实现联邦学习客户端训练部分的示例
1. 模型定义(SimpleCNN 类)
class SimpleCNN(nn.Module):def __init__(self):super(SimpleCNN, self).__init__()self.conv = nn.Sequential(nn.Conv2d(1, 32, 3, 1),nn.ReLU(),nn.MaxPool2d(2),nn.Conv2d(32, 64, 3, 1),nn.ReLU(),nn.MaxPool2d(2))self.fc = nn.Sequential(nn.Flatten(),nn.Linear(64 * 5 * 5, 128),nn.ReLU(),nn.Linear(128, 10))def forward(self, x):x = self.conv(x)x = self.fc(x)return x
SimpleCNN类:这是一个简单的卷积神经网络模型,包含两个卷积层 (Conv2d),每个卷积层后面都有一个 ReLU 激活函数和最大池化 (MaxPool2d)。第一层卷积:从输入的 1 通道图像中提取 32 个 3x3 卷积核特征图。
第二层卷积:将 32 个特征图输入,提取 64 个特征图。
Flatten():将多维数据展平为一维,作为全连接层的输入。全连接层:两个线性层(
Linear),第一个线性层输出 128 个节点,第二个线性层输出 10 个节点,作为分类任务的 10 个类别。
forward()方法:定义了模型的前向传播过程,输入x经过卷积层处理后,展平并通过全连接层输出结果。
2. 数据加载(load_data 函数)
def load_data(iid=True, num_clients=10, batch_size=64):transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])# 加载MNIST数据集train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)num_train = len(train_dataset)indices = list(range(num_train))random.shuffle(indices)# IID分配client_indices = []base = 0for i in range(num_clients):size = num_train // num_clientsif i == num_clients - 1:size = num_train - baseclient_indices.append(indices[base:base + size])base += size# 非IID分配:每个客户端选择不同的数字类别进行训练if not iid:class_indices = {i: [] for i in range(10)}for idx, (_, label) in enumerate(train_dataset):class_indices[label].append(idx)client_indices = [[] for _ in range(num_clients)]for client_id in range(num_clients):for digit in range(10):client_indices[client_id].extend(class_indices[digit][client_id::num_clients])# 为每个客户端创建数据加载器client_loaders = []for client_data in client_indices:client_loaders.append(DataLoader(Subset(train_dataset, client_data), batch_size=batch_size, shuffle=True))return client_loaders, DataLoader(test_dataset, batch_size=batch_size, shuffle=False)load_data函数:该函数用于加载MNIST数据集并将数据分配到客户端。数据预处理:使用
transforms.Compose()对数据进行标准化(将每个像素点除以0.3081,并减去0.1307,这两个参数是 MNIST 数据集的均值和标准差)。IID分配:将训练数据集均匀地分配给多个客户端。每个客户端的训练数据量相同。
非IID分配:如果
iid=False,则每个客户端会拥有不同的数字类别。通过按类别划分数据来实现非IID分配。class_indices按类别将数据分组,之后每个客户端将收到一个不同类别的数据。返回:该函数返回每个客户端的数据加载器
client_loaders和一个全局的测试数据加载器test_loader。
3. 训练函数(train_model 函数)
def train_model(model, dataloader, epochs=2, lr=0.01, device='cpu'):
model.to(device)
model.train()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=lr)
for epoch in range(epochs):
total_loss = 0.0
total = 0
correct = 0
for data, target in dataloader:
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
total_loss += loss.item() * data.size(0)
_, pred = torch.max(output, 1)
correct += (pred == target).sum().item()
total += data.size(0)
return model.state_dict(), correct / total # 返回模型的参数和准确率
train_model函数:该函数用于训练模型,使用交叉熵损失函数(CrossEntropyLoss)和随机梯度下降(SGD)优化器。设备选择:将模型和数据移到指定的设备(CPU 或 GPU)。
模型训练:每个训练轮次(
epochs)中,模型通过反向传播和优化器更新参数。损失计算和优化:使用
loss.backward()进行反向传播,计算梯度,然后使用optimizer.step()更新模型参数。返回:返回训练后的 模型权重(
state_dict) 和 准确率。
4、潜在改进
数据增强:在
load_data中可以加入数据增强来提高模型的泛化能力。优化器选择:可以尝试其他优化器(如 Adam)来加速训练。
学习率调整:在训练过程中,使用学习率衰减策略(如
StepLR)来动态调整学习率。
这段代码只是联邦学习客户端部分的基础,可以在此基础上进一步扩展,例如加入模型聚合、增加安全性(如差分隐私)、处理更多类型的数据等。
5、运行结果
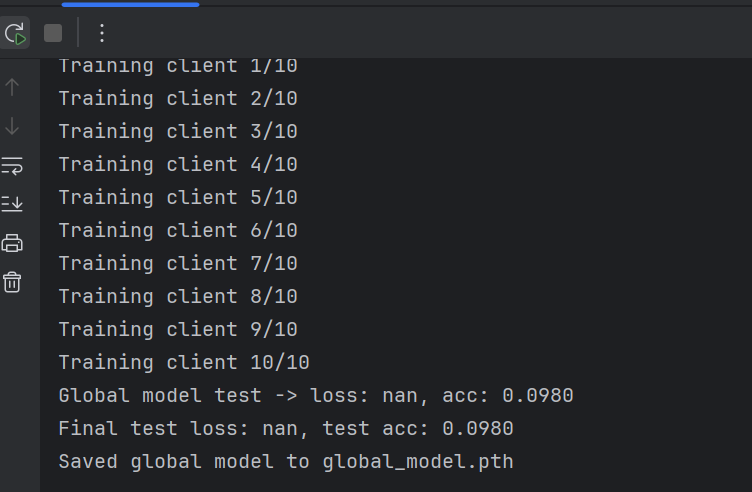
6、结果分析
loss: nan和test acc: 0.0980:损失(loss)为NaN表示训练过程中出现了数值不稳定的问题,而准确率为0.0980可能是由于模型无法正常学习,表现得和随机猜测一样。NaN损失:通常是由以下原因引起的:学习率过高:学习率过高会导致参数更新过大,从而导致训练不稳定,最终使损失变为
NaN。梯度爆炸:如果梯度过大,会导致参数更新过大,最终使损失变为
NaN。数据问题:训练数据中可能存在异常值或
NaN,这些数据会导致训练时的损失计算出错。模型初始化问题:模型的初始化可能导致参数更新过大或不稳定,尤其是在深度神经网络中。
解决方案
降低学习率:
通过减小学习率,避免过大的梯度更新,确保训练过程更加稳定。你可以尝试将学习率从0.01降低到0.001或更小的值。optimizer = optim.SGD(model.parameters(), lr=0.001) # 尝试将学习率设置为 0.001梯度裁剪:
使用 梯度裁剪(gradient clipping) 来限制梯度的大小,防止梯度爆炸问题。可以通过torch.nn.utils.clip_grad_norm_来裁剪梯度。torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0) # 限制梯度的最大范数检查数据:
确保数据集没有异常值或者NaN,可以通过检查数据的范围和类型来排查问题。你也可以添加一些数据预处理步骤来确保数据的质量。初始化:
如果问题出现在模型初始化阶段,可以使用合适的初始化方法。比如,对于全连接层和卷积层,PyTorch 提供了nn.init来帮助初始化权重。调试训练损失:
你可以在训练过程中输出每一步的损失,查看损失变为NaN的具体步骤:print(f"Loss at step {step}: {loss.item()}")调试输出:
增加一些调试输出,帮助追踪模型训练的状态。例如,可以打印训练时的最大梯度,看看是否有异常。for param in model.parameters():
print(param.grad.max()) # 输出每一轮训练的最大梯度