跨越符号的鸿沟——认知语义学对人工智能自然语言处理的影响与启示
摘要
进入2025年,以Transformer架构为基础的大型语言模型(LLMs)在自然语言处理(NLP)领域取得了前所未有的成就,展现出强大的文本生成与理解能力 。然而,尽管这些模型在诸多基准测试中超越了人类水平 一个根本性的挑战依然存在:它们是否真正“理解”了语言?当前主流的NLP模型在处理需要深层常识、语境推理、隐喻和意图理解的任务时,仍然暴露出其“语义鸿沟”(semantic gap)。本报告旨在深入探讨认知语义学(Cognitive Semantics)作为连接人类认知与机器智能的桥梁,如何为解决当前NLP的深层挑战提供理论基础、实践启示以及未来的发展方向。报告将系统性地梳理认知语义学的核心原则,分析其对NLP产生的理论影响与间接贡献,探讨其在具体模型中的应用现状与挑战,并展望二者深度融合的未来路径。
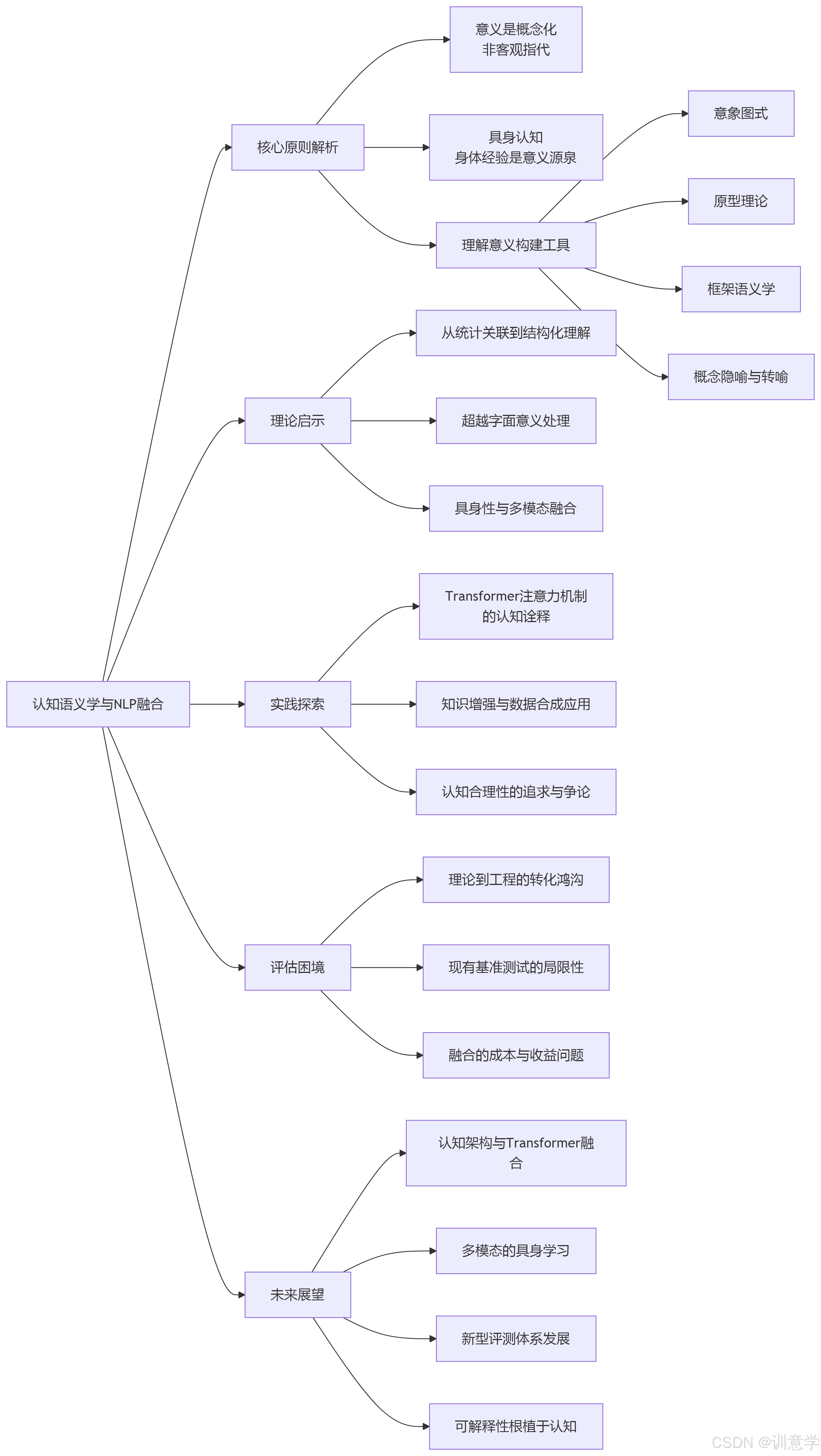
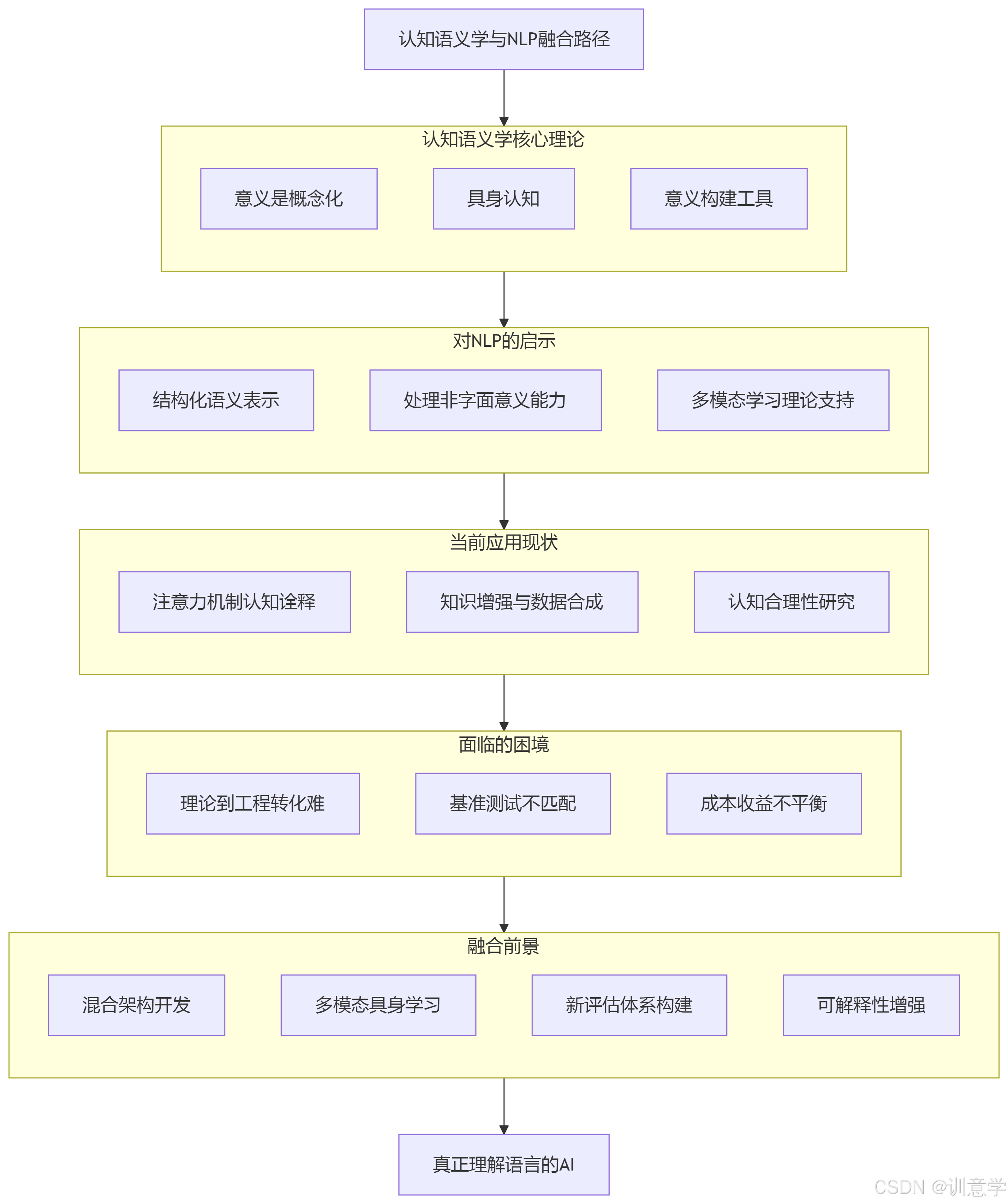
1. 认知语义学核心原则解析:重塑我们对“意义”的理解
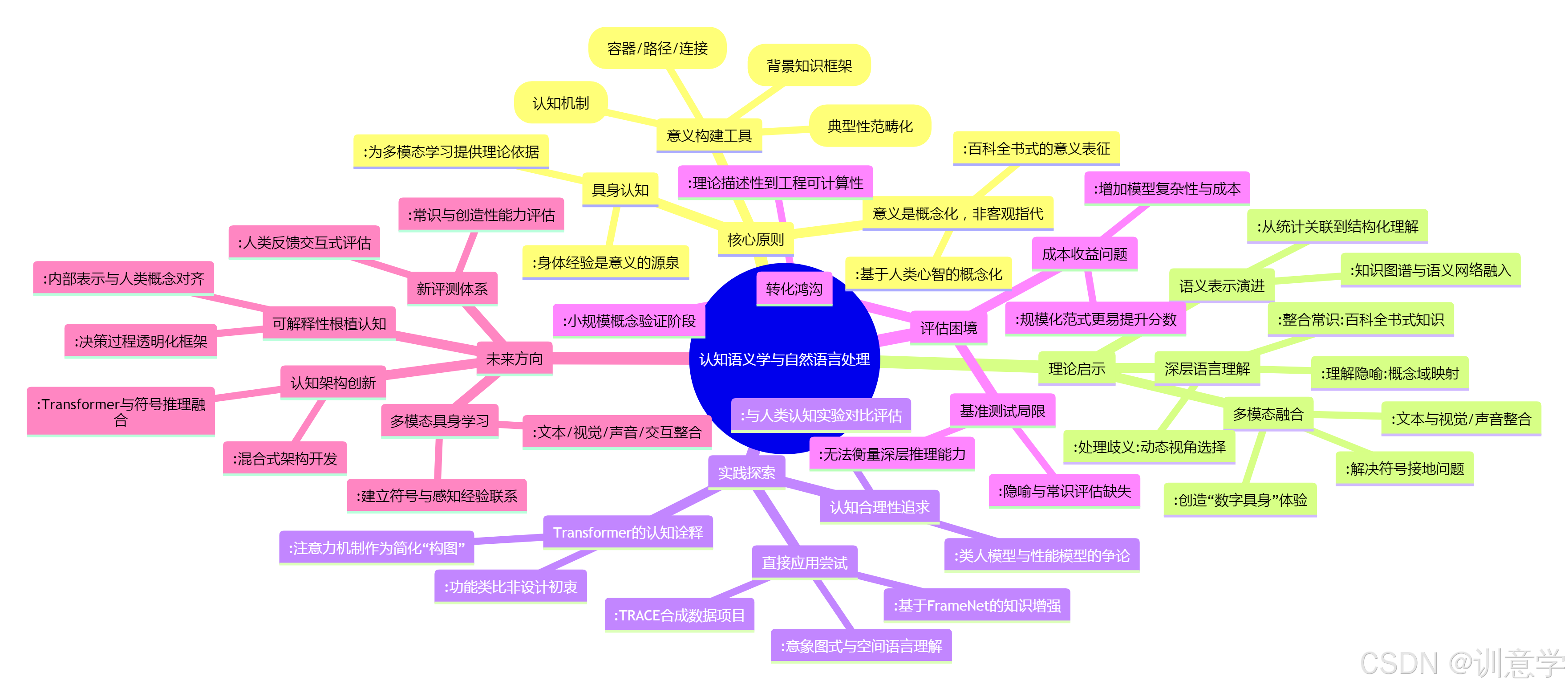
认知语义学是认知语言学的一个核心分支,它从根本上挑战了传统形式语义学中“意义是客观指代”的观点。它认为,语言意义并非世界事实的直接映射,而是人类心智基于身体经验和文化环境进行概念化(conceptualization)的产物 。这一视角为我们理解语言的本质提供了全新的框架。
1.1 意义是概念化,而非客观指代
认知语义学的基石性观点是“语义结构即概念结构”(semantic structure is conceptual structure)。这意味着词语和句子指向的不是外部世界的实体或真相,而是我们头脑中构建的概念。例如,“杯子”这个词的意义不仅是其物理属性的集合,更是一个包含了其功能(喝水)、使用场景(厨房、办公室)和相关动作(拿起、放下)的概念复合体。这种“百科全书式”的意义表征(meaning representation is encyclopedic)认为,我们对一个词的理解调用了与之相关的庞大知识网络,而非一个孤立的、最小化的词典定义 。
1.2 具身认知:身体经验是意义的源泉
认知语义学强调“概念结构是具身的”(embodied cognition)。我们的抽象思维和语言结构根植于我们的身体经验——我们的空间感、运动模式以及与物理世界的互动。这一原则为理解抽象概念的来源提供了关键线索。例如,我们通过身体的经验理解了“上”和“下”,进而将其隐喻性地应用到“情绪高涨/低落”、“地位高/低”等抽象领域 。这种将语言理解与感知和运动系统联系起来的观点,为NLP领域的多模态学习提供了深刻的理论依据 。
1.3 理解意义构建的核心工具
为了解释意义是如何被动态构建(construal)的,认知语义学提出了一系列分析工具:
意象图式 (Image Schemas): 这是从我们与世界反复的身体互动中抽象出的、前语言的认知结构,如“容器”(CONTAINER)、“路径”(SOURCE-PATH-GOAL)、“连接”(LINK)等 。例如,我们理解“陷入麻烦”或“走出困境”正是应用了“容器”图式,将“麻烦”和“困境”概念化为一个可以进入或离开的空间 。
原型理论 (Prototype Theory): 这一理论认为,我们对概念的范畴化并非基于严格的边界和充分必要条件,而是围绕一个最典型的“原型”成员展开 。例如,“鸟”的范畴原型可能是麻雀或知更鸟,而企鹅和鸵鸟则是边缘成员。这解释了为何某些句子(如“知更鸟是鸟”)比其他句子(如“企鹅是鸟”)更容易被理解。
框架语义学 (Frame Semantics): 由Charles Fillmore提出,该理论认为词语的意义只有在其所激活的背景知识“框架”(frame)中才能被完全理解 。例如,要理解“买”或“卖”,我们必须激活一个包含买方、卖方、商品、货币等角色的“商业交易”框架。这一理论为NLP中的语义角色标注和情境理解提供了结构化的分析方法 。
概念隐喻与转喻 (Conceptual Metaphor and Metonymy): 认知语义学认为,隐喻和转喻不仅是修辞手法,更是我们认知世界的基本方式。我们通过将一个熟悉的概念域(源域)的结构映射到另一个抽象的概念域(目标域)来理解后者(例如,“辩论是战争”)。这为机器处理非字面语言提供了强大的理论武器。
2. 理论启示:认知语义学如何启发下一代NLP
认知语义学的理论原则虽然尚未在主流NLP模型中被系统性地实现,但它们为克服当前模型的局限性提供了深刻的启示,正引导着研究范式的演进。
2.1 从“统计关联”到“结构化理解”:对语义表示的启示
当前的词嵌入(word embeddings)和Transformer模型,本质上是通过大规模数据学习词语间的统计共现关系 。例如,Word2Vec能够发现“国王-男人+女人≈女王”这样的类比关系,这在某种程度上反映了概念结构 。然而,这种表示是扁平的、非结构化的。
认知语义学启发我们,更高级的语义表示应当是结构化的,能够体现概念的内部构成和概念间的关系网络 。框架语义学启示我们,可以构建包含角色和关系的表示,而不仅仅是单一的向量 。这推动了将知识图谱、语义网络等结构化知识融入语言模型的研究,旨在让模型不仅知道词语“相关”,更知道它们“如何相关”。
2.2 超越字面意义:处理歧义、隐喻和常识的蓝图
大型语言模型在处理字面文本上表现出色,但常在需要语境推理和世界知识的场景中失败。认知语义学为此提供了解决方案的蓝图:
- 处理歧义: 认知语义学的“构图”(construal)概念指出,同一场景可以从不同视角进行描述,从而产生不同意义 。这启发模型在理解时,应能动态地根据上下文选择最合适的视角或框架,而不是给出一个静态的、唯一的解释。
- 理解隐喻: 概念隐喻理论为机器系统化地理解和生成隐喻提供了可能。通过建立源域和目标域之间的映射规则,模型或许可以像人一样理解“我的律师是头鲨鱼”这类非字面表达。
- 整合常识: 认知语义学认为意义是“百科全书式”的,这强调了背景知识的重要性。这为NLP模型为何需要整合庞大的常识知识库提供了理论支撑,并指明了整合的方向——知识应围绕人类的基本经验(如意象图式)和生活场景(如框架)来组织。
2.3 具身性与多模态学习的理论融合
认知语义学的“具身认知”原则与当前NLP领域兴起的多模态学习趋势不谋而合。研究人员开始探索将文本与图像、视频、声音等信息结合起来训练模型 。这可以被看作是为AI创造一种“数字身体”,让其通过多样的“感官”输入来“体验”世界,从而将语言符号“锚定”(grounding)在非语言的经验上。例如,通过同时看到“猫”的图片和读到“猫”的文本,模型对“猫”的概念理解会更加丰富和扎实,这与人类通过视觉、听觉、触觉形成概念的过程形成了呼应 。
3. 实践探索:认知语义学在NLP模型中的应用现状
尽管认知语义学的许多思想仍停留在理论层面,但已有研究开始探索将其原则融入实际的NLP模型中。然而,这种融合是初步的、间接的,并且面临着巨大的挑战。
3.1 间接的体现:Transformer注意力机制的认知诠释
Transformer模型的核心是自注意力机制(self-attention mechanism),它允许模型在处理一个词时,动态地评估序列中所有其他词的重要性并分配不同的权重 。从认知语义学的角度看,这可以被视为一种简化的“构图”或“焦点”机制。当模型为句子中的不同部分分配不同注意力权重时,它实际上是在根据任务需求,突出概念场景的某些方面而忽略其他方面,这与人类在理解语言时将注意力聚焦于特定语义角色的过程有相似之处 。然而,必须强调,这种相似性是功能上的类比,而非设计的初衷。Transformer的学习过程完全是数据驱动的,并未明确编码任何认知原则。
3.2 初步的直接应用:知识增强与数据合成
一些前沿研究正尝试更直接地应用认知语义学概念:
- 基于框架语义学的知识增强: 研究人员利用FrameNet等框架语义学资源,来增强模型的语义角色标注能力。例如,通过将FrameNet的框架结构作为一种先验知识注入模型,或用于生成带有丰富语义标注的训练数据,可以提升模型对句子谓词-论元结构的理解 。一个名为“TRACE”的项目就探索了通过合成数据来训练Transformer,这些数据精确控制了框架语义学的相关变量 。
- 意象图式与空间语言理解: 在处理空间介词(如“in”, “on”, “over”)等模糊性极高的语言现象时,研究者开始尝试引入意象图式的拓扑结构。通过将介词的意义建模为几何或拓扑关系,而非离散的符号,模型有望更好地泛化到新的空间描述中。然而,将抽象的意象图式转化为可计算的特征,仍然是一个开放的研究课题 。
3.3 “认知合理性”的追求与争论
一个新兴的研究方向是评估模型的“认知合理性”(cognitive plausibility),即模型的内部处理过程或其行为模式是否与人类认知实验的结果相符 。例如,研究者会比较模型对歧义句的解读偏好、阅读时间预测等是否与人类一致。这种研究不仅旨在提升模型性能,更希望通过构建更类人的模型来反哺对人类认知过程的理解 。但这也引发了争论:NLP的目标究竟是最大化任务性能,还是模拟人类智能?在许多情况下,最“类人”的模型并不一定是在特定基准测试上得分最高的模型 。
4. 评估的困境:为何缺乏直接的基准测试证据?
在对大量搜索结果进行分析后,一个显著的发现是:几乎没有公开的、标准化的基准测试结果(如GLUE, SQuAD, BLEU)能够直接证明“认知语义学增强的NLP模型”相较于标准模型有稳定的性能提升 。造成这一“证据缺口”的原因是多方面的:
理论到工程的转化鸿沟: 认知语义学的原则大多是描述性的、高度抽象的。如何将“具身性”、“意象图式”或“概念隐喻”等理论转化为可以在神经网络中进行端到端训练的、可微的数学运算,是一个巨大的工程挑战。这导致许多研究仍停留在小规模的概念验证阶段。
现有基准测试的局限性: 当前主流的NLP基准测试(如SQuAD的阅读理解,GLUE的语言理解套件,BLEU的机器翻译评分)更多地是在评估模型的信息检索、模式匹配和文本流畅度 。它们往往无法有效衡量深层的常识推理、隐喻理解或创造性语言使用能力。一个在认知上更合理的模型,可能在处理微妙的语境和非字面意义上更强,但这些优势在现有评测体系中可能无法转化为分数上的显著提升 。
融合的成本与收益问题: 引入外部的认知知识或复杂的结构化表示,通常会增加模型的复杂性、训练成本和推理时间。在当前“规模为王”(scaling laws)的范式下,通过简单地增加模型参数和数据量往往能更直接地提升基准分数,这使得投入资源进行复杂的认知理论融合显得“性价比”不高 。
5. 未来展望与研究方向:构建真正“理解”语言的AI
尽管面临诸多挑战,认知语义学为通向更鲁棒、更通用、更类人的自然语言处理指明了方向。未来的研究可以从以下几个方面展开:
5.1 认知架构与Transformer的深度融合
未来的模型架构可能会超越纯粹的Transformer,走向一种混合式架构(Hybrid Architecture)。这种架构将结合Transformer强大的序列建模能力和基于认知理论的符号推理模块(如知识图谱、逻辑引擎)。例如,模型可以利用Transformer进行初步的语义解析,然后调用一个基于框架语义学的符号模块进行深层的情境推理和角色关系分析。
5.2 从海量文本到多模态的“具身”学习
未来的NLP训练将更加强调多模态数据的整合,以实现“数字具身”。模型将在包含文本、视觉、声音甚至模拟物理交互的环境中进行学习,从而让语言符号与感知经验建立稳固的联系。这不仅能帮助模型掌握更丰富的概念知识,还有望解决符号接地(symbol grounding)这一人工智能的根本难题。
5.3 发展面向深度理解的新型评测体系
学术界和工业界需要共同开发新的基准和评测方法,以衡量模型在常识推理、比喻理解、价值判断、创造性等高级认知能力上的表现。这可能包括设计更具挑战性的对抗性测试集,或建立更依赖人类反馈的交互式评估框架 从而为认知增强型模型的研发提供正确的“指挥棒”。
5.4 将可解释性根植于认知
认知语义学为模型的可解释性(XAI)提供了天然的框架。我们可以尝试让模型的决策过程和内部表示与意象图式、语义框架等人类可理解的概念对齐。例如,当模型做出一个决策时,它不仅给出一个结果,还能解释它激活了哪个“框架”,并将输入句子的各个成分填充到了哪些“角色”中,从而使其“思考”过程透明化。
结论
认知语义学与人工智能自然语言处理的关系,正从单向的理论启示,迈向双向的融合与共建。虽然当前的技术主流仍由数据驱动的深度学习模型主导,但这些模型在通往通用人工智能的道路上已显现出其根本局限。认知语义学以其对人类语言和思维本质的深刻洞察,为我们描绘了下一代NLP技术的可能形态:它们将不再是只会模仿文本统计模式的“随机鹦鹉”,而是能够基于经验、理解语境、进行推理的、真正意义上的“语言使用者”。跨越当前符号处理的鸿沟,需要我们不仅在算力和数据上持续投入,更要在借鉴人类认知智慧的道路上,进行更为大胆和深入的探索。这正是认知语义学为人工智能领域带来的最宝贵的启示。