开始 ComfyUI 的 AI 绘图之旅-Flux.1图生图(八)
文章标题
- 一、Flux Kontext Dev
- 1.关于 FLUX.1 Kontext Dev
- 1.1 版本说明
- 1.2 工作流说明
- 1.3 模型下载
- 2.Flux.1 Kontext Dev 工作流
- 2.1 工作流及输入图片下载
- 2.2 按步骤完成工作流的运行
- 3.Flux Kontext 提示词技巧
- 3.1 基础修改
- 3.2 风格转换
- 3.3 角色一致性
- 3.4 文本编辑
- 4.常见问题解决
- 4.1 角色变化过大
- 4.2 构图位置改变
- 4.3 风格应用不准确
- 5.核心原则
- 6.最佳实践模板
- 二、字节跳动 USO
- 1.字节跳动 USO ComfyUI 原生工作流
- 1.1 工作流和输入
- 1.2 模型链接
- 1.3 工作流说明
- 1.4 补充说明
一、Flux Kontext Dev
ComfyUI Flux Kontext Dev 原生工作流示例。
1.关于 FLUX.1 Kontext Dev
FLUX.1 Kontext 是 Black Forest Labs 推出的突破性多模态图像编辑模型,支持文本和图像同时输入,能够智能理解图像上下文并执行精确编辑。其开发版是一个拥有 120 亿参数的开源扩散变压器模型,具有出色的上下文理解能力和角色一致性保持,即使经过多次迭代编辑,也能确保人物特征、构图布局等关键元素保持稳定。
与 FLUX.1 Kontext 套件具备相同的核心能力:
角色一致性:在多个场景和环境中保留图像的独特元素,例如图片中的参考角色或物体。
局部编辑:对图像中的特定元素进行有针对性的修改,而不影响其他部分。
风格参考:根据文本提示,在保留参考图像独特风格的同时生成新颖场景。
交互速度:图像生成和编辑的延迟极小。
虽然之前发布的 API 版本提供了最高的保真度和速度,但 FLUX.1 Kontext [Dev] 完全在本地机器上运行,为希望进行实验的开发者、研究人员和高级用户提供了无与伦比的灵活性。
1.1 版本说明
- [FLUX.1 Kontext [pro] - 商业版本,专注快速迭代编辑
- FLUX.1 Kontext [max] - 实验版本,更强的提示遵循能力
- FLUX.1 Kontext [dev] - 开源版本(本教程使用),12B参数,主要用于研究
目前在 ComfyUI 中,你可以使用所有的这些版本,其中 Pro 及 Max 版本 可以通过 API 节点来进行调用,而 Dev 版本开源版本请参考本篇指南中的说明。
1.2 工作流说明
目前在本篇教程中,我们涉及了两类工作流,本质上他们其实是相同的,
- 使用了组节点 FLUX.1 Kontext Image Edit 的工作流,使得整个界面和工作流复用起来变得简单
- 而另一个工作流没有使用组节点,是完整的原始工作流。
使用组节点的主要优点是工作流简洁,你可以复用组节点来实现复杂的工作流,快速复用节点组,另外在新版本的前端中,我们也为 Flux.1 Kontext Dev 增加了一个快速添加组节点的功能:
- ComfyUI 下载
- ComfyUI 更新教程
本指南里的工作流可以在 ComfyUI 的工作流模板中找到。如果找不到,可能是 ComfyUI 没有更新。
如果加载工作流时有节点缺失,可能原因有:
- 你用的不是最新开发版(nightly)。
- 你用的是稳定版或桌面版(没有包含最新的更新)。
- 启动时有些节点导入失败。
1.3 模型下载
为了使本篇指南的工作流能够顺利运行,你先需要下载下面的模型文件,你也可以直接加载对应工作流下直接获取模型的下载链接,对应的工作流已经包含了模型文件的下载信息。
Diffusion Model
- flux1-dev-kontext_fp8_scaled.safetensors
VAE
- ae.safetensors
Text Encoder
- clip_l.safetensors
- t5xxl_fp16.safetensors 或 t5xxl_fp8_e4m3fn_scaled.safetensors
安装aria2快速下载模型,几乎能将我家1000M的宽带跑满,每秒80~90M,接下来的介绍模型都会给出安装命令。
apt install aria2
aria2c https://huggingface.co/comfyanonymous/flux_text_encoders/resolve/main/t5xxl_fp8_e4m3fn_scaled.safetensors -o SourceCode/ComfyUI/models/text_encoders/t5xxl_fp8_e4m3fn_scaled.safetensors auto-file-renaming=false --allow-overwrite=falsearia2c https://huggingface.co/Comfy-Org/flux1-kontext-dev_ComfyUI/resolve/main/split_files/diffusion_models/flux1-dev-kontext_fp8_scaled.safetensors -o SourceCode/ComfyUI/models/diffusion_models/flux1-dev-kontext_fp8_scaled.safetensors auto-file-renaming=false --allow-overwrite=false
小技巧:你要是打不开https://huggingface.co,可以将其换成为https://hf-mirror.com/试一试
模型保存位置
📂 ComfyUI/
├── 📂 models/
│ ├── 📂 diffusion_models/
│ │ └── flux1-dev-kontext_fp8_scaled.safetensors
│ ├── 📂 vae/
│ │ └── ae.safetensor
│ └── 📂 text_encoders/
│ ├── clip_l.safetensors
│ └── t5xxl_fp16.safetensors 或者 t5xxl_fp8_e4m3fn_scaled.safetensors
2.Flux.1 Kontext Dev 工作流
这个工作流是正常的工作流,不过使用了 Load Image(from output) 节点来加载需要编辑的图像可以让你更方便地获取到编辑后的图像,从而进行多轮次编辑
2.1 工作流及输入图片下载
下载下面的文件,并拖入 ComfyUI 中加载对应工作流
输入图片

2.2 按步骤完成工作流的运行
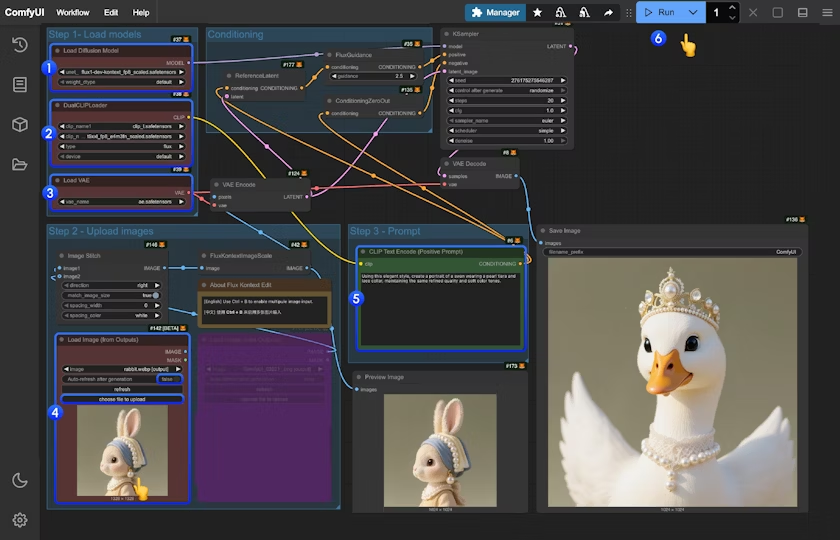
你可参考图片中的序号来完成图工作流的运行:
- 在
Load Diffusion Model节点中加载flux1-dev-kontext_fp8_scaled.safetensors模型 - 在
DualCLIP Load节点中确保:clip_l.safetensors及t5xxl_fp16.safetensors或t5xxl_fp8_e4m3fn_scaled.safetensors已经加载 - 在
Load VAE节点中确保加载ae.safetensors模型 - 在
Load Image(from output)节点中加载提供的输入图像 - 在
CLIP Text Encode节点中修改提示词,仅支持英文 - 点击
Queue按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来运行工作流

3.Flux Kontext 提示词技巧
3.1 基础修改
- 简单直接:
"Change the car color to red" - 保持风格:
"Change to daytime while maintaining the same style of the painting"
3.2 风格转换
原则:
- 明确命名风格:
"Transform to Bauhaus art style" - 描述特征:
"Transform to oil painting with visible brushstrokes, thick paint texture" - 保留构图:
"Change to Bauhaus style while maintaining the original composition"
3.3 角色一致性
框架:
- 具体描述:
"The woman with short black hair"而非"she" - 保留特征:
"while maintaining the same facial features, hairstyle, and expression" - 分步修改:先改背景,再改动作
3.4 文本编辑
- 使用引号:
"Replace 'joy' with 'BFL'" - 保持格式:
"Replace text while maintaining the same font style"
4.常见问题解决
4.1 角色变化过大
❌ 错误:"Transform the person into a Viking"
✅ 正确:"Change the clothes to be a viking warrior while preserving facial features"
4.2 构图位置改变
❌ 错误:"Put him on a beach"
✅ 正确:"Change the background to a beach while keeping the person in the exact same position, scale, and pose"
4.3 风格应用不准确
❌ 错误:"Make it a sketch"
✅ 正确:"Convert to pencil sketch with natural graphite lines, cross-hatching, and visible paper texture"
5.核心原则
- 具体明确 - 使用精确描述,避免模糊词汇
- 分步编辑 - 复杂修改分为多个简单步骤
- 明确保留 - 说明哪些要保持不变
- 动词选择 - 用"change"、“replace"而非"transform”
6.最佳实践模板
对象修改:
"Change [object] to [new state], keep [content to preserve] unchanged"
风格转换:
"Transform to [specific style], while maintaining [composition/character/other] unchanged"
背景替换:
"Change the background to [new background], keep the subject in the exact same position and pose"
文本编辑:
"Replace '[original text]' with '[new text]', maintain the same font style"
记住: 越具体越好,Kontext 擅长理解详细指令并保持一致性。
二、字节跳动 USO
使用字节跳动 USO 模型实现统一风格和主体驱动生成
USO (Unified Style-Subject Optimized) 是字节跳动 UXO 团队开发的模型,统一了风格驱动和主体驱动生成任务。
基于 FLUX.1-dev 架构构建,该模型通过解耦学习和风格奖励学习 (SRL) 实现了风格相似性和主体一致性。
USO 支持三种主要方法:
- 主体驱动:将主体放置到新场景中,同时保持身份一致性
- 风格驱动:基于参考图像将艺术风格应用于新内容
- 组合模式:同时使用主体和风格参考
相关链接
- 项目主页
- GitHub
- 模型权重
1.字节跳动 USO ComfyUI 原生工作流
请确保你的 ComfyUI 已经更新。- ComfyUI 下载
- ComfyUI 更新教程
本指南里的工作流可以在 ComfyUI 的工作流模板中找到。如果找不到,可能是 ComfyUI 没有更新。
如果加载工作流时有节点缺失,可能原因有:
- 你用的不是最新开发版(nightly)。
- 你用的是稳定版或桌面版(没有包含最新的更新)。
- 启动时有些节点导入失败。
1.1 工作流和输入
下载下方图像并拖拽到 ComfyUI 中以加载对应的工作流。
使用下面的图片作为输入

1.2 模型链接
checkpoints
- flux1-dev-fp8.safetensors
loras
- uso-flux1-dit-lora-v1.safetensors
model_patches
- uso-flux1-projector-v1.safetensors
clip_visions
- sigclip_vision_patch14_384.safetensors
安装aria2快速下载模型,几乎能将我家1000M的宽带跑满,每秒80~90M,接下来的介绍模型都会给出安装命令。
apt install aria2
aria2c https://huggingface.co/Comfy-Org/USO_1.0_Repackaged/resolve/main/split_files/loras/uso-flux1-dit-lora-v1.safetensors -o SourceCode/ComfyUI/models/loras/uso-flux1-dit-lora-v1.safetensors --auto-file-renaming=false --allow-overwrite=falsearia2c https://huggingface.co/Comfy-Org/USO_1.0_Repackaged/resolve/main/split_files/model_patches/uso-flux1-projector-v1.safetensors -o SourceCode/ComfyUI/models/model_patches/uso-flux1-projector-v1.safetensors --auto-file-renaming=false --allow-overwrite=falsearia2c https://huggingface.co/Comfy-Org/sigclip_vision_384/resolve/main/sigclip_vision_patch14_384.safetensors -o SourceCode/ComfyUI/models/clip_vision/sigclip_vision_patch14_384.safetensors --auto-file-renaming=false --allow-overwrite=false
小技巧:你要是打不开https://huggingface.co,可以将其换成为https://hf-mirror.com/试一试
请下载所有模型并将它们放置在以下目录中:
📂 ComfyUI/
├── 📂 models/
│ ├── 📂 checkpoints/
│ │ └── flux1-dev-fp8.safetensors
│ ├── 📂 loras/
│ │ └── uso-flux1-dit-lora-v1.safetensors
│ ├── 📂 model_patches/
│ │ └── uso-flux1-projector-v1.safetensors
│ ├── 📂 clip_visions/
│ │ └── sigclip_vision_patch14_384.safetensors
1.3 工作流说明
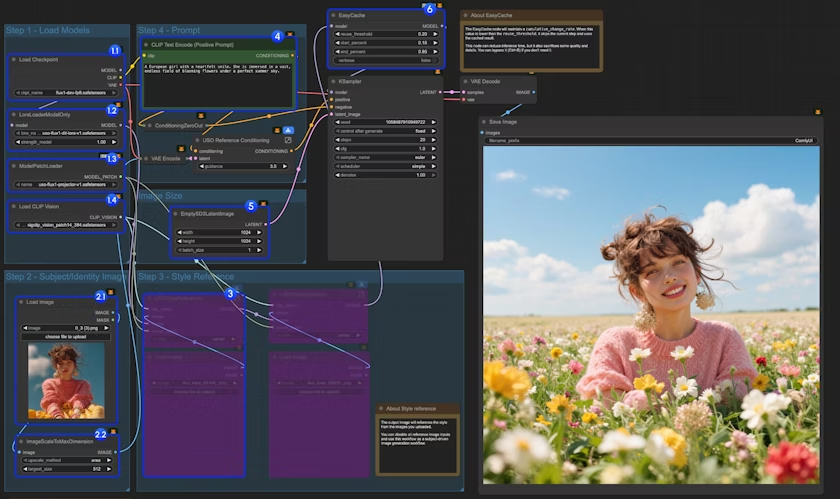
-
加载模型:
- 1.1 确保
Load Checkpoint节点已加载flux1-dev-fp8.safetensors - 1.2 确保
LoraLoaderModelOnly节点已加载dit_lora.safetensors - 1.3 确保
ModelPatchLoader节点已加载projector.safetensors - 1.4 确保
Load CLIP Vision节点已加载sigclip_vision_patch14_384.safetensors
- 1.1 确保
-
上传图像:
- 2.1 点击
Upload上传我们提供的输入图像 - 2.2
ImageScaleToMaxDimension节点将会缩放你的输入图像用于内容参考,512px 会保留更多的角色特征,但如果你仅使用角色头部作为输入,最终输出图像往往会有角色占据太多空间的问题(或者结果很糟)。设置为 1024px 会得到更好的结果。
- 2.1 点击
-
在示例中,我们只使用
content reference图像输入。如果你想使用style reference图像输入,可以使用Ctrl+B绕过标记的节点组。 -
编写你的提示词或保持默认设置
-
如果需要调整输出图像尺寸
-
EasyCache 节点用于推理加速,但也会牺牲一些质量和细节。如果不需要使用,可以用
Ctrl+B绕过它。 -
点击
Run按钮,或使用快捷键Ctrl(Cmd) + Enter运行工作流
1.4 补充说明
- 仅使用风格参考:
我们在同一个工作流中也提供了仅使用风格参考的版本
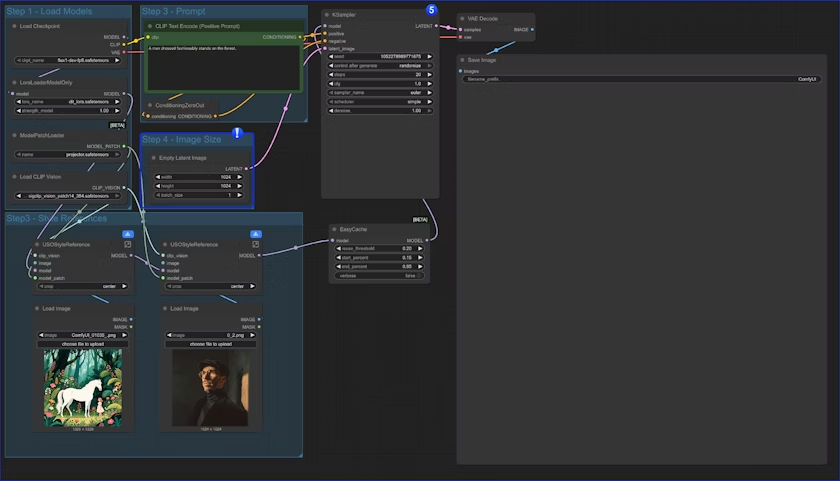
唯一的区别是我们替换了 content reference 节点,仅使用 Empty Latent Image 节点来创建一个我们需要的图像大小
- 你也可以 绕过(Ctrl+B) 整个
Style Reference组,将工作流用作文本到图像的工作流,也就是这个文本存在 4 个变体
- 仅使用内容(主体)参考
- 仅使用风格参考
- 混合内容及风格参考
- 作为文生图工作流