【LLM】Transformer注意力机制全解析:MHA到MLA
Transformer架构彻底革新了自然语言处理(NLP)领域,推动诞生了BERT、GPT等突破性模型及其后续演进。其中,注意力机制作为Transformer的核心组件,赋予模型聚焦输入关键信息的能力,显著提升了预测准确性。
我们已经进行了各种优化,在本文中我们将介绍各种注意力机制 — MHA、MQA、GQA 和 MLA。
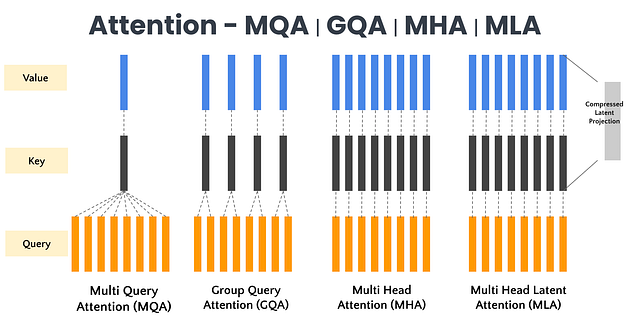
一、 多头注意力机制(MHA)
多头注意力机制采用独立的查询、键和值矩阵进行计算,虽然增加了计算和内存消耗,但显著提升了模型性能。
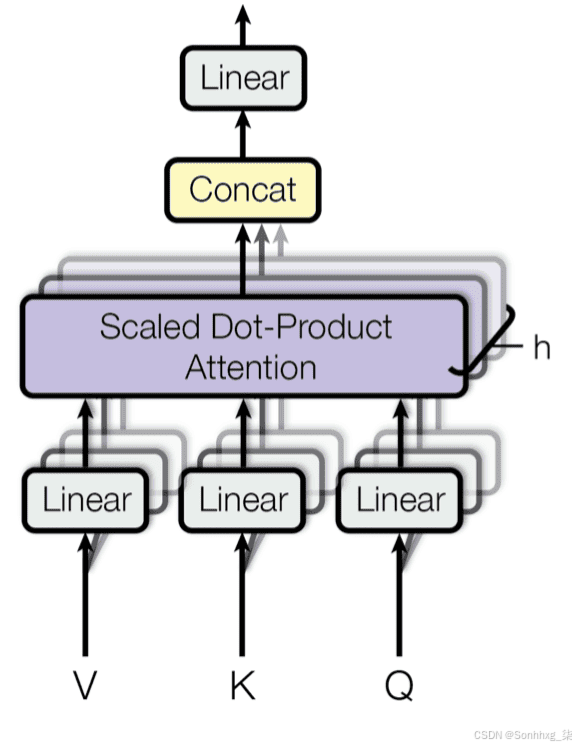
1.1、MHA简单代码实现
import math
from typing import Optional, Listimport torch
from torch import nnfrom labml import trackerclass PrepareForMultiHeadAttention(nn.Module):"""<a id="PrepareMHA"></a>## Prepare for multi-head attentionThis module does a linear transformation and splits the vector into givennumber of heads for multi-head attention.This is used to transform **key**, **query**, and **value** vectors."""def __init__(self, d_model: int, heads: int, d_k: int, bias: bool):super().__init__()# Linear layer for linear transformself.linear = nn.Linear(d_model, heads * d_k, bias=bias)# Number of headsself.heads = heads# Number of dimensions in vectors in each headself.d_k = d_kdef forward(self, x: torch.Tensor):# Input has shape `[seq_len, batch_size, d_model]` or `[batch_size, d_model]`.# We apply the linear transformation to the last dimension and split that into# the heads.head_shape = x.shape[:-1]# Linear transformx = self.linear(x)# Split last dimension into headsx = x.view(*head_shape, self.heads, self.d_k)# Output has shape `[seq_len, batch_size, heads, d_k]` or `[batch_size, heads, d_model]`return xclass MultiHeadAttention(nn.Module):r"""<a id="MHA"></a>## Multi-Head Attention ModuleThis computes scaled multi-headed attention for given `query`, `key` and `value` vectors.$$\mathop{Attention}(Q, K, V) = \underset{seq}{\mathop{softmax}}\Bigg(\frac{Q K^\top}{\sqrt{d_k}}\Bigg)V$$In simple terms, it finds keys that matches the query, and gets the values ofthose keys.It uses dot-product of query and key as the indicator of how matching they are.Before taking the $softmax$ the dot-products are scaled by $\frac{1}{\sqrt{d_k}}$.This is done to avoid large dot-product values causing softmax togive very small gradients when $d_k$ is large.Softmax is calculated along the axis of of the sequence (or time)."""def __init__(self, heads: int, d_model: int, dropout_prob: float = 0.1, bias: bool = True):"""* `heads` is the number of heads.* `d_model` is the number of features in the `query`, `key` and `value` vectors."""super().__init__()# Number of features per headself.d_k = d_model // heads# Number of headsself.heads = heads# These transform the `query`, `key` and `value` vectors for multi-headed attention.self.query = PrepareForMultiHeadAttention(d_model, heads, self.d_k, bias=bias)self.key = PrepareForMultiHeadAttention(d_model, heads, self.d_k, bias=bias)self.value = PrepareForMultiHeadAttention(d_model, heads, self.d_k, bias=True)# Softmax for attention along the time dimension of `key`self.softmax = nn.Softmax(dim=1)# Output layerself.output = nn.Linear(d_model, d_model)# Dropoutself.dropout = nn.Dropout(dropout_prob)# Scaling factor before the softmaxself.scale = 1 / math.sqrt(self.d_k)# We store attentions so that it can be used for logging, or other computations if neededself.attn = Nonedef get_scores(self, query: torch.Tensor, key: torch.Tensor):"""### Calculate scores between queries and keysThis method can be overridden for other variations like relative attention."""# Calculate $Q K^\top$ or $S_{ijbh} = \sum_d Q_{ibhd} K_{jbhd}$return torch.einsum('ibhd,jbhd->ijbh', query, key)def prepare_mask(self, mask: torch.Tensor, query_shape: List[int], key_shape: List[int]):"""`mask` has shape `[seq_len_q, seq_len_k, batch_size]`, where first dimension is the query dimension.If the query dimension is equal to $1$ it will be broadcasted."""assert mask.shape[0] == 1 or mask.shape[0] == query_shape[0]assert mask.shape[1] == key_shape[0]assert mask.shape[2] == 1 or mask.shape[2] == query_shape[1]# Same mask applied to all heads.mask = mask.unsqueeze(-1)# resulting mask has shape `[seq_len_q, seq_len_k, batch_size, heads]`return maskdef forward(self, *,query: torch.Tensor,key: torch.Tensor,value: torch.Tensor,mask: Optional[torch.Tensor] = None):"""`query`, `key` and `value` are the tensors that storecollection of *query*, *key* and *value* vectors.They have shape `[seq_len, batch_size, d_model]`.`mask` has shape `[seq_len, seq_len, batch_size]` and`mask[i, j, b]` indicates whether for batch `b`,query at position `i` has access to key-value at position `j`."""# `query`, `key` and `value` have shape `[seq_len, batch_size, d_model]`seq_len, batch_size, _ = query.shapeif mask is not None:mask = self.prepare_mask(mask, query.shape, key.shape)# Prepare `query`, `key` and `value` for attention computation.# These will then have shape `[seq_len, batch_size, heads, d_k]`.query = self.query(query)key = self.key(key)value = self.value(value)# Compute attention scores $Q K^\top$.# This gives a tensor of shape `[seq_len, seq_len, batch_size, heads]`.scores = self.get_scores(query, key)# Scale scores $\frac{Q K^\top}{\sqrt{d_k}}$scores *= self.scale# Apply maskif mask is not None:scores = scores.masked_fill(mask == 0, float('-inf'))# $softmax$ attention along the key sequence dimension# $\underset{seq}{softmax}\Bigg(\frac{Q K^\top}{\sqrt{d_k}}\Bigg)$attn = self.softmax(scores)# Save attentions if debuggingtracker.debug('attn', attn)# Apply dropoutattn = self.dropout(attn)# Multiply by values# $$\underset{seq}{softmax}\Bigg(\frac{Q K^\top}{\sqrt{d_k}}\Bigg)V$$x = torch.einsum("ijbh,jbhd->ibhd", attn, value)# Save attentions for any other calculations self.attn = attn.detach()# Concatenate multiple headsx = x.reshape(seq_len, batch_size, -1)# Output layerreturn self.output(x)二、多查询注意力机制(MQA)
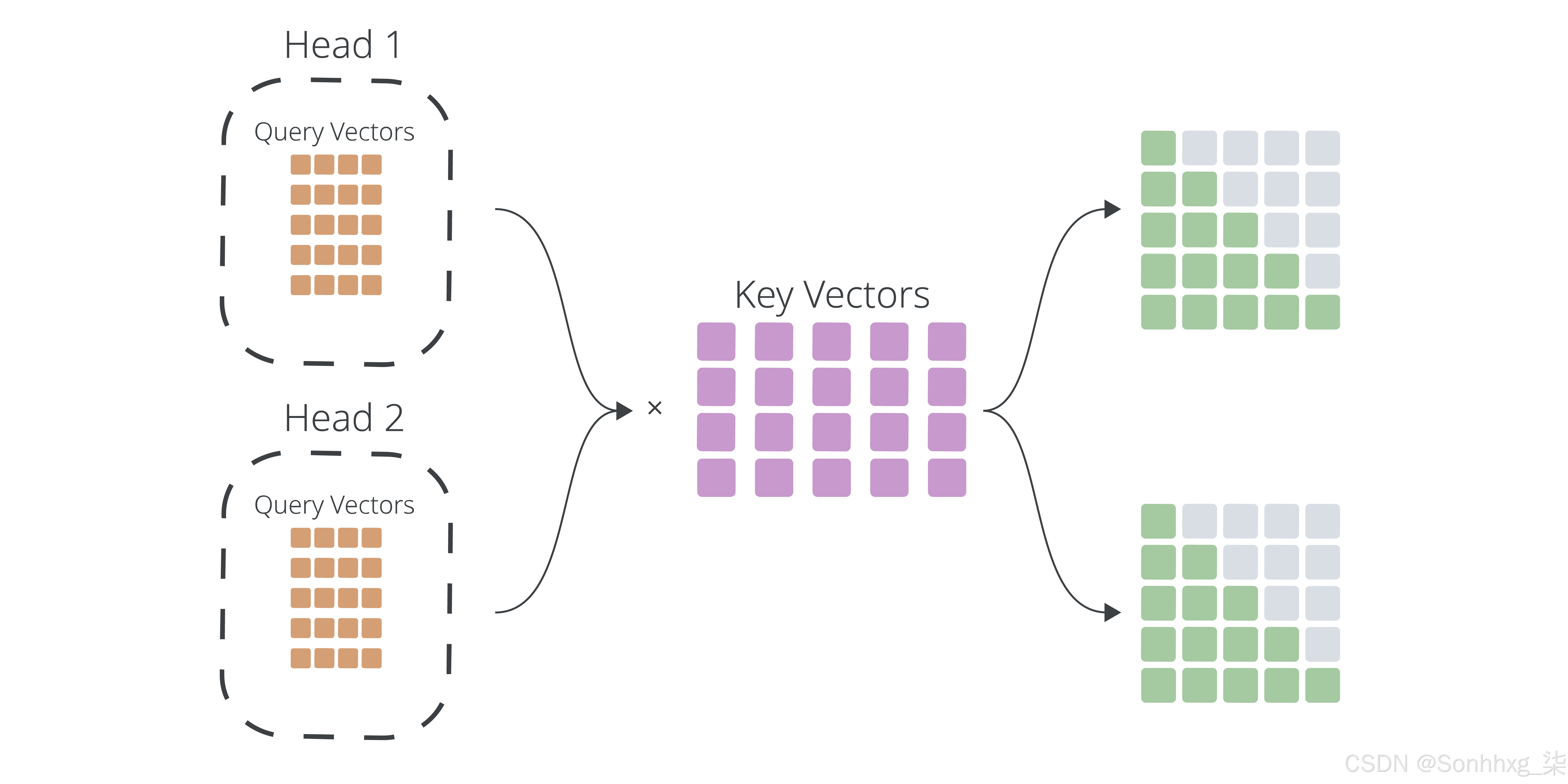
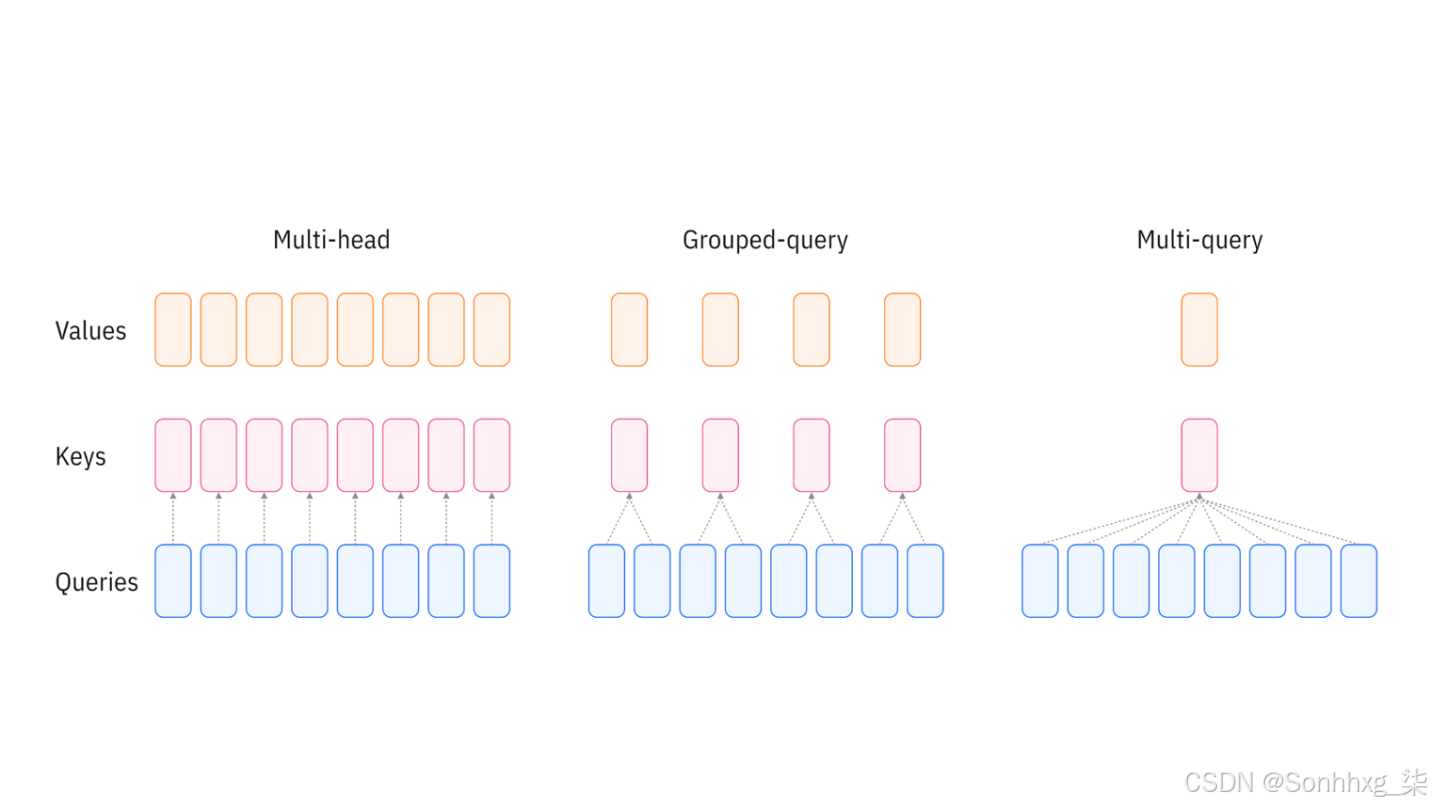
多头查询注意力机制 (MQA) 是 Transformer 架构中传统多头自注意力机制的一种优化变体。传统方法中每个注意力头都需维护独立的查询、键和值参数,导致计算资源消耗随注意力头数量增加而显著上升。MQA 的创新之处在于让多个注意力头共享相同的键和值参数,同时保留各自独立的查询参数,从而在保持模型性能基本不变的前提下,有效减少了计算量和内存占用。
2.1、MQA简单代码实现
import torch
from torch import nnclass MutiQueryAttention(torch.nn.Module):def __init__(self, hidden_size, num_heads):super(MutiQueryAttention, self).__init__()self.num_heads = num_headsself.head_dim = hidden_size // num_headsself.q_linear = nn.Linear(hidden_size, hidden_size)self.k_linear = nn.Linear(hidden_size, self.head_dim) ###self.v_linear = nn.Linear(hidden_size, self.head_dim) ###self.o_linear = nn.Linear(hidden_size, hidden_size)def forward(self, hidden_state, attention_mask=None):batch_size = hidden_state.size()[0]query = self.q_linear(hidden_state)key = self.k_linear(hidden_state)value = self.v_linear(hidden_state)query = self.split_head(query)key = self.split_head(key, 1)value = self.split_head(value, 1)attention_scores = torch.matmul(query, key.transpose(-1, -2)) / torch.sqrt(torch.tensor(self.head_dim))if attention_mask != None:attention_scores += attention_mask * -1e-9attention_probs = torch.softmax(attention_scores, dim=-1)output = torch.matmul(attention_probs, value)output = output.transpose(-1, -2).contiguous().view(batch_size, -1, self.head_dim * self.num_heads)output = self.o_linear(output)return outputdef split_head(self, x, head_num=None):batch_size = x.size()[0]if head_num == None:return x.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1,2)else:return x.view(batch_size, -1, head_num, self.head_dim).transpose(1,2)2.2、多查询注意力机制的关键概念
- 共享键和值:与传统的多头注意力(每个头都有自己的键和值)不同,MQA 对所有注意力头使用相同的键和值。
- 不同的查询:MQA 中的每个注意力头仍然使用自己的一组查询,从而使其能够关注输入序列的不同方面。
- 效率:通过共享键和值,MQA 减少了所需的计算量和内存,使其比传统的多头注意力更高效。
2.3、多查询注意力机制的好处
- 降低计算复杂度:通过共享键和值,MQA 显著减少了所需的操作数量,使其比传统的多头注意力更高效。
- 更低的内存使用率:MQA 通过存储更少的键和值矩阵来减少内存使用率,这对于处理长序列特别有益。
- 保持性能:尽管效率有所提高,MQA 仍保持着与传统多头注意力相媲美的竞争性能,使其成为大规模 NLP 任务的可行选择。
三、 群组查询注意力机制(GQA)
组查询注意力机制 (GQA) 是对 Transformer 中使用的传统多头自注意力机制的优化。在标准的多头自注意力机制中,每个注意力头独立处理整个序列。这种方法虽然功能强大,但计算成本较高,尤其对于长序列而言。GQA 通过将查询分组来解决这个问题,从而降低了计算复杂度,同时又不会显著影响性能。
3.1、GQA简单代码实现
import torch
from torch import nn
class GroupQueryAttention(torch.nn.Module):def __init__(self, hidden_size, num_heads, group_num):super(MutiQueryAttention, self).__init__()self.num_heads = num_headsself.head_dim = hidden_size // num_headsself.group_num = group_num## 初始化Q、K、V投影矩阵self.q_linear = nn.Linear(hidden_size, hidden_size)self.k_linear = nn.Linear(hidden_size, self.group_num * self.head_dim)self.v_linear = nn.Linear(hidden_size, self.group_num * self.head_dim)## 输出线性层self.o_linear = nn.Linear(hidden_size, hidden_size)def forward(self, hidden_state, attention_mask=None):batch_size = hidden_state.size()[0]query = self.q_linear(hidden_state)key = self.k_linear(hidden_state)value = self.v_linear(hidden_state)query = self.split_head(query)key = self.split_head(key, self.group_num)value = self.split_head(value, self.group_num)attention_scores = torch.matmul(query, key.transpose(-1, -2)) / torch.sqrt(torch.tensor(self.head_dim))if attention_mask != None:attention_scores += attention_mask * -1e-9attention_probs = torch.softmax(attention_scores, dim=-1)output = torch.matmul(attention_probs, value)output = output.transpose(-1, -2).contiguous().view(batch_size, -1, self.head_dim * self.num_heads)output = self.o_linear(output)return outputdef split_head(self, x, group_num=None):batch_size,seq_len = x.size()[:2]if group_num == None:return x.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1,2)else:x = x.view(batch_size, -1, group_num, self.head_dim).transpose(1,2)x = x[:, :, None, :, :].expand(batch_size, group_num, self.num_heads // group_num, seq_len, self.head_dim).reshape(batch_size, self.num_heads // group_num * group_num, seq_len, self.head_dim)return x3.2、群组查询注意力机制的关键概念
- 分组查询:在 GQA 中,查询会根据相似性或其他标准进行分组。这使得模型能够在相似的查询之间共享计算,从而减少所需的总体操作数量。
- 共享键和值表示:GQA 不会为每个查询计算单独的键和值表示,而是为每个组计算共享的键和值表示。这进一步减少了计算负载和内存占用。
- 高效计算:通过分组查询和共享计算,GQA 可以更高效地处理更长的序列,使其适合需要处理大量文本或数据的任务。
3.3、群组查询注意力机制如何发挥作用?
为了理解 GQA 的工作原理,我们将该过程分解为几个步骤:
- 查询分组:根据预定义的标准(例如序列中的位置或语义相似性)将输入查询分成几组。
- 共享键和值计算:对于每组查询,计算一组共享的键和值表示。这是通过对输入嵌入应用线性变换来实现的。
- 注意力计算:计算分组查询和共享键表示之间的注意力分数。这些分数决定了每个键对于每个查询组的重要性。
- 加权和:根据注意力分数,计算共享值表示的加权和,从而获得最终的注意力输出。
- 合并结果:所有查询组的输出被合并以产生最终表示,然后在 Transformer 的后续层中使用该表示。
3.4、群组查询注意力机制的好处
- 降低计算复杂度:通过对查询进行分组和共享计算,GQA 显著减少了所需的操作数量,使其比传统的多头自注意力更高效。
- 可扩展性:GQA 对于需要处理长序列的模型特别有用,因为它可以随着序列长度更有效地扩展。
- 性能:尽管效率很高,GQA 仍保持着与传统注意力机制相媲美的竞争性能,使其成为大规模 NLP 任务的可行选择。
一些大型语言模型 (LLM) 已经引入了群组查询注意力机制来提升其性能和效率。一些著名的例子包括:Llama、Mistral 等。
四、多头潜在注意力(MLA)
多头潜在注意力 (MLA) 将潜在表征融入注意力机制,以降低计算复杂度并提升语境表征能力。与直接处理输入 token 的标准注意力机制不同,MLA 引入了一组可学习的潜在嵌入,作为查询、键和值之间的中介。这些潜在嵌入能够捕捉高级抽象模式,并实现更高效的跨 token 交互。
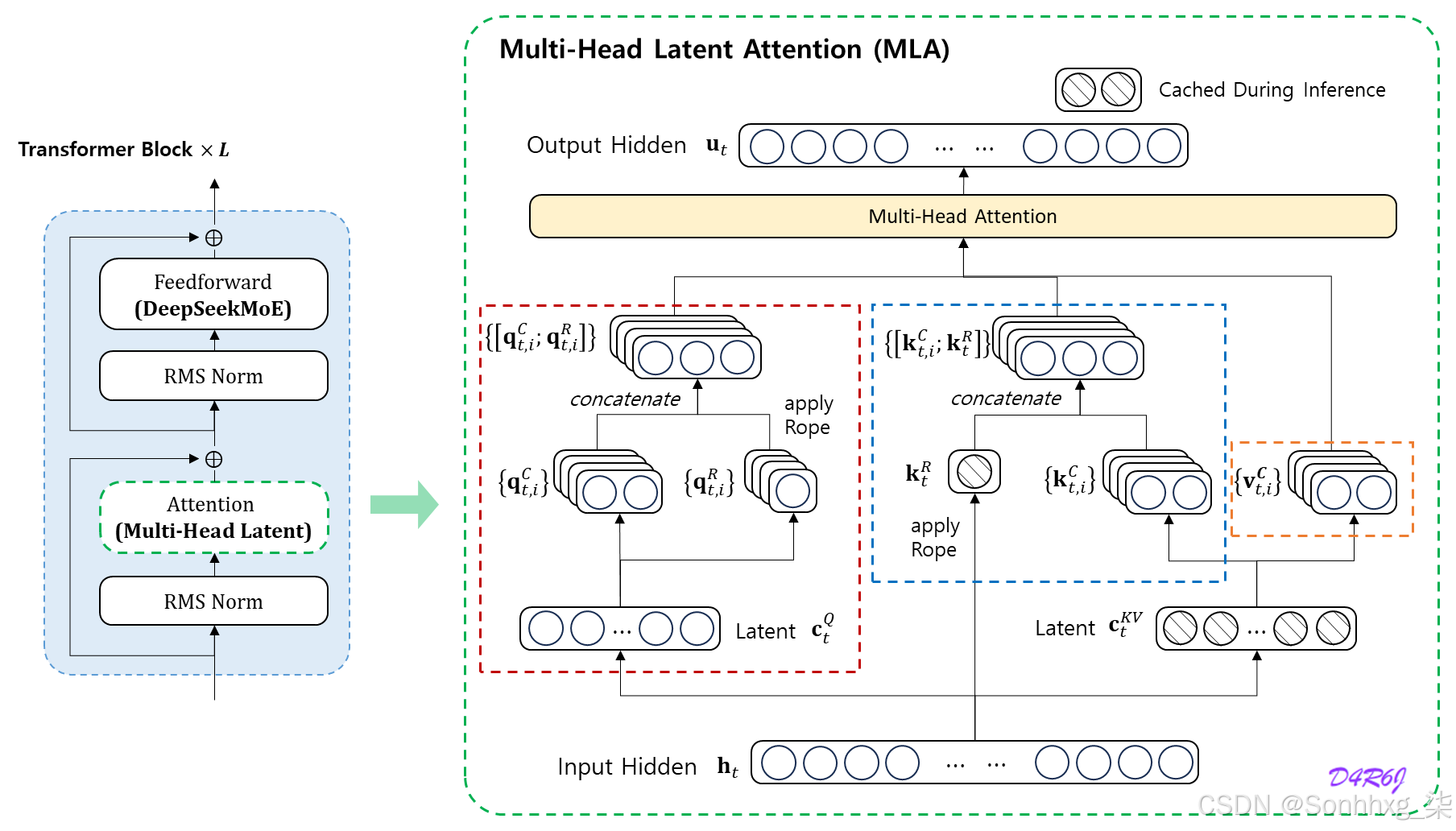
MLA 的主要特点:
- 潜在嵌入:可学习的嵌入,代表输入空间的压缩摘要。
- 减少注意力开销:注意力不再关注所有输入标记,而是集中在潜在嵌入上,从而加快计算速度。
- 可扩展性:适用于涉及大规模数据或极长序列的场景。
4.1、MLA简单代码实现
import math
import torch
import torch.nn as nnclass MultiHeadLatentAttention(nn.Module):def __init__(self, d_model=128*128, num_heads=128, q_latent_dim=12, kv_latent_dim=4):super().__init__()self.d_model = d_modelself.num_heads = num_headsself.q_latent_dim = q_latent_dimself.kv_latent_dim = kv_latent_dimhead_dim = d_model // num_heads# Query projectionsself.Wq_d = nn.Linear(d_model, q_latent_dim)# Precomputed matrix multiplications of W_q^U and W_k^U, for multiple headsself.W_qk = nn.Linear(q_latent_dim, num_heads * kv_latent_dim)# Key/Value latent projectionsself.Wkv_d = nn.Linear(d_model, kv_latent_dim)self.Wv_u = nn.Linear(kv_latent_dim, num_heads * head_dim)# Output projectionself.Wo = nn.Linear(num_heads * head_dim, d_model)def forward(self, x):batch_size, seq_len, d_model = x.shape# Projections of input into latent spacesC_q = self.Wq_d(x) # shape: (batch_size, seq_len, q_latent_dim)C_kv = self.Wkv_d(x) # shape: (batch_size, seq_len, kv_latent_dim)# Attention score, shape: (batch_size, num_heads, seq_len, seq_len)C_qW_qk = self.W_qk(C_q).view(batch_size, seq_len, self.num_heads, self.kv_latent_dim)scores = torch.matmul(C_qW_qk.transpose(1, 2), C_kv.transpose(-2, -1)[:, None, ...]) / math.sqrt(self.kv_latent_dim)# Attention computationattn_weight = torch.softmax(scores, dim=-1)# Restore V from latent spaceV = self.Wv_u(C_kv).view(batch_size, seq_len, self.num_heads, -1)# Compute attention output, shape: (batch_size, seq_len, num_heads, head_dim)output = torch.matmul(attn_weight, V.transpose(1,2)).transpose(1,2).contiguous()# Concatentate the heads, then apply output projectionoutput = self.Wo(output.view(batch_size, seq_len, -1))return output4.2、MLA 如何优于 MHA、MQA 和 GQA
4.2.1、 MLA 与 MHA(多头注意力)
多头注意力(MHA):
- 将输入序列分割为多个注意力头,每个头处理完整的查询、键和值集合。
- 该机制能在不同注意力头间生成多样化的上下文表征,但会因输入序列长度导致二次方的计算复杂度(O(n²))。
MLA优势:
- 潜在压缩:MLA通过聚焦潜在嵌入降低注意力空间的维度,减少成对token交互的计算成本。
- 更快推理:通过关注较小规模的潜在嵌入而非整个序列,MLA实现线性或接近线性复杂度(O(n)或O(k),其中k << n)。
- 更好泛化:潜在嵌入能捕捉基于token的多头注意力可能忽略的高层模式,提升模型在未知场景中的鲁棒性
4.2.2、 MLA 与 MQA(多查询注意力机制)
多查询注意力机制(MQA):
- 通过对所有注意力头使用单个共享键值对来简化 MHA,从而显著减少内存开销。
- 非常适合大型语言模型 (LLM) 等大规模模型,但在捕捉细微的标记级交互方面有所妥协。
MLA优势:
- 保留令牌多样性:与 MQA 的单一共享键值不同,MLA 通过启用潜在嵌入作为中间层来保持多样性,从而实现更丰富的上下文捕获。
- 效率与表现力之间的平衡: MLA 通过减少计算而不牺牲标记级粒度来弥合 MQA 的简单性和 MHA 的表现力之间的差距。
4.2.3、MLA 与 GQA(分组查询注意力)
分组查询注意(GQA):
- 将标记分组为更小的子集以在组内执行注意,与 MHA 相比有效降低复杂性。
- 适用于局部注意力足够但可能忽略全局依赖关系的任务。
MLA优势:
- 全局表示: MLA 的潜在嵌入本质上捕捉了全局模式,克服了 GQA 关注群体的局限性。
- 高效的全局语境化: MLA 的潜在嵌入不是对标记进行分组,而是充当全局摘要,使其可扩展,同时保留整个序列的上下文。
4.3、MLA 的机制
潜在嵌入初始化:固定数量的潜在嵌入(L)作为模型的一部分,随机初始化或预训练。这些嵌入充当输入序列的压缩表示空间。
查询-潜在交互:输入查询关注的是这些潜在嵌入,而不是整个序列。这大大减少了成对交互的数量。
潜在键值映射:潜在嵌入关注原始键和值,充当将上下文提炼为有意义模式的中介。
输出聚合:查询和潜在嵌入之间的注意力结果被投射回标记空间,从而保留关键的标记级信息。
4.4、MLA 的主要优势
- 效率:与 MHA 相比,降低了内存和计算成本。
- 可扩展性:由于压缩的潜在空间,在长序列或大数据集上表现良好。
- 增强泛化:潜在嵌入提供了更高级别的抽象,帮助模型更好地推广到看不见的数据。
- 灵活性:结合了全球和本地关注的优势,而没有任何一个极端的缺点。
4.5、MLA 的用例
MLA 在需要高效处理长序列和大规模模型的应用中表现出色:
- 自然语言处理 (NLP):基于 Transformer 的文本生成或机器翻译模型。
- 计算机视觉(CV):输入尺寸(像素)较大的图像转换器。
- 时间序列分析:捕捉大量时间数据中的模式。
- 推荐系统:利用潜在用户和项目表示对用户-项目交互进行建模。
4.6、局限性和挑战
虽然 MLA 解决了 MHA、MQA 和 GQA 的许多问题,但它也面临着一系列挑战:
- 潜在嵌入的优化:性能取决于潜在嵌入的初始化和训练的有效性。
- 表示中的权衡:将输入标记压缩到潜在嵌入中可能会丢失对某些任务至关重要的细粒度细节。
五、结论
多头潜在注意力 (MLA) 引入了一种创新方法,利用潜在表征来优化注意力机制。MLA 解决了 MHA 的计算效率低下、MQA 的表达能力有限以及 GQA 的局部聚焦问题,是一项极具前景的进步。它在效率、可扩展性和表征能力之间取得的平衡,使其成为自然语言处理 (NLP)、计算机视觉等领域众多应用的有力选择。