Linux 进程深度解析(6):资源隔离的底层实现 (Namespace、Cgroups 与容器化)
文章目录
- 0.简介
- 1.Namespace
- 2.CGroup
- 4.总结
0.简介
在前面文章中,我们对于进程相关的知识和实际案例进行了介绍,但在进程管理的世界中,仅仅理解进程的创建和调度还是不够的。当应用从单机走向容器化,从本地使用走向云端部署,资源隔离的失效轻则导致服务异常,重则导致宕机。本文将对内核级进程隔离和资源限制的实现和使用进行介绍,带读者一起深入理解容器技术的实现。
1.Namespace
Namespace本质上是对于进程可见全局资源的一层封装,使得每一个进程(进程组)都认为自己独占一套独立的资源,其提供了多种类型的Namespace来隔离不同的系统资源:
PID │ 进程ID隔离 → 容器内首个进程以为自己是"init"(PID=1)
NET │ 网络栈隔离 → 容器拥有独立IP、端口、路由表
IPC │ 进程通信隔离 → 禁止跨容器的共享内存通信
MNT │ 文件系统隔离 → `/` 在容器内外看到不同内容
UTS │ 主机名隔离 → 容器可自定义hostname
USER │ 用户权限隔离 → 容器内"root"≠宿主机root
NameSpace的核心数据结构是nsproxy,每个进程的task_struct中都有一个nsproxy的指针,指向其所属的命名空间:
struct nsproxy {atomic_t count;struct uts_namespace *uts; // UTS Namespace(主机名/域名)struct ipc_namespace *ipc; // IPC Namespace(进程间通信)struct mnt_namespace *mnt; // Mount Namespace(文件系统挂载)struct pid_namespace *pid; // PID Namespace(进程ID)struct net *net; // Network Namespace(网络资源)... //time相关struct cgroup_namespace *cgroup; // CGroup Namespace(cgroup视图)
};struct task_struct {// ... 其他字段 ...struct nsproxy *nsproxy; // 进程所属的namespace集合// ... 其他字段 ...
};
我们以创建一个新的PID Namespace为例,可以调用clone(CLONE_NEWPID | …)创建新 PID Namespace,然后会将创建的task指向新的nsproxy。
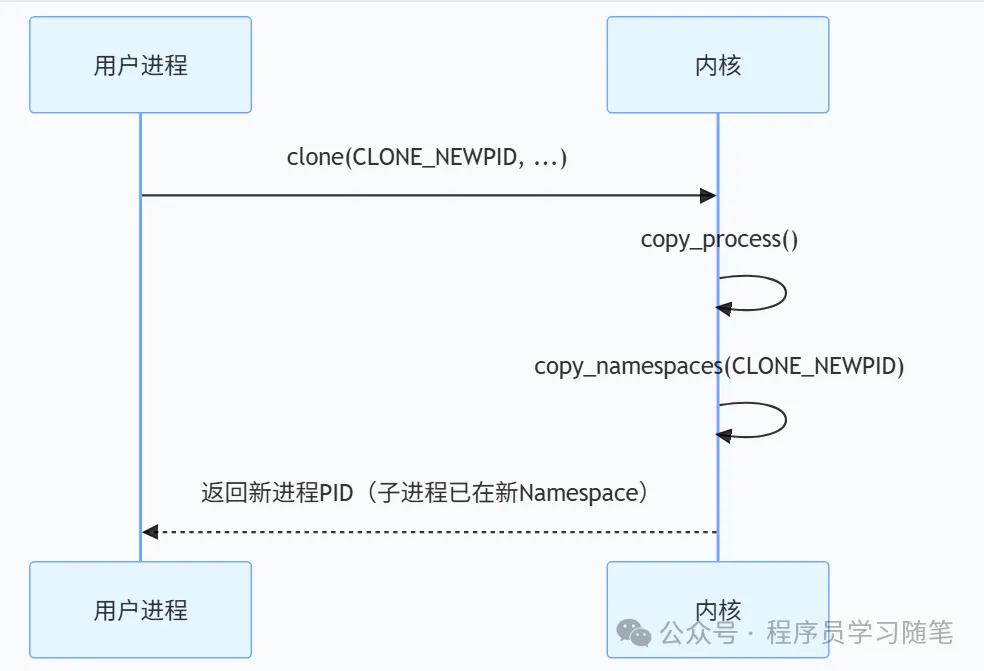
我们来实际操作一下,使用unshare(用于在新的命名空间中来运行程序)来作为例子,可以看到使用这个之后只能看到bash和ps -ef本身,看不到原本的宿主进程了。
#创建一个"看不见"宿主进程的隔离环境,--mount-proc让容器挂载独立的/proc,使ps只能看到"假"的进程树
sudo unshare --pid --fork --mount-proc /bin/bash
ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 20:10 pts/3 00:00:00 /bin/bash
root 8 1 0 20:10 pts/3 00:00:00 ps -ef
容器的各种隔离就是通过这种方式来进行实现的,我们的程序需要这个隔离时也可以自己使用这种方法或者函数去进行环境隔离。
2.CGroup
有了Namespace后,容器可以拥有自己的运行环境,但是如果一个容器无限制的去消耗系统资源(CPU,内存等),就可能将整个机器拖垮,所以就需要一种限制手段,也就是CGroup,CGroup(Control Group)是将进程分组并且对每组资源进行监控和限制的一种手段。
CGroup的核心概念有两个:
1)控制组:是一组进程的集合,可以是树状的(子进程继承父进程的限制)。
2)子系统:每个子系统对应一种资源控制,如CPU、内存、IO等。
在linux中,实现CGroup的核心结构是cgroup,其结构主要内容如下,在task_struct中有进程所属的cgroup:
struct cgroup {struct cgroup_subsys_state self;unsigned long flags; int level; // 当前cgroup在树中的深度(root=0)/* Maximum allowed descent tree depth */int max_depth; // 允许的最大子树深度...struct kernfs_node *kn; /* cgroup kernfs entry */struct cgroup_file procs_file; /* handle for "cgroup.procs" */struct cgroup_file events_file; /* handle for "cgroup.events" */...//子系统状态指针struct cgroup_subsys_state __rcu *subsys[CGROUP_SUBSYS_COUNT];struct cgroup_root *root;struct list_head cset_links;struct list_head e_csets[CGROUP_SUBSYS_COUNT];struct cgroup *dom_cgrp;struct cgroup *old_dom_cgrp; /* used while enabling threaded *///CPU统计量struct cgroup_rstat_cpu __percpu *rstat_cpu;struct list_head rstat_css_list;/* cgroup basic resource statistics */struct cgroup_base_stat last_bstat;struct cgroup_base_stat bstat;struct prev_cputime prev_cputime; /* for printing out cputime */struct list_head pidlists;struct mutex pidlist_mutex;/* used to wait for offlining of csses */wait_queue_head_t offline_waitq;/* used to schedule release agent */struct work_struct release_agent_work;/* used to track pressure stalls */struct psi_group psi;/* used to store eBPF programs */struct cgroup_bpf bpf;/* If there is block congestion on this cgroup. */atomic_t congestion_count;/* Used to store internal freezer state */struct cgroup_freezer_state freezer;// 祖先cgroup的ID数组(快速判断层级关系)u64 ancestor_ids[];
};struct task_struct {// ... 其他字段 ...struct css_set *cgroups; // 进程所属的cgroup集合// ... 其他字段 ...
};
接下来来看其资源限制的实现逻辑,以CPU限制为例(cpu 子系统通过 cpu.cfs_quota_us 和 cpu.cfs_period_us 控制 CPU 时间片(如 quota=50000、period=100000 表示 50% 使用率)。其整体设置后逻辑如下:
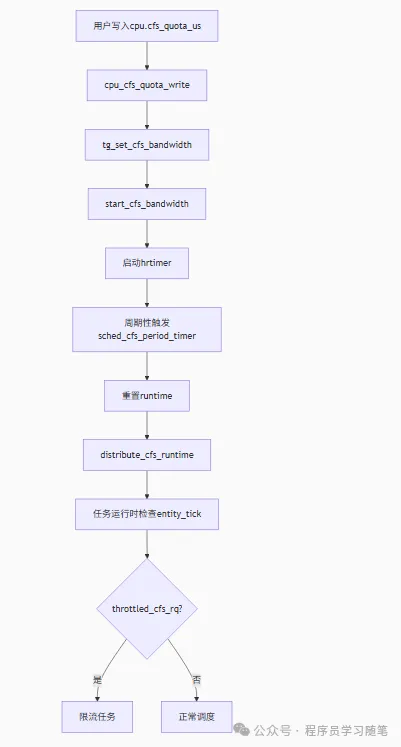
其可以通过如下方式使用限制:
# 创建内存限制组
mkdir /sys/fs/cgroup/memory/mygroup
echo 104857600 > /sys/fs/cgroup/memory/mygroup/memory.limit_in_bytes # 限制100MB
各类容器(如Docker)中的资源限制也是通过Cgroup来实现的,各类子系统都支持限制,种类较多,不在此列举。
4.总结
Namespace实现了各类,为容器创建独立的运行环境(像网络,进程,文件等),实现了逻辑隔离;CGroup实现了资源控制(CPU、IO等),实现了物理控制,保证系统的稳定和公平。从这个设计也能体会到Linux的分层抽象、按需组合的设计思想。最后用伪代码来启动一个我们自己的容器(主要步骤描述)。
unshare(CLONE_NEWPID | CLONE_NEWNS) # 创建Namespace
cgroup = Cgroup(cpu_shares=512, memory_limit="1G") # 创建Cgroup
pivot_root("./alpine-rootfs") # 切换根文件系统
execv("/bin/bash") # 启动容器进程