YOLO 模型从 PyTorch 转换为 ONNX 并优化
YOLO 模型从 PyTorch 转换为 ONNX 并优化
在深度学习部署中,ONNX(Open Neural Network Exchange) 已成为跨框架与跨平台的标准格式。我们经常需要将 YOLOv8 在 PyTorch 中训练好的模型转换为 ONNX,并进行优化,以便在 CPU、GPU 或边缘设备 上高效推理。
本文将详细介绍:
- 如何从 PyTorch 导出 YOLOv8 为 ONNX
- 如何用 onnxruntime 优化模型(包含新旧版本对比)
- 每个操作的意义
- 优化选项与参数说明
1. 为什么要优化 ONNX 模型?
导出的原始 ONNX 文件里,可能包含很多“冗余算子”或“不适合推理加速的计算方式”。
比如:
- 多余的
Transpose、Identity节点。 - 可合并的
Conv → BatchNorm → Relu。 - 未展开的常量。
优化的目的就是:减少节点数、合并算子、提升推理速度,同时不改变模型的计算逻辑。
2. onnxruntime 的优化机制
在 onnxruntime 里,优化是在 InferenceSession 初始化 时完成的,控制参数就是:
options = ort.SessionOptions()
options.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_ALL
2.1 优化级别(GraphOptimizationLevel)
onnxruntime 提供 4 种优化级别:
| 选项 | 作用 | 典型场景 |
|---|---|---|
ORT_DISABLE_ALL | 完全不做优化 | 调试/测试 |
ORT_ENABLE_BASIC | 基础优化:常量折叠、消除无用节点 | 保守优化,结果最安全 |
ORT_ENABLE_EXTENDED | 扩展优化:算子融合(Conv+BN+Relu),节点重排序 | 性能更好,常用 |
ORT_ENABLE_ALL | 启用所有可用优化,包括 layout 优化、内存重用 | 生产环境推荐 |
默认是 ORT_ENABLE_ALL,你可以按需求调节。
2.2 其他常用参数(SessionOptions)
options.intra_op_num_threads = 4 # 单个算子内部使用的线程数
options.inter_op_num_threads = 2 # 不同算子之间的并行线程数
options.execution_mode = ort.ExecutionMode.ORT_PARALLEL # 启用并行执行
options.enable_mem_pattern = True # 内存复用模式
options.enable_cpu_mem_arena = True # CPU 内存分配优化
📌 意义:
- 线程数控制可以充分利用 CPU 多核。
- 内存优化选项可以减少内存占用,适合边缘设备。
3. 优化的保存方式
旧版本(≤1.16):
- 优化只存在于内存,不会保存到
.onnx文件。 - 即使你
onnx.save(),保存的还是原始模型。
新版本(≥1.17):
-
可以用:
options.optimized_model_filepath = "yolov8n_optimized.onnx"这样在 Session 初始化时,会把优化后的图写入文件。
👉 这就是新版和旧版最大的区别。
4. 环境准备
安装必要依赖:
pip install ultralytics onnx onnxruntime
如果需要高级优化(算子融合、量化),还可以安装:
pip install onnxruntime-tools
确认版本(非常关键,因为 API 有变化):
pip show onnxruntime
- 旧版 onnxruntime:≤ 1.16.x
- 新版 onnxruntime:≥ 1.17.0
5. 从 PyTorch 导出 YOLOv8 为 ONNX
from ultralytics import YOLO
from pathlib import PathMODELS_DIR = Path("models")# 加载 YOLOv8 模型
model = YOLO(str(MODELS_DIR / "yolov8n.pt"))# 导出为 ONNX 格式
model.export(format="onnx")
- 输入:PyTorch 的
.pt模型 - 输出:
yolov8n.onnx - 意义:ONNX 模型是跨平台的,可以在不同推理引擎(onnxruntime、TensorRT、OpenVINO)中运行。
👉 导出后,你可以用 Netron 查看模型结构,检查输入/输出 shape 是否正确。
5.1 什么是 Netron?
Netron 是一个 神经网络模型可视化工具,用来查看 .onnx、.pt、.h5、.tflite 等模型的网络结构。
- 你可以 直观查看每一层的算子(Conv、Relu、FC 等)。
- 支持 模型输入输出 shape、权重信息。
- 非常适合在导出 ONNX 后,检查网络结构是否符合预期。
5.2 怎么使用 Netron?
-
安装(桌面应用 / 浏览器版):
- 桌面版下载地址:https://github.com/lutzroeder/netron
- 浏览器版直接打开:https://netron.app
-
打开模型:
- 在桌面应用里,直接拖拽
yolov8n.onnx文件进去。 - 在网页端,点击
Open Model上传模型。
- 在桌面应用里,直接拖拽
-
查看结构:
- 你会看到类似一张「流程图」,每一层算子(Conv、BN、Relu、Concat 等)都展示出来。
- 可以点选层节点,查看 输入/输出 shape 和 权重参数。
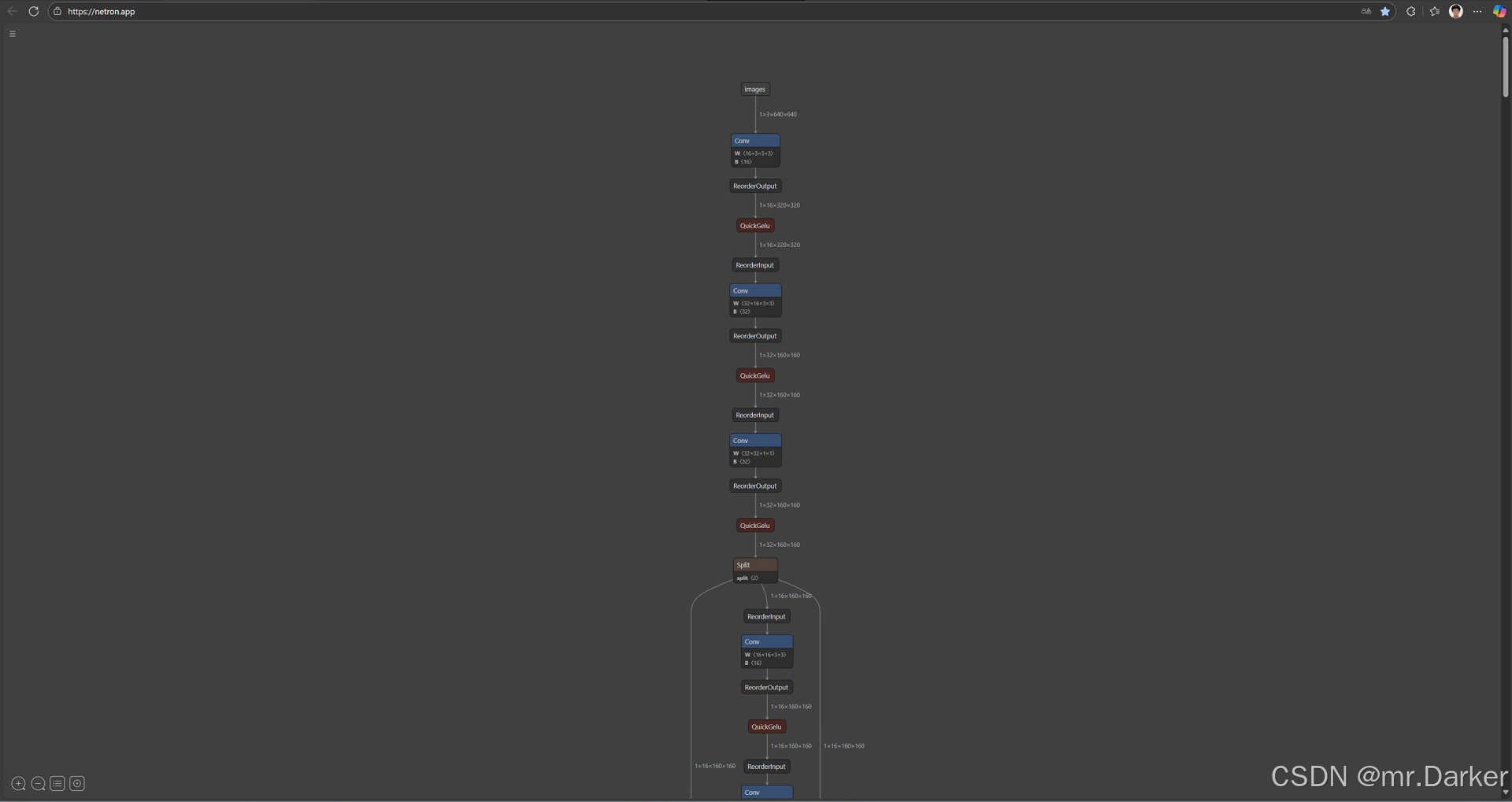
5.3 为什么要用 Netron?
- 确认 ONNX 导出是否成功(有时候导出会缺少算子或层)。
- 检查 输入输出 shape 是否正确(例如 YOLO 输入是否是
1x3x640x640)。 - 验证 模型优化前后层结构是否保持一致。
它就像模型的「显微镜」,帮我们把黑盒的 .onnx 文件拆开看清楚。
6. 优化 ONNX 模型(onnxruntime)
6.1 新旧版本对比
| 对比项 | 旧版 onnxruntime (≤1.16.x) | 新版 onnxruntime (≥1.17.0) |
|---|---|---|
| 导入方式 | from onnxruntime import GraphOptimizationLevel, SessionOptions | import onnxruntime as ort |
| 设置优化级别 | options.graph_optimization_level = GraphOptimizationLevel.ORT_ENABLE_ALL | options.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_ALL |
| 创建 Session | session = ort.InferenceSession("model.onnx", options) | session = ort.InferenceSession("model.onnx", sess_options=options) |
| 保存优化模型 | ❌ 不支持,优化仅存在内存 | ✅ options.optimized_model_filepath = "optimized.onnx" |
| 是否推荐 | ⚠️ 已过时 | ✅ 官方推荐 |
6.2 新版写法(推荐,onnxruntime ≥ 1.17)
import onnxruntime as ort
from pathlib import PathMODELS_DIR = Path("models")
onnx_path = str(MODELS_DIR / "yolov8n.onnx")
optimized_path = str(MODELS_DIR / "yolov8n_optimized.onnx")# 设置优化选项
options = ort.SessionOptions()
options.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_ALL
options.optimized_model_filepath = optimized_path# 创建 Session(会触发优化并保存)
session = ort.InferenceSession(onnx_path, sess_options=options)print(f"优化后的模型已保存到: {optimized_path}")
📌 意义:
- 优化发生在 Session 初始化 阶段。
- 优化图会被写入文件,避免每次加载时重复优化。
- 部署时直接加载优化好的
.onnx,加快推理启动速度。
6.3 旧版写法(已过时,onnxruntime ≤ 1.16.x)
from onnxruntime import GraphOptimizationLevel, SessionOptions
import onnxruntime as ortoptions = SessionOptions()
options.graph_optimization_level = GraphOptimizationLevel.ORT_ENABLE_ALLsession = ort.InferenceSession("yolov8n.onnx", options)
⚠️ 问题:
- 优化仅存在内存,不会保存到
.onnx文件。 - 部署时需要每次重新优化,影响启动性能。
7. 高级优化(可选,onnxruntime-tools)
如果需要进一步优化(算子融合、Transformer 专用优化、量化),可以用:
from onnxruntime_tools import optimizer
from pathlib import PathMODELS_DIR = Path("models")
onnx_path = str(MODELS_DIR / "yolov8n.onnx")
optimized_path = str(MODELS_DIR / "yolov8n_tools_optimized.onnx")# YOLO 没有专用类型,"transformer" 或 "bert" 都能工作
optimized_model = optimizer.optimize_model(onnx_path,model_type="bert",opt_level=99
)optimized_model.save_model_to_file(optimized_path)
print(f"进一步优化后的模型已保存到: {optimized_path}")
8. InferenceSession 和 onnxruntime-tools 对比
| 方法 | 优点 | 缺点 |
|---|---|---|
onnxruntime-tools | 支持更多优化策略(图融合、量化),可控性强 | 需要额外安装 |
options.optimized_model_filepath | 依赖少,直接在 onnxruntime 里完成 | 只做 onnxruntime 的图级优化,不包含高级策略 |
9. 验证优化后的模型
优化后需要验证模型是否能正确推理:
import numpy as np# 加载优化模型
session = ort.InferenceSession(str(MODELS_DIR / "yolov8n_optimized.onnx"))# 构造随机输入 (1, 3, 640, 640)
input_data = np.random.randn(1, 3, 640, 640).astype(np.float32)# 获取输入/输出名称
input_name = session.get_inputs()[0].name
output_name = session.get_outputs()[0].name# 运行推理
outputs = session.run([output_name], {input_name: input_data})print(outputs)
📌 意义:
- 确保优化后的模型依然输出正确结果。
- 可以进一步对比 PyTorch 原始输出和 ONNX 输出,确保差异在数值误差范围内(1e-4 ~ 1e-6)。
10. 总结
- 转换:使用 Ultralytics 将 YOLOv8
.pt导出为.onnx。 - 优化:用 onnxruntime 的
SessionOptions,推荐设置graph_optimization_level = ORT_ENABLE_ALL,并保存为新文件。 - 版本差异:onnxruntime ≥ 1.17 才能保存优化模型;旧版仅内存优化。
- 参数调整:可以通过线程数和内存选项进一步提升性能。
- 验证:运行推理,确认优化模型与原始模型一致。
- 高级优化:onnxruntime-tools 可做更激进的算子融合与量化。