PyTorch深度学习实战【10】之神经网络的损失函数
文章目录
- 零 回顾:机器学习中的模型训练流程
- 一 神经网络的损失函数
- 1.1 机器学习中的优化思想
- 1.2 回归:误差平方和SSE
- 1.3 二分类交叉熵损失的原理与实现
- 1.3.1 极大似然估计求解二分类交叉熵损失
- 1.3.2 实现二类交叉熵损失
- 1.4 多分类交叉熵损失的原理与实现
- 1.4.1 二分类推广到多分类
- 1.4.2 用PyTorch实现多分类交叉熵损失
零 回顾:机器学习中的模型训练流程
- 模型训练流程
- 提出基本模型,明确目标:基本模型就是自建的神经网络架构,需要求解的就是神经网络架构中的权重向量www。
- 确定损失函数/目标函数:定义评估指标,衡量模型权重为www的情况下,预测结果与真实结果的差异。当真实值与预测值差异越大时,丢失的这部分被形象地称为”损失”。因此,评估真实值与预测值差异的函数被称为“损失函数”。
- 损失函数:衡量真实值与预测结果的差异,评价模型学习过程中产生的损失的函数。在数学上,表示为以需要求解的权重向量w为自变量的函数L(w)L(w)L(w)。如果损失函数的值很小,则说明模型预测值与真实值很接近,模型在数据集上表现优异,权重优秀;如果损失函数的值大,则说明模型预测值与真实值差异很大,模型在数据集上表现差劲,权重糟糕。
- 确定适合优化算法。
- 利用优化算法,最小化损失函数,求解最佳权重www(训练)。
一 神经网络的损失函数
1.1 机器学习中的优化思想
- 神经网络的正向传播过程:建立神经网络时,先设定好www和bbb的值或通过PyTorch随机生成权重向量www,然后通过计算得到zzz,再在zzz上嵌套sigmod或softmax函数,最终获得神经网络的输出。
- 正向传播的过程虽然可以输出预测结果,但是无法保证神经网络的输出结果与真实值接近。所以,正向传播并不是神经网络算法的全流程。

- 在线性回归中,线性回归的任务是构造一个预测函数来映射输入的特征矩阵XXX和标签yyy的线性关系。构造预测函数的核心是找出模型权重向量www,并令线性回归的输出结果与真实值相近。换句话说,就是求解线性方程组中的www和bbb。
- 模型训练的目标:求解一组最合适的权重向量www,令神经网络中的输出结果与真实值尽量接近。
- 评价www和bbb是否合适?如何衡量输出结果与真实值之间的差异?可以通过机器学习中的通用的优化流程:定义损失函数,定义优化算法,以最小化损失函数为目标,求解权重。
1.2 回归:误差平方和SSE
- 回归类神经网络,常见的损失函数是SSE(Sum of the Squared Errors)
SSE=∑i=1m(zi−z^i)2MSE=1m∑i=1m(zi−z^i)2SSE=\sum_{i=1}^{m}(z_i-\hat z_i)^2 \\ MSE=\frac{1}{m}\sum_{i=1}^{m}(z_i-\hat z_i)^2 SSE=i=1∑m(zi−z^i)2MSE=m1i=1∑m(zi−z^i)2 - 简单调用代码:
import torch from torch.nn import MSELoss y_hat = torch.randn(size=(50,), dtype=torch.float32) y = torch.randn(size=(50,), dtype=torch.float32) criterion = MSELoss() loss = criterion(y_hat, y) print(loss)
1.3 二分类交叉熵损失的原理与实现
- 二分类神经网络的损失函数:二分类交叉熵损失函数(Binary Cross Entropy Loss)/对数损失(log loss),广泛应用于二分类(单层或多层)神经网络中。除非特别声明为二分类,常见提到交叉熵损失,默认是多分类。
- 二分类交叉熵损失函数是由极大似然函数估计推导而来,对于有m个样本的数据集,在全部样本上的平均损失写作:
L(w)=−∑i=1m(yi∗ln(σi)+(1−yi)∗ln(1−σi))L(w)=-\sum_{i=1}^{m} (y_i * ln(\sigma_i)+(1-y_i) * ln(1-\sigma_i) ) L(w)=−i=1∑m(yi∗ln(σi)+(1−yi)∗ln(1−σi)) - 单个损失函数:
L(w)=−(yi∗ln(σi)+(1−yi)∗ln(1−σi))L(w)=-(y_i * ln(\sigma_i)+(1-y_i) * ln(1-\sigma_i) ) L(w)=−(yi∗ln(σi)+(1−yi)∗ln(1−σi)) - ln是以自然底数e为底的对数函数,w表示求解出来的一组权重(在等号的右侧,w在σ\sigmaσ里),m是样本的个数,y是样本i上真实的标签,σi\sigma_iσi是样本i上,基于参数w计算出来的sigmoid函数的返回值,xix_ixi是样本i各个特征的取值。目标是求解出使L(w)L(w)L(w)最小的w取值。
- 注意:在神经网络中,特征张量X是自变量,权重是w。但在损失函数中,权重w是损失函数的自变量,特征x和真实标签y都是已知的数据,相当于是常数。不同的函数中,自变量和参数各有不同,因此在数学计算中,尤其是求导的时候避免混淆。
1.3.1 极大似然估计求解二分类交叉熵损失
- 基于极大似然法推导交叉熵损失,帮助充分了解交叉熵损失的含义,以及为什么L(w)L(w)L(w)的最小化能够实现模型在数据集上的最好拟合。
- 极大似然估计(Maximum Likelihood Estimate,MLE):如果一个事件的发生概率很大,那这个事件应该很容易发生。如果我们希望一件事发生,就应该增加这件事发生的概率。假设现在存在事件A,其发生概率受权重w的影响。那为了事件A尽可能地发生,那么只要寻找令其发生概率最大化的权重w。
- 极大似然估计的基本方法寻找相应的权重w,使得目标事件的发生概率最大。极大似然,就是“最大概率”,估计就是权重w。
- 整体步骤如下:
- 构筑似然函数P(w)P(w)P(w):用于评估目标事件发生的概率,该函数被设计成目标事件发生时,概率最大。
- 对整体似然函数取对数,构成对数似然函数ln(P(w))ln(P(w))ln(P(w))。
- 在对数似然函数上对权重www求导,并使导数为000,对权重进行求解。
- 在二分类例子中,“任意事件”就是每个样本的分类都正确对数似然函数的负数就是我们的损失函数。以此例为起点,介绍逻辑回归的对数似然函数的构筑过程。
- 二分类神经网络的标签是[0,1][0,1][0,1],此标签服从伯努利分布(即0−10-10−1分布),因此可得样本iii在由特征向量ccc和权重向量www组成的预测函数中,样本标签被预测为1的概率为:P1=P(y^i=1∣xi,w)=σP_1=P(\hat y_i =1 |x_i,w)=\sigmaP1=P(y^i=1∣xi,w)=σ(对二分类来说,σ\sigmaσ就是sigmoid函数的结果);样本标签被预测为000的概率为:P0=P(y^i=0∣xi,w)=1−σP_0=P(\hat y_i =0 | x_i,w)=1- \sigmaP0=P(y^i=0∣xi,w)=1−σ。
- 当P1P_1P1的值为1时,代表样本iii的标签被预测为1,当当P0P_0P0的值为1时,代表样本iii的标签被预测为0。P1P_1P1和P0P_0P0相加一定等于1。
- 假设样本的真实标签y为1,并且P1=1P_1=1P1=1,说明将标签预测为1的概率很大,与真实值一致,模型预测准确,拟合程度很高,信息损失少。相反,如果真实标签y为1,P1P_1P1接近0,说明将标签预测为1的概率很小,即与真实值一致的概率很小,模型预测失败,拟合程度很低,信息损失多。当yiy_iyi为0时,也是同理。所以,当yiy_iyi为1时,我们希望P1P_1P1非常接近1,当yiy_iyi为0的时候,我们希望PP0P_0P0非常接近1,这样,模型效果好,信息损失少。
| 真实标签 | 被预测为1的概率 P1 | 被预测为0的概率 P0 | 样本被预测为? | 与真实值一致吗? | 拟合状况 | 信息损失 |
|---|---|---|---|---|---|---|
| 1 | 0 | 1 | 0 | 否 | 坏 | 大 |
| 1 | 1 | 0 | 1 | 是 | 好 | 小 |
| 0 | 0 | 1 | 0 | 是 | 好 | 小 |
| 0 | 1 | 0 | 1 | 否 | 坏 | 大 |
- 将两种取值的概率整合,可以定义如下等式:
P(y^i∣xi,w)=P1yi∗P01−yiP(\hat y_i| x_i,w)=P_1^{y_i}* P_0^{1-y_i} P(y^i∣xi,w)=P1yi∗P01−yi
- 二分类模型中损失与预测概率的关系:理解二分类模型中损失与预测概率的关系,需结合真实标签 yiy_iyi 和模型预测概率分析。
- 当 yi=1y_i = 1yi=1 时,1−yi=01 - y_i = 01−yi=0,因此 P00=1P_0^0 = 1P00=1,条件概率为:
P(y^i∣xi,w)=P1P(\hat{y}_i | x_i, w) = P_1 P(y^i∣xi,w)=P1
若模型效果好,P1P_1P1 应接近 1,此时损失很小。 - 当 yi=0y_i = 0yi=0 时,同理:
P(y^i∣xi,w)=P0P(\hat{y}_i | x_i, w) = P_0 P(y^i∣xi,w)=P0
若模型效果好,P0P_0P0 应接近 1,此时损失也很小。
- 模型拟合目标与极大似然估计:为了让模型拟合好、损失小,我们希望P(y^i∣xi,w)P(\hat{y}_i | x_i, w)P(y^i∣xi,w) 的值尽可能接近 1****。这是因为 P(y^i∣xi,w)P(\hat{y}_i | x_i, w)P(y^i∣xi,w) 表示模型在给定样本 xix_ixi 和参数 www 下预测正确标签的概率,其最大值为 1。换言之,我们始终在追求 P(y^i∣xi,w)P(\hat{y}_i | x_i, w)P(y^i∣xi,w) 的最大化。寻找参数www使得预测概率最大,这正是极大似然估计的核心思想。
- 由于P(y^i∣xi,w)P(\hat{y}_i | x_i, w)P(y^i∣xi,w) 是针对单个样本的,我们还需将其拓展到整个样本集上。对于一个训练集m个样本来说,我们可以定义如下等式来表达所有样本在特征张量X和权重向量www组成的预测函数,预测出所有可能的y^\hat yy^的概率P为:
P=∏i=1mP(y^i∣xi,w)=∏i=1m(P1yi⋅P01−yi)=∏i=1m(σiyi⋅(1−σi)1−yi)\begin{align*} P &= \prod_{i=1}^{m} P(\hat{y}_i | x_i, w) \\ &= \prod_{i=1}^{m} (P_1^{y_i} \cdot P_0^{1-y_i}) \\ &= \prod_{i=1}^{m} (\sigma_i^{y_i} \cdot (1 - \sigma_i)^{1-y_i}) \end{align*} P=i=1∏mP(y^i∣xi,w)=i=1∏m(P1yi⋅P01−yi)=i=1∏m(σiyi⋅(1−σi)1−yi)
其中:
- ∏i=1m\prod_{i=1}^{m}∏i=1m 表示从第 1 个样本到第m个样本的连乘。
- P(y^i∣xi,w)P(\hat{y}_i | x_i, w)P(y^i∣xi,w) 是样本 i 在特征向量xix_ixi和参数www下的预测概率。
- P1yi⋅P01−yiP_1^{y_i} \cdot P_0^{1-y_i}P1yi⋅P01−yi 利用真实标签yiy_iyi选择对应的类别概率(yi=1y_i=1yi=1时取P1P_1P1,yi=0y_i=0yi=0时取P0P_0P0)。
- σiyi⋅(1−σi)1−yi\sigma_i^{y_i} \cdot (1 - \sigma_i)^{1-y_i}σiyi⋅(1−σi)1−yi 是用sigmoid函数σi\sigma_iσi表示的二分类概率形式(σi\sigma_iσi 通常对应 P1P_1P1)。
-
上面的函数就是逻辑回归的似然函数。对该概率PPP取以e为底的对数,再由log(A⋅B)=logA+logBlog(A \cdot B)=logA + logBlog(A⋅B)=logA+logB和logAB=BlogAlogA^B=BlogAlogAB=BlogA可以得到逻辑回归的对数似然函数:
lnP=ln∏i=1m(σiyi⋅(1−σi)1−yi)=∑i=1mln(σiyi⋅(1−σi)1−yi)=∑i=1m(lnσiyi+ln(1−σi)1−yi)=∑i=1m(yi⋅lnσi+(1−yi)⋅ln(1−σi))\begin{align*} \ln P &= \ln \prod_{i=1}^{m} \left( \sigma_i^{y_i} \cdot (1 - \sigma_i)^{1 - y_i} \right) \\ &= \sum_{i=1}^{m} \ln \left( \sigma_i^{y_i} \cdot (1 - \sigma_i)^{1 - y_i} \right) \\ &= \sum_{i=1}^{m} \left( \ln \sigma_i^{y_i} + \ln (1 - \sigma_i)^{1 - y_i} \right) \\ &= \sum_{i=1}^{m} \left( y_i \cdot \ln \sigma_i + (1 - y_i) \cdot \ln (1 - \sigma_i) \right) \end{align*} lnP=lni=1∏m(σiyi⋅(1−σi)1−yi)=i=1∑mln(σiyi⋅(1−σi)1−yi)=i=1∑m(lnσiyi+ln(1−σi)1−yi)=i=1∑m(yi⋅lnσi+(1−yi)⋅ln(1−σi)) -
这就是二分类交叉熵函数,为了数学上的便利以及更好定义“损失”的含义,我们希望将极大值问题转化为极小值问题,因此对lnPlnPlnP取负,并且让权重www作为函数的自变量,得到损失函数L(w)L(w)L(w):
L(w)=−∑i=1m(yi⋅lnσi+(1−yi)⋅ln(1−σi))L(w)=-\sum_{i=1}^{m} \left( y_i \cdot \ln \sigma_i + (1 - y_i) \cdot \ln (1 - \sigma_i) \right) L(w)=−i=1∑m(yi⋅lnσi+(1−yi)⋅ln(1−σi)) -
现在,我们已经将模型拟合中的“最小值损失”问题,转化为对函数求解极值的问题。这就是一个基于逻辑回归的返回值σi\sigma_iσi的概率性质以及极大似然估计得出的损失函数。只要追求该函数的最小值,就能让模型在训练数据上的拟合效果最好、损失最低。
-
在极大似然估计中,只要在对数似然函数上对权重w求导,再令导数为0,就可以求解出最合适的w,但是对于像交叉这样复杂的损失函数,加上神经网络中复杂的权重组合,令所有权重的导数为0,并一个个求解方程的难度很大。因此要使用优化算法。
1.3.2 实现二类交叉熵损失
- 用tensor实现二分类交叉熵损失
import torch
m = 3*pow(10, 6)
torch.random.manual_seed(520)
x = torch.rand((m, 4), dtype=torch.float32)
w = torch.rand((4, 1), dtype=torch.float32, requires_grad=True)
y = torch.randint(low=0, high=2, size=(m, 1), dtype=torch.float)
z_hat = torch.mm(x, w)
sigma = torch.sigmoid(z_hat)
loss = -(1/m)*torch.sum(y*torch.log(sigma)+(1-y)*torch.log(1-sigma))
print(loss)
- 用PyTorch中的类实现二分类交叉熵损失
class BCEWithLogitsLoss class BCELoss
- 对于二分类交叉损失,nn提供两个类:BCEWithLogitsLoss以及BCELoss,两个函数所需要输入的参数不同。
- BCEWithLogitsLoss内置sigmoid函数与交叉熵函数,它会自动计算输入值的sigmoid值,因此需要输入z^\hat zz^与真实标签,且顺序不能变化,zhatz_hatzhat必须在前;BCELoss中只有交叉熵函数,没有sigmoid层,因此需要输入sigma与真实标签,且顺序不能变化。同时,这两个函数都要求预测值与真实标签的数据类型以及结构(shape)必须相同,否则运行就会报错。
import torch
import torch.nn as nnm = 3*pow(10, 6)
torch.random.manual_seed(520)
x = torch.rand((m, 4), dtype=torch.float32)
w = torch.rand((4, 1), dtype=torch.float32, requires_grad=True)
y = torch.randint(low=0, high=2, size=(m, 1), dtype=torch.float)
z_hat = torch.mm(x, w)
sigma = torch.sigmoid(z_hat)criterion = nn.BCELoss()
loss = criterion(sigma, y)
print(loss)criterion_2 = nn.BCEWithLogitsLoss()
loss = criterion_2(z_hat, y)
print(loss)
1.4 多分类交叉熵损失的原理与实现
1.4.1 二分类推广到多分类
- 对于多分类的状况而言,标签不再服从伯努利分布(0-1分布),因此可以定义,样本i在由特征向量x和权重向量w组成的预测函数中,样本标签被预测为类别k的概率为:
Pk=P(y^i=k∣xi,w)=σP_k=P(\hat y_i = k| x_i,w)=\sigma Pk=P(y^i=k∣xi,w)=σ - 对于多分类算法而言,σ\sigmaσ就是softmax函数返回的对应类别的值。
考虑一种最简单的情况:现在有三分类 [1, 2, 3],则样本iii被预测为三个类别的概率分别为:
P1=P(y^i=1∣xi,w)=σ1P2=P(y^i=2∣xi,w)=σ2P3=P(y^i=3∣xi,w)=σ3\begin{align*} P_1 &= P(\hat{y}_i = 1 | x_i, w) = \sigma_1 \\ P_2 &= P(\hat{y}_i = 2 | x_i, w) = \sigma_2 \\ P_3 &= P(\hat{y}_i = 3 | x_i, w) = \sigma_3 \end{align*} P1P2P3=P(y^i=1∣xi,w)=σ1=P(y^i=2∣xi,w)=σ2=P(y^i=3∣xi,w)=σ3
- 假设样本的真实标签为 1,我们就希望 P1P_1P1 最大;同理,如果样本的真实标签为其他值,我们就希望其他值所对应的概率最大。
- 在二分类中,我们将yyy 和(1−y)(1 - y)(1−y) 作为概率PPP 的指数,以此来融合真实标签为 0 和为 1 的两种状况。但在多分类中,真实标签可能是任意整数,无法使用yyy 和(1−y)(1 - y)(1−y) 这样的结构来构建似然函数。所以如果多分类的标签也可以使用 0 和 1 来表示,我们就可以继续使用真实标签作为指数的方式。
- 因此,可以对多分类的标签做出如下变化:
- 表格 1:原始标签表
| 样本 | y |
|---|---|
| 样本1 | 2 |
| 样本2 | 3 |
| 样本3 | 1 |
| … | … |
| 样本N | 3 |
- 表格 2:独热编码后标签表
| 样本 | y1 | y2 | y3 |
|---|---|---|---|
| 样本1 | 0 | 1 | 0 |
| 样本2 | 0 | 0 | 1 |
| 样本3 | 1 | 0 | 0 |
| … | … | … | … |
| 样本N | 0 | 0 | 1 |
- 表格 3:Softmax 输出概率表
| 样本 | σ(y1) | σ(y2) | σ(y3) |
|---|---|---|---|
| 样本1 | 0.234 | 0.687 | 0.079 |
| 样本2 | 0.135 | 0.335 | 0.530 |
| 样本3 | 0.597 | 0.234 | 0.169 |
| … | … | … | … |
| 样本N | 0.246 | 0.112 | 0.642 |
-
原本的真实标签yyy 是包含 [1, 2, 3] 三个分类的列向量,现在把它变成了标签矩阵,每个样本对应一个向量(独热编码 one-hot)。在矩阵里,每一行还是对应原来的样本,但由三分类衍生出了三个新列,分别代表:真实标签是否等于 1、等于 2 以及等于 3。矩阵中用 “1” 标注样本真实标签的位置,用 0 表示不是这个标签。不难注意到,这个标签矩阵的结构其实和 softmax 函数输出的概率矩阵的结构一致,并且一一对应的。
-
当我们将标签整理为标签矩阵后,我们就可以将单个样本在总共K个分类情况整合为以下似然函数:
P(y^i∣xi,w)=P1yi(k=1)⋅P2yi(k=2)⋅...⋅PKyi(k=K)P(\hat y_i | x_i, w)=P_1^{y_i(k=1)} \cdot P_2^{y_i(k=2)} \cdot ... \cdot P_K^{y_i(k=K)} P(y^i∣xi,w)=P1yi(k=1)⋅P2yi(k=2)⋅...⋅PKyi(k=K) -
其中:
-
P就是样本标签被预测为某个具体值的概率,而右上角的指数就是标签矩阵中对应的值,即这个样本的真是标签是否为当前标签的判断(1是,0否)。对于一个样本来说,除了自己所在的真实类别为1,其他类别都为0.所以可以将上面的式子简写为:
P(y^i∣xi,w)=Pjyi(k=j),j为样本i对应的真实标签编号P(\hat y_i | x_i,w)=P_j^{y_i(k=j)},j为样本i对应的真实标签编号 P(y^i∣xi,w)=Pjyi(k=j),j为样本i对应的真实标签编号 -
对一个训练集的m个样本来说,可以定义如下等式,来表达所有样本在特征张量X和权重向量w组成的预测函数中,预测出所有可能的y的概率P为:
P=∏i=1mP(y^i∣xi,w)=∏i=1mPjyi(k=j)=∏i=1mσjyi(k=j)\begin{align*} P &= \prod_{i=1}^{m} P(\hat{y}_i | x_i, w) \\ &= \prod_{i=1}^{m} P_j^{y_{i(k=j)}} \\ &= \prod_{i=1}^{m} \sigma_j^{y_{i(k=j)}} \end{align*} P=i=1∏mP(y^i∣xi,w)=i=1∏mPjyi(k=j)=i=1∏mσjyi(k=j) -
与二分类情况下的似然函数一致,对似然函数进行求对数:
lnP=ln∏i=1mσjyi(k=j)=∑i=1mln(σjyi(k=j))=∑i=1myi(k=j)lnσi\begin{align*} \ln P &= \ln \prod_{i=1}^{m} \sigma_j^{y_{i(k=j)}} \\ &= \sum_{i=1}^{m} \ln \left( \sigma_j^{y_{i(k=j)}} \right) \\ &= \sum_{i=1}^{m} y_{i(k=j)} \ln \sigma_i \end{align*} lnP=lni=1∏mσjyi(k=j)=i=1∑mln(σjyi(k=j))=i=1∑myi(k=j)lnσi -
σ\sigmaσ就是softmax函数返回的对应类别的值,再对整个公式取负,可以得到多分类情况下的损失函数:
L(w)=−∑i=1myi(k=j)InσiL(w)= - \sum_{i=1}^{m}y_{i(k=j)} In\sigma_i L(w)=−i=1∑myi(k=j)Inσi -
这就是交叉熵损失函数。
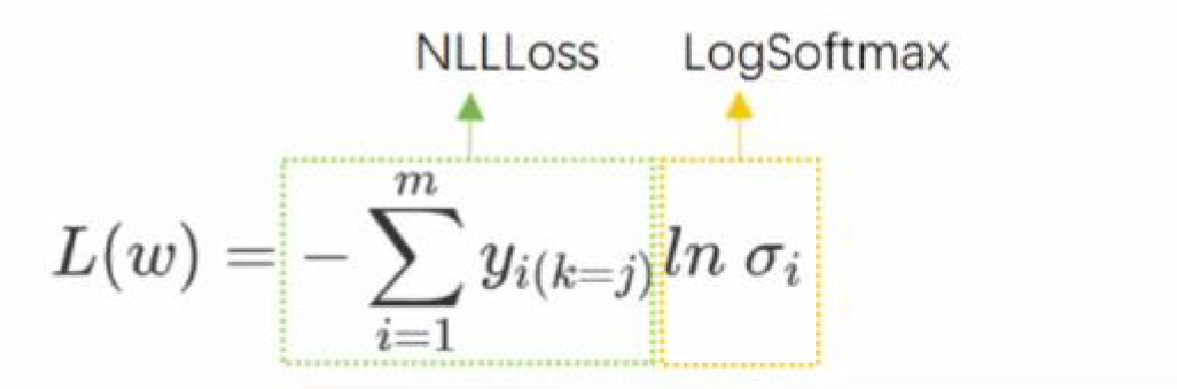
-
交叉熵函数十分特殊,虽然再求解过程中,取对数操作是在确定似然函数后进行的,但从计算结果来看,对数操作其实只对softmax函数的结果σ\sigmaσ起效。因此,在实际操作中,把ln(softmax(z))ln(softmax(z))ln(softmax(z))单独定义一个功能做logsoftmax,PyTorch中可以直接通过nn.logsoftmaxnn.logsoftmaxnn.logsoftmax类调用此功能。同时,将整体的计算称为负对数似然函数(Negative Log Likelihood function),在PyTorch中可以使用nn.NLLLossnn.NLLLossnn.NLLLoss进行调用。
1.4.2 用PyTorch实现多分类交叉熵损失
- 调用logsoftmax和NLLLoss实现
import torch
import torch.nn as nn
torch.random.manual_seed(520)m = 3*pow(10, 3)
x = torch.rand((m, 4), dtype=torch.float32)
w = torch.rand((4, 3), dtype=torch.float32, requires_grad=True)
y = torch.randint(low=0, high=3, size=(m,), dtype=torch.float)
z_hat = torch.mm(x, w)logsm = nn.LogSoftmax(dim=1)
logsigma = logsm(z_hat)
print(logsigma) #ln(softmax)criterion = nn.NLLLoss()
criterion(logsigma, y.long())
- 使用CrossEntropyLoss实现
import torch
import torch.nn as nn
torch.random.manual_seed(520)m = 3*pow(10, 3)
x = torch.rand((m, 4), dtype=torch.float32)
w = torch.rand((4, 3), dtype=torch.float32, requires_grad=True)
y = torch.randint(low=0, high=3, size=(m,), dtype=torch.float)
z_hat = torch.mm(x, w)criterion = nn.CrossEntropyLoss()
loss = criterion(z_hat, y.long())
print(loss)
- PyTorch 对二分类和多分类任务均提供两类输出层实现方式:含输出层激活函数和不含输出层激活函数。实际建模时,需根据需求选择是否包含激活函数(由用户自行决定)。
- 选择依据:
- 重视网络结构与灵活性 → 选「不含输出层激活函数」的类。若在 Model 类的
__init__中定义层数,forward 函数会因内置激活函数(如 sigmoid/logsoftmax)少一层(输出层),导致结构展示不清晰 。复杂网络需结构清晰,且单独写的激活函数修改方便(若混在损失函数中,改激活函数需重构损失函数代码,不利于维护)。 - 重视稳定性与运算精度 → 选「包含输出层激活函数」的类。若长期不修改输出层激活函数,且模型稳定运行更重要,内置激活函数可提升运算精度; 内置激活函数能避免手动实现时的精度损失。
- 综上,损失函数的实现方式最终取决于具体需求。