第6篇、Kafka 高级实战:生产者路由与消费者管理
Kafka 高级实战:生产者路由与消费者管理(Python 版)
从基础到进阶:深入理解 Kafka 的生产者消息路由、消费者 Offset 管理,以及 Exactly-Once 语义实现
实战导向:提供完整的可运行代码示例,涵盖自定义分区器、消息头、大消息处理、Offset 控制、事务性消费等核心场景
🚀 快速开始
环境准备
# 基础客户端(纯 Python,适合大多数场景)
pip install kafka-python==2.0.2# 高级客户端(依赖 librdkafka,支持事务和更高性能)
pip install confluent-kafka==2.6.0# 可选:压缩算法支持
pip install lz4 snappy zstandard
前置条件
确保 Kafka 集群已启动:
# 使用 Docker 快速启动 Kafka
docker run -d --name kafka \-p 9092:9092 \-e KAFKA_ZOOKEEPER_CONNECT=localhost:2181 \-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092 \confluentinc/cp-kafka:latest
📚 核心概念深度解析
1. 生产者核心原理
🎯 分区与消息顺序
Kafka 的核心设计原则:只保证同一分区内的消息顺序。这意味着:
- ✅ 同一分区内:消息严格按发送顺序存储和消费
- ❌ 跨分区:无法保证全局顺序
- 🎯 业务顺序:通过相同 key 路由到同一分区实现业务层面的顺序保证
🔧 自定义分区器设计
关键挑战:Python 内置 hash() 函数使用随机种子,重启后结果不一致!
# ❌ 错误做法:Python hash() 不稳定
def bad_partitioner(key_bytes, all_partitions, available_partitions):return all_partitions[hash(key_bytes) % len(all_partitions)]# ✅ 正确做法:使用稳定哈希算法
import hashlib
def stable_partitioner(key_bytes, all_partitions, available_partitions):if key_bytes is None:return available_partitions[0] # 无 key 时的策略h = int(hashlib.md5(key_bytes).hexdigest(), 16)return all_partitions[h % len(all_partitions)]
📦 消息头(Headers)的威力
Headers 是消息的元数据载体,典型应用场景:
- 链路追踪:
trace_id、span_id - 协议版本:
schema_version、api_version - 业务标签:
event_type、source_system - 灰度控制:
canary_flag、experiment_id
⚡ 性能优化策略
| 优化维度 | 参数配置 | 效果 |
|---|---|---|
| 批量发送 | batch_size=64KB, linger_ms=50ms | 提升吞吐 3-5x |
| 压缩算法 | compression_type=lz4 | 减少网络传输 50-70% |
| 消息大小 | 超过 1MB 使用外部存储 | 避免 Broker 压力 |
🚨 大消息处理最佳实践
问题:Kafka 不适合处理大消息(>1MB)
解决方案:外部存储 + 消息引用模式
# 大消息处理示例
def send_large_message(user_id, large_data):# 1. 上传到对象存储s3_key = f"reports/{user_id}/{timestamp}.json"s3_client.put_object(Bucket="data-lake", Key=s3_key, Body=large_data)# 2. 发送引用消息message = {"type": "report_ready","user_id": user_id,"s3_location": f"s3://data-lake/{s3_key}","size_bytes": len(large_data),"checksum": hashlib.sha256(large_data).hexdigest()}producer.send("reports", key=user_id, value=message)
🛠️ 实战案例:生产者消息路由
案例一:用户事件按 ID 路由到固定分区
🎯 业务场景
电商系统中,需要保证同一用户的所有操作事件按时间顺序处理:
- 用户下单 → 支付 → 发货 → 确认收货
- 必须严格按顺序,避免状态不一致
💡 解决方案
通过自定义分区器,将相同 user_id 的消息路由到同一分区,实现业务层面的顺序保证。
📝 完整实现(kafka-python 版本)
# producer_user_routing.py
import hashlib
import json
import time
import uuid
from datetime import datetime
from kafka import KafkaProducerdef user_id_partitioner(key_bytes, all_partitions, available_partitions):"""基于稳定哈希的用户分区器核心特性:- 使用 MD5 确保跨进程/重启后的稳定性- 相同 user_id 始终路由到同一分区- 无 key 时使用轮询策略"""if key_bytes is None:# 无 key 时的策略:轮询到可用分区return available_partitions[0] if available_partitions else all_partitions[0]# 使用 MD5 确保稳定性(Python hash() 不稳定)h = int(hashlib.md5(key_bytes).hexdigest(), 16)idx = h % len(all_partitions)return all_partitions[idx]# 创建高性能生产者
producer = KafkaProducer(bootstrap_servers=["localhost:9092"],acks="all", # 强一致性:等待所有副本确认retries=5, # 重试次数linger_ms=10, # 批量发送等待时间batch_size=32 * 1024, # 32KB 批量大小compression_type="lz4", # LZ4 压缩(高性能)value_serializer=lambda v: json.dumps(v, ensure_ascii=False).encode("utf-8"),key_serializer=lambda k: str(k).encode("utf-8") if k is not None else None,partitioner=user_id_partitioner,
)topic = "user-events"def send_user_event(user_id: int, event_type: str, data: dict):"""发送用户事件,自动路由到固定分区Args:user_id: 用户ID(用作分区key)event_type: 事件类型data: 事件数据"""# 构建消息头(元数据)headers = [("trace_id", str(uuid.uuid4()).encode()),("schema_ver", b"v1.0"),("event_type", event_type.encode()),("timestamp", str(int(time.time() * 1000)).encode()),("source", b"order-service"),]# 构建事件消息event = {"user_id": user_id,"event_type": event_type,"timestamp": datetime.now().isoformat(),"data": data}# 发送消息(异步)future = producer.send(topic,key=user_id, # 关键:user_id 作为分区 keyvalue=event,headers=headers,)# 等待发送结果try:metadata = future.get(timeout=10)print(f"✅ 发送成功: {metadata.topic}-{metadata.partition}@{metadata.offset}")print(f" 用户: {user_id}, 事件: {event_type}")return metadataexcept Exception as e:print(f"❌ 发送失败: {e}")raisedef simulate_user_journey():"""模拟用户完整的购物流程"""user_id = 1001# 用户购物流程:必须按顺序处理events = [("view_product", {"product_id": "P001", "price": 99.9}),("add_to_cart", {"product_id": "P001", "quantity": 2}),("checkout", {"cart_total": 199.8, "payment_method": "credit_card"}),("payment_success", {"transaction_id": "TXN123", "amount": 199.8}),("order_created", {"order_id": "ORD456", "status": "confirmed"}),("order_shipped", {"tracking_number": "TRK789", "carrier": "FedEx"}),("order_delivered", {"delivery_time": "2024-01-15T10:30:00Z"}),]print(f"🛒 开始模拟用户 {user_id} 的购物流程...")for event_type, data in events:send_user_event(user_id, event_type, data)time.sleep(0.5) # 模拟事件间隔print(f"✅ 用户 {user_id} 购物流程完成!")if __name__ == "__main__":try:# 模拟多个用户的并发事件simulate_user_journey()# 模拟其他用户的事件send_user_event(1002, "view_product", {"product_id": "P002", "price": 149.9})send_user_event(1003, "add_to_cart", {"product_id": "P003", "quantity": 1})# 确保所有消息发送完成producer.flush(timeout=30)print("🎉 所有消息发送完成!")except KeyboardInterrupt:print("⏹️ 用户中断")finally:producer.close()print("🔒 生产者已关闭")
🚀 运行效果
python producer_user_routing.py
预期输出:
🛒 开始模拟用户 1001 的购物流程...
✅ 发送成功: user-events-0@1234用户: 1001, 事件: view_product
✅ 发送成功: user-events-0@1235用户: 1001, 事件: add_to_cart
✅ 发送成功: user-events-0@1236用户: 1001, 事件: checkout
...
🎉 所有消息发送完成!
🔍 关键特性验证
- 分区一致性:相同
user_id的消息都发送到同一分区 - 顺序保证:同一分区内的消息严格按发送顺序存储
- 元数据丰富:Headers 包含完整的追踪信息
- 高性能:批量发送 + 压缩提升吞吐量
🔒 顺序保证的进阶策略
幂等生产者(confluent-kafka 版本)
对于严格顺序要求的场景,推荐使用 confluent-kafka 的幂等生产者:
# producer_idempotent.py
import hashlib
import json
from confluent_kafka import Producer, KafkaException# 幂等生产者配置
conf = {"bootstrap.servers": "localhost:9092","enable.idempotence": True, # 启用幂等性"acks": "all", # 必须配合 acks=all"compression.type": "lz4","linger.ms": 10,"batch.size": 32768,"max.in.flight.requests.per.connection": 5, # 限制并发,避免乱序"retries": 2147483647, # 无限重试(幂等保证不重复)
}producer = Producer(conf)
topic = "user-events"def delivery_callback(err, msg):"""消息发送回调"""if err is not None:print(f"❌ 发送失败: {err}")else:print(f"✅ 发送成功: {msg.topic()}-{msg.partition()}@{msg.offset()}")def send_with_idempotence(user_id: int, event: dict):"""使用幂等生产者发送消息"""key_bytes = str(user_id).encode()# 计算稳定分区h = int(hashlib.md5(key_bytes).hexdigest(), 16)partition = h % 3 # 假设有3个分区headers = [("schema_ver", "v1.0"),("event_type", event.get("type", "unknown")),("user_id", str(user_id)),]producer.produce(topic=topic,partition=partition,key=str(user_id),value=json.dumps(event, ensure_ascii=False),headers=headers,on_delivery=delivery_callback,)# 使用示例
if __name__ == "__main__":events = [{"type": "login", "timestamp": "2024-01-15T10:00:00Z"},{"type": "view_product", "product_id": "P001"},{"type": "purchase", "amount": 99.9},]for event in events:send_with_idempotence(1001, event)producer.flush()
关键优势
| 特性 | kafka-python | confluent-kafka |
|---|---|---|
| 幂等性 | ❌ 不支持 | ✅ 原生支持 |
| 事务 | ❌ 不支持 | ✅ 完整支持 |
| 性能 | 🟡 中等 | ✅ 更高 |
| 稳定性 | 🟡 良好 | ✅ 企业级 |
📖 消费者核心原理
2. Offset 管理深度解析
🎯 Offset 的本质
Offset 是 Kafka 中消息在分区内的唯一标识,类似于数据库中的主键:
- 递增性:同一分区内严格递增
- 持久性:存储在
__consumer_offsets主题中 - 可控制性:支持手动设置和自动管理
🔄 消费语义对比
| 语义类型 | 处理顺序 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| At-most-once | 先提交,后处理 | 不重复 | 可能丢失 | 日志收集 |
| At-least-once | 先处理,后提交 | 不丢失 | 可能重复 | 业务处理 |
| Exactly-once | 事务性处理 | 不丢失不重复 | 复杂度高 | 金融交易 |
🛠️ 手动 Offset 控制
# consumer_offset_control.py
import json
import time
from kafka import KafkaConsumer, TopicPartitionclass SmartRebalanceListener:"""智能再均衡监听器"""def __init__(self, consumer):self.consumer = consumerself.processed_offsets = {} # 记录已处理的 offsetdef on_partitions_revoked(self, revoked_partitions):"""分区被收回前:安全提交进度"""print(f"🔄 分区被收回: {revoked_partitions}")try:# 提交当前所有已处理的 offsetself.consumer.commit()print("✅ 进度已安全提交")except Exception as e:print(f"❌ 提交失败: {e}")def on_partitions_assigned(self, assigned_partitions):"""分区分配后:恢复消费位置"""print(f"📋 分配到分区: {assigned_partitions}")# 可选:从自定义存储恢复 checkpointfor partition in assigned_partitions:checkpoint = self.load_checkpoint(partition)if checkpoint is not None:self.consumer.seek(partition, checkpoint)print(f"📍 恢复分区 {partition} 到 offset {checkpoint}")def load_checkpoint(self, partition):"""从外部存储加载 checkpoint(示例)"""# 实际项目中可以从 Redis/数据库 读取return None # 使用 Kafka 默认的 committed offsetdef create_advanced_consumer():"""创建高级消费者"""
consumer = KafkaConsumer(bootstrap_servers=["localhost:9092"],group_id="advanced-consumer-group",enable_auto_commit=False, # 手动提交,精确控制auto_offset_reset="earliest", # 无 offset 时从最早开始value_deserializer=lambda v: json.loads(v.decode("utf-8")),key_deserializer=lambda v: int(v.decode()) if v else None,max_poll_records=10, # 批量拉取session_timeout_ms=30000, # 会话超时heartbeat_interval_ms=10000, # 心跳间隔)# 设置再均衡监听器listener = SmartRebalanceListener(consumer)consumer.subscribe(["user-events"], listener=listener)return consumer, listenerdef process_message_batch(consumer, listener):"""批量处理消息"""
try:while True:# 批量拉取消息records = consumer.poll(timeout_ms=1000)if not records:continue# 按分区处理消息for partition, messages in records.items():print(f"\n📦 处理分区 {partition} 的 {len(messages)} 条消息")for message in messages:# 业务处理逻辑process_business_logic(message)# 记录已处理的 offsetlistener.processed_offsets[partition] = message.offset + 1# 批量提交该分区的 offsetconsumer.commit({partition: message.offset + 1})print(f"✅ 分区 {partition} 处理完成,已提交到 offset {message.offset + 1}")except KeyboardInterrupt:print("\n⏹️ 用户中断消费")except Exception as e:print(f"❌ 消费异常: {e}")raisedef process_business_logic(message):"""业务处理逻辑示例"""print(f" 🔍 处理消息: {message.topic}-{message.partition}@{message.offset}")print(f" 用户: {message.key}, 事件: {message.value.get('event_type', 'unknown')}")# 模拟业务处理time.sleep(0.1)if __name__ == "__main__":consumer, listener = create_advanced_consumer()try:print("🚀 开始消费消息...")process_message_batch(consumer, listener)
finally:consumer.close()print("🔒 消费者已关闭")
🎯 实战案例:消费者高级管理
案例二:按时间戳重放消息
🎯 业务场景
数据修复场景:发现某个时间点后的数据处理有误,需要重新处理历史数据:
- 从指定时间点开始重放
- 不重复处理已正确的数据
- 支持多次重放和调试
💡 解决方案
使用 Kafka 的时间戳定位功能,精确找到指定时间点对应的 offset,然后从该位置开始消费。
📝 完整实现
# consumer_replay.py
import time
import json
from datetime import datetime, timedelta
from kafka import KafkaConsumer, TopicPartitionclass MessageReplayer:"""消息重放器"""def __init__(self, topic: str, group_id: str):self.topic = topicself.group_id = group_idself.consumer = Nonedef create_replay_consumer(self):"""创建重放专用消费者"""self.consumer = KafkaConsumer(bootstrap_servers=["localhost:9092"],group_id=self.group_id,enable_auto_commit=False, # 不自动提交,支持多次重放auto_offset_reset="earliest",value_deserializer=lambda v: json.loads(v.decode("utf-8")),key_deserializer=lambda v: int(v.decode()) if v else None,)return self.consumerdef seek_to_timestamp(self, timestamp_ms: int):"""定位到指定时间戳"""print(f"🔍 定位到时间戳: {datetime.fromtimestamp(timestamp_ms/1000)}")# 1. 订阅主题并等待分区分配self.consumer.subscribe([self.topic])time.sleep(2) # 等待分区分配# 2. 获取分配的分区assignment = self.consumer.assignment()
while not assignment:self.consumer.poll(100)assignment = self.consumer.assignment()print(f"📋 分配到分区: {assignment}")# 3. 为每个分区创建时间戳查询timestamp_queries = [TopicPartition(tp.topic, tp.partition, timestamp_ms) for tp in assignment]# 4. 查询时间戳对应的 offsetoffsets_for_times = self.consumer.offsets_for_times(timestamp_queries)# 5. 定位到查询到的 offsetfor tp, offset_info in offsets_for_times.items():if offset_info is not None and offset_info.offset is not None:self.consumer.seek(tp, offset_info.offset)print(f"📍 分区 {tp.partition} 定位到 offset {offset_info.offset}")else:# 该时间戳之后没有消息,定位到末尾self.consumer.seek_to_end(tp)print(f"📍 分区 {tp.partition} 定位到末尾(时间戳后无消息)")def replay_messages(self, duration_minutes: int = 10):"""重放指定时长的消息"""print(f"🎬 开始重放最近 {duration_minutes} 分钟的消息...")message_count = 0start_time = time.time()try:
while True:records = self.consumer.poll(timeout_ms=1000)if not records:print("⏰ 没有更多消息,重放完成")breakfor partition, messages in records.items():print(f"\n📦 分区 {partition.partition} 收到 {len(messages)} 条消息")for message in messages:message_count += 1# 解析消息时间戳msg_timestamp = datetime.fromtimestamp(message.timestamp / 1000)print(f" 🔍 消息 {message_count}: {message.topic}-{message.partition}@{message.offset}")print(f" 时间: {msg_timestamp}")print(f" 用户: {message.key}, 事件: {message.value.get('event_type', 'unknown')}")# 业务处理逻辑self.process_replay_message(message)# 检查是否超过重放时长if time.time() - start_time > duration_minutes * 60:print(f"⏰ 重放时长达到 {duration_minutes} 分钟,停止重放")return message_countexcept KeyboardInterrupt:print("\n⏹️ 用户中断重放")except Exception as e:print(f"❌ 重放异常: {e}")raisereturn message_countdef process_replay_message(self, message):"""处理重放消息的业务逻辑"""# 这里实现具体的业务处理逻辑# 例如:重新计算用户积分、更新订单状态等event_type = message.value.get('event_type', 'unknown')user_id = message.keyif event_type == 'purchase':print(f" 💰 重新处理用户 {user_id} 的购买事件")# 重新计算积分、更新库存等elif event_type == 'refund':print(f" 💸 重新处理用户 {user_id} 的退款事件")# 重新计算退款金额、更新财务记录等# 模拟处理时间time.sleep(0.05)def close(self):"""关闭消费者"""if self.consumer:self.consumer.close()print("🔒 重放器已关闭")def replay_from_hours_ago(hours: int = 1):"""从指定小时前开始重放"""# 计算目标时间戳target_time = datetime.now() - timedelta(hours=hours)timestamp_ms = int(target_time.timestamp() * 1000)print(f"🎯 重放目标: {target_time}")# 创建重放器replayer = MessageReplayer("user-events", f"replay-group-{int(time.time())}")try:# 创建消费者replayer.create_replay_consumer()# 定位到目标时间replayer.seek_to_timestamp(timestamp_ms)# 开始重放message_count = replayer.replay_messages(duration_minutes=5)print(f"🎉 重放完成!共处理 {message_count} 条消息")finally:replayer.close()if __name__ == "__main__":# 从1小时前开始重放replay_from_hours_ago(hours=1)
🚀 运行效果
python consumer_replay.py
预期输出:
🎯 重放目标: 2024-01-15 09:00:00
🔍 定位到时间戳: 2024-01-15 09:00:00
📋 分配到分区: {TopicPartition(topic='user-events', partition=0)}
📍 分区 0 定位到 offset 1234
🎬 开始重放最近 5 分钟的消息...📦 分区 0 收到 3 条消息🔍 消息 1: user-events-0@1234时间: 2024-01-15 09:00:15用户: 1001, 事件: purchase💰 重新处理用户 1001 的购买事件
...
🎉 重放完成!共处理 15 条消息
🔒 Exactly-Once 语义实现
案例三:事务性消费处理
🎯 业务场景
金融交易系统:需要保证消费消息 → 处理业务 → 发送结果的原子性:
- 要么全部成功,要么全部失败
- 不能出现部分成功的情况
- 需要严格的事务保证
💡 解决方案
使用 confluent-kafka 的事务性生产者,将消费 offset 和业务处理结果打包在一个事务中。
📝 完整实现
# consumer_transactional.py
import json
import time
from confluent_kafka import Producer, Consumer, KafkaException, TopicPartitionclass TransactionalProcessor:"""事务性消息处理器"""def __init__(self, bootstrap_servers: str):self.bootstrap_servers = bootstrap_serversself.producer = Noneself.consumer = Noneself.transaction_id = f"txn-processor-{int(time.time())}"def setup_transactional_producer(self):"""设置事务性生产者"""conf = {"bootstrap.servers": self.bootstrap_servers,"enable.idempotence": True, # 启用幂等性"transactional.id": self.transaction_id,"acks": "all", # 必须配合 acks=all"compression.type": "lz4","linger.ms": 10,"batch.size": 32768,"max.in.flight.requests.per.connection": 5,}self.producer = Producer(conf)self.producer.init_transactions()print(f"✅ 事务性生产者已初始化: {self.transaction_id}")def setup_transactional_consumer(self, input_topic: str, group_id: str):"""设置事务性消费者"""conf = {"bootstrap.servers": self.bootstrap_servers,"group.id": group_id,"enable.auto.commit": False, # 关键:手动提交 offset"auto.offset.reset": "earliest","isolation.level": "read_committed", # 只读取已提交的事务}self.consumer = Consumer(conf)self.consumer.subscribe([input_topic])print(f"✅ 事务性消费者已初始化: {group_id}")def process_with_transaction(self, input_topic: str, output_topic: str, group_id: str):"""事务性处理消息"""print(f"🚀 开始事务性处理: {input_topic} → {output_topic}")processed_count = 0try:while True:# 1. 消费消息msg = self.consumer.poll(timeout=1.0)if msg is None:continueif msg.error():if msg.error().code() == KafkaException._PARTITION_EOF:continueelse:raise KafkaException(msg.error())print(f"\n📨 收到消息: {msg.topic()}-{msg.partition()}@{msg.offset()}")# 2. 开始事务self.producer.begin_transaction()print("🔄 开始事务")try:# 3. 处理业务逻辑processed_data = self.process_business_logic(msg)# 4. 发送处理结果self.producer.produce(output_topic,key=msg.key(),value=json.dumps(processed_data, ensure_ascii=False),headers=[("processed_at", str(int(time.time() * 1000)))])print(f"📤 发送处理结果到: {output_topic}")# 5. 将消费 offset 纳入事务partitions = [TopicPartition(msg.topic(), msg.partition(), msg.offset() + 1)]self.producer.send_offsets_to_transaction(partitions, self.consumer.consumer_group_metadata())print(f"📝 提交消费 offset: {msg.offset() + 1}")# 6. 提交事务self.producer.commit_transaction()print("✅ 事务提交成功")processed_count += 1except Exception as e:# 7. 回滚事务self.producer.abort_transaction()print(f"❌ 事务回滚: {e}")raiseexcept KeyboardInterrupt:print("\n⏹️ 用户中断处理")except Exception as e:print(f"❌ 处理异常: {e}")raiseprint(f"🎉 事务性处理完成!共处理 {processed_count} 条消息")def process_business_logic(self, msg):"""业务处理逻辑示例"""# 解析输入消息input_data = json.loads(msg.value())user_id = msg.key().decode() if msg.key() else "unknown"print(f" 🔍 处理用户 {user_id} 的事件: {input_data.get('event_type', 'unknown')}")# 模拟业务处理(例如:计算积分、更新余额等)processed_data = {"user_id": user_id,"original_event": input_data,"processed_at": time.time(),"result": "success","points_earned": 10, # 示例:获得积分"new_balance": 1000, # 示例:新余额}# 模拟处理时间time.sleep(0.1)return processed_datadef close(self):"""关闭生产者和消费者"""if self.consumer:self.consumer.close()if self.producer:self.producer.flush()print("🔒 事务处理器已关闭")def run_transactional_example():"""运行事务性处理示例"""processor = TransactionalProcessor("localhost:9092")try:# 设置事务性生产者和消费者processor.setup_transactional_producer()processor.setup_transactional_consumer("user-events", "transactional-group")# 开始事务性处理processor.process_with_transaction(input_topic="user-events",output_topic="processed-events",group_id="transactional-group")finally:processor.close()if __name__ == "__main__":run_transactional_example()
🔍 事务性处理的关键特性
- 原子性:消费、处理、发送要么全部成功,要么全部失败
- 一致性:不会出现部分处理的情况
- 隔离性:其他消费者只能看到已提交的事务结果
- 持久性:事务结果持久化到 Kafka
🚀 运行效果
python consumer_transactional.py
预期输出:
✅ 事务性生产者已初始化: txn-processor-1705123456
✅ 事务性消费者已初始化: transactional-group
🚀 开始事务性处理: user-events → processed-events📨 收到消息: user-events-0@1234
🔄 开始事务🔍 处理用户 1001 的事件: purchase
📤 发送处理结果到: processed-events
📝 提交消费 offset: 1235
✅ 事务提交成功
...
🎉 事务性处理完成!共处理 5 条消息
📋 最佳实践与故障排查
🚨 常见问题诊断
问题 1:消息顺序混乱
症状:相同用户的消息处理顺序不一致
原因分析:
- ❌ 使用了不稳定的哈希算法(如 Python
hash()) - ❌ 多线程并发发送相同 key 的消息
- ❌ 生产者重试导致乱序
解决方案:
# ✅ 使用稳定哈希
import hashlib
def stable_partitioner(key_bytes, all_partitions, available_partitions):h = int(hashlib.md5(key_bytes).hexdigest(), 16)return all_partitions[h % len(all_partitions)]# ✅ 启用幂等生产者
conf = {"enable.idempotence": True,"max.in.flight.requests.per.connection": 5, # 限制并发
}
问题 2:消费重复或丢失
症状:消息被重复处理或丢失
原因分析:
- ❌ 自动提交 + 处理失败 = 消息丢失
- ❌ 手动提交 + 处理失败 = 消息重复
解决方案:
# ✅ At-least-once 语义
def process_with_at_least_once(consumer):while True:records = consumer.poll(timeout_ms=1000)for partition, messages in records.items():for message in messages:try:# 先处理业务逻辑process_business_logic(message)# 处理成功后提交 offsetconsumer.commit({partition: message.offset + 1})except Exception as e:# 处理失败,不提交 offset,消息会重新消费print(f"处理失败: {e}")raise
问题 3:大消息传输失败
症状:超过 1MB 的消息发送失败
解决方案:
# ✅ 外部存储 + 消息引用模式
def send_large_message(user_id, large_data):# 1. 上传到对象存储s3_key = f"data/{user_id}/{int(time.time())}.json"s3_client.put_object(Bucket="data-lake", Key=s3_key, Body=large_data)# 2. 发送引用消息message = {"type": "large_data_ready","user_id": user_id,"s3_location": f"s3://data-lake/{s3_key}","size_bytes": len(large_data),"checksum": hashlib.sha256(large_data).hexdigest()}producer.send("large-messages", key=user_id, value=message)
⚡ 性能优化清单
生产者优化
| 参数 | 推荐值 | 说明 |
|---|---|---|
batch_size | 64KB | 批量发送提升吞吐 |
linger_ms | 50ms | 等待更多消息聚合 |
compression_type | lz4 | 平衡压缩率和性能 |
acks | all | 强一致性场景 |
retries | 3-5 | 避免无限重试 |
消费者优化
| 参数 | 推荐值 | 说明 |
|---|---|---|
max_poll_records | 100-500 | 批量拉取消息 |
session_timeout_ms | 30000 | 会话超时时间 |
heartbeat_interval_ms | 10000 | 心跳间隔 |
fetch_min_bytes | 1 | 最小拉取字节数 |
fetch_max_wait_ms | 500 | 最大等待时间 |
🏗️ 项目结构建议
kafka-advanced-python/
├── config/
│ ├── kafka_config.py # Kafka 配置管理
│ └── topics.py # Topic 定义
├── producers/
│ ├── user_event_producer.py # 用户事件生产者
│ ├── large_message_producer.py # 大消息生产者
│ └── transactional_producer.py # 事务生产者
├── consumers/
│ ├── user_event_consumer.py # 用户事件消费者
│ ├── replay_consumer.py # 重放消费者
│ └── transactional_consumer.py # 事务消费者
├── utils/
│ ├── partitioners.py # 自定义分区器
│ ├── serializers.py # 序列化器
│ └── monitoring.py # 监控工具
├── tests/
│ ├── test_producers.py # 生产者测试
│ └── test_consumers.py # 消费者测试
└── examples/├── user_routing_demo.py # 用户路由演示├── replay_demo.py # 重放演示└── transaction_demo.py # 事务演示
📊 监控与运维
关键指标监控
# monitoring.py
from kafka import KafkaProducer, KafkaConsumer
import timeclass KafkaMonitor:"""Kafka 监控工具"""def __init__(self, bootstrap_servers):self.bootstrap_servers = bootstrap_serversdef get_producer_metrics(self, producer):"""获取生产者指标"""metrics = producer.metrics()return {"batch_size_avg": metrics.get("batch-size-avg", 0),"record_send_rate": metrics.get("record-send-rate", 0),"record_error_rate": metrics.get("record-error-rate", 0),}def get_consumer_metrics(self, consumer):"""获取消费者指标"""metrics = consumer.metrics()return {"records_consumed_rate": metrics.get("records-consumed-rate", 0),"fetch_latency_avg": metrics.get("fetch-latency-avg", 0),"commit_rate": metrics.get("commit-rate", 0),}def check_topic_health(self, topic_name):"""检查 Topic 健康状态"""producer = KafkaProducer(bootstrap_servers=self.bootstrap_servers)consumer = KafkaConsumer(topic_name, bootstrap_servers=self.bootstrap_servers)try:# 检查分区数量partitions = producer.partitions_for(topic_name)print(f"Topic {topic_name} 有 {len(partitions)} 个分区")# 检查消费延迟consumer.poll(timeout_ms=1000)assignment = consumer.assignment()for partition in assignment:committed = consumer.committed(partition)end_offset = consumer.end_offsets([partition])[partition]lag = end_offset - committed if committed else 0print(f"分区 {partition.partition} 消费延迟: {lag}")finally:producer.close()consumer.close()
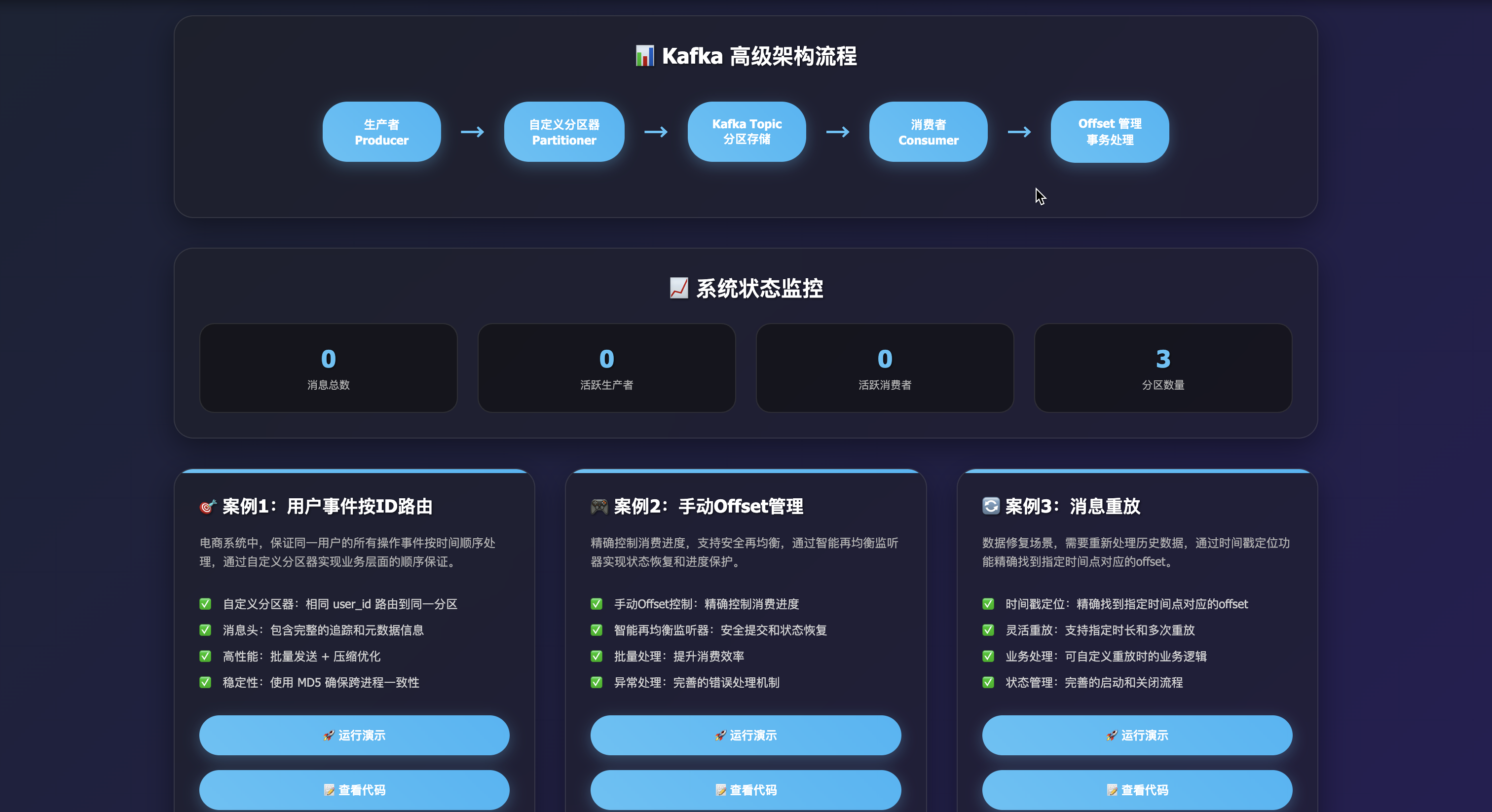

🎯 总结
📚 核心知识点回顾
生产者端
- 分区策略:使用稳定哈希确保相同 key 路由到同一分区
- 消息头:利用 Headers 传递元数据(追踪、版本、标签)
- 性能优化:批量发送 + 压缩 + 幂等性
- 大消息处理:外部存储 + 消息引用模式
消费者端
- Offset 管理:手动提交实现精确控制
- 再均衡处理:安全提交 + 状态恢复
- 时间戳重放:支持数据修复和调试
- 事务性消费:Exactly-Once 语义实现
🚀 实战价值
本文提供的代码示例涵盖了 Kafka 生产环境中的核心场景:
- ✅ 电商订单系统:用户事件按 ID 路由,保证订单状态一致性
- ✅ 数据修复:按时间戳重放,支持历史数据重新处理
- ✅ 金融交易:事务性消费,保证资金操作原子性
- ✅ 大文件传输:外部存储 + 消息引用,避免 Broker 压力
🔮 进阶方向
- Schema Registry:消息格式版本管理
- Kafka Streams:流处理应用开发
- Kafka Connect:数据集成和同步
- 多集群管理:跨数据中心数据复制
通过掌握这些高级特性,你将能够构建高可靠、高性能、易维护的 Kafka 应用系统!