知识图谱RAG
先看实现效果
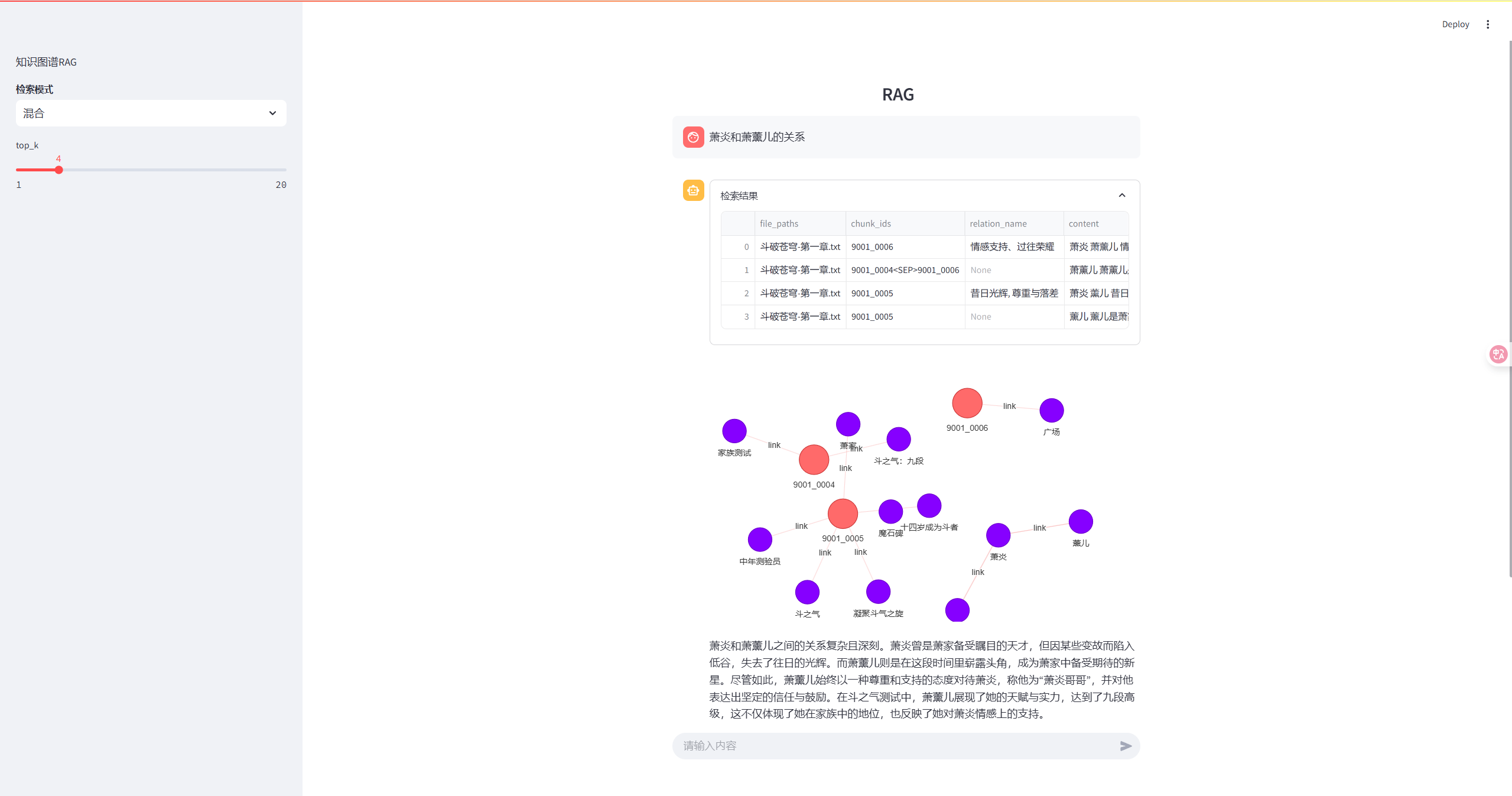
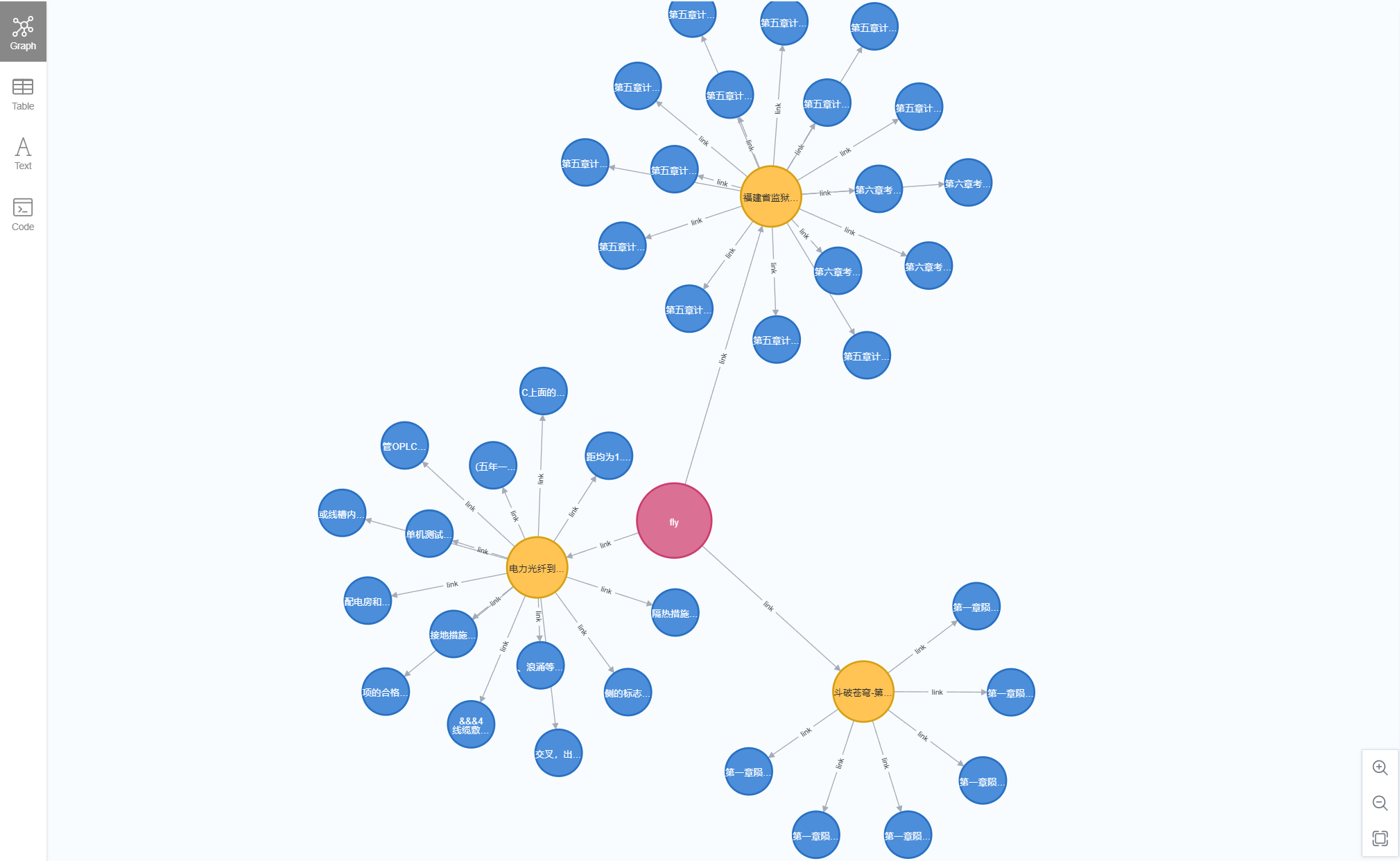
图谱使用neo4j进行数据存储
一、工具介绍
[llm]
model = "qwen-turbo"
api_key = "****"
base_url = "https://dashscope.aliyuncs.com/compatible-mode/v1"
max_tokens = 30000
temperature = 0.5
top_p = 0.5[chunking]
chunk_size = 500
overlap = 50
chunk_type = "general" # 切片方法,支持通用方式、父子分块方式、规则方式等 regulation/general/[embedding]
model = "quentinz/bge-large-zh-v1.5:latest"
api_key = "ollama"
base_url = "http://192.168.1.86:11435/v1"
max_tokens = 512[rerank]
model = "bge-reranker-v2-m3"
api_key = "xinfer"
base_url = "http://192.168.1.86:9997/v1/rerank"
max_tokens = 512[neo4j]
uri = "bolt://ip:7687"
user_name = "neo4j"
password = "***"[es]
es_url = "http://ip:9200"
es_username = "elastic"
es_password = "***"
index_name = "fly905"
1.1 图数据库选择
使用neo4j,对于开发爱好者还是挺友好的,性能什么的都够用。
1.2 向量数据库选择
使用es,支持向量检索版本,也可以直接用来进行全文检索。
1.3 大模型选择
使用通义千问官网大模型,有数据保密要求的可以更换自己本地启动的大模型,如上所示可直接在配置文件只中进行调整。
1.4 嵌入模型选择
使用本地ollama运行的bge-large-zh-v1.5:latest模型,如上所示可直接在配置文件中进行调整。
1.5 重排序模型选择
使用本地xinfer运行的bge-reranker-v2-m3模型,如上所示可直接在配置文件中进行调整。
二、流程介绍
流程和lightRAG类似,范围入库流程和检索流程,如下。
2.1 入库流程
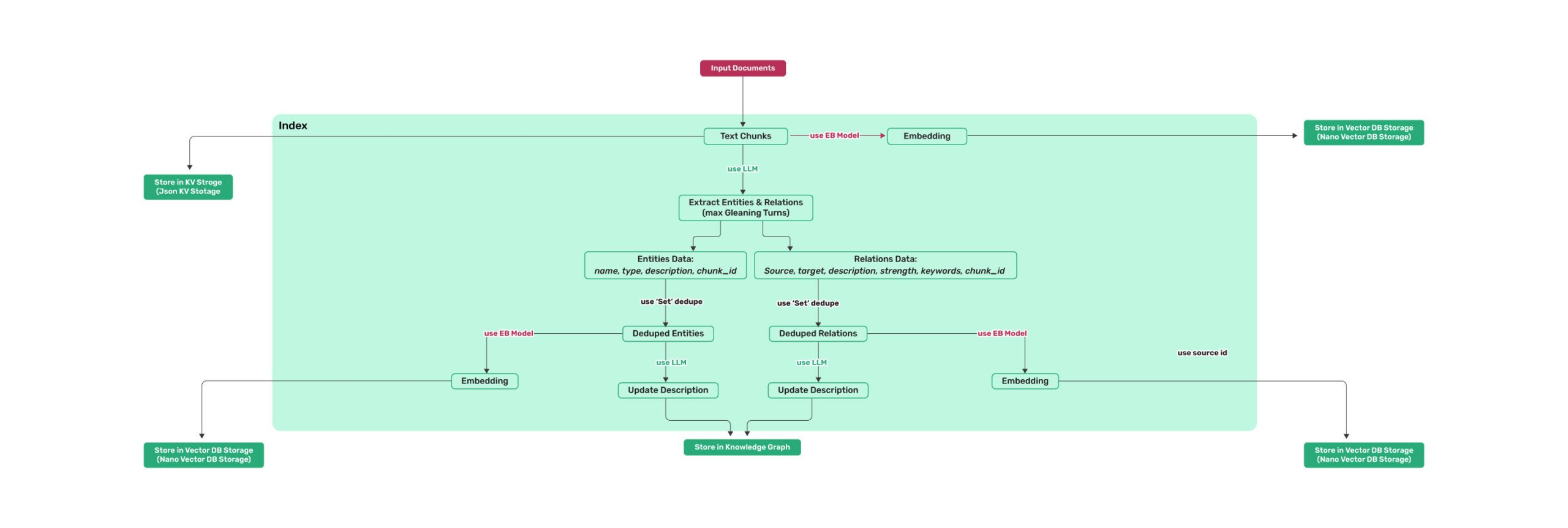
2.1.1 文本切块
2025-09-08 18:01:52,173 - tester1 - INFO - [ 数据抽取任务【090802】开始 ]
2025-09-08 18:01:52,173 - tester1 - INFO - [ ================================================== ]
2025-09-08 18:01:52,173 - tester1 - INFO - [ step 1: 文件读取 ]
2025-09-08 18:01:52,173 - tester1 - INFO - [ ================================================== ]
2025-09-08 18:01:52,173 - tester1 - INFO - [ 文档路径:data/电力光纤到户施工及验收规范(DLT 5716-2015 ).docx ]
2025-09-08 18:01:52,173 - tester1 - INFO - [ 文档格式:.docx ]
2025-09-08 18:01:52,209 - tester1 - INFO - [ 文档长度:6360 ]
2025-09-08 18:01:52,209 - tester1 - INFO - [ 数据入库中... ]
2025-09-08 18:01:52,224 - tester1 - INFO - [ 数据入库成功 ]
2025-09-08 18:01:52,226 - tester1 - INFO - [ ================================================== ]
2025-09-08 18:01:52,226 - tester1 - INFO - [ step 2: 文件切块、向量化 ]
2025-09-08 18:01:52,226 - tester1 - INFO - [ ================================================== ]
2025-09-08 18:01:52,226 - tester1 - INFO - [ 切块方式:general ]
2025-09-08 18:01:52,227 - tester1 - INFO - [ 块大小:500 重叠大小:50 ]
2025-09-08 18:01:52,228 - tester1 - INFO - [ 块数量:14 ]
2025-09-08 18:01:52,228 - tester1 - INFO - [ 数据入库中... ]
2025-09-08 18:01:54,285 - tester1 - INFO - [ 数据入库成功,插入14条,重复的0条不做处理 ]
2025-09-08 18:01:54,285 - tester1 - INFO - [ ================================================== ]
切片方法,支持通用方式、父子分块方式、规则方式等,还有excel/qa/law等(RAGFlow中的切块方法)。
这一步结束会将块内容转向量并存储至es(chunk DB)和neo4j中。
2.1.2 实体与关系抽取
提示词大致如下所示
---目标---
给定一份可能与该活动相关的文本文件和一个实体类型列表,从文本中识别出所有这些类型的实体以及这些已识别实体之间的所有关系。
使用{language}作为输出语言。---步骤---
1. 识别所有实体。对于每个已识别的实体,提取以下信息:
- entity_name(实体名称):实体的名称,使用与输入文本相同的语言。如果是英文,则将名称大写。
- entity_type(实体类型):以下类型之一:[{entity_types}]
- entity_description(实体描述):对实体的属性和活动进行详细描述
将每个实体格式化为("entity"{tuple_delimiter}<entity_name>{tuple_delimiter}<entity_type>{tuple_delimiter}<entity_description>)2. 从第1步中识别出的实体中,识别出所有(source_entity,target_entity)对,这些对彼此之间是*明确相关*的。
对于每对相关实体,提取以下信息:
- source_entity(源实体):第1步中识别出的源实体的名称
- target_entity(目标实体):第1步中识别出的目标实体的名称
- relationship_description(关系描述):解释为什么认为源实体和目标实体彼此相关
- relationship_strength(关系强度):一个数字分数,表示源实体和目标实体之间关系的强度
- relationship_keywords(关系关键词):一个或多个高级关键词,总结关系的总体性质,重点关注概念或主题,而不是具体细节
将每对关系格式化为("relationship"{tuple_delimiter}<source_entity>{tuple_delimiter}<target_entity>{tuple_delimiter}<relationship_description>{tuple_delimiter}<relationship_keywords>{tuple_delimiter}<relationship_strength>)3. 识别出能够总结整个文本的主要概念、主题或主题的高级关键词。这些关键词应能够捕捉文档中呈现的总体思想。
将内容级关键词格式化为("content_keywords"{tuple_delimiter}<high_level_keywords>)4. 将步骤1和2中识别出的所有实体和关系作为单一列表返回,使用**{record_delimiter}**作为列表分隔符。5. 完成后,输出{completion_delimiter}######################
---示例---
######################
{examples}#############################
---真实数据---
######################
Entity_types(实体类型):[{entity_types}]
Text(文本):
{input_text}
######################
Output(输出):
需要提前设计需要抽取的实体类型,如下所示
entity_types = ["PERSON", "LOCATION", "SKILL", "RANK", "ELIXIR", "EVENT"]
entity_info = '''PERSON:人
LOCATION:地点
SKILL:斗技(斗技由高到低分为天阶、地阶、玄阶、黄阶四大等阶,每阶又细分为初级、中级、高级三个小等级,共四阶十二级。)
RANK:段位(斗之气[分为一段到九段]、斗者[分为一至九星]、斗师[分为一至九星]、大斗师[分为一至九星]、斗灵[分为一至九星]、斗王[分为一至九星]、斗皇[分为一至九星]、斗宗[分为一至九星]、斗尊[分为一至九星]、斗尊巅峰[一至十转,接近半圣]、半圣[分为低、中、高三级]、斗圣[一至九星,每星又分初、中、后三期]、斗帝[斗气大陆的顶级境界])
EVENT:事件
ELIXIR:丹药、草药等'''
也可以使用以下提示词自动根据文档内容生成实体类型:
# 你是一位知识图谱专家,擅长从文档内容中分析并设计出有效的知识图谱方案。当前的任务是基于给定的文档来构建一个知识图谱,并从中抽取实体信息。
## 你的具体任务包括但不限于识别和定义%s种不同的实体类型。对于每一种实体类型,请提供其英文名称、中文名称以及简要说明。
请确保所选实体能够准确反映文档的核心内容,并且对理解文档主题至关重要。
# 输出
## 输出格式为json,json中不能包含任何#说明文字,格式如下:
{"entity_type_english": "实体类别英文名(符合命名规范,不能出现空格)", "entity_type_chinese": "实体类别中文名", "explain": "实体简要解释"
}
--- **文档内容:**
{text}
然后就可以进行实体信息抽取了
2025-09-11 16:13:26,163 - tester1 - INFO - [ step 5: 块内容抽取spo三元组 ]
2025-09-11 16:13:26,163 - tester1 - INFO - [ ================================================== ]
2025-09-11 16:13:26,164 - tester1 - INFO - [ 抽取方式:entity ]
2025-09-11 16:13:26,164 - tester1 - INFO - [ Processing chunk 1/14 (515 word) ]
2025-09-11 16:13:33,546 - tester1 - INFO - [ Processing chunk 2/14 (444 word) ]
2025-09-11 16:13:41,267 - tester1 - INFO - [ Processing chunk 3/14 (547 word) ]
2025-09-11 16:13:50,691 - tester1 - INFO - [ Processing chunk 4/14 (539 word) ]
2025-09-11 16:13:56,674 - tester1 - INFO - [ Processing chunk 5/14 (516 word) ]
2025-09-11 16:14:06,643 - tester1 - INFO - [ Processing chunk 6/14 (535 word) ]
2025-09-11 16:14:13,767 - tester1 - INFO - [ Processing chunk 7/14 (513 word) ]
2025-09-11 16:14:22,942 - tester1 - INFO - [ Processing chunk 8/14 (534 word) ]
2025-09-11 16:14:36,037 - tester1 - INFO - [ Processing chunk 9/14 (525 word) ]
2025-09-11 16:14:51,662 - tester1 - INFO - [ Processing chunk 10/14 (536 word) ]
2025-09-11 16:15:04,239 - tester1 - INFO - [ Processing chunk 11/14 (532 word) ]
2025-09-11 16:15:11,523 - tester1 - INFO - [ Processing chunk 12/14 (507 word) ]
2025-09-11 16:15:22,149 - tester1 - INFO - [ Processing chunk 13/14 (510 word) ]
2025-09-11 16:15:43,893 - tester1 - INFO - [ Processing chunk 14/14 (256 word) ]
2025-09-11 16:15:49,591 - tester1 - INFO - [ 块内容 抽取entity三元组 结果保存至 E:\zhx\workspace_2025\Event_Graph\module_selfgraph/log/090802\chunkEntity_json.json ]
2025-09-11 16:15:49,591 - tester1 - INFO - [ ================================================== ]
2025-09-11 16:15:49,592 - tester1 - INFO - [ step 6: 实体数据入库 ]
2025-09-11 16:15:49,592 - tester1 - INFO - [ ================================================== ]
2025-09-11 16:15:49,593 - tester1 - INFO - [ Processing chunk 090802_0001 ]
2025-09-11 16:15:52,515 - tester1 - INFO - [ 数据更新0个实体,插入11个实体 ]
2025-09-11 16:15:53,853 - tester1 - INFO - [ 数据更新0个关系,插入5个关系 ]
2025-09-11 16:15:53,880 - tester1 - INFO - [ Processing chunk 090802_0002 ]
2025-09-11 16:15:54,979 - tester1 - INFO - [ 数据更新0个实体,插入8个实体 ]
2025-09-11 16:15:56,029 - tester1 - INFO - [ 数据更新0个关系,插入7个关系 ]
2025-09-11 16:15:56,032 - tester1 - INFO - [ Processing chunk 090802_0003 ]
2025-09-11 16:15:58,535 - tester1 - INFO - [ 数据更新4个实体,插入7个实体 ]
2025-09-11 16:15:59,924 - tester1 - INFO - [ 数据更新0个关系,插入8个关系 ]
2025-09-11 16:15:59,927 - tester1 - INFO - [ Processing chunk 090802_0004 ]
2025-09-11 16:16:01,127 - tester1 - INFO - [ 数据更新2个实体,插入5个实体 ]
2025-09-11 16:16:01,923 - tester1 - INFO - [ 数据更新0个关系,插入5个关系 ]
2025-09-11 16:16:01,925 - tester1 - INFO - [ Processing chunk 090802_0005 ]
2025-09-11 16:16:04,320 - tester1 - INFO - [ 数据更新2个实体,插入11个实体 ]
2025-09-11 16:16:05,699 - tester1 - INFO - [ 数据更新0个关系,插入9个关系 ]
2025-09-11 16:16:05,702 - tester1 - INFO - [ Processing chunk 090802_0006 ]
2025-09-11 16:16:06,882 - tester1 - INFO - [ 数据更新2个实体,插入6个实体 ]
2025-09-11 16:16:08,487 - tester1 - INFO - [ 数据更新0个关系,插入8个关系 ]
2025-09-11 16:16:08,489 - tester1 - INFO - [ Processing chunk 090802_0007 ]
2025-09-11 16:16:10,251 - tester1 - INFO - [ 数据更新6个实体,插入6个实体 ]
2025-09-11 16:16:11,434 - tester1 - INFO - [ 数据更新0个关系,插入7个关系 ]
2025-09-11 16:16:11,437 - tester1 - INFO - [ Processing chunk 090802_0008 ]
2025-09-11 16:16:14,132 - tester1 - INFO - [ 数据更新4个实体,插入12个实体 ]
2025-09-11 16:16:15,955 - tester1 - INFO - [ 数据更新0个关系,插入12个关系 ]
2025-09-11 16:16:15,958 - tester1 - INFO - [ Processing chunk 090802_0009 ]
2025-09-11 16:16:18,708 - tester1 - INFO - [ 数据更新3个实体,插入11个实体 ]
2025-09-11 16:16:21,159 - tester1 - INFO - [ 数据更新0个关系,插入11个关系 ]
2025-09-11 16:16:21,162 - tester1 - INFO - [ Processing chunk 090802_0010 ]
2025-09-11 16:16:24,364 - tester1 - INFO - [ 数据更新9个实体,插入9个实体 ]
2025-09-11 16:16:25,992 - tester1 - INFO - [ 数据更新0个关系,插入9个关系 ]
2025-09-11 16:16:25,997 - tester1 - INFO - [ Processing chunk 090802_0011 ]
2025-09-11 16:16:27,229 - tester1 - INFO - [ 数据更新3个实体,插入3个实体 ]
2025-09-11 16:16:28,183 - tester1 - INFO - [ 数据更新0个关系,插入6个关系 ]
2025-09-11 16:16:28,184 - tester1 - INFO - [ Processing chunk 090802_0012 ]
2025-09-11 16:16:30,377 - tester1 - INFO - [ 数据更新1个实体,插入7个实体 ]
2025-09-11 16:16:32,517 - tester1 - INFO - [ 数据更新0个关系,插入7个关系 ]
2025-09-11 16:16:32,520 - tester1 - INFO - [ Processing chunk 090802_0013 ]
2025-09-11 16:16:36,169 - tester1 - INFO - [ 数据更新0个实体,插入20个实体 ]
2025-09-11 16:16:39,315 - tester1 - INFO - [ 数据更新0个关系,插入19个关系 ]
2025-09-11 16:16:39,320 - tester1 - INFO - [ Processing chunk 090802_0014 ]
2025-09-11 16:16:40,220 - tester1 - INFO - [ 数据更新2个实体,插入3个实体 ]
2025-09-11 16:16:41,222 - tester1 - INFO - [ 数据更新0个关系,插入5个关系 ]
2025-09-11 16:16:41,225 - tester1 - INFO - [ 数据入库成功 ]
2025-09-11 16:16:41,225 - tester1 - INFO - [ 数据抽取任务【090802】结束 ]
2025-09-11 16:16:41,226 - tester1 - INFO - [ ************************************************** ]
这一步结束会将实体、关系内容转向量并存储至es(entity DB、relation DB)和neo4j中。在入库的时候可对实体进行对齐合并,可以选择使用llm和lcs两种方法(entity实体去重,支持使用LLM增强去重效果,默认使用最长公共子序列(LCS)进行去重)
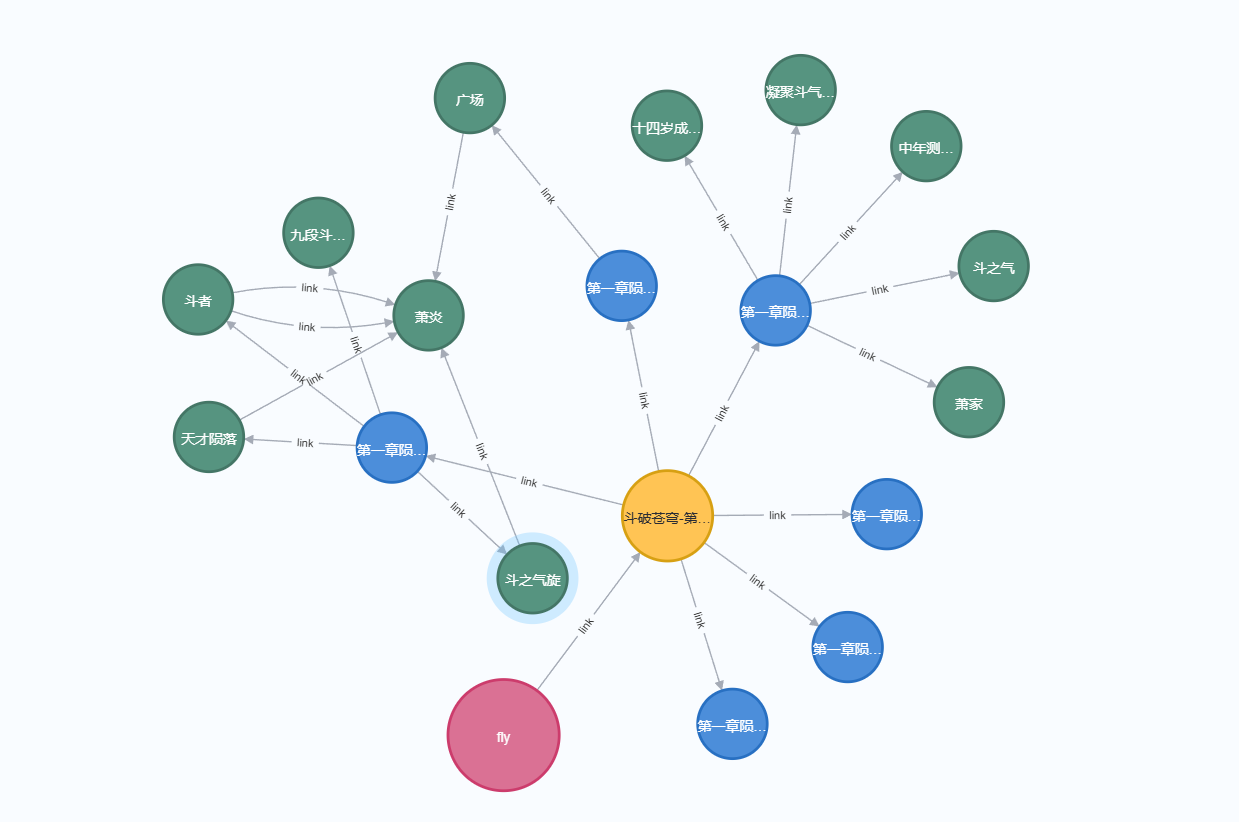
2.1.3 文档总结、目录识别(可选)
文档内容字数超了的话会切块进行子总结,最后汇总总结,这个在针对用户询问某某文档某某章节内容时进行知识召回。
2025-08-14 09:44:16,822 - tester1 - INFO - [ step 3: 文档总结、目录识别 ]
2025-08-14 09:44:16,822 - tester1 - INFO - [ ================================================== ]
2025-08-14 09:44:16,823 - tester1 - INFO - [ 文档内容长度【未超过】大模型输入限制,直接进行总结与目录识别 ]
2025-08-14 09:44:22,686 - tester1 - INFO - [ 文档总结、目录识别结果保存至 E:\zhx\workspace_2025\Event_Graph\module_fusion/log/1003\summary_json.json ]
2025-08-14 09:44:22,686 - tester1 - INFO - [ 数据入库中... ]
2025-08-14 09:44:22,703 - tester1 - INFO - [ 数据入库成功 ]
2025-08-14 09:44:22,703 - tester1 - INFO - [ ================================================== ]
{"summary": "本文详细介绍了操作系统的五大基本功能,包括处理机管理、存储管理、设备管理、信息管理和用户接口。这些功能涵盖了硬件资源的分配与保护以及软件资源的信息管理,并提供了友好的用户交互方式。","title_structure": ["1.4 操作系统功能","1.4.1 处理机管理","1.4.2 存储管理","1.4.3 设备管理","1.4.4 信息管理(文件系统管理)","1.4.5 用户接口"]
}
2.1.4 块内容 摘要化、标题化、标签化 (可选)
2025-08-14 09:44:22,703 - tester1 - INFO - [ step 4: 块内容 摘要化、标题化、标签化 ]
2025-08-14 09:44:22,703 - tester1 - INFO - [ ================================================== ]
2025-08-14 09:44:22,703 - tester1 - INFO - [ Processing chunk 1/4 (511 word) ]
2025-08-14 09:44:25,754 - tester1 - INFO - [ Processing chunk 2/4 (548 word) ]
2025-08-14 09:44:28,137 - tester1 - INFO - [ Processing chunk 3/4 (494 word) ]
2025-08-14 09:44:30,617 - tester1 - INFO - [ Processing chunk 4/4 (254 word) ]
2025-08-14 09:44:32,771 - tester1 - INFO - [ 块内容 摘要化、标题化、标签化 结果保存至 E:\zhx\workspace_2025\Event_Graph\module_fusion/log/1003\chunkAbstract_json.json ]
2025-08-14 09:44:32,772 - tester1 - INFO - [ 数据入库中... ]
2025-08-14 09:44:33,340 - tester1 - INFO - [ 数据入库成功 ]
2025-08-14 09:44:33,341 - tester1 - INFO - [ ================================================== ]
[{"id": "1002_0001","data": {"summary": "操作系统负责管理和控制计算机硬件和软件资源,包括处理机、存储器等,并提供用户友好的工作环境。具体功能分为处理机管理和存储管理两部分。","tags": ["操作系统","处理机管理","存储管理","内存分配","存储保护"],"title_structure": ["1.4 操作系统功能","1.4.1 处理机管理","1.4.2 存储管理"]}},{"id": "1002_0002","data": {"summary": "讨论了存储保护、内存分配和内存扩充的问题,包括如何防止程序间的数据冲突以及在物理内存不足时通过虚拟存储技术提供更大的存储空间。","tags": ["存储管理","内存分配","存储保护","内存扩充","虚拟存储器"],"title_structure": ["1.4 存储管理"]}},{"id": "1002_0003","data": {"summary": "介绍了文件系统的管理和重要性,包括信息共享、保密和保护机制。还提到了用户接口的概念。","tags": ["文件系统管理","信息共享","保密机制","保护机制","用户接口"],"title_structure": ["1.4 操作系统功能","1.4.4 信息管理(文件系统管理)","1.4.5 用户接口"]}},{"id": "1002_0004","data": {"summary": "介绍了操作系统通过两种方式的用户接口为用户提供服务,包括程序级和作业级接口。","tags": ["操作系统","用户接口","系统调用","作业控制"],"title_structure": ["1.4 用户接口"]}}
]
2.2 检索流程
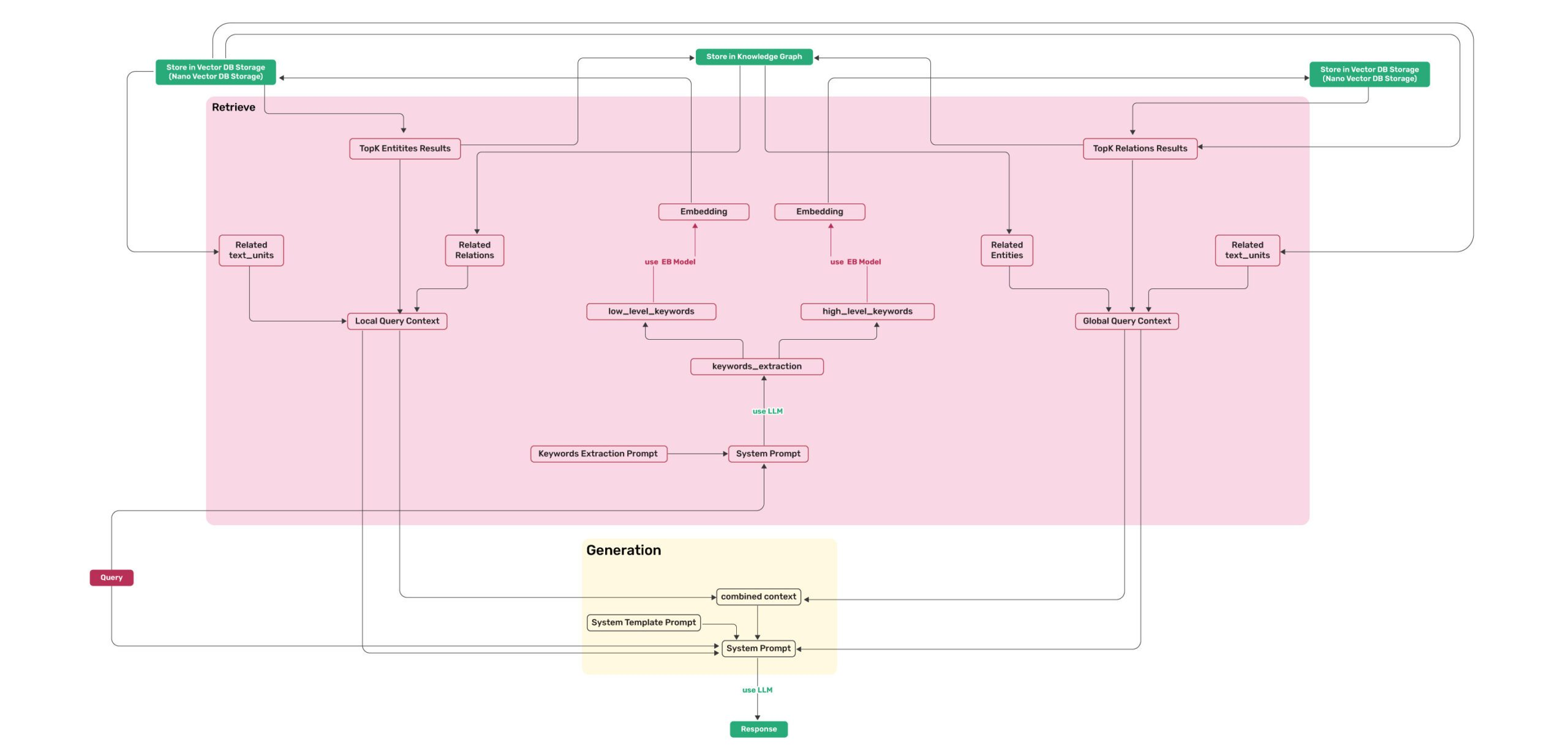
2.2.1 生成查询关键词
对用户的问题进行查询关键词生成,分为两种,低级关键词和高级关键词,高级关键词侧重于总体概念或主题,而低级关键词侧重于特定的实体、细节或具体的术语。
低级关键词应用于查询entity DB,高级关键词应用于relation DB。
---角色---你是一个乐于助人的助手,负责从用户的查询内容以及对话历史记录中识别高级关键词和低级关键词。---目标---根据给定的查询内容和对话历史记录,列出高级关键词和低级关键词。高级关键词侧重于总体概念或主题,而低级关键词侧重于特定的实体、细节或具体的术语。---说明---- 在提取关键词时,需同时考虑当前的查询内容和相关的对话历史记录。
- 以JSON格式输出关键词。
- JSON应包含两个键:- “high_level_keywords”(高级关键词)用于表示总体概念或主题。- “low_level_keywords”(低级关键词)用于表示特定的实体或细节。######################
---示例---
######################
示例1:查询内容:“国际贸易如何影响全球经济稳定?”
################
输出:
{"高级关键词": ["国际贸易", "全球经济稳定", "经济影响"],"低级关键词": ["贸易协定", "关税", "货币兑换", "进口", "出口"]
}
#############################示例2:查询内容:“森林砍伐对生物多样性会产生哪些环境方面的后果?”
################
输出:
{"高级关键词": ["环境后果", "森林砍伐", "生物多样性丧失"],"低级关键词": ["物种灭绝", "栖息地破坏", "碳排放", "雨林", "生态系统"]
}
#############################示例3:查询内容:“教育在减贫方面起到了什么作用?”
################
输出:
{"高级关键词": ["教育", "减贫", "社会经济发展"],"低级关键词": ["入学机会", "识字率", "职业培训", "收入不平等"]
}
##########################################################
---真实数据---
######################
对话历史记录:
{历史记录内容}当前查询内容:{查询内容}
######################
“输出”内容应该是人类可读的文本,而非Unicode字符。使用与“查询内容”相同的语言。
输出:
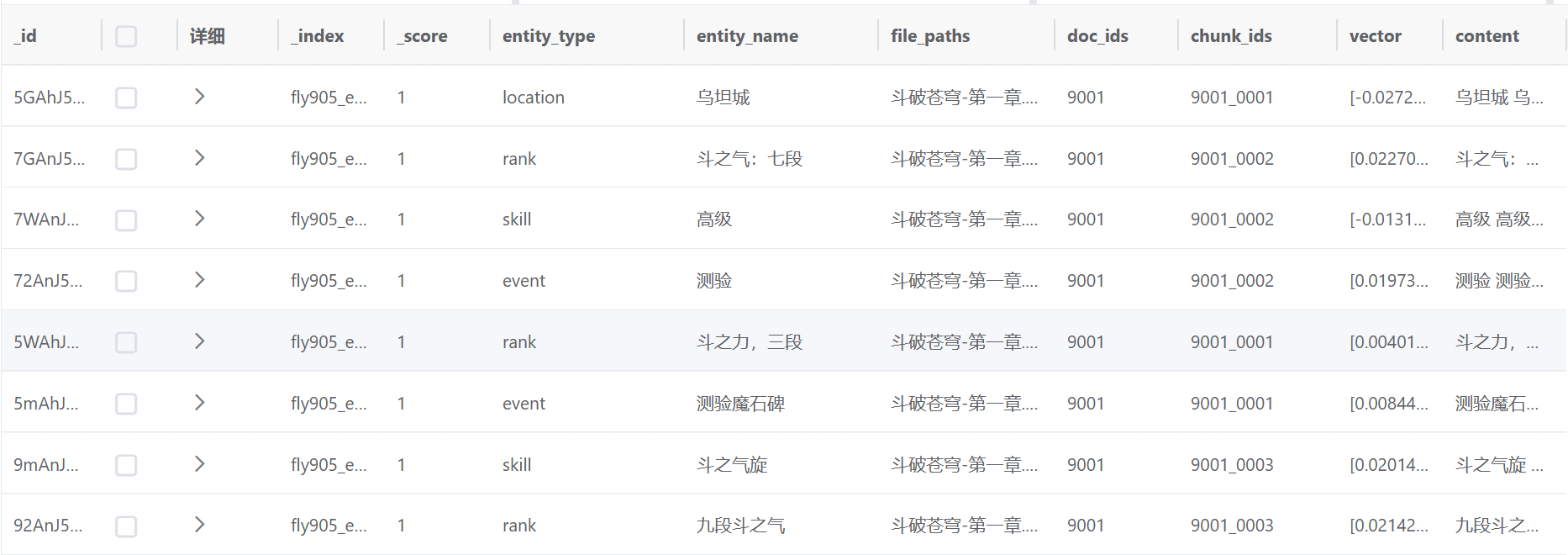
2.2.2 实体查询
顾名思义,查询实体es库
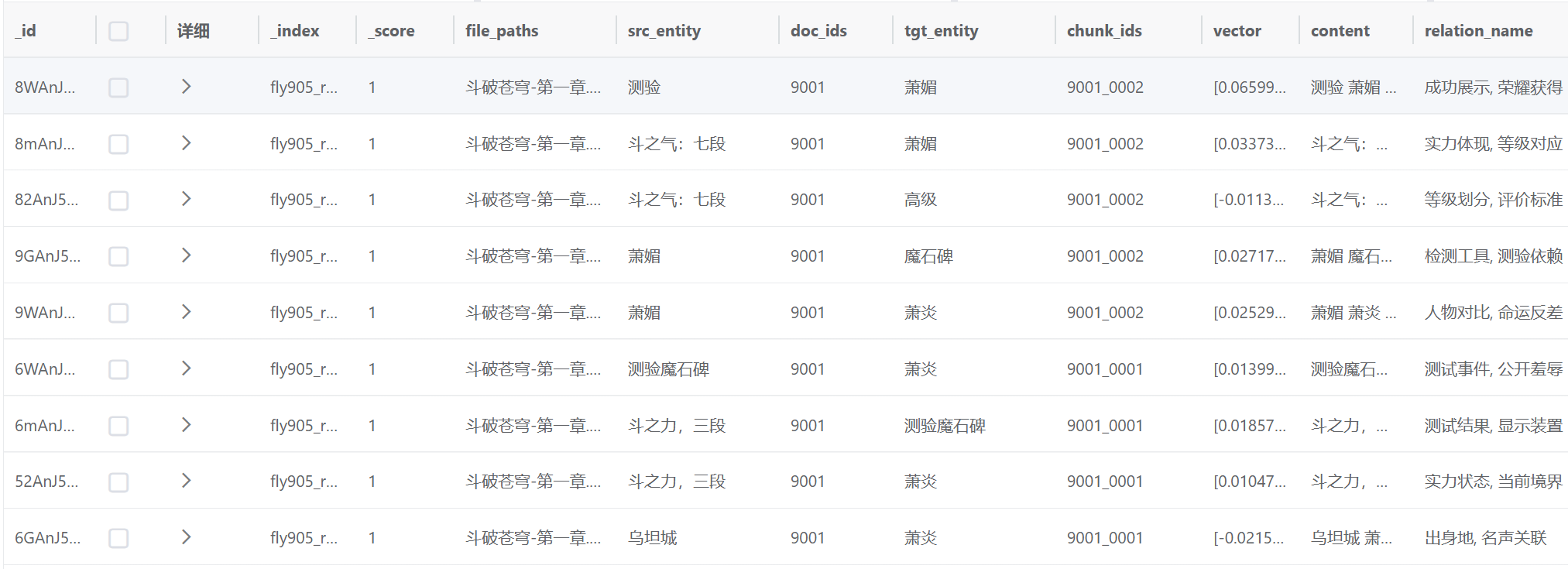
2.2.3 关系查询
顾名思义,查询关系es库
2.2.4 chunk查询
顾名思义,查询块es库
2.2.5 重排序
将所有查询内容汇总进行重拍
2.3 知识拼接
---角色---你是一个帮助助手,负责回答用户关于以下数据源的查询。---目标---基于数据源生成简明的回答,遵循回答规则,同时考虑对话历史和当前查询。数据源包含两部分:知识图谱(KG)和文档片段(DC)。总结数据源中提供的所有信息,并结合与数据源相关的通用知识。不要包含数据源未提供的信息。在处理带有时间戳的信息时:
1. 每条信息(包括关系和内容)都有一个"created_at"时间戳,表示我们获取这个知识的时间
2. 当遇到冲突信息时,同时考虑内容/关系和时间戳
3. 不要自动优先选择最近的信息 - 根据上下文进行判断
4. 对于特定时间的查询,在考虑创建时间戳之前优先考虑内容中的时间信息---对话历史---
{history}---数据源---1. 来自知识图谱(KG):
{kg_context}2. 来自文档片段(DC):
{vector_context}---回答规则---- 目标格式和长度:{response_type}
- 使用markdown格式并添加适当的章节标题
- 请使用与用户提问相同的语言回答
- 确保回答与对话历史保持连贯性
- 将回答组织成多个章节,每个章节专注于一个主要观点或方面
- 使用清晰且能反映内容的章节标题
- 在"参考来源"章节的末尾列出最多5个最重要的参考来源。清楚地标明每个来源是来自知识图谱(KG)还是文档数据(DC),使用以下格式:[KG/DC] 来源内容
- 如果不知道答案,请直接说明。不要编造内容。
- 不要包含数据源未提供的信息。
三、可视化问答
使用streamlit编写简单对话界面

四、上升空间
持续优化中