使用 OpenTelemetry 从你的日志中获取更多信息
作者:来自 Elastic David Hope

学习如何通过利用 OpenTelemetry 进行摄取、结构化日志、地理信息增强和 ES|QL 分析,超越基础日志摄取。通过实际示例和主动观测策略,将原始日志数据转化为可操作的情报。
如今大多数人使用日志工具的方式仍然和几十年来一样,作为一个简单的搜索湖,本质上仍是在一个集中平台上 grep 日志。这样做没有问题,通过集中式日志平台你仍然可以获得很多价值,但问题是我如何开始超越这种基础的日志和搜索用例?我从哪里开始才能在事件调查中更高效?在这篇博客中,我们从大多数客户当前的使用情况出发,给你一些实用建议,帮助你稍微超越这种简单的日志使用场景。
摄取
让我们从头开始,摄取。通常你们很多人今天使用的是较老的摄取工具。如果你想更有前瞻性,是时候向你介绍 OpenTelemetry 了。OpenTelemetry 曾经在日志方面不够成熟或功能有限,但情况已经发生了显著变化。Elastic 一直在特别努力地提升 OpenTelemetry 中的日志能力。所以让我们先探讨如何通过 OpenTelemetry collector 将日志引入 Elastic。
首先,如果你想跟着操作,只需创建一台主机来运行日志生成器和 OpenTelemetry collector。
按照这里的说明启动日志生成器:
https://github.com/davidgeorgehope/log-generator-bin/
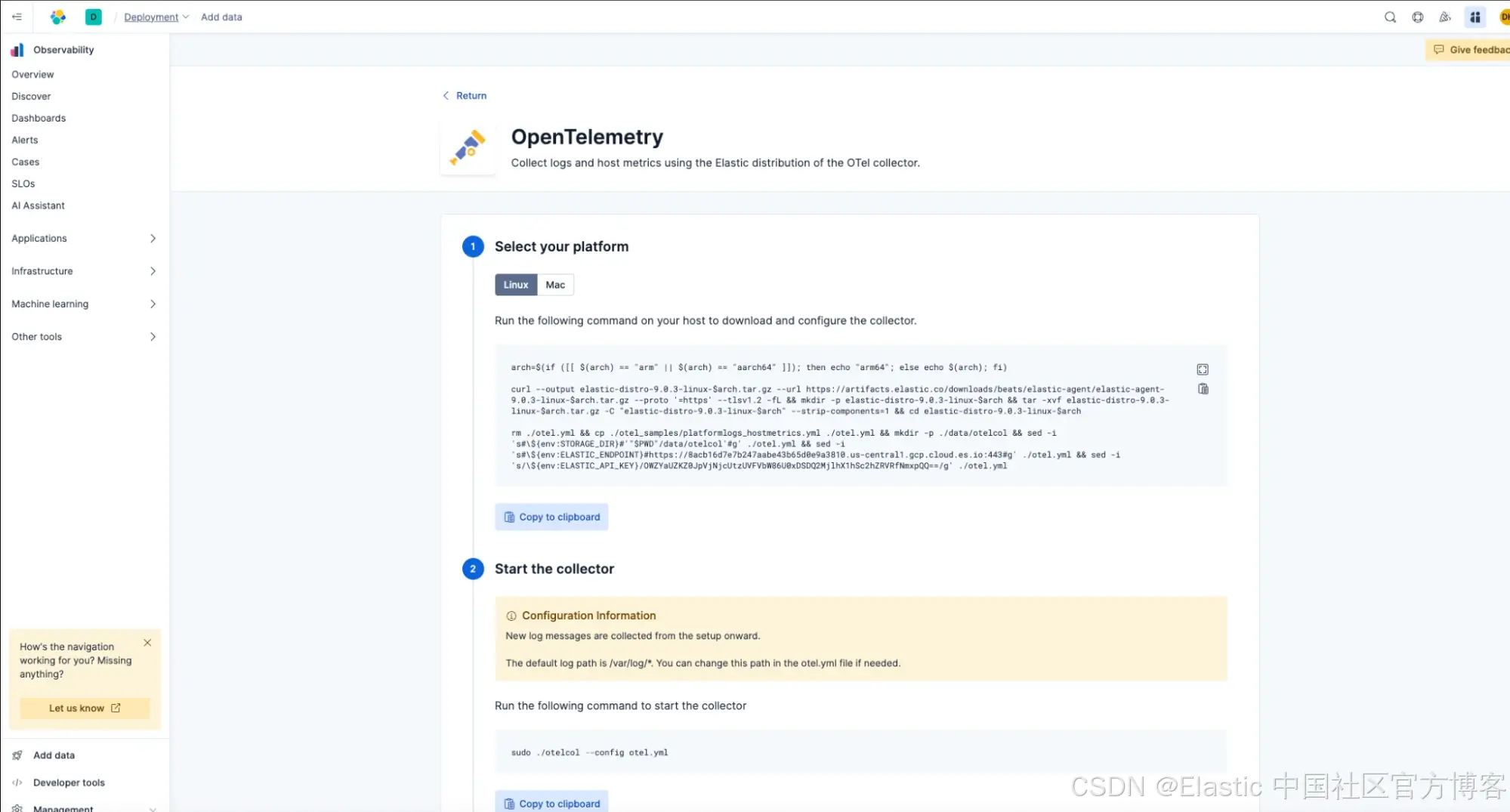
要在 Elastic Serverless 中启动 OpenTelemetry collector,可以点击左下角的 Add Data,然后选择 'host',最后选择 'opentelemetry'。

按照说明操作,但暂时不要启动 collector。
我们的主机运行的是一个三层应用,有 Nginx 前端、后端,并连接到 MySQL 数据库。所以让我们开始将日志引入 Elastic。
首先我们将安装 OpenTelemetry 的 Elastic 版本,但在启动之前,我们会对 OpenTelemetry 配置文件做一个小修改,扩展它搜索日志的目录。使用 vi 或你喜欢的编辑器编辑 otel.yml:
vi otel.yml
我们不只是使用 /var/log/.log,而是添加 /var/log/**/.log 来引入所有日志文件。
receivers:# Receiver for platform specific log filesfilelog/platformlogs:include: [ /var/log/**/*.log ]retry_on_failure:enabled: truestart_at: endstorage: file_storage
启动 otel collector
sudo ./otelcol --config otel.yml
我们可以在 Discover 中看到这些日志正在被引入。
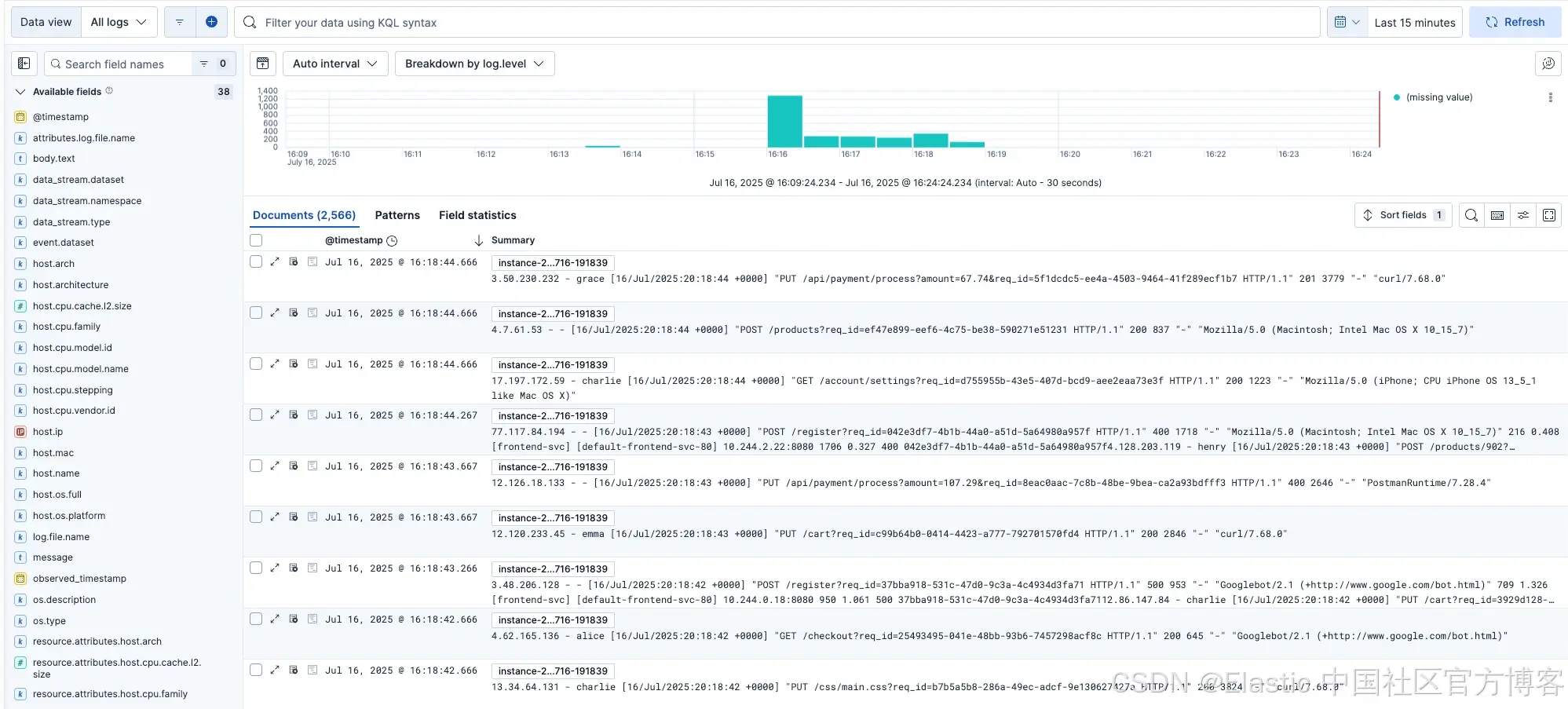
现在一个立即注意到的点是,我们无需做任何修改就自动获得了很多有用的额外信息,比如操作系统名称和 CPU 信息。
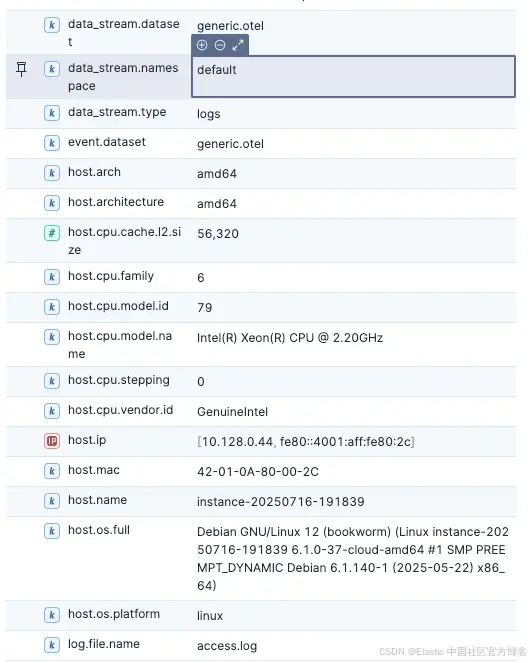
OpenTelemetry collector 已经自动、无需任何修改地开始丰富我们的日志,使其对额外处理有用,尽管我们还能做得更好!
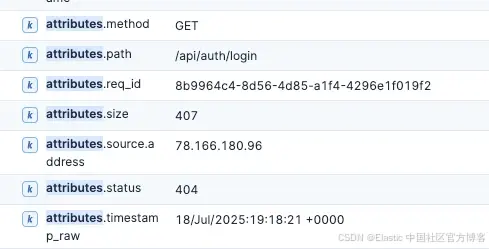
首先,我们希望给日志增加一些结构。让我们编辑 otel.yml 文件,添加一些 OTTL,从我们的 NGINX 日志中提取一些关键数据。
transform/parse_nginx:trace_statements: []metric_statements: []log_statements:- context: logconditions:- 'attributes["log.file.name"] != nil and IsMatch(attributes["log.file.name"], "access.log")'statements:- merge_maps(attributes, ExtractPatterns(body, "^(?P<client_ip>\\S+)"), "upsert")- merge_maps(attributes, ExtractPatterns(body, "^\\S+ - (?P<user>\\S+)"), "upsert")- merge_maps(attributes, ExtractPatterns(body, "\\[(?P<timestamp_raw>[^\\]]+)\\]"), "upsert")- merge_maps(attributes, ExtractPatterns(body, "\"(?P<method>\\S+) "), "upsert")- merge_maps(attributes, ExtractPatterns(body, "\"\\S+ (?P<path>\\S+)\\?"), "upsert")- merge_maps(attributes, ExtractPatterns(body, "req_id=(?P<req_id>[^ ]+)"), "upsert")- merge_maps(attributes, ExtractPatterns(body, "\" (?P<status>\\d+) "), "upsert")- merge_maps(attributes, ExtractPatterns(body, "\" \\d+ (?P<size>\\d+)"), "upsert")
.....logs/platformlogs:receivers: [filelog/platformlogs]processors: [transform/parse_nginx,resourcedetection]exporters: [elasticsearch/otel]
现在,当我们使用这个新配置启动 Otel collector 时
sudo ./otelcol --config otel.yml
我们会看到现在我们的日志已经是结构化的了!!
存储与优化
为了确保这些额外的结构化数据不会让你的预算超支,你可以做一些事情来最大化存储效率。
例如,你可以在 Otel collector 中使用 filter processors,对无关属性进行精细过滤/丢弃,从而控制从 collector 输出的数据量。
processors:filter/drop_logs_without_user_attributes:logs:log_record:- 'attributes["user"] == nil'filter/drop_200_logs:logs:log_record:- 'attributes["status"] == "200"'service:pipelines:logs/platformlogs:receivers: [filelog/platformlogs]processors: [transform/parse_nginx, filter/drop_logs_without_user_attributes, filter/drop_200_logs, resourcedetection]exporters: [elasticsearch/otel]
filter processor 可以帮助减少噪声,例如如果你想丢弃调试日志或来自噪声服务的日志。这是控制观测成本的好方法。
此外,对于你最关键的流程和日志,你不想丢弃任何数据,Elastic 已经提供支持。在 Elastic 9.x 版本中,LogsDB 默认已开启。
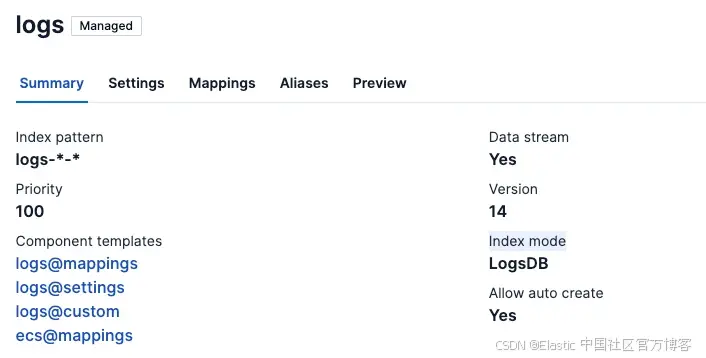
使用 LogsDB,Elastic 将 Elasticsearch 中日志数据的存储占用减少了最多 65%,允许你在不超出预算的情况下存储更多的观测和安全数据,同时保持所有数据可访问和可搜索。
LogsDB 将日志存储减少最多 65%。它通过利用 ZSTD、增量编码(delta encoding)和游程编码(run-length encoding)等高级压缩技术,大幅减少存储占用,同时按需重建 _source 字段,通过不保留原始 JSON 文档额外节省约 40% 的存储空间。Synthetic _source 代表了 Elasticsearch 中列式存储的引入。
分析
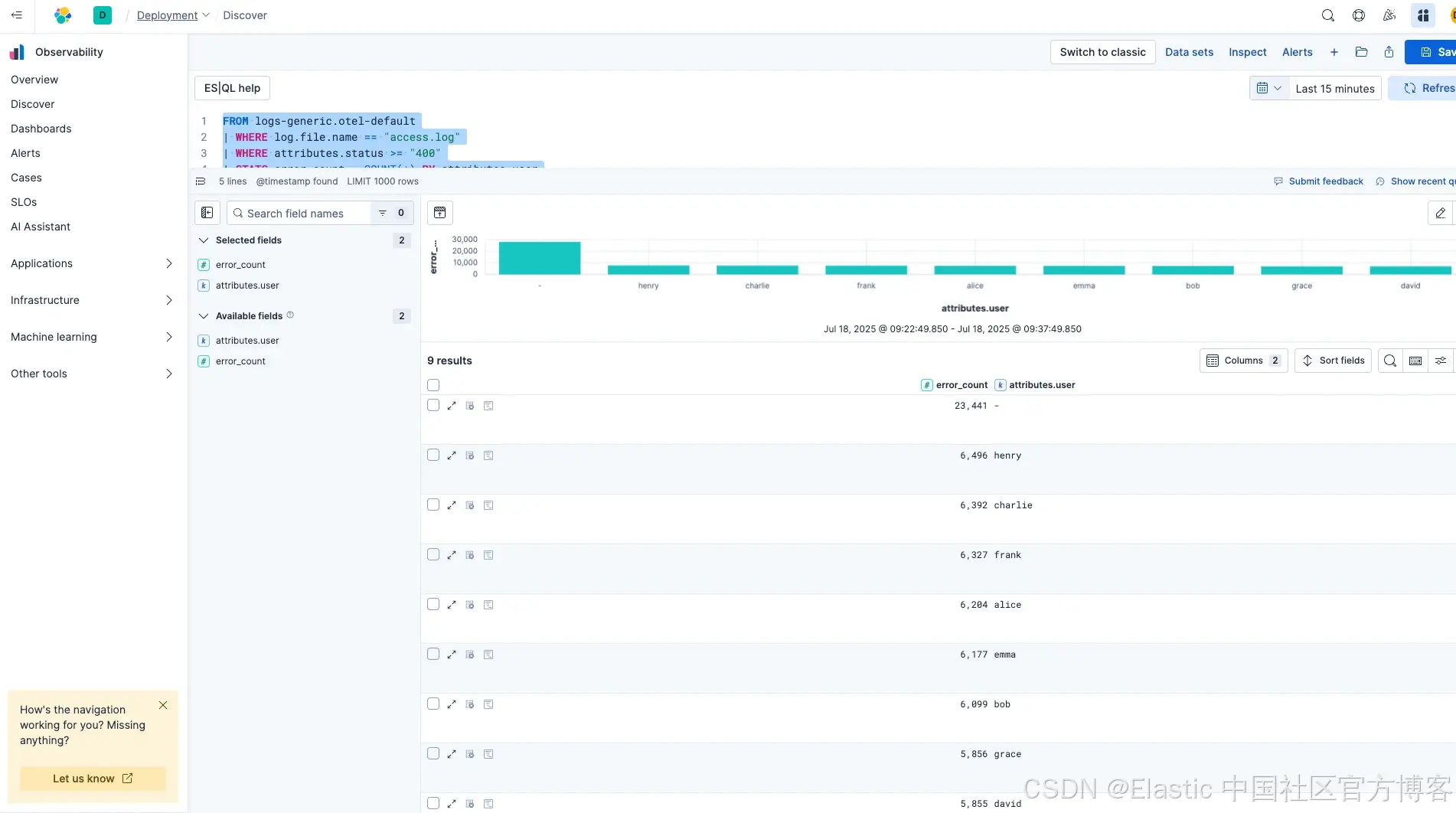
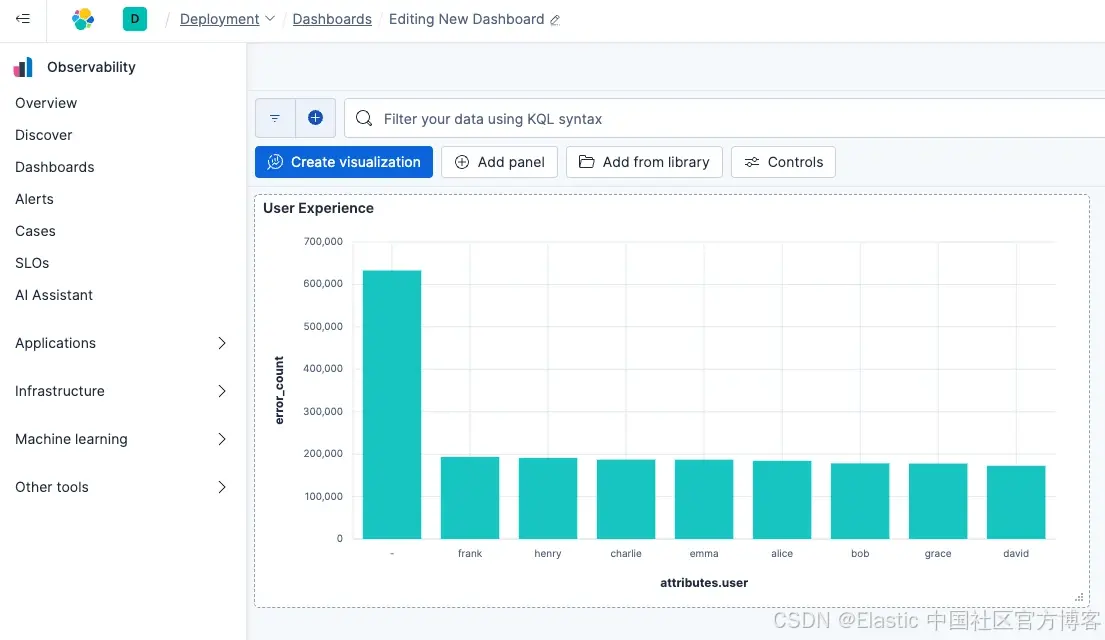
现在我们的数据在 Elastic 中,它是结构化的,符合宽事件日志的概念,因为它包含了丰富的上下文、用户 ID、请求 ID,并且数据是在请求开始时捕获的。接下来我们来看分析部分。首先,让我们尝试查看应用中每个用户事务的错误数量。
FROM logs-generic.otel-default
| WHERE log.file.name == "access.log"
| WHERE attributes.status >= "400"
| STATS error_count = COUNT(*) BY attributes.user
| SORT error_count DESC
现在将其保存并放到仪表板上非常简单,我们只需点击保存按钮:
接下来让我们看看如何组合数据以展示全球影响,首先我们将更新 collector 配置,用地理位置信息丰富我们的日志数据。
在 OTTL 配置中添加这一新行:
log_statements:- context: logconditions:- 'attributes["log.file.name"] != nil and IsMatch(attributes["log.file.name"], "access.log")'statements:- merge_maps(attributes, ExtractPatterns(body, "^(?P<client_ip>\\S+)"), "upsert")- merge_maps(attributes, ExtractPatterns(body, "^\\S+ - (?P<user>\\S+)"), "upsert")- merge_maps(attributes, ExtractPatterns(body, "\\[(?P<timestamp_raw>[^\\]]+)\\]"), "upsert")- merge_maps(attributes, ExtractPatterns(body, "\"(?P<method>\\S+) "), "upsert")- merge_maps(attributes, ExtractPatterns(body, "\"\\S+ (?P<path>\\S+)\\?"), "upsert")- merge_maps(attributes, ExtractPatterns(body, "req_id=(?P<req_id>[^ ]+)"), "upsert")- merge_maps(attributes, ExtractPatterns(body, "\" (?P<status>\\d+) "), "upsert")- merge_maps(attributes, ExtractPatterns(body, "\" \\d+ (?P<size>\\d+)"), "upsert")- set(attributes["source.address"], attributes["client_ip"]) where attributes["client_ip"] != nil
接下来添加一个新的 processor(你需要从 MaxMind 下载 GeoIP 数据库)。
geoip:context: recordsource:from: attributesproviders:maxmind:database_path: /opt/geoip/GeoLite2-City.mmdb
并将其添加到 parse_nginx 之后的日志管道中。
service:pipelines:logs/platformlogs:receivers: [filelog/platformlogs]processors: [transform/parse_nginx, geoip, resourcedetection]exporters: [elasticsearch/otel]
启动 otel collector
sudo ./otelcol --config otel.yml
一旦数据开始流入,我们就可以添加地图可视化:
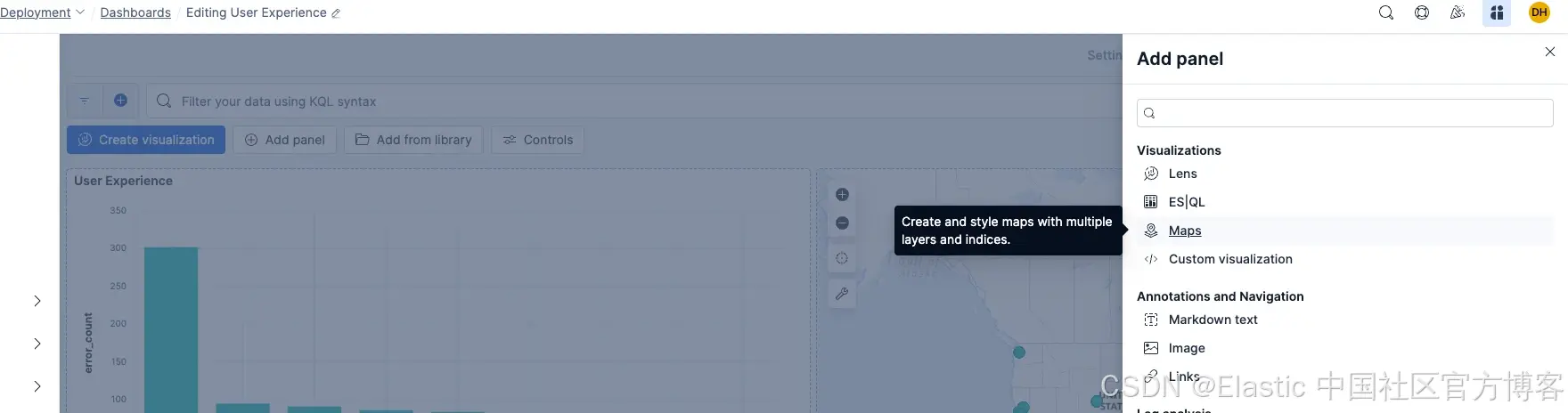
添加一个图层:
使用 ES|QL

使用以下 ES|QL
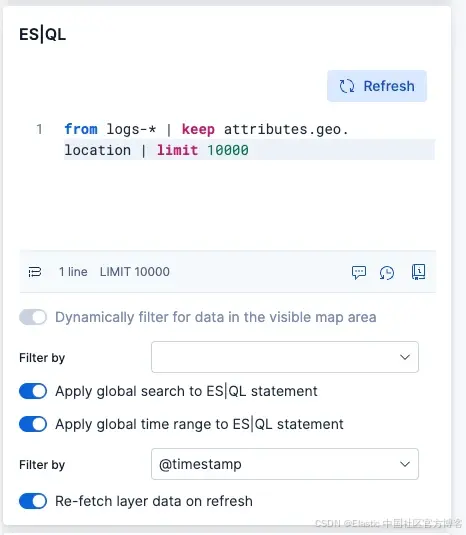
这应该会给你一个地图,显示所有 NGINX 服务器请求的位置!
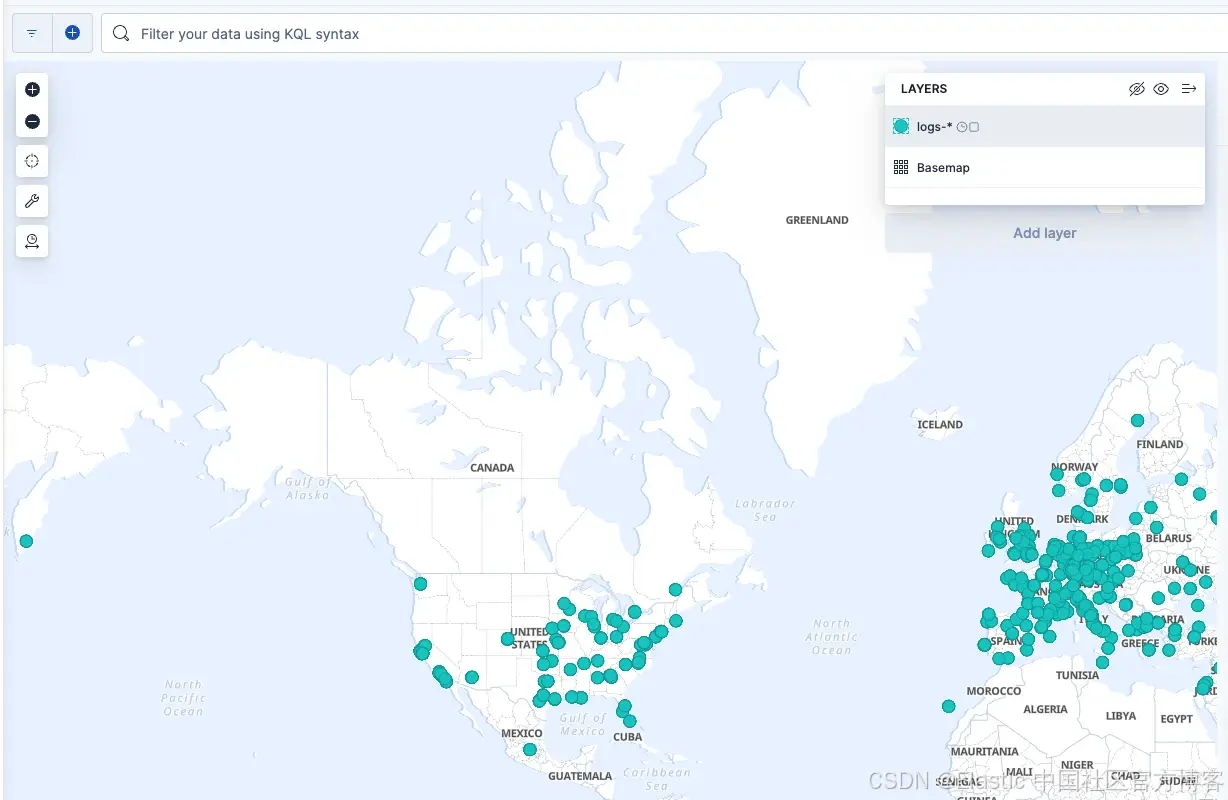
如你所见,使用新的 Otel 数据收集管道,分析变得轻而易举。
结论:从日志聚合到运维智能
从基础日志聚合到结构化、丰富的观测,这不仅仅是技术升级,更是组织理解系统和响应事件方式的转变。通过采用 OpenTelemetry 进行摄取、实施智能过滤以控制成本,并利用 LogsDB 的存储优化,你不仅在现代化你的 ELK 堆栈,还在为主动系统管理打下基础。
这里展示的结构化日志、地理信息增强和分析能力,将原始日志数据通过 ES|QL 转化为可操作的情报。不再是在事件中被动地 grep 日志,你现在有基础设施来识别模式、跟踪用户旅程,并在问题成为严重故障之前关联整个堆栈中的问题。
但关键问题是:你准备好根据这些洞察采取行动了吗?拥有丰富、结构化的数据只有在组织能够从被动的“发现并修复”思维转向主动的“预测并防范”方式时才有价值。真正的演进不在于日志堆栈,而在于运维文化。
今天就在 Elastic Serverless中开始吧。
原文:https://www.elastic.co/observability-labs/blog/getting-more-from-your-logs-with-opentelemetry