头文件一起打包给我下载之后,他会执行一些系统命令存放在我电脑的默认搜索路径下,当我使用时,直接根据它的头文件就可以使用了,这就是所谓的库。
动态库
了解上面的静态库创建的整个流程,接下来我们再看看动态库又是如何创建的呢?
- 头文件
- myprint.h
#pragma once #include<stdio.h>void my_print(); - mylog.h
#pragma once #include<stdio.h>void my_log(const char* s);
- myprint.h
- 源文件
- myprint.c
#include "myprint.h"void my_print() {printf("hello buluo\n");printf("hello buluo\n"); } - mylog.c
#include "mylog.h"void my_log(const char *s) {printf("Warning:%s\n", s); }
- myprint.c
其实动态库的创建过程与静态的创建过程大致相同,都是先将源文件通过命令形成可重定向二进制文件,然后将这些可重定向二进制文件组成动态库,最后将其和我们的头文件一起打包发送给其他人使用即可,但是制作动态库和静态库,它们使用的命令是不同的。
- 制作动态库时形成可重定向二进制文件时,我们需要使用-fPIC选项(产生于位置无关码)
- 而将这些个可重定向二进制文件打包成库不再使用ar命令(ar是专门生成静态库的),只需要使用gcc,再增加一个-shared选项(表示生成共享库格式)就可以了形成动态库了。
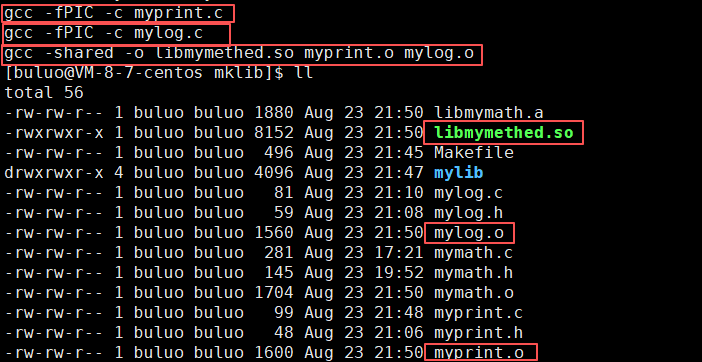
这样我们就形成了动态库了,现在我们可以将我们之前的静态库和现在做成的动态库一并打包,这样其他人就既可以使用我们静态库的方法,也可以使用静态库的方法。
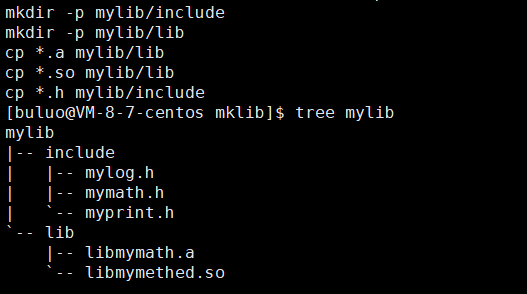
这样就把我们的静态库和动态库都打包好了,同样为了更好的测试,我们现在也将其拷贝到另一个目录下进行使用。
#include "myprint.h"
#include "mylog.h"int main()
{my_print();my_log("hello buluo\n");
}现在我们来通过编译链接执行这段代码,看看我们的动态库能否生成可执行文件。

可以看到我们已经成功的将程序生成了这执行程序,这一切看上去是那么的顺顺利利,现在我们再来执行以下,看看这似乎临门一脚的成功!

但是结果却大失所望,可见我们的程序并没有正确的运行,这是怎么回事呢?可以看到我们的程序并没有链接到我们的动态库上,这又是怎么回事,我们明明不是在编译的时候已经告诉gcc编译器我们使用的动态库在何处了么,为什么还会有链接不到的问题?这真是让我们头痛不已。
原因其实也是很好理解的,在我们gcc编译的时候,我们只是告诉了编译器我们所写的库在哪里,所以gcc可以正确的生成可执行文件,但是我们的可执行文件一旦形成,就和编译器没有关系了,当我们将这个可执行文件加载到内存,形成对应的task_struct(PCB)进程,最后通过调度到CPU上执行的时候,当我们的程序运行到我们写的库中的方法时,我们的操作系统找不到我们写的库在何处,这就导致运行错误,所以我们的需要告诉操作系统我们写的库在哪里,才能使得我们的程序可以执行。所以现在的问题就是如何让我们的操作系统找到我们的库所在位置呢?
其实上面的总结起来就是一句话(我们的动态库不仅仅需要让编译器知道,还得让我们的操作系统知道,而我们如果直接通过命令的方式告诉编译器了,虽然此时编译器知道了,我们的操作系统还是不知道的,所以我们让我们的操作系统可以知道,还是得把我们的动态库得位置放到操作系统可以搜索的路径,即系统路径)
动态库的链接细节
接下来我们提供4中方法来让我们的操作系统也可以找到我们的库所在位置。
- 第一种方法就和我们的静态库是一样的,直接将我们的动态库拷贝进我们的/usr/lib64/目录下,这样操作系统在系统中找的时候就可以找到了。
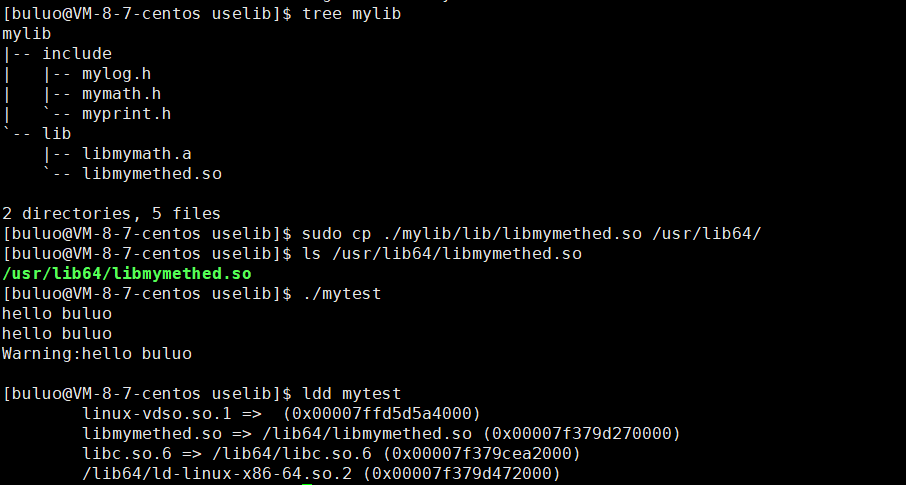
可以看到我们如果将我们的动态库拷贝进我们的/usr/lib64/目录下,我们的操作系统就可以找到了,这样我们的程序也就可以正常运行了。
- 第二种办法同样就是建立软连接就可以让我们的操作系统找到我们对应的动态库所在位置
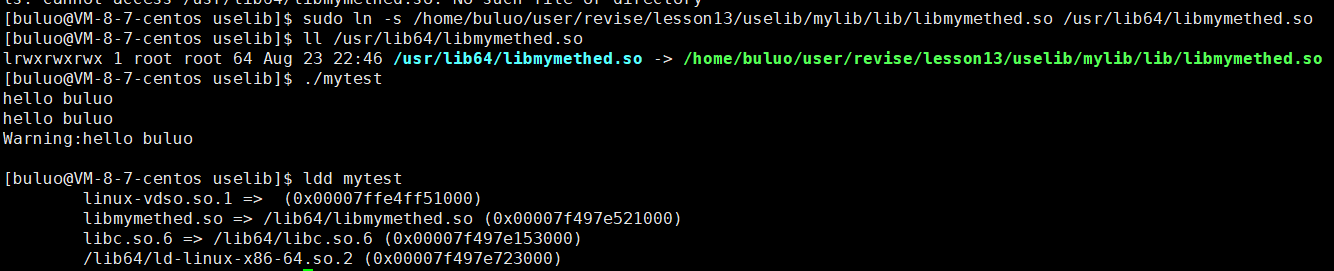
可以看到我们在系统默认路径的库路径/usr/lib64/目录下建立软连接之后。我们的操作系统也是可以找到对应的动态库所在位置了。
- 第三种办法就计较特殊了,在系统中存在一个环境变量是(LD_LIBRARY_PATH),从这个环境变量的名字我们就可以看到它是一个加载库的路径,它的功能就是专门保存用户自定义的库路径,所以只要将我们的库所在路径放在这个环境变量中,我们的操作系统就可以找到了。
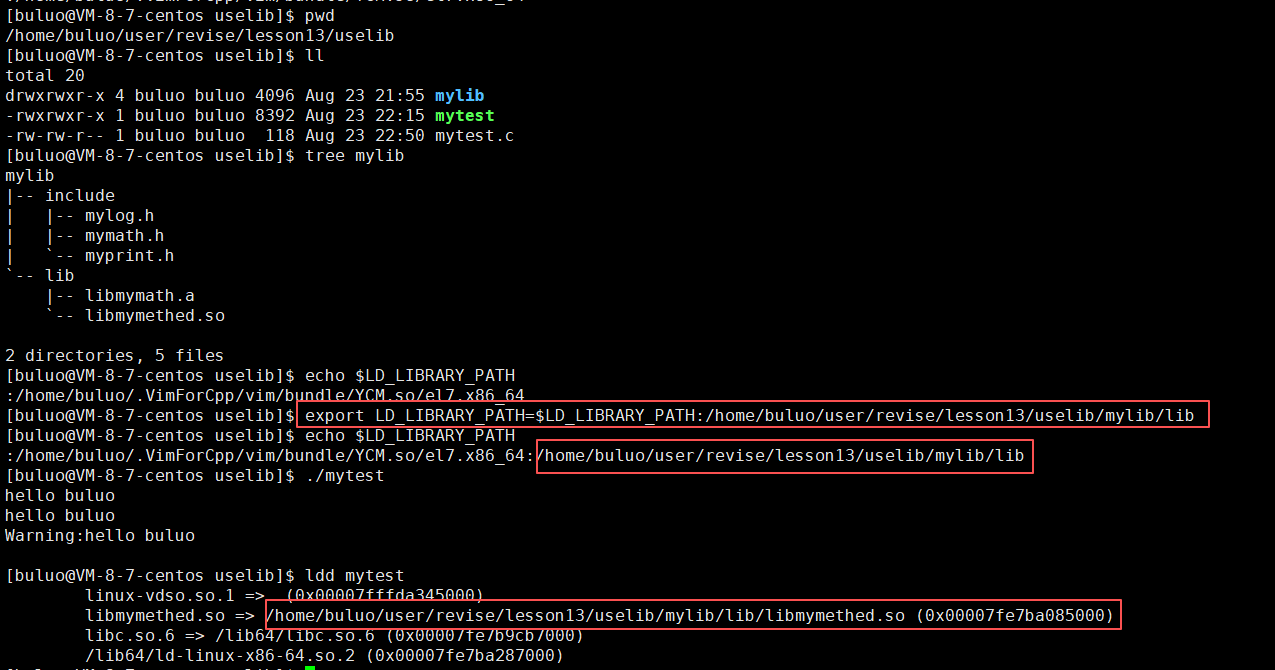
将我们库的路径加载到这个环境变量之后(LD_LIBRARY_PATH),我们的操作系统也就可以找到了,我们的程序也就又可以运行了。
- 最后一种方法就是系统给我们提供的一种方法就是,在/etc/ld.so.conf.d这个目录下建立一个自己的动态库路径的配置文件,然后重新ldconfig即可
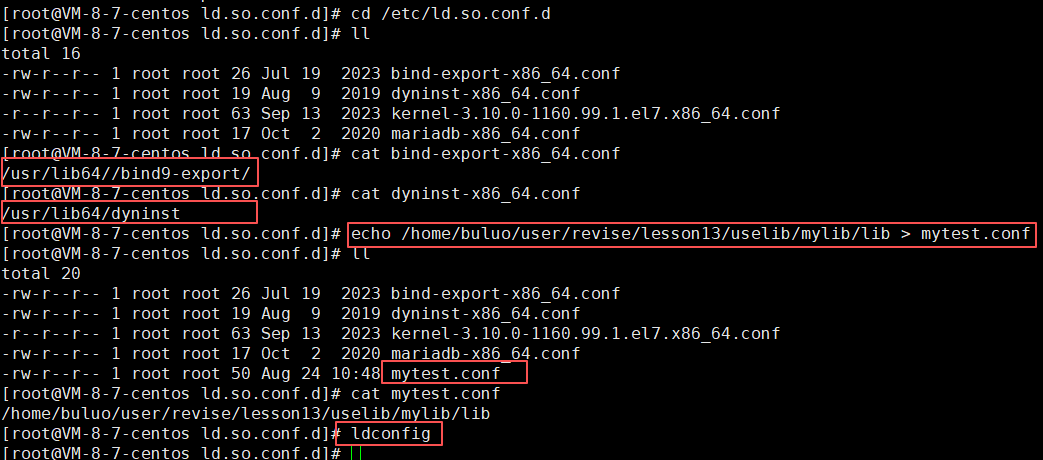
可以看到在这个路径下的文件内容都是一串路径,所以我们只需要在这个目录下建立一个自己的动态库路径的配置文件,并将我们写的库的路径写进去,这样我们的写的动态库就可以被我们的操作系统找到,我们的程序也就可以正确运行了。
这就是我们动态库制作和使用的整个流程,其实对于这四种方法,在实际使用中,都是使用的是第一种,因为能发布出来且能被广泛使用的都是成熟的库,所以这些库就直接放到我们的默认系统搜索路径中了,之后我们也只需要指明它的库名即可(其实不知道大家有没有使用过python语言,在python中我们使用库的时候都是(export 库名),原理就是这样,我们在下载对应库的时候他就已经将它的路径给我们干到系统默认搜索路径中了,这个时候我们只需要指明库名,就可以使用了)
总而言之,其实我们现在肯定明白一点就是我们的动态库是需要加载的,我们在编译的时候可以生成可执行程序,就好比我们之前例子中我们提前找我们的学长了解学校周围的网吧在哪里一样,你知道了哪里有网吧,你就可以去网吧都游戏了,这样也就是编译可以通过,因为编译器知道,当程序运行到这里的时候,会有具体的实现方法给他提供。但是当正儿八经我们的可执行文件开始上CPU运行的时候,当执行的具体的语句,我们需要跳转,这个时候就需要让我们的操作系统也知道我们对应的静态库到底在哪里,所以这就是我们目前掌握动态库的内容,明白动态库需要加载。
深刻理解动静态链接的特性
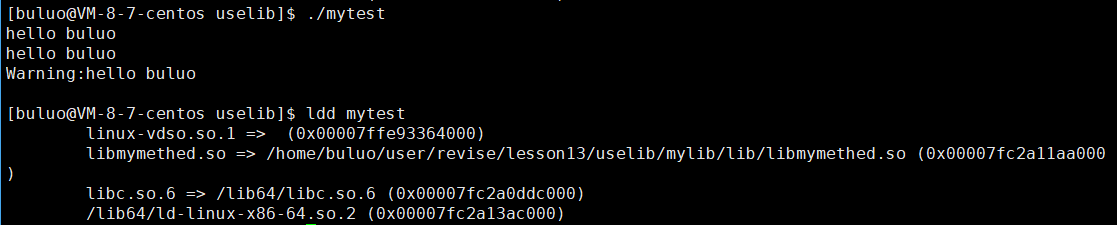
现在我们已经成功建立动态库和静态库,那么现在我们根据我们写的动静态库来验证以下之前动态链接和静态链接的特性。
- 静态链接的特性
#include "mymath.h"
#include "myprint.h"
#include "mylog.h"int main()
{int n = add(10, 10);printf("10 + 10 = %d\n", n);my_print();my_log("hello buluo\n");return 0;
}
可以看到我们的程序也是成功运行了,现在假如我们干掉我们写的静态库之后,看看还可不可以运行。
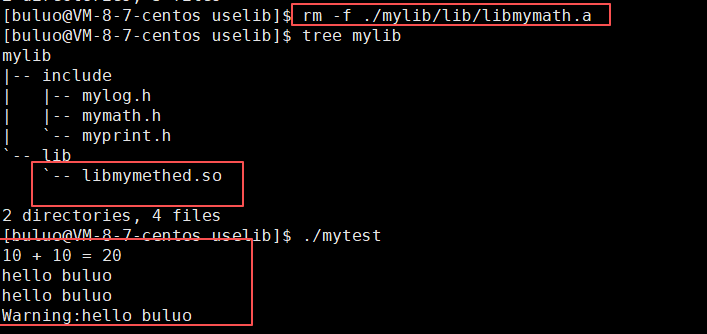
可以明显看到即使我们删除了静态库,我们的程序一就可以运行,这就是因为,静态库的内容在链接的时候就已经干到我们的程序中了,所以我们删掉了静态库,对我们的程序时没有任何影响的,这就是之前网吧老板被查封后,以二手电脑的价格卖给你后,你就有了一台属于自己的电脑,所以即使那个老板把电脑都卖完走掉了,你也不关心,因为你已经有了一台独属于你的电脑,根本不关心他。这就是静态链接的特点。
- 动态链接
#include "myprint.h"
#include "mylog.h"int main()
{my_print();my_log("hello buluo\n");return 0;
}还是之前的那份动态代码,现在我们再将其拷贝一份,这次形成两个可执行程序(mytest1和mytest2)。
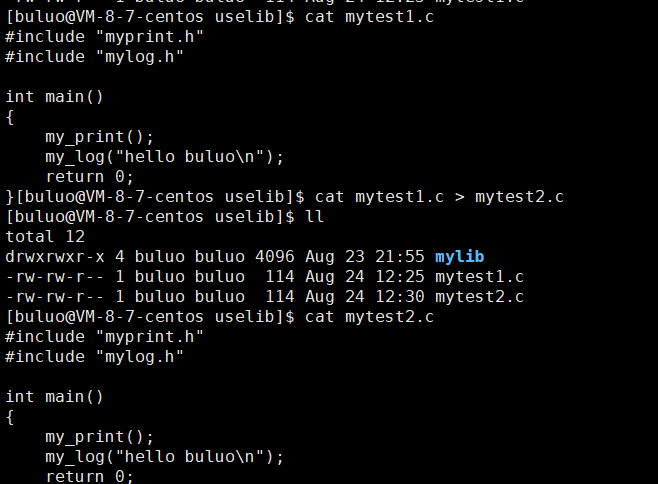
接下来编译运行这两个源文件。
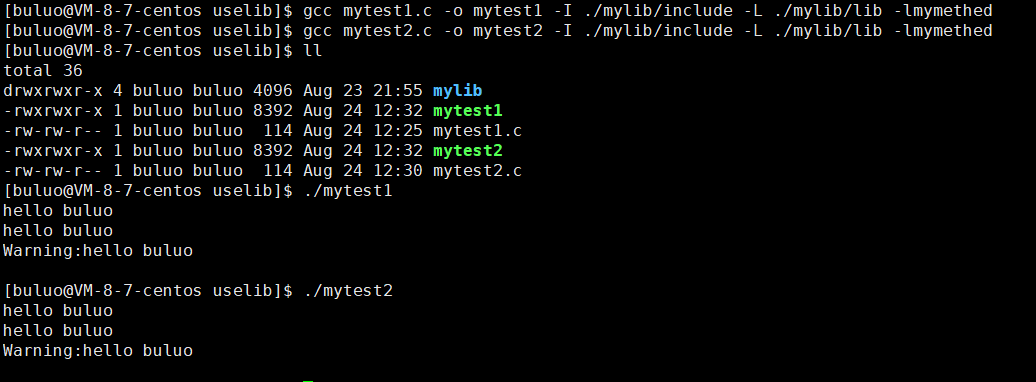
可以看到成功编译并运行,现在我们将动态库也干掉,看看还能不能执行。
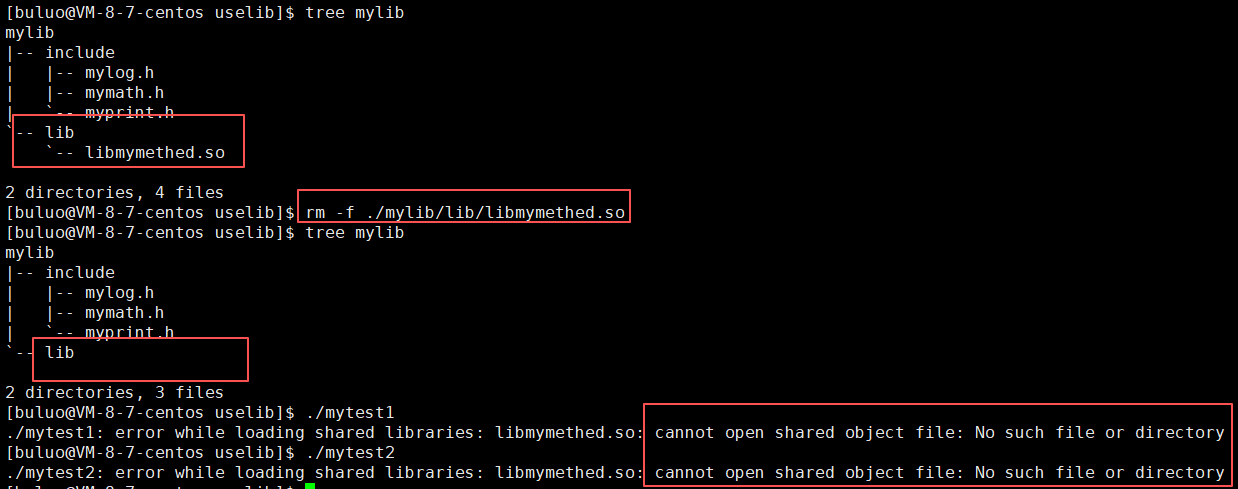
从结果来看,我们清楚的看到当我们的动态库被我们干掉之后,我们的程序也就不能运行了,因为我们的在加载的时候已经找不到我们的库在何处了。这是之前例子中刚上高中你们每次周末开开心心去上网吧,但是一天网吧老板被查封之后,你们就再也去不了网吧上网了。
现在我们就明白了,我们常见的动态库被所有的可执行程序动态链接的,都会使用这个动态库,所以这个动态库一般也会被称为共享库,所以这个共享库被加载到内存之后,会被所有的进程共享,那么这是如何做到的呢?
动态库是如何被加载的

现在,假设有两个程序都需要使用一个动态库,这个时候我们就需要将这个动态库先加载到内存,然后我们两个进程的共享区就可以通过页表都映射到这个动态库,这样我们的两个进程就都可以使用这个共享库的内容,当我们的程序运行到与共享库相关的代码时,这个时候只需要我们跳转到进程地址空间的共享区中,当执行完毕之后,再返回之前运行的位置即可,这样就可以实现我们的进程对库的使用了。所以我们可以得出一个结论就是:当我们的进程地址空间的共享区通过页表与动态库形成映射之后,我们再执行任何代码,都只需要在我们的进程地址空间中进行就可以了。
并且我们的动态库只需要再物理内存中保持一份即可,哪个进程需要使用时,只需要将其进程地址空间的共享区与动态库通过页表进行连接就可以了。
了解了以上的内容,我现在提出以下问题供大家思考一下:
- 万一我们的共享库中定义了一些全局变量,而我们每个进程都是使用的这一个库,会不会造成干扰呢?
- 我们的进程被CPU调度之后,CPU读到的指令到底是什么地址?到底是进程地址空间的地址(虚拟地址)?还是物理地址?
- 到底什么是虚拟地址,并且在我们的可执行程序调入内存的时候操作系统给其分配内存,并将可执行程序的内容映射到进程的地址空间中去,那么你将可执行程序的内容映射到代码段的时候,我怎么知道刚开始的地址是多少?
- 并且我这个共享区要是不仅仅只是映射了一个库呢?我要是映射了好几十个库,那么我们将这么多的共享库映射到进程的共享区时,我们的进程怎么知道我们要使用的函数所在共享区的位置呢?
- 还有一个问题至今没有解决的就是,之前我们在创建可执行文件的时候,你告诉我在生成可重定向二进制文件的时候,需要增加一个选项为-fPIC(产生位置无关码)这又是什么东西?
针对第一个问题,我们结合之前的知识,我们可以很快找到答案,共享库映射进各自的进程地址空间,多进程共享同一份物理内存,所以这个时候一旦其中一个进程开始对这个全局变量进行写操作,我们的操作系统就会发生写时拷贝,就这个数据给这个进程创建一个副本给他,这样,我们的多进程对于这些全局变量彼此之间是不会有干扰的。回答完这个简单问题之后,为了更好的回答下面几个问题,我们先来了解几个关于地址的概念。
地址的概念
程序没有加载前的地址(程序)
大家先来想一个问题就是我们的程序在编译好之后,它的内部有地址这个概念吗?答案是有的,我相信大家应该都使用过VS2022这种编译器,在我们将我们的代码写好之后进行调试的时候,我们其实可以看到我们写的一些函数,在main函数中进行调用的时候都是call命令后面跟着地址,这个地址就是这个函数的地址。所以我们可以明白,我们程序在编译好之后就有了地址。
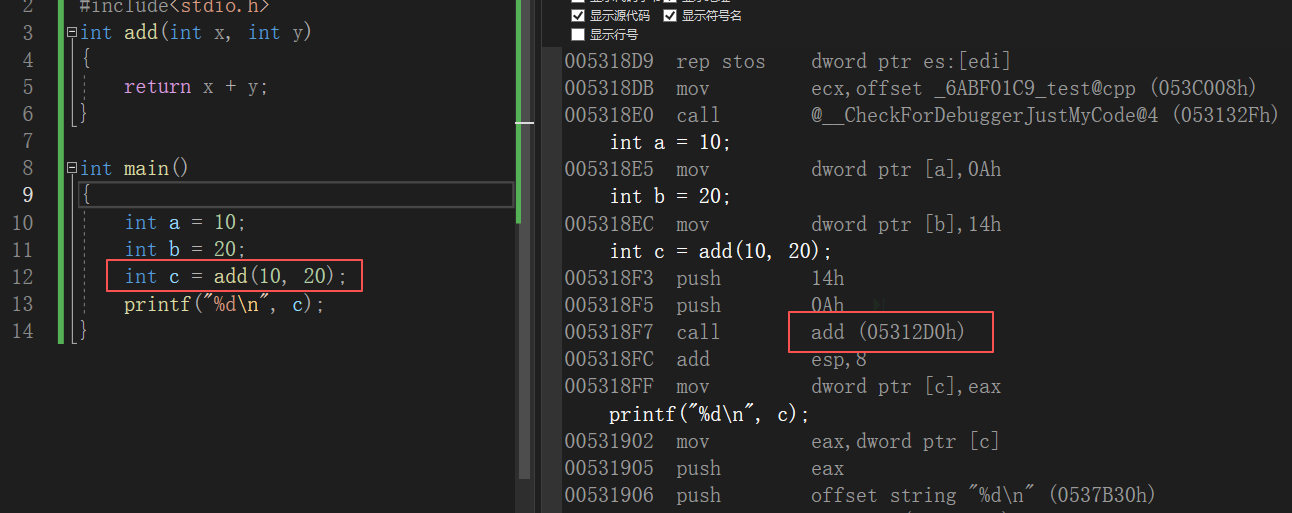
现在我们的编译器它形成的地址会同时考虑操作系统,所以编译器会对整个程序按照像进程地址空间那样,按照不同的区域进行编址,兼顾加载的问题,所以按照不用区域划分好之后,在它上面相关的字段都会有它对应的地址,这个地址就相当于每个函数相对于0号地址的偏移量,所以这个地址也就是所谓的逻辑地址。接下来我们通过在Linux中证明。
#include <stdio.h>int a = 10;
int b = 20;int main()
{printf("hello buluo\n");int x = 30;int y = 40;int z = x + y;printf("ret:%d\n", x + y);return 0;
}在Linux,可执行文件都是ELF格式。

我们可以通过反汇编ELF,让大家看到可执行程序被明确分为了各个段。指令(objdump -x a.out)
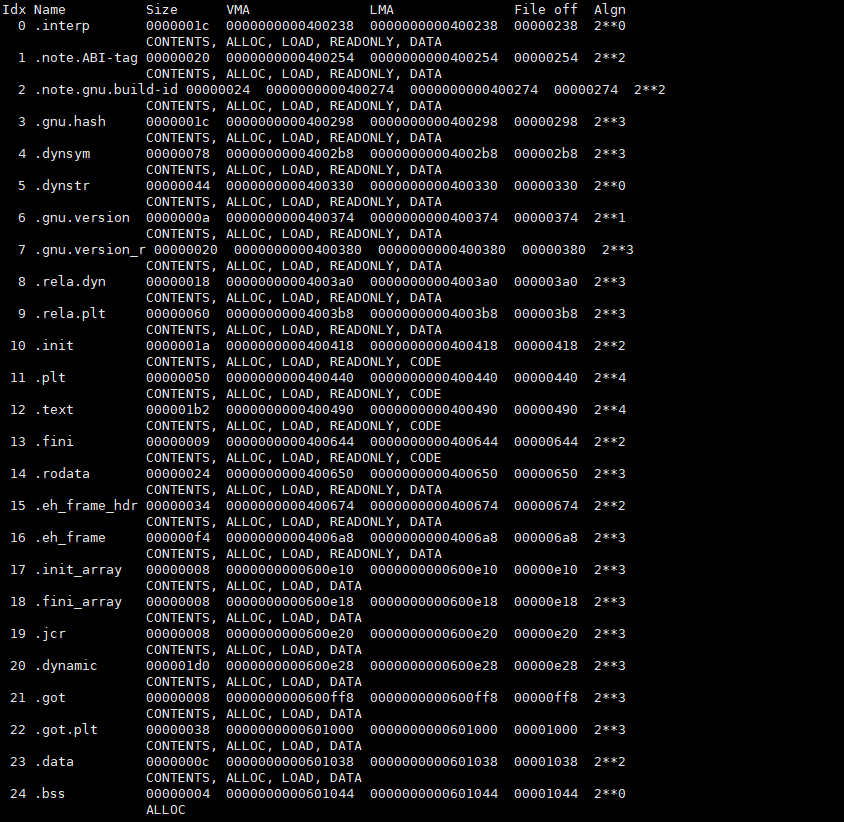
.text(主要的代码区,程序指令就在这里).rodata(Read-Only Data,字符常量和其他只读常量).data(已初始化的全局/静态变量)- .bss(未初始化数据区)
- 共享区
.interp(告诉程序加载器要使用哪个动态链接器).dynamic(动态链接所需信息).plt+.got(运行时函数调用跳转表,支持共享库调用)
至于堆区和静态区是不会出现在ELF的表中,因为栈是运行时由内核为进程分配的内存空间,而堆则是在程序运行时由操作系统和 malloc/brk/mmap 等调用动态分配的。
总而言之就是编译器已经将我们的程序划分为了各个分区。
程序加载后的地址(进程)
当我们将可执行程序加载到内存后,至于加载到哪里,这个得根据操作系统给我们分配了哪些个页框,同时结合页面替换算法决定的,这些都不重要,现在我们关心的是原本那些编译器编译好的指令占不占用物理地址呢?
答案显然易见,肯定需要占据空间,那么我们加载到内存之后,是不是这些编译器形成的指令默认就有了一个唯一的物理地址了。这样既有了逻辑地址又有了物理地址。这样就可以填充我们进程的页表,同时内核的加载器会根据 ELF的头文件将我们程序中的各个段映射到进程的虚拟地址空间,这样我们这个可执行文件的PCB就建立好了。
那么我们的CPU是如何执行第一条指令呢?
在我们还未加载到内存的时候,我们的可执行文件中有一个程序头表,里面记录了一个特别重要的字段:入口地址(Entry Point Address)。入口地址就是就是编译器/链接器写入 ELF 文件头的 程序执行起始虚拟地址。
接下来我们查看 ELF 文件头(指令:readelf -h a.out)
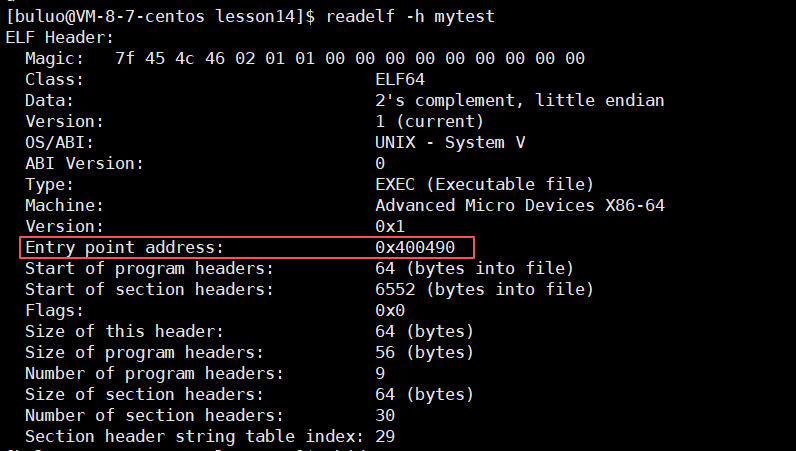
可以明确看到确实有一个程序执行起始虚拟地址。
这样Linux内核的加载器会找到这个ELF文件头里的入口点地址,当我们的进程被调度到CPU运行的时候,内核最后会把 CPU 的程序计数器(PC)设置为入口点的虚拟地址,这样,CPU就开始从这个地址中取指令执行了。
所以根据这个描述,我们现在也应该知道了一点就是,我们的CPU所读取的指令,就是逻辑地址,也就是我们的虚拟地址。
动态库的地址
在我们了解动态库的地址之前,我们先来了解一下绝对地址和相对地址的概念。
绝对地址其实就是我们进程虚拟内存空间的固定地址,是一个确定的数值,不依赖于当前的位置。
而相对地址则是相对于某一个基准的偏移量。
简单举一个生活中的例子就是绝对地址就是我家是XX市XX区XX小区XX单元XXX室;而相对地址就是你现在往你家大门口走,往前走50米,左转,然后看到第一个红路灯右转就可以看到我了。
这就是绝对地址和相对地址的概念。
现在开始库的讲解,假如我们的可执行程序的进程被调入了CPU运行,于是我们的CPU开始运行你的可执行程序,运行到你使用库中的一个函数(例如my_printf函数)时,并且我们的可执行程序在编译后这个函数已经成为了一个可以跳转的位置了(比如0X11223344),这个时候我们就需要将我们的库加载到内存,然后将库与我们进程的共享区通过页表完成映射,那么现在又有一个问题了:共享区那么大,我们的库具体应该映射到哪里?
这个时候假如我们使用绝对地址,由于我们的CPU要访问的就是上面(0X11223344),所以我们必须将我们库中的相关函数的代码映射到这个地址(0X11223344),这样可以吗?如果我们只使用一个库的情况下是可以的,但是现在我们很有可能使用好几个库,如果采用这种绝对地址的方式,那么下一个库中的同样的位置有数据这不就尴尬了么,到底这个位置应该使用哪个库的,这不就又成一个问题了么,所以这种方式是行不通的。
所以可以得出一个结论就是动态库被加载到固定位置是不可能的,库必须是可以在虚拟内存中的任意位置加载的。那么我们是如何让库可以在任意位置加载呢?
所以我们在做库的时候就不可以采用绝对编址,只要表明每一个函数在库中的偏移量即可,这就是为什么我们在形成库的时候需要带-fPIC(产生位置无关码)的选项,妙用就是在这,这样我们将这个库加载到内存之后,通过页表映射到进程的共享区时,位置随便放,只需要知道在你虚拟内存中的起始位置就可以了,这样我们的CPU在访问之前库中的函数(my_printf)时,只需要通过它记录我们的起始位置+我的这个偏移量,这样我们就可以锁定我的这个函数的准确位置,这样就可以成功调用了。
这就是动静态库制作的整个过程,希望对大家的学习有所帮助!!!
