Spark+Hive中间件
Spark
Spark入门教程(非常详细)从零基础入门到精通,看完这一篇就够了-CSDN博客
基础
Spark是用来代替Hadoop中的MapReduce,其存储依然用的是Hadoop,但中间结果可以存放在内存中。MapReduce仅支持Map+Reduce且不适合迭代计算、交互计算、实时流处理。
提出了RDD模型:容错并行的数据结构,运行用户将中间结果数据集保存在 内存 中,并且通过控制数据集的分区来达到数据存放处理最优化
| 类型 | Hadoop | Spark |
|---|---|---|
| 定位 | 分布式基础平台,包含计算、存储、调度 | 分布式计算工具 |
| 适用场景 | 大规模数据集上的批处理 | 迭代计算、交互式计算、流计算 |
| 成本 | 对机器要求低,便宜 | 对内存有要求,相对较贵 |
| 编程范式 | Map+Reduce, API 较为底层,算法适应性差 | RDD 组成 DAG 有向无环图,API 较为顶层,方便使用 |
| 数据存储结构 | 中间计算结果存在 HDFS 磁盘上,延迟大 | 中间运算结果存在内存中,延迟小 |
| 任务运行方式 | Task 以进程方式维护,任务启动慢 | Task 以线程方式维护,任务启动快 |
结构:Spark Core 核心计算框架、Spark SQL:结构化数据查询、Spark Streaming:实时流处理、Spark MLib机械学习、Spark GraphX:图计算
Sprak Core:RDD
(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据抽象,代表一个不可变、可分区、里面的元素可并行计算的集合。
创建方式:
- 外部存储系统的数据集创建
- 已有的RDD经过算子转化
- Scala集合创建
算子:
- Transformation 转化操作:返回一个新的RDD
- Action 动作操作:返回值并不是RDD
持久化:
persist方法或cache方法将计算结果缓存,这两种方法并不是调用会被立即缓存,而是会出触发action才会缓存。注意:通过查看 RDD 的源码发现 cache 最终也是调用了 persist 无参方法(默认存储只存在内存中):
存储级别:
- 默认:将RDD以非序列化的java对象存储在JVM中,如果没有足够内存,则某些分区不会被缓存
- MORY_AND_DISK:在默认条件下,将溢出的数据写入磁盘
- 将RDD以序列化的java对象存储
容错机制:重点
持久化局限性:将缓存放在内存,虽然快但数据容易丢失;放在磁盘也有可能损坏
容错机制就是未了解决上述问题,直接将数据放在HDFS里面。这样程序运行结束后,其处理的数据依然存在。持久化方法会删除。
依赖关系:
- 宽依赖:父 RDD 的一个分区只会被子 RDD 的一个分区依赖;必须等到上个阶段计算完成才能计算下一个阶段。
- 窄依赖:父 RDD 的一个分区会被子 RDD 的多个分区依赖(涉及到 shuffle);多个分区可以并行计算;分区数据丢失只需要重新计算就行。
DAG:有向无环图
数据转换执行的过程,有方向,无闭环(其实就是 RDD 执行的流程)
DAG 的边界:
- 开始:通过 SparkContext 创建的 RDD;
- 结束:触发 Action,一旦触发 Action 就形成了一个完整的 DAG
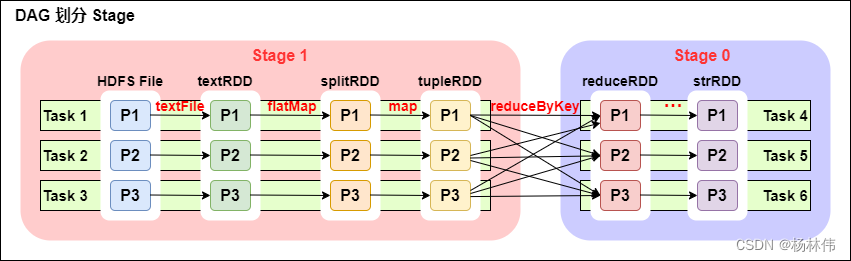
一个 Spark 程序可以有多个 DAG,一个 DAG 可以有多个 Stag,同一个 Stage 可以有多个 Task 并行执行,只 reduceByKey 操作是一个宽依赖,从 textFile 到 flatMap 到 map 都是窄依赖。
Spark SQL
Hive 是将 SQL 转为 MapReduce。
SparkSQL 可以理解成是将 SQL 解析成:“RDD + 优化” 再执行
数据分类:
- 结构化数据:有固定的schema、 如:表格
- 半结构化数据:无固定的schema,但有结构 如:文件格式JSON
- 非结构化数据:无固定的schema,无结构、如:图片音频
RDD 主要用于处理非结构化数据 、半结构化数据、结构化;
SparkSQL 主要用于处理结构化数据(较为规范的半结构化数据也可以处理)。
抽象数据:
| 特性 | Spark RDD | Spark DataFrame | Spark Dataset |
|---|---|---|---|
| 本质 | 弹性分布式数据集 | 基于 RDD 的分布式数据集合,按命名的列组织 | DataFrame API 的扩展,强类型 |
| 数据表示 | JVM 对象的集合 | Row 对象的集合(可理解为无类型的 JVM 对象) | 强类型 JVM 对象的集合(如 Dataset[Person]) |
| 序列化效率 | 较低(Java 序列化或 Kryo) | 高(Tungsten 二进制格式 + off-heap) | 高(同 DataFrame) |
| 优化方式 | 无,开发者需自行优化 | 有,Catalyst 查询优化器(逻辑/物理优化) | 有(同 DataFrame) |
| 执行效率 | 较低 | 高(Tungsten 优化执行引擎) | 高(同 DataFrame) |
| API | 函数式转换(map, filter, reduce) | 类似 SQL 的结构化操作(select, filter, groupBy) | 强类型 API + 类 DataFrame 的无类型 API |
Spark Streaming
基于 Spark Core 之上的实时计算框架,可以从很多数据源消费数据并对数据进行实时的处理,具有高吞吐量和容错能力强等
数据抽象:
DStream(Discretized Stream,离散化数据流,连续不断的数据流),代表持续性的数据流和经过各种 Spark 算子操作后的结果数据流。
① DStream 本质上就是一系列时间上连续的 RDD
② 对 DStream 的数据的进行操作也是按照 RDD 为单位来进行的
③ 容错性,底层 RDD 之间存在依赖关系,DStream 直接也有依赖关系,RDD 具有容错性,那么 DStream 也具有容错性。
总结: 简单来说 DStream 就是对 RDD 的封装,你对 DStream 进行操作,就是对 RDD 进行操作。对于 DataFrame/DataSet/DStream 来说本质上都可以理解成 RD
Structured Streaming
基于 Spark SQL 引擎的可扩展、容错的流处理引擎。统一了流、批的编程模型,你可以使用静态数据批处理一样的方式来编写流式计算操作。并且支持基于 event_time 的时间窗口的处理逻辑。
Spark 两种核心 Shuffle
在 MapReduce 框架中,Shuffle 阶段是连接 Map 与 Reduce 之间的桥梁, Map 阶段通过 Shuffle 过程将数据输出到 Reduce 阶段中。由于 Shuffle 涉及磁盘的读写和网络 I/O,因此 Shuffle 性能的高低直接影响整个程序的性能。Spark 也有 Map 阶段和 Reduce 阶段,因此也会出现Shuffle。
Hash Shuffle
Sort Shuffle
Spark 底层执行原理
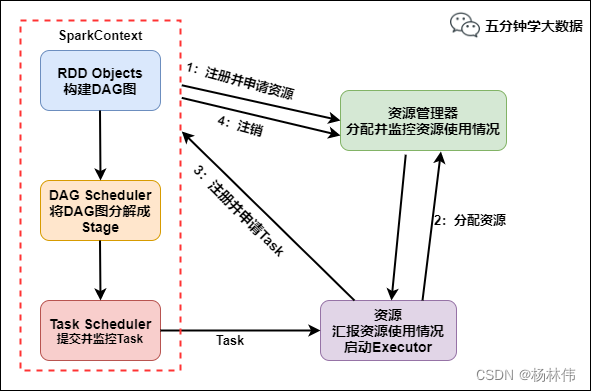
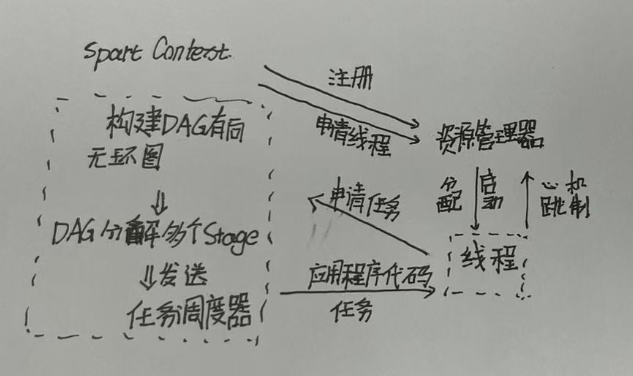
申请资源
- SparkContext 向资源管理器注册并向资源管理器申请运行 Executor线程
- 资源管理器分配 Executor,然后资源管理器启动 Executor
- Executor 发送心跳至资源管理器
任务调度和执行
- SparkContext 构建 DAG 有向无环图
- 将 DAG 分解成 Stage(TaskSet)
- 把 Stage 发送给 TaskScheduler任务调度器
- Executor 向 SparkContext 申请 Task
- TaskScheduler 将 Task 发送给 Executor 运行
- 同时 SparkContext 将应用程序代码发放给 Executor
- Task 在 Executor 上运行,运行完毕释放所有资源
提问
1. 讲讲spark的数据倾斜
主要是在shuffle阶段,某个或某几个分区的数据量远远超过其他分区,导致“少数几个Task干活特别慢,拖慢了整个Stage甚至整个作业”的现象。其本质是数据分布不均。
| 产生原因 | 典型场景 | 解决方案 |
|---|---|---|
| Key 分布不均 | reduceByKey / groupByKey 某些 key 特别大 | - Key 加盐(Salting) 打散大 key- 抽取热点 key 单独处理- 自定义分区器 |
| 数据热点(业务本身不均) | 日志类数据:某个用户/商品访问量特别高 | - map 端局部聚合(combineByKey)减少 shuffle- 广播小表(broadcast join)替代 reduce-side join |
| 算子使用不当 | 使用 groupByKey 导致所有数据拉到 reduce 端 | - 改为 reduceByKey(map 端预聚合)- 使用 aggregateByKey、combineByKey |
| 分区器设计不合理 | 默认 HashPartitioner 导致分布不均 | - 自定义分区器,按业务字段规则分区- 增加 spark.sql.shuffle.partitions 并行度 |
| 单点热点数据过大 | 某些 key 的数据量占比极大(如超过 50%) | - 单独抽取该 key 走独立逻辑- 其他数据正常走 shuffle |
常见原因:
1、key分布不均匀:某些 key 的数据量远大于其他 key,导致部分 task 处理数据过多,运行时间远超其他 task。
2、数据热点:数据本身分布不均匀,大部分落在同一个分区,造成执行缓慢
3、业务逻辑导致单点放大:groupByKey 会把相同 key 的数据收集到同一个 reducer,导致内存溢出或 OOM
4、分区器设计不合理
解决方案
1、数据预处理:剔除异常key,并在map端进行combineByKey或reduceByKey聚合,减少shuffle数据量
2、调优算子选择:将groupByKey改为reduceByKey,因为groupByKey会将所有数据拉到内存,而 reduceByKey 在 map 端可预聚合,减少网络 IO 和数据倾斜风险。
3、Key 加盐:给热点 key 人为拼接随机前缀,把大 key 拆散成多个小 key,打散后在 reduce 阶段再聚合。
4、自定义分区器:根据 key 的实际分布规律,设计自定义 Partitioner,避免数据集中到某一个分区。
5、任务参数调优:增加并行度:提高 spark.sql.shuffle.partitions(默认 200),让 shuffle 后的 task 更多,数据更均匀。调大资源配置:提高 executor 内存、core 数,缓解单 task 负载。
6、拆分热点任务:对于某些极端热点 key,可以单独抽取出来单独处理,其余数据正常 shuffle
2. 讲讲spark的宽窄依赖
窄依赖(Narrow Dependency)
定义
- 子 RDD 的每个分区只依赖于父 RDD 的一个或少量分区。
- 不涉及全量数据的重新分布,数据依赖关系是局部的。
特点
- 数据本地性好:数据只需要在父分区和子分区之间传递,不会发生大量的网络 IO。
- 可以流水式计算:父 RDD 分区算完直接传递给子 RDD,task 可以 pipeline 化执行。
- 执行效率高。
宽依赖
定义
- 子 RDD 的一个分区依赖于父 RDD 的多个分区。
- 涉及数据的 shuffle,需要跨节点数据传输和重新分区。
特点
- 会触发 shuffle:需要将父 RDD 的数据按照 key 或分区规则重新分布。
- 存在网络 IO 和磁盘 IO,性能开销大。
- 会产生 stage 划分:DAG 会在宽依赖处切分 stage。
Hive
4. 讲讲hive的内部表外部表
udf udaf udtf核心区别总结
| 特性 | UDF | UDAF | UDTF |
|---|---|---|---|
| 全称 | 用户自定义函数 | 用户自定义聚合函数 | 用户自定义表生成函数 |
| 输入输出关系 | 一行进,一行出 | 多行进,一行出 | 一行进,多行出 |
| 功能类比 | 类似于 SQL 中的普通函数 | 类似于 SQL 中的聚合函数 | 类似于 SQL 中的 EXPLODE() 函数 |
| 常见场景 | 数据格式化、字段拼接、大小写转换、计算等 | 求和、求平均、求最大值、计数、Top N 等 | 解析JSON数组、Map键值对展开、一行拆多行 |
| 继承类 | org.apache.hadoop.hive.ql.exec.UDF | org.apache.hadoop.hive.ql.exec.UDAF | org.apache.hadoop.hive.ql.udf.generic.GenericUDTF |
| 开发难度 | 简单 | 复杂 | 中等 |
数仓
模型
层级