深度学习(六):代价函数的意义
在深度学习的浩瀚世界中,代价函数(Cost Function),又称损失函数(Loss Function)或目标函数(Objective Function),扮演着至关重要的角色,它就像一个导航员,为神经网络的训练指引方向。简单来说,代价函数就是用来衡量模型预测结果与真实值之间差异的度量标准。这个差异越小,说明模型的性能越好。
核心作用:衡量与优化
代价函数的核心意义在于将模型的性能量化为一个单一的数值。这个数值就是我们进行优化的目标。在训练过程中,我们不断调整模型的参数(如权重和偏置),目的就是为了最小化这个代价函数的值。这个过程就像登山者朝着山谷最低点前进,每走一步都选择能让海拔降低的方向。
通过最小化代价函数,我们能有效地:
- 量化误差:将复杂的预测结果与真实标签之间的差距,简化为一个易于计算和比较的数值。
- 指导优化:这个数值成为了梯度下降等优化算法的依据。梯度下降算法会计算代价函数对每个参数的梯度,并沿着梯度减小的方向更新参数,从而逐步减小误差。
- 评估模型性能:代价函数的值可以作为模型在训练集或验证集上性能的一个重要指标。
常见的代价函数类型
不同的任务需要不同的代价函数来衡量误差。以下是一些最常见且重要的代价函数:
a. 均方误差 (MSE)
-
全称:Mean Squared Error
-
公式:
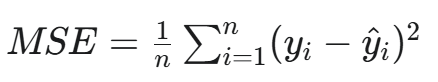
-
用途:主要用于回归任务。它计算预测值和真实值之差的平方的平均值。
-
特点:对离群点(Outliers)非常敏感。由于平方运算,大的误差会被放大,这使得模型会更努力地去纠正那些偏差较大的预测。
b. 交叉熵 (Cross-Entropy)
- 全称:Cross-Entropy
- 用途:主要用于分类任务。它衡量两个概率分布之间的差异,即模型预测的概率分布与真实标签的概率分布之间的相似性。
- 特点:
- 二元交叉熵:用于二分类任务,如逻辑回归。
- 多类别交叉熵:用于多分类任务,常与Softmax函数结合使用。
- 相比于均方误差,交叉熵在分类任务中表现更好。当预测结果与真实标签相差甚远时,交叉熵的梯度更大,能更快地进行参数更新。
c. 均方根误差 (RMSE)
-
全称:Root Mean Squared Error
-
公式:
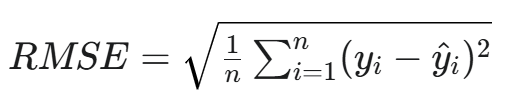
-
用途:同样用于回归任务。它是MSE的平方根。
-
特点:与原始数据的单位保持一致,更具可解释性。
d. 平均绝对误差 (MAE)
-
全称:Mean Absolute Error
-
公式:
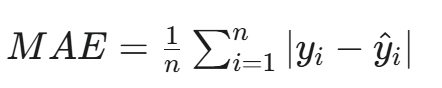
-
用途:用于回归任务。
-
特点:对离群点不那么敏感,因为它是取绝对值而不是平方。当数据中存在较多异常值时,MAE是一个更稳健的选择。
代价函数的选择与影响
选择合适的代价函数并非易事,它直接影响着模型的学习效果和最终性能。
- 任务决定选择:正如前面所提到的,回归问题通常使用MSE或MAE,而分类问题则首选交叉熵。
- 影响优化效率:一个设计良好的代价函数,其曲面(Cost Surface)应该是平滑且凸的(至少在局部),这样才能让梯度下降等优化算法更高效地找到最小值。如果代价函数存在很多局部最小值或平坦区域,优化过程可能会陷入困境。
- 模型泛化能力:有时,我们会将正则化项(如L1或L2正则化)添加到代价函数中,以惩罚复杂的模型,防止过拟合,从而提高模型的泛化能力。
总结:代价函数的重要性
总而言之,代价函数是深度学习的灵魂之一。它不仅仅是一个简单的公式,更是连接模型、数据和优化算法的核心纽带。它清晰地定义了“好”与“坏”,并为模型提供了一个明确的优化目标。没有代价函数,模型的训练将失去方向,无法从数据中学习有效的模式。理解和选择正确的代价函数,是构建高效、稳健的深度学习模型的关键第一步。