大数据电商流量分析项目实战:Day 1-1 Linux基础(补充)


✨博客主页: https://blog.csdn.net/m0_63815035?type=blog
💗《博客内容》:大数据、Java、测试开发、Python、Android、Go、Node、Android前端小程序等相关领域知识
📢博客专栏: https://blog.csdn.net/m0_63815035/category_11954877.html
📢欢迎点赞 👍 收藏 ⭐留言 📝
📢本文为学习笔记资料,如有侵权,请联系我删除,疏漏之处还请指正🙉
📢大厦之成,非一木之材也;大海之阔,非一流之归也✨

前言&课程重点
大家好,我是程序员小羊!接下来一周,咱们将用 “实战拆解 + 技术落地” 的方式,带大家吃透一个完整的大数据电商项目 ——不管你是想靠项目经验敲开大厂就业门,还是要做毕业设计、提升技术深度,这门课都能帮你 “从懂概念到能落地”。
毕竟大数据领域不缺 “会背理论” 的人,缺的是 “能把项目跑通、能跟业务结合” 的实战型选手。咱们这一周的内容,不搞虚的,全程围绕 “电商业务痛点→数据解决方案→技术栈落地” 展开,每天聚焦 1 个核心模块,最后还能输出可放进简历的项目成果。
进入正题(Day1-1):
本项目是一门实战导向的大数据课程,专为具备Java基础但对大数据生态系统不熟悉的同学量身打造。你将从零开始,逐步掌握大数据的基本概念、架构原理以及在电商流量分析中的实际应用,迅速融入当下热门的离线数据处理技术。
在这门课程中,你将学会如何搭建和优化Hadoop高可用环境,了解HDFS存储、YARN资源调度的核心原理,为数据处理打下坚实的基础。同时,你将掌握Hive数据仓库的构建和数仓建模方法,了解如何将海量原始数据经过层次化处理,转化为高质量的数据资产。
课程还将引领你深入Spark SQL的世界,通过实际案例学习如何利用Spark高效计算PV、UV以及各类衍生指标,提升数据分析效率。此外,你还将学习Flume的安装与配置,实现Web日志的实时采集和ETL入仓,确保数据传输的稳定与高效。
为了贴近企业实际运作,本项目还包括定时任务的设置和自动化数据管道构建,教你如何编写Shell脚本并利用crontab定时调度Spark作业,让数据处理过程实现自动化与智能化。最后,通过可视化展示模块,你将学会用FineBI等工具将数据分析结果直观呈现
总之,这是一门集大数据基础、系统搭建、数据处理与智能分析于一体的全链路实战课程。无论你是初入大数据领域的新手,还是希望提升数据处理能力的开发者,都将在这里收获满满,掌握最前沿的大数据技术。
课程计划:
| 天数 | 主题 | 主要内容 |
|---|---|---|
| Day 1 | 大数据基础+项目分组 (ZK补充) | 大数据概念、数仓建模、组件介绍、分组;简单介绍项目。 |
| Day 2 | Hadoop初认识+ HA环境搭建 | 初认识Hadoop,了解HDFS 基本操作,YARN 资源调度,数据存储测试等,并且完成Hadoop高可用的环境搭建。 |
| Day 3 | Hive 数据仓库 | Hive SQL 基础、表设计、加载数据,搭建Hive环境并融入Hadoop实现高可用 |
| Day 4 | Spark SQL 基础 | 讲解Spark基础,DataFrame & SQL 查询,Hive 集成和环境的搭建 |
| Day 5 | Flume 数据采集及ETL入仓 | 安装Flume高可用,学习基础的Flume知识并且使用Flume 采集 Web 日志,存入 HDFS;数据格式解析,数据传输优化 |
| Day 6 | 数据入仓 & 指标计算 | 解析 PV、UV 计算逻辑,Hive 数据清洗、分层存储(ODS → DWD) |
| Day 7 | Spark 计算 & 指标优化 | 使用 Spark SQL 计算 PV、UV 及衍生指标(如跳出率、人均访问时长等) |
| Day 8 | 定时任务 & 数据管道 | 编写 Shell 脚本,使用 crontab 实现定时任务,调度 Spark SQL |
| Day 9 | 可视化 & 数据分析 | 搭建一个简单的项目使用 FineBI 进行数据展示,分析趋势。 |
| Day 10 | 项目答辩 | 小组演示分析结果,可以后台联系程序员小羊点评 |
今日学习重点:
Linux简介和作者等
Linux 内核最初只是由芬兰人林纳斯·托瓦兹(Linus Torvalds)在赫尔辛基大学上学时出于个人爱好而编写的,同时他也是Git的作者
Linux是一个典型的GPL通用公共许可证项目,只要你遵循GNU的GPL保证开源,任何人都有权利自由的使用和修改Linux底层源码,因为这个特性,市面上的Linux发行版层出不穷。
Linux的主要实现就是内核,然后是系统自带库,shell,应用程序
内核包括:设备驱动程序,进程管理内存管理,文件系统,网络协议栈等
系统库包括:C标准库,数学库,动态链接库,线程库,第三方库等
shell:命令行解释器,接受用户传来的命令通过它调用api来传递给操作系统运行
应用程序:Linux软件。

发行版就是将如图上面的东西编辑打包在一起形成一个新的操作系统。常见的发行版是CentOS,Ununtu,KALI,debian等等
安装虚拟机
在电脑安装Vmware之后创建一个虚拟机,这里不做教程
Vmware 16 下载 https://www.123pan.com/s/2BtiVv-3Ke8.html
Centos7 镜像下载 https://mirrors.aliyun.com/centos/7/isos/x86_64/?spm=a2c6h.25603864.0.0.6aa74511u1Gh2p
目标大数据项目当个机器的硬盘要大于 80G,内存要大于 2G
也可以使用docker,或者使用云服务器
Linux二级目录讲解
/bin:存放基本用户命令的二进制文件,例如 ls、cp、mv 等。这些命令在单用户模式和所有用户环境中都可用。
/boot:存放启动引导程序和内核文件,包括 grub 启动引导程序和内核映像文件(如 vmlinuz)。
挂载分区
/dev:存放设备文件。这些文件是对系统中各种设备(如硬盘、终端、打印机)的抽象。
/dev/null: 黑洞文件,在这里面的信息不存在默认删除
/media:挂载点目录,用于挂载可移动媒体设备(如 CD-ROM、USB 设备)。系统会在该目录下创建子目录并挂载设备。
/mnt:临时挂载点目录,用于手动挂载临时文件系统。
/etc:存放系统配置文件和脚本,包括系统启动、网络配置、用户管理等。
/home:存放用户的主目录,每个用户都有一个自己的子目录(如 /home/username),用于存放用户的个人文件和设置。
/root:超级用户(root 用户)的主目录。与 /home 目录下的普通用户主目录不同。
/lib和/lib64:存放系统的共享库文件,这些库文件是系统和应用程序运行所需的基本函数库。
/opt:用于安装附加的可选软件包。通常用于存放第三方应用程序。
/proc:虚拟文件系统目录,包含关于正在运行的进程和系统状态的文件。这些文件不是实际存储在磁盘上的,而是由内核动态生成的。
/sbin:存放系统管理员使用的基本系统二进制文件,例如 fdisk、ifconfig 等。普通用户通常无权运行这些命令。
/sys:虚拟文件系统目录,类似于 /proc,用于存放关于系统和硬件信息的文件。这些文件由内核生成,用于表示设备和内核结构。
/tmp:存放临时文件。系统和应用程序在运行过程中会在此目录中存放临时文件。通常,该目录中的文件会在系统重启时删除。
/usr:存放用户二进制文件和只读数据,包括二进制文件、库文件、文档等。常见子目录有:
-
/usr/bin:存放用户使用的二进制文件(除了基本命令之外的其他命令)。
-
/usr/sbin:存放系统管理员使用的二进制文件。
-
/usr/lib:存放系统和用户程序的库文件。
-
/usr/share:存放共享的、独立于架构的数据文件(如文档、配置文件示例等)。
/var:存放变量文件,如日志文件、邮件队列、打印机队列等。内容经常变化。
-
/var/log:存放系统日志文件。
-
/var/spool:存放任务队列文件,例如打印机队列、邮件队列。
-
/var/tmp:存放临时文件,重启后通常不会删除。
vi/vim 编辑器
vi是Linux中默认使用的原版编辑器,vim是他的增强版需要手动安装 yum install vim -y。使用方法是一样的,但是vim添加一些新的功能等实现更好的显示和使用
vi中常用的 有三种模式,命令模式,插入模式和尾行模式 默认是命令模式
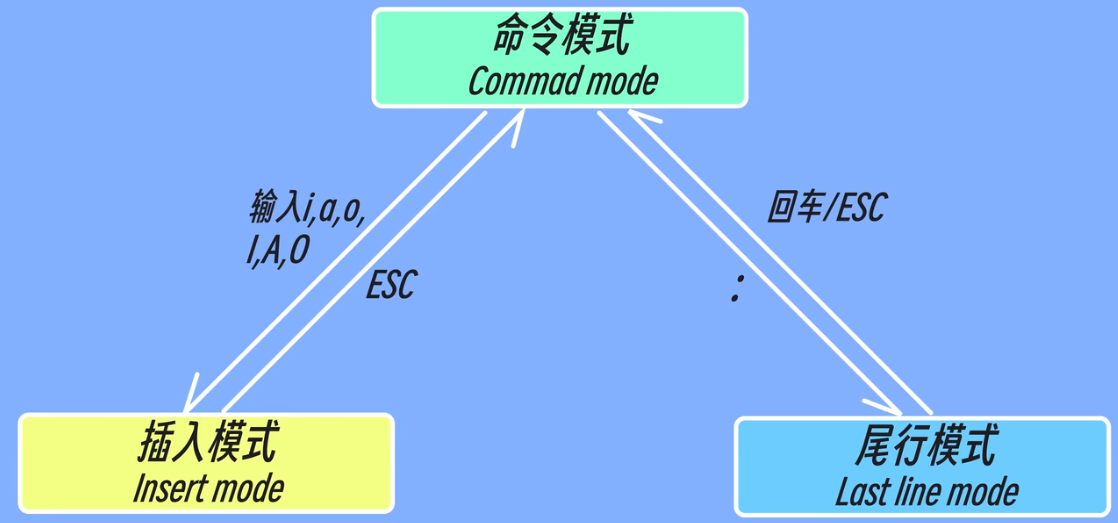
模式切换: 打开文件 vi [文件名] 或者 vim [文件名] 如果当前目录下没有此文件就会自动创建一个,当我们打开文件后想要从命令模式改为插入模式 可以按 I 进入插入 A 追加 O打开,编辑完成后按ESC回到命令模式。其中大小写的区别如下O是上一行插入,o是下一行插入,i是当前位置插入,I当前行头插入,a当前位置插入,A行末尾插入。
保存按下:进入尾行模式 输入 wq 回车保存并退出 !是强制的意思


浏览 在使用vim的时候,我们可以使用HJKL 或者箭头来实现光标的左下上右。按下^就会到行首,$就会到行尾。使用Ctrl+f或者Ctrl+b可以快速的向前或者向后翻页。Ctrl+u Ctrl+d 可以快速的向上或者向下翻半页。

快捷复制 在命令模式连续按下两次y就可以复制内容,p粘贴光标的下一行,dd删除内容 分别代表复制,粘贴,剪切。按下一个G就可以快速跳转最后,gg来跳转文件的第一行。100G就是跳转到第100行,或者 :100 也可以跳转到100行
查找 在尾行模式输入 :set nu 侧面会显示行号 不想显示 :set nonu。在命令模式下,输入 /[查找内容] 就会触发查找,这个是往当前光标下面开始查找,?[查找内容] 从上查找,(区分大小写 \可以不区分大小写 例如 /hello\c )n定位下一个,N定位上一个
替换 [start,over]s/Hello/World/g [start,over]范围,不写选中当前行 s替换Hello为World g代表其中的所有匹配项 。如果替换范围是整个文件 范围 [1,$]
撤销 点击u
针对文件操作 命令
- 显示文件信息
cat 文件名 显示文件的全部内容
less 文件名 分页展示文件内容
head [-n 数字] 文件名 显示文件前n行 [-n 数字] 属性可选,默认5
tail [-n 数字] 文件名 显示文件后n行,默认5
tail -f 实时展示文件内容更新
- 文件操作
复制文件: cp 目标文件 复制后文件名 (-r 递归复制文件夹下的所有文件)
移动文件:mv 目标文件 移动后的文件名 (mv 是移动文件的做法,如果操作位置一致文件名不一致就是重命名)
删除文件:rm 文件名 删除文件 rm -rf 文件目录 递归删除文件夹目录下的所有文件
创建目录:mkdir 文件名 创建文件夹 (-p 遍历创建目录层级)
文件位置:cd [ ] … 表示上一级 …/… 上一级的上一级目录 / 根目录
查看位置:du -h列出当前目录下的所有文件和文件大小
使用树方式查看当前目录的文件位置:[要提前安装 yum install tree -y] tree
删除目录:rmdir 目标文件 删除目标空文件夹,里面不可以有东西 【更推荐 rm -r 目录名称】
创建文件:touch 文件名 在当前目录下创建一个新文件 echo " " > 文件名 创建文件写入信息
Linux目录结构:
在Linux中 目录是按照目录树的方式排布的所有的文件都是从根目录开始的 ‘/’ 标识根目录 ,在系统中有两个路径类型,相对文件类型和绝对文件类型 相对会从当前位置开始找没有用’/'开头,绝对从/开始一层一层的指引到文件位置。 ‘~’ 当前用户的home 目录。 ‘-’ 上一次所在的目录。
文件下载,压缩解压
tar -czvf 压缩包名.tar.gz 目录或文件名:压缩文件或目录。
tar -xzvf 压缩包名.tar.gz:解压缩文件。
wget 文件网址:从指定网址下载文件。
curl -O 文件网址:从指定网址下载文件。
v 展示过程 c 创建压缩 z 使用gzip算法 f 指定压缩文件名 -C 指定解压位置
zip -r 压缩包名.zip 文件名1 文件名2 文件名3
unzip 压缩包名.zip -d 目标目录
Linux之间的文件传输:
scp 源数据地址 目标数据地址 (scp是默认覆盖模式,适合大文件)
scp -C[允许在传输的时候压缩,可以提高效率] [-r 递归整个目录] [-l 限制传输带宽KB/s]参考使用: scp -Crp -l 100 test/ root@IP:目标IP位置
rsync 需要提前安装 rsync会先对文件比较,不一样了才会传输,时间比较慢比较吃资源
-a 归档递归,-z 允许压缩处理,–progress 显示传输进度,-bwlimit 限制传输带宽kb/s,–partial 恢复上次进度,断点重传 --exclude ‘X’ 传输排除x文件 --exclude-from ‘X’ 排除指定X格式的文件
列表操作和文件权限
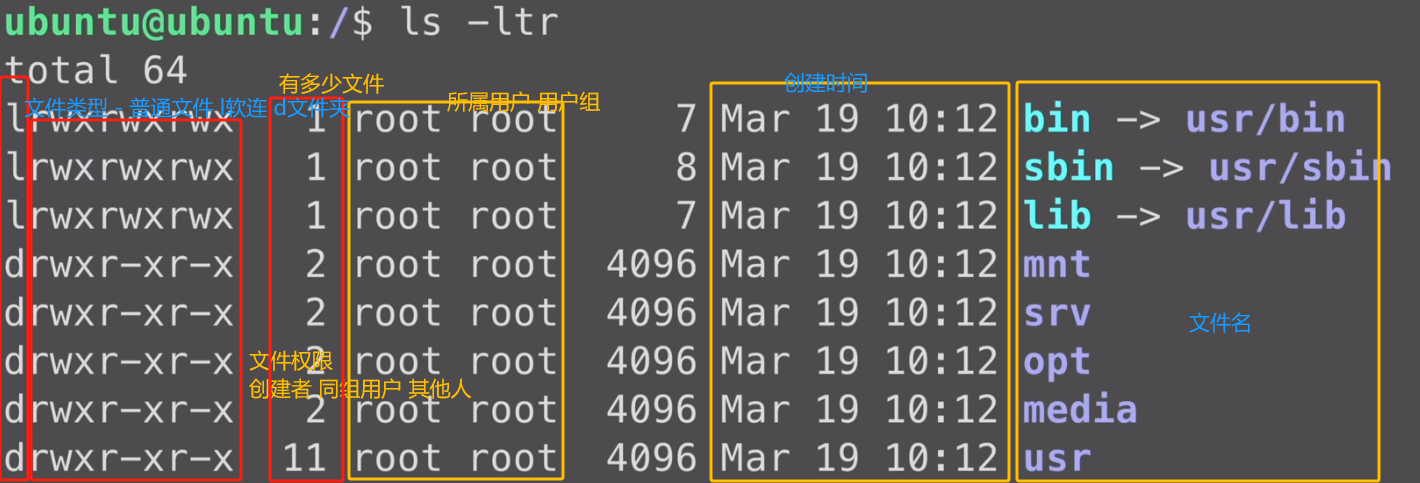
ls 列出目录下的所有文件 (-l 更详细的文件信息 -a 显示所有隐藏文件 -h 格式化显示文件大小 -t按照时间排序 -r 逆序显示 -i 显示i节点信息)
ll 列出目录下的所有文件的详细信息 等同于 ls -l
使用软链接相当于快捷方式,当这个文件被调用的时候就相当于重定向到另一个文件中,硬链接复制了这个文件的i节点共享一样的文件内容,创建方式分为软链接和硬链接ln -s 目标文件 链接文件名 (-s 创建软链接)
tree 可以展示文件目录树,需要提前安装。
文件权限说明
例如:rw- rw- r-- 这是一个文件的对应操作权限展示 r标识可读,w可写,x可运行 -无此权限 3个一组,三组一个标识 创建者权限 同组用户权限 其他用户权限
chmod +x 文件名 (添加执行权限给这个文件,+rw 添加读,写权限)
chomd o-x 文件名 (删除其他用户的可执行权限,u 所属用户 g 同组用户 o 其他用户)
chomd ug+xr 文件名 (为ug者两种用户添加可执行可写权限)
还可以使用数字来说明权限:r = 4,w = 2,x = 1,rwx = 7 , rw = 6,rx = 5
chomd 711 (拥有者有rwx权限,其他用户都有可执行权限)
进程|时间同步|防火墙|系统管理等杂项
网络和防火墙
ifconfig 展示网络信息 ip addr 展示网络接口等信息
ping 域名或IP 测试网络连接
netstat -tuln 显示当前监听的网络端口
traceroute 域名或IP 显示到目标主机的路径
systemctl stop firewalld 关闭防火墙 (stop enable start 启动,禁用,启动)
vi /etc/sysconfig/network-scripts/ifcfg-ens33 编辑网络配置
BOOTPROTO=static
UUID 整行删除
NOBOOT=yes
IPADDR= IP
NETMASK=255.255.255.0
GATEWAY= 网关
DNS1、DNS2、DNS3=114.114.114.114--> systemctl restart network
--> 图形化网络配置:nmtui
查看进程
ps aux 展示所有进程
jps 查看JAVA运行程序
top 动态显示进程信息
htop 优化版动态显示进程信息 需要安装
kill PID [-9] [-15] 强制删除进程 软关闭进程
ps -ef | group [进程关键字] 根据关键字查询进程
磁盘使用情况:
df -h 显示文件系统的磁盘使用情况
查看系统信息:
uname -a 显示系统详细信息。
uname -r 显示内核版本
hostname [主机名] 显示或设置主机名
关闭Linux:
halt 断电关闭poweroff 直接关机不管里面进程
shutdown -h [now]时间 延迟一段时间关机计算机但是会给其他用户发通知
reboot 重启
时间同步:
yum install ntp 安装时间同步的软件
ntpdate -su 210.72.145.44 【中国国家授时中心】
ntpdate -su api.bz 【NTP上海服务器】
不允许联网的情况下可以在内网中自己搭建NTP服务器来让内网中的其他机器访问实现时间同步。
用户管理和多进程
用户管理
useradd 用户名 [-g 组名 -G 附属组] 添加新用户
passwd 用户名 为用户设置密码
usermod -L 用户名 锁定用户
usermod -U 用户名 解锁用户
userdel -r 用户名 删除用户
groupadd 组名 新建新用户组
groupmode -n 新名 旧名 修改组名
usermod 用户名 -g 主组 -G 附属组名 将用户添加到组
groupdel 组名 删除组名 如果下面有主用户删除不了需要提前转移
多窗口 screen 需要安装
screen -S 窗口名 创建一个新的窗口并进入
[在窗口中] Ctrl + A + D 挂载当前状态回退到主机
screen -ls 展示当前所有在后台的窗口
screen -r 窗口id 进入指定窗口id
su 权限赋予
编辑 chmod u+w /etc/sudoers 先给只读文件添加可写权限,vi /etc/sudoers 在大概100行的时候添加 wangwu(用户) ALL=(root) /sbin/useradd 给用户王五添加可以sudo 用户添加的能力,执行效果等同于root用户操作
包管理命令
rpm -lvh xxx.rpm 安装指定的rpm软件 软件安装到 /usr 如果安装的需要有环境配置会软连接到 /usr/bin 会被自动加载,
rpm -qs | grep 匹配名称 根据关键字查找这个rpm包信息
rpm -Uvh xxx.rpm 升级指定的rpm软件
rpm -evh xxx.rpm 删除rpm包
yum底层是rpm 更好用
yum 适用于RedHat,apt适用于Debian
yum update | apt update 更新包索引,新系统必做
apt upgrade 升级所有已经安装的包
apt remove 包名 | yum remove 包名 删除指定包
apt autoremove | yum clean all 自动清理缓存和无用包
关于国内无法使用apt,yum的换源说明:运行脚本:bash <(curl -sSL https://linuxmirrors.cn/main.sh)) 参考操作:1 y y y y
管道和重定向
cat 文件监听 grep ‘文本’ 文本匹配
在Linux中管道和重定向作为高级用法的一部分,具有极高的灵活性和使用价值,分别用符号 ‘>’,‘>>’‘<’ 和 ’ | ’ 等
重定向用于将命令的输入或输出重定向到文件或另一个命令。常见的重定向符号包括 >、>>、<、2> 等。
输出重定向
‘>’ 将命令的输出重定向到一个文件(单此操作覆盖原文件内容),不建议第一次创建文件使用
‘>>’ 将命令的输出追加到一个文件(不覆盖原文件内容)
例如:ls > file1 echo “这是我查找的文件” >> file1
输入重定向
‘<’ 将文件的内容作为命令的一部分传入,常用用法:cat > [目标文件] << EOF
将cat监听到的数据写入到目标文件中,输入EOF结束
错误重定向
在运行代码的时候后面添加 ‘2>>’ 或者 ‘2>’ 可以把标准的错误日志追加到一个文件中 例如:ls 错误文件名 2>> error.log 代码会把错误信息追加到error.log文件中
&> &>> 可以同时做错误重定向的同时还会做输出重定向 2&>1
管道: 管道用于将一个命令的输出作为另一个命令的输入,使用符号 |。
ls -l | grep “正则” 常用,查看匹配正则的当前目录下的所有文件信息
cat 文件名 | grep “关键词” > output.txt 上述命令会将 cat 命令的输出传递给 grep 进行过滤,并将过滤后的结果写入到 output.txt 文件中。
ll或者ls | grep ‘关键字’ 根据关键字列出匹配的文件信息
ping -c 1 baidu.com | grep from | cut -d ’ ’ -f 4 ping百度,匹配带有from的哪一行给cut按照空格分割取第四段
创建一个shell脚本
shell是作为系统内核的api服务层的一个壳子,他接受外部的请求并协调系统内核将处理的数据返回,我们可以创建一些脚本来做到复杂的命令执行,定时的任务等等不需要有人值守,他的原理就是根据算法一层一层的往内核提供命令
在编辑器中使用 vim hello.sh 可以创建一个shell文件,后缀可不写,需要注意的是,如果在脚本中定义函数,这个函数的作用域会一直持续到脚本结束,如果需要创建一个局部变量要加一个 local修饰
运行脚本的方式:bash 脚本名.sh source 脚本名.sh . 脚本名.sh ./脚本名.sh
#!/bin/bash # 设置默认脚本解释器为bashusername=$(whoami) #创建变量username 存储 whoami 的输出数据
local datatime=$(date) #创建临时变量datatime 存储 date 的储输出数据
echo "你好${suername},现在是${datatime}" #调用变量展示数据
#!/bin/bash# 设置默认脚本解释器为bash# 定义函数来打印99乘法表
print_multiplication_table() {# 外层循环,从1到9for i in {1..9}; do# 内层循环,从1到ifor j in $(seq 1 $i); do# 计算并打印乘法结果,格式化输出result=$((i * j))printf "%d x %d = %d\t" $j $i $resultdone# 每一行结束后换行echo ""done
}# 定义函数来计算阶乘
calculate_factorial() {local num=$1local factorial=1# 使用for循环计算阶乘for ((i = 1; i <= num; i++)); dofactorial=$((factorial * i))doneecho "阶乘 $num! = $factorial"
}# 调用函数打印99乘法表
echo "99乘法表:"
print_multiplication_table# 计算并打印1到5的阶乘
echo ""
for n in {1..5}; docalculate_factorial $n
done
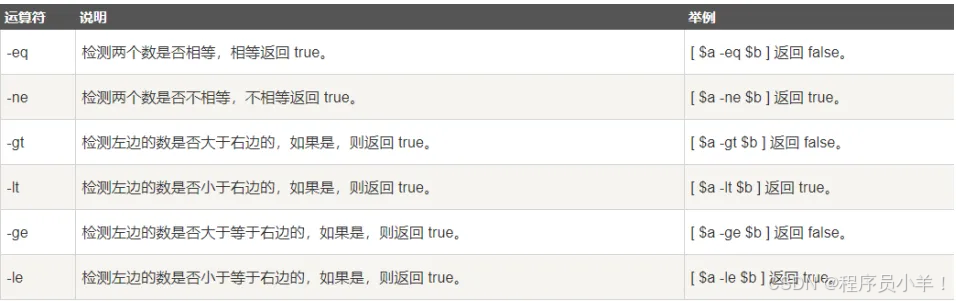
It :小于 | le :小于等于 | gt :大于 | ge :大于等于 | eq :等于 | ne :不等于
给编写的脚本添加可执行权限 chmod +x file1.sh
$0 标识当前脚本名 $1 标识第一个参数 $2 标识传入的第二个参数 通过参数给文件提供信息的案例:
#!/bin/bashfilename = $0
name = $1
channel = $2
echo "你好$name,欢迎你来到$filename中"
echo "你传入的值是 $channel"

配置环境变量:在用户home目录下 .profile,每次加载终端会刷新一次,.bashrc只有加载用户的时候才会被刷新,/etc/profile 是对所有用户都有效的系统环境变量 修改环境变量要使用 source /etc/profile
#!/bin/bash# 获取当前用户名
username=$(whoami)# 欢迎用户
echo "$username 你好,欢迎来玩猜数字游戏"
echo "正在重新生成一个数字..."# 生成一个随机数字
randomnum=$(echo $RANDOM)
echo "随机数已生成(为了测试,实际数字是:$randomnum)"# 无限循环,直到用户猜对数字或选择退出
while true; do# 提示用户输入数字echo "请输入一个数字:"read usernum# 判断用户输入的数字和随机数字的关系if [[ $usernum -ne $randomnum ]]; thenif [[ $usernum -lt $randomnum ]]; thenecho "数字小了"elseecho "数字大了"fielse# 用户猜对了数字echo "猜对了,太厉害了!再来一把?(y/n)"read restartif [[ $restart == "y" ]] || [[ $restart == "Y" ]]; then# 重新生成一个随机数字randomnum=$(echo $RANDOM)echo "新的随机数已生成(为了测试,实际数字是:$randomnum)"else# 用户选择不再玩,退出循环breakfifi
doneecho "游戏结束,谢谢你的参与!"
Shell编程和入门
脚本的启动有多种方式 bash 或 sh 执行脚本时会新开一个 bash,不同 bash 中的变量无法共享。而 source 或 . 是在同一个 bash 里面执行的,所以变量可以共享。 带路径运行或者使用bash添加路径都要有可执行的权限
# 这是一个单行注释<< EOF
我是一个多行注释
EOF# 定义变量
# 当希望变量存储更复杂的值时,就需要使用引号。引号用于处理带有空格字符的文本和文件名。
name = $(shell语句)
take = 'Hello how a u'
echo $name
echo ${take}
[双引号 " " 包围变量的值时,输出时会先解析里面的变量和命令,而不是把双引号中
的变量名和命令原样输出。这种方式比较适合字符串中附带有变量和命令并且想将其解
析后再输出的变量定义。 ' '适用纯文本]# 位置参数
# 在调用的时候传入的值,在内部使用 $1,$2或者${1},${2}……接收
echo "name: $1"
echo "age: $2"
# 脚本调用 bash test.sh zhangsan 18
返回》》》》》》》
name: zhangsan
age: 18# 其他位置变量
$$ 获取当前进程ID $0 表示文件名 $n 传递给脚本的参数,n数字 $@ $* 传递给脚本
或函数的所有参数 $# 传递给脚本或函数的参数个数。 $?获取上一个命令的退出状态,
或者上一个函数的返回值
function add() {
return $(expr $1 + $2)
}
# 调用函数
add 20 30
echo $?
返回》》》》》 50
# 字符串
单引号'' 和 双引号"" 都可以标识一个字符串,在shell中基本数据类型除了字符串和
数字类型就没有了
' ' :会原样输出,不吃变量,不可以内部出现单引号也不允许转义单引号
" " :引用输出,包含变量可得到该变量的值不是原样输出,可以输出单引号只要有转义# 获取长度
name=mrhelloworld echo ${#name} # 在变量前加一个#可以获得长度# 拼接字符串
str1=$name$age # 中间不能有空格
str2="$name $age" # 如果被双引号包围,那么中间可以有空格
str3=$name": "$age # 中间可以出现别的字符串
str4="$name: $age" # 这样写也可以
str5="${name}同学: ${age}岁" # 这个时候需要给变量名加上大括号# 截取字符串
str name1 = zhangsan
echo ${name:5} # 输出name从0开始第六位开始输出,结果为 san
echo ${name:3:2} # 输出name的第四位开始后的两位 结果 ng
echo ${name:0-10:5} # 0-表示从右边开始数 结果 hangsan# 匹配字符串
#*xx 返回字符串右边 %*xx 返回字符串的左边
url=https://www.baidu.com
echo ${url#*//} #返回//右边的东西 www.baidu.com
echo ${url%*//} #返回//左边的东西 https
# 数组(Array)是若干数据的集合,其中的每一份数据都称为元素,数组长度不固定
arr=(20 56 "mrhelloworld")
# 获取索引
echo arr[0] # 根据所引进获得值 20
# 指定索引添加值
arr[3] = 3# 获取长度
echo ${#arr[*]} # arr中所有元素的长度 4# 拼接字符串
array_new = (${array1[*]} ${array2[*]})# 删除数字或者指定值
unset arr[3] # 删除数组指定索引的数据
unset arr # 删除这个数组
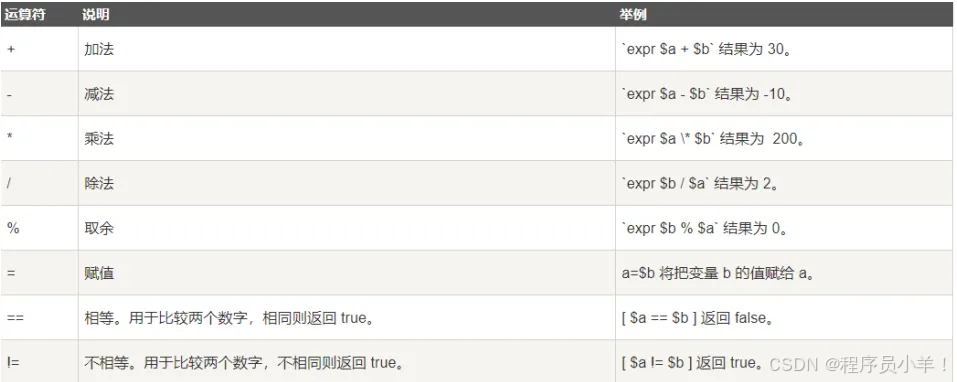
# Shell 不能直接进行算数运算,必须使用数学计算命令,expr 是一款表达式计算工具,使用它能完成表达式的求值操作。》》》测试脚本1》》EOF
#!/bin/bash
a=10
b=20
val=$(expr $a + $b)
echo "a + b : $val"
val=`expr $a - $b`
echo "a - b : $val"
val=`expr $a \* $b`
echo "a * b : $val"
val=`expr $b / $a`
echo "b / a : $val"
val=`expr $b % $a`
echo "b % a : $val"if [ $a == $b ]
thenecho "a 等于 b"
fiif [ $a != $b ]
thenecho "a 不等于 b"
fi
EOF《《《测试脚本1结束《《《》》》测试脚本2》》EOF
#!/bin/bash
a=10
b=20if [ $a -eq $b ]
thenecho "$a -eq $b : a 等于 b"
elseecho "$a -eq $b: a 不等于 b"
fiif [ $a -ne $b ]
thenecho "$a -ne $b: a 不等于 b"
elseecho "$a -ne $b : a 等于 b"
fiif [ $a -gt $b ]
thenecho "$a -gt $b: a 大于 b"
elseecho "$a -gt $b: a 不大于 b"
fiif [ $a -lt $b ]
thenecho "$a -lt $b: a 小于 b"
elseecho "$a -lt $b: a 不小于 b"
fiif [ $a -ge $b ]
thenecho "$a -ge $b: a 大于或等于 b"
elseecho "$a -ge $b: a 小于 b"
fiif [ $a -le $b ]
thenecho "$a -le $b: a 小于或等于 b"
elseecho "$a -le $b: a 大于 b"
fi
EOF《《《 测试脚本2结束《《《》》》测试脚本3》》》EOF
#!/bin/bash
a=10
b=20
if [ $a != $b ]
thenecho "$a != $b : a 不等于 b"
elseecho "$a == $b: a 等于 b"
fi
if [ $a -lt 100 -a $b -gt 15 ]
thenecho "$a 小于 100 且 $b 大于 15 : 返回 true"
elseecho "$a 小于 100 且 $b 大于 15 : 返回 false"
fi
if [ $a -lt 100 -o $b -gt 100 ]
thenecho "$a 小于 100 或 $b 大于 100 : 返回 true"
elseecho "$a 小于 100 或 $b 大于 100 : 返回 false"
fi
if [ $a -lt 5 -o $b -gt 100 ]
thenecho "$a 小于 5 或 $b 大于 100 : 返回 true"
else
echo "$a 小于 5 或 $b 大于 100 : 返回 false"
fi
if [[ $a -lt 100 && $b -gt 100 ]]
thenecho "返回 true"
elseecho "返回 false"
fi
if [[ $a -lt 100 || $b -gt 100 ]]
thenecho "返回 true"
elseecho "返回 false"
fi
EOF《《《测试脚本3结束《《《


》》》脚本1开始》》》EOF
#!/bin/bash
file="/root/test.sh"
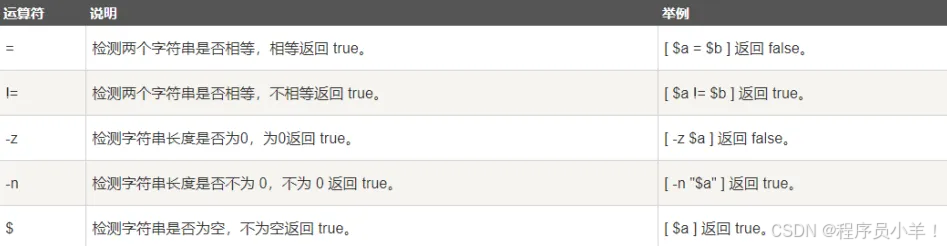
if [ -r $file ]
thenecho "文件可读"
elseecho "文件不可读"
fiif [ -w $file ]
thenecho "文件可写"
elseecho "文件不可写"
fiif [ -x $file ]
thenecho "文件可执行"
elseecho "文件不可执行"
fiif [ -f $file ]
thenecho "文件为普通文件"
elseecho "文件为特殊文件"
fiif [ -d $file ]
thenecho "文件是个目录"
elseecho "文件不是个目录"
fiif [ -s $file ]
thenecho "文件不为空"
else
EOF《《《脚本结束《《《

# if语法
if [ 条件 ]
then成立怎么完成
fi # 代表结束# if else
if [ 条件1 ]
then条件1成立
elif [ 条件2 ]
then条件1不成立但条件2成立
else都不成立的情况下
fi# 匹配语句 case shell不存在流程语句穿透
》》》脚本开始》》》EOF
#!/bin/bash
echo '输入 1 到 4 之间的数字:'
echo '你输入的数字为:'
read num
case $num in1)echo '你选择了 1';;2)echo '你选择了 2';;3)echo '你选择了 3';;4)echo '你选择了 4';;*)echo '你没有输入 1 到 4 之间的数字';;
esac
EOF《《《脚本结束《《《
# for 循环
for var in item1 item2 ... itemN
do # 开始循环循环体
done # 循环结束# while 循环
while 条件 # true为死循环,需要break
do循环体
done》》》脚本开始》》》EOF
for loop in 1 2 3 4 5
doecho "The value is: $loop"
donefor i in node01 node02 node03
doecho $i
donemy_array=("apple" "banana" "cherry" "date" "elderberry")
# 使用 for 循环遍历数组
for element in "${my_array[@]}"; doecho "Current element: $element"
donei=1
while(( $i<=5 ))
doecho $ilet "i++" # 只有在双引号中才能计算
done
EOF《《《脚本结束《《《# break 命令允许跳出所有循环(终止执行后面的所有循环)
# continue 命令不会跳出所有循环,仅仅跳出当前循环。
# 创建一个函数
demoFun(){echo "这是我的第一个 shell 函数!"
}echo "-----函数开始执行-----"
demoFun
echo "-----函数执行完毕-----"# 返回参数传递的函数
funWithParam(){
echo "第一个参数为 $1 !"
echo "第二个参数为 $2 !"
echo "第十个参数为 $10 !" # 错误写法,如果参数个数太多,达到或者超过了 10 个,那么就得用 ${n} 的形式来接收了
echo "第十个参数为 ${10} !" # 正确写法
echo "第十一个参数为 ${11} !"
echo "参数总数有 $# 个!"
echo "作为一个字符串输出所有参数 $* !"
}
funWithParam a b c d e f g h i j
开机自动运行
启用开启启动项文件,chmod +x /etc/rc.d/rc.local 以确保他可以被启动的时候自动执行,我们只需要在里面配置脚本就可以实现开机自启动 确保下面脚本正确然后将文件的内容添加到rc.local中 echo '/usr/local/scripts/auto_ntpdate.sh' >> /etc/rc.d/rc.local
正则表达式
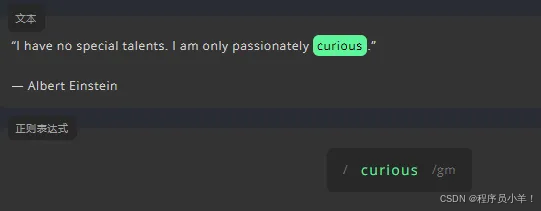
Regex 是正则表达式的简称。它便于匹配、查找和管理文本。 我们想要查找的字符或单词可以直接输入,就像搜索一样。例如,要找出文本中的 curious 一词,只需输入同样的内容:
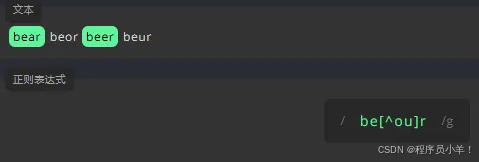
‘.’ 代表任意字符,包括空格或者特殊字符 , 如果一个词中的字符可以是各种字符,我们就将所有的可选字符写进中括号 [ ] 0中,^ 代表排除,例如不想要某一位是e、o [^eo]。
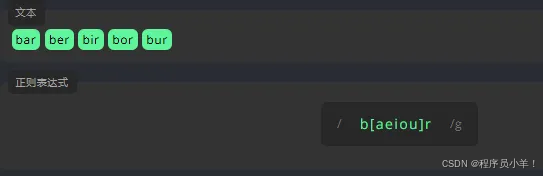
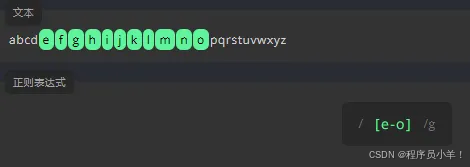
为了查找指定范围的字母,我们需要将起始字母和结束字母写进 [] 中,中间用连字符 - 分隔。它区分大小写。 a-z A-Z 0-9 例如: 匹配所有数字 [0-9]
重复 一些特殊字符用来指定一个字符在文本中重复的次数。它们分别是加号 +、星号 * 和问号 ?。
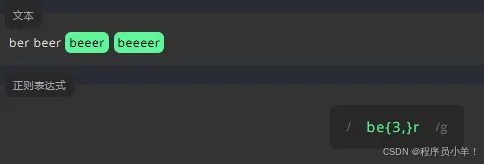
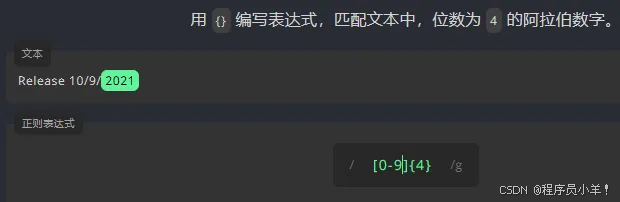
我们在字符后面加上 ,表示一个字符完全不匹配或可以匹配多次 例如:ber -> br ber beer为了表示一个字符可以出现一次或多次,我们将 + 放在它后面 例如:be+r -> ber beer为了表示一个字符是可选的,我们在它后面加一个 ? 例如:colou?r -> colour color指定一个字符的显示次数 可以在对应的旁边添加 {数字} 例如:be{2}r -> beer ,不匹配 ber beeer还可以指定最低显示位数 {3,} 例如下图: {最低位,最高位}
分组:() 我们可以对一个表达式进行分组,并用这些分组来引用或执行一些规则。为了给表达式分组,我们需要将文本包裹在 () 中。 竖线允许一个表达式包含多个不同的分支。所有分支用 | 分隔。
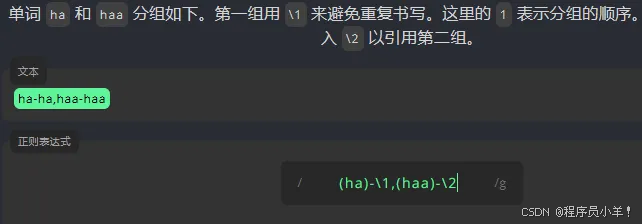
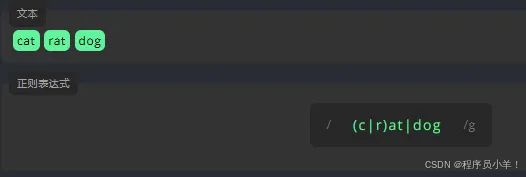
在书写正则表达式时,我们会用到特殊字符可以在后面添加一个 \实现转义 '$'代表只匹配末尾是html的数据
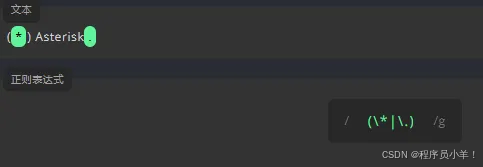
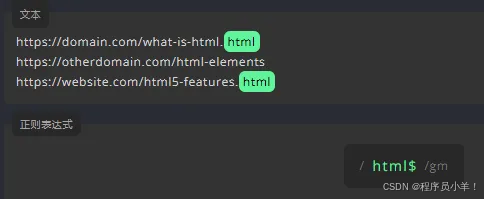
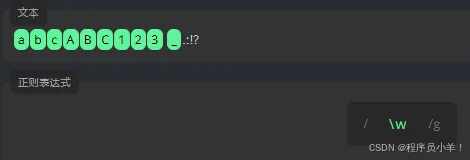
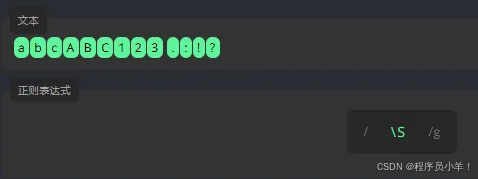
\w 字母、数字或者下划线的查询, \W 相反 只查\w之外的。 \d 表示匹配数字 \D 标识除了数字以外。 \s 空白字符 \S标识非空字符
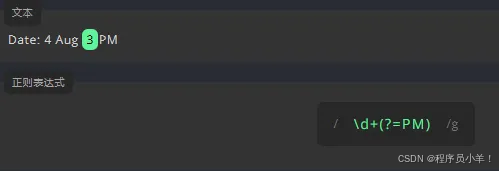
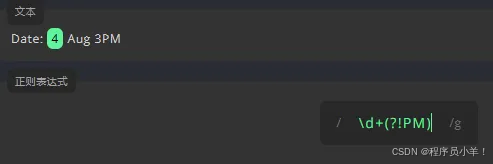
为了只匹配后面有 PM 的数值,我们需要在表达式后面使用正向先行断言 (?=) ,我们要在文本中匹配除小时值以外的数字。我们需要在表达式后面使用负向先行断言 (?!)
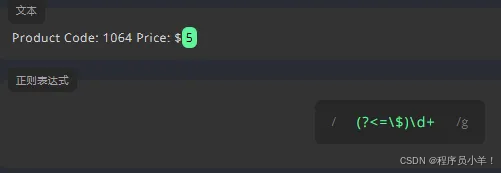
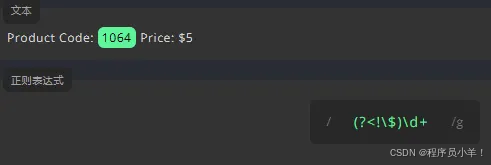
为了只匹配前面带有 $ 的数字。我们要在表达式前面使用正向后行断言 (?<=),并在括号内的 = 后面添加 $。为了只匹配前面没有 $ 的数字,我们要在表达式前用负向后行断言 (?<!),并在括号内的 ! 后面添加 $。
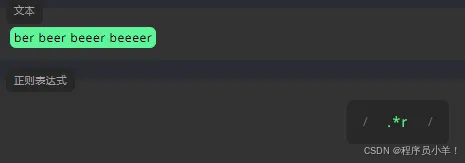
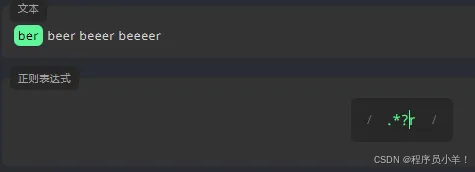
末尾使用 /g 标识全局 /gm 标识 多行查找 /gmi 标识大小写不敏感的。贪婪匹配:它匹配任何以 r 结尾的字符串,以及前面带有该字符串的文本,但它不会在第一个 r 处停止匹配。懒惰匹配在第一次匹配时停止。
常用正则表达式题目
题目 1
匹配电话号码 编写一个正则表达式,能够匹配以下格式的电话号码:
-
123-456-7890
-
(123) 456-7890
-
123 456 7890
-
123.456.7890
-
+91 (123) 456-7890
题目 2
匹配电子邮件地址 编写一个正则表达式,能够匹配有效的电子邮件地址。电子邮件地址的格式通常是:
-
username@domain.com -
username@sub.domain.com
题目 3
匹配IP地址 编写一个正则表达式,能够匹配IPv4地址。IPv4地址的格式是四个0-255之间的数字,用点分隔开,如:
-
192.168.1.1
-
10.0.0.1
题目 4
匹配日期 编写一个正则表达式,能够匹配以下格式的日期:
-
yyyy-mm-dd
-
dd/mm/yyyy
-
mm.dd.yyyy
题目 5
匹配URL 编写一个正则表达式,能够匹配有效的URL,如:
-
http://www.example.com
-
https://example.com
-
ftp://fileserver.com
-
www.example.com
题目 6
匹配16进制颜色代码 编写一个正则表达式,能够匹配16进制颜色代码,如:
-
#FFFFFF
-
#000
-
#abc123
题目 7
匹配密码 编写一个正则表达式,能够匹配满足以下条件的密码:
-
至少8个字符
-
至少包含一个大写字母
-
至少包含一个小写字母
-
至少包含一个数字
-
至少包含一个特殊字符(如 !@#$%^&*)
题目 8
匹配HTML标签 编写一个正则表达式,能够匹配简单的HTML标签,如:
-
<div> -
</div> -
<img src="image.jpg"/>
题目 9
匹配美国邮政编码 编写一个正则表达式,能够匹配美国的邮政编码(ZIP Code),格式如下:
-
5位数字:12345
-
9位数字:12345-6789
题目 10
匹配含有重复单词的句子 编写一个正则表达式,能够匹配包含重复单词的句子,例如:
- “This is is a test.”
题目 11
匹配单词边界 编写一个正则表达式,能够匹配以某个特定单词开始和结束的字符串。
题目 12
匹配货币金额 编写一个正则表达式,能够匹配货币金额的格式,如:
-
$100.00
-
$0.99
-
$1000
-
$1,000.00
定时任务
查看当前用户定时任务: crontab -l
查看指定用户的定时任务:crontab -lu 用户名
给自己创建定时任务:crontab -e 给别人创建定时任务:crontab -eu 用户名
删除定时任务 crontab -r 删除定时任务 给别人删除定时任务 crontab -re
编辑的定时任务的格式为: *(分钟) *(小时) *(天) *(月) *(星期) command 需要执行的命令
常见的时间案例:
# 每分钟执行
* * * * * command
# 每小时的第3和第15分钟执行
3,15 * * * * command
# 在上午8点到11点的第3和第15分钟执行
3,15 8-11 * * * command
# 每隔两天的上午8点到11点的第3和第15分钟执行
3,15 8-11 */2 * * command
# 每个星期一的上午8点到11点的第3和第15分钟执行
3,15 8-11 * * 1 command
# 每晚的21:30重启xxxxx
30 21 * * * /etc/init.d/xxxxx restart
# 每月1、10、22日的3:30重启
30 3 1,10,22 * * /etc/init.d/xxxxx restart
# 每周六、周日的1:10重启xxxxx
10 1 * * 6,0 /etc/init.d/xxxxx restart
# 每天18:00至23:00之间每隔30分钟重启
0,30 18-23 * * * /etc/init.d/xxxxx restart
# 每星期六的晚上23:00重启xxxxx
0 23 * * 6 /etc/init.d/xxxxx restart
# 每一小时重启xxxxx
0 */1 * * * /etc/init.d/xxxxx restart
# 凌晨1点到6点之间,每隔一小时重启xxxxx
0 1-6/1 * * * /etc/init.d/xxxxx restart
# 每月的6号与每周一到周三的11点重启xxxxx
0 11 6 * mon-wed /etc/init.d/xxxxx restart
# 一月一号的6点重启xxxxx
0 6 1 jan * /etc/init.d/xxxxx restart
# 每小时执行/etc/cron.hourly目录内的脚本
0 */1 * * * root run-parts /etc/cron.hourly
说明:如果去掉 run-parts 参数的话,后面就写要运行的某个脚本名,而不是目录名在线编写 Crontab:https://crontab.guru/examples.html
结尾:
本课程是一门以电商流量数据分析为核心的大数据实战课程,旨在帮助你全面掌握大数据技术栈的核心组件及其在实际项目中的应用。从零开始,你将深入了解并实践Hadoop、Hive、Spark和Flume等主流技术,为企业级电商流量项目构建一个高可用、稳定高效的数据处理系统。
在课程中,你将学习如何搭建并优化Hadoop高可用环境,熟悉HDFS分布式存储和YARN资源调度机制,为大规模数据存储与计算奠定坚实基础。随后,通过Hive数据仓库的构建与数仓建模,你将掌握如何将原始日志数据进行分层处理,实现数据清洗与结构化存储,从而为后续数据分析做好准备。
借助Spark SQL的强大功能,你将通过实战案例学会快速计算和分析关键指标,如页面浏览量(PV)、独立访客数(UV),以及通过数据比较获得的环比、等比等衍生指标。这些指标将帮助企业准确洞察用户行为和流量趋势,为优化营销策略提供科学依据。
同时,本课程还包含Flume数据采集与ETL入仓的实战模块,教你如何采集实时Web日志数据,并利用ETL流程将数据自动导入HDFS和Hive,确保数据传输和处理的高效稳定。
总体来说,这门课程面向希望提升大数据应用能力的技术人员和企业项目团队,紧密围绕公司电商流量项目的实际需求展开。通过系统的理论讲解与动手实践,你不仅能够构建从数据采集、存储、处理到可视化展示的完整数据管道,还能利用PV、UV、环比、等比等关键指标,全面掌握电商流量数据分析的核心技能。
今天这篇文章就到这里了,大厦之成,非一木之材也;大海之阔,非一流之归也。感谢大家观看本文
